基于學科特性的高校圖書館讀者借閱行為實證研究
2020-08-12 01:58:48陳添源
圖書館界 2020年3期
陳添源
(閩南師范大學圖書館,福建 漳州 363000)
1 引 言
當前高校圖書館紙質圖書借閱量逐年下滑,加之圖書購置經費不足和館藏空間轉型等外在因素影響,館藏資源在教學和科研的文獻保障能力和形態正在悄然發生改變。提振借閱率、優化館藏建設結構和提高精準化的圖書借閱服務,逐漸成為高校圖書館發展轉型中不得不面對的實踐問題之一。為此,準確把握高校圖書館讀者的用戶行為,建立用戶驅動的館藏建設與服務體系日益迫切。然而,由于高校圖書館自動化系統從用戶視角的固定化報表與統計數據較少,隨需而變的用戶行為數據存在難以獲取、歷史數據積累較少和系統孤島等技術因素,直接導致了基于數據驅動的業務決策模式無從談起。為此,文章試圖探索構建一套挖掘高校圖書館用戶借閱行為的實證研究體系,并抽樣選取不同學科類型讀者的借閱行為作為實證研究對象,實證獲取的結論可以豐富和完善圖書采訪人員的采購策略,優化圖書館館藏建設體系,提高基于不同學科特征的精準化圖書借閱服務能力,以期逐步建立起基于讀者真實需求的館藏建設新模式。
2 相關研究述評
國內高校圖書館從業務實踐出發,結合自身圖書館業務實際和讀者需求不斷優化圖書借閱服務和創新讀者服務模式。較多的研究集中于圖書借閱關聯分析,例如,南昌航空大學圖書館結合借閱服務特征,使用改進的L-Apriori關聯算法實現圖書的個性化推薦[1]。任武[2]通過構建讀者偏好的本體模型分析了讀者借閱行為,從而獲取讀者閱讀偏好值實現個性化推薦服務。張煒[3]通過關聯挖掘技術對讀者借閱數據隱含的知識展開分析,從而縮短讀者需求與圖書館服務之間的差距。一些研究從提升圖書借閱率的視角切入,錢玲飛等[4]采用h指數對OPAC數據統計分析,獲取不同圖書集合的“核心讀者”以及不同讀者群的“核—Ca”圖書,從而實現館藏的合理分布和圖書使用率。孟德泉等[5]利用主成分分析得出影響讀者借閱行為的關鍵因素,并根據研究結果提出提升圖書外借率的具體建議。許毅等[6]將讀者圖書借閱冊數、進館人次與本科生成績等字段聯合回歸分析,指出圖書館資源利用率與學業成績存在極強的正相關關系。而在讀者借閱行為分析的研究方面,劉春霞[7]從提升圖書借閱率的角度出發,采用方差分析、相關分析和回歸分析等統計方法挖掘,從而為圖書采訪建設與借閱管理提供決策支持。呂遠等[8]借助關聯和分類分析等數據挖掘方法實證分析了在校讀者的借閱行為模式,并提出建立以用戶需求驅動的主動服務方式。邢榮華等[9]基于流通借閱日志分析了各時段讀者借閱的行為差異。嚴貝妮等[10]從抽樣調查的10所高校圖書館2016年的借閱排行入手分析了讀者閱讀行為,指出讀者閱讀有較強的偏向性和功利性,倡導多元閱讀和提升讀者閱讀修養。
