基于分級服務(wù)的家庭護理區(qū)域劃分研究
2021-06-25 07:30:06李炫諭王謙
科技促進發(fā)展 2021年12期
■ 李炫諭 王謙
中國科學(xué)院大學(xué)經(jīng)濟與管理學(xué)院 北京 100190
0 引言
我國處在并將長期處在老齡化社會中,且中國的老齡化具有進程快、數(shù)量多和未富先老等特點。截至2019年底,全國65 周歲及以上老年人口數(shù)量為1.76 億人,占總?cè)丝诒戎氐?2.6%,老年人口比重較大且具有不斷上升的趨勢。加之社會快速發(fā)展帶來生活水平提高和醫(yī)療科技進步,人口平均預(yù)期壽命由2000年71.40 歲增加到2015年76.34 歲[1],平均預(yù)期壽命增加使得人口高齡化程度加深。因此,如何妥善解決人口老齡化、高齡化帶來的問題是當今社會的一大挑戰(zhàn),也是關(guān)乎民生和國家發(fā)展全局的大事。
2021年3月國務(wù)院頒布了《中華人民共和國國民經(jīng)濟和社會發(fā)展第十四個五年規(guī)劃和2035年遠景目標綱要》,在完善以居家為基礎(chǔ)、社區(qū)為依托、機構(gòu)為補充的基本養(yǎng)老服務(wù)體系的基礎(chǔ)上提出構(gòu)建居家社區(qū)機構(gòu)相協(xié)調(diào)、醫(yī)養(yǎng)康養(yǎng)相結(jié)合的養(yǎng)老服務(wù)體系。在養(yǎng)老資源緊缺的背景下支持家庭承擔養(yǎng)老功能,利用存量資源發(fā)展嵌入式養(yǎng)老,使老年人居住家中的同時接受社區(qū)提供的專業(yè)護理。加之大多數(shù)老年人具有慢性病需要長期護理、出行不便等原因,家庭護理服務(wù)應(yīng)運而生。家庭護理服務(wù)是指在患者家中提供復(fù)雜、協(xié)調(diào)醫(yī)療以及輔助醫(yī)療服務(wù),是傳統(tǒng)住院治療的替代方案,旨在避免不必要的住院和再住院。家庭護理在滿足老年人居住在家中的條件下為其提供專業(yè)的醫(yī)療、護理服務(wù),能夠有效緩解老齡化帶來的壓力。