融合深度學習與搜索的實時策略游戲微操方法
2020-06-18 03:41:20王子磊
計算機工程 2020年6期
陳 鵬,王子磊
(中國科學技術大學 自動化系,合肥 230027)
0 概述
機器博弈[1]又稱為計算機博弈,主要研究如何使計算機模擬人類進行游戲對抗,是人工智能領域最具挑戰性的研究方向之一。繼以圍棋[2-4]、五子棋[5]、亞馬遜棋[6]、兵棋[7]等棋類游戲為代表的序貫博弈問題得以解決后,以實時策略(Real-Time Strategy,RTS)游戲[8]為代表的同步博弈問題成為機器博弈領域的研究熱點,如星際爭霸(StarCarft)[9-11]、Dota 2、王者榮耀[12]等。通常,RTS游戲職業玩家或RTS AI 程序(Bot)的操作可劃分為宏觀操作和微觀操作兩部分[8],分別稱為宏操、微操。宏操側重于對整個戰局的調控,用于保證玩家占有經濟和科技優勢;微操側重于遭遇戰中作戰單元的控制,用于保證玩家占有軍事優勢。可見,RTS游戲微操是RTS游戲AI研究的基礎問題,也是RTS AI Bot的核心模塊。
相較于棋類游戲中參與者輪流行動,RTS游戲微操要求參與者同時采取行動,實時性更強,且雙方作戰單元數目不定,導致動作空間規模隨作戰單元數量的增加而呈指數級增長。目前,常見的解決思路分為搜索方法和強化學習方法兩種,兩者相互獨立。但在面對大規模戰斗場景時,搜索方法存在搜索速率下降和搜索空間有限的問題,難以保證求解的最優性,而強化學習[13-15]方法存在學習困難的問題,且訓練好的強化學習模型往往局限于固定的戰斗場景。因此,現有方法難以解決大規模戰斗場景下的RTS游戲微操問題。
采用深度學習與搜索相結合的思路,可以實現學習模型對搜索方法的合理指導,使得在實時性約束下,盡可能地搜索大概率存在最優解的動作空間,如AlphaGo[3]、AlphaGoZero[4]在圍棋上取得的巨大成功,為解決RTS微操問題提供可能。考慮到采用強化學習方式,難以訓練適用于多變戰斗場景的學習模型,參考AlphaGo[3]的思路,采用監督學習方式訓練深度學習模型。基于此,本文提出融合深度學習與搜索的RTS游戲微操方法。根據作戰狀態表達方法,將游戲狀態映射為多通道特征圖,給出一種基于卷積神經網絡的聯合策略網絡(Joint Policy Network,JPN),不同于大多數模型僅能學習游戲狀態至個體動作映射的策略模型,JPN可以實現多智能體聯合動作的端到端學習,并將JPN與組合貪婪搜索(PGS)[16]、組合在線演化(POE)[17]、自適應分層策略選擇(SSS+)[18]相結合,提出了3種改進方法,分別為PGS w/JPN、POE w/JPN、SSS+w/JPN。
1 相關工作
現有的RTS游戲微操方法分為搜索方法和強化學習方法兩類,搜索方法是在有限時間內進行在線搜索,由搜索到的局部最優解決定最終行動;強化學習是通過環境交互完成模型學習,使用時由模型決定最終行動。
搜索方法應用于RTS游戲微操始于Churchill等人提出的ABCD[19]和UCTCD[16],這兩種算法由廣泛應用于棋類游戲的Alpha-Beta搜索和UCT算法演變而來。后來的研究工作主要圍繞如何在搜索方法中引入精煉機制,包括動作精煉和狀態精煉兩類,即通過減小動作空間或狀態空間的規模來加快搜索效率。動作精煉一般將原始動作替換為固定規則(Script)動作,如組合貪婪搜索(PGS)[16]、基于Script的UCT[20]、組合在線演化(POE)[17]等;狀態精煉則是合并相似狀態的作戰單元,如基于空間聚類的UCT[20]、基于類型系統的分層策略選擇(SSS)[18]、自適應分層策略選擇(SSS+)[18]等。然而,動作空間規模隨作戰單元數量的增加而呈指數級增長,當作戰單元數量較多時,實時性約束(一般為42 ms)下的精煉機制也只能搜索有限的動作空間,所求解的最優性仍不足。
