基于模仿學習和強化學習的智能車輛換道行為決策*
2021-02-02 08:13:32宋曉琳曹昊天李明俊易濱林
汽車工程 2021年1期
宋曉琳,盛 鑫,曹昊天,李明俊,易濱林,黃 智
(湖南大學,汽車車身先進設計與制造國家重點實驗室,長沙 410082)
前言
近年來,智能車輛已成為車輛工程領域的研究熱點之一,具備自動駕駛系統的智能車輛相比傳統車輛不僅更加安全、舒適,且有助于節約能源和降低污染物排放[1]。智能車輛自動駕駛系統通常由感知模塊、行為決策模塊、規劃模塊和控制模塊等構成,其中行為決策模塊是上層感知模塊和下層規劃控制模塊間的重要橋梁,基于感知信息決策車輛應采取的行為,從而為下層規劃控制提供目標引導,起著承上啟下的關鍵作用,智能汽車換道行為決策是其中很重要的一種。
現有智能車輛換道行為決策方法按照決策機理,可以分為非數據驅動方法和數據驅動方法兩大類。其中有限狀態機(finite state machine,FSM)、動態博弈(dynamic game)等方法屬于非數據驅動方法。例如冀杰等[2]將車輛行駛過程劃分為車道保持、跟馳、變道和緊急制動4 種狀態,構建有限狀態機進行換道行為決策。Kurt 等[3]將決策過程進行層次劃分,構造分層有限狀態機用于決策,以此簡化狀態轉移規則來提高決策時的規則查詢效率。各類有限狀態機方法均需要人為劃分狀態并制定狀態轉移規則,因而存在規則完備性的固有問題。有學者提出動態博弈方法,在換道行為決策時考慮車輛間的持續交互作用。Wang 等[4]將換道行為決策問題表述為微分博弈(differential game),假定自車和周邊車輛進行非合作博弈,自車根據其他車輛的預期行為進行換道行為決策。Yu等[5]將自車及周邊車輛視作斯塔克伯格博弈(Stackelberg game)參與者,估計周邊車輛的駕駛激進度以確定其收益函數,通過在線求解動態博弈問題來確定自車換道行為。動態博弈方法求解平衡點的計算復雜度較高,在車載嵌入式計算平臺上的實時性往往難以滿足要求。
數據驅動方法主要包括模仿學習方法和強化學習方法等。模仿學習方法基于數據驅動,模仿專家駕駛員策略進行決策。例如Bojarski 等[6]使用卷積神經網絡(convolutional neural networks,CNN)基于車載視覺傳感器原始圖像信息進行模仿學習決策控制,并在結構化道路場景和非結構化道路場景中進行了測試。Codevilla 等[7]在此基礎上提出條件模仿學習方法,通過引入駕駛員指令來加速模仿學習并使駕駛員可在一定程度上干預決策以保障行車安全。Kuefler 等[8]則使用生成對抗網絡(generative adversarial networks,GAN)模仿專家駕駛員進行決策,實驗表明該方法能學習到諸如緊急狀況處置等高階策略。但模仿學習方法需要海量數據支持,存在模型訓練成本較高、工作時無法根據環境變化在線調整優化策略、難以適應復雜多變的真實道路環境等不足。而強化學習可在與環境在線交互過程中學習得到優化策略,因此,近幾年來強化學習在電子游戲[9]、機器人控制[10]和高級輔助駕駛系統[11]等領域取得一系列顯著成果,因而有學者將其應用于智能車輛換道行為決策中。Mirchevska 等[12]使用深度Q 網絡(deep Q network,DQN)深度強化學習方法進行智能車輛高速公路場景換道行為決策,仿真實驗表明該方法決策性能優于傳統基于復雜規則的方法。 Wang 等[13]采用連續的狀態空間和動作空間,設計具有閉式貪婪策略的Q函數逼近器來提高深度Q 網絡的計算效率,從而更快地學習得到了平穩有效的換道策略。然而,由于強化學習方法未利用先驗知識,僅通過主動策略探索尋找優化策略,因而策略學習效率偏低,處理復雜問題顯得能力不足,制約了其在智能車輛換道行為決策領域的應用。