陳鳳[11]所指出,將讀者圖書借閱行為可視化分析并直觀地支持采購決策已成為當前實踐研究常態。蔣小峰[12]在對近10年高校圖書館流通借閱服務的總結與分析基礎上,明確提出在讀者需求產生的原因、演變規律以及滿足需求的途徑等方面應深入研究。從前述研究不難發現,諸多文獻未能融入諸如學科背景、專業特征、學習需求和借閱次數等外在因素一同作用戶行為分析,所采用的分析數據也僅能分析單獨一個年度的借閱數據,未能形成基于歷史數據的規律挖掘。這一方面源于圖書館自動化系統軟件都未集成圖書流通的關聯分析模塊;另一方面是可視化的用戶行為分析工具尚未得到廣泛應用,圖書館及時挖掘和分析讀者借閱行為的時效性明顯滯后。
故此,文章將基于大數據思維理念,通過相關數理分析工具和模型算法,從自動化系統中抽取我校讀者6年以來的讀者借閱行為數據,探尋讀者借閱行為,系統全面地掌握基于學科特性的讀者借閱行為特征,不斷積累讀者的借閱行為規律、熱門圖書、主題詞分布和圖書關聯,從而實現更為精準的紙質文獻保障。建立和優化基于讀者行為驅動的館藏建設服務體系,提升館藏紙質圖書建設經費的效益,也為圖書館館藏空間讓位空間服務提供有益的業務決策。
3 實證研究設計與相關模型方法
3.1 實證思路與框架
以學科特性為視角,選取高校圖書館某個學院歷年的讀者借閱數據,以此數據集為實證對象,結合高校讀者學科專業學習的階段特性,借助大數據分析Tableau平臺、R語言關聯分析和主題詞分詞技術等定量分析方法,探索與分析基于學科特性的借閱規律和主題詞演變規律,從而更為精準地為高校圖書館的新書采編、典藏優化和學科服務提供決策支撐,力求形成系統性把握圖書館在教學與科研的紙質資源保障特征。
確立以上實證思想后,本文重點分析:1)圖書借閱的潛在聯系。讀者在借閱圖書時,是否與其學科和學習階段相關聯,能否根據當前所學的專業進行特定分類號內的圖書選擇,這些圖書之間是否存在一定的關聯;2)根據已借閱圖書的主題詞和圖書題名分詞后的匯聚分布情況。詳細的實證分析框架如圖1所示。
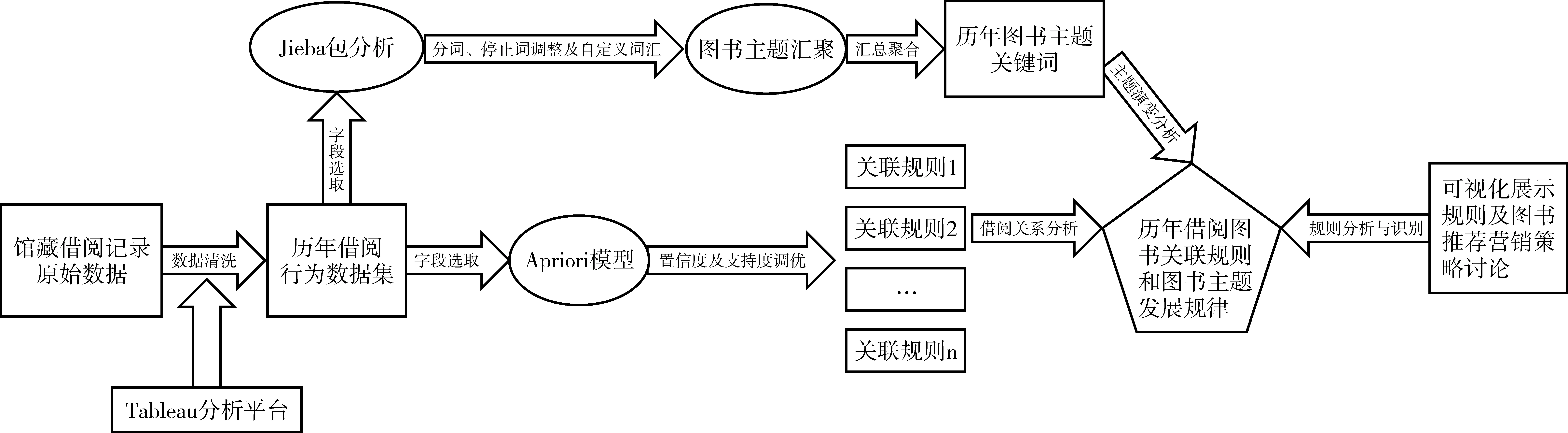
圖1 基于學科特性的高校圖書館借閱行為分析框架
3.2 關聯分析
無論是館藏紙質圖書,還是電子圖書,圖書的流通和檢索獲取都存在著與商品銷售相似的關聯特性,圖書館的管理者都期望從內外在因素探索圖書在流通時的關聯,從而挖掘出圖書之間的前后借閱關系,積累讀者借閱行為的規則庫和知識庫,提升圖書館個性化服務的精確度。關聯分析一般被用于挖掘隱藏在大型數據集中的有意義聯系,所獲取的結果采用關聯規則或者頻繁項集表示。圖書借閱前后時序的關聯挖掘與分析,目前較為典型的是Apriori算法。最為經典的應用當屬沃爾瑪公司的“啤酒、尿布”購物籃分析,目前廣泛應用于商品購物籃數據、生物信息學、醫學診斷和網站挖掘等科學數據分析領域。通過數據集挖掘獲取的關聯規則是否有效,一般采用它的支持度、置信度和提升度三個指標度量。