我國政府部門從80年代末開始關(guān)注家庭護理,2009年將家庭護理列為實現(xiàn)人人享有基本醫(yī)療服務(wù)這一目標的重要舉措之一[2],國內(nèi)家庭護理主要由大醫(yī)院門診設(shè)立的延伸護理中心以及社區(qū)衛(wèi)生服務(wù)中心提供上門護理服務(wù),服務(wù)的內(nèi)容主要包括專業(yè)人員提供的注射、康復(fù)訓(xùn)練、心理指導(dǎo)等專業(yè)服務(wù)以及非專業(yè)人員提供的日常生活照料服務(wù)。
區(qū)域劃分作為家庭護理服務(wù)的中期決策旨在將小的地理單元根據(jù)相關(guān)標準分組為大型的地理區(qū)域,Lin等[3]認為當區(qū)域劃分的結(jié)果滿足標準時就會被認為是一個好的分區(qū)。Benzarti 等[4]對家庭護理服務(wù)區(qū)域劃分所要達到的標準做出了概括,主要分為地理標準、護理工作標準、不同區(qū)域劃分方案比較的標準和組織標準。地理標準主要考慮的是緊湊性、地理單元之間的連接性以及每個區(qū)域包含地理單元的數(shù)量。緊湊性標準是指每個區(qū)域的形狀應(yīng)該盡可能是圓形或者是正方形。Ríos-Mercado 等[5]認為每個區(qū)域內(nèi)的任意兩個地理單元之間不應(yīng)該出現(xiàn)其他區(qū)域的地理單元,即避免出現(xiàn)相互包含關(guān)系。護理工作標準是指平衡每個區(qū)域的護理工作量,護理工作量主要由旅行工作量和直接護理工作量組成,該標準主要是為了滿足護理人員公平分配工作量的愿望。不同區(qū)域劃分方案比較的標準主要指尊重行政區(qū)域邊界,Seda Yan?k等[6]在涉及跨期分配時為了保證護理工作的連續(xù)性應(yīng)使兩個時期的區(qū)域劃分結(jié)果變動盡可能小。組織標準涉及兩方面,第一方面是地理單元的不可分性即一個地理單元只能分配給一個區(qū)域,這樣可以保證護理人員與需求者建立穩(wěn)定的長期關(guān)系,避免了責任糾紛。另一方面是區(qū)域劃分數(shù)量,在絕大多數(shù)家庭護理區(qū)域劃分的文獻中假定區(qū)域劃分數(shù)量是預(yù)先設(shè)定的。
