基于多通道卷積神經網絡的中文文本關系抽取
2021-06-03 09:29:36梁艷春房愛蓮
華東師范大學學報(自然科學版) 2021年3期
梁艷春, 房愛蓮
(華東師范大學 計算機科學與技術學院,上海 200062)
0 引 言
在信息爆炸的現代社會, 快速獲得準確的信息具有重大意義, 關系抽取則是幫助我們從海量數據中獲取關鍵信息的重要方式之一. 關系抽取也被稱為關系分類, 即從自然語言文本中識別出關鍵實體后, 再判斷兩個或多個實體間的語義關系, 屬于多分類問題. 作為重要的語義處理任務, 關系抽取也在知識庫填充、問題回答、自動知識庫構建等復雜應用中起著中間作用.
為了抽取出兩個實體間的正確關系, 需要解析句子的句法特征和語義特征. 句法特征是指句子的組成部分以及它們的排列順序, 語義特征是指詞語的意義以及在句子中詞語意義如何相互結合以形成句子意義. 為了學習這些特征, 早期的關系抽取方法通常需要解析文本并人工構建特征, 這些方法很大程度上依賴于外部自然語言處理工具, 如詞性標注、語法分析等. 而卷積神經網絡(CNN)建模語句的最短依存路徑, 將語法分析融入深度學習框架中. 因此, CNN可以代替句法樹提供語法信息. 但中文句法結構比英文更為復雜, 如何自動地從句子中學習特征, 最小化對外部工具包和資源的依賴,實現端到端的中文關系抽取, 是值得研究的問題.
為解決上述難點, 本文在CNN的基礎上提出了MCNN_Att_RL模型. 該模型將兩種類型的詞向量輸入卷積層, 每個通道都用分層的網絡結構, 使神經網絡學習到不同的表示. 為了學習到更多的語義特征, 還加入注意力機制, 獲得強調實體的句子表示. 此外, 采用兩層池化結構, 先用分段平均池化融入句子的結構特征, 再經過最大池化保留句子的最大信息. 同時, 采用基于邊界的排序損失函數, 替代普遍使用的Softmax分類函數和交叉熵函數, 排序損失函數使模型更能區分易于分錯的類別. 綜上,本文的主要貢獻如下.
(1)研究了多通道CNN方法如何用于中文文本關系抽取, 在沒有外部信息的情況下, 學習到句子不同的表示.
(2)加入注意力機制獲取句子的語義特征, 并通過分段平均池化融入句子結構特征, 在不依賴外部工具包的情況下, 實現了端到端的關系抽取.
(3)用排序損失函數代替交叉熵函數進行訓練, 以區分易于分錯的類別, 提高了中文文本關系抽取的準確性.
1 相關工作
關系抽取的方法可分為監督學習、半監督學習或無監督學習. 其中監督學習的關系集合通常是確定的, 可以當作分類問題去處理. 半監督學習方法利用少量的標注信息作為種子模板, 從非結構化數據中抽取大量新的實例來構成新的訓練數據, 由于這種方法依賴于模板和規則, 會導致數據不太精確,存在大量噪聲. 無監督方法一般利用語料中存在的大量冗余信息做聚類, 在聚類結果的基礎上給定關系, 但聚類方法本身就存在難以描述關系和低頻實例召回率低等問題, 因此無監督學習一般難以得到很好的抽取效果. 下面主要介紹監督學習和半監督學習方法.
早期的方法通常基于正則表達式表示的模式和規則. 模式方法假設同一關系類型的所有句子具有相同的語言環境, 其不能覆蓋所有的語言形式, 導致了很低的召回率.
在2013年, Liu等[1]最先提出用CNN方法做關系分類. 他們使用的網絡結構很簡單, 即是將同義詞的嵌入表示作為輸入, 之后是卷積層全連接層以及用Softmax分類. 相比于傳統方法, 該方法具有一定的提升, 為后續神經網絡用于關系抽取提供了啟發. 2014年, Zeng等[2]在此基礎上進行了改進,使用預處理的詞向量, 并設置了實體, 即實體的上位詞、實體的上下文環境、詞位置等詞匯特征, 結果表明, WordNet和位置特征比較重要. 2015年, Zhang等[3]開始嘗試用RNN做關系抽取, 在不使用任何詞匯特征的情況下, 效果與CNN結合詞匯特征相類似. Zhou等[4]在RNN的基礎上, 用LSTM(Long Short-Term Memory)替代RNN模型, 并加入注意力機制, 效果取得了提升. 之后, Zhu等[5]也在CNN中采用注意力機制, 并改進損失函數, 在英文數據集SemEval 2010 Task8 中獲得了當前最佳結果. Li等[6]則設計了一種雙卷積神經網絡方法, 結合注意力機制, 并借助知識庫提升關系抽取性能.此外, Hong等[7]通過改進圖卷積神經網絡, 用一種新的感知注意力機制來獲取實體間的關系表示, 在多個公共數據集上取得了較好的效果.
