基于深度學習的風格遷移算法的研究與實現(xiàn)
2020-04-29 10:55:12曾國輝
智能計算機與應用 2020年2期
王 鹿, 曾國輝, 黃 勃
(上海工程技術大學 電子電氣工程學院, 上海 201620)
0 引 言
近年來,隨著人工智能、計算機視覺技術的迅猛發(fā)展,越來越多的機器學習應用場景在不斷涌現(xiàn)。與此同時,目前有著較好表現(xiàn)的監(jiān)督學習需要大量的標注數(shù)據(jù),但標注數(shù)據(jù)是一項枯燥無味且花費巨大的任務,所以無監(jiān)督的image-to-image式風格遷移學習即吸引了學界的更多關注,并已成為深度學習技術的重要應用之一。對于傳統(tǒng)監(jiān)督式機器學習而言,遷移學習都是基于同分布假設[1],同時需要大量標注數(shù)據(jù),然而實際使用不同數(shù)據(jù)集的過程中可能出現(xiàn)一些問題,比如數(shù)據(jù)分布差異,訓練數(shù)據(jù)過期,也就是已然做過標定的數(shù)據(jù)要被丟棄,有些應用中數(shù)據(jù)分布也會隨著時間的推移產(chǎn)生變化。因此,如何充分利用已經(jīng)標注好的數(shù)據(jù),同時又保證在新任務上的模型精度已經(jīng)成為一個亟需解決的難題。基于此,本文擬對基于深度學習的遷移學習進行研究[2-3]。
目前,研究發(fā)現(xiàn)對一幅圖像而言,風格和內(nèi)容在卷積神經(jīng)網(wǎng)絡中的表達是可以分開的。也就是說,研究中可以獨立地操縱2種表達來產(chǎn)生新的、可以感受的有意義的圖片。在本文中,將使用VGG-16、VGG-19和 Cycle GAN[4],來實現(xiàn)風格遷移,對比這3種網(wǎng)絡的結果,分析后發(fā)現(xiàn),Cycle GAN的效果最好,VGG-16和VGG-19雖然也有一定的效果,但是合成圖像的整體風格并不突出,不能滿足本文研究的需求。
1 圖像風格遷移算法
圖像風格遷移技術主要有2種。一種是由Gatys等人[5]率先提出的NAAS,該方法以VGG網(wǎng)絡為基礎進行損失網(wǎng)絡的設計;另一種是Johnson等人[6]提出的快速圖像風格遷移技術(FNST),該方法基于Gatys等人的研究成果,在損失網(wǎng)絡的前端添加了一個Image Transform Net,該網(wǎng)絡基于殘差網(wǎng)絡進行設計。兩者之間的關系如圖1所示。
Gatys所提出的NAAS是在VGG網(wǎng)絡的基礎上,利用梯度下降,經(jīng)過若干次的迭代從而獲得轉換風格后的圖像。該方法的整體流程如圖2所示。