現(xiàn)有研究主要用選址-分配模型和集合劃分模型來解決區(qū)域劃分問題,設(shè)施選址模型最近被證明可以用于解決區(qū)域劃分問題[7]。選址-分配模型和設(shè)施選址模型的區(qū)別在于選址-分配模型的區(qū)域中心需要預(yù)先設(shè)定,設(shè)施選址模型則不需要設(shè)定中心點,任意地理單元都可以作為中心點。為了在適當?shù)臅r間找到可接受的方案,Lin等[8]認為有必要采用啟發(fā)式算法對區(qū)域劃分問題進行求解,因為啟發(fā)式算法可以較為靈活的處理目標和約束,許多研究者采用不同的啟發(fā)式算法進行求解。
在家庭護理實際運營過程中已有學(xué)者提出應(yīng)該將護理人員和服務(wù)內(nèi)容進行分級,元彪等[9]在考慮人員調(diào)度問題時考慮了多類型護理服務(wù)人員,Mankowska 等[10]提出了由于客戶需求的不同,需要找到具有相對應(yīng)技能的護理人員進行護理,即假設(shè)每類護理人員只能服務(wù)部分需求者。陶楊懿、劉冉[11]在考慮同時服務(wù)需求的情況下提出不同等級的護理人員具備不同的能力,劃分等級能夠優(yōu)化人員配置并節(jié)約成本。Schwarze 等[12]提出應(yīng)根據(jù)服務(wù)提供者的能力和需求內(nèi)容進行劃分,高層級人員具有低層級人員不具有的技能和知識,能夠服務(wù)所有的客戶,低層級人員僅能進行簡單的服務(wù)。席恒[13]基于經(jīng)濟、家庭支持條件以及個體差異的調(diào)查研究在2015年提出解決中國養(yǎng)老護理服務(wù)供求不匹配的矛盾應(yīng)針對不同人群的需求進行分層分類,提高供給的精度和準度。
現(xiàn)有文獻中關(guān)于家庭護理區(qū)域劃分的研究僅考慮單一層級的護理服務(wù),而沒有考慮由于需求存在差異性需要對護理人員和護理內(nèi)容進行分級,這將造成供需不匹配、服務(wù)質(zhì)量不高、運營成本過高的現(xiàn)象。本文在家庭護理運營管理中考慮分級護理服務(wù),即根據(jù)客戶所需服務(wù)對護理人員進行分類分級,讓高層級護理人員滿足較為復(fù)雜的護理服務(wù)需求,低層級護理人員提供簡單的護理服務(wù)這使得區(qū)域劃分能夠更精細化的平衡工作量從而能夠提高護理人員工作效率。同時,通過區(qū)域劃分最小化選址建設(shè)和護理人員工資兩類運營成本,使得模型更具實際意義。
1 問題描述與模型構(gòu)建
1.1 問題描述
