基于協同過濾決策樹的商品推薦算法的研究
2020-04-20 11:32:44常昊楊盛泉
價值工程 2020年9期
關鍵詞:大數據
常昊 楊盛泉


摘要: 大數據時代的到來,生活種每天都產生著大量的數據,對這些數據進行分析并推薦商品在電商領域就會顯得尤為的重要。協同過濾算法是目前發展比較成熟的,在各領域都取得了非常好的效果。但傳統的協同過濾算法在計算相似度和預測評分時太過粗糙,并且效率很低。我們將協同過濾算法與決策樹算法相結合,并對算法進行改進,創建一種協同過濾決策樹算法來對商品進行推薦,并將新的協同過濾決策樹算法運行在Hadoop平臺上。Hadoop是一種分布式的處理大規模數據的云計算平臺。實驗證明,改進后算法使得推薦的準確率有了顯著的提升。
Abstract: With the advent of the era of big data, daily life is generating a large amount of data. Analyzing and recommending these data will be particularly important in the field of e-commerce. Collaborative filtering algorithms are currently relatively mature and have achieved very good results in various fields. However, the traditional collaborative filtering algorithm is too rough and inefficient in calculating similarity and prediction score. We combine the collaborative filtering algorithm with the decision tree algorithm and improve the algorithm to create a collaborative filtering decision tree algorithm to recommend products and run the new collaborative filtering decision tree algorithm on the Hadoop platform. Hadoop is a distributed cloud computing platform for processing large-scale data. Experiments have shown that the improved algorithm has significantly improved the accuracy of recommendation.
關鍵詞:大數據;推薦算法;協同過濾;Hadoop
Key words: big data;recommendation algorithm;collaborative filtering;Hadoop
中圖分類號:TP311.5? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? 文獻標識碼:A? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? 文章編號:1006-4311(2020)09-0127-03
0? 引言
