分種群遺傳算法的含分布式電源配電網故障定位
2021-06-08 08:29:34蔡偉強
蘭州文理學院學報(自然科學版) 2021年3期
蔡偉強,洪 炎,徐 濤
(安徽理工大學 電氣與信息工程學院,安徽 淮南 232001)
目前,在新能源政策的推動下,分布式電源DG逐漸接入配電網,造成配電網結構發生變化,配電網穩定性隨之變差,增大了配電網的故障定位難度,同時由于外在因素原因,故障定位的電流信息會發生畸變,使得配電網故障定位更為困難.為解決此問題需要一種新的能夠提高配電網的安全性和穩定性的算法.
針對配電網故障使用的定位方法有:直接算法,即矩陣算法[1-2],是一種簡單快捷高效的方法,計算速度快,但對信息發生畸變的故障定位準確性較差,容易受到錯誤信息影響,定位不準確.
常見的算法有粒子群算法[3]、人工神經網絡算法[4]、免疫算法[5]、蟻群算法[6]等.人工智能算法在配電網故障定位中雖然容錯性能高,能夠對信息發生畸變時提高定位準確率,但卻在算法運行時需要處理大量的數據,效率低.
遺傳算法[7-12]具有全局搜索能力強、容錯性高、運算步驟簡單等優點,但是運算時容易早熟,后期搜索能力較差,常對遺傳算法進行改進來提高性能.
當配電網中接入多個分布式電源后,對配電網造成影響,使其結構和潮流方向改變,影響了傳統的故障定位精度.近年來,對智能算法的故障定位因其定位準確,容錯性高而受到重視,本文對遺傳算法的初始種群進行改進,采用分種群方法,使每一個種群分別代表不同故障類型,通過仿真驗證,得出該改進的遺傳算法在已有的智能算法優點基礎上具有對單重故障、雙重故障等少重故障定位上,定位更加準確、運算效率高、計算速度快,具有一定的實用性.
1 算法定位原理
1.1 編碼方法
配電網中的饋線終端單元FTU用來采集開關故障電流狀態信息,將數據傳輸到配電網控制中心,進行信息處理.由于分布式電源的接入使得傳統的算法編碼方式不再適用,在含有分布式電源的配電網中需要對正方向進行規定,如圖1所示,規定正方向為主電源到DG的方向,當K點發生故障時,S1、S2的故障電流方向跟正方向一致,其編碼為1.S3、S4、S5的故障電流與正方向相反,其編碼為-1.
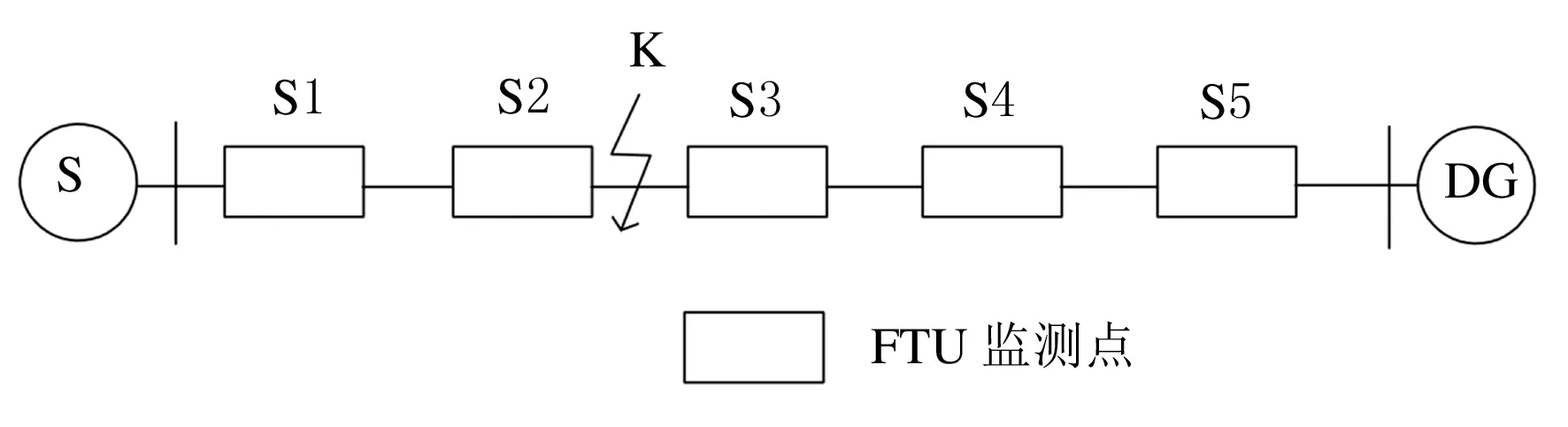
圖1 含DG配電網絡圖
用Ij表示第j個開關的狀態.即
(1)
1.2 建立開關函數
當配電網運行時在某一時刻發生故障,FTU檢測的開關電流越線信號發送給SCADA系統中,此時的信息不是故障線路信息,需要建立一個開關函數將開關電流越線信號轉換成故障線路信息,使得每個分段開關與每個線路區段相關聯.
對于含分布式電源的配電網,需要對開關函數進行改進,使其在含有多個分布式電源的情況下也能夠適應,采用文獻[7]中的開關函數,建立邏輯關系公式為

