基于K-S 檢驗與距離相關分析的網絡借貸信用評價指標體系構建
2020-07-25 09:17:06
技術經濟 2020年5期
關鍵詞:評價
(內蒙古財經大學經濟學院,呼和浩特 010070)
一、研究背景
P2P 網絡借貸(peer to peer lending,個人對個人借貸)系指資金出借方與借入方不是通過銀行而是依托互聯網平臺建立借貸關系的無抵押貸款[1]。
網絡借貸作為一種極具活力的新型互聯網金融模式,具有無需中介、交易便利與覆蓋面廣等優點,備受借貸雙方青睞,近年來獲得了蓬勃發展。根據網貸之家發布的《2018 年中國網絡借貸行業年報》顯示,截至2018 年中國網絡借貸行業累計平臺達6430 家,全年累計交易規模為17948 億元,行業參與人數突破千萬。
網絡借貸突破了時間與地點的局限,提升了金融資源的使用效率,緩解了小企業融資難的困局。然而,由于貸款門檻較低、缺乏專業信貸人員與借貸雙方缺乏現實接觸等因素,使得相比于傳統信貸,網絡借貸的信息不對稱情況更嚴重,導致平臺違約事件頻發、信用風險日益加劇。信用風險過大已成為網絡借貸發展的瓶頸。
科學評估網絡借貸的信用風險,從而對網絡借貸這一新經濟業態的潛在風險隱患及時甄別與預防,對于互聯網金融健康持續發展意義重大。網絡借貸信用風險評估已成為備受關注的前沿領域[2]。
評價指標體系建立是網絡借貸信用評價的基礎環節,若是構建的評價指標體系包含大量重復或是不重要的指標,則運用何種評價模型均無法得到科學的評價結果。
目前網絡借貸的信用評價主要側重兩類。
(一)信用評價指標體系研究現狀
Francesco 等[3]通過相關分析篩選指標,建立了包括盈利能力、償付能力、流動性狀況和信貸質量共4 個準則的網絡借貸信用評級指標體系。譚中明等[4]通過網絡問卷調查方式與隸屬度分析結合,利用因子分析方法,從流動性、透明度、品牌等方面構建網貸風險評價指標體系。蔣翠清等[5]運用信息增益、信息增益率及卡方檢驗對軟、硬信息指標的重要性進行排序,通過封裝篩選確定最優的網絡信貸指標體系。張成虎與武博華[6]在網絡調研與因子分析篩選基礎上,構建了包含軟信息的P2P 網絡借貸信用風險評價指標體系。劉傳哲等[7]以對稱不確定性為基礎測算指標間的相關系數,刪除冗余指標,并利用異質集成模型對網貸信用評分問題進行研究。
現有信用評價指標體系的共同不足:一是現有信用評價指標篩選方法基本采用相關分析、因子分析剔除反映信息冗余的指標,上述方法僅僅揭示了變量間的線性關聯程度,但P2P 網絡借貸作為一種互聯網金融創新模式,其海量、復雜的借貸數據往往具備非線性特征。因此,采用現有相關分析、因子分析無法揭示網貸信用評價指標間的非線性聯系,從而導致信用評價指標篩選的結果不可靠;二是現有信用評價指標不能保證對客戶違約與否進行有效甄別,這與信用風險評價這一根本目的相悖。信用評價目的是甄別違約企業與非違約企業。
(二)網絡借貸影響因素的研究現狀
Puro 等[8]通過美國網絡借貸平臺prosper 數據實證發現,網絡借貸成功率與借貸利率及借貸額正相關。Lin 等[9]發現借款者的朋友關系可以降低借款者承擔的利率并降低違約風險。廖理等[10]發現雖然借貸利率越高,借款者才容易獲得貸款,但此類貸款的違約風險也更高。Emekter 等[11]認為信用評分、借款期限、負債收入比等對于借款違約概率有重要影響。Malekipirbazari 和Aksakalli[12]認為借款者的債務收人比也是影響借貸行為的一個關鍵因素。Lin 和Viswanathan[13]發現文化與地理位置是影響借貸重要因素,貸款者更傾向于借貸給地域接近、文化相近的借款者。何光輝等[14]運用Logistic 與Probit 模型對中國網絡借貸風險決定因素進行分析。李杰和劉露[15]根據Logistic 模型發現借款者總收入、總支出是網貸違約與否關鍵因素。李延喜等[16]運用Logistic 與Cox 模型發現,借貸成功并不完全取決于貸款利率,借款者的年齡、學歷及婚姻狀況均有重要影響。