支持度是關聯規則的重要度量指標,因為支持度很低的規則可能只是偶然出現,低支持度的規則多半也是無意義的。因此,支持度通常用來刪去那些無意義的規則。置信度是通過規則進行推理具有可靠性。對于給定的規則X→Y,置信度越高,Y在包含X的事物中出現的可能性就越大。即Y在給定X下的條件概率P(Y|X)越大。借鑒Apriori算法思想對于支持度和置信度的定義,本文根據圖書館實際借閱情況作出相應的定義:支持度是指讀者借閱的圖書集合中,某個項集出現的百分比;與商品關聯分析不同的是,商品領域的“副本量”較大,而高校圖書館則存在圖書復本較少的情況。因此,圖書借閱關聯分析時將讀者該年度的所有圖書借閱記錄合并視為一個集合。置信度是指獲取的關聯規則X→Y中,項集{X,Y}同時出現的次數占項集{X}出現次數的比例。可理解為讀者借閱圖書X的情況下,后續借閱Y的概率。為有效衡量項集{X}和項集{Y}的獨立性,關聯分析中設立了提升度(lift)指標。提升度就是在借閱圖書X這個條件下借閱圖書Y的可能性與沒有這個條件下借閱圖書B的可能性之比。
考慮實際的圖書借閱情境,一方面,圖書借閱無法類似于貨架上的商品售賣,“復本量”保障供應充足。另一方面,讀者借閱圖書基于學科專業學習需要、復習迎考、各類專業資質認證和閱讀暢銷圖書等因素,存在集中借閱復本量不足的某種分類號圖書,這將無法獲取讀者實際的圖書需求,進而導致關聯分析無法采用商業領域的購物籃分析方式。本文將采用基于時序的關聯分析方法,借助R語言里的arules數據包合理調整算法中的支持度(support)、置信度(confidence)和提高度(lift)指標,挖掘適宜于圖書館業務實踐需求的關聯規則。
3.3 主題詞文本挖掘方法
為更詳細地掌握基于學科特性的讀者借閱行為,透過圖書主題詞分類與題名信息掌握和挖掘讀者借閱圖書的主題詞分布情況,除了統計被借閱圖書的分類主題詞,還采用文本挖掘技術對圖書借閱歷史中的圖書題名分詞處理,可以更為精細地匯聚產生某一個時段集中借閱的圖書種類和借閱熱點,從而有利于新書采購策略調整和館藏借閱服務的精準化。當前文本分詞工具有很多種,Jieba分詞是中文自然語言分詞較為常用的一種。它采用了動態規劃查找最大概率路徑,找出基于詞頻的最大切分組合,分詞準確度高[13]。支持精確、全模式和搜索引擎三種分詞模式。Jieba在R語言平臺上有專門的軟件包JiebaR,可采用自定義字典和函數調用方式對圖書主題詞分詞,從而實現主題詞集中匯聚展示。