針對強化學習方法策略學習效率偏低的問題,本文中將模仿學習引入強化學習,采用模仿學習從專家駕駛員示范數據中學習其宏觀決策經驗,換道行為決策時依據學習得到的專家駕駛員經驗確定所需求解的換道行為決策子問題,構造多個強化學習模塊分治處理不同的換道行為決策子問題,以此縮減強化學習所需求解問題的規模,降低優化策略學習難度,提高策略學習速度,從而使其比單純強化學習方法能夠處理更為復雜的智能車輛換道行為決策問題。
1 整體框架
本文中設計的智能車輛換道行為決策方法分為宏觀決策和細化決策兩層,如圖1 所示。其中,每一換道行為決策周期t 所需輸入信息It包括通過車輛總線獲取的自車信息、通過感知融合獲取的周邊車輛信息和通過高精地圖獲取的道路信息。宏觀決策模塊使用模仿學習構建的極端梯度提升(extreme gradient boosting,XGBoost)模型,將It輸入XGBoost模型的K 個基學習器CART 中,求和各基學習器輸出s并通過Softmax變換得到宏觀決策指令概率向量St,再依據St從車道保持、左換道、右換道中選擇宏觀決策指令Ct,縮減所需求解的換道行為決策問題規模。細化決策模塊的3 個確定性策略梯度(deep deterministic policy gradient,DDPG)深度強化學習子模塊DDPG_LK、DDPG_LLC 和DDPG_RLC 分別負責求解車道保持、左換道和右換道行為決策子問題,根據宏觀決策指令Ct調用相應子模塊,利用強化學習得到的優化換道行為決策策略,確定自車運動目標位置Pt,輸出給下層模塊后進入下一行為決策周期。
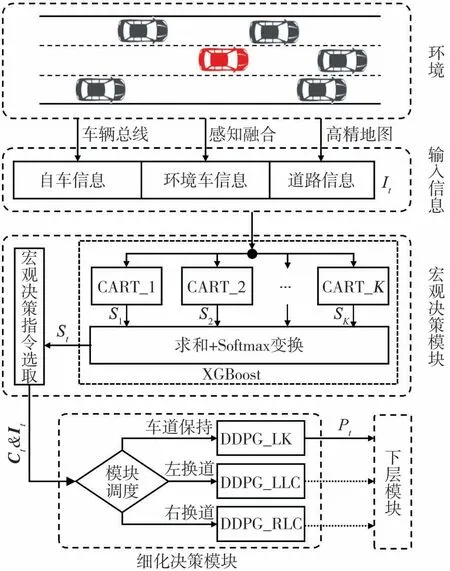
圖1 行為決策方法整體框架
2 輸入信息
由于車輛行駛時與周邊車輛及道路均存在交互作用,因而換道行為決策時需要綜合考慮自車運動狀態、周邊車輛運動狀態及車道可通行性。圖2 中carh 表示自車,自車的前方、后方、左前方、左后方、右前方、右后方6 個區域中最鄰近周邊車輛按順時針方向標記為car1~car6。
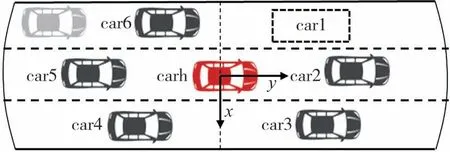
圖2 自車與周邊車輛標識
換道行為決策輸入信息如下。
(1)自車當前時刻t運動狀態信息Sh,t:包括自車車速vh,t和縱向加速度ah,t。
(2)周邊車輛當前時刻t 運動狀態信息Si,t(i =1,2,…,6):包括與自車間縱向距離dyi,t、橫向距離dxi,t和相對車速rvi,t。若某區域無周邊車輛(如圖2 中左前區域),則將距離設為∞,相對車速設為0。
(3)車道通行性信息Ir,t:由左側車道標記和右側車道標記flagl,t和flagr,t組成,記錄自車相鄰車道可通行狀況,可供通行標記為1,不可供通行(如對向車道、非機動車道、路沿)標記為0。
最終,輸入信息可用It表示為

