關聯挖掘在軍事物資管理中的應用
2020-12-23 05:47:19葉國權崔魁劉曉光閆曉陽
軟件 2020年10期
葉國權 崔魁 劉曉光 閆曉陽
摘? 要: 本文首先利用元倉庫將異域、異構的軍事物資數據庫整合,然后利用關聯挖掘中的Apriori算法對整合后的數據庫進行深度挖掘,用于幫助管理者在數量龐大的分布、異構的物資信息中,快速智能的查準查全其所需要的數據,及物資之間隱藏的關聯關系。
關鍵詞: 元數據;關聯;挖掘;整合
中圖分類號: TP39? ? 文獻標識碼: A? ? DOI:10.3969/j.issn.1003-6970.2020.10.011
本文著錄格式:葉國權,崔魁,劉曉光,等. 關聯挖掘在軍事物資管理中的應用[J]. 軟件,2020,41(10):4244+49
【Abstract】: This paper firstly will use the meta warehouse to integrate different places and heterogeneous database of military supplies, then use the Apriori algorithm of the mining association rules to mine the integration of database, used to help managers in the huge number of distributed, heterogeneous information, to find the data they need, and the hidden relationship between the information.
【Key words】: Metadata; Association; Mining; Integrate
0? 引言
隨著數據庫技術的迅速發展以及數據庫管理系統的廣泛應用,軍事物資的管理也逐漸實現了信息化,但由于建設的過程中沒有統一的規劃,建設的數據庫的結構不同、標準各異,這樣就造成了各部門系統之間交互能力不夠,無法快速對突發事件做出應有的響應。目前的數據庫系統無法發現數據中存在的關系和規則和預測未來的發展趨勢。缺乏挖掘數據背后隱藏的關聯關系,導致不能實現物資采購的全盤統籌,降低物資庫存產生的成本。為了解決以上問題,本文將通過元倉庫將異域、異構的軍事物資數據庫整合,然后利用關聯挖掘中的Apriori算法對整合后的數據庫進行深度挖掘,找到分布在異構的數量庫中的龐大的物資信息之間隱藏的關聯關系,來最終實現物資的快速響應和彈性的物資采購策略,降低我們物資的在采購、運輸、倉儲整個環節的成本。
1? 關聯挖掘技術
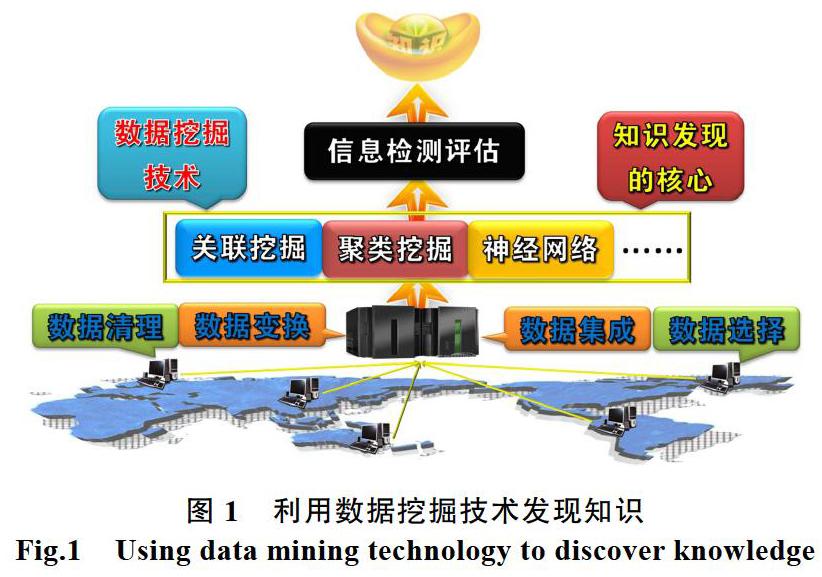