4 實證分析
4.1 數據集獲取及行為數據概覽
借助Tableau平臺,通過數據庫接口從館藏自動化系統選取采集計算機學院等6年來所有有效讀者的借閱歷史記錄,字段涵蓋讀者證號、借閱日期、借閱圖書題名、索書號、借閱次數等字段。基于前述,以計算機學院為例闡述本文實證分析過程,獲取的計算機學院借閱記錄共包含 125 180 條。刪除字段缺失數據792條,有效數據為 124 388 條。按照自然年在Tableau平臺繪制借閱歷史曲線,如圖2所示。
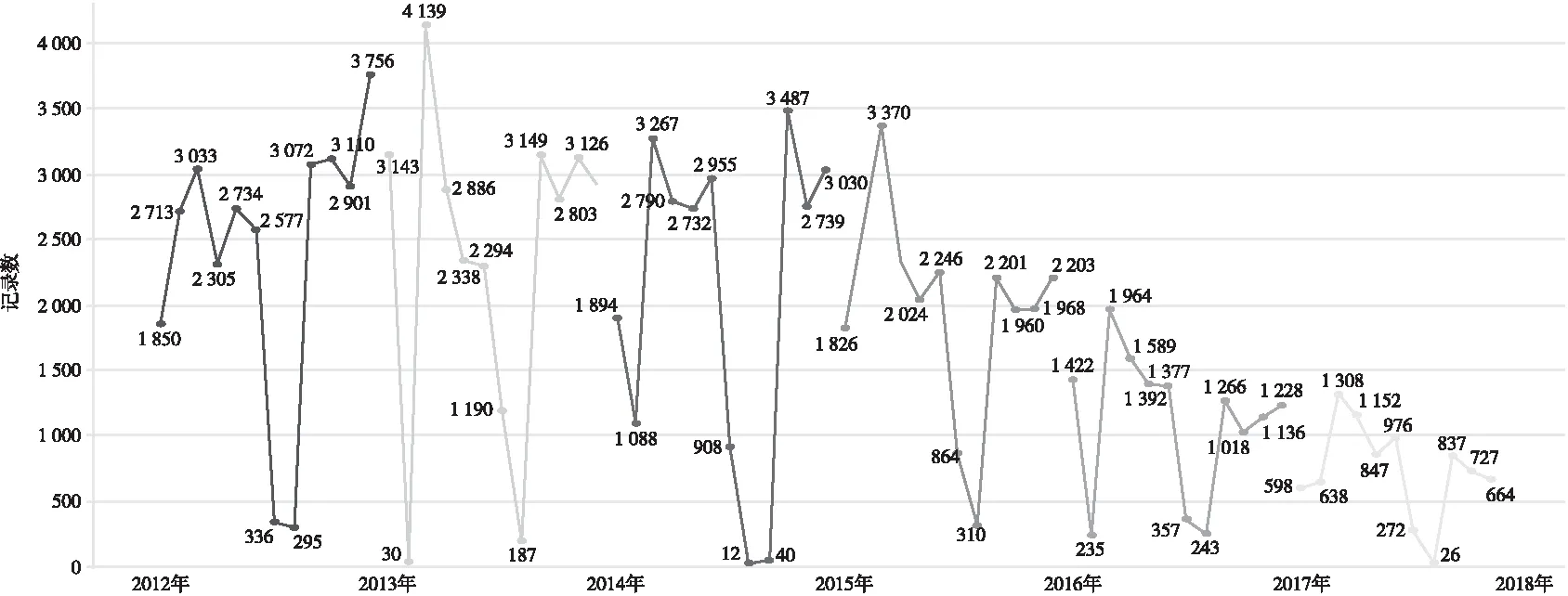
圖2 計算機學院讀者2012—2017年每月借閱圖書統計
從圖2可以看出,計算機學院讀者的年度借閱數量呈現逐年下降趨勢,每年的借閱行為曲線呈現出明顯的季節性變化,這與該專業讀者的高校專業學習階段特征較為符合。通過Tableau平臺的數據透視功能,以每年3月的借閱高點進行對比發現,該月都是年度借閱高峰,從匯聚的主題詞來看,這與高校計算機專業讀者的學習階段相匹配:畢業論文、專業方向學習和考級準備息息相關。
2012—2017年,計算機學院的讀者共借閱 23 236 種圖書,生均借閱19.6本,最高為263本。從性別差異對比看,男性讀者比女性讀者多借閱了 7 000 多次。統計每個借閱時段的借閱次數,該學院讀者傾向于在早上9點—11點借閱圖書。從分位數分布情況可以看出,計算機學院讀者的借閱圖書記錄中,25%的借閱包含了4本或者更少的圖書,大約50%為12本,詳見表1。

表1 計算機學院讀者借閱記錄的分位數特征
在Tableau平臺上匯聚圖書分類號,如圖3所示。計算機學院借閱圖書依次排序的前10種是I267/SM(三毛小說系列)、TP312C/WX11(C#語言類)、TP312C/TH17(C語言類)、TP312C/MR11(C、C++和C#等編程類)、TP312JA/WG8(各類軟件開發案例類)、TP312JA/LZ23(JAVA編程系列)、I313.45/DY7(東野圭吾著作系列)、I313.45/CS3(村上春樹著作系列)、O13/TJ4(高等數學系列)和TP312C/ZL(C++語言類)。此10種集中反映了計算機學院讀者偏向于借閱編程類圖書、流行小說和軟件項目案例等,也說明紙質圖書依然保障了高校讀者在專業課程學習的文獻需求。高校圖書館可以增加此類圖書的復本數、推廣相關的專題數據庫資源和做好經典圖書的閱讀推廣活動。
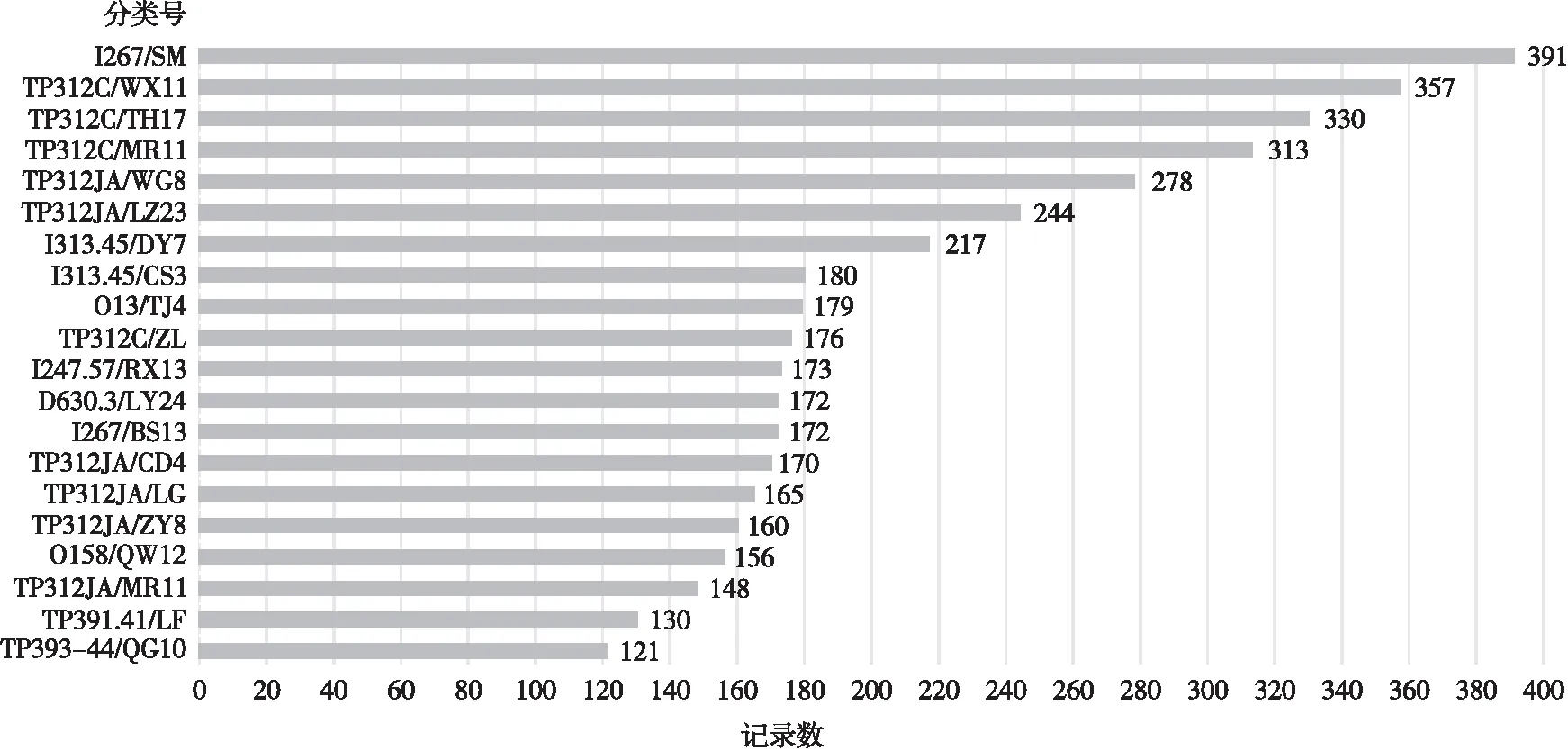
圖3 計算機學院讀者借閱圖書分類號統計(2012—2017)
4.2 Apriori關聯分析
4.2.1 數據轉換。基于項集間的借閱時序關系,在R語言平臺對獲取的數據按照讀者借閱時間進行排列。部分數據樣式見圖4。