現有研究方法的不足之處:現有網絡借貸影響因素中不僅涉及諸多不能顯著甄別客戶違約狀態的指標,還涵蓋不少信息重復的指標。
上述問題,本文在網絡借貸信用評價海選指標體系,采用K-S檢驗選取可以顯著甄別借款人違約狀態的指標,進而通過距離相關分析剔除掉反映信息重復的指標,最終構建網絡借貸的信用評價指標體系。并通過全球最大的P2P 網絡借貸平臺LendingClub 的實際交易數據進行實證研究。
二、網絡借貸信用評價指標體系構建原理
(一)P2P 網絡借貸的特點
(1)借款者和投資者之間不存在真實的接觸,信息更加不透明,導致投資者對借款者的信用風險進行評價更加困難。
(2)現有關于銀行各類貸款表現的研究[17-18]表明,消費者信用貸款在很大程度上會受到國內生產總值、失業率和利率等宏觀因素的影響,因此如何控制這些宏觀因素對于P2P 網絡借貸信用風險的影響,將是一個重要的問題。
(3)P2P 網絡借貸作為依托云計算、社交網絡等新興技術平臺涌現出來的互聯網金融創新模式,海量、復雜的網絡借貸數據往往具備非線性、高維的大數據特征。
(二)網絡借貸信用評價的問題
問題1:怎樣從眾多繁雜指標中遴選得到可以對網絡借貸者違約狀態顯著分辨的重要指標。
問題2:如何克服現有指標篩選方法僅僅反映指標間線性關聯程度的弊端。現有信用評價指標篩選方法基本采用相關分析、因子分析剔除反映信息冗余的指標,上述方法僅揭示了變量間線性關聯程度,但P2P網絡借貸依托于云計算、社交網絡等新興技術平臺,其數據量極大,往往具備非線性特征。
(三)解決問題的思路
問題1 的解決思路:將企業數據分為違約和非違約兩類樣本,通過K-S檢驗比較違約樣本與非違約樣本的分布函數是否有顯著差異,按照K-S檢驗統計值越大、違約樣本分布函數和非違約樣本的分布函數的偏離愈大,指標越能顯著甄別客戶的違約狀態,選取可以顯著區分違約狀態與否的指標。
問題2 的解決思路:距離相關分析是近年來高維數據非線性相關分析的流行度量方法,其從特征函數的距離角度定義了兩個隨機變量間的非線性相關系數。本文采用距離相關系數反映指標間的線性與非線性的綜合關聯程度,在關聯程度強的一對指標中,剔除K-S檢驗較小、對違約狀態影響較小的指標,刪除了反映信息冗余指標。
(四)評價指標篩選原理
通過K-S檢驗統計值的大小反映指標對違約狀態分辨能力上的差異,按照K-S檢驗統計值越大、違約樣本與非違約樣本的分布函數的偏離越大,指標分辨客戶違約與否的能力就越強。進而根據距離相關分析在兩個關聯程度高的指標中篩選出鑒別分辨違約狀態能力強的指標。克服現有相關分析、因子分析等指標篩選方法僅揭示了指標間的線性關聯程度和無法反映指標間的非線性關聯程度的弊端,彌補現有研究不以能否區分違約狀態為標準遴選評價指標的不足。
網絡借貸信用評價指標體系構建原理如圖1 所示。
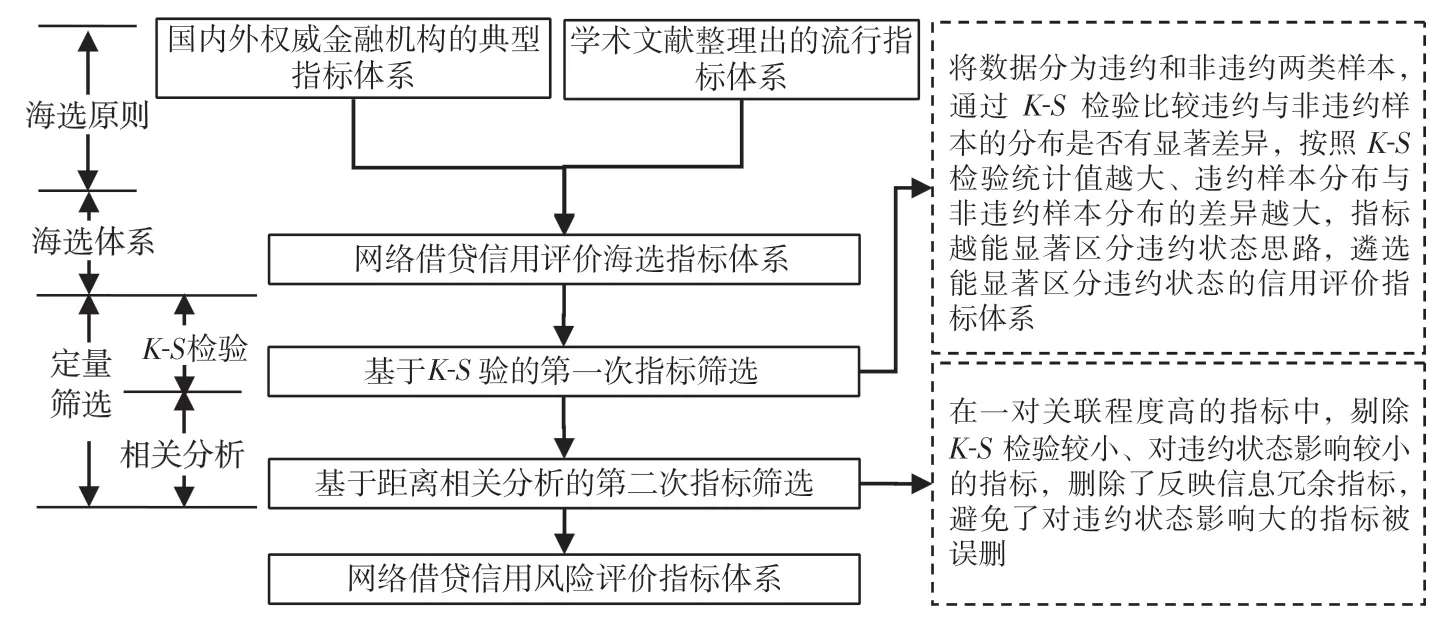
圖1 網絡借貸信用評價指標體系構建原理
三、網絡借貸信用評價指標體系的構建
(一)海選指標體系的建立
1.網絡借貸信用風險的內涵
網絡借貸信用風險指網絡借貸中貸款者未能按照合同約定及時足額還本付息而給資金出借方帶來的風險損失[13-15]。
資金出借方通過考量貸款人的還款能力及還款意愿這兩方面來評估其發生違約的可能性。貸款人的還款能力可以通過貸款者年收入等財務特征與貸款者職業等個人特征來反映;而貸款人的還款意愿可由貸款者違約次數等個人信用特征來體現。
同時,現有研究[8-16]表明:貸款金額、貸款利率等借款特征也對網絡貸款的信用風險影響顯著。此外,現有關于銀行各類貸款表現的研究[17-18]表明,消費信用貸款在很大程度上會受到國內生產總值、失業率和利率等宏觀因素的影響,因此將外部宏觀經濟特征納入網絡借貸信用評價指標體系中。
2.準則層設置
3.海選指標體系的構建