3 宏觀決策模塊
本文中基于專家駕駛員宏觀決策示范樣本,構造XGBoost模型[14]模仿專家駕駛員選擇宏觀決策指令,選用分類回歸樹(classification and regression tree,CART)作為基學習器。模仿學習目標函數O(θ)定義為

單個基學習器Tk的模型復雜度定義為

式中:m 為基學習器Tk的葉子節點數為節點權值的L2范數;權重系數γ、λ均取1。

圖3 XGBoost模型構建過程
XGBoost 通過集成一系列學習能力較弱的基學習器來獲得較好的性能,模型構建過程如圖3 所示。基于專家駕駛員宏觀決策示范樣本,不斷訓練CART基學習器擬合先前模型殘差并集成入XGBoost 模型中,不斷迭代直到訓練預設數量基學習器或模型殘差小于設定閾值。訓練第k 個基學習器Tk時的學習目標函數為

式中:θk為Tk的參數;Ω(Tk)為Tk的模型復雜度;yi-為前一輪迭代的模型殘差為Tk的輸出;學習率ε取值范圍(0,1)。
如圖1所示,換道行為決策時輸入信息It傳入宏觀決策模塊XGBoost 模型各基學習器,將各基學習器的輸出向量s 求和后,利用Softmax 函數即可得到宏 觀 決 策 指 令 概 率 向 量St=(p1,p2,p3),其 中p1,p2和p3分別是宏觀決策指令應為車道保持、左換道和右換道的概率。選擇概率向量St中最大概率值對應的宏觀決策指令Ct輸出,據此確定所需求解的換道行為決策子問題是車道保持、左換道還是右換道。
4 細化決策模塊
4.1 馬爾可夫決策過程定義
假定各換道行為決策子問題均滿足馬爾可夫性,將其構造為無模型馬爾可夫決策過程(Markov decision process,MDP),表示為MDP(S,A,R,γ)。S為觀測狀態空間;s ∈S 為觀測狀態即輸入信息It;決策動作空間A 為圖4 所示目標車道中心線上的運動可達域,即自車本決策周期在車輛運動學約束下所能到達位置的集合;決策動作a ∈A,即自車本決策周期運動目標位置Pt;獎勵R 表征環境對自車換道行為決策的反饋;γ ∈(0,1]為折扣系數,體現對短期獎勵相比長期獎勵的重視程度。

圖4 運動可達域及運動目標位置
求解換道行為決策子問題即是尋找使該馬爾可夫決策過程在無窮時域期望獎勵值最大化的優化策略πopt:S →A

式中:t為決策時刻;k為決策時間步;Rt+k為第k時間步的獎勵值;E[]為求數學期望。
4.2 DDPG深度強化學習
各子模塊使用DDPG 深度強化學習方法[15]學習換道行為決策子問題的優化策略。利用具備強大非線性擬合能力的深度神經網絡構造表征策略函數μ(s|θμ)的演員網絡和表征動作價值評估函數Q(s,a|θQ)的評論家網絡。通過經驗回放[16]打破經歷樣本間時序相關性,同時采用類似DQN 的獨立目標網絡機制[17]來提高策略學習收斂性,DDPG 由主演員網絡θμ、目標演員網絡θμ,ta、主評論家網絡θQ和目標評論家網絡θQ,ta4部分構成。
如圖1 所示,換道行為決策時細化決策模塊根據宏觀決策模塊輸出的宏觀決策指令Ct,調用相應DDPG子模塊的主演員網絡,根據輸入信息It確定自車本決策周期運動目標位置Pt,下發執行后將經歷(It,Pt,It+1,Rt,Et)存入經驗回放庫中,其中It對應觀測狀態s,Pt對應決策動作a,It+1對應決策動作執行后更新的觀測狀態s",Rt為獎勵值,Et記錄是否滿足終止條件。定期從經驗回放庫中隨機采樣經歷樣本,訓練DDPG的主評論家網絡和主演員網絡。
訓練主評論家網絡以更加準確地評估動作價值,主評論家網絡學習損失函數定義為