數據關聯是數據庫中存在的一類重要的可被發現的知識。若兩個或多個變量的取值之間存在某種規律性,那么其中一個變量就能通過其他變量進行預測,這就是關聯。關聯可分為簡單關聯、時序關聯、因果關聯。關聯分析是指搜索事務數據庫中的所有細節或事務,從中尋找重復出現概率很高的模式或規則。關聯分析的目的是為了挖掘隱藏在數據問的相互關系,其生成的規則帶有可信度。關聯挖掘技術是KDD(知識發現)的核心,是我們在信息爆炸的年代尋找知識的有效途徑,其具體的過程如圖1所示。
首先我們將分布在不同地區的,結構相異的數據庫中的數據變換清理,利用數據集成技術,將清理后的數據信息整合,然后通過數據挖掘技術如:關聯挖掘、聚類挖掘、神經網絡等對整合后的數據進行深度發掘,并通過相應信息評估手段,對挖掘的信息評估,最終提取有用的知識。
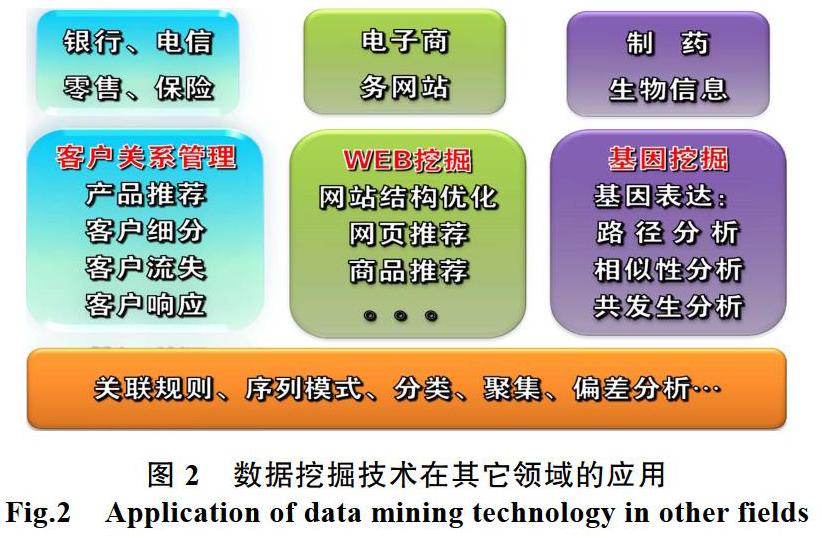
數據挖掘的應用除了在知識發現體系中的應用外,在客戶關系管理、WEB挖掘、基因挖掘等領域也非常的廣泛,具體情況如圖2所示。
2? 利用元倉庫技術實現數據庫整合
近年來,自動識別技術在全球范圍內許多領域得到應用和推廣。自動識別技術是以計算機技術和通信技術為基礎的綜合型科學技術,是信息技術自動識讀、自動傳輸到計算機的重要方法和手段。其中主要包括:射頻識別(RFID)技術、條碼技術、磁卡技術、光學字符識別技術、視覺識別技術、聲音識別技術等。
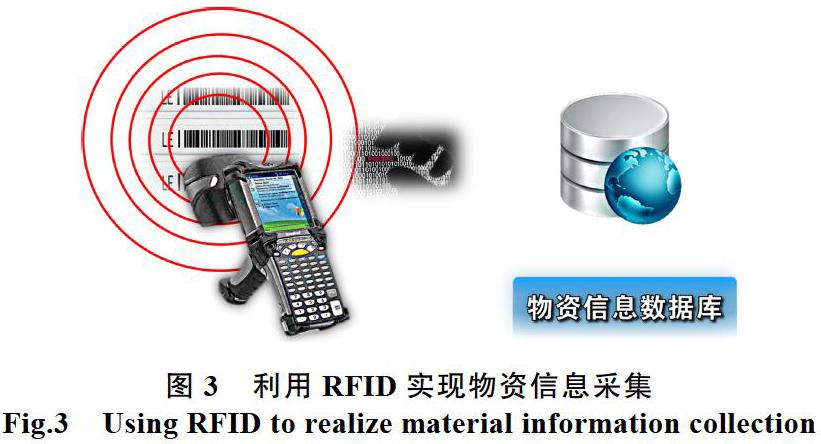
在以上自動識別技術中,RFID技術具有精度高、識別速度快、抗干擾能力強等特點,因此,比其他自動識別技術具有更廣的應用領域。對于需要經常進行維護的大型工業生產設備,利用RFID標簽能夠實現準確的設備管理,并能夠自動記錄設備的運行狀況。通過RFID技術的使用,能夠省略記錄管理的繁瑣手續,并通過操作指令與RFID標簽聯動,防止對設備的誤操作。因此在這里我們采用了RFID技術來將物資的信息提取到相應的物資管理的數據庫中。其原理如圖3所示。
在后勤物資管理系統的建設過程中,由于沒有進行整體的規劃,系統中使用的數據庫的系統不同,數據存儲的結構不同,存儲的地點不同,那么如何將這些異域異構的數據庫進行整合,也是擺在我們面前的一個主要的問題。異域異構的數據庫如圖4所示。
一般來說,目前發展比較成熟的數據集成方法從總體上可分為三種:數據倉庫、聯邦數據庫和中間件。這幾種方法特點鮮明,體現了對數據集成的不同側重點。經過對數據倉庫和聯邦數據庫集成思想的分析研究,針對物資管理數據庫的數據集成問題,我們提出了一個基于元數據的數據資源整合方案,該方案繼承了聯邦數據庫集成方法的主要優點,利用 CWM(元倉庫)來實現異域異構的數據庫中元數據的提取和整合,來解決傳統數據集成中面臨的結構異構和語義異構難題。
元數據是描述數據的數據或是與數據有關的信息,它對數據的結構信息進行了詳細的描述,它是面向某種特定應用的用于描述資源屬性的機器可理解的信息。通過規范語法結構和語義結構,使得機器能夠無二義性地表現和獲取信息。圖5是我們利用元倉庫(CWM)提取的元數據信息。
3? 關聯挖掘在軍事物資數據庫的應用