以網絡借貸信用風險內涵為基礎,根據國內外網絡借貸信用評價文獻的流行高頻指標[3-16],建立了包括借款金額、年齡等指標構成的涉及借款標的特征、借款者個人特征、借款者財務特征、借款者信用特征及宏觀經濟特征5 個準則層的網絡借貸信用評價的海選指標體系,見表1。
(二)信用評價指標體系的建立
1.指標數據的歸一化
指標數據歸一化是把指標原始數據轉化為[0,1]間的數,剔除單位及量綱對評價結果的影響。
信用評價指標可分成定量指標與定性指標。定量指標分為成本類型指標、效益類型指標及區間型指標。
成本型指標系指網絡借款者的信用狀況與指標的數值負相關,即指標數值愈大,則說明借款者的信用狀況愈差。效益型系指標系指網絡借款者的信用狀況與指標的數值正相關,即指標數值愈大,則說明借款者的信用狀況愈好。
臨床生化檢驗屬于醫院重要工作內容,生化檢測結果的準確性對診斷和治療疾病產生直接影響[1]。血液樣本溶血是指血液樣本在臨床檢驗過程中由各種因素影響導致紅細胞被破壞,而細胞內物質進入血清,使得血清呈現出紅色,進而影響生化檢驗結果準確性的醫學現象。在當下臨床檢驗實踐過程中,若因血液標本溶血導致結果不準確而引發的醫療糾紛,醫院往往處于被動地位,并可能需要承擔全部責任,所以臨床上如何避免或預防血液溶血對生化檢測結果帶來的影響依然是臨床檢驗科室面對的焦點問題[1]。此外臨床對糾正溶血所產生影響的措施缺少關注。本研究對溶血對生化檢驗準確性影響進行分析并總結相關應對措施,現將相關內容總結如下:
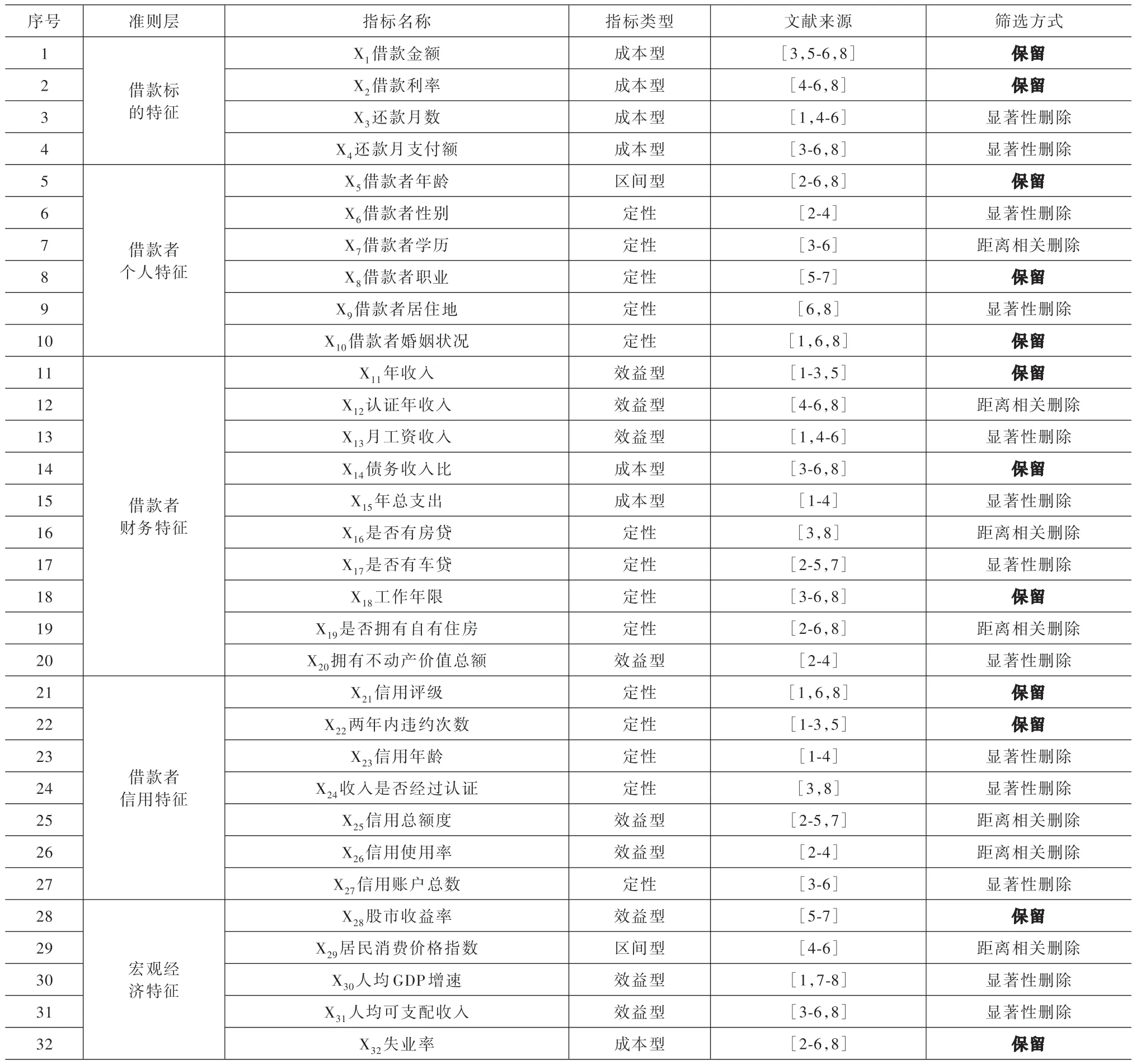
表1 網絡借貸信用評價海選指標體系
成本類、效益類指標歸一化公式[12]如下所示。
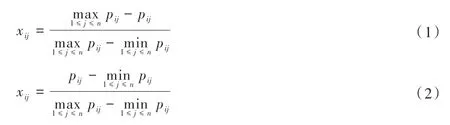
其中:xij為第i個指標第j個借款的歸一化值;pij為第i個指標第j筆借款原始數據;n為借款個數。
區間型指標是指當指標的數據值落在某一個特定區間內都是合理的指標。例如:居民消費價格指數、年齡等兩指標。指標“居民消費價格指數”理想區間是[100.6,104.7][17-18]。“居民消費價格指數”數值處于該區間中既不通貨膨脹又不通貨緊縮。根據對網絡借貸平臺發放調查問卷,發現將指標“年齡”合理區間范圍設置為[30,48],即年齡處于該區間的借款者還款意愿、清償能力都是最強的。
設q1為指標最佳區間左端點,q2為指標最佳區間右端點,根據區間指標的歸一化打分公式[12]如下:
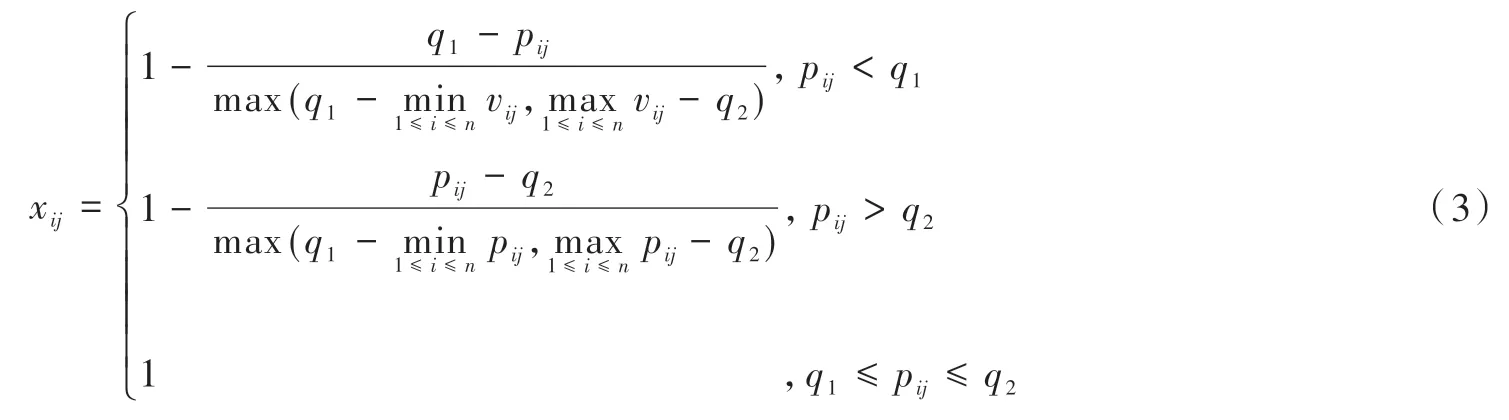
定性指標的標準化得分是在對網貸信用評價專家進行實地訪談調研基礎上,按照定性指標的不同程度確定量化打分標準。見表2。
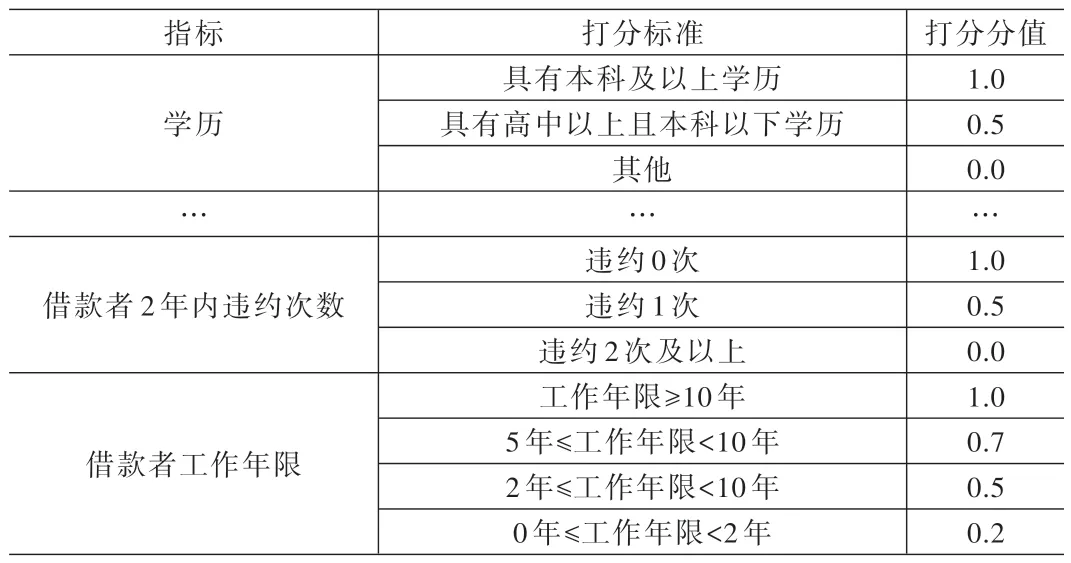
表2 定性指標打分標準
2.指標的正態分布檢驗
通過Jarque-Bera 正態檢驗,可判斷指標是否服從正態分布。Jarque-Bera 正態檢驗步驟[19]如下。
(1)建立假設檢驗。
原假設:第i個指標Xi服從正態分布(H0)。
備擇假設:第i個指標Xi不服從正態分布(H1)。
(2)構造JB統計量(即Jarque-Bera 檢驗統計量)。設為第i個指標標準化得分的平均值,n為樣本借款總數,xij為第i個指標第j個借款的標準化得分,j=1,2,…,n,則


設Si為第i個指標偏度系數,由文獻[19]可知

式(6)中其他字母含義與式(4)、式(5)相同。
設Ki-第i個指標的峰度系數,由文獻[19]可知

設JBi為第i個指標Jarque-Bera 檢驗統計量,則

式(8)中其他字母含義與式(6)、式(7)相同。
(3)檢驗標準[19]。原假設H0 成立時,Jarque-Bera 檢驗統計量JBi服從自由度為2 的χ2分布[19],給定顯著性水平α,查表可得χ2分布的臨界值J0。若統計量JBi大于臨界值J0,則拒絕原假設H0,即第i個指標Xi不服從正態分布;反之,則接受原假設H0,即第i個指標Xi服從正態分布。