隨著科技的發展,互聯網技術也隨之迅速發展和普及,這就使得網絡上的數據每天高速增長,豐富用戶生活消費的同時,大量信息資源膨脹迅速的問題也隨之出現,“信息過載”也是目前互聯網正面對的難題。“信息過載”指的是用戶難以從海量數據中準確并且迅速地定位到自己所需要的信息。推薦系統的出現大大地緩解了“信息過載”這一難題。推薦系統根據用戶的歷史行為,預測并且推薦使用戶滿意的物品,實現個性化的服務。推薦系統是自動智能的為用戶推薦物品,而且還會根據用戶行為的變化,動態的調整推薦的物品類型,真正意義上避免了“信息過載”的困擾。
推薦算法是推薦系統的核心,本文主要研究了在Hadoop平臺下的推薦算法,該推薦算法將決策樹和協同過濾算法相結合,并對傳統的協同過濾算法進行改進,來克服傳統算法可擴展性差、新用戶和新項目冷啟動等缺點,提高推薦的時效性[1]。
1? 傳統的協同過濾算法簡介
協同過濾算法算是目前的推薦系統中運用最為成功的信息過濾算法,主要做法是提取用戶所產生的歷史行為做出推薦[2]。傳統的協同過濾算法主要分為基于物品的協同過濾算法(ItemCF)和基于用戶的協同過濾算法(UserCF)[2]。本文將會選取基于物品的協同過濾算法做為主研究方向,其核心流程如下:收集用戶偏好、找到相似的用戶或物品、計算推薦,其中最為核心部分為相似度的計算。本文將采用Cosine相似度方法,也就是余弦相似度方法來計算物品或用戶的相似度。如公式(1)所示
(1)
2? 推薦算法設計
協同過濾有它自身所存在的難題,比如“冷啟動”和“稀疏性”。本文為解決此難題,設計了一種混合推薦算法。
2.1 人口統計學推薦的提出
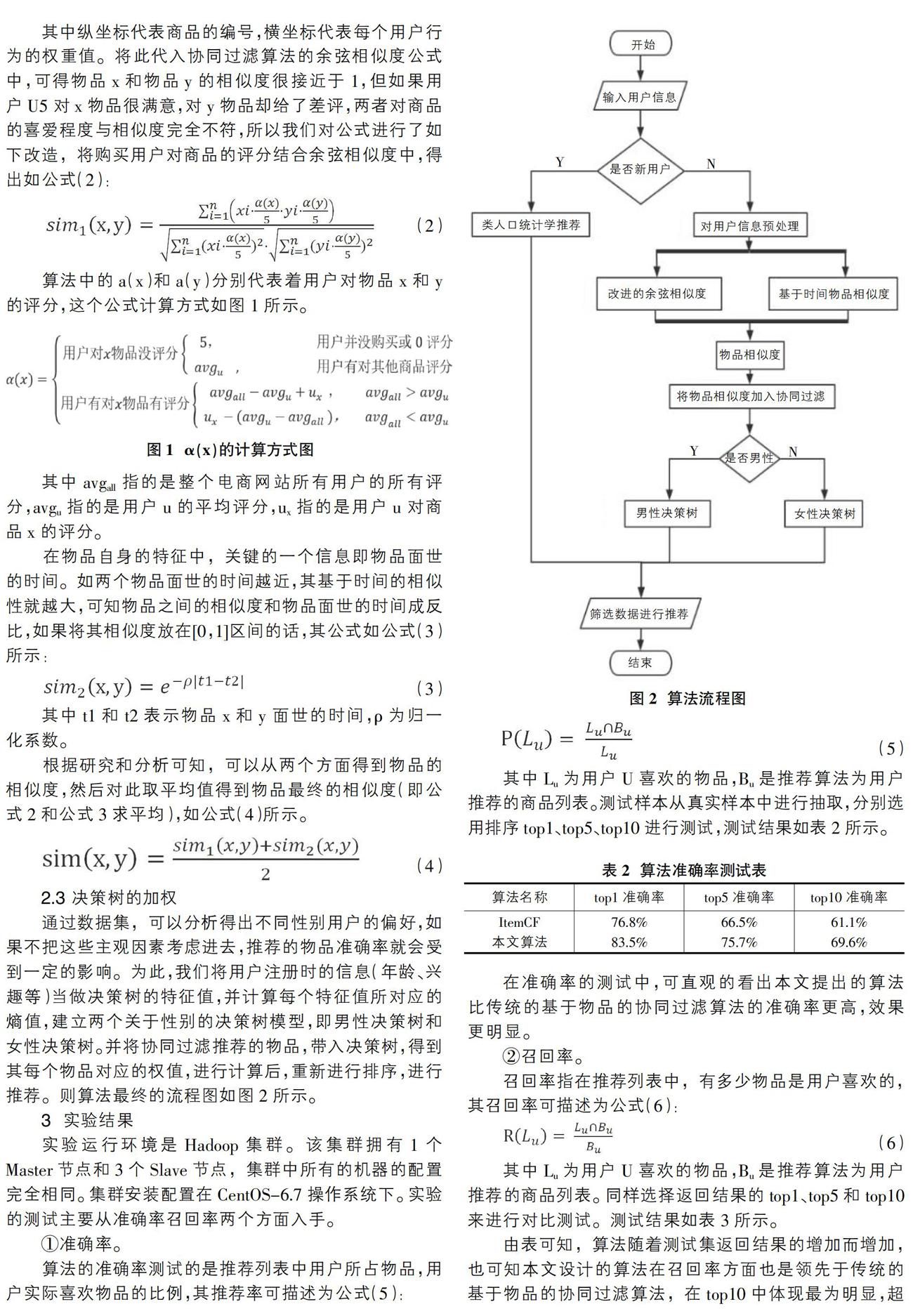
“冷啟動”問題,指的是在新用戶剛注冊賬號的時,并沒有生成提供信息的行為數據,從而導致協同過濾算法無法有效的實施。如何解決這個問題,各國學者專家提出了不同的方案,如隨機推薦法、平均值法等[3]。本文將采用人口統計學推薦的方法來解決“冷啟動”的問題。首先對用戶進行判斷,如果是新用戶,算法走人口統計學推薦的分支,如果不是,則走協同過濾混合推薦的分支。目前的電商網站在用戶注冊的時候,都會對相關信息以及喜好進行相應的登記和調查,根據這些信息即可進行人口統計學推薦,有效的解決了協同過濾算法“冷啟動”的問題。
2.2 協同過濾算法的改進
相似度的計算是協同過濾算法最關鍵的一步,物品相似度的精準程度將會直接影響著整個算法的可靠性,所以本文將對算法相似度的計算進行改進。
我們推薦系統中的用戶行為主要劃分為點擊、加入購物車、收藏和購買4種行為,在矩陣中購買的權重肯定是最高的(假定點擊為1,加入購物車為2,收藏為3,購買為10),根據公式3,我們計算如表1的矩陣。
其中縱坐標代表商品的編號,橫坐標代表每個用戶行為的權重值。將此代入協同過濾算法的余弦相似度公式中,可得物品x和物品y的相似度很接近于1,但如果用戶U5對x物品很滿意,對y物品卻給了差評,兩者對商品的喜愛程度與相似度完全不符,所以我們對公式進行了如下改造,將購買用戶對商品的評分結合余弦相似度中,得出如公式(2):
(2)
算法中的a(x)和a(y)分別代表著用戶對物品x和y的評分,這個公式計算方式如圖1所示。
其中avgall指的是整個電商網站所有用戶的所有評分,avgu指的是用戶u的平均評分,ux指的是用戶u對商品x的評分。
在物品自身的特征中,關鍵的一個信息即物品面世的時間。如兩個物品面世的時間越近,其基于時間的相似性就越大,可知物品之間的相似度和物品面世的時間成反比,如果將其相似度放在[0,1]區間的話,其公式如公式(3)所示:
(3)
其中t1和t2表示物品x和y面世的時間,ρ為歸一化系數。
根據研究和分析可知,可以從兩個方面得到物品的相似度,然后對此取平均值得到物品最終的相似度(即公式2和公式3求平均),如公式(4)所示。
(4)
2.3 決策樹的加權
通過數據集,可以分析得出不同性別用戶的偏好,如果不把這些主觀因素考慮進去,推薦的物品準確率就會受到一定的影響。為此,我們將用戶注冊時的信息(年齡、興趣等)當做決策樹的特征值,并計算每個特征值所對應的熵值,建立兩個關于性別的決策樹模型,即男性決策樹和女性決策樹。并將協同過濾推薦的物品,帶入決策樹,得到其每個物品對應的權值,進行計算后,重新進行排序,進行推薦。則算法最終的流程圖如圖2所示。
3? 實驗結果
實驗運行環境是Hadoop集群。該集群擁有1個Master節點和3個Slave節點,集群中所有的機器的配置完全相同。集群安裝配置在CentOS-6.7操作系統下。實驗的測試主要從準確率召回率兩個方面入手。
①準確率。
算法的準確率測試的是推薦列表中用戶所占物品,用戶實際喜歡物品的比例,其推薦率可描述為公式(5):
(5)
其中Lu為用戶U喜歡的物品,Bu是推薦算法為用戶推薦的商品列表。測試樣本從真實樣本中進行抽取,分別選用排序top1、top5、top10進行測試,測試結果如表2所示。
在準確率的測試中,可直觀的看出本文提出的算法比傳統的基于物品的協同過濾算法的準確率更高,效果更明顯。
②召回率。
召回率指在推薦列表中,有多少物品是用戶喜歡的,其召回率可描述為公式(6):
(6)
其中Lu為用戶U喜歡的物品,Bu是推薦算法為用戶推薦的商品列表。同樣選擇返回結果的top1、top5和top10來進行對比測試。測試結果如表3所示。
由表可知,算法隨著測試集返回結果的增加而增加,也可知本文設計的算法在召回率方面也是領先于傳統的基于物品的協同過濾算法,在top10中體現最為明顯,超出傳統協同過濾12%。
4? 結論
本文設計的推薦算法模型在計算物品相似度之前采用了判斷語句,有效的解決了系統的冷啟動問題,提升了算法的可行性。在計算物品相似度時增加了物品面世時間的條件,并且在傳統的余弦相似度算法上做出了進一步的改進,使得算法的準確率得到了有效的提升。最后通過數據集驗證了改進后算法的在整體上都優于傳統的協同過濾算法,并在Hadoop分布式系統中運行,充分發揮了在大數據環境下,Hadoop分布式系統計算數據的優勢。
參考文獻:
[1]冀曉巖.基于Hadoop的電子商務個性化推薦研究與實現[D].蘭州交通大學,2017.
[2]劉暢,吳清烈.基于協同過濾的大規模定制個性化推薦方法[J].工業工程,2014,17(04):24-28,34.
[3]張磊.基于遺忘曲線的協同過濾研究[J].電腦知識與技術,2014,10(12):2757-2762.
作者簡介:常昊(1994-),男,陜西榆林人,碩士。
猜你喜歡
中國市場(2016年36期)2016-10-19 04:41:16
中國市場(2016年36期)2016-10-19 03:31:48
中國市場(2016年35期)2016-10-19 01:30:59
商(2016年27期)2016-10-17 06:26:00
今傳媒(2016年9期)2016-10-15 23:35:12
今傳媒(2016年9期)2016-10-15 22:09:11
新聞世界(2016年10期)2016-10-11 20:13:53
科技視界(2016年20期)2016-09-29 10:53:22
中國記者(2016年6期)2016-08-26 12:36:20