強化學習[13-15]方法通常將RTS游戲微操問題建模為多智能體馬爾科夫決策過程,其目標是讓多智能體學會合作式行動。主流方法是將多智能體強化學習與深度學習相結合,研究方向包括學習架構、學習策略及多智能體溝通機制。學習架構涉及多智能體強化學習框架的設計,主要圍繞傳統強化學習中的行動家-評判家框架,如相互獨立的行動家-評判家[21-23]框架、分布式行動家-集中式評論家[24]框架等。學習策略主要用于提升強化學習的學習效率,如文獻[22]采用課程學習逐步將強化學習模型由簡單場景遷移至復雜場景,文獻[23]利用職業玩家先驗知識預訓練強化學習模型。多智能體溝通機制涉及多智能體信息傳遞的顯性建模,如文獻[25]由單個溝通網絡實現多智能體間信息傳遞、文獻[26]采用雙向遞歸神經網絡實現各個智能體的信息傳遞。強化學習模型的訓練難度正比于狀態空間、動作空間規模,導致現有方法難以應對大規模場景。另外,現有強化學習方法往往局限于單一場景,雙方作戰單元的種類、數目固定,難以應對多變的復雜場景。
綜上,搜索方法和強化學習方法相互獨立,均難以解決大規模戰斗場景下的RTS游戲微操問題。本文方法融合了搜索方法、學習方法的優勢,有利于拓展RTS游戲微操的研究思路。
2 問題描述
RTS游戲微操問題涉及作戰環境、敵我雙方控制的作戰單元,參與者要求控制各自的作戰單元進行實時對抗,直至一方所有作戰單元消滅殆盡,屬于零和同步博弈問題。本文關注二人零和的RTS游戲微操問題,假設參與者為P={i,-j},己方i控制m(m≥1)個作戰單元,敵方-j控制n(n≥1)個作戰單元,分別對應作戰單元集合Ui=(u1,u2,…,um)、U-j=(u-1,u-2,…,u-n)。由此,RTS游戲微操問題可以被建模為包含m+n個智能體的馬爾科夫決策過程,該問題可以表示為一個四元組G={S,A,Γ,R},S表示所有作戰單元U=Ui∪U-j可能經歷的狀態,A表示作戰單元的所有可行動作。在任意狀態s∈S下,待命單元選取各自動作α∈A構成聯合動作{{αi}i=1,2,…,m,{α-j}j=1,2,…,n},依據狀態轉移函數Γ:S×Am+n×S→[0,1]可以實現作戰場景的狀態轉移,并依據獎勵函數R:S×Am+n→[0,1]獲得即時回報。本文采用監督學習方式訓練策略模型,在此忽略獎勵函數的定義及使用。
固定規則常被用于輸出智能體的個體行動,可將其定義為σ:S×U→A,在任意狀態s∈S下,依據固定規則輸出單元u∈U的動作決策α∈A。通常以UCTCD為代表的樹搜索方法事先建立博弈樹,搜索樹根節點(Root)至葉子節點的最佳路徑對應局部最優解。博弈樹中各個節點對應S中各個可能狀態,若狀態si與狀態sj間存在邊,則兩狀態間存在狀態轉移。不同于樹搜索方法,PGS、POE、SSS+不要求建立博弈樹,基本思想是在初始解的基礎上,采用不同的迭代策略使得初始解朝最優解方向演變。搜索方法結合固定規則σ和靜態評估函數ψ來評估出現狀態s∈S的價值,前者用于模擬狀態轉移,后者用于評估終局局勢,典型的LTD2函數如式(1)所示:
(1)
其中,hp(ui)、dpf(ui)表示單元ui∈Ui的當前生命、單幀可造成的傷害。