3.違約顯著區分的指標篩選方法
通過該方法可刪除對違約狀態區分不顯著的指標。
按照某個指標數據,把借款數據分為違約和非違約兩類,若該指標K-S檢驗值愈大,即違約的經驗分布與非違約的經驗分布的偏離愈大,說明評價指標甄別借款人是否違約的能力越強,指標對信用評價結果影響顯著,應保留;反之,說明該指標無法有效區分違約借款人與非違約借款人,指標對信用評價結果影響不大,須刪除。
K-S檢驗篩選指標的計算步驟如下。
(1)建立假設檢驗。
原假設:第i個指標的違約樣本的分布與非違約樣本的分布沒有顯著差異(H0)。
備擇假設:第i個指標的違約樣本分布與非違約樣本分布有顯著差異(H1)。
(2)構造K-S檢驗的D統計量。
步驟1:兩類樣本經驗分布函數的確定。
以違約樣本的經驗分布為例。設違約借款個數為n1,非違約借款個數為n2,借款總數為n,n=n1+n2。
令xi1,xi2,…,xi,n1為第i個指標n1個違約借款的標準化值。將這n1個數從小到大排序,重新編號得到這n1個標準化值的次序統計量。同理得到n2個非違約借款的標準化值的次序統計量。
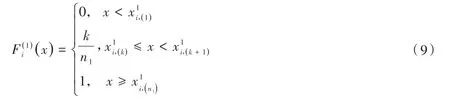
同理得第i個指標的非違約經驗分布。
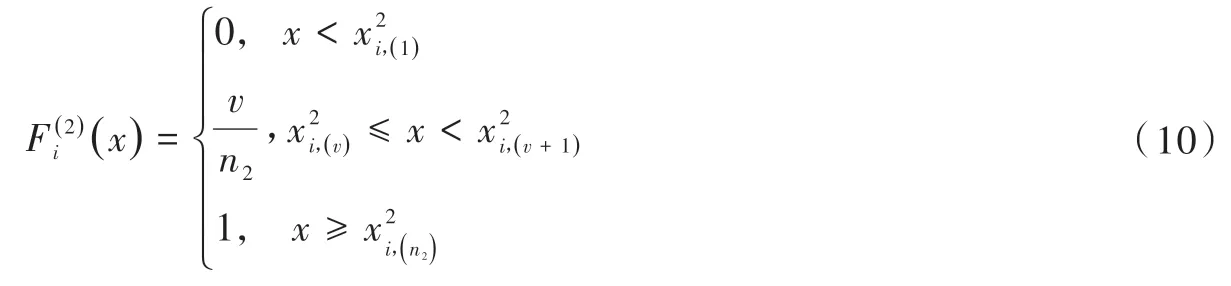
其中:v表示在第i個指標n2個非違約借款的標準化值中,小于等于x的標準化值的個數。
步驟2:K-S檢驗D統計量的確定。
設Di為第i個指標K-S檢驗的D統計量,I為由第i個指標n個借款的標準化值構成的實數集合,即I={xi1,xi2,…,xi,n},為第i個指標的違約經驗分布,為第i個指標的非違約經驗分布,由文獻[19]可知

其中:第i個指標K-S檢驗統計量Di等于第i個指標違約經驗分布與第i個指標非違約經驗分布之差的絕對值的最大值。
K-S檢驗統計量Di反映了第i個指標區分違約狀態的能力強弱。第i個指標的D統計量越大,第i個指標在違約樣本與非違約樣本中的差異越大,表明第i個指標區分違約狀態能力越強;反之亦然。
式(11)采用K-S檢驗篩選指標的好處:一是按照違約樣本與非違約樣本的分布函數的差異越大,這個指標越能顯著區分違約與否狀態的思路,構造指標的K-S檢驗值,遴選能顯著區分違約狀態的指標,彌補現有研究不以能否區分違約狀態為標準遴選評價指標的不足;二是采用K-S檢驗這一對評價指標的總體分布無任何要求、適用于分布未知的非參數統計方法篩選指標,克服現有方法要求指標服從正態分布的這一嚴格假設弊端。
(3)篩選標準。在原假設H0 成立時,第i個指標K-S檢驗的統計量Di服從Kolmogorov 分布[17]。給定顯著性水平α,通過查表可得Kolmogorov 分布的臨界值D0。
①若統計量Di大于等于臨界值D0,則拒絕原假設H0,即第i個指標的違約樣本分布與非違約樣本分布有顯著差異,說明違約樣本與非違約樣本能被第i個指標明顯區分,則保留第i個指標。
②若統計量Di小于臨界值D0,則接受原假設H0,即第i個指標的違約樣本分布與非違約樣本分布沒有顯著差異,說明違約樣本與非違約樣本不能被第i個指標明顯區分,則刪除第i個指標。
4.冗余信息剔除的指標篩選方法
該方法可在關聯程度高的一對指標中篩選出違約甄別能力強的指標,確保得到信息不重復的指標。
距離相關系數是一種新型相關系數,其基本思想是根據兩個隨機變量的聯合分布函數F(x,y)與各自的邊緣分布函數FX(x)、FY(y)間的距離測度隨機變量X與Y之間的相關性[20-21]。與傳統皮爾遜相關系數、秩相關系數等線性相關系數相比,距離相關系數無論變量間是線性關系或是非線性關系均可度量,無需任何假設與分布條件,具有很強的普適性。因此,本文采用距離相關系數度量同一準則層下兩指標間的相關性,進而進行冗余指標的刪除。