圖1 快速圖像風格遷移方法
Fig. 1 Fast image style migration method
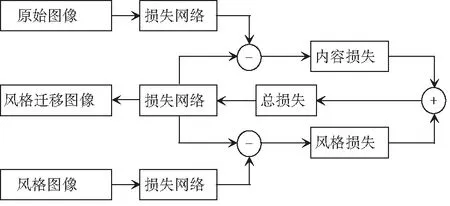
圖2 NASS工作流程圖
1.1 VGG網(wǎng)絡
VGG (Visual Geometry Group)隸屬于牛津大學, VGG自2014年先后發(fā)布了網(wǎng)絡模型VGG11~VGG19, 該小組研究證明了增加神經(jīng)網(wǎng)絡的深度能夠在一定程度上影響神經(jīng)網(wǎng)絡的性能。VGG網(wǎng)絡結構簡單,其卷積層和池化層可以劃分為不同的塊(Block),從前到后依次編號為Block1~Block5。每一個塊內(nèi)包含若干卷積層和一個池化層。使用同樣大小的卷積核尺寸 (3×3) 和最大池化尺寸 (2×2)。此外,VGG網(wǎng)絡還有5個最大池化層,分別分布在不同的卷積層之下[7-8]。
(1) VGG16。VGG16共有13個卷積層(Convolutional Layer),分別用conv3-XXX表示,3個全連接層(Fully connected Layer)分別用FC-XXXX表示,5個池化層(Pool layer)分別用MaxPool表示。卷積層和全連接層具有權重系數(shù),因此也被稱為權重層,總數(shù)目為13+3=16,這即是VGG16中16的來源。考慮到池化層不涉及權重,因此不屬于權重層,不被計數(shù)。VGG16神經(jīng)網(wǎng)絡模型結構如圖3所示。
(2) VGG19。VGG19共有16個卷積層和3個全連接層。如圖4所示。
以圖4為例,在VGG19的Block2中包含2個卷積層,卷積核為3×3×3,通道數(shù)都是128,而Block4包含4個卷積層,1個最大池化層,通道數(shù)是512。
1.2 Cycle GAN
傳統(tǒng)的GAN的G是將隨機噪聲轉換為圖片,但風格遷移中需要將圖片轉為圖片,所以這個時候就要將圖片作為G的輸入,而G則是學習一種映射了。但是用單獨一個GAN的訓練并不穩(wěn)定,可能導致所有照片全部映射到同一張圖片的mode collapse[9]。為此,就提出了Cycle GAN用來解決這個問題,Cycle GAN是將2個GAN組合起來,其目的是實現(xiàn)非成對image的轉換,尤其適用于圖像風格遷移中。為了使得GAN更加穩(wěn)定,引入了此雙向映射的機制,即A→B的GAN和B→A的GAN,同時加入了一個cycle_loss,cycle_loss是采用L1損失設計而成[10-11]。所以研究得到Cycle GAN的損失函數(shù),可將其寫為:

圖3 VGG16網(wǎng)絡結構圖

圖4 VGG19網(wǎng)絡結構圖
LGAN(F,DX,Y,X)=Ex~Pdata(x)[logDX(x)],
(1)
LGAN(G,DY,X,Y)=Ey~Pdata(y)[logDY(y)],
(2)
接下來,研究得到了循環(huán)一致性損失可表示為:
Lcyc(G,F)=Ex~Pdata(x)[‖F(xiàn)(G(x))-x‖1],
(3)
進而,推得總損失的數(shù)學公式如下:
L(G,F,DX,DY)=LGAN(G,DY,X,Y)+
LGAN(F,DX,Y,X)+λLcyc(G,F).
(4)
1.3 損失函數(shù)

(5)
(6)
(7)
綜上可知,總的損失函數(shù)可由下式來計算:
(8)
其中,α和β分別是內(nèi)容和風格在圖像重構中的權重因子,且滿足:
α+β=1.
(9)
2 實驗
2.1 遷移效果的衡量指標
(1)峰值信噪比(Peak Signal to Noise Ratio,PSNR)[12]:這是一種全參考的圖像質量評價指標。運算中需用到如下數(shù)學公式:
(10)
(11)
其中,MSE(Mean Square Error)表示當前圖像X和參考圖像Y的均方誤差;H、W分別表示圖像的高度和寬度;n為每像素的比特數(shù),一般取8,即像素灰階數(shù)為256。PSNR,單位是dB,取值范圍為(0,∞),數(shù)值越大表示失真越小。
(2)結構相似性(structural similarity,SSIM)[13]: 這也是一種全參考的圖像質量評價指標,可分別從亮度、對比度、結構三方面度量圖像相似性。運算中涉及的數(shù)學公式可表示為:
(12)
(13)
(14)
其中,uX,uY分別表示圖像X和Y的均值;σX,σY分別表示圖像X和Y的方差;σXY表示圖像X和Y的協(xié)方差,即:
(15)
(16)
(17)
其中,C1、C2、C3為常數(shù),為了避免分母為0的情況,SSIM取值范圍[0,1],值越大,表示圖像失真越小。
2.2 實驗環(huán)境
本實驗選擇Python語言和Tensorflow, Pytorch框架進行圖像風格遷移的仿真測試。實驗環(huán)境為 Intel(R) Core(TM) i5-8300H 2.1GHz CPU, GPU 為 NVIDIA。
2.3 訓練部分
(1) VGG16和VGG19訓練。由于VGG網(wǎng)絡深,網(wǎng)絡架構權重數(shù)量非常大,導致訓練非常緩慢,故研究用到的模型就是在ImageNet數(shù)據(jù)集上預訓練的模型。
研究將從預訓練的模型中,獲取卷積層部分的參數(shù),用于構建仿真中使用的模型,這些參數(shù)均是作為常量使用,即不再被訓練,在反向傳播的過程中也不會改變,此外VGG中的全連接層舍棄掉。參數(shù)設置見表1。
(2) Cycle GAN。使用vangogh2photo數(shù)據(jù)集,Generator采用的是文獻[6]中的網(wǎng)絡結構;一個residual block組成的網(wǎng)絡,降采樣部分采用stride 卷積,增采樣部分采用反卷積;Discriminator采用的仍是pix2pix中的Patch GANs結構,大小為70×70,Lr=0.000 2。對于前100個周期,保持相同的學習速率0.000 2,然后在接下來的100個周期內(nèi)線性衰減到0。

