基于多重對應分析的大學生心理調查研究
2021-03-24 11:16:32肖明魁
電腦知識與技術 2021年2期
關鍵詞:大數據
肖明魁
摘要:隨著大數據時代的來臨,計算機及相關數據分析專業軟件被廣泛運用于數據分析,建模及數據挖掘等領域。在當今社會生產經營活動中,對于諸如產品定位,客戶細分,社會調研,工程管理等各行業研究,經常會采用多重對應分析法,用于揭示同一變量的各個類別之間的差異,以及不同變量各個類別之間的對應關系。本文以某高校大學生心理調查數據作為依據,研究和分析多重對應法在現實中的具體應用,對于開展大學生心理指導和教育工作具有一定借鑒意義。
關鍵詞:大數據;SPSS;對應分析
中圖分類號:TP311? ? ?文獻標識碼: A
文章編號:1009-3044(2021)02-0202-02
1 基本概念介紹
對應分析法又稱關聯分析,R-Q因子分析,對應分析是在傳統因子分析基礎上發展起來的一種新型多元統計分析法,相對于傳統因子分析,對應分析可將研究對象的樣本和變量聯系在一起,綜合處理,不僅降低了因子選擇和因子旋轉等計算過程的復雜度,而且便于直觀,高效,簡單地展示分析結果,適合于多分類變量數據研究。
對應分析可分為簡單對應分析(只有兩個分類變量)和多重對應分析(樣本多于兩個變量),簡單對應分析是分析兩個分類變量間的關系,而多重對應分析則是分析一組屬性變量之間的相關性,二者均是以散點在低維空間中的行列位置表示相關強度。簡單對應分析中的變量通常為分類頻數,而多重對應分析中變量除分類變量外還可使用數值型變量。
2 多重對應分析的條件和步驟
2.1 多重對應分析的條件
首先,多重對應分析法不能自動篩選變量,需要用戶手動操作;其次,該方法對于數據樣本量要求較大,尤其對少數極端值變化較為敏感;再次,其分析結果通常以圖形方式展現,對缺乏經驗的用戶而言容易造成誤判;最后,當數據樣本變量增減變換后,處理結果會產生很大差異。