距離相關系數篩選指標的步驟如下。
(1)距離相關系數的計算。設有m個指標,n個借據。令Xi為第i個指標歸一化值的向量,即Xi=(xi1,xi2,…,xin)。則向量Xi與向量Xj的距離相關系數drij[20]為
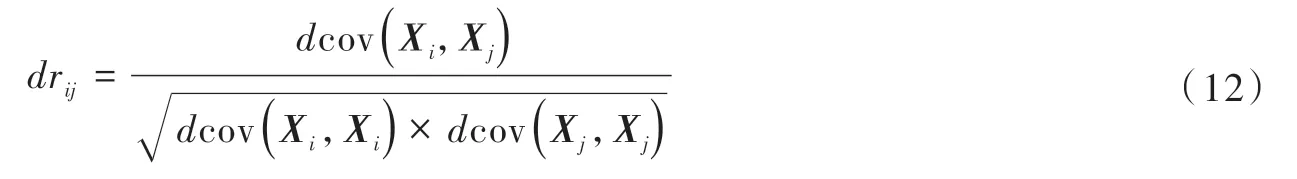
其中:dcov(Xi,Xj)為向量Xi、Xj的距離協方差,由下式(13)計算得到。

其中:Akl、Bkl由式(14)與式(15)確定。

設xik為第i個指標第k筆借款的歸一化值,則式(14)的4 個參數分別由式(16)~式(19)確定。

(2)臨界值確定。設定臨界值M∈[0,1],若距離相關系數絕對值 |rik|≥M,則刪除兩個指標中反映違約鑒別能力弱的指標。兩個指標距離相關系數大于0.8 時屬高度相關[20]。因此,選取臨界值M=0.8。
(3)指標篩選標準。若第i個指標與第k個指標的距離相關系數絕對值 |rik|≥0.8 時,則第i個指標與第k個指標反映信息重復,應刪除其中K-S檢驗值較小的;反之,說明指標反映信息不重復,同時保留兩指標。
本研究篩選信息冗余指標方法的好處:通過距離相關系數刪除反映信息重復的指標,保留K-S檢驗值大的,即對違約區分能力強的指標,避免對違約狀態區分能力強的指標被誤刪,無論指標間是線性關系或是非線性關系均可適用,無須指標數據滿足正態分布,適用于指標分布未知的情形。
(三)評價指標體系的合理性檢驗
信用評價指標體系合理與否是看基于指標體系構建信用評價模型的違約預測力是否顯著。即檢驗利用指標體系構建的信用評價模型違約預測能力越顯著,信用評價指標體系就越合理。
先利用上述指標篩選方法構建網絡借貸的信用評價指標體系。再根據該指標體系及Logistic 模型可以計算得到每個借款者的違約概率(PDi)。將PDi與違約臨界值比較,可對借款者是否違約進行預測。繼而采用ROC 曲線(受試者工作特征曲線)AUC 值(ROC 曲線所覆蓋的區域面積)對網貸信用評價指標體系的違約預測效果進行檢驗。
將實際違約借款被模型判定為違約借款數量記為DD;實際違約借款被模型判定為非違約的借款數量記為DN;實際非違約借款被模型判定為違約的數量記為ND;實際非違約借款被模型判定為非違約的數量記為NN,見表3。

表3 實際違約狀態與模型判別結果劃分
ROC 曲線涉及兩個變量,靈敏度(Sensitivity)和特異度(Specificity),如式(20)和式(21)[22]所示:

靈敏度(Sensitivity)等于實際違約借款中被模型判定為違約的個數DD與實際違約借款總數(DD+DN)的比率,即借款違約狀態的判對率。

特異度(Specificity)等于實際非違約的借款中被模型判定為非違約的個數ND與實際非違約借款總數(ND+NN)的比率,即借款非違約狀態判對率。
ROC 曲線的縱軸為Sensitivity,橫軸即1-Specificity,也就是1-借款非違約狀態判對率。
ROC 曲線下方圍成面積為AUC 值。當橫軸不變時,縱軸越向上,即實際違約借款判對率越高,模型判別準確率也越高,ROC 曲線也越向上,曲線下圍成的面積AUC 值也越大。因此,AUC 值越大,信用評價模型對違約狀態判別準確性越高,信用評價指標體系也就越合理。
四、實證研究
(一)實證樣本與數據來源
本文的指標實證樣本來自美國P2P 借貸平臺LendingClub 提供的借款標的數據[23],樣本數據區間為2009—2014。Lending Club 成立于2007 年,是目前世界上最大的在線P2P 網絡借貸平臺,平臺提供企業及個人信貸、房貸及消費貸款等借貸品種。在樣本區間內,選取已完結的網絡借款,并去掉數據缺失較多的指標,最終得到31000 條借款信息,對應31000 個借款人。非違約樣本為27000 個,違約樣本為4000 個。違約系指貸款到期后90 天內未能足額償還貸款的本金與利息。P2P 網絡借貸的指標原始數據見表4 第31000 列所示。表4 第33 行為貸款借款的違約狀態標識,違約、非違約分別用“1”和“0”標識。