表1 VGG16與19相關訓練參數(shù)設定
2.4 實驗分析
實例中的風格圖片選為梵高先生的名畫《星夜》,如圖5所示。

圖5 模板藝術圖《星夜》
分別使用Cycle GAN、VGG16、VGG19進行實驗, 通過生成的圖片觀察不同目標函數(shù)的效果,實例中的風格圖片均為梵高先生的名畫《星夜》,實驗運行效果見圖6,圖6的對應數(shù)據(jù)指標見表2。
通過對圖6以及表2 的對比發(fā)現(xiàn),VGG16,VGG19得到的結果相近,相較之下藝術風格并不濃烈,而Cycle GAN給人的直觀感受就好得多,色度適宜,藝術化表現(xiàn)也恰到好處。

圖6 實驗效果
表2 實驗指標
Tab. 2 Experimental index

SSIM/PSNRVGG-19VGG-16Cycle GANImage_10.481 7/17.473 00.449 4/16.868 80.424 6/16.190 5Image_20.431 0/17.329 70.396 1/17.069 80.373 0/16.722 1Image_30.432 2/16.645 30.459 2/17.248 00.428 2/16.390 3
2.5 實驗結果分析
VGG-16與VGG-19本質上并無太大區(qū)別,兩者均繼承了Alex Net的深度思想,以其較深的網(wǎng)絡結構、較小的卷積核和池化采樣域,使其能夠在獲得更多圖像特征的同時控制參數(shù)的個數(shù),避免過多的計算量以及過于復雜的結構,如此一來VGG就能更好地找出內(nèi)在特性,從而提取圖像的style features。
對比之下,由2個鏡像對稱的GAN組成的Cycle GAN不僅不需要成對的數(shù)據(jù)樣本,在損失函數(shù)方面也進一步考慮了防止生成器G與F生成的樣本相互矛盾,保證生成的樣本與真實的樣本同分布,這樣也就保證了生成圖像的連續(xù)性。
總體來說,GAN網(wǎng)絡在這種image-to-image 領域內(nèi)還是存在很大的優(yōu)勢。
3 結束語
本文選用卷積神經(jīng)網(wǎng)絡模型VGG16、VGG19和Cycle GAN作為訓練模型,詳細論述三者的網(wǎng)絡結構,在pytorch框架下實現(xiàn)圖像的風格遷移。對比分析了3種模型的優(yōu)缺點。最后,以梵高的著作《星夜》為風格模板,以峰值信噪比(PSNR)和結構相似度(SSIM)作為評價指標,選取3幅真實的照片做主觀和客觀評價,結果表明Cycle GAN效果最佳。但是在實際中,由于卷積神經(jīng)網(wǎng)絡的不可控性,以及噪聲處理等原因,可能會使得網(wǎng)絡的結果變得不可接受,這也是后續(xù)有待深入研究加以改進的問題。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
小獼猴智力畫刊(2022年9期)2022-11-04 02:31:42
中學生數(shù)理化·中考版(2022年11期)2022-02-16 07:01:20
中學生數(shù)理化·七年級數(shù)學人教版(2020年10期)2020-11-26 08:24:50
數(shù)學物理學報(2020年2期)2020-06-02 11:29:24
小哥白尼(趣味科學)(2019年6期)2019-10-10 01:01:50
光學精密工程(2016年6期)2016-11-07 09:07:19
發(fā)明與創(chuàng)新(2016年38期)2016-08-22 03:02:52
太空探索(2016年5期)2016-07-12 15:17:55
核科學與工程(2015年4期)2015-09-26 11:59:03