假定φ(s,ui)表示從單元ui∈Ui視角出發,狀態s∈S對應特征圖,則多智能體強化學習方法依據π:φ(s,ui)→αi生成單元ui∈Ui的動作決策。假定φ(s,Ui)表示從己方所有單元視角出發,狀態s∈S對應特征圖,本文提出方法的決策過程如下:1)JPN依據π:φ(s,Ui)→ρ(s,Ui)生成己方所有單元的動作概率分布;2)由生成的概率分布指導搜索方法,依據T:〈s,φ(s,Ui)〉→{αi}i=1,2,…,m輸出己方所有單元的最終行動。
3 RTS游戲微操方法
本節描述融合深度學習與搜索的RTS游戲微操方法,給出整體解決方案描述各部分的邏輯關系,介紹策略模型,包括狀態表達、動作表達、JPN等,并對PGS w/JPN、POE w/JPN、SSS+ w/JPN 3種改進方法進行說明。
3.1 整體方案
梳理傷害機制密切相關的單元屬性,完成作戰狀態表達,利用特征圖表達原始狀態;采用動作精煉的思路,完成作戰單元的動作表達,運用Script動作表達原始動作。RTS游戲微操的整體方案如圖1所示。對于當前游戲狀態s∈S,經狀態表達生成特征圖φ(s,Ui),輸入至JPN,生成動作的概率分布;搜索方法在此先驗概率分布指導下,循環執行搜索過程直至有限決策時間到達;最后將Script動作轉換為實際動作,輸出至RTS游戲實驗平臺,作為最終決策。
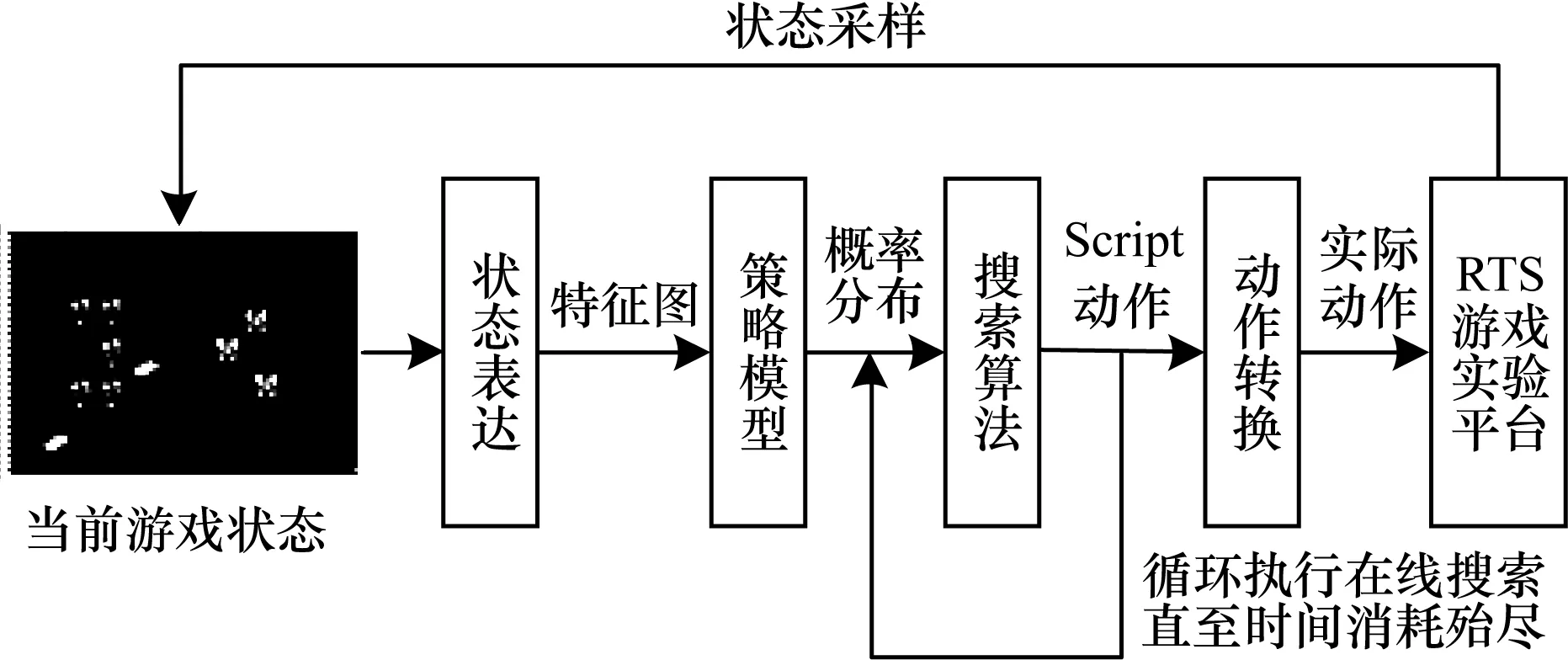
圖1 融合深度學習與搜索的RTS游戲微操方法
3.2 狀態表達
狀態表達是將原始游戲狀態轉換為多通道特征圖。鑒于RTS游戲涉及單元種類繁多,本文參考之前搜索方法和多智能體強化學習方法的設置,選取StarCarft中4種采用物理攻擊的作戰單元,分別是Zergling、Zealot、Dragoon、Marine。在狀態特征設計上,主要考慮與空間分布、傷害機制密切相關的單元屬性,具體如表1所示,己方、敵方各對應一半。其中,不同單元之間可造成的傷害由單元類型、攻擊類型、體型共同決定,單元生命按基數、比率、序數劃分為3種特征,基數、序數分別對應當前生命、生命排行,比率表示當前生命與最大生命的比值。
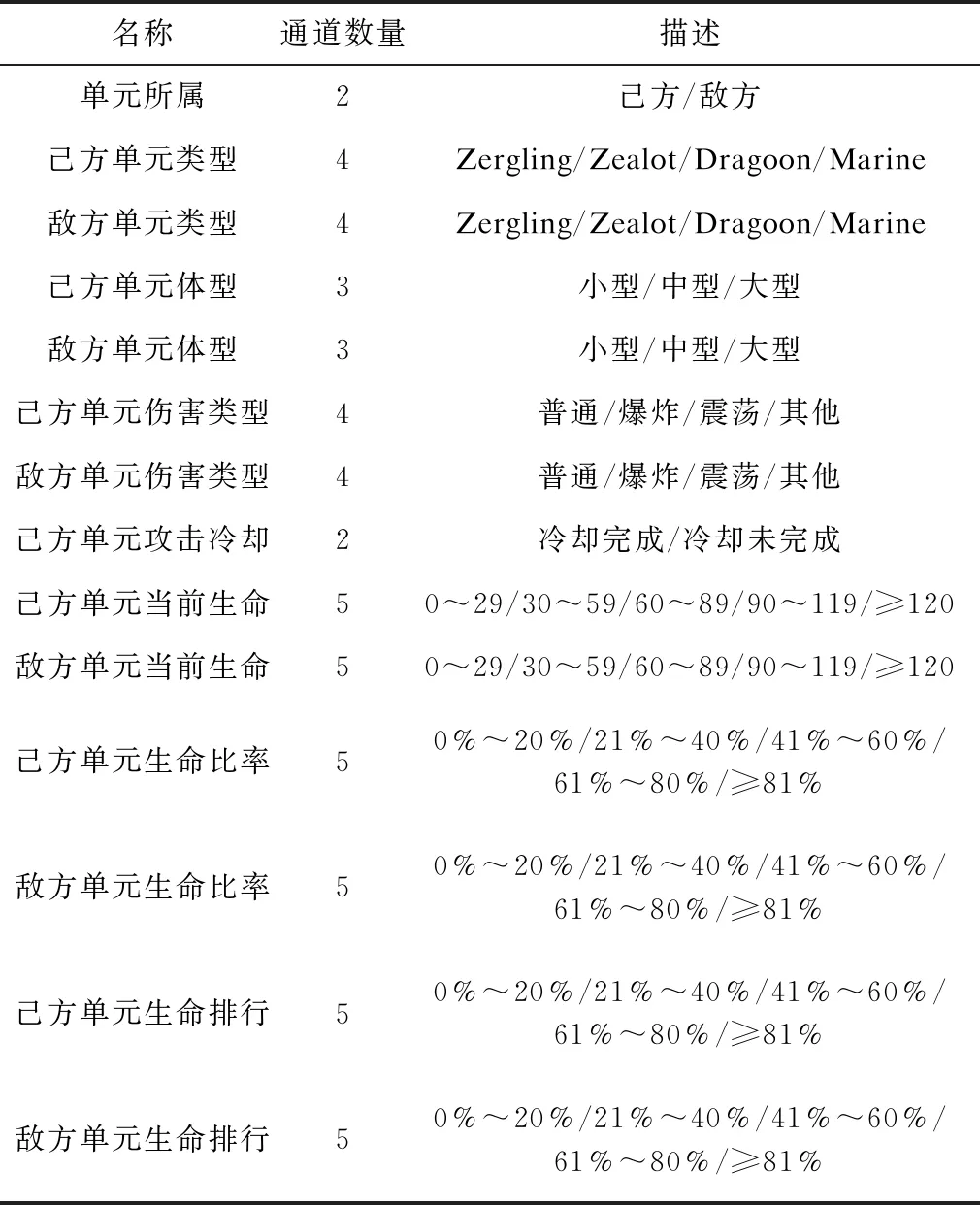
表1 特征描述
特征編碼采取one-hot編碼方式,每一種連續或離散特征對應多通道的0/1特征圖,共編碼為56通道特征圖。如圖2所示,單元所屬被編碼為2通道特征圖,分別對應己方所屬、敵方所屬。考慮到實際游戲狀態的稀疏性,作戰單元僅占據很小的空間,特征編碼在變化的作戰場景尺度上進行。具體地,若作戰場景尺度為H×W,則特征圖尺度為λH×λW,λ≤1為縮放系數,單元在作戰場景中的真實坐標可以映射為特征圖的像素坐標。
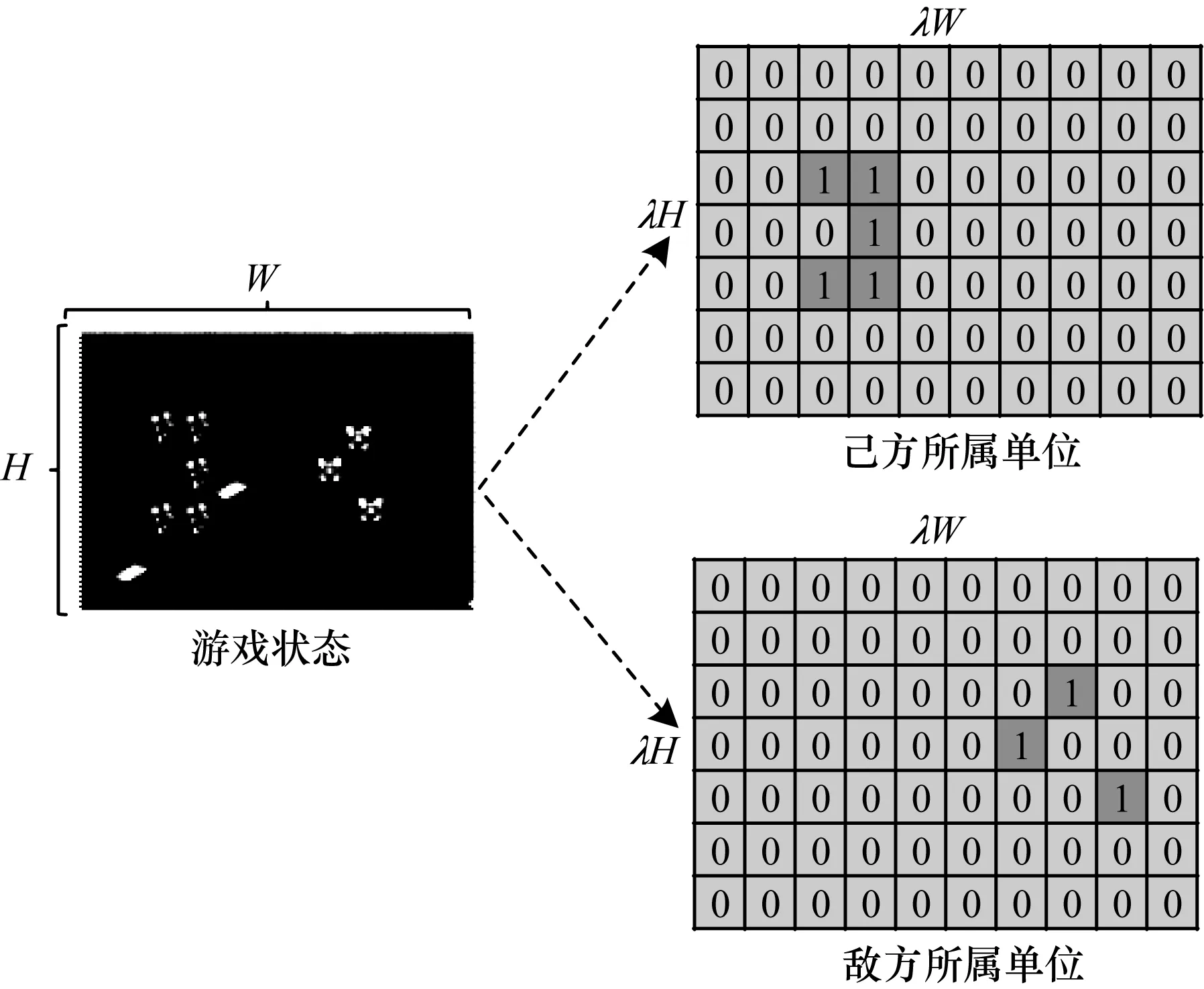
圖2 單元所屬特征編碼示意圖
3.3 動作表達
與狀態表達類似,動作表達是編碼作戰單元的移動動作、攻擊動作。本文采用PGS[16]、POE[17]、SSS+[18]為基準搜索方法,因此使用這3種算法的Script作為單位動作,分別為NOK-AV、Kiter、BackFar、BackClose、Forward、ForwardFar及Cluster共計7種。通常,Script動作可分為攻擊前移動、攻擊時目標選擇和攻擊間隙移動3個階段,前6種Script動作在攻擊前朝最近的敵方單元移動,攻擊時優先選擇dpf/hp最高的敵方單元,但它們在攻擊間隙的移動動作有所不同[16-17],如NOK-AV在攻擊間隙原地等待、Kiter在攻擊間隙朝遠離最近敵方單元的方向移動等。Cluster僅涉及移動動作,表示朝友方單元的中心移動[18]。與特征編碼一致,動作編碼采用one-hot編碼方式生成7通道的0/1動作圖,其動作圖尺度為λH×λW,單元在作戰場景中的真實坐標可以映射為動作圖中的像素坐標。