2.2 多重對應分析的步驟
1)將原始數據樣本經規格化和最優尺度變換處理后,得到樣本概率列聯表。
2)計算Z矩陣。
3)根據變量相關系數矩陣Σr和樣本斜方差矩陣Σc進行多維變量因子分析和樣本因子分析,并推導出結果。
4)以散點或線條在二維圖上展示樣本變量狀態并分析其相關性。
3 具體案例分析
這里以某高校大學生心理調查問卷數據為例,共計555個有效樣本,從中提取九個變量,分別從九個方面表示大學生不同的心理狀態和興趣愛好,如幸福度,自我感覺,精力水平,孤獨感,情緒控制力,易怒性,戶外活動,體育活動,交友等,每個變量依據程度,由低到高分為五級。案例研究的目標是探索大學生心理狀態和興趣愛好之間的相關性,分析軟件采用IBM SPSS statistics,分析結果以圖表方式展現,結果如下。
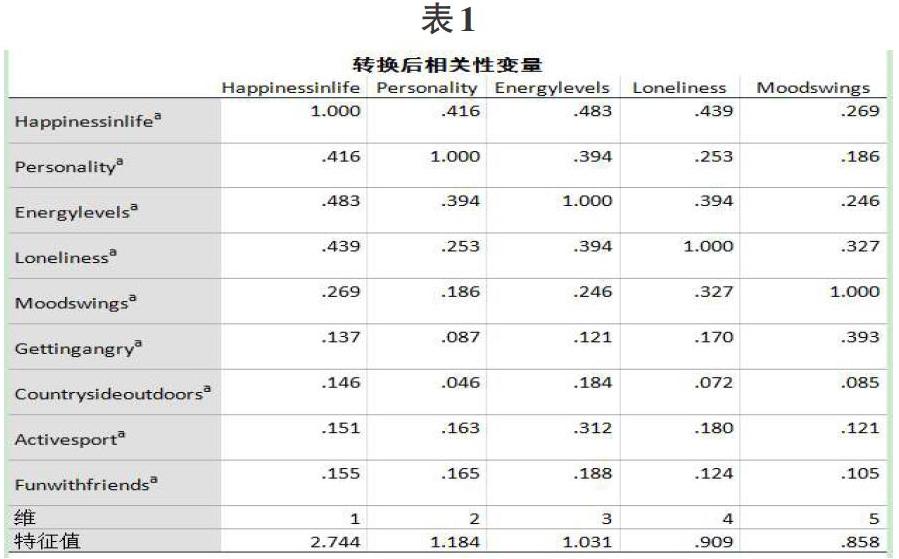
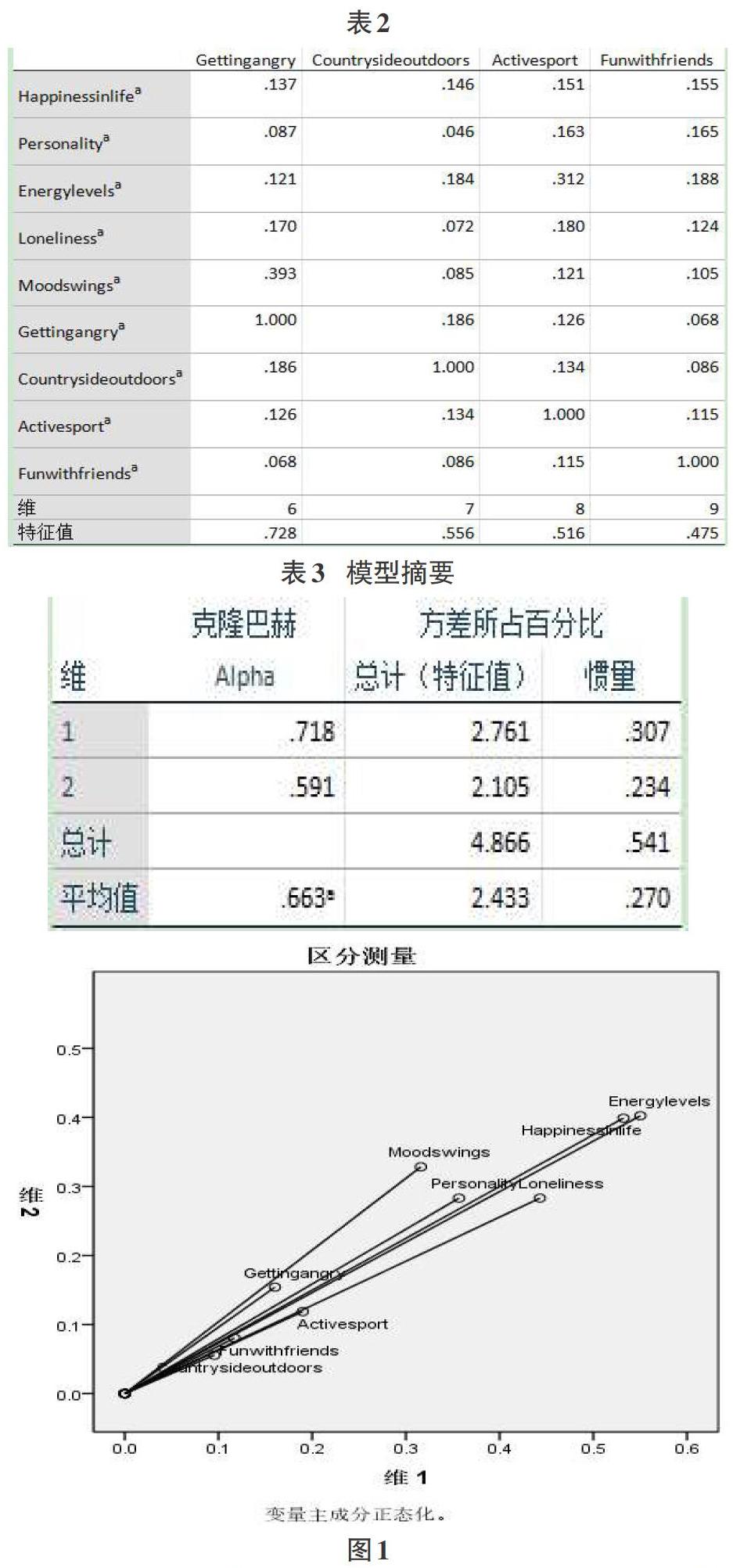
首先需要對原始數據九個變量作相關分析,如表1和表2的行列陣所示,經過軟的后的不同變量之間相關度也有所不同,數值越大,相關度越高。表3是數據模型摘要表,反映了樣本變量的信度系數,特征值及慣量等統計信息,多重對應分析將原始數據九個變量經過最優尺度變換后,得到兩個維度,信度系數分別為0.718和0.591,慣量即方差貢獻率分別為0.307和0.234。表3展示了各變量區分測量的結果,以坐標軸分別代表兩個不同維度, 原始變量在圖中不同的位置反映出該變量在不同維度上所攜帶的信息量,變量的某個坐標值越高,說明該變量在某個維度上關聯度越強,如果變量的兩個坐標值都很高,說明該變量和兩個維度均有強相關性。如圖中所示,變量“energylevels”和“happiness”和兩個維度都有很強的相關性,而變量“loneliness”和維度1相關性較強,“moodswings”則和維度2相關度更強,至于“countrysideoutdoors”“funwithfriends”“activesport”三個變量在兩個維度上的相關性均相對較弱。