本文所考慮的區(qū)域劃分問題是將I個地理單元劃分到M 個區(qū)域中,并在每個區(qū)域中選擇一個地理單元作為中心點。地理單元I={1,…,i}是一個代表著人口數(shù)量、護理服務(wù)需求的區(qū)域,每一個地理單元用坐標表示為(ix,iy),代表該區(qū)域的總需求。其中每個地理單元的需求分為3 個層級,每一層級的服務(wù)需求人數(shù)是預(yù)先給定的。區(qū)域劃分數(shù)量M 是由管理者預(yù)先設(shè)定的,但是區(qū)域中心并未確定,區(qū)域內(nèi)任意一個地理單元均可作為區(qū)域中心。一旦地理單元i 被選為區(qū)域中心,則在該點建設(shè)相應(yīng)護理服務(wù)所需的固定設(shè)施,并為該區(qū)域內(nèi)的其他地理單元提供護理服務(wù)。區(qū)域劃分結(jié)果D={D1, D2,…,其中Dp表示由地理單元組成的區(qū)域,Dp∩Dk= ?,?p,k ∈M且p≠k,如圖1所示。
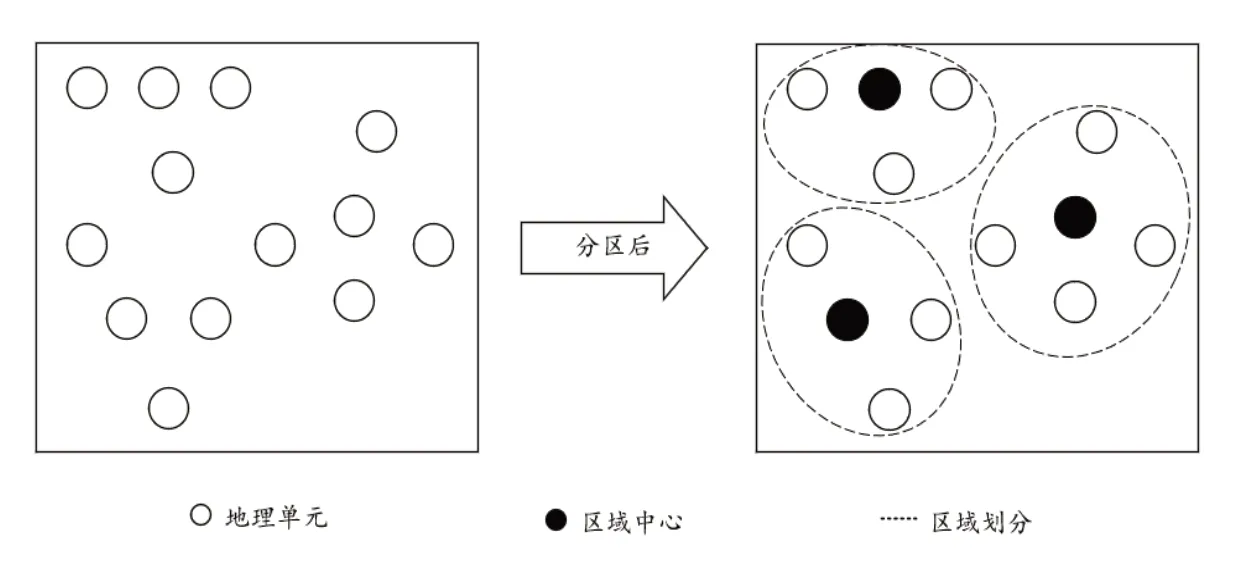
圖1 區(qū)域劃分圖示
本文根據(jù)以下標準進行區(qū)域劃分:
1.1.1 工作量平衡
工作量平衡使得分配較公平,從而能夠提高護理人員的工作效率及服務(wù)質(zhì)量,是區(qū)域劃分的主要目標之一。工作量由旅行工作量和直接護理服務(wù)工作量組成。旅行工作量與區(qū)域的緊湊性相關(guān),直接護理服務(wù)工作量與護理需求人數(shù)和護理服務(wù)時長相關(guān)。之前的研究者在區(qū)域劃分問題上僅考慮了單一層級的護理服務(wù),但在現(xiàn)實護理服務(wù)中由非專業(yè)護理人員提供日常生活照料服務(wù)、低級護理人員提供基礎(chǔ)性醫(yī)療護理服務(wù)、高級護理人員或全科醫(yī)生提供專業(yè)醫(yī)療護理服務(wù),3 個層級的護理人員提供相互獨立的服務(wù)。工作量平衡時應(yīng)考慮每個層級的護理人員工作量平衡而不僅僅考慮總工作量平衡,這樣才能使分區(qū)更加合理并提高工作效率。
1.1.2 運營成本最小化