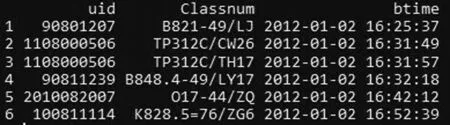
圖4 基于時間序列的部分讀者借閱數據
因每行借閱記錄記載讀者一次借閱圖書時,讀者的ID、圖書題名、分類號和借閱時間等字段。按照關聯分析的數據格式要求,需要轉換為項集,如項集{TP393.11,TP397.12}表示某位讀者的圖書借閱集合。為此,本文按照讀者ID、借閱時間對數據集重新排序,然后通過函數轉換為Apriori算法可處理的0-1稀疏矩陣。去除借閱時間的字段后,將讀者的ID轉換為因子型變量,采用R語言split函數進行數值處理,共獲取計算機學院 2 797 位讀者按照時序關系排列的圖書借閱路徑。此時調用as函數將其轉換為transactions形式的稀疏矩陣。通過上述數據處理方式分別對其余學院借閱數據進行數據清洗,得到匯總數據如圖5所示。
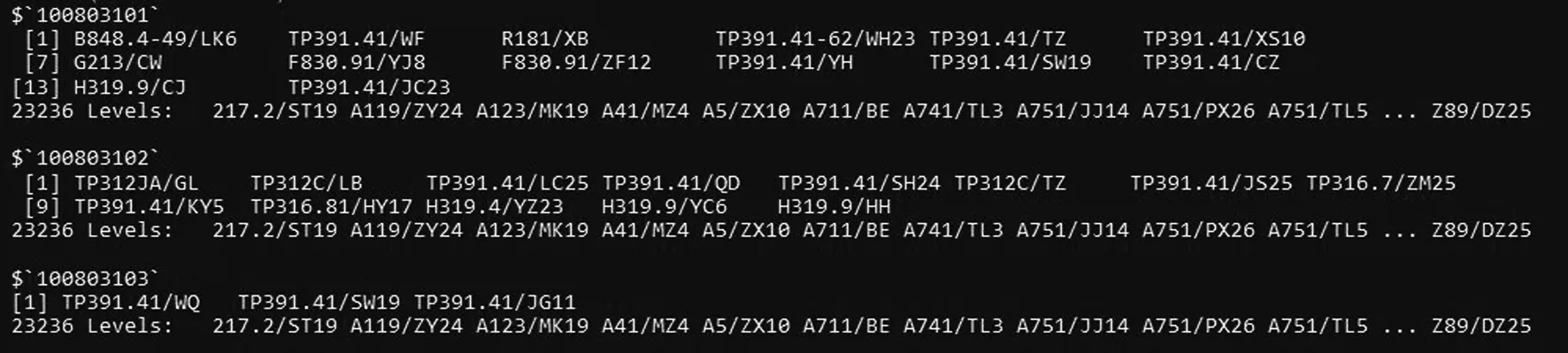
圖5 部分讀者圖書借閱路徑數據集
4.2.2 關聯分析參數討論與調優。關聯規則獲取是否有效取決于Apriori算法的支持度、置信度和提升度等參數值。考慮到商業領域的購物籃關聯分析,其分析對象取值的數據粒度為商品種類。而對于圖書而言,高校館藏自動化系統的分類號的數據粒度更為精細。例如,以I267/SM為例,其表示當代作品三毛著作系列,館藏查詢對應100多本圖書,這說明此粒度的圖書類別已能明確表示讀者的借閱行為。故此,本文對分類號不作合并歸類處理。
關聯分析算法中參數默認值設定支持度為0.1,置信度為0.8。首次運行算法無法獲取有效關聯規則。以前述獲取的計算機學院讀者借閱數據來看,每位讀者平均年借閱2種分類號圖書,圖書借閱關聯度顯然不及購物籃分析中的商品關聯結果。結合圖5所示的讀者借閱圖書分類號集合,由于學科、專業和課程等因素影響著讀者的借閱行為和傾向,導致分類號分布集中在計算機相關學科領域,而其他學科分類號的分布極為稀疏。故此,采用arules模型運算和分析圖書借閱關聯時,需要多次動態調整支持度和置信度的參數。
4.2.3 關聯結果獲取與分析。在R語言分析平臺采用arules函數分析包對轉換后的借閱記錄數據進行多次參數調整后,支持度確立為0.0025,置信度為0.5,項集設置為至少2種,從而獲取了13條關聯規則。如圖6所示,獲取的關聯規則支持度區間為[0.025,0.004],提升度區間為[11.8,195.8]。
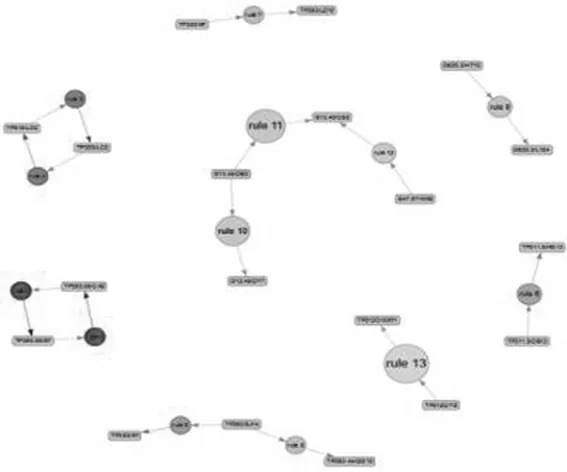
對于關聯規則的識別與區分,一般可將其歸納為可操作規則、平凡規則和費解規則等三類[14]。