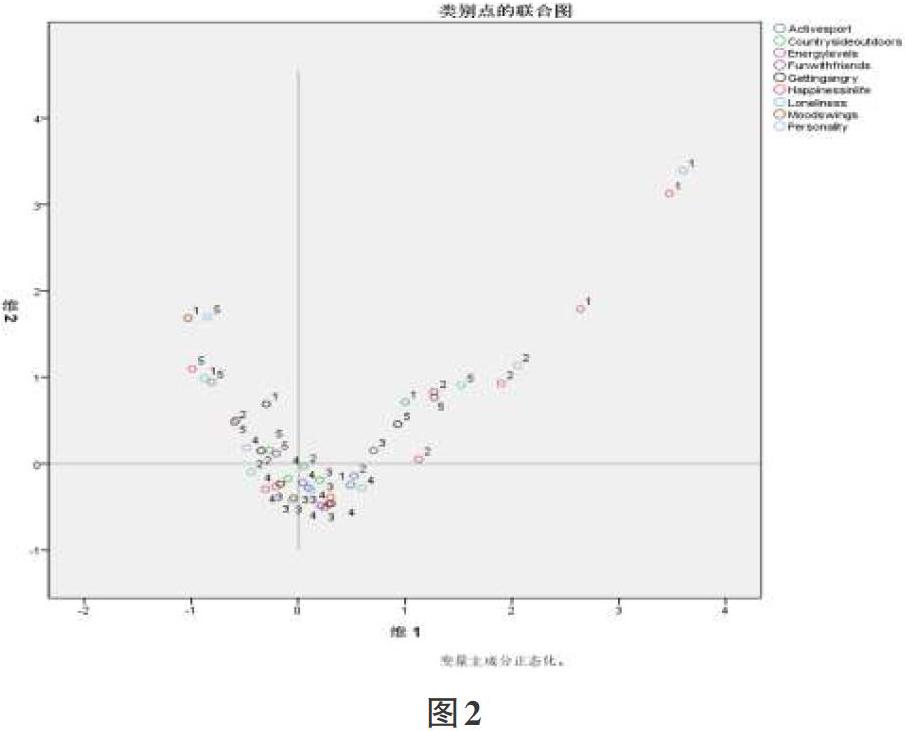
圖2是類別點聯合圖,以散點圖的形式向用戶展示數據樣本各變量之間的相關性強弱,聯合圖用不同顏色的散點代表不同原始變量,標簽則標注了變量頻數和數值等信息,和區分測量圖一樣,以坐標軸表示兩個不同維度,用戶通過觀察各個散點的坐標分布,可以分析出數據變量之間相關性。本圖中增加了兩根十字交叉的輔助線,將聯合圖分為四個象限,有助于更清楚地觀察分析統計結果。首先,在第一象限中,有一些散點大體沿相同方向有規律地分布,說明這些散點所代表的變量具有較強的相關性,因而可以認為這些變量代表了一部分特征人群,尤其是“happiness”“personality”這兩個變量的維度坐標值都相對較高,說明這些變量所代表的屬性在相關特征人群中表現更為明顯。此外,這兩個變量在四個象限中的坐標分布又相當分散,則說明這兩種屬性在不同特征人群中區別較為明顯。在第二象限中,發現另一些散點沿某個方向呈現類似規律的分布狀態,同樣可以理解為這部分變量代表了另一部分特征人群,并且通過進一步觀察,發現這些散點變量的頻數值與第一象限變量值成反比,由此說明,這兩種特征人群屬于截然不同的類型。第三和第四象限中,各個散點距離原點較近,并且分布較為集中,變量值也較為居中,可以認為,這部分人群屬于差異相對較小,沒有明顯的特征屬性,并且在各個方面表現較為“平均”的類型。
4 案例分析總結
通過以上多重對應分析法對高校大學生調研問卷的分析和理解,可以得出以下幾個判斷和結論:
1) 被調查樣本依據性格愛好大體可分為三類:自信開朗型,消極自卑型,“平均”型;
