基于DDQN的運載火箭姿態控制器參數設計
2020-09-03 10:45:58柳嘉潤駱無意
航天控制 2020年4期
黃 旭 柳嘉潤 駱無意
1.北京航天自動控制研究所,北京100854 2.宇航智能控制技術國家級重點實驗室,北京100854
0 引言
隨著現代控制理論和智能控制方法的發展,一些新的控制方法,如變結構滑模控制和模糊控制等被引入到運載火箭姿態控制中。但由于箭載計算機計算能力限制、工程化困難等問題,大多數火箭姿態控制設計還是依賴于古典控制理論中的頻域設計方法[1]。工程中一般在建立運載火箭姿態動力學模型的基礎上,通過不斷調節自動穩定裝置的傳遞系數、校正網絡參數和分析系統相關性能的方式,完成整個飛行時段的姿態控制設計并開展仿真驗證[2]。這種方法可操作性強,但設計效率依賴設計者的經驗,存在設計周期長和通用性差等缺點,在工程中具有一定的局限性。
人類設計師利用頻域設計方法進行火箭姿態控制系統設計的過程本質上是一個序列決策問題。而人工智能(Artificial Intelligence,AI)領域中的深度強化學習(Deep Reinforcement Learning,DRL)算法則有效實現了序列決策的過程。2016年,以DRL算法作為核心技術之一的 AlphaGo[3]智能體在圍棋比賽中擊敗了人類頂尖職業棋手李世石,使得DRL算法被研究界普遍認可并深入研究。近幾年來,DRL在機器人技術[4]、智能駕駛[5]、電子設計[6]等諸多領域得到了廣泛的推廣和研究。