規則1和規則2屬于可操作性規則,借閱了TP393.08/XY分類號的讀者,因專業課程的技術實戰需要,也將借閱TP393.08/CX2,這兩個分類號無前后優先關系。規則3與規則4的關聯規律也與此相同,其中的分類號對應計算機專業考研書目。因此,從學科的文獻保障角度出發,圖書館可增加此分類號的復本數,并調整此類館藏比例,提升圖書借閱量。
規則5和規則8以分類號TP393/SJ14為左關聯點,規則5屬于叢書上下冊關系,規則8屬于輔導解析的圖書關聯,兩者均屬于平凡規則類別,也同屬于高校讀者認證考試的必備書目。從高校圖書館文獻保障的需求出發,可以通過在圖書采編業務上增加復本來加強館藏建設,滿足高校讀者在專業技術認證備考的圖書借閱需求。
規則6、規則7、規則9和規則13屬于有前后順序的關聯,4個規則涉及了計算機專業的網絡工程師與軟件設計師的認證考試、公務員招考和畢業設計課程。從數據集抽取查看,此類圖書借閱群體集中于高校大四階段讀者,而且規則13涉及的畢業設計課程圖書關聯的支持度最高。結合規則的可信度和提升度,圖書館可在保障一定比例的圖書復本前提下,從數據庫資源、視頻課程和電子圖書等引入相應的數字資源予以保障,提高此類文獻資源的可獲得性與可用性,以及針對高年級本科教學的文獻保障能力。
規則10、規則11和規則12屬于費解規則,規則10和規則11反映了讀者在閱讀渡邊淳一類著作以后,其后續0.3%的單次借閱中,各有50%的概率借閱了村上春樹或者東野圭吾的著作。規則12則反映了讀者先借閱王小波的著作后也同時會借閱村上春樹的著作。這說明該學院讀者傾向于閱讀人性、偵探和懸疑類系列小說。
4.3 主題詞分析
在Tableau平臺上匯總借閱圖書的主題詞,連接圖書館自動化系統關聯獲取本地化主題詞表作為待分析的圖書主題詞。為更精準地揭示這些主題詞是否反映了周期性的借閱規律,按照自然年依次統計每個主題詞的頻次。通過R語言的wordcloud2詞云工具,依次按照自然年讀入主題詞和頻次字段,并按照頻次降序排列,調用wordcloud2函數依次匯聚,最終結果如圖7、表2所示。“長篇小說”“英語”“C語言”“散文”“JAVA語言”“短篇小說”和“程序設計”等主題詞的圖書一直保持前列,但從圖5詞云的字體相對大小,結合相鄰頻次計算百分比差異可以看出,上述高頻的主題詞圖書借閱率經歷2013年、2014年的增長后一直下滑。故此,這些借閱頻次較高的主題詞,并非讀者不再借閱,而是全媒體圖書資源的便捷讓讀者有更多渠道閱讀,這足以反映紙質館藏和電子館藏優化調整的重點。與此同時,對2017年的百分比差異數據排序,持續增長的主題詞為“叔本華”“python”“JBUILDER”“古典文學”“古典小說”“章回小說”“軟件工程”“職業選擇”和“講史小說”等。這些主題詞可以作為新書采訪、館藏調整優化和學科服務的決策依據。
