大數據環境下居民對個人醫療信息被訪的容忍度研究
2021-03-02 05:52:42吳丁娟
醫學與社會 2021年2期
吳丁娟
廣州醫科大學衛生管理學院,廣東廣州,511436
醫療信息承載大量患者隱私,涉及內容非常廣泛和敏感。電子信息的記憶性和共享性日益凸顯出共享醫療數據的倫理與隱私保護的倫理在價值方式、技術方式上同時呈現的矛盾[1]。為了實現醫療信息開發的同時兼顧隱私保護,很多學者致力于通過技術限制訪問[2-3]。但是,出于生命健康權益的考慮和醫療大數據價值的追求,醫療信息依然會在多種用途下被訪問和共享[4]。
從隱私主體立場,學者們對隱私泄露容忍度進行了探討。容忍度和風險關系密切,Grable將金融風險容忍度定義為決策者所愿接受的最大程度的不確定性[5]。借鑒此定義,李睿指出隱私泄露容忍度是用戶對隱私泄露的接受程度[6]。Carducci等表明心理和個體因素測試可以探究個體的風險容忍度及其影響因素[7],問卷調查比較適于研究容忍度。利用問卷,易紅等得出圖書館用戶隱私泄露容忍度低的結論[8],李睿也指出移動互聯用戶呈現隱私泄露風險厭惡傾向[6]。既有文獻表明了網絡用戶的隱私泄露容忍度不高,然而,基于患者視角對醫療隱私泄露容忍度的相關研究尚不多見。醫療信息應用場景比較特殊,隱私獨享和信息共享的沖突更為明顯。多變訪問場景和非固定訪問目的下,設計合情合理合法的醫療信息訪問策略十分重要,因此,深入了解民眾的個人醫療信息被訪敏感度和容忍度迫在眉睫。
1 資料來源與方法
1.1 研究對象
由于研究主題涉及到醫療數據,要求受訪者對大數據有初步認識,所以,本次調查的目標總體界定為18-55歲的居民。于2019年9-10月,采取兩階段抽樣法,先利用隨機抽樣在廣州市選取了天河區、越秀區、番禺區、荔灣區4個行政區,然后利用便利抽樣法在4個區發放問卷295份,剔除填寫不完整、邏輯混亂、填寫錯誤等無效問卷,保留有效問卷244份,有效回收率為82.7%。
1.2 研究方法
依據研究目的,首先查閱了相關文獻并進行資料整理,然后,分別訪談一名醫生和居民,了解當前醫院對醫療數據的管理和使用現狀,居民對隱私保護與醫院權限的理解和態度,以及醫生和居民的各自立場和顧慮。最后,基于文獻研究和訪談結論來設計問卷,經過專家咨詢、小范圍測試和題項分析方法,得到預調查問卷。預調查共發放53份問卷,效度和信度良好,為正式調查問卷的發放奠定基礎。調查問卷主要包括5方面內容。
1.2.1 居民對隱私的關注度。采用非平衡量級的單選題進行測量,1-4分別代表不關注、一般、關注、非常關注,分數越高,關注度越高。
1.2.2 居民對醫院的隱私保護工作的信任度。基于醫療數據在醫院的流轉程序,分別從醫療數據的收集、使用、訪問、存儲和轉讓5個工作情境的醫療隱私保護入手,利用Likert 5級量表測量居民對醫院隱私保護的信任態度,分為非常不信任、不信任、一般、信任、非常信任5個級別,分數越高,信任度越高。
1.2.3 居民對不同醫療信息隱秘性的敏感度。敏感度表現為居民對不同醫療信息隱私保護的重視程度,參考賀旭設計的醫療信息指標[9],篩選出具有一定敏感性的9個典型指標:機器檢查圖像信息,住院信息(床號、門診號、住院號、入住時間天數等),治療信息(主要病史、化驗結果、治療期間病情變化、手術方式、使用藥物等),勞動力鑒定(傷殘情況),整容信息,傳染疾病信息,精神疾病信息(神經衰弱、強迫癥、抑郁癥等),家族遺傳病史,DNA鑒定結果。利用Likert 5級量表,分為非常不重要、不重要、一般、重要、非常重要5個級別,分數越高,敏感度越高。