DRL從字面意思就是深度學習和強化學習的結合。深度學習起源于人工神經網絡,具有很強的特征表征能力;強化學習則受到生物能夠有效適應環境的啟發,以試錯的機制與環境進行交互,通過最大化累積獎賞的方式來學習到最優策略。DRL有效地吸收了兩者的優點,將抽象思維的表征能力和決策能力集合于一體。而工程中火箭姿態控制器參數設計規則相對明確且設計過程實際上就是一個決策過程,所以可以進行基于DRL算法進行智能體離線設計控制器參數方面的研究探索。
航天控制系統正在走向智能化,通過智能技術的賦能可以使航天裝備變得更聰明[7]。如果可以成功使用智能體代替工程設計人員進行控制器參數設計,不僅可以提高設計效率、縮短設計時間,所得結果也可以給工程設計人員提供一定的參考,為人工智能新方法在航天領域的應用提供新思路。
1 姿控系統頻域分析模型
以三通道交聯較小、各通道控制器可獨立設計的火箭模型為例。考慮箭體的彈性和推進劑晃動,某特征秒的箭體俯仰通道運動方程如下[2]:
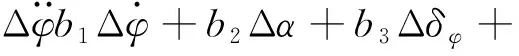
(1)
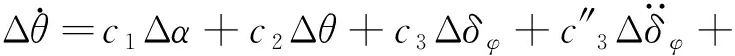
(2)
Δφ=Δα+Δθ
(3)
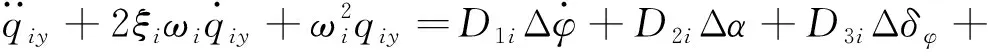
(4)
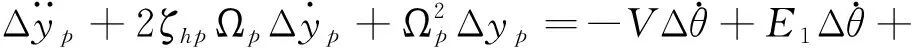
(5)
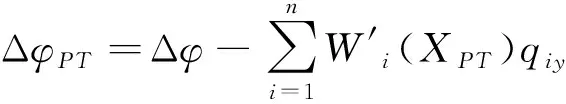
(6)
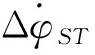
1.1 傳遞函數求解
根據式(1)~(6)選取合適的狀態變量建立對應的狀態空間方程:
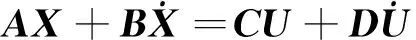
(7)

要進行火箭姿態控制器設計首先要建立姿控系統的頻域分析模型。控制策略選擇工程上常用的基于“小擾動線性化”的增益預置法。本文僅考慮俯仰通道,整個姿控系統閉環回路的結構如圖1所示[9]。
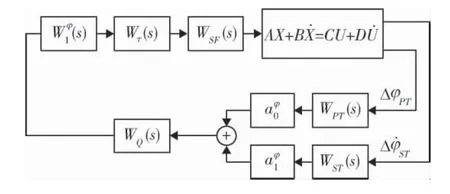
圖1 俯仰通道姿控系統閉環回路結構圖
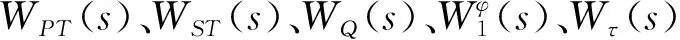
1.2 控制器參數選擇
設計參數包括靜態增益系數、動態增益系數以及校正網絡結構參數。借鑒傳統姿態控制器離線設計過程,設計出的靜態增益系數在飛行過程中一般是以插值表的形式根據時間插值得出。可選擇有代表性的特征秒點,并設計這些特征點上的靜態增益系數,飛行中靜態增益系數按時間插值得出。而性能較好的校正網絡可以使系統保留一定的裕度,并在最差的飛行環境中保持穩定。文中的校正網絡分子和分母均包含3個二階環節。見式(8)。
(8)
(9)
一共有14個待設計參數。
2 DRL算法選擇與MDP設計
人類工程師在進行姿態控制器設計時,通過觀察分析系統開環傳遞函數的bode圖調節相關設計參數,不斷迭代最終得出相應的
參數。調參過程可以理解為一個離散動作過程,本文選擇基于值函數的深度強化學習算法:DDQN(Double Deep Q Network)[10]作為智能體訓練算法。
2.1 本問題的馬爾科夫決策過程描述
強化學習本質上是解決一個馬爾科夫決策過程(Markov Decision Process,MDP)。根據1.2節選擇的待設計參數和DDQN相關特點,結合運載火箭姿態控制器設計過程建立對應的MDP模型:
M=(S,A,P,R,γ)
(10)
a)狀態集S={s1,s2,s3,…}:狀態空間由各個特征秒點的的各實際裕度張成:
(11)
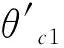
b)動作集A={a1,a2,a3,…}。智能體在調參中對各參數在一定范圍內進行增減,為了縮減智能體動作空間的維度,智能體每一步只調節一個參數值。待設計參數有14個,則智能體的動作空間中一共有28種動作。
(12)
c)狀態轉移概率P:在本文的研究內容中,下一個狀態可以根據頻域分析計算獲得;
d)立即回報r:立即回報的設置是深度強化學習應用中非常關鍵的部分,它的設置將很大程度上影響到算法的訓練效果,應用場景目標越明確,立即回報的設計越簡單,訓練效果越好。這里給出本文的立即回報設置:
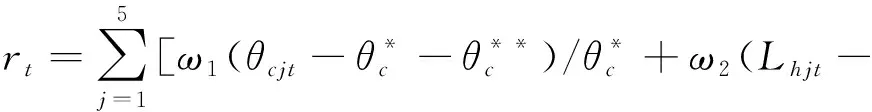
(13)
單星號上標代表對應裕度的指標值。雙星號上標代表懲罰因子,即對應實際裕度不滿足指標值時,將減去一個定值以對智能體進行懲罰。5個特征秒點的設計指標值和懲罰因子一致。ωi代表各個裕度的權重。
當設計參數超界或者系統不穩定時:
rt=-1
(14)
e)折扣因子γ:用來計算累計回報,取值在[0,1]之間,取值根據實驗時具體情況進行調節。本文中取0.95。
2.2 本文的DDQN算法訓練流程
DDQN是經典深度強化學習算法DQN(Deep Q Network)[11]的改進算法,DDQN一定程度上解決了DQN中的過估計問題,提高了算法的穩定性[12]。