區(qū)域劃分作為家庭護理服務(wù)中期決策問題應(yīng)考慮其運營成本,主要包括選址建設(shè)成本以及人員工資成本,最小化運營成本可使得區(qū)域劃分更具有經(jīng)濟意義。由于資金的有限性,需要對區(qū)域進行劃分并確定每個區(qū)域配備各個層級護理人員的數(shù)量。每個層級的護理人員在有需求的情況下才提供相應(yīng)的服務(wù),在工作時間滿足服務(wù)需求的情況下不出現(xiàn)人員閑置。
1.1.3 距離最小化
距離最小化可使得區(qū)域劃分具有緊湊性、連接性并使得護理人員旅行工作量最小化。減少旅行時間能減少服務(wù)需求者等待時間并增加直接護理服務(wù)時間使得護理服務(wù)變得更加有效率,因此我們采用了最小化函數(shù)使得區(qū)域具有緊湊性。
為了使研究問題不失一般性,我們對模型做了如下假設(shè):
(1)區(qū)域劃分屬于首次劃分,區(qū)域一旦劃分完成將在很長一段時間內(nèi)保持不變。
(3)當老年人申請護理時需要的護理服務(wù)內(nèi)容、層級已知。
(4)每個區(qū)域的老年人對每種服務(wù)的需求都是確定的。
(5)老年人的護理需求都得到滿足。
(6)假設(shè)同一層級護理人員的護理技能、水平一致,高層級護理人員在護理范圍、醫(yī)療技術(shù)、熟練度等方面均優(yōu)于低層級護理人員。
(7)所有地理單元都將被劃分到相應(yīng)的區(qū)域。
1.2 符號說明
本文主要參數(shù)和變量的含義如表1、表2所示。
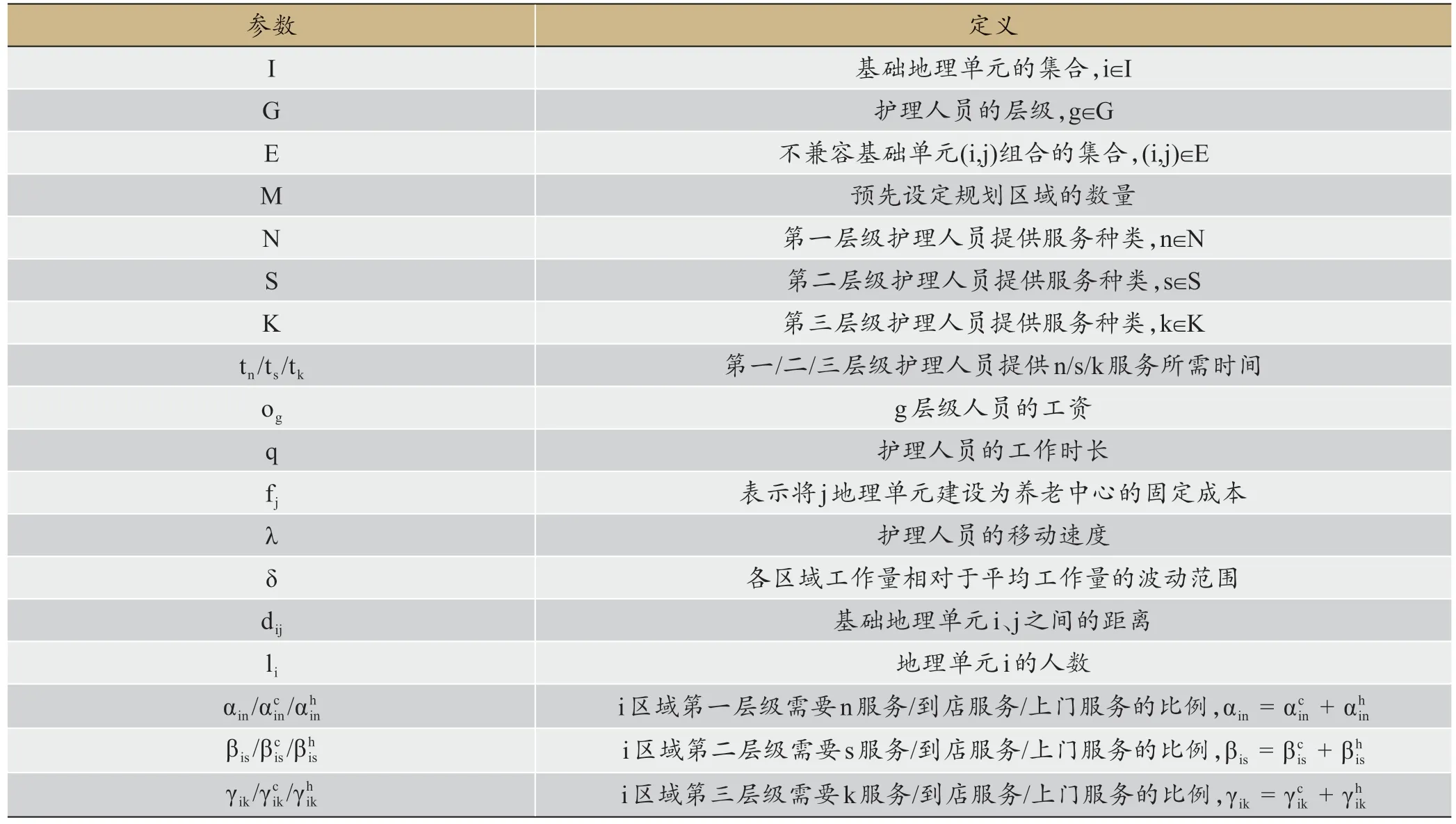
表1 集合與參數(shù)及定義

表2 變量符號及定義
1.3 數(shù)學(xué)模型
對于該區(qū)域劃分問題我們建立了混合整數(shù)規(guī)劃模型:
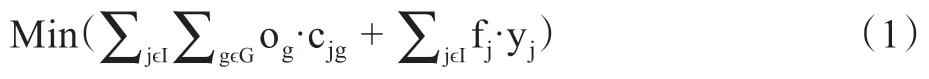

目標方程(1)表示最小化選址成本和各個層級人員工資成本。目標方程(2)通過最小化每個區(qū)域中心點到區(qū)域內(nèi)各個地理單元的距離之和來使得區(qū)域劃分具有緊湊性。約束(3)規(guī)定了地理單元的不可分性,即每個地理單元只能分配給一個區(qū)域。約束(4)限制了劃分區(qū)域數(shù)量為M。約束(5)表明只有當?shù)乩韱卧猨選作區(qū)域中心時地理單元i 才能分配給j。約束(6)規(guī)定了不兼容的地理單元和距離超過規(guī)定的地理單元不能分在同一個區(qū)域。