(2)
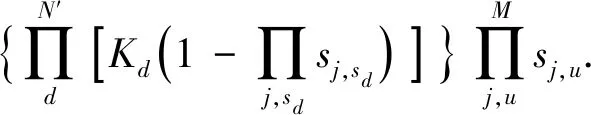
(3)
(4)

1.3 適應度函數的構造
適應度函數構造是否合理在遺傳算法故障定位中起到重要作用,適應度函數的構造能夠將算法與配電網故障定位相聯系,適應度函數構造越合理,遺傳算法故障定位越精確,根據故障電流信息經過開關函數運算后轉變為故障電路信息,再算出種群中所有個體的適應度值,其適應度函數為
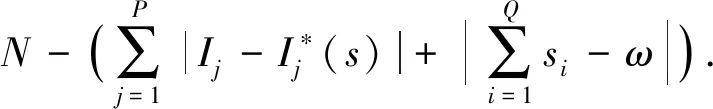
(5)
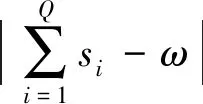
2 改進遺傳算法的故障定位
2.1 初始種群的改進
遺傳算法中初始種群的生成是隨機生成的,其中包含所有故障種群,當配電網發生單重故障時,算法對初始種群進行篩選,會消耗大量的時間處理單重故障以外的種群個體.本文對遺傳算法中初始種群的改進在于以故障類型來生成不同的種群,如單重故障對應的初始種群為[a1a2a3a4…ai](其中i為配電網聯絡結構圖中區段的個數)單重故障時,生成的初始種群中a1a2a3a4…ai中有且只有一位ak(k∈[1,i])為1,其余全為0.雙重故障對應的初始種群為[a1a2a3a4…ai](其中i為配電網聯絡結構圖中區段的個數),生成的初始種群中a1a2a3a4…ai中有且只有兩位ak、aj(k∈[1,i]、j∈[1,i]其中k≠j)為1,其余全為0.最多只能生成i個種群,在算法運行時根據故障個數生成相應的種群.以i=10為例,對于一到三重故障生成初始種群,其中隨機抽取的單個個體如表1所列.

表1 生成初始種群的隨機個體
2.2 單體交叉
對個體交叉進行改進,使用單體交叉在確保各種群所代表的各重故障不變的情況下,增加種群中個體的多樣性.適應度函數對種群個體進行評估時,在選擇最優解時能夠在最小范圍進行種群中個體基因的變動,從而更快地獲得最優解.以圖2配電網結構為例,生成三重故障種群時,其中某一個體基因為001010100000時,如果進行單體交叉操作,與另一個體基因001100100000進行交叉時,生成新的個體基因為001110100000,此個體不再是三重故障的個體.當使用單體交叉時,生成三重故障種群時,其中某一個體基因也為001010100000時,進行單體交叉時,隨機選擇其中某一位進行交叉,如第3位和第4位進行交叉,交叉后的個體基因為000110100000,仍為三重故障種群的個體,其種類不變.