上述的全監督方法是在完全正確的標注數據集上做的, 數據量小. 而半監督學習方法則在大數據集上做關系抽取, 需要考慮數據中的噪聲問題. 2015年, Zeng等[8]在自己2014年的研究基礎上, 使用多示例學習方法解決遠程監督自動標注數據產生的大量噪聲以及錯誤標注數據的問題, 并進行了分段池化. 雖然這種方法減弱了噪聲的影響, 但也丟失了一部分信息. Lin等[9]在Zeng的基礎上引入注意力機制, 這樣既可以減弱噪聲, 加強正樣本, 也可以充分利用信息. 之后, Kim等[10]提出了在文本中附加可確定的顯著實體, 幫助識別傳統方法無法識別的關系. Sun等[11]則采用多頭自注意力網絡去噪方法以提取關聯, 跟傳統模型相比達到了較好效果. Chen等[12]通過融合強化學習, 設計了DQN(Deep Q Network)對句子進行降噪, 減少錯誤標簽的影響, 提高了關系抽取的準確度.
英文關系抽取技術的研究相對比較成熟, 但由于中文數據集的缺乏, 中文關系抽取相應地研究較少. 其中, Wu等[13]采用基于注意力的CNN做中文關系抽取, 并加入了HowNet上位詞嵌入信息, 在ACE 2005中文語料中取得了一定的效果提升. 而針對中文文學作品沒有明顯連詞關聯, 主語比較隱蔽, 詞的用法相對復雜等難點, Wen等[14]利用結構正則化去除句法信息中的噪聲, 通過最短依賴路徑進行中文文學文本關系的提取. Li等[15]利用外部語義信息, 將字義、詞義、同義詞等通過Lattice LSTM融入一起, 在多個中文數據集上驗證了模型較好的魯棒性. 張等[16]則針對中文電子病歷, 采用雙向GRU模型, 并引入注意力機制提升了在特定領域中中文關系抽取的準確性.
2 多通道CNN模型
2.1 多通道機制介紹
多通道機制是圖像處理方法的基礎, 在圖像處理領域, 圖像由3個通道(紅色、綠色和藍色)組成.每個通道都使用多層神經網絡進行處理, 由于每個通道在循環傳播過程中互不影響, 因此它使神經網絡能從每個通道學習不同的表示. 基于單通道CNN處理句子的方法與處理圖像不同, 它們在不考慮句子結構的情況下對整個句子進行卷積. 整個方法忽略了一個重要問題: 單詞可能具有多種含義. 單一詞向量只能表征自然語言的一部分語義信息, 這限制了總的信息輸入量. 基于此, 本文采用了多通道CNN結構, 每個通道輸入不同的預訓練詞向量, 多個通道表征了輸入語句的更多語義信息, 從而使模型學習出區分度更強的語義特征, 對自然語言具有更強的表征能力.
2.2 基于多通道機制的模型MCNN_Att_RL
本文提出的MCNN_Att_RL模型如圖1所示. 該模型主要由向量映射層、注意力層、卷積層、分段平均池化層、最大池化層和全連接層組成. 由圖1可以看到, 本文模型不同于普通CNN模型的地方在于, 這里使用了兩種詞向量將輸入映射到兩條通道, 并在通道2中加入了注意力機制以獲得面向實體的向量表示. 此外, 在經過雙通道CNN獲得多個通道信息后, 按實體位置將其分成5段通過平均池化層, 以融入句子的結構信息. 最后經過最大池化層, 學習到句子的最終表示. 這樣, 網絡可以自動學習到更豐富的特征.
2.2.1 向量映射層
經典的one-hot編碼方法將詞與詞間視為相互獨立, 具有高稀疏性的缺點. 2013年, Mikolov等[17]提出了Word2vec模型. Word2vec模型分為Skip-gram模型和CBOW模型, 它可通過學習文本的方式將每個字映射成低維的實值向量, 從而得到字的語義表征. 使用Word2vec模型訓練好的詞向量直接輸入下一個網絡結構進行使用. 自然語言處理領域使用詞向量的方式一般分為兩種: 一種是使用大型數據預訓練的詞向量; 另一種是針對特定任務或特定數據集訓練詞向量, 這兩種方式都只能使用一種詞向量, 獲取的是句子的單一表示. 在本文的MCNN_Att_RL模型中, 采用了兩個通道融合兩種詞向量, 獲得的是詞的不同語義特征, 其中通道1使用在Gigaword[14]中預訓練的中文詞向量, 通道2則使用特定于中文文學作品的詞向量.
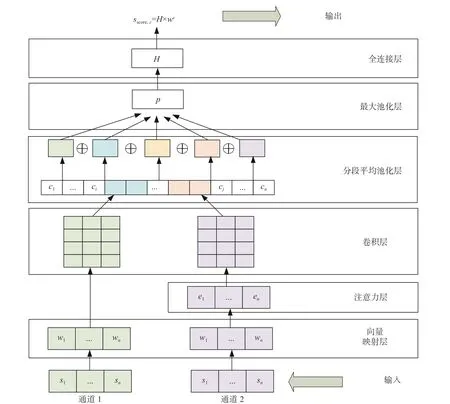
圖 1 MCNN_Att_RL模型結構Fig. 1 MCNN_Att_RL model structure