約束(7)至(9)規(guī)定了每個區(qū)域的第一/二/三層級護理工作量等于直接護理時間加上旅行時間。約束(10)至(12)分別表明每個區(qū)域的一/二/三層級護理人員在工作時間內(nèi)完成護理服務(wù)。約束(13)至(15)限制了區(qū)域j每個層級的工作量相對于均值的波動范圍,保證了護理工作量平衡。約束(16)至(18)規(guī)定了決策變量的取值范圍。
2 快速非支配排序遺傳算法設(shè)計及改進
上述模型是一個混合整數(shù)規(guī)劃模型,變量和約束較多,求解復(fù)雜性會隨著問題規(guī)模的增大而快速增加,適合采用智能優(yōu)化算法求解。本文在標準快速非支配排序遺傳算法的基礎(chǔ)上根據(jù)區(qū)域劃分模型特點設(shè)計并改進算法,主要體現(xiàn)在以下幾個方面:首先,設(shè)計了一種固定分段的實數(shù)編碼方式以提高算法求解效率;其次,利用貪婪算法產(chǎn)生較好的初試解并分別設(shè)計了3種依概率進行選擇的交叉、變異算子,擴大了染色體的采樣空間從而避免早熟;最后,在目標函數(shù)中加入罰函數(shù)解決了約束中工作量不平衡的問題。改進的算法主要操作步驟流程如圖2所示:
傳統(tǒng)金融信用評估模型雖然可以在信用風險評估中具有一定評估作用,但是大數(shù)據(jù)的出現(xiàn)導(dǎo)致其數(shù)據(jù)出現(xiàn)了更多的信息維度。除了交易結(jié)構(gòu)數(shù)據(jù)本身,還有大量的其他類型數(shù)據(jù),如:企業(yè)水電數(shù)據(jù)、企業(yè)高管人員數(shù)據(jù)、相關(guān)企業(yè)信息數(shù)據(jù)等,上述數(shù)據(jù)均不兼容于傳統(tǒng)評估模型,導(dǎo)致最終信息出入較大,所以必須設(shè)計新的金融信用評估模型。這就需要利用大數(shù)據(jù)下的信用評估分析,原理如圖1所示。
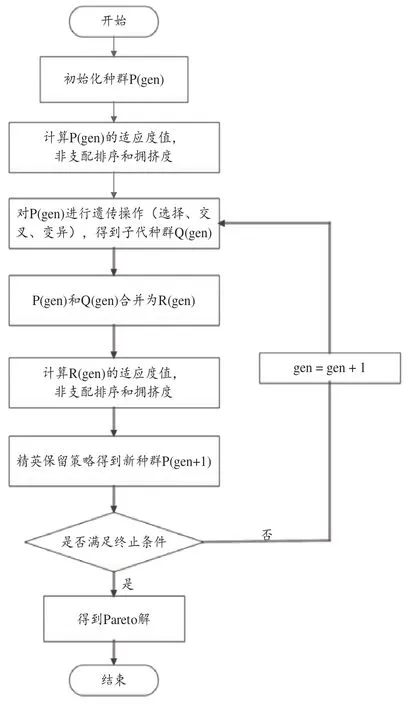
圖2 算法流程
2.1 染色體編碼