結合本文設計的MDP模型,給出具體智能體訓練算法流程。
首先初始化記憶回放單元D和兩個網絡的網絡參數θ和θ-,開始進行實驗。每次實驗智能體最多可進行1500次調參。每次調參后,頻域分析得到的裕度值作為狀態st經過式(16)預處理,得到φt,將其作為當前值網絡的輸入,輸出各動作的狀態行為值,使用ε-greedy算法選擇動作at并執行,得到下一個狀態st+1和立即回報rt+1,將(φt,at,rt+1,φt+1)存儲到記憶回放單元中。每進行一定次數的調參,在記憶回放單元中采集一定數量的樣本,按目標函數式(15)進行梯度下降,求解當前值網絡參數,Qπ代表當前策略下的對應狀態和動作的值函數,并每隔一定時間將當前值網絡參數賦值給目標值網絡,如此不斷迭代完成智能體訓練。當φj+1為本次實驗最終狀態時,yj的值為rj+1。
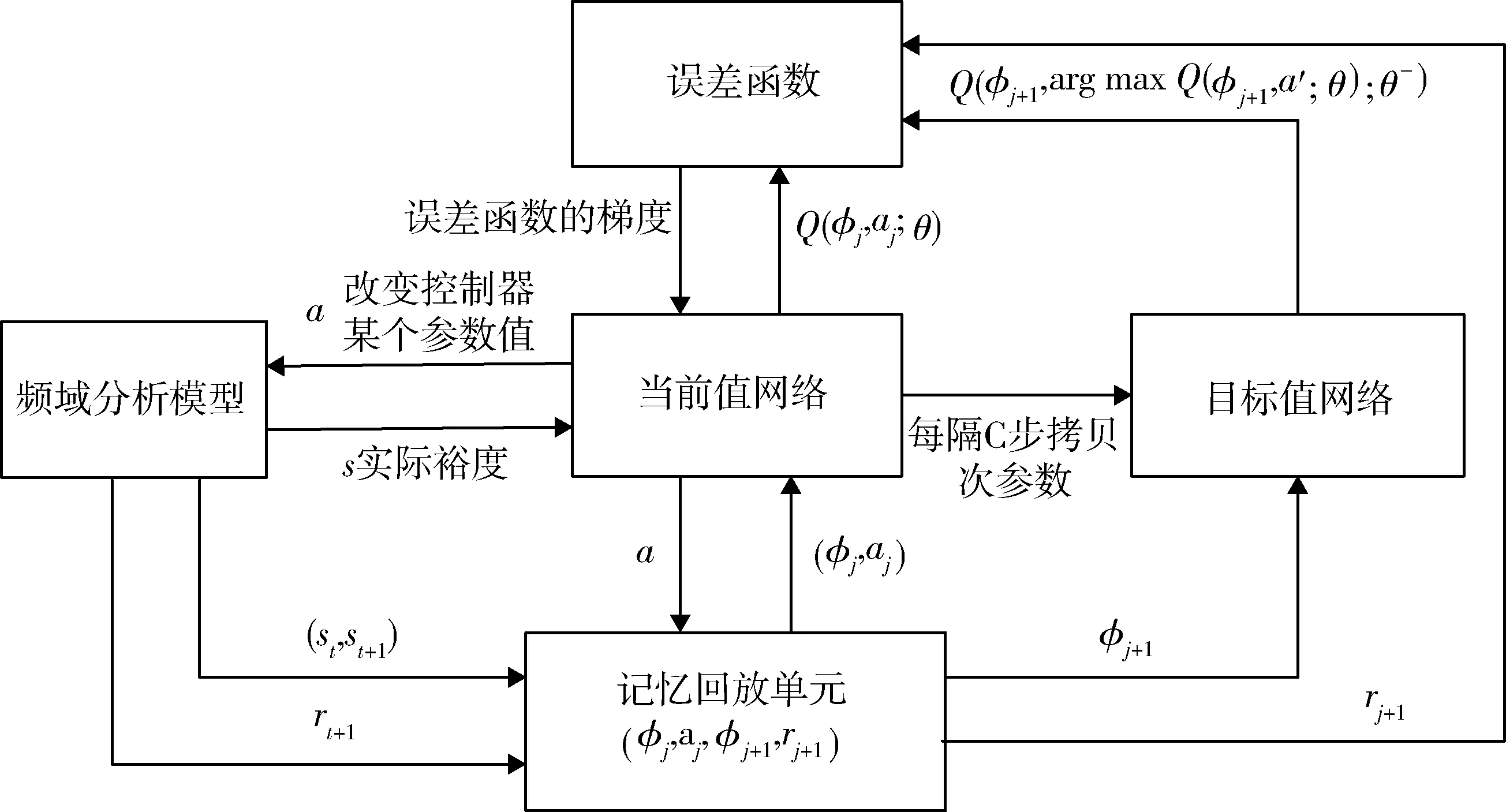
圖2 智能體訓練算法流程圖
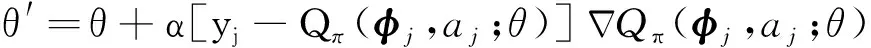
(15)
對狀態預處理形式如式(16)所示。s*代表對應裕度的指標。
(16)
3 智能體訓練與前向參數設計
綜合1、2節,進行智能體的訓練和前向參數設計。
3.1 智能體訓練
根據前面章節的內容設置相關網絡參數和訓練超參數開始進行智能體的訓練。當前值網絡和目標值網絡的結構一致,均使用單隱層BP神經網絡,激活函數選取tanh。單次實驗中,記憶回放單元存儲數量設置為300,智能體每進行100次調參,在記憶回放單元中隨機抽取50個樣本,按式(15)進行梯度下降以更新當前值網絡參數。