3.4 基于卷積神經網絡的聯合策略模型
策略模型的目標是在給定56通道特征圖下,計算己方所有單元的動作概率分布,本節將描述具體的網絡結構、損失函數。
3.4.1 網絡結構
考慮到編碼-解碼卷積架構在圖像分割[27]領域的成功,本文提出面向RTS游戲微操的聯合策略網絡。JPN的結構設計參考SegNet,如圖3所示,主要不同點是移除了大量卷積層,以保證前向運算的速度。具體地,JPN的編碼部分包含5層卷積層、4層最大池化層,解碼部分包含5層卷積層、4層上采樣層,最后一層接Softmax層。其中,10層卷積層的卷積核大小都為3×3,第1層、第10層卷積層的卷積核數量為64,第2層、第9層卷積層的卷積核數量為128,第3層、第8層卷積層的卷積核數量為256,其余卷積層的卷積核數量都為512;4層最大池化層與4層上采樣層一一對應,采樣步長都為2,兩部分分別實現輸入特征圖的16倍尺度縮小、放大,使得輸入、輸出的尺度均為λH×λW。
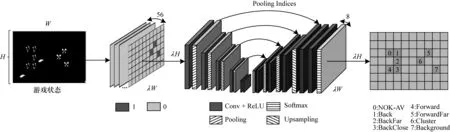
圖3 聯合策略網絡示意圖
3.4.2 損失函數
采用交叉熵損失函數作為JPN的目標函數,考慮到不同類別動作之間的不均衡性,構建一種加權交叉熵損失函數:
(2)
(3)
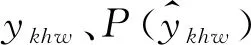
3.5 改進搜索方法
本節將JPN與3種典型的搜索方法(PGS[16]、POE[17]、SSS+[18])相結合,提出3種改進方法,即PGS w/JPN、POE w/JPN、SSS+ w/JPN。3種改進方法的思路類似。具體地,由JPN輸出己方單元在7種Script動作上的概率分布;將最大概率Script動作設定為初始解;由先驗概率分布指導初始解的優化過程,若采用狀態精煉來合并相似狀態的作戰單元,則面向群體展開搜索過程,群體內單元共享相同的Script動作,否則面向個體展開搜索過程,直至決策時間消耗殆盡;輸出有限時間內搜索到的局部最優解。
3.5.1 PGS w/JPN方法
PGS w/JPN的算法流程如算法1所示,主要分為設定初始解(第2行、第3行)、產生可能動作子集(第4行)、迭代優化(第5行~第12行)3個部分。
算法1PGS w/JPN方法
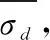
輸出己方單元聯合動作Ai={α1,α2,…,αm}
1.計算先驗概率分布ρπ(s,Ui)=π(φ(s,Ui);θ)
2.設定己方初始解{σ1,σ2,…,σm}←Max(ρπ(s,Ui))
5.While 消耗時間小于t do
6.for i=1→m do
7.for j=1→M1do
8.己方當前解Σ={σ1,σ2,…,σm}
9.對方當前解Σ-1={σ-1,σ-2,…,σ-n}
11.if ζ(S,Σ,Σ-1)<ζ(S,Σ′,Σ-1) then
13.計算并返回己方單元聯合動作Ai←{σ1,σ2,…,σm}
將最大概率Script動作設定為己方初始解(第2行),將默認Script動作設定為對方初始解(第3行),而原始的PGS采用迭代方式確定雙方初始解。由先驗概率分布產生可能動作子集(第4行),在給定先驗概率分布下,采取排序方式,按從大到小的原則確定不同Script動作對于各個單元的優先級,若可能動作子集大小設定為M1,則按優先級從大到小選取前M1個Script動作構成各個單元的可能動作子集。在給定可能動作子集下,逐個優化己方單元的當前解(第10行),類似PGS,采用動態評估方法ζ來評價解的好壞,先由當前解模擬狀態轉移,再由靜態評估函數評估終局局勢,選取評分最高的Script動作(第11行、第12行)。待決策時間消耗殆盡,將局部最優解轉換為具體的動作指令(第13行)。