(二)信用評價指標體系的建立
1.指標的歸一化
(1)定量指標歸一化。根據表4 的指標類型,分別將表4 第1~31000 列的正向指標、負向指標、區間型指標數據pij代入式(1)~式(3),得到指標的標準化得分xij,列入表4 后31000 列各定量指標對應行。
(2)定性指標標準化。根據表4 的指標類型及表2 定性指標的打分標準,為表4 中的各個定性指標進行歸一化打分。結果列入表4 各定性指標的對應行。
2.指標的正態分布檢驗
(1)Jarque-Bera 正態檢驗統計值的確定。以第1 個指標X1“借款金額”的Jarque-Bera 正態檢驗統計量的確定過程為例。把表4 第1 行指標X1的歸一化得分x1j、借款總數n=31000 依次代入式(4)~式(7),得到指標X1的偏度系數S1=-0.531、峰度系數K1=-0.949。把偏度系數S1=-0.531、峰度系數K1=-0.949 代入式(8),得到指標X1的正態檢驗統計值JB1=126.412。將結果列入表5 第1 行第3 列。同理得其余指標的統計量JBi,結果列入表5 第3 列其余行。
(2)正態檢驗結果。原假設H0 成立時,第i個指標的檢驗統計量JBi服從自由度為2 的χ2分布[18],給定顯著性水平α=0.05,查表得χ2分布的臨界值J0=5.991。由于表5 第3 列的81 個指標的JBi均大于J0=5.991,由正態檢驗標準,則32 個指標Xi均不服從正態分布。在表5 第4 列用“否”標注。
由于所有32 個指標Xi均不服從正態分布,故本文采用K-S檢驗、距離相關分析的非參數統計方法篩選信用評價指標。
3.違約顯著區分的指標第1 次篩選
(1)K-S檢驗值的確定。以指標“X1借款金額”為例。
步驟1:違約樣本經驗分布函數的確定。把表4 第1 行指標X1的4000 個違約借款的歸一化值x1j按照從小到大次序排列,得到指標X1對應次序統計值。把得到的指標X1標準化值對應的次序統計值,n1=4000 代入式(9),得到違約樣本經驗分布。仿照上述過程,可得非違約樣本經驗分布。
步驟2:K-S檢驗值的確定。把指標X1第1 個借款的歸一化值x11依次代入函數,得到x11的違約樣本經驗分布值、非違約樣本經驗分布值,得到|F1(1)(x11)-F1(2)(x11)|。同理,可得其余歸一化值的違約樣本與非違約樣本經驗分布值之差的絕對值。
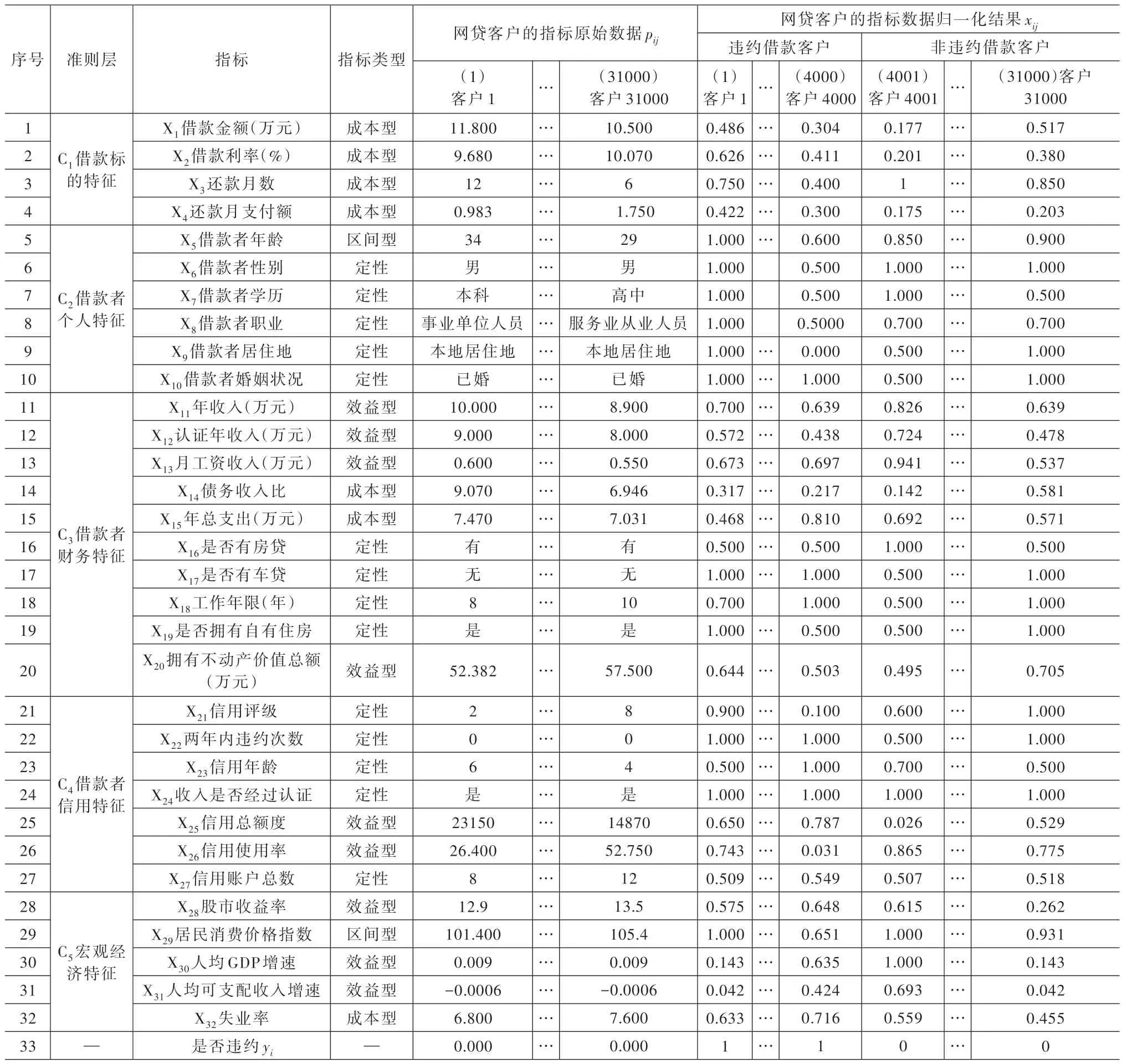
表4 P2P 網絡借貸指標篩選原始數據
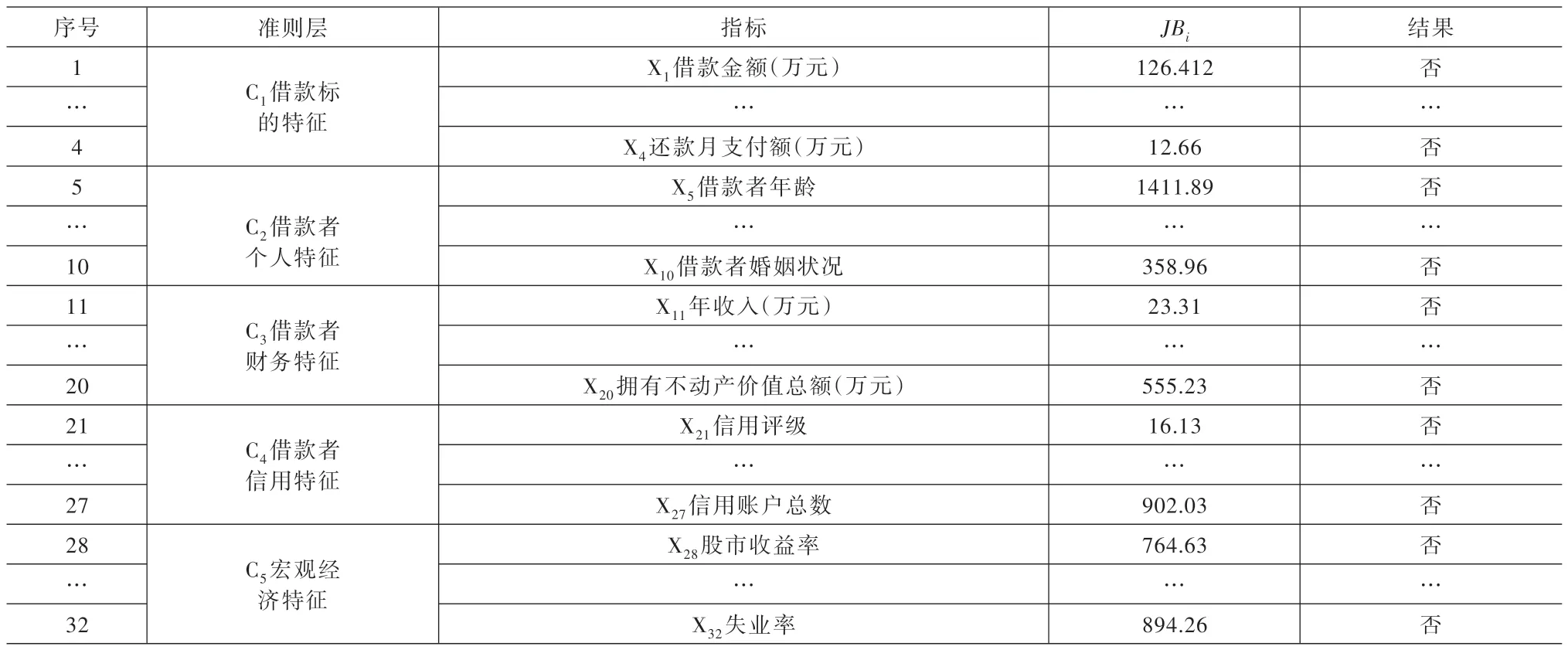
表5 Jarque-Bera 正態檢驗結果
綜上,總共得到指標X1的31000 個、違約樣本與非違約樣本的經驗分布函數值之差的絕對值。求解這31000 個絕對值中的最大值即得到指標X1的K-S檢驗統計值D1,即。其中,I為由表4 第1 行指標X1的歸一化值組成的實數集合。結果列入表6 第1 行第3 列。重復上述步驟1~步驟2,可得其余31 個指標的K-S檢驗統計值Di,結果列入表6 第3 列其余行。
(2)K-S檢驗篩選指標的結果。K-S檢驗統計量Di服從Kolmogorov 分布[19]。給定顯著性水平α=0.05,通過查表可得Kolmogorov 分布的臨界值D0≥1.358。
通過表6 第3 列可知,在32 個指標中,“X3還款月數”等13 個指標的K-S檢驗值全都低于1.358,檢驗不通過,說明這些指標的違約借款與非違約借款的經驗分布函數并不存在明顯區別,指標無法顯著甄別借款者是否違約,應刪除。通過表6 第3 列可知,32 個指標中,“X1借款金額”等19 個指標的K-S檢驗值全都大于1.358,表明這些指標的違約借款與非違約借款的經驗分布函數存在明顯區別,指標可以顯著甄別借款者是否違約,應保留。