1.2.4 匿名信息被訪容忍度和實名信息被訪容忍度。由于患者就醫診療過程中的醫生和相關人員對于個人醫療數據的訪問是必然且合理的,所以,對于醫療隱私被訪容忍度的調查主要從其他非診療情境入手,包含非就診的其他醫生查看個人醫療信息、醫學院作為案例展示給醫學生、醫學生在病史室翻閱病歷進行學習、醫院用于宣傳疾病的治療手段、制藥公司做藥物療效跟蹤記錄、醫療保險公司統計數據制定醫保策略6個題項設置。在身份是否能夠識別的兩種前提下,利用Likert 5級量表測量匿名信息被訪和實名信息被訪容忍度,分為非常不同意、不同意、一般、同意、非常同意5個級別,分數越高,容忍度越高。
1.2.5 個人信息。為了分析個人特征與醫療隱私被訪容忍度的關系,設置了性別、年齡、學歷、職業等題項。
1.3 信度和效度分析
利用SPSS 19.0對數據進行信效度分析,總量表和各個分量表的信度系數都滿足Cronbach's alpha大于0.8,表明量表內部一致性非常理想,量表信度較高。KMO值均大于0.8,Bartlett球形檢驗P<0.001,表明變量適合進行因子分析。采用主成分分析法配合最大差異法旋轉得到4個因子,信任度、敏感度、匿名信息被訪容忍度、實名信息被訪容忍度4個構念分屬于4個因子,且在分屬因子上的最低因子載荷量為0.672,累積解釋總方差73.0%,可以認為萃取的4個因子是非常適切的。結合咨詢專家的內容效度和表面效度檢驗,問卷的可靠性和有效性可以得到驗證。見表1。

表1 量表的信度和效度分析
1.4 統計學方法
用SPSS 19.0軟件進行統計分析,主要使用獨立樣本t檢驗、配對樣本t檢驗、方差分析、多重比較及線性回歸分析等方法。
2 結果
2.1 調查對象基本情況
調查對象中,男性134人(54.9%),女性110(45.1%),其中18-35歲124人(50.8%),36-55歲120人(49.2%)。比例基本均衡,職業和學歷的分布也基本符合廣州市的現狀。見表2。

表2 樣本基本信息與被訪容忍度
2.2 基本數據描述
醫院在信息流轉過程中隱私保護工作的信任度方面,總信任度為(3.13±0.82),各類場景下隱私保護工作的信任度排序如下:轉讓信任度(2.94)<收集信任度(3.14)<使用信任度(3.15)<訪問信任度(3.17)<存儲信任度(3.24)。其中,過渡數據給第三方的隱私保障是最不被認可的。
醫療信息保護的敏感度方面,總敏感度為(4.25±0.66),各類醫療信息的敏感度排序為:傳染病(4.41)、家族遺傳病史(4.41)> DNA鑒定結果(4.39)>精神疾病信息(4.33)>整容信息(4.27)>治療信息(4.2)>勞動力傷殘鑒定(4.16)>住院信息(4.11)>機器檢查圖像信息(3.98)。
信息被訪的容忍度方面,匿名和實名信息被訪容忍度分別為(2.80±0.88)、(2.09±0.90),6個情境下的匿名信息和實名信息被訪容忍度分別為:非就診的其他醫生查看醫療信息(2.93/2.38)、醫學院作為案例展示給醫學生(2.90/2.04)、醫學生在病史室翻閱病歷學習(2.84/2.09)、醫院用于宣傳疾病的治療手段(2.43/1.80)、制藥公司做藥物療效跟蹤記錄(2.90/2.14)、醫療保險公司統計數據制定醫保策略(2.81/2.12)。無論是否匿名,醫院用于宣傳疾病治療都是最不被接受的一種隱私訪問方式。匿名信息被訪容忍度趨于中立,實名信息被訪容忍度普遍偏低,以不同意個人醫療信息被訪為主要態度。