采用傳統(tǒng)二進制對區(qū)域劃分問題編碼會導(dǎo)致染色體長度過長并增加計算量,因此采用異于傳統(tǒng)編碼的實數(shù)編碼方式。染色體共有M+1個基因段,前M個基因段代表區(qū)域劃分的方案,最后一個基因段分別表示目標函數(shù)值、非支配排序以及擁擠度。特別的,在交叉、變異環(huán)節(jié)只對前M 段染色體進行操作。染色體編碼方式如圖3所示。

圖3 染色體構(gòu)成
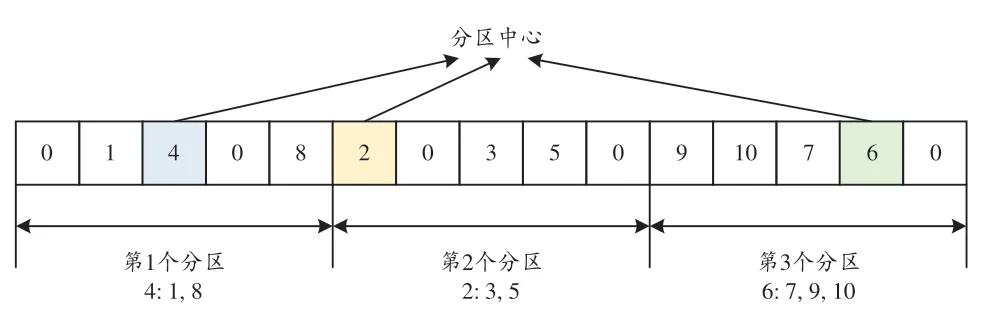
圖4 染色體編碼示例
2.2 適應(yīng)度函數(shù)
將分別代表總成本和總距離的雙目標函數(shù)設(shè)置為適應(yīng)度函數(shù),同時把護理工作量平衡約束轉(zhuǎn)化為罰函數(shù),當工作量不平衡時罰函數(shù)將取一個很大的罰值并導(dǎo)致該染色體由于適應(yīng)度函數(shù)值過高而被淘汰,達到了平衡工作量的目的。
2.3 初始化種群
采用貪婪算法初始化種群,首先從N 個地理單元中隨機選擇M 個點作為區(qū)域中心點,再分別計算其余N-M個地理單元到M 個中心的距離,將地理單元分配給距離其最近的中心點。當距離最近的中心點包含地理單元數(shù)量大于時,則將該地理單元分配給距離第二近的中心點。以此類推,直到N-M 個地理單元都分配完畢,得到一種分配方案即一個染色體。對初始化種群進行快速非支配排序和擁擠度計算[14]。
2.4 選擇、交叉、變異
通過二進制錦標賽算子進行選擇操作,在兩個染色體中優(yōu)先選擇等級低的染色體,假如兩個染色體等級一致則選擇擁擠度較大的染色體。
根據(jù)染色體編碼方式設(shè)計了3種依概率選擇的交叉算子,具體交叉操作過程如下:首先,隨機選擇兩個切點獲得交叉片段POP1 和POP2。若交叉片段的基因全是0,則重新選擇直到兩個交叉片段都不全為0。刪除兩個交叉片段中的0,只留下表示地理單元序號的基因,得到POP3 和POP4。將父代A 中與POP4 相同的基因刪除,父代B 中與POP3 相同的基因刪除后再根據(jù)交叉概率將POP3、POP4 插入到B、A 的前部、中部和尾部得到新的染色體。3種交叉方式的示例具體如圖5所示:
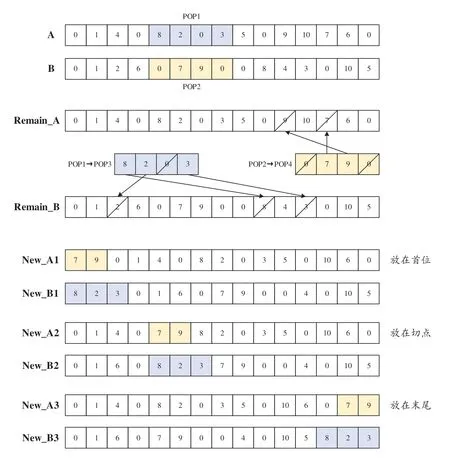
圖5 染色體交叉互換示例