其中
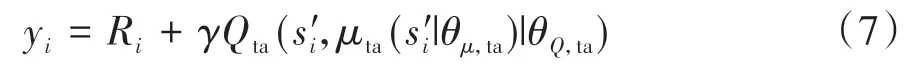
式中:n 為批采樣經歷樣本數;Ri為經歷樣本i 獎勵值;Q(si,ai|θQ)為使用主評論家網絡估計的動作價值;Qta(s"i,μta(s"i|θμ,ta)|θQ,ta)為使用目標演員網絡和目標評論家網絡估計的未來動作價值。根據式(6)計算損失值,使用Adam 優化器按設定的學習率αQ更新網絡參數。
訓練主演員網絡以優化換道行為決策策略,根據式(8)計算采樣策略梯度值,使用Adam 優化器按設定的學習率αμ更新網絡參數:

式中μ(s|θμ)為確定性策略。
目標演員網絡和目標評論家網絡無需訓練,通過式(9)和式(10)所示更新方式使其網絡參數緩慢逼近對應主網絡:
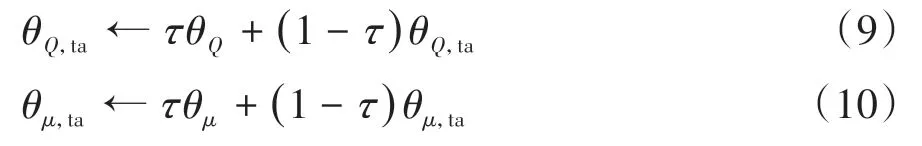
式中τ為目標網絡參數更新率,0 <τ ?1。
4.3 獎勵函數設置
強化學習在獎勵值引導下進行優化策略探索學習,因而獎勵函數設置十分關鍵。為使換道行為決策策略兼顧安全性、通行效率及乘坐舒適性,各子模塊獎勵函數需包含如下3部分內容。
(1)安全性獎勵函數:車輛行駛過程中,需與前后車輛間保持安全車距,安全性獎勵函數可表示為

式中:Thf為自車與最近前車間的車頭時距值;Thr為自車與最近后車間的車頭時距值;Thb為車頭時距閾值,Thb設定為4 s[18]。
(2)通行效率獎勵函數:車輛在保證安全前提下,應盡可能以較高車速行駛,設置通行效率獎勵函數為

式中:vh,t為自車當前車速;vl為當前路段限速;vf為當前路段車流速度。
(3)乘坐舒適性懲罰函數:車輛行駛過程中應避免頻繁變速換道,以保證乘客乘坐舒適性,乘坐舒適性懲罰函數表示為