2.2.2 注意力層

其中, 函數f表示web和wi的內積和. 之后, 計算相關性矩陣ab, 矩陣ab的元素為

其中,b=1,2;i=1,2,···,n. 令

得到面向實體對的向量

其中,i=1,2,···,n. 最終融入語義信息的句子S表示為E={e1,e2,···,en}.
2.2.3 卷積層

2.2.4 平均池化層
為了獲取句子的結構信息, 根據實體1跟實體2的位置, 將c分成5段. 假設實體1的起始與終止位置為a、b, 實體2的起始位置與終止位置為c、d, 則c被劃分為 [c1,···,ca?1] 、 [ca,···,cb] 、 [cb+1,···,cc?1] 、[cc,···,cd] 、 [cd+1,···,cn] 5部分, 將c表示為

將每段輸入分別通過平均池化層, 得到
對于庫里南,用文字去仔細形容它的座椅舒適程度其實是相當乏味的,只有親身體驗才能明白其中的奧妙。不過遺憾的是,在官方重點宣傳的“覽景坐席”并沒有出現在我體驗的那輛庫里南上。要不然,在后備廂開啟“覽景坐席”的兩個座椅,讓自己沐浴在三亞冬天溫暖的陽光下,也算是一種很容易就忘記煩惱的愉快。

其中,j=1,2,3,4,5 . 這樣, 每段輸入都在平均池化層的作用下得到一個值, 組合在一起就得到了融入了句子結構信息的特征向量.
2.2.5 最大池化層
為了保留最大的信息特征, 再加入最大池化層對平均池化后的結果進行最大化操作, 得到最后的特征信息, 即