我們在前面已經介紹了關聯挖掘的方法和異構數據庫整合的方案,下面我們將利用上面的技術來實現軍事物資管理系統,在該系統中我們已經利用RFID技術將數據提取到數據庫中,并通過CWM將異構數據庫進行了整合,下面我們便是選取合適的關聯挖掘的算法來實現該系統。在關聯挖掘算法中比較經典的有兩種:Apriori算法和FP-Tree算法。利用這兩種算法實現數據關聯挖掘的示意如圖6所示。
Apriori算法的優點是邏輯結構簡單,要求硬件運行環境較低,但是參與運算的關聯項如果過多,那么進行關聯運算時,運算的量就會成指數級增長,因此這種方法不適合大關聯項的運算。FP-Tree算法是利用二叉樹對大關聯項進行裁剪,因此不會產生大量的運算,但是我們知道對樹型結構進行運算時,需要消耗大量的存儲空間,因此其要求的硬件的資源較高。考慮到我們處理的倉庫中物品關聯項的規模較小,最終采用了Apriori算法,具體實現的代碼如下所示。
L1 = {large 1-itemsets}; 所有1-項目頻集
for (k=2; Lk-1; k++) do begin
Ck=apriori-gen(Lk-1); Ck是k-候選集
for all transactions tD? do begin
Ct=subset(Ck, t); Ct是所有t包含的候選集元素
for all candidates c Ct do
c.count++;
end
Lk={cCk |c.countminsup_count}
end
L= ∪Lk;
for all itemset p Lk-1? ?do
for all itemset qLk-1? ? do
if p.item1=q.item1, …, p.itemk-1 < q.itemk-1
then begin
C= p∞q; 把q的第k–1個元素連到p后
if has_infrequent_subset(C, Lk-1)? then
delete c;? ?刪除含有非頻繁項目子集的侯選元素
else? add c to Ck;
end
Return Ck;
has_infrequent_subset(C, Lk-1),判斷c是否加入到k-侯選集中
下面是我們通過Apriori算法對整合過的數據庫中的數據進行關聯挖掘后,獲得的物資之間的關聯關系(如圖7),通過該關系,我們可以清晰的發現,各種物資之間的支持度和置信度,并通過用戶要求的最小支持度和置信度對分析后的數據進行篩選,找到用戶感興趣的物資關聯項。這樣我們就可以利用獲得物資關聯項,預測物資使用的頻率合理的安排物資的采購量,節省物資的存儲成本,其次我們還可以通過該關聯規則,將關聯度較高的物品排放在同一貨架上,優化提取路徑,提高物品提取效率等。關聯挖掘除了在物資管理中的應用外,在軍人病案信息管理中也有廣泛地應用,我們可以在病例分析中影響疾病康復用相關因素的數據進行挖掘,以便提高軍人疾病的治愈率。使用Microsoft時序模型預測醫院未來的門診工作量,以便為合理安排人、財、物資源提供科學依據。如此不但是為醫院管理者提供了良好分析方法,還為醫院科研人員提供了新的手段。
4? 結語