3.5.2 POE w/JPN方法
POE w/JPN的算法流程如算法2所示,類似演化算法,主要分為初始化基因組(第2行~第5行)、產生可能動作子集(第6行、第7行)、突變(第9行~第12行)、交叉(第13行)和選擇(第14行)5個部分。這里的改進主要集中在前3個部分,后兩部分與POE完全一致,交叉對所有基因進行隨機兩兩交換,選擇篩選優良基因。
算法2POE w/JPN方法
輸出己方單元聯合動作Ai={α1,α2,…,αm}
1.計算先驗概率分布ρπ(s,Ui)=π(φ(s,Ui);θ)
2.for i=1→size do
3.for j=1→step do
4.設定己方初始基因Σij←Max(ρπ(s,Ui))
8.While 消耗時間小于t do
9.for i=1→size do//執行突變步驟
10.for j=1→step do
12.Σij←Random(Σij,offsprings,ε′)
13.執行交叉步驟Σ←Cross(Σ,select)
14.執行選擇步驟Σ←Select(Σ,select,ψ)
15.計算并返回己方單元聯合動作Ai←Σ11
在初始化基因組階段,由最大概率Script動作設定為己方初始基因(第4行),將默認Script動作設定為對方初始基因(第5行),而原始的POE完全采取默認初始解,其中基因對應己方單位或對方單位的Script動作組合。在產生可能動作子集階段,類似PGS w/JPN,若可能動作子集大小設定為M2,按照優先級排序方式選取前M2個Script動作構成各個單元的可能動作子集(第6行),并計算這M2個Script動作的歸一化概率分布,其他Script動作的概率取0(第7行)。在突變階段,在可能動作子集內執行基因變異操作,朝向各個Script動作的變異率由默認變異率和歸一化概率分布共同決定(第11行),這意味著同一個基因朝不同動作的變異率可能不同。
3.5.3 SSS+ w/JPN方法
SSS+ w/JPN的算法流程如算法3所示,主要分為設定初始解(第2行、第3行)、劃分群體(第4行)、產生可能動作子集(第5行)和迭代優化(第6行~第13行)4個部分。
算法3SSS+ w/JPN方法
輸出己方單元聯合動作Ai={α1,α2,…,αm}
1.計算先驗概率分布ρπ(s,Ui)=π(φ(s,Ui);θ)
2.設定己方初始解{σ1,σ2,…,σm}←Max(ρπ(s,Ui))
4.己方單元劃分群體{g1,g2,…,gk}←types(Ui)
6.While 消耗時間小于t do
7.for i=1→k do
8.for j=1→M3do
9.己方當前解Σ={σ1,σ2,…,σm}
10.對方當前解Σ-1={σ-1,σ-2,…,σ-n}
12.if ζ(S,Σ,Σ-1)<ζ(S,Σ′,Σ-1) then
14.計算并返回己方單元聯合動作Ai←{σ1,σ2,…,σm}
首先將最大概率Script動作設定為己方初始解(第2行),將默認Script動作設定為對方初始解(第3行),而原始的SSS+完全采取默認初始解。然后由當前類型系統歸并相似狀態的單元,所采用的自適應類型系統types與SSS+一致,包含5種類型系統,分別是{T(c,3),T(c,2),T(c,1),T(c,0),TRGD},前4種類型系統計算公式如下:
(4)
