多維數據融合的研究生培養質量研究
2020-11-25 05:38:04
科教導刊·電子版 2020年29期
關鍵詞:質量
(浙江工商大學信息化辦公室 浙江·杭州 310018)
0 引言
碩士研究生報名連續五年持續上漲且增幅驚人,自2018年考研人數首次突破200萬之后,2020考研報考人數更是達到了341萬。研究生是教育鏈的最高端,培養的是高科技人才,是技術的創新者、開拓者,是國家的技術棟梁,研究生培養質量關系到國家長遠的發展。因此,形成一套有效的研究生培養質量監控體系是保證研究生培養質量的重要基礎。
目前,研究生培養質量監控體系從時間維度上講政策措施的事后總結比較多,建模預測的比較少。研究范圍上,有些是效仿國外,提出改進措施政策。有些分析國內高校的研究生數據。雖然研究范圍不同,但是大家都有個共同的認識,就是要嚴出。2019年2月26日教育部辦公廳發布《關于進一步規范和加強研究生培養管理的通知》,狠抓學位論文和學位授予管理。在這樣的大背景下,本文通過融合實驗室門禁次數、課程修學及成績、圖書借閱、入學成績、專業、學院、人均導師數、是否調劑、總成績、復試成績、培養方向、學位類型等多維數據,預測研究生學位論文的質量。
1 模型選擇
監控的指標選取原則主要指標的粒度和范圍。
一指標的粒度:因為本文研究的樣本主體是研究生個人,監控指標盡可能的細,比如人均導師數,有的研究是選擇一個學校的人均導師數,本篇文章選取的該學生導師名下的學生人數。二監控指標的范圍盡可能多,包括從入校到畢業整個過程比如初試成績、課程修學及成績、圖書借閱、專業等,后面可以通過算法篩選。
對比了多種算法,類神經網絡算法比較符合這一特點。神經網絡思想是把大量的個體作為訓練樣本,然后生成一個可以通過訓練樣本學習的系統。換句話說,神經網絡使用樣本自動地推斷出變量與目標之間的規則。另外,神經網絡算法通過增加訓練樣本的數量,可以學到更多,并且更加準確。根據建模效果,選擇了神經網絡反向傳播算法。
2 神經網絡反向傳播
基于以上的準備工作,為了使預測結果更加準確,選擇樣本數盡可能多,結合研究生院實際的信息化建設情況,本文選用近三年畢業的研究生7000多人作為研究樣本,使用spss18.0進行建模分析。
對樣本進行處理,最關鍵是監測目標的處理。對畢業論文質量進行分類,畢業論文主要包含兩部分,論文成績和答辯情況。論文成績由多位老師分別評閱,審查角度等因素影響評定論文成績有所不同。答辯是綜合各老師的意見給定的結果。所以一開始分類的時候,分成答辯一次性通過和多次通過兩類。但是發現預測率不高,再進行優化細分把論文成績這一因素考慮進去。最終畢業論文質量分為A、B、C、D四類,以此表示優秀、中上、中下、下。A是論文評分優秀或良好且答辯一次通過,B是除去A類之外答辯一次通過的論文,C存在二次答辯通過的情況,D存在多次答辯或延期答辯的情況。
該算法里激活函數對預測結果有較大的影響,它能夠實現線性模型到非線性的變換,反應變量間內在復雜深層次的關系。隱藏層的激活函數選擇tanh函數,值輸出在-1~1,是以0為中心的,并且在0附近的梯度大,模型收斂快。輸出層的激活函數選擇softmax函數,歸一化后和為1,最后的輸出是每個分類被取到的概率,本文即預測該學生某類論文質量的概率。
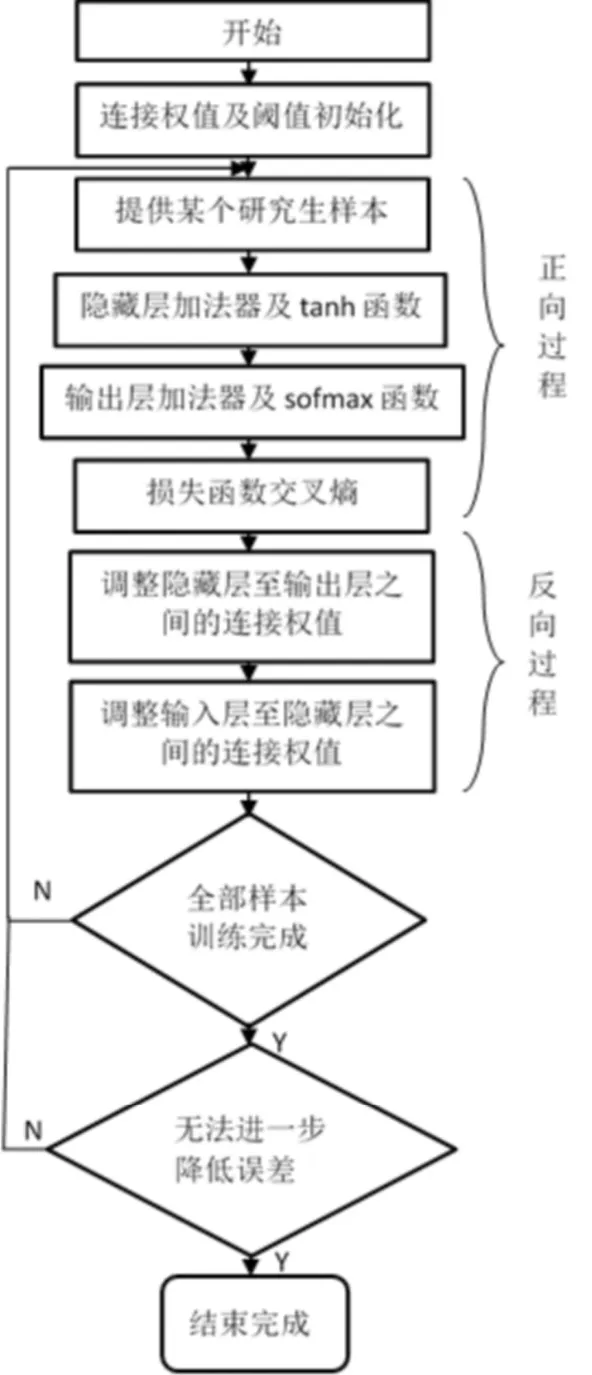
圖1:算法流程圖
最終確定的神經網絡結構為三層,分別為輸入層、隱藏層和輸出層。輸入層包含12個節點,分別是實驗室門禁次數、課程修學及成績、圖書借閱、入學成績、專業、學院、人均導師數、是否調劑、總成績、復試成績、培養方向、學位類型。隱藏層5個節點,隱藏層是神經網絡算法為了更好的計算輸入層和輸出層之間的復雜關系而出現的中間層。輸出層4個節點,就是要預測的指標,即論文的質量為ABCD四類。