將題名和圖書被借閱時間兩個字段抽取并導入R語言平臺上,調用jiebaR軟件包,導入學科相關領域的細胞詞庫和默認的停止詞作為分詞引擎參數對2012年的題名進行分詞切割,共獲取圖書主題詞 8 809 個。通過對停止詞的多次篩選和調整,增加自定義詞典和停用詞,重新獲取有效主題詞 5 543 個。挑選前200個主題詞通過wordcloud2模型包進行匯聚,按照此方法依次對后續5個學年的圖書借閱記錄進行文本挖掘,挖掘結果中,字體大小與主題詞出現頻次成正比,如圖8所示。

圖7 計算機學院讀者歷年借閱圖書的主題詞匯聚
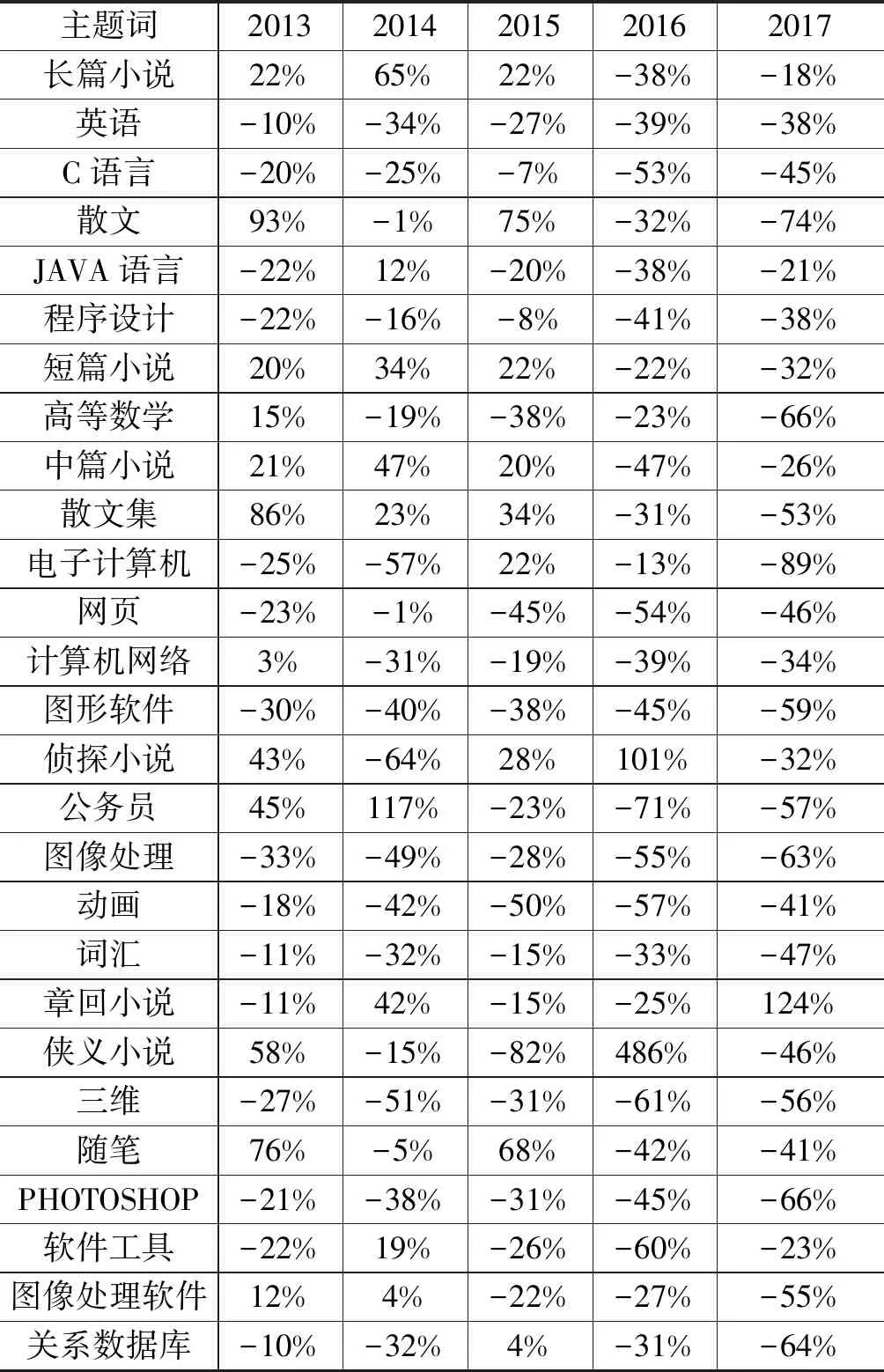
表2 計算機學院讀者歷年借閱圖書的頻次統計
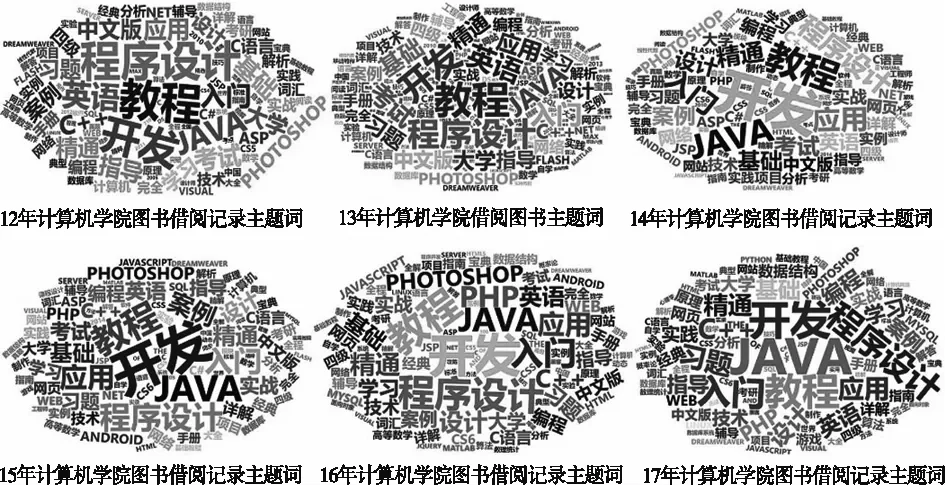
圖8 計算機學院2012—2017年圖書借閱
觀察分析圖8的標簽云,字體逐步變化到最大的關鍵詞“JAVA”,說明該編程語言是我校計算機學院讀者最常借閱的圖書書籍主題。
其次,出現字體較大且保持穩定的主題詞是“教程”“程序設計”“開發”“案例”和“入門”等。通過查詢與這些主題詞共現的圖書名,基本涵蓋的是編程開發類(如“C”“C++”“JAVA”“PHP”“ANDROID”)、圖形圖像類(如“PHOTOSHOP”“FLASH”“3DS MAX”“CORELDRAW”“ILLUSTRATOR”)和專業軟件類(如“MATLAB”“AUTOCAD”“MYSQL”“SQL SERVER”)等。同時,也涵蓋了英語、數學、物理、計算機網絡和數據結構等基礎學科專業。
部分主題詞如“PHP”“HTML5”“MYSQL”“PYTHON”“CSS3”等當前技術發展熱點相關圖書的借閱量已經逐步上升,基于閩南師范大學計算機學科專業培養方向調整和學生對于未來崗位技能的知識需求,與此類相關的主題圖書是今后該校圖書館館藏采訪與文獻保障建設需要補充的方向。
將以上部分標簽主題詞進行內部連接,出現頻率保持高位的“應用”“精通”和“設計”等主題詞,側面說明了計算機學院的讀者在專業學習的定位明確,眾多計算機領域專業技能學習的圖書借閱率所占比例較高。圖書館較好地匹配了高校讀者大學四年專業學習的需求和技能層次發展。
5 結語與展望