其中,r(u)與d(u)分別表示單位u的攻擊距離和傷害,hp(u)與hpm(u)分別表示單位u的當前生命與最大生命,若兩單位的Tc,l(u)三要素完全一致,則劃分至一類,否則劃分至各自類別;而TRGD將單元分為近戰單元、遠戰單元兩類。另外,自適應類型系統types依據運行情況自動調整所使用的類型系統,若給定時間內可以遍歷所有可能解,則增大所使用類型系統的精細程度,如Tc,2(u)調整至Tc,3(u);否則,降低所使用類型系統的精細程度,如Tc,3(u)調整至Tc,2(u)。接著由先驗概率分布產生可能動作子集(第5行),采取排序、投票相結合的方式,先排序確定不同動作對于各個單元的優先級,再在各個群體內執行投票,統計不同動作對于各個群體的優先級,若可能動作子集大小設定為M3,則按優先級從大到小選取前M3個Script動作構成各個群體的可能動作子集,群體內單元共享相同的可能動作子集。最后在給定可能動作子集下,逐個優化己方群體的當前解(第11行),類似PGS w/JPN,采用動態評估方法ζ來評價解的好壞,選取評分最高的Script動作(第12行、第13行)。待決策時間消耗殆盡,將局部最優解轉換為具體的動作指令(第14行)。
4 實驗評估
為評估JPN和改進方法(PGS w/JPN、POE w/JPN、SSS+ w/JPN)的性能,本節一方面在SparCraft上展開原始方法(PGS[16]、POE[17]、SSS+[18])和改進方法的對比實驗,測試改進方法的性能提升,另一方面在StarCraft:BroodWar上展開內置AI和改進方法的對比實驗,測試改進方法的AI真實水平。兩個實驗平臺的作戰場景類似,單元類型、單元屬性也基本一致。其中,SparCraft顯性建模了RTS游戲微操涉及的狀態轉移,為搜索方法提供了極大的便捷; StarCraft:BroodWar提供了更加真實的作戰場景,更有利于鑒定改進方法的AI水準。考慮到目前尚無可用于訓練JPN的數據集,首先構建覆蓋基準場景的學習用數據集;然后將訓練完成的模型接入改進方法,在2個實驗平臺上分別開展驗證實驗。
4.1 場景設置
借鑒PGS[16]、POE[17]、SSS+[18]的場景設置,選取4種采取物理攻擊的作戰單元,分別是Zergling(L)、Zealot(Z)、Dragoon(D)和Marine(M),在多種作戰基準場景中開展驗證實驗,統計1 000場戰斗中改進方法對抗原始方法或內置AI的勝率。具體地,為評估改進方法的性能提升,選取了5類基準場景,各方控制單元的數量n選取自{4,8,16,32,50},分別為nD vs.nD、nL vs.nL、n/2Dn/2Z vs.n/2Dn/2Z、n/2Dn/2M vs.n/2Dn/2M、n/2Mn/2L vs.n/2Mn/2L,共計25種基準場景。為評估改進方法的AI真實水平,選取了BiCNet[22]中的2種大尺度場景:即10 M vs.13 L、 20M vs.30L,并設計了8種變種場景:分別為6M vs.7L、8M vs.10L、12M vs.16L、14M vs.20L、16M vs.24L、18M vs.27L、22M vs.33L、24M vs.36L。由此,共采用了35種作戰基準場景。
4.2 基準算法設置
