基于CNN和LSTM混合模型的車輛行為檢測方法
2020-04-29 10:55:18王巖松王孝蘭
智能計算機與應用 2020年2期
王 碩, 王巖松, 王孝蘭
(上海工程技術大學 機械與汽車工程學院, 上海 201620)
0 引 言
隨著汽車行業科學技術的發展,智能車輛成為未來汽車行業發展的必然趨勢[1]。自動駕駛作為智能車輛的關鍵技術,引起了研究者的廣泛關注。其中,環境感知技術通過傳感器探測車輛周圍環境,為智能車決策部分提供信息,是自動駕駛技術的重要前提。車輛作為道路環境的主體,其行為姿態的識別對自身車輛周圍環境理解具有重要影響[2]。
車輛行為的分類主要采用隱馬爾科夫模型(Hidden Markov Model,HMM)、貝葉斯網絡、BP神經網絡等方法。文獻[3]采用貝葉斯網絡對每個典型的軌跡建模進行分類。Regine等人[4]將當前場景與數據庫中場景進行對比,選出最相似場景的基于案件推理的在線學習行為預測方法。黃慧玲等人[5]提出一種基于前方車輛行為識別的碰撞預警系統,通過梯度方向直方圖和支持向量機來訓練前方車輛檢測模型,并結合Kalman濾波對車輛進行跟蹤,最后通過 HMM算法建立車輛行為識別模型,完成前方車輛行為的識別。傳統方法多存在檢測和識別精度低的問題,并且傳統方法的使用場景多是環境簡單的道路路口或高速車道等固定場景,無法滿足實際需求。
隨著深度學習技術的發展,循環神經網絡(RNN)[6]被用于處理行為識別問題。但RNN存在梯度消失和梯度爆炸等問題,標準的RNN網絡對長序列的學習效果不佳。Hochreiter等人[7]對RNN進行改進,在1997 年提出長短期記憶網絡(Long Short-Term Memory,LSTM),在長序列的處理上表現更好。Donahue等人[8]提出一種長效遞歸卷積神經網絡(LRCN),初次將CNN與LSTM結合,用于視頻識別、分類等領域。隨后越來越多的研究者采用這種方式對人體行為進行識別,通過CNN模型提取特征,并采用LSTM進行訓練分類[9-10]。文獻[11]通過雙卷積網絡并行對關鍵幀的特征信息提取,利用LSTM網絡建立序列模型,完成車輛行為動態識別,但存在實時性差與不能識別多臺車輛行為的問題。車輛在實際行駛中會遇到陰影、光斑、畸變等因素影響,導致傳統方法的車輛檢測誤檢率高、目標偏差大與定位誤差大的問題,基于深度學習的方法對硬件要求較高,實時性低。同時車輛之間的遮擋也會導致跟蹤丟失目標,使得車輛軌跡難以跟蹤,參數獲取缺乏完整性和準確性,影響最后的行為識別精度。
本文針對上述情況提出一種基于CNN和LSTM混合模型的車輛行為檢測方法,分別選擇基于YOLOv3[12]的車輛識別方法,采用Kalman[13]濾波器跟蹤車輛融合LSTM網絡構建車輛行為識別模型。通過試驗,驗證本文提出方法的有效性和準確性。
1 車輛檢測與跟蹤
1.1 YOLOv3原理
YOLO算法將目標檢測問題作為回歸問題處理,一步完成分類與定位任務,直接預測目標的類別與位置,減少檢測時間的同時提升了目標檢測精度。YOLOv3算法是在YOLO的基礎上進行改進,增加到3種檢測尺度,有效地增加了算法對不同尺寸物體的檢測精度,同時采用多尺度訓練的方式增強了魯棒性,并在DarkNet19基礎上引入殘差網絡提出來新的特征提取網絡DarkNet53。其網絡結構如圖1所示,DarkNet53主要由一系列1×1和3×3的卷積層組成,每個卷積層后跟一個Batch Normalization層和一個LeakyReLU層,進行5次下采樣提取特征,采用FPN的思想,利用多尺度的特征增加特征豐富度,從而達到對不同尺寸目標的精確檢測。

圖1 YOLOv3網絡結構
在目標檢測階段,YOLOv3首先將圖片縮放到416×416的大小,并劃分為S×S的等大單元格。當待檢測目標中心落入單元格內,該單元格預測目標B個候選框的位置信息以及目標類別的條件概率,即中心坐標(x,y)和目標的寬w和高h,記為tx,ty,tw,th。目標中心所在單元格相對圖像左上角有偏移(cx,cy),pw和ph代表該單元格對應候選框的寬高,計算出候選框的坐標如下:
bx=σ(tx)+cx,
(1)
by=σ(ty)+cy,
(2)
bw=pwetw,
(3)
bh=pheth.
(4)
當多個候選框檢測到相同目標時,通過對置信度設定閾值篩選出高分的候選框,并利用非極大值抑制處理得到最終的預測結果。
1.2 車輛檢測與跟蹤模型
復雜環境下的車輛檢測會受到遮擋影響,導致跟蹤丟失目標,使得車輛軌跡難以跟蹤,參數獲取缺乏完整性和準確性,影響最后的行為識別精度。針對上述情況,利用Kalman濾波器對檢測到的車輛目標大小(w,h)、位置(x,y)等確切信息進行跟蹤預測。
Kalman 濾波具體的原理和過程分析如下:
(5)
Pk|k-1=APk-1|k-1AT+Q,
(6)
Kk=Pk|k-1HT(R+HPk|k-1HT),
(7)
(8)
Pk|k=Pk|k-1-KkHPk|k-1.
(9)
其中,A、B表示系統參數;H表示觀測系統參數;Q、R分別為系統噪聲和觀測系統噪聲的方差。
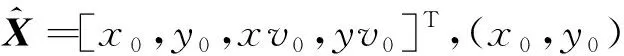