其中,j=1,2,3,4,5 .
2.2.6 全連接層
最后采用全連接層進行全局調節, 得到最終的輸出

其中,wf為模型的參數, 在反向傳播時進行訓練.
2.2.7 分數計算
不同于用Softmax分類函數計算關系概率, 這里用句子最終表示與關系類別c的相關性作為得分. 即

其中,wc為關系c的嵌入向量, 通過關系嵌入查找表得到.sscore,c為句子中的實體預測為關系c的分數, 因此, 最終預測的關系類別為

2.2.8 損失函數
不再使用交叉熵函數作為損失函數, 而是采用基于邊界的排序損失函數. 在獲得關系分數后, 損失函數定義為

3 實 驗
3.1 數據集介紹
由于中文關系抽取語料庫的缺乏, 2017年, Xu等[18]爬取了1 000多篇中文文章, 去掉太短和噪聲太多的文章, 歷時3個月從837篇中文文學作品中獲得語料, 定義了7種實體類型和9種關系類型用于中文文本命名實體識別和關系抽取. 本文選取這個中文文學文本數據集進行關系抽取實驗, 其中關系類別定義如表1所示.
對該語料進行預處理, 共獲得21 240個句子. 其中17 227個句子作為訓練集, 4 013個句子用作測試集. 每一句都有標記好的兩個實體, 預處理后的部分數據示例如圖2所示.
這些句子均從中文文學作品中得到, 中文關系抽取任務為抽取兩個實體之間的語義關系. 例如,幽蘭、山谷, “幽蘭在山谷, 本自無人識”. 這里, 標記的兩個實體為“幽蘭”和“山谷”. 模型的輸入為句子的嵌入向量表示, 輸出為關系類別5, 對應表1中的Located關系.

表 1 關系類別Tab. 1 Relationship category

圖 2 預處理數據Fig. 2 Pre-processed data
3.2 評價指標
對于給定樣本集, 評估機器學習算法預測結果的方式有: 查準率P, 即分為正例的實例中實際值為正例的比例; 查全率R, 又叫召回率, 即正例被分到正例的比例. 由于查準率P和查全率R會出現矛盾, 需要綜合考慮, 所以用P和R的加權調和平均地去評估是最好的方式. 在多分類問題中, 查準率和召回率的調和平均F1值的計算為[19]