其中

式中:pa為急加減速懲罰項;plc為換道懲罰項。
則各子模塊的復合獎勵函數表示為

式中:ws、wv和wc為各項權重系數,調參確定的最佳權重系數取值為(0.9,0.8,0.4),歸一化操作Normal用來將復合獎勵函數取值范圍變換到[0,1]區間。
5 實驗與分析
5.1 專家駕駛員宏觀決策示范樣本采集
本文中使用圖5 所示駕駛模擬器采集專家駕駛員宏觀決策示范樣本。其中虛擬駕駛環境為4.2 km 長的環形三車道高速公路,設置一輛可控自車和若干輛由自動駕駛模型[19]控制的環境車輛,各車輛均基于簡化車輛運動學模型[20],道路全段限速90 km/h。
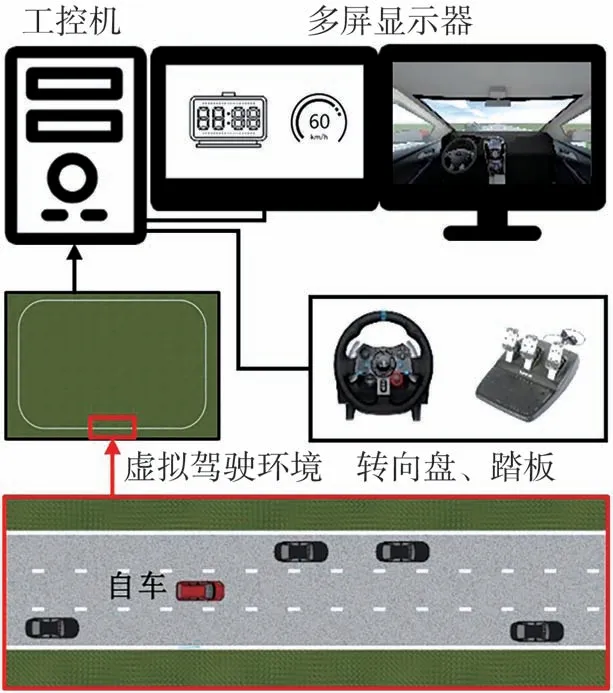
圖5 駕駛模擬器及虛擬駕駛環境
由于不同駕駛員駕駛經驗不同,因而宏觀決策行為傾向性不同,為避免決策二義性問題,僅采集1名專家駕駛員的宏觀決策示范樣本。共進行10 輪模擬駕駛實驗,每輪需駕駛自車在虛擬駕駛環境道路上行駛5 圈,以5 Hz 采樣頻率同步記錄自車與環境車輛的狀態、道路信息和駕駛員操縱輸入。為避免疲勞駕駛,兩輪實驗間隔時間均大于15 min。
剔除駕駛員出現失誤或違規的數據后獲得約2.5 h 的原始數據。使用寬度為5 s、重疊量為2 s 的移動窗口從原始數據中提取樣本:提取窗口起點時刻自車與周邊車輛的運動狀態信息和道路通行性信息,作為樣本特征值;通過窗口范圍內自車橫向位置的極差判斷駕駛員是否采取換道,將此宏觀決策行為作為樣本對應標簽值。提取得到3 020 組專家駕駛員宏觀決策示范樣本,其中車道保持1 328 組,左換道873組,右換道819組。
5.2 宏觀決策模塊訓練
為保障專家駕駛員宏觀決策示范樣本類別平衡,對車道保持類別樣本進行下采樣隨機保留850組。網格調參確定的最佳XGBoost 模型訓練參數設置如表1 所示。通過十折交叉驗證評估模型性能,XGBoost 模型平均測試集分類準確率為91.46%,歸一化混淆矩陣如圖6 所示,算得kappa 系數值為0.87,表明構建的XGBoost 模型可以較好模仿專家駕駛員進行宏觀行為決策。
使用專家駕駛員所有宏觀決策示范樣本訓練得到最終XGBoost 模型。XGBoost 模型相比神經網絡等黑箱模型的顯著優勢是其內在決策機理可知,因而安全性更高且易于迭代優化。可以通過統計XGBoost 模型中基于各學習特征組分裂的節點數目占比來獲知其內在決策機理,如圖7所示。由圖7可看出,基于主車前方周邊車輛car1~car3 的運動狀態S1,t、S2,t、S3,t以及道路通行性信息Ir,t分裂的節點占比較高,對模型輸出影響較顯著,表明XGBoost 模型主要基于主車前方車輛的運動狀態及道路通行性狀況進行宏觀決策。
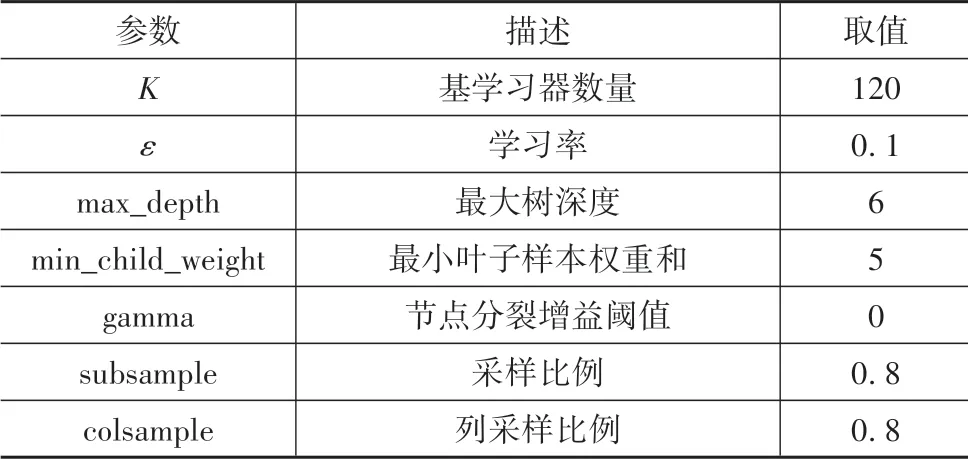
表1 XGBoost訓練參數設置