圖2 配電網結構圖
以圖2線路4故障為例,設DG2=0,此時線路狀態為
s1s2s3s4s5s6s7s8s9s10s11s12=000100000000.
(6)
此時開關函數的值為
Ij*(s)=1111-1-1-1-11-1-1-1.
(7)
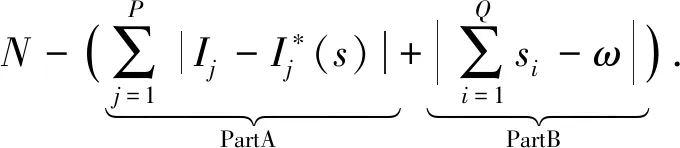
(8)
當準確故障定位時,FTU檢測到線路故障,根據編碼規則進行編碼,反饋的值為
Ij=1111-1-1-1-11-1-1-1.
(9)

(10)
此時適應度函數取值最大
F1=N+ω-1.
當算法運算時,執行單重故障種群個體為001000000000,此時的開關函數值為
Ij*(s)=111-1-1-1-1-11-1-1-1.
(11)
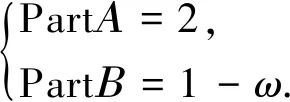
(12)
此時適應度函數值為
F2=N+ω-3.
(13)
如果靠傳統的基因交叉變異,改變其中基因狀態,可能會出現兩個1的情況,如出現001010000000的情況,這時的PartΑ≥2,適應度值為F3,F3≤F2不利于得到最大適應度值,快速進行故障定位.執行單體交叉不但能夠保持種群故障類型不變,還能夠加速故障線路的尋優.執行單體交叉時

(14)
適應度函數取值
F4≥N+ω-3.
(15)
此時算法不會出現種群倒退的情況,同時保持相同的種群故障類型.
2.3 遺傳操作
對遺傳算法進行改進后,遺傳操作也有相應的變化,添加了初始故障類型種群的生成,單體交叉,取消交叉變異操作,計算種群中每個個體適應度值,得到的適應度值最大時即得到最優解,把最優解解碼,輸出故障線路;否則對下一個故障種群進行評估,最終輸出最優解.遺傳算法故障定位流程如圖3所示.

圖3 遺傳算法故障定位流程圖
3 算例分析
3.1 單重故障
按照圖2結構圖搭建仿真模型,分布式電源DG1、DG3、DG4接入配電網中故為1,DG2沒接入配電網故為0,利用FTU上傳的信息輸入目標函數,算法參數設置如下:DG1、DG3、DG4為1,DG2為0.設置每個種群數量為60,基因長度為12,最大迭代次數為50.
假設區段4發生短路,取N=100,w在本文中取0.5.根據上文的編碼規則(1)和開關函數公式(2)、(3)、(4)計算相關的故障信息,結果如表2所列.

表2 各開關實際與期望狀態值
根據已知的開關狀態值,借助MATLAB,寫入相應的評價函數,仿真結果如圖4所示.