2)自信開朗型人群的性格特征表現為以下幾個特點:自信心十足,情緒控制力強,積極開朗,精力旺盛,樂善合群等;
3)與之對應,消極自卑型人群則表現出:自信心不足,悲觀消極,性格孤僻,精神不振,易怒易躁等特點;
4)自信開朗型人群更愛好戶外運動、社交、體育活動等,消極自卑型人群則正好相反;
5) 大多數“平均”型人群性格愛好位于二者之間;
6)社交,體育活動及戶外運動等興趣愛好與學生性格塑造和完善有著較強的相關性,因而在學生培養過程中應當予以重視和引導。
參考文獻:
[1] 關炯暉,楊振杰.偏最小二乘回歸法在海洋初級生產力影響因子分析中的應用[J].漁業科學進展,2014,35(5):19-25.
[2] 閻麗萍,余姝緯,崔超英.基于因子分析法的二級學院績效考評研究[J].商業會計,2014(18).
[3] 李燕華,路立敏.基于因子分析的水泥行業上市公司財務績效研究[J].現代商貿工業,2020(26).
[4] 陳媛媛.基于解釋結構模型的高校輔導員職業能力因子分析[J].兵團教育學院學報,2020,30(4):30-34.
[5] 李麗媚.基于因子分析的高校閱讀推廣之影響因子實證研究[J].科技視界,2020(21):107-110.
【通聯編輯:梁書】
猜你喜歡
中國市場(2016年36期)2016-10-19 04:41:16
中國市場(2016年36期)2016-10-19 03:31:48
中國市場(2016年35期)2016-10-19 01:30:59
商(2016年27期)2016-10-17 06:26:00
今傳媒(2016年9期)2016-10-15 23:35:12
今傳媒(2016年9期)2016-10-15 22:09:11
新聞世界(2016年10期)2016-10-11 20:13:53
科技視界(2016年20期)2016-09-29 10:53:22
中國記者(2016年6期)2016-08-26 12:36:20