通過Q-Q圖和P-P圖的觀察,結合單樣本K-S檢驗,可以接受匿名被訪容忍度、實名被訪容忍度、兩個容忍度之差值都服從正態分布的假設。
2.3 身份信息是否被識別的容忍度差異分析
容忍度差值定義為匿名被訪容忍度-實名被訪容忍度,數據有正有負,檢驗得到容忍度差值滿足正態分布。利用配對樣本t檢驗驗證結論:相比于匿名信息被訪,實名信息被訪時居民的容忍度顯著降低。見表3。

表3 信息被訪容忍度的配對樣本t檢驗
2.4 不同特征人群的容忍度差異分析
利用獨立樣本t檢驗和單因素方差分析,分析不同人群容忍度的差異,并對有差異的組別進行S-N-K多重比較。基于表4的差異分析和表5的多重比較分析,可以得出:①匿名信息被訪容忍度在性別、年齡、學歷上無顯著差異,實名信息被訪容忍度在性別、年齡、職業上無顯著差異;②企業員工、自由職業者及其他類型人員的匿名信息容忍度顯著低于公務員、事業單位工作人員和大學生,但是無論何種職業的實名信息被訪容忍度都沒有顯著差異;③實名信息被訪容忍度普遍偏低,高中及以下學歷居民的實名信息被訪容忍度顯著高于更高學歷的居民。

表4 容忍度差異分析
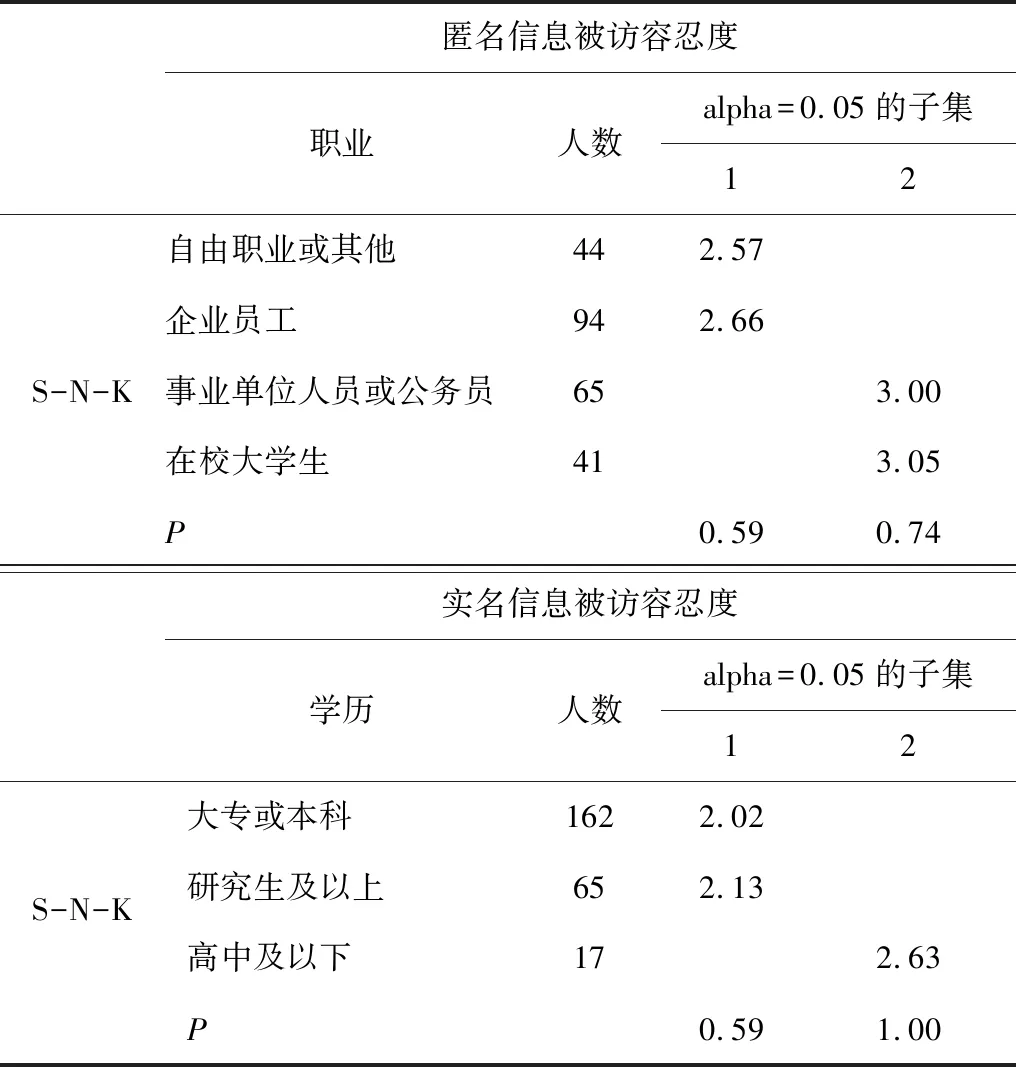
表5 醫療信息被訪容忍度多重比較
2.5 實名信息被訪容忍度影響因素分析
結合相關分析和差異分析方法,得到匿名信息被訪容忍度除了與職業有關之外,與關注度、信任度、敏感度以及其他個人特征都沒有顯著相關性,表明職業類別是匿名信息被訪容忍度差異的主要原因。同樣,實名信息被訪容忍度與關注度、信任度、敏感度、匿名信息被訪容忍度、學歷都顯著相關,利用線性回歸分析進一步探討實名信息被訪容忍度的影響因素。設置虛擬變量edu1、edu2代表學歷,變量說明和線性回歸分析結果見表6、表7。

表6 變量說明

表7 實名信息被訪容忍度的回歸分析
為了保證學歷變量的同進同出,使用進入法納入變量。依據表7的數據,回歸方程顯著,所有自變量對因變量的影響都顯著。調整后R2=0.38,表明自變量解釋了因變量38%的變異。DW值=2.32,表明沒有嚴重的自相關現象。VIF值在1.04-3.64,表明沒有明顯的共線性。由此,實名信息被訪容忍度的回歸方程為:
Y=2.73-0.16X1+0.20X2-0.36X3+0.43X4-0.51edu1-0.51edu2
回歸方程表明:①隱私關注度、敏感度、學歷負向影響實名信息被訪容忍度,對醫院隱私保護工作的信任度、匿名信息被訪容忍度正向影響實名信息被訪容忍度;②各個因素對實名信息被訪容忍度影響力大小的排序為:匿名信息被訪容忍度>敏感度>學歷>信任度>關注度;③以高中及以下學歷為基準,控制其他變量不變的情況下,更高學歷的實名信息被訪容忍度都會降低0.51個點。
3 討論
3.1居民對醫院信息保護工作的信任度較高,對第三方機構的數據共享持有質疑
在醫院信息保護工作中,居民對于信息的收集、使用、訪問、存儲的隱私保護信任均值基本持平于3.14-3.24之間,轉讓數據給第三方機構的隱私保護信任度均值為2.94。說明民眾對于醫院的信譽是持比較樂觀的態度,但是對于第三方機構在數據共享下的隱私保護懷有質疑。因此,規范醫院自身的數據管理有利于醫院形象的維護和塑造,特別是和第三方機構合作進行數據開發時要充分考慮隱私保護并做好隱私保護工作,提升民眾對醫院的信任。