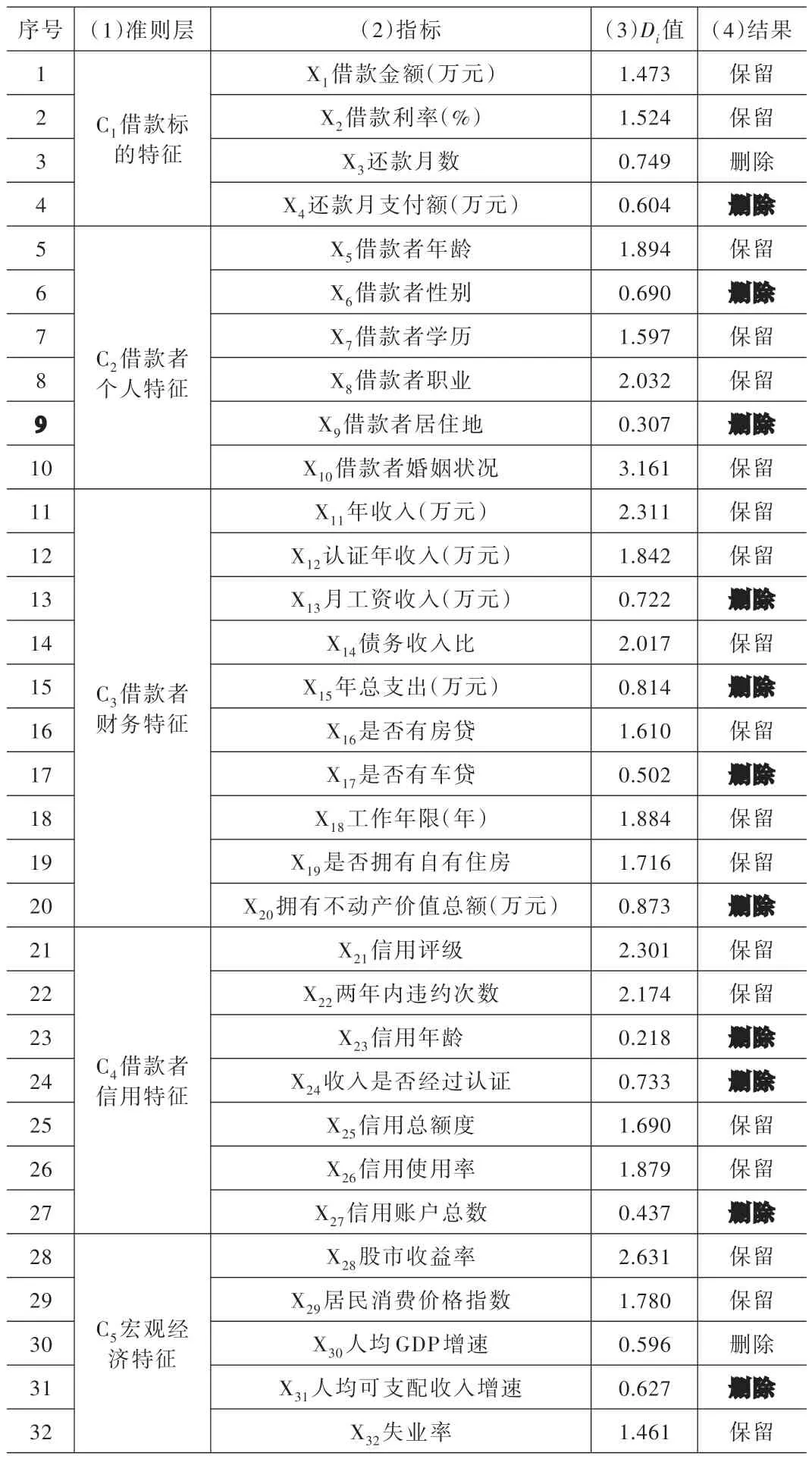
表6 K-S 檢驗指標篩選結果
4.冗余信息刪除的指標第2 次篩選
(1)距離相關系數的確定。經過第四節第(二)節第3 小節的第一次篩選,刪除了13 個指標,剩余19 個指標。將表6 第1~2 列的K-S檢驗保留的19 個指標按準則層合并,合并后的19 個指標進行距離相關分析的第二次指標遴選。用于距離相關分析的第二次指標遴選的19 個指標標準化數據見表7。利用表7 的標準化數據以及式(12)~式(19),可得到同一準則層下兩個指標的距離相關系數。
以指標X1的和X2的距離相關系數計算為例。利用指標X1歸一化得分x1j、指標X2歸一化得分x2j及式(12)~式(19),得到指標X1和X2的距離相關系數r12=0.353。其他指標的距離相關系數類推可得。將所有指標中絕對值大于0.8 的距離相關系數 值rik列入表8 第5 列。表8 第2、4 列的Di來源于表6 第3 列的相應行。
(2)距離相關分析篩選結果。選取0.8 作為距離相關系數臨界值。由表8 第5 列可知,共有7對指標的距離相關系數大于0.8,故此7 對指標屬于反映信息冗余,在這7 對指標中保留K-S檢驗統計值Di較大的指標。由表6 第3 列的Di可知,max{D11、D12}={2.311、1.842}=2.311,指 標X11“年收入”的K-S檢驗統計值D11最大,故保留指標X11,刪除指標X12,刪除的指標列于表8 第2 行第6列。同理,其他的刪除指標列于表8 第6 列的其他行。
綜上,通過距離相關分析將K-S檢驗篩選后留下的19 個指標進行第二次篩選,去除反映信息冗余的7 個指標,最終保留了12 個指標。刪除的7 個在表1 用“冗余信息刪除”標出;最終保留的12 個指標在表1 用“保留”標出。
5.網絡借貸信用評價指標體系的建立
在32 個指標中,根據K-S檢驗去掉區分違約不顯著的13 個指標,利用距離相關分析刪除7 個信息冗余的指標,最后建立了包含12 個指標的小企業信用評價指標體系,見表9 第a~d列。同時,最終保留12 個指標在表1 中用“保留”標出。

表7 進行距離相關分析的19 個海選指標的標準化數據
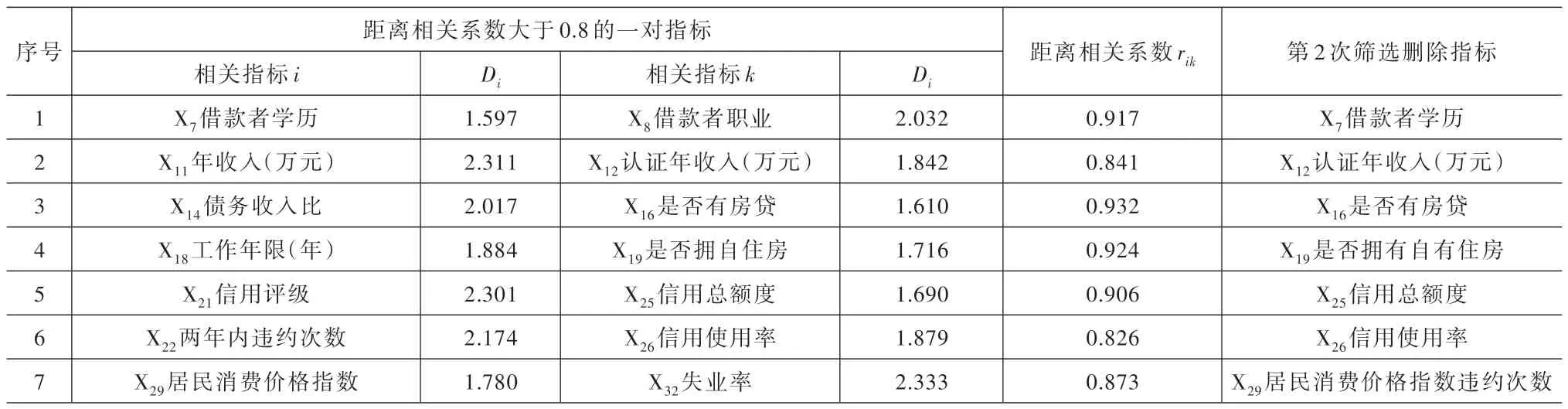
表8 經距離相關分析刪除的評價指標
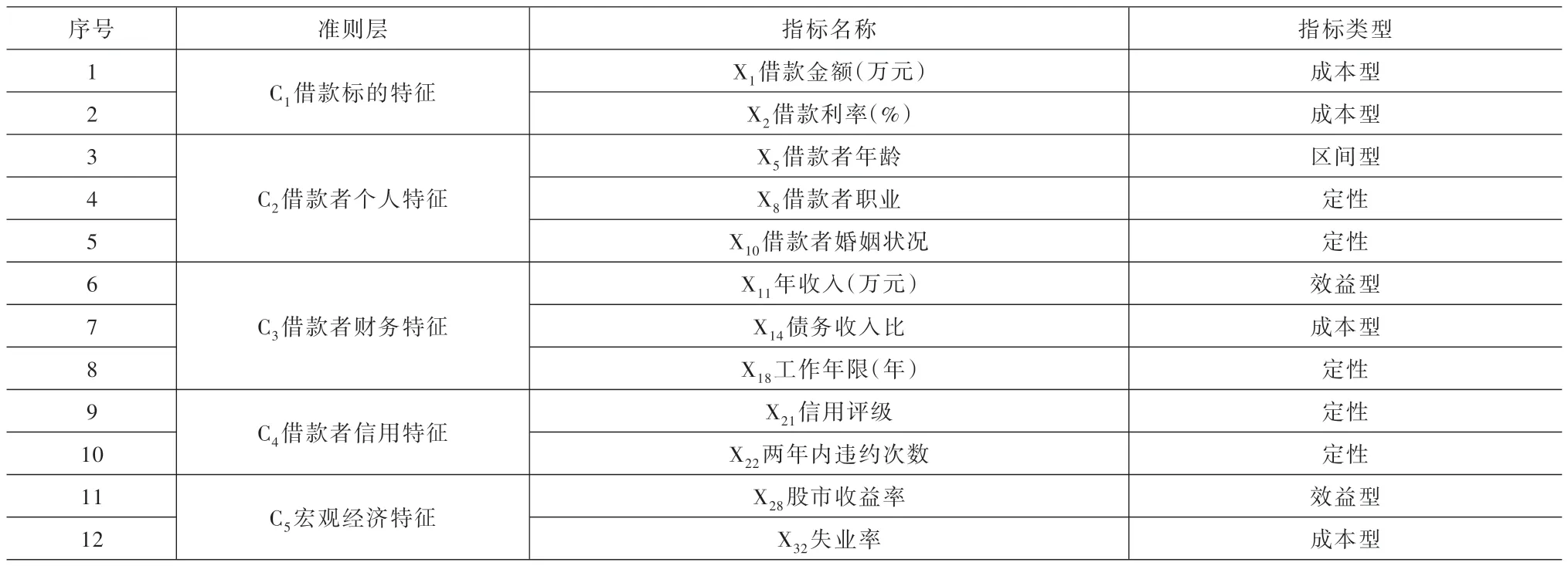
表9 網絡借貸信用評價指標體系
(三)信用評價指標體系合理性檢驗
根據表9 的網絡借貸信用評價指標體系及Logistic模型計算得到實證31000 個借款者的違約概率PDi(i=1,2,…,31000)。當取違約臨界值為0.5 時,即當違約概率PD低于0.5,判定貸款者為違約;不低于0.5 判定貸款者為非違約。
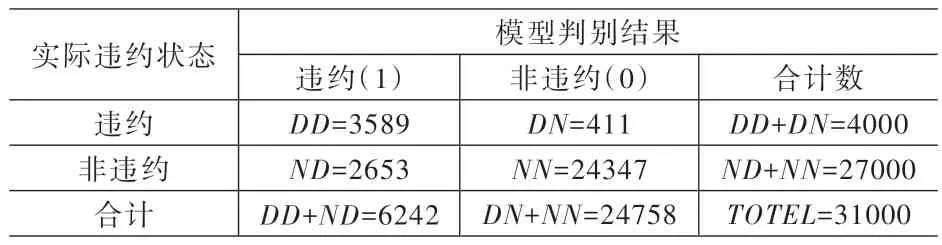
表10 實際違約狀態與模型判別結果
在31000 個借款者中,有4000 個違約借款者與27000 個非違約借款者。將4000 個違約借款者的違約概率PDi逐個與臨界值0.5 比較,可得實際違約借款人被判定為違約的個數DD、實際違約借款人被判定為非違約的個數DN。同理可得到實際非違約借款人被判定為違約個數ND、實際非違約借款人被判定為非違約個數NN。計算結果列入表10 的數字矩陣。
表10 的數據代入式(20),得到靈敏度為0.897;代入式(21),得到特異度為0.902,也就得到橫坐標1-特異度為0.098,這樣就可以確定ROC 曲線上的一個點(0.098,0.897)。ROC 曲線中,每取一個臨界值,就得到一組靈敏度和特異度,每個(1-特異度,靈敏度)可確定一個點坐標,取不同臨界值50、60…,會得到多個點,可畫出ROC 曲線,如圖2 所示。