圖6 歸一化混淆矩陣

圖7 分裂節點數目占比統計
5.3 細化決策模塊訓練
由于本文中著重研究換道行為決策,因而對下層模塊進行簡化處理:采用基于五次多項式的軌跡規劃方法[21],并假定控制模塊能使自車理想地跟蹤目標軌跡行駛。
細化決策模塊各DDPG 子模塊網絡結構如表2所示,訓練參數設置如表3所示。通過與圖5虛擬駕駛環境在線交互來訓練各DDPG 子模塊,每當自車行駛一圈或與環境車輛發生碰撞時終止當前訓練輪次,重新隨機初始化虛擬駕駛環境后開始新的訓練輪次,直到完成設定輪次訓練。
平滑處理后的訓練過程中單步平均獎勵值變化曲線如圖8 所示,可看出經過約1 600 輪次訓練后獎勵值逐漸穩定在高位,策略學習收斂。由式(16)可知單步獎勵理論最大值為1,但由于多數情況下自車需要在安全、通行效率和乘坐舒適性間平衡取舍,因而平均值必然小于1,圖8中終端單步平均獎勵值約為0.85,已較為逼近實際可達最優值。

表2 DDPG網絡結構
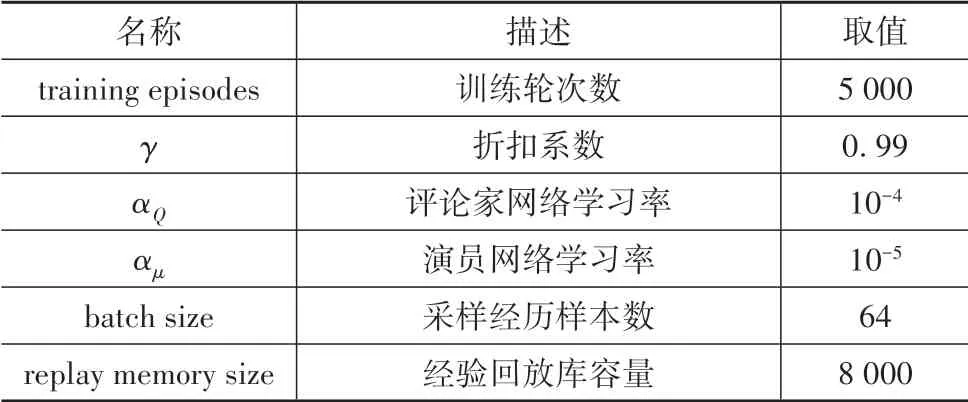
表3 DDPG訓練參數設置

圖8 單步平均獎勵值變化曲線
5.4 測試比對
參與測試比對的換道行為決策方法如下。
(1)D_FSM:文獻[19]提出的有限狀態機方法。
(2)D_IL:基于多層感知機(multi?layer percep?tron,MLP)的行為克隆模仿學習方法,使用模擬駕駛實驗采集的數據訓練。
(3)D_RL:單純強化學習方法,網絡結構及獎勵函數設置與本文細化決策子模塊相同。
(4)D_IRL:本文中設計的模仿強化學習方法。
首先比對D_IRL 與D_RL 的策略學習速度。為消除隨機因素影響,兩者使用相同訓練參數設置分別進行5 次訓練,結果如圖9 所示。由圖9 可知,D_IRL 的平均終端獎勵值相比D_RL 占優,且D_IRL平均策略學習收斂所需訓練輪次數比D_RL 降低約32%,表明本文基于宏觀決策指令縮減待求解換道行為決策問題規模的機制,有效降低了優化策略求解難度,顯著提升了策略學習速度。

圖9 策略學習速度對比
采用上述4 種方法分別控制虛擬駕駛環境中自車進行100 輪隨機初始化的自動駕駛測試,以評估本文方法與各基線方法的換道行為決策策略綜合性能,每輪行駛里程為1圈,結果如表4所示。