圖2 前方車輛運動軌跡
2 前方車輛行為識別
2.1 LSTM網絡
循環神經網絡具有強烈的時間序列性,其當前時刻的輸出由之前時刻的狀態和當前時刻的輸入決定,保留了時間維度上的信息。LSTM是循環神經網絡的一種,為了解決一般循環神經網絡梯度消失只能對短時間序列建模的問題,LSTM引入輸入門、遺忘門、輸出門三個部分更新系統狀態,可以有效處理時間序列中間隔和延遲較長的信息。其網絡結構如圖3所示。

圖3 LSTM原理圖
LSTM通過輸入門it、遺忘門ft、輸出門ot丟棄時間序列中的無用的信息并傳遞后續時刻所需信息。其中,it和ot控制信息的流入和流出,ft代表遺忘門的輸出,具體公式為:
ft=sigmoid(Wf·[ht-1,xt]+bf),
(10)
it=sigmoid(Wi·[ht-1,xt]+bi),
(11)
(12)
(13)
ot=sigmoid(Wo·[ht-1,xt]+bo),
(14)
ht=ot*tanh(Ct).
(15)
其中,xt,ht表示當前時刻單元的輸入和輸出;Ct表示更新后的單元;Wi,Wf,Wc,Wo與bi,bf,bc,bo分別表示加權項與偏置項。
2.2 車輛行為識別模型
利用YOLOv3目標檢測算法與Kalman濾波對前方車輛視頻中的車輛目標進行實時檢測與跟蹤,結合LSTM網絡構建前方車輛行為識別模型。
本文網絡結構模型如圖4所示。首先,對輸入的視頻利用訓練的YOLOv3車輛檢測模型逐幀檢測,提取前方車輛目標,得到目標類別、檢測框尺寸和目標中心點坐標;其次,結合kalman濾波對前方車輛視頻中的車輛目標進行實時檢測與跟蹤,獲取目標大小、位置、軌跡等信息,獲取準確的車輛運動軌跡特征;再次,將車輛運動軌跡特征輸入到 LSTM 網絡框架中,建立時間序列模型,分析序列間特征,最終識別前方車輛的行為。

圖4 前方車輛行為識別模型
3 實驗結果
3.1 實驗平臺與數據集
實驗平臺配置:Windows 10操作系統,CPU為Inter Core i5-8400,內存為16 GB,GPU為NVIDIA GeForce GTX1070Ti,深度學習框架為Tensorflow。
本文采用自行搭建的車載試驗平臺所采集的視頻數據集,數據采集設備固定于車輛前擋風玻璃正前方,在自身車輛不變道的情況下,采集前方車輛的行駛行為。數據集包含城區、高速、鄉村和學校等場景采集的真實視頻數據,每段視頻中包含車輛、行人和電動車等各種目標,還包括光照變化、樹木陰影和目標被各種程度的遮擋與截斷等情況。根據實際應用場景,車輛視頻數據分為7類別,分別為直行、左轉、右轉、左變道、右變道、左切入和右切入。車輛行為數據集如圖5所示,本文選取300個視頻作為實驗數據,其中80%作為訓練集,20%作為驗證集。
3.2 實驗結果
經過訓練得到前車行為識別網絡模型,其實驗結果見如下。
圖6為車輛行為識別結果。圖6(a)中靠近本車的車輛在接下來的5 s向右側變道,遠方車輛保持直行,采用本文方法識別出2臺目標車輛,并進行軌跡跟蹤。識別結果顯示,正確地識別出了不同車輛的右變道與直行行為。圖6(b)識別出3臺目標車輛并進行跟蹤,采用本文方法正確識別出3輛車的直行行為。

圖5 車輛行為數據集

(a)場景一

(b) 場景二
表1為前車直行、左轉、右轉、左變道、右變道、左切入和右切入行為識別結果統計表。由表1分析可得, 直行行為的識別正確率較高,而右轉和右變道行為識別的正確率略低,主要原因是車輛變道與轉向操作前期軌跡特征相似,易誤檢為前車左轉和右轉行為,對于左切入和右切入兩種行為,本文方法可以做到有效識別。

表1 車輛行為識別結果
4 結束語
本文提出一種基于CNN和LSTM混合模型的車輛行為檢測方法,首先訓練YOLOv3網絡模型進行前方車輛識別,然后使用Kalman濾波跟蹤檢測車輛;最后訓練LSTM網絡模型對車輛行為進行建模,完成前方車輛行為識別。實驗結果表明,根據前方車輛運動軌跡可在復雜環境下識別多車行為。但是,本文的研究存在自身車輛保持直行的局限性,下一步的重點應放在自身車輛行為變化的情況下識別前方車輛行為上。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
光學精密工程(2016年6期)2016-11-07 09:07:19
海峽科技與產業(2016年3期)2016-05-17 04:32:12
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