本文將通過元倉庫將異域、異構的軍事物資數據庫整合,然后利用關聯挖掘中的Apriori算法對整合后的數據庫進行深度挖掘,找到分布在異構的數量庫中的龐大的物資信息之間隱藏的關聯關系,來最終實現物資的快速響應和彈性的物資采購策略,但利用單一的數據挖掘技術,獲得的數據的深度和廣度還有一定的局限性,因此在今后的研究中我們可以把本體引入到我們的體系中,將本體樹建立在數據倉庫中的元數據庫上,通過本體描述集成在元數據庫上的元數據信息之間的關系,從而可以大幅度的提高由元數據進行數據挖掘的深度。
參考文獻
[1]John Poole等著. 公共倉庫元模型—數據倉庫集成標準導論. 彭蓉, 何璐璐等譯. 機械工業出版社, 2008. 3.
[2]John Poole等著. 公共倉庫元模型開發指南. 彭蓉, 劉進等譯. 機械工業出版社, 2004. 9.
[3]Meng XF, Zhou LX, WangS. State of the art and trends in database research. Journalof Software, 2004, 15(12): 1822- 1836.
[4]James Pitkow, Peter Pirellis. Mining longest repeating subsequences to predict World Wide Web surfing. 1999, 10, 2(10): 11-14. Berkeley, C USA: USENIX Association.
[5]Alejandro A, Yaisman, Alberto O. Mendelzon Enrique Molina and Pablo Tome. Temporal XMI Model Language and Implementation.
[6]Wirth N. Type Extensions. ACM Transactions on Programming Languages and Systems, 1988, 10(2): 204-214.
[7]何新貴. 人工智能新進展[M]. 北京: 清華大學出版社, 1994.
[8]曾勇, 唐小我. 線性規劃在非負權重最優組合預測計算中的應用[J]. 預測, 1994.
猜你喜歡
當代陜西(2021年17期)2021-11-06 03:21:36
學苑創造·A版(2018年11期)2018-02-01 06:29:20
讀者(2017年5期)2017-02-15 18:04:18
散文百家·下旬刊(2016年9期)2016-11-23 22:52:23
教師博覽·科研版(2016年9期)2016-11-23 08:50:22
文理導航(2016年30期)2016-11-12 15:02:43
電腦知識與技術(2016年21期)2016-10-18 23:08:26
考試周刊(2016年76期)2016-10-09 08:23:04
成才之路(2016年26期)2016-10-08 11:39:33
成才之路(2016年25期)2016-10-08 10:33:44