表4 自動駕駛測試統計結果
由表4可知如下結果。
(1)在安全性方面,D_IRL、D_RL和D_FSM 方法在測試中主車均未發生碰撞事件,而D_IL 有3 次碰撞記錄,這可能是由于行為克隆模仿學習方法無法依據環境變化在線調整策略,遇到訓練樣本覆蓋范圍外的情形策略失效造成的,由此可見D_IRL 策略的安全性優于D_IL。
(2)在通行效率方面,D_IRL 策略的表現較優,測試中主車平均車速相比D_FSM 提升5.7%,相比D_RL提升0.6%,與D_IL基本持平。
(3)在乘坐舒適性方面,D_IRL 方法測試中主車車速標準差相比D_FSM 降低45.6%,相比D_IL降低3.4%,相比D_RL 降低13.8%,表明D_IRL 策略較少采取急加減速動作,乘坐舒適性較優。D_IRL 方法測試中主車平均單輪換道次數少于D_IL 和D_RL,減少了換道時橫向加速度變化對乘坐舒適性的影響;D_IRL 方法測試中主車平均單輪換道次數高于D_FSM,這是因為D_FSM 基于規則的策略偏于保守,謹慎采取換道而比較容易引發緊急制動,而D_IRL 的策略則更加積極主動,通過更主動采取安全換道行為來提升通行效率,并通過規避部分不必要的緊急制動來提高乘坐舒適性,這一點在兩者平均車速及車速標準差的對比中也可以得到體現。
綜上所述,本文中設計的D_IRL 方法學習得到的換道行為決策策略的綜合性能優于其他3 種基線方法,在安全性、通行效率和乘坐舒適性間取得了良好平衡。
5.5 場景測試
為了更直觀地展現本文方法換道行為決策策略的性能,基于自動駕駛仿真軟件Prescan 搭建兩個典型場景進行換道行為決策測試。場景中主車的換道行為決策模塊采用本文方法,環境車輛的運動由文獻[19]的自動駕駛模型控制。兩場景測試過程中的鳥瞰視角關鍵幀如圖10 所示,圖中主車為用紅框標記的綠色車,各關鍵幀車輛實時速度也標注在圖中,測試道路長度均為200 m。
由圖10(a)可見:場景1中主車前后及兩側相鄰車道均有環境車輛,且主車通行嚴重受制于前方白色車輛,主車換道行為決策模塊根據輸入信息,判定應采取左換道以獲得更好的通行效率;主車安全換到左側車道后,前向運動空間充足,平緩加速至目標車速行駛。
由圖10(b)可見:場景2中位于主車同車道前方的紅色車輛在開始階段忽然制動減速,由于主車兩側相鄰車道均有環境車輛且距離較近,主車換道行為決策模塊根據輸入信息,判定應采取減速從而避免與前車發生碰撞;待前車開始提速后,主車調整車速繼續車道保持,以安全距離跟馳前車行駛。
由以上兩個典型場景的測試結果可看出,采用本文方法學習得到的換道策略可以較好地應對主動換道、前方車輛急減速等情況,具備良好的工程應用前景。

圖10 典型場景換道行為決策測試
6 結論
本文中設計了一種基于模仿強化學習的智能車輛換道行為決策方法,其中宏觀決策模塊XGBoost模型模仿專家駕駛員選擇宏觀決策指令,確定所需求解的行為決策子問題,在此基礎上,使用細化決策模塊對應DDPG 子模塊強化學習得到的優化策略,確定車輛運動目標位置并作為行為決策結果下發執行。仿真結果表明,本文方法相比單純強化學習方法在策略學習速度上有顯著提升,且換道行為決策策略的綜合性能優于有限狀態機等現有方法。
本文研究中假定換道行為決策輸入信息是準確無誤的,實際情況中受車載傳感器等因素影響,輸入信息可能是不準確或不完整的。后續研究將考慮輸入信息的缺失及噪聲問題,以提高換道行為決策方法的魯棒性。另外,如何在實車平臺上應用本文中設計的換道行為決策方法也將是后續研究的重點內容。
猜你喜歡
汽車實用技術(2022年14期)2022-07-30 06:13:42
汽車實用技術(2022年4期)2022-03-07 06:07:20
中學生數理化(高中版.高考理化)(2020年2期)2020-04-21 05:32:50
小學生作文(低年級適用)(2019年9期)2019-10-08 08:37:10
數學大世界(2018年1期)2018-04-12 05:39:14
公民與法治(2016年4期)2016-05-17 04:09:26
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
時代英語·高三(2014年5期)2014-08-26 02:49:51