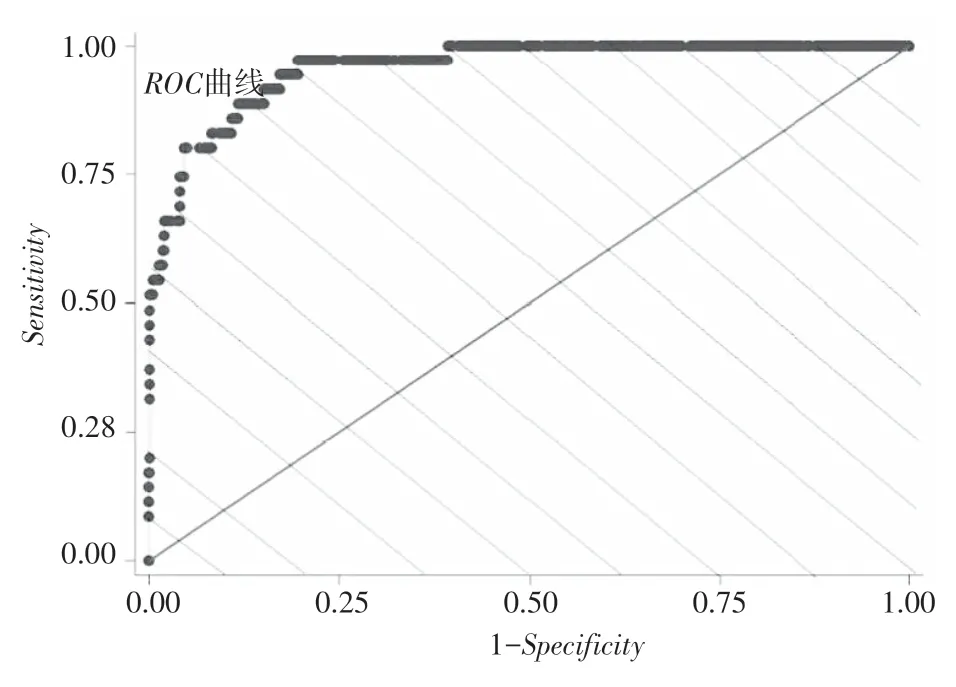
圖2 檢驗指標體系的ROC 曲線
經計算,本文構建的網絡借貸信用評價指標體系對違約與非違約借款者違約狀態判別精度的AUC=0.913。一般認為違約判別精度AUC 超過0.8[19]時,評價指標體系的違約判別能力就較強。因此,由于本文構建的網絡借貸信用評價指標體系的AUC=0.913>0.8,故認為構建的評價指標體系具有較強違約鑒別力,則評價指標體系構建合理。
五、結論與建議
(一)主要工作
本文根據K-S檢驗與距離相關分析相結合,篩選對借款客戶違約狀態甄別能力強的指標,建立了網絡借貸信用評價指標體系,并通過全球最大的P2P 網絡借貸平臺Lending Club 的實際交易數據進行實證研究。結果表明:本研究評價指標體系中的借款金額、借款者職業、失業率等12 個指標均對區分違約狀態有顯著影響。
(二)特色與創新
(1)按照K-S檢驗統計值愈大、其對應違約樣本分布函數與非違約樣本分布函數的偏離愈大,表明評價指標甄別借款客戶違約狀態的能力愈強,遴選能顯著區分違約狀態與否的評價指標,彌補現有研究不以能否區分違約狀態為標準遴選評價指標的不足。
(2)通過距離相關系數反映同一準則層下兩個指標間的線性與非線性關聯程度,在關聯程度強的一對指標中,剔除K-S檢驗較小、對違約狀態影響較小的指標,刪除了反映信息冗余指標,克服現有相關分析、因子分析等指標篩選方法僅揭示了指標間的線性關聯程度,無法反映指標間非線性關聯程度的弊端,拓展信用評價指標篩選方法適用范圍。
(三)啟示及政策建議
本文采用K-S檢驗與距離相關分析構建的網絡借貸信用評價指標體系,實證表明:借款金額、借款者職業、失業率等12 個指標均對區分違約狀態有顯著影響。上述研究有助于理解網絡借貸違約行為及其變化規律,預測借貸違約的發生,進而在發放貸款時制定或調整相應的借貸標準,控制借貸違約的發生。
P2P 網絡借貸作為新型經濟業態,已成為拉動國民經濟的重要增長點,但由于網絡借貸的違約風險較難甄別,導致當前P2P 平臺的相關監管存在一定程度的缺失或滯后。基于上述研究結果,本文提出如下政策建議:
(1)建議監管部門構建網絡借貸違約風險評估模型,對P2P 平臺進行風險監測。相關監管機構可以借鑒本文評價指標篩選方法,充分利用大數據技術,識別網絡借貸的違約風險,從而對P2P 平臺潛在的風險進行及時預判與控制。
(2)建立金融機構與P2P 平臺的信息共享機制,融合多源數據。由于商業銀行對借款者歷史違約信息了解更多,監管部門應倡導銀行等機構與P2P 平臺加強信息共享,融合多維度信息,為準確地評估借款人違約風險提供充分的數據資源。
(四)不足之處及展望
本文主要屬于應用性研究,在指標篩選方法的改進上創新有限,這也是本文的不足所在。在之后研究中,擬在信用評價指標賦權方面,按照對借款者違約狀態區分能力愈強、指標賦權越大的思路,測算評價指標的權重。由于該項研究與本文的科學問題聚焦不同,因而本文未做進一步拓展,后續我們將另文專述。
猜你喜歡
石油瀝青(2021年4期)2021-10-14 08:50:44
世界科學技術-中醫藥現代化(2021年10期)2021-03-02 05:52:06
現代檢驗醫學雜志(2016年3期)2016-11-15 01:59:56
中學語文(2015年21期)2015-03-01 03:52:11
中國教育技術裝備(2015年19期)2015-03-01 02:43:07
中國工程咨詢(2015年2期)2015-02-14 02:59:26
西南軍醫(2015年1期)2015-01-22 09:08:16
中國音樂教育(2014年9期)2014-05-20 10:26:24
治淮(2013年1期)2013-03-11 20:05:18
俄羅斯問題研究(2012年1期)2012-03-25 09:54:51