圖4 故障點判斷最優解
從圖4可知,此改進算法對于單重故障能夠快速進行故障定位,得到最優個體為4,即區段4線路發生故障,仿真結果與假設的故障線路一致,證明在含DG的配電網故障定位應用中此算法具有可行性.
3.2 多重故障
假設在圖2所示配電網結構圖中,區段4、區段8、區段12發生故障,根據已知的開關狀態值,借助MATLAB,寫入相應的評價函數,仿真結果如圖5所示.
如圖5得出,算法迭代9次后得到最優解,最優個體為4、8、12分別對應配電網結構圖中的區段4、區段8、區段12.由仿真的結果可知與假設的故障線路位置一致,表明此算法在配電網故障定位中線路發生多重故障時能夠進行準確定位.
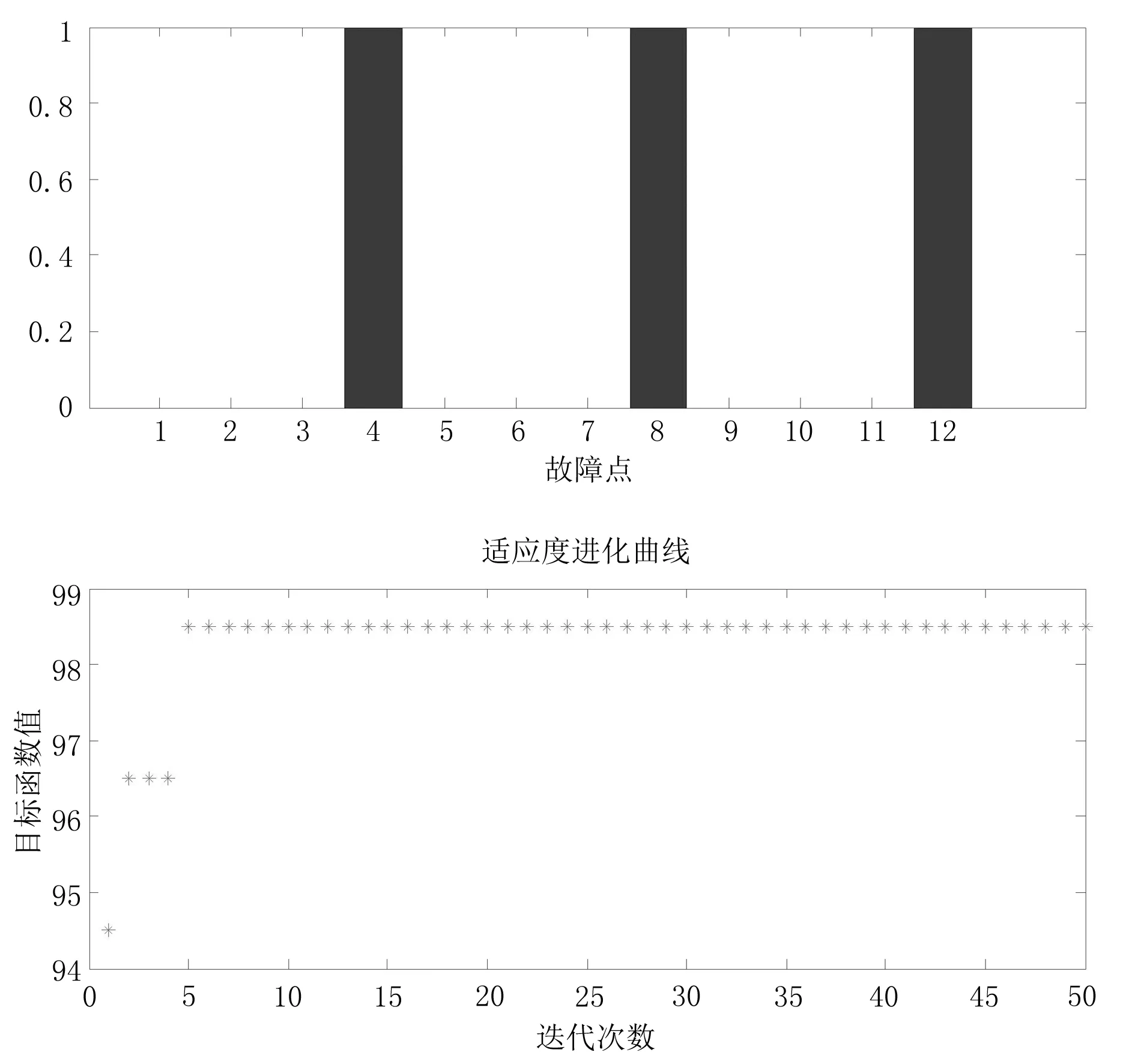
圖5 故障點判斷最優解
3.3 信息發生畸變
由于FTU會因為外界環境影響故障或是上傳電流信息畸變,導致算法定位不準確,采用改進后的遺傳算法進行故障定位時能夠彌補之前算法的不足,以三重故障為例,假設區段4、區段8、區段12發生故障,受外界環境影響FTU信息發生畸變,使I7的值由“1”變為“-1”,寫入發生畸變的開關狀態值,仿真結果如圖6所示.