基于讀者借閱行為的用戶行為分析,是通過Tableau平臺、R語言Apriori函數包、Jieba分詞包和wordcloud2詞云匯聚等挖掘方法從讀者借閱行為數據的分類號、頻次、主題詞、題名和借閱時間等字段入手,較為全面地掌握高校圖書館計算機專業讀者借閱行為的季節性變化,并根據圖書館藏結構和讀者借閱圖書的實際情境,調整關聯規則置信度、支持度和提升度的參數,從而獲取匹配業務實踐且具有時序模式的關聯規則,結合讀者的學科特性和專業方向詳細闡述3類關聯規則,以期更為精準化的輔助圖書館決策。從規范化的圖書主題詞按照借閱頻次排序和匯聚詞云結果來看,揭示的主題詞分布結果有效反映了讀者借閱的變化趨勢和今后的借閱上升區域,可以將其作為新書采訪、館藏調整優化和學科服務的決策依據。基于圖書題名的自然語言分詞和標簽云匯聚,從較為細粒度的角度挖掘出基于學科特性的讀者借閱行為,以數據可視化展示計算機讀者的圖書借閱熱點變化。這些分析能夠為高校圖書館調整館藏結構、提升新書采訪精準化和拓展有針對性的閱讀推廣提供非常有益的參考依據。
(1)以點帶面,分析與挖掘其他院系專業的讀者借閱行為數據,可以精準化推動大眾化閱讀推廣工作。文章獲取的數據顯示,計算機學院讀者借閱“長篇小說”常年排列首位,在主題詞匯聚中還發現“古典小說”“章回小說”“短篇小說”和“散文”均為該學科特性讀者借閱,但在關聯規則挖掘中也發現傾向于某一類系列小說,因此,需要圖書館員加強閱讀多樣化引導、經典文學宣傳推廣等工作,拓寬讀者的閱讀視野。
(2)進一步加強熱門圖書以及技能認證和經典文學類圖書的推介。加強紙質館藏元數據與電子資源的元數據匹配,提高電子圖書、專業輔導視頻和技能認證考試的使用頻率,實現更為快速的文獻保障效率,完善高校圖書館全媒體資源的文獻資源保障機制。
(3)更為精準地拓展有針對性的嵌入式學科服務。以文章分析的計算機專業為例,編程語言學習、項目案例開發和畢業設計等階段的文獻保障是每年較為穩定的讀者借閱行為,面對借閱率下滑,高校圖書館應深化“紙電同步”的一體化館藏體系,探索數字閱讀和專業閱讀的讀者行為數據積累,不斷繪制和完善高校學科專業視角的讀者借閱行為用戶畫像,從而更為精準地提升在教學與科研中的文獻保障能力。
猜你喜歡
小獼猴智力畫刊(2022年3期)2022-03-29 01:09:42
當代陜西(2021年17期)2021-11-06 03:21:36
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:26:14
小太陽畫報(2018年1期)2018-05-14 17:19:25
學苑創造·A版(2018年11期)2018-02-01 06:29:20
Coco薇(2017年11期)2018-01-03 20:59:57
讀者(2017年5期)2017-02-15 18:04:18
暨南學報(哲學社會科學版)(2016年9期)2017-01-15 13:52:02
少年博覽·小學低年級(2016年10期)2016-11-24 06:48:23
漫畫月刊·炫版(2015年4期)2015-05-27 07:52:10