其中,n是指關系類別的數量, 在本文所用數據集中,n為9.
3.3 實驗設置
本文中模型超參數設置如表2所示. 表2中, batch、epoch、Dropout、學習速率、隱藏層個數、詞向量維度等均為其他文獻中的經驗所得; 而縮放系數z, 邊界系數a、b, 卷積核大小等通過五折交叉驗證確定, 驗證集從測試集中隨機選擇.
3.4 實驗結果與分析
為了評估MCNN_Att_RL模型的有效性, 本文選取了CNN[3]模型、BiLSTM[4]模型、加入注意力機制的BiLSTM[5]模型這3種基線模型, 并增加了3組對比實驗模型, 即雙通道CNN模型MCNN、在MCNN模型中加入注意力機制的MCNN_Att模型、在MCNN_Att模型中加入了分段平均池化的MCNN_Att_P模型. 實驗結果如表3所示.
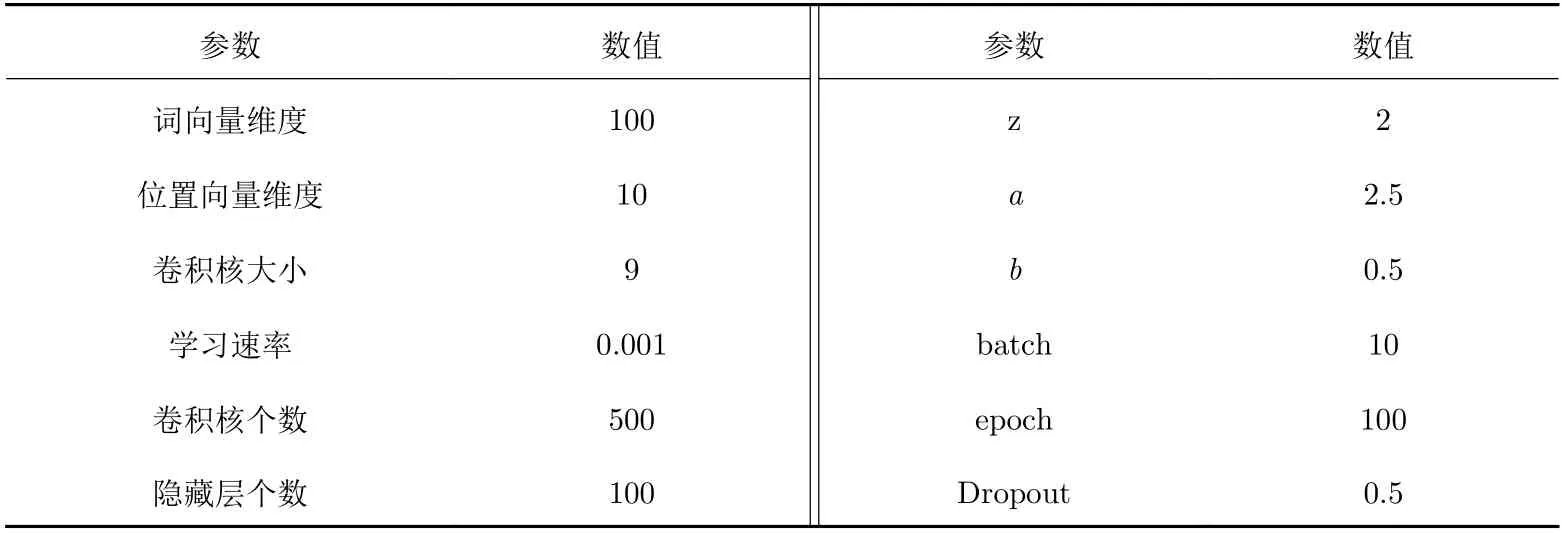
表 2 實驗的參數Tab. 2 Experimental parameters
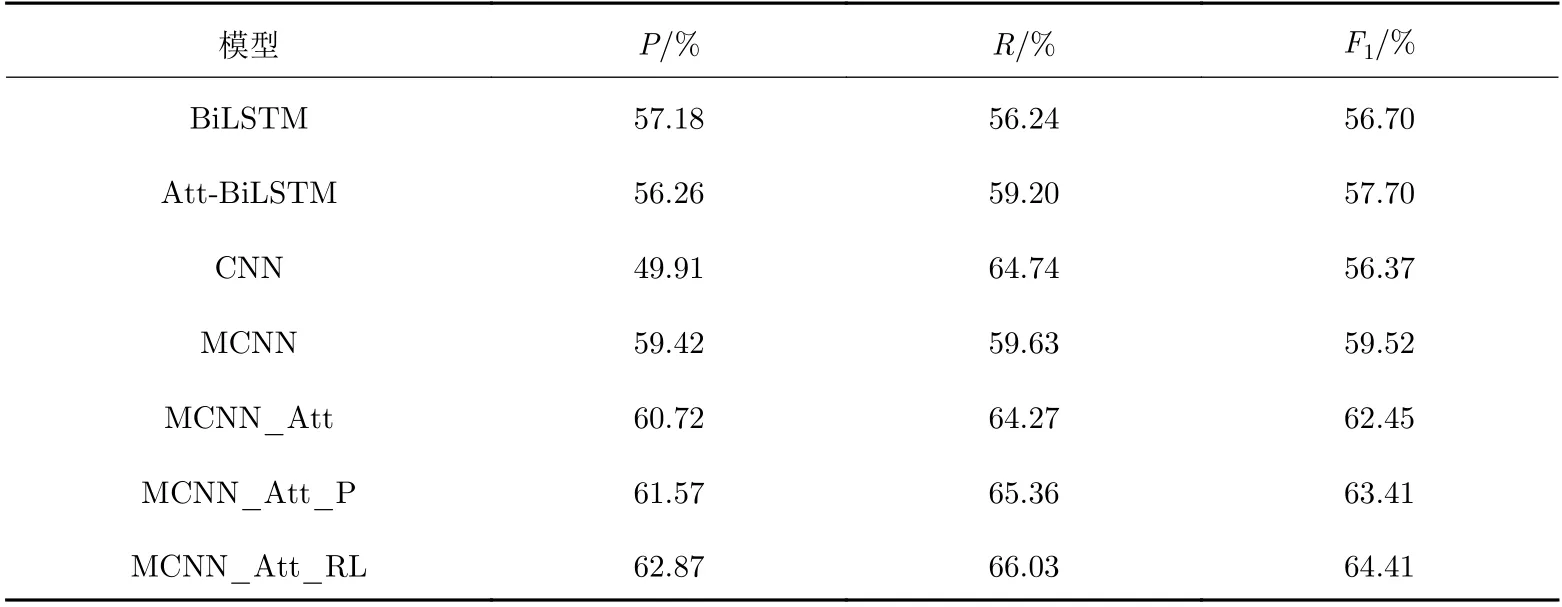
表 3 實驗結果Tab. 3 Experimental results
從實驗結果可以看出: ①相比于只使用預處理詞向量的CNN模型, 融合兩種詞向量的MCNN模型的分類性能有很大提升, 說明詞向量中確實包含自然語句的豐富表示, 多通道網絡結構能學習到句子更多的語義特征; ②加入注意力機制的MCNN_Att模型比MCNN模型F1值提高了2.78%, 也證實了融入更多語義信息的重要性; ③加入分段平均池化的MCNN_Att_P模型比直接進行最大池化的MCNN_Att模型提升了1%左右的F1值, 說明雖然之前已經突出了實體位置, 并且雙通道卷積層也在一定程度上提供了句子的語法信息, 但融入句子的結構特征還是提供了更多的有效信息; ④采用排序損失函數替代交叉熵函數,F1值也提升了1%左右, 證實了排序損失函數也適用多分類問題;⑤MCNN_Att_RL模型在無須任何外部語言信息的情況下得到了最佳的效果. 