2.1 算法過程
神經網絡反向傳播主要包括正向和反向兩個過程,通過使誤差函數最小,不斷調整連接權值,直到無法進一步降低誤差,神經網絡模型訓練完成。具體的算法流程如圖1所示。
首先輸入某個樣本,初始化網絡權值,計算處理每層的加法器和激活函數值,推導隱藏層到輸出層之間的算法過程。輸出層與隱層之間的網絡權值調整完成之后,依次逐層進行,通過同樣方法調整隱層與輸入層之間的權值。隨著神經網絡訓練中樣本的輸入,這種正向過程和反向過程將不斷重復,以實現預測值越來越接近真實值。
3 實驗結果與分析
通過神經網絡反向傳播算法預測畢業論文質量結果如表1所示。

表1:畢業論文質量預測結果
建模時為了提高模型的準確性,劃分為四類。實際運用中可以把預測結果簡化為兩類,A和B劃分一類作為論文質量較高,C和D劃分一類論文質量較差。真實值A,預測為AB類的概率為96.7%;真實值 B,預測為 AB類的概率為92.3%;真實值C,預測為CD類的概率為84.9%;真實值D預測為CD類的概率為82.8%。預測率按照論文優秀程度遞減。
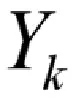

專業的影響程度,因為專業本身水平不同,對論文的影響也會不同,為了便于分析,列出下面5個相同水平的專業進行比較,分別為環境科學工程、設計學、信息與通信工程、計算機科學與技術、馬克思主義理論。如圖2所示:
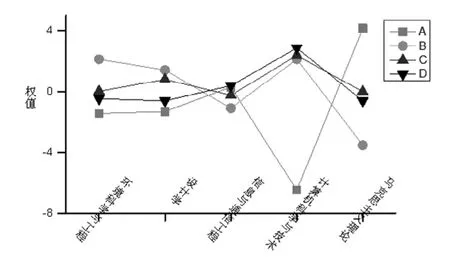
圖2:同等學科水平里不同專業權值比較
前面三個專業權值相差不大,后面兩個相差比較大,特別是A類論文。計算機科學與技術對A類論文權值是負,對其他類論文權值是正。馬克思主義理論專業正好相反。調查發現這和專業風氣有關。計算機科學與技術專業很多學生在讀研期間都去公司實習兼職,相對馬克思主義理論專業的學生來說在論文上面花費的精力和時間較少。
學院權值是各個專業權值的綜合,學院內部各專業水平不同,報考時錄取分數不同。我們對學院各專業比較,發現錄取分數高的專業,論文質量顯著偏高。這與前面的入學成績權值存在一定的關聯。
4 結束語
本文選用神經網絡算法,構建了一種預測論文質量的模型。可以通過模型預測的結果,加上個體因素的分析,找出疑似論文質量欠佳的學生和因素。調查反饋結合影響因素的歸納,影響論文質量主要包含三個方面:主觀能動性,自身基礎以及外界的影響。未來更多的行為特征將被納入數字化,有關的因素可以加入到模型中,使預測結果更加精準。從研究生個體來講,需要提高自身能動性與本身水平。從學校來講要提高學校聲譽與學科水平,及加強學校軟硬件水平,吸引優秀生源報考。
猜你喜歡
中學生數理化·中考版(2022年10期)2022-11-10 09:37:42
中學生數理化·八年級物理人教版(2022年12期)2022-02-14 07:08:42
中學生數理化·八年級物理人教版(2021年12期)2021-12-31 03:23:08
中學生數理化·中考版(2020年10期)2020-11-27 01:59:48
中國生殖健康(2019年2期)2019-08-23 08:12:08
石油化工建設(2018年6期)2018-04-22 03:16:54
產品可靠性報告(2017年7期)2017-09-05 09:49:12
中學生數理化·八年級物理人教版(2017年12期)2017-04-18 12:59:38
汽車觀察(2016年3期)2016-02-28 13:16:26
民生周刊(2014年7期)2014-03-28 01:30:54