采用PGS[16]、POE[17]、SSS+[18]作為基準搜索方法,采用GMEZO[21]、CommNet[25]、BiCNet[22]以及PS-MAGDS[26]作為基準多智能體強化學習方法。為評估改進方法的性能提升,實驗對比了原始方法(PGS[16]、POE[17]、SSS+[18])、改進方法(PGS w/JPN、POE w/JPN、SSS+ w/JPN),以及結合隨機先驗概率分布的搜索方法(PGS w/RND、POE w/RND、SSS+ w/RND)。出于公平性,借鑒SSS+[18]中可能動作集合的大小,三類搜索方法可能動作集合的大小均設置為3,原始搜索方法默認為NOK-AV、Kiter、Cluster,其他搜索方法依據各自的先驗概率分布,從7種Script動作中構建各自的可能動作集合。除此以外,所有搜索方法的參數一致,如決策時間限制為40 ms。
4.3 數據集構建
SSS+是所有開源搜索方法中的最佳方法,因此將其分別接入SparCraft和StarCraft:BroodWar,生成所設定基準場景的數據集。對于前25種基準場景,為增強樣本的質量和多樣性,采取了4點特殊設置:1)將SSS+的可能動作集合設定為7種Script動作;2)將決策時間限制由40 ms延長至200 ms;3)各方控制單元的數量n分別隨機選取自[1,4]、[5,8]、[9,16]、[17,32]、[33,50],每個基準場景進行100 000場戰斗,共進行了2 500 000場戰斗;4)合并相同規模場景中產生的數據集,生成用于4v4、8v8、16v16、32v32、50v50五類場景的數據集。對于場景10 M vs.13 L、 20M vs.30L,鑒于StarCraft:BroodWar產生樣本的速度遠遠低于SparCraft,這里僅將可能動作集合設定為7種Script動作,未采用其他3點特殊設置,共進行了200 000場戰斗。在上述設定下,按50幀時間間隔來隨機記錄中間狀態,經狀態表達、動作表達、數據打亂,進一步地按4:1劃分訓練集、測試集,生成的7組數據集分別稱為I4v4、I8v8、I16v16、I32v32、I50v50、I10Mv13L、I20Mv30L,具體如表2所示。
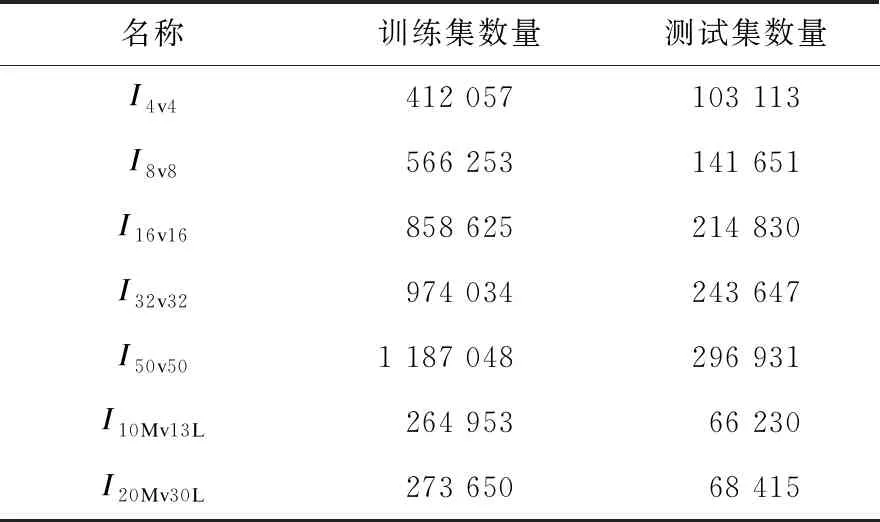
表2 數據集統計情況
4.4 結果分析
首先在7個數據集上訓練并測試JPN,然后將訓練完成的學習模型接入各個搜索方法,分別在2個實驗平臺上展開性能評估實驗。
4.4.1 策略模型的預測性能評估
訓練完成的JPN在7個測試集上的Top-1預測準確率如圖4所示,此處類別總數為8(7類Script動作和1類背景)。由圖4可知,前5個測試集上的最大準確率、最小準確率、平均準確率約為73.10%、69.66%、73.10%,后2個測試集上的最大準確率、最小準確率、平均準確率約為57.30%、56.80%、57.05%。可見,JPN可以適應復雜的作戰場景,甚至是單元數量達到100的大規模作戰場景。JPN在前5個測試集上的表現優于其在2個測試集上的表現,這主要是由于前5組數據集在構建過程中所采用的特殊設置。
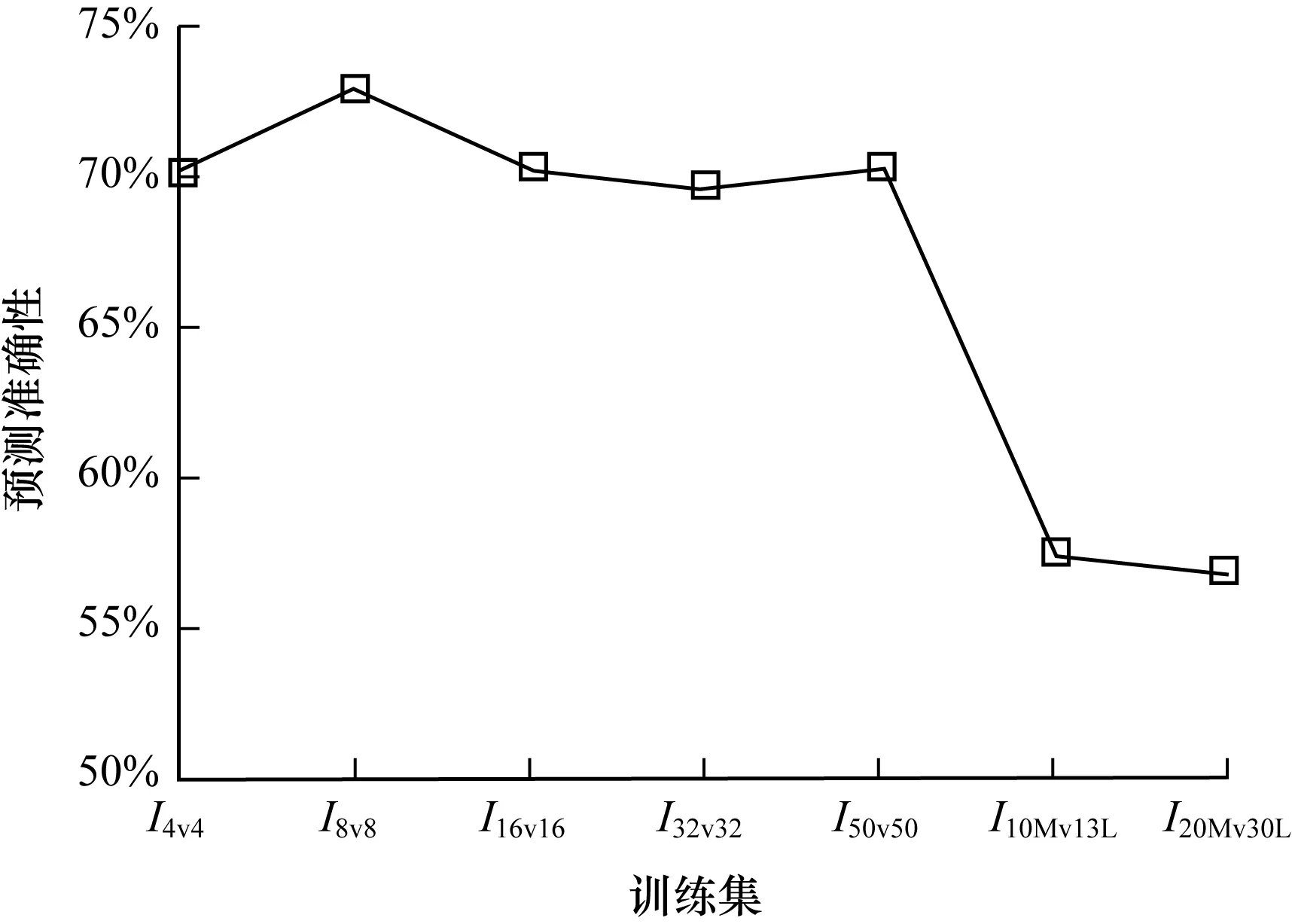
圖4 JPN在7個測試集上的預測準確率
4.4.2 原始搜索方法與改進搜索方法的對比分析
改進方法(PGS w/JPN、POE w/JPN、SSS+w/JPN)、結合隨機先驗概率分布的搜索方法(PGS w/RND、POE w/RND、SSS+ w/RND)對抗原始方法(PGS、POE、SSS+)的實驗結果如表3所示,其中,第1列指定了場景設置,第1行指定了測試的搜索方法。例如在場景4D4Z vs.4D4Z中,PGS w/RND vs.PGS的勝率是47%,PGS w/JPN vs.PGS的勝率是79%,對應地,兩種搜索方法的增益分別是-3%和+29%。