圖6 發生畸變時故障點判斷最優解
由圖6可知,算法迭代11次后得到最優解,最優個體為4、8、12,與假設的區段4、區段8、區段12相對應.由此可知當FTU上傳信息發生畸變時在含DG的配電網故障定位應用中該算法仍能夠準確定位.
3.4 算法性能分析
上文對算法進行分析得出,此算法對配電網故障定位具有可行性,運算效率較快,準確率高.通過算例仿真驗證當接收信息有畸變時也具有以上特性.表3為不同類型故障的仿真結果,當對算法的單重故障、兩重故障、三重故障以及分別有畸變的情況下進行20次仿真,對各類型的故障平均迭代次數、正確次數進行分析.
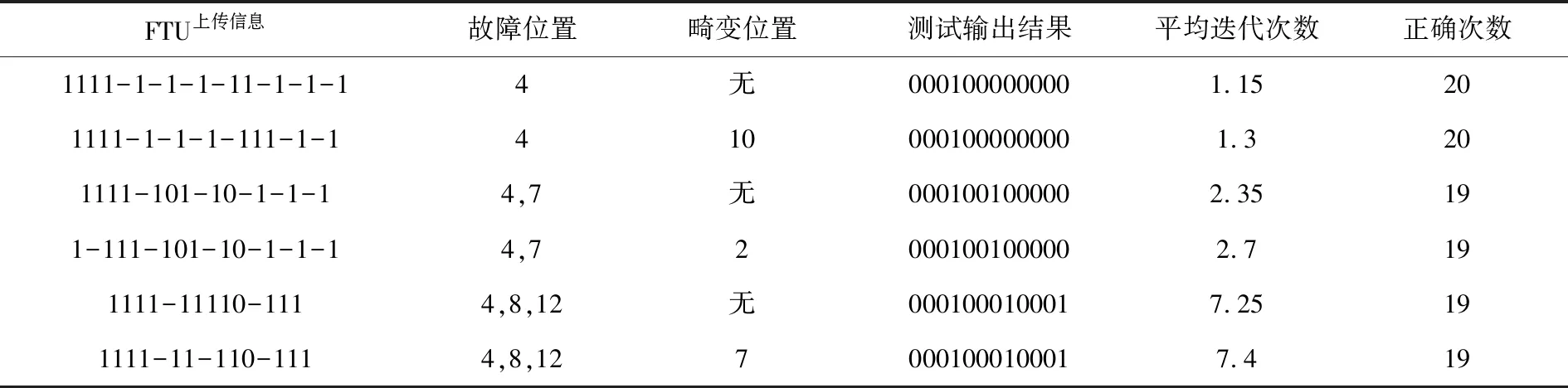
表3 不同類型故障仿真結果
由表3可知,對單重故障、兩重故障、三重故障進行定位時,單重故障的迭代次數很少,算法效率很高,準確率也較高;兩重故障、三重故障的迭代次數也不多,準確率很高.該算法能準確地在上傳信息有畸變的情況下進行故障定位,證明了該算法在配電網故障定位應用中具有一定的應用價值.
4 結語
本文提出了一種對初始種群進行改進的遺傳算法能夠對含有多個DG的配電網故障快速定位,對遺傳操作中的交叉步驟進行改進,加入單體交叉,能夠加快算法的快速性,同時也維持了故障種群類型.此算法在進行單重故障、兩重故障等低重故障時能夠快速、準確進行定位,仿真結果表明,改進的遺傳算法對帶分布式電源的配電網故障定位具有良好的容錯性,算法的效率和準確性也都很高.
猜你喜歡
汽車維修與保養(2019年7期)2020-01-06 03:30:42
經濟技術協作信息(2018年32期)2018-11-30 01:43:16
汽車維護與修理(2016年10期)2016-07-10 08:17:41
電子制作(2016年23期)2016-05-17 03:54:05
電測與儀表(2016年5期)2016-04-22 01:14:14
河南電力(2016年5期)2016-02-06 02:11:24
汽車維修與保養(2015年12期)2015-04-18 07:51:49
汽車維修與保養(2015年6期)2015-04-17 03:31:50
汽車維修與保養(2015年2期)2015-04-17 01:30:34
電測與儀表(2015年13期)2015-04-09 11:57:38