每進行200次調參,目標值網絡的網絡參數對當前值網絡參數進行一次拷貝,以減小兩個網絡的相關性,從而提升網絡訓練效率。設置ε-greedy算法的ε值為0.85以提高智能體的探索能力,即0.85的概率選擇狀態行為值最大的那個動作執行,否則隨機選取一個動作執行。
當網絡在一定程度上收斂時結束智能體訓練。訓練累計誤差結果如圖3所示。訓練開始時誤差較大,累計變化的斜率很大,隨著訓練次數的增多,誤差減小,斜率放緩。
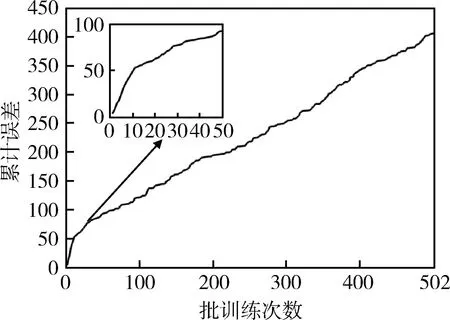
圖3 累計誤差變化隨訓練次數變化曲線
每次實驗的累計回報隨訓練次數的變化曲線如圖4所示,經過一定量的實驗后單次實驗的累計回報能相對穩定在20左右。由于智能體的探索以及其他問題,累計回報存在少量波動,但基本保持一個上升并收斂的趨勢。
訓練過程的波動有多方面的原因:1)基于值函數方法的強化學習算法存在一定的不穩定性;2)對記憶庫中樣本進行隨機采樣訓練網絡可能會破壞較好的網絡參數,而且智能體訓練過程加入探索一定程度上會影響收斂;3)由于各個裕度之間存在的復雜的交聯也會影響訓練;4)在訓練中超參數和神經網絡結構的設置完全依賴經驗,也是機器學習中一直困擾著研究者們的問題。
由于火箭姿態控制器參數設計沒有嚴格意義上的最優參數集合,所以理論上控制器的可行參數集合有無窮個。訓練的目的就是讓智能體模擬人類設計師的設計過程,在不斷調整參數分析系統性能的過程中,逐漸變得“老道”,從而成為一位優秀的控制器“設計師”。
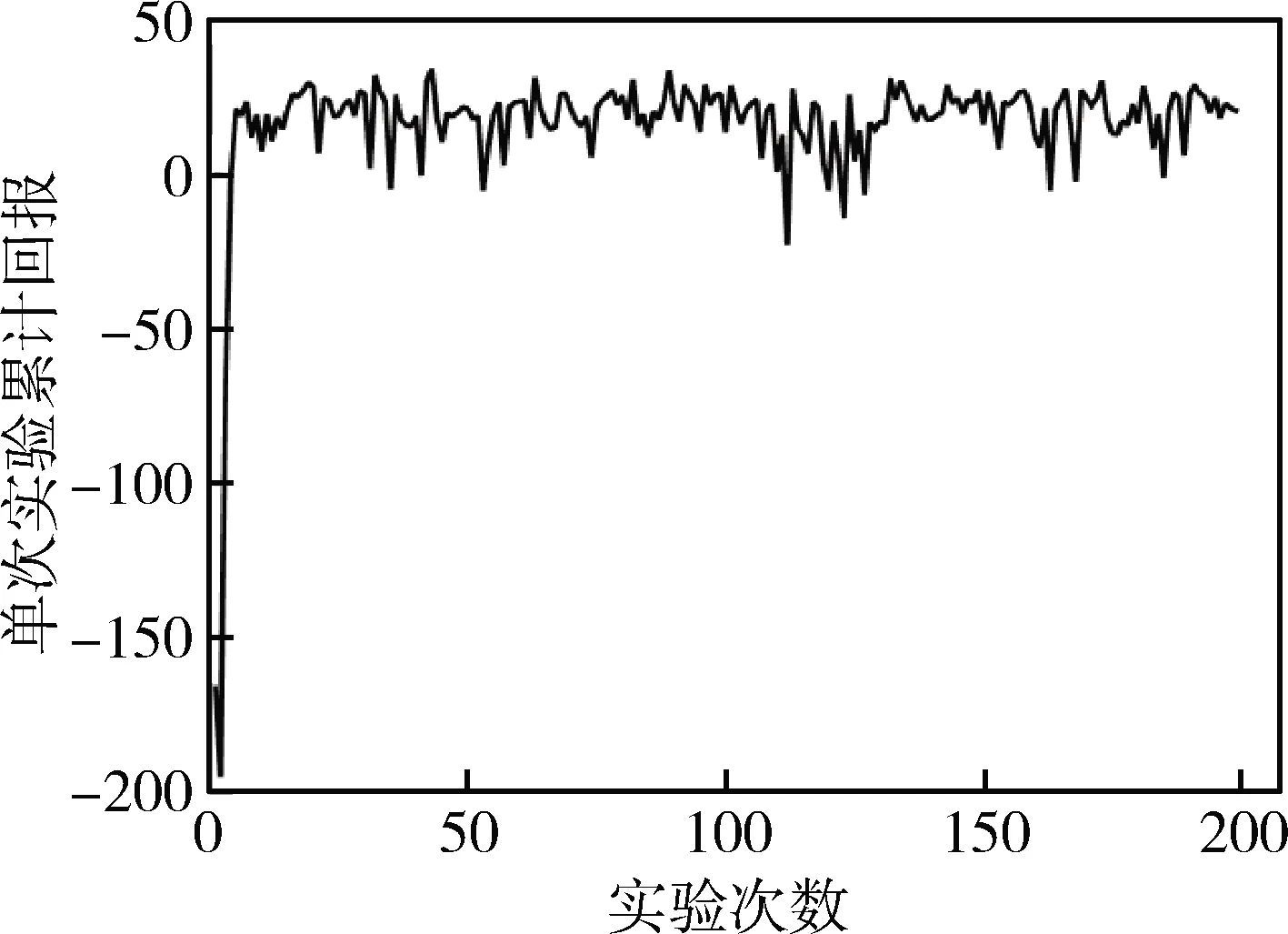