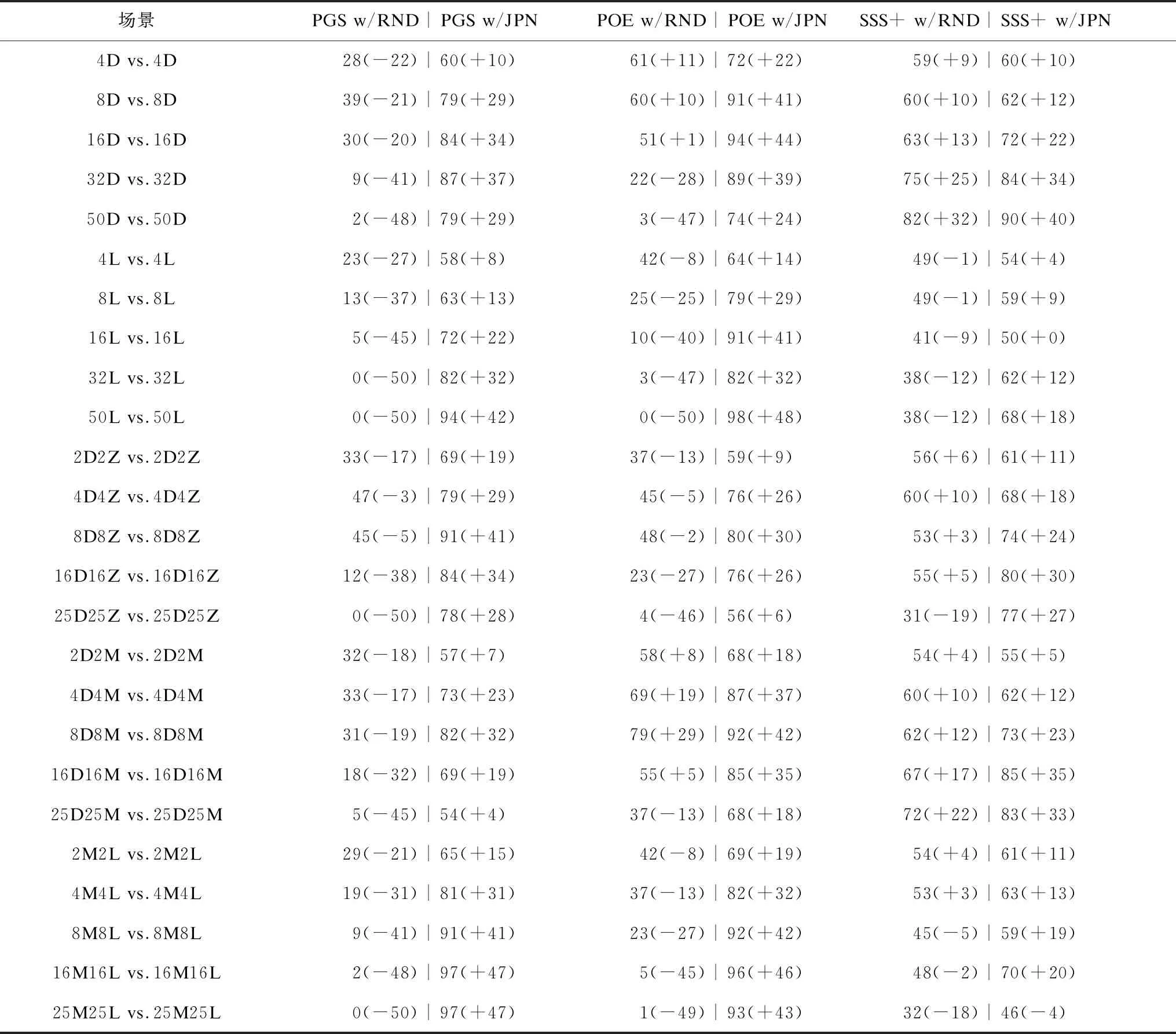
表3 原始搜索方法、改進搜索方法的對比實驗結果
由表3可得出以下實驗結論:1)在絕大多數場景中,相比于改進方法,結合隨機先驗概率分布的搜索方法取得較低的勝率,這表示合適的先驗概率分布對于引導搜索方法至關重要;2)SSS+ w/RND總是存在增益,POE w/RND在一半場景中有增益,而PGS w/RND在所有場景中無增益,這表示隨機先驗概率分布帶來的多樣性對于PGS、POE、SSS+影響程度不等,SSS+受益最大;3)在絕大多數場景中,改進搜索方法對抗原始搜索方法的勝率大于50%,其增益也總是大于結合隨機先驗概率分布的搜索方法,這證實了JPN可以有效提升搜索方法;4)PGS w/JPN、POE w/JPN的增益往往大于SSS+ w/JPN的增益,相比于SSS+,JPN更有利于提升PGS、POE,這主要由于采用了SSS+產生的訓練集,SSS+的性能優于PGS、POE,導致訓練產生的學習模型更有利于提升PGS、POE。
4.4.3 內置AI與改進搜索方法的對比分析
改進方法(PGS w/JPN、POE w/JPN、SSS+w/JPN)對抗內置AI的實驗結果如表4和表5所示,其中,表4在2種基準場景中對比了改進方法、基準多智能體強化學習方法,表5在8種變種場景中評估了改進方法的泛化能力。例如在表4場景10M vs.13L中,PGS w/JPN vs.內置AI的勝率和增益分別是95%和+8%。

表4 改進搜索方法、多智能體強化學習方法的性能對比
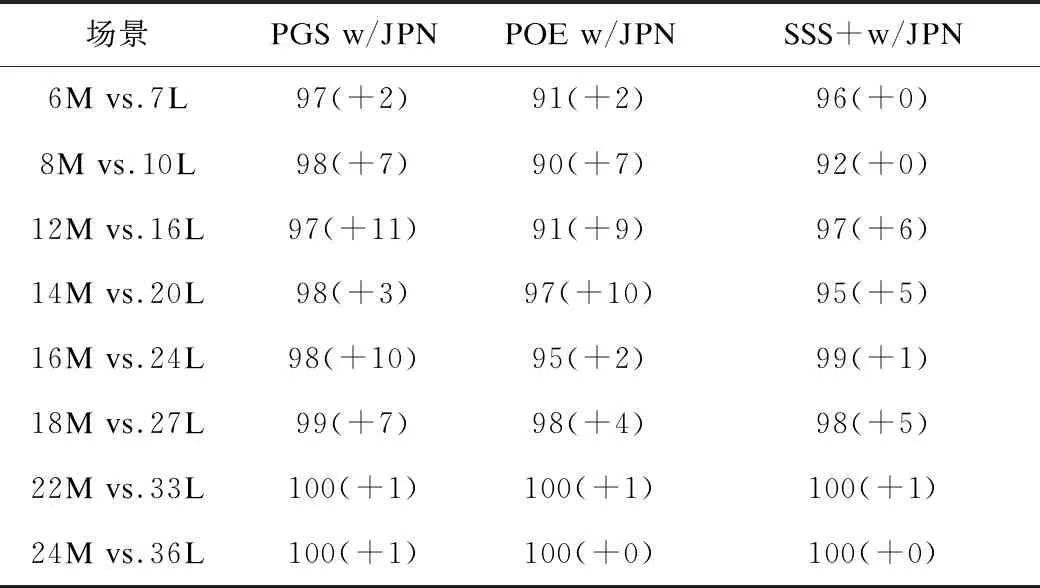
表5 改進搜索方法在8種變種場景中的性能測試
由表4和表5可得出以下實驗結論:1)在2種基準場景中,改進方法可以擊敗內置AI,PGS w/JPN取得勝率接近最好的基準方法,分別是95%、99%,這證實了改進搜索方法對抗內置AI的優勢,同時,改進方法的增益總大于0,這再次表明了JPN可以有效提升搜索方法;2)在8個變種場景中,改進方法同樣可以擊敗內置AI,且增益同樣大于0%,這表明訓練好的學習模型可以泛化至類似場景;3)在絕大多數場景中,PGS w/JPN的表現好于POE w/JPN、SSS+ w/JPN,但實際上PGS弱于POE、SSS+,表明學習與搜索的結合機制對性能是至關重要的。
5 結束語
本文提出一種基于卷積神經網絡的聯合策略網絡方法。該方法將所有智能體作為群體,以實現多智能體聯合動作的端到端學習。改進搜索方法由JPN輸出的先驗概率分布保證初始解,以盡可能地搜索大概率存在最優解的動作空間。實驗結果表明,JPN可以有效提升搜索方法。本文主要通過學習模型提升搜索方法,后續將研究學習模型與搜索方法相結合的機制以進一步提升學習模型的性能。
猜你喜歡
小學生作文(低年級適用)(2018年3期)2018-04-17 00:58:35
少年博覽·小學低年級(2017年4期)2017-06-09 16:22:28
作文評點報·低幼版(2017年7期)2017-03-11 20:49:41
初中生學習·低(2016年10期)2016-11-25 04:51:34
飛碟探索(2016年11期)2016-11-14 19:34:47
作文大王·笑話大王(2016年8期)2016-08-08 11:28:22
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
小學科學(2015年7期)2015-07-29 22:29:00
少兒科學周刊·少年版(2015年4期)2015-07-07 20:56:37