相比于使用語義分析工具或資源(如依存句法[14]、同義詞信息[15]等)使關系抽取效果得到提升的方式, 該模型僅改進網絡結構就學習到了更多的語義和結構特征, 也給其他自然語言處理任務提供啟發; ⑥相比于其他模型, 本文模型用來實現融合兩種詞向量的雙通道結構是并行計算的, 在提高抽取效果的同時仍不降低計算效率.
4 結 論
本文提出了一種雙通道CNN模型, 其中加入了注意力機制, 采用兩層池化, 并用排序損失函數代替交叉熵函數. 在不依賴外部信息源和工具的情況下, 實現了中文文學文本上端到端的關系抽取. 該模型中的雙通道結構, 使用兩種詞向量作為輸入, 以得到不同的語義信息. 而注意力機制又關注了每個字對句子的貢獻, 得到了面向實體對的向量表示. 最后為了學習句子的結構特征, 采用分段平均池化和最大池化. 實驗結果表明, MCNN_Att_RL模型的關系抽取效果優于其他神經網絡模型. 未來的工作包括以下兩個方面: ①嘗試將模型應用在其他語言的關系抽取上, 特別是藏語等一些小眾語言,可用的外部工具包較少, 需要這種端到端的關系抽取方式; ②嘗試引入更多的特征, 如同義字向量表示等作為第三個通道, 進一步提升模型的性能.
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
開放教育研究(2020年2期)2020-03-31 01:54:14
中華手工(2017年2期)2017-06-06 23:00:31
光學精密工程(2016年6期)2016-11-07 09:07:19
現代語文(2016年21期)2016-05-25 13:13:44
大連民族大學學報(2015年2期)2015-02-27 08:28:11
中外會展(2014年4期)2014-11-27 07:46:46
外語學刊(2011年1期)2011-01-22 03:38:33