圖4 單次實驗累計回報隨實驗次數變化曲線
3.2 智能體前向測試
為了驗證智能體的調參能力,在一定范圍內隨機初始化控制器參數,使用訓練好的智能體調節參數,觀察調參過程中姿態控制系統綜合性能即單步立即回報值的變化來評價智能體。
在前向測試(圖5)中,對姿態控制系統進行頻域分析后的各個實際裕度值進行預處理后作為狀態,輸入到訓練好的目標值網絡,目標值網絡進行前向計算得到當前狀態對應各個動作的狀態行為值函數,使用ε-greedy算法選擇一個動作執行,不斷迭代直到本次前向測試結束,ε-greedy算法的ε值設置為0.95以作為一個調參干擾加入智能體調參過程。
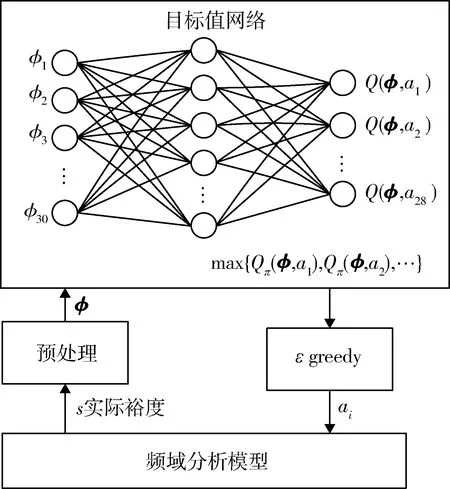
圖5 智能體前向測試流程圖
取一次前向測試實驗的單步立即回報值變化曲線如圖6所示。智能體經過不斷地調節參數使得單步立即回報增大即使姿態控制系統的綜合性能增強,在經過一系列的調參動作后找到了76個可行控制器參數組。可見其擁有一定的調參能力。
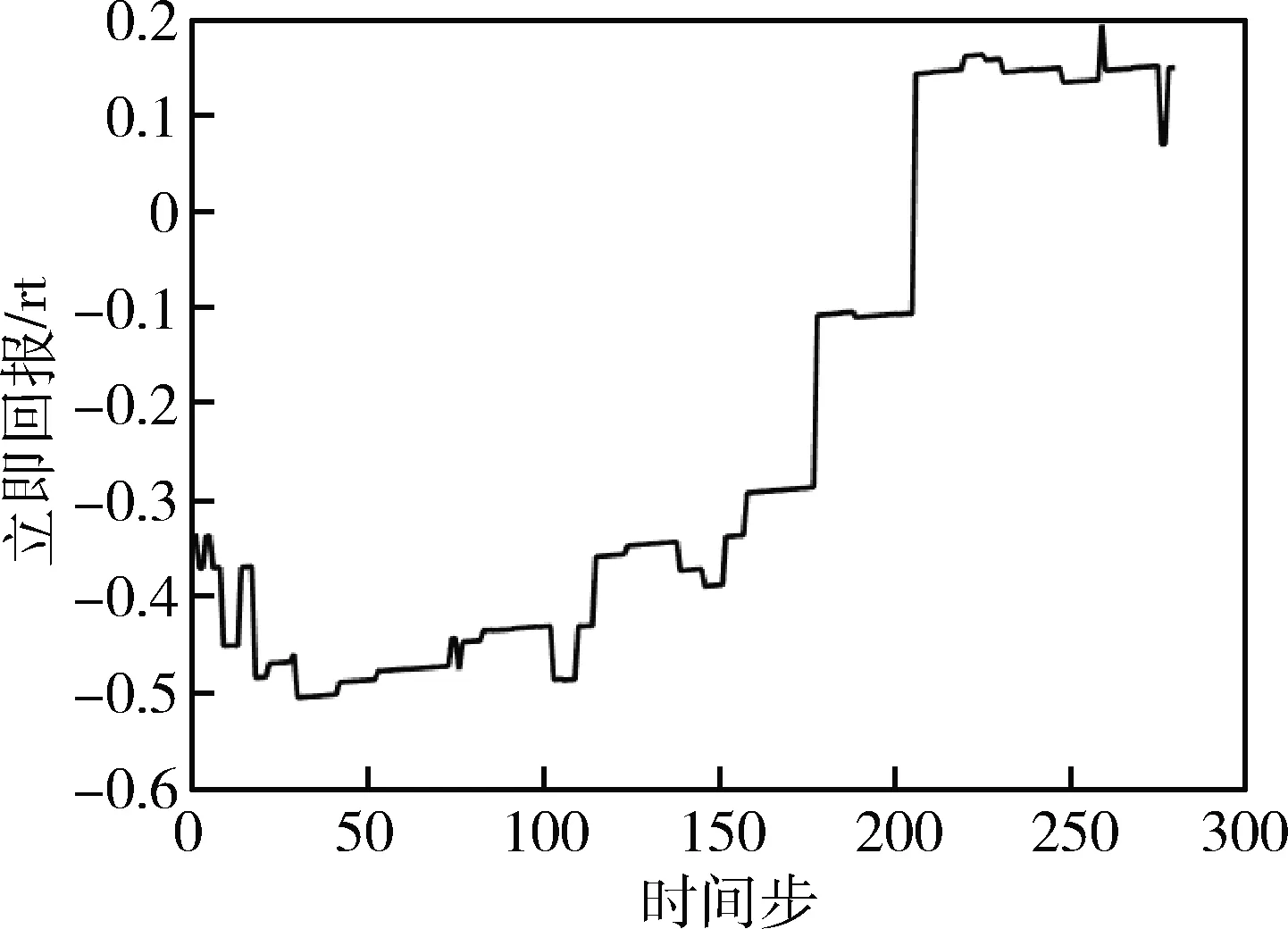
圖6 單次前向測試中立即回報隨時間步變化曲線
選取本次前向測試中回報最大的一組控制器參數組,繪制5個特征秒點的姿態控制系統bode圖(圖7~8)。得到的系統各裕度均符合設計指標并有一定的冗余。設計得到的控制器幅頻特性(圖9)呈現典型的雙漏斗結構。
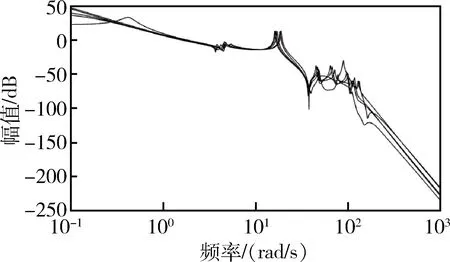
圖7 姿控系統開環幅頻特性曲線
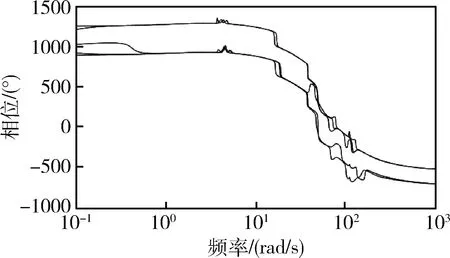