3.2 居民重視醫療信息的隱私保護
居民對各類醫療信息隱私保護的整體敏感度為(4.25±0.66),表明對于帶有敏感性的醫療信息,居民認為隱私保護工作十分重要。各類醫療信息的敏感度均值位于區間3.98-4.41,區間長度為0.43。如果從最低敏感度的3.98開始,每隔0.15分為一個等級,即3個等級的隱私保護敏感度分別為(3.98-4.13)、(4.14-4.29)、(4.3-4.45),那么,一級保密的依次是傳染病、家族遺傳病史、DNA鑒定結果、精神疾病信息,二級保密的是整容信息、治療信息、勞動力傷殘鑒定信息;三級保密的是住院信息、機器檢查信息。本研究對于醫療信息的分級結果和婁培的醫療數據分級結果進行對比[10],雖然內容有差異,但是重合部分信息的級別順序是吻合的,依據居民感知的隱私敏感度進行隱私訪問權限的分層控制或能有助于降低隱私糾紛。
3.3 身份能夠識別的醫療信息被訪容忍度極低
數據分析結果顯示,匿名信息被訪容忍度接近于“一般”的態度,實名信息被訪的主要態度為“不同意”,表明了在非就醫情形下的信息被訪是不被接納的。其中,醫院用于宣傳疾病的治療手段是最不被接受的一種隱私訪問方式。因此,醫療信息超出正常隱私讓渡范圍時,醫療機構須爭取患者知情同意,特別是涉及個人身份信息時,更應該在隱私保護的范疇之下進行,以免引起隱私權糾紛,引發醫患矛盾。另一方面,雖然現在醫療機構在數據隱私保護上都充分體現了匿名原則,差強人意的匿名信息被訪容忍度也為隱私共享留下了些許空間。然而,隨著技術發展,人工智能的學習分析能力將可以透過醫療信息推導其他隱私[11],匿名醫療信息在技術上反向定位至個人也會成為必然。因此,隱藏身份標志的信息共享也可能會和實名信息共享一樣陷入倫理困境。
3.4 實名信息被訪容忍度將會越來越低
通過回歸分析得到結論,居民的學歷和對隱私的關注度都反向影響實名信息被訪容忍度。一方面,當前學歷高的居民容忍度低,反映了對大數據的認知越多,就越不能容忍隱私泄露,與易紅對圖書館用戶的調查結論一致[8],但是,隨著大數據的應用不斷拓展,即使學歷低的民眾對于大數據知識的理解也必將越來越深入。另一方面,各類隱私侵權事件的出現越來越強化人們的隱私意識,隱私保護的愿望也日益迫切,將帶來隱私關注度的提升。如何一方面尊重個人隱私,一方面開發大數據醫療的巨大潛力,關于這個辯題的倫理思考和技術探討任重道遠。
猜你喜歡
兒童繪本(2018年10期)2018-07-04 16:39:12
中華手工(2017年2期)2017-06-06 23:00:31
小朋友·快樂手工(2016年5期)2016-05-14 17:18:34
中國衛生(2015年8期)2015-11-12 13:15:20
中外會展(2014年4期)2014-11-27 07:46:46
中國衛生(2014年11期)2014-11-12 13:11:28
中國衛生(2014年8期)2014-11-12 13:00:54
中國衛生(2014年7期)2014-11-10 02:33:12
建筑創作(2001年3期)2001-08-22 18:48:14
祝您健康(1987年3期)1987-12-30 09:52:32