圖8 姿控系統開環相頻特性曲線
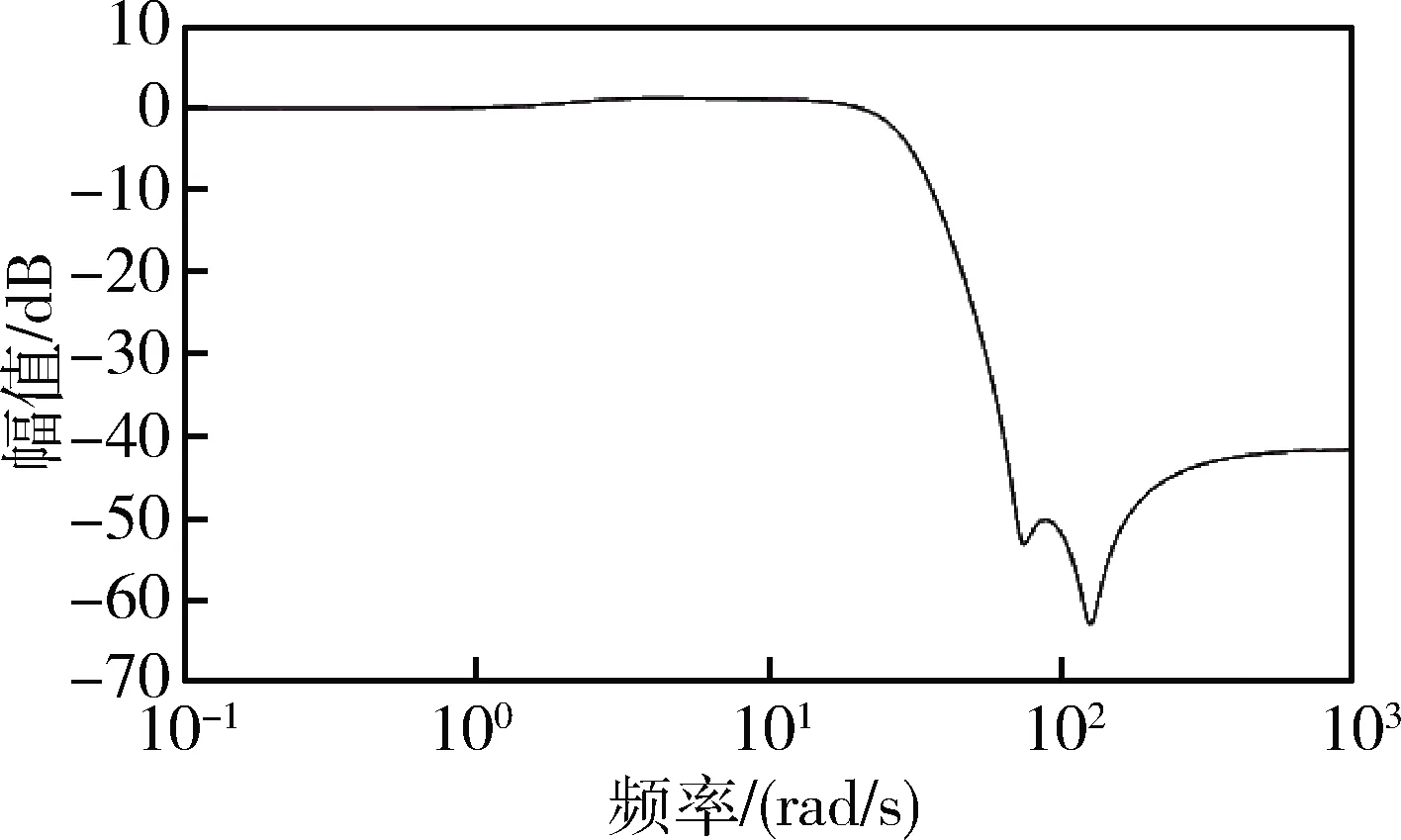
圖9 校正網絡幅頻特性曲線
4 結論與未來展望
智能體的訓練和前向測試的結果表明,該使用智能體代替人工設計姿態控制器參數的思路具有一定的研究價值和潛力。當然也需要在改進強化學習算法、深化神經網絡、設置更加合理的MDP模型等方面繼續努力。
強化學習的優勢在于無過多的先驗知識的智能體能在與環境的不斷交互中學習到一些人工設計的常用經驗,甚至可能發現一些工程師未總結出的經驗。依托當前計算機算力等技術的發展,相信在不久的將來,進行工程設計的智能體也能擁有如Alpha Go和Alpha Zero[13]等智能體一樣強大的決策能力,幫助甚至代替人類工程師進行一些復雜的工程設計。
猜你喜歡
文苑(2018年23期)2018-12-14 01:06:06
文苑(2018年19期)2018-11-09 01:30:14
文苑(2018年17期)2018-11-09 01:29:26
文苑(2018年21期)2018-11-09 01:22:32
藝術啟蒙(2018年7期)2018-08-23 09:14:18
小學生作文(低年級適用)(2018年3期)2018-04-17 00:58:35
海峽姐妹(2017年7期)2017-07-31 19:08:17
少年博覽·小學低年級(2017年4期)2017-06-09 16:22:28
Coco薇(2017年5期)2017-06-05 08:53:16
作文評點報·低幼版(2017年7期)2017-03-11 20:49:41