在變異操作中同樣設(shè)計了依變異概率不同而進行選擇的3個變異算子,增加了染色體的多樣性,使得算法盡可能的在全局搜索,避免過早收斂。第一種變異算子是切點互換,將染色體i 位置的基因與j 位置的基因互換;第二種變異算子是單鏈翻轉(zhuǎn),在染色體中截取一個片段,并對該片段的染色體進行倒序排列,其余基因位的染色體不變;第三種變異方式為單鏈重組。首先對染色體進行切片,剩余基因位按順序合并,然后將切片放在整條染色體最后,3種變異方式如圖6所示。

圖6 染色體變異
2.5 合并父代子代種群
合并父代和子代種群進行非支配排序和擁擠度計算,并通過精英保留策略選擇優(yōu)質(zhì)染色體作為新的父代進入下一輪迭代[15]。
3 算例分析
通過算例與敏感度分析證明模型、算法的有效性,并且能夠用于解決多層級家庭護理服務(wù)區(qū)域的問題。為了證明對護理內(nèi)容、人員進行分級的合理性和必要性,采用成本分析比較單一層級和多層級護理人員在運營成本和總工作量上的差異。
3.1 參數(shù)設(shè)置
由于不存在家庭護理服務(wù)區(qū)域劃分的標準算例,所以選取編號為R101 的Solomon 標準數(shù)據(jù)集的前30 個地理坐標作為算例的地理單元。下表給出參數(shù)的具體生成方法,其中U [a,b]表示均勻分布,兩個點之間的距離dij由歐式距離進行計算(表3)。
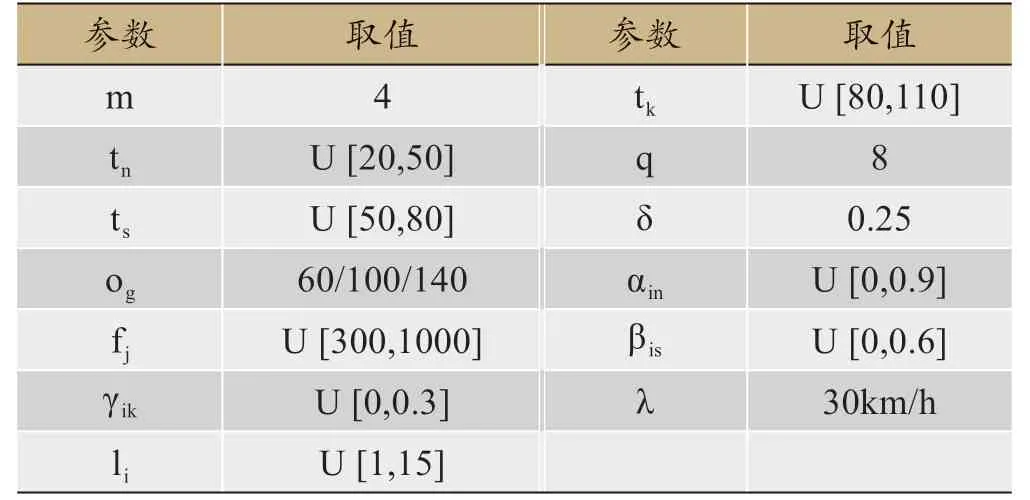
表3 參數(shù)數(shù)據(jù)
算法使用matlab_R2020b 進行編程實現(xiàn),運行CPU為2.4GHz Intel core i7,內(nèi)存8GB。參數(shù)設(shè)置種群規(guī)模pop=200,初始種群規(guī)模greedy size=2000,最大進化代數(shù)gen=200,交叉概率pc=0.8,變異概率pm=0.3,競標賽選手個數(shù)tour=4。
3.2 結(jié)果分析
根據(jù)數(shù)據(jù)產(chǎn)生方式隨機生成數(shù)據(jù),運用快速非支配排序遺傳算法以總成本最低和距離最小化為雙目標同時加入工作量平衡的罰函數(shù)進行求解并得到滿意的分配方案。運行多次求解,其中一次運行結(jié)果的帕累托前沿如圖7所示。同時,分別記錄每次迭代中目標函數(shù)1和目標函數(shù)2的最小值,將其結(jié)果展示在圖8中。由圖8可知,f1 和f2 在后期平穩(wěn)收斂,因此本文改進的算法具有收斂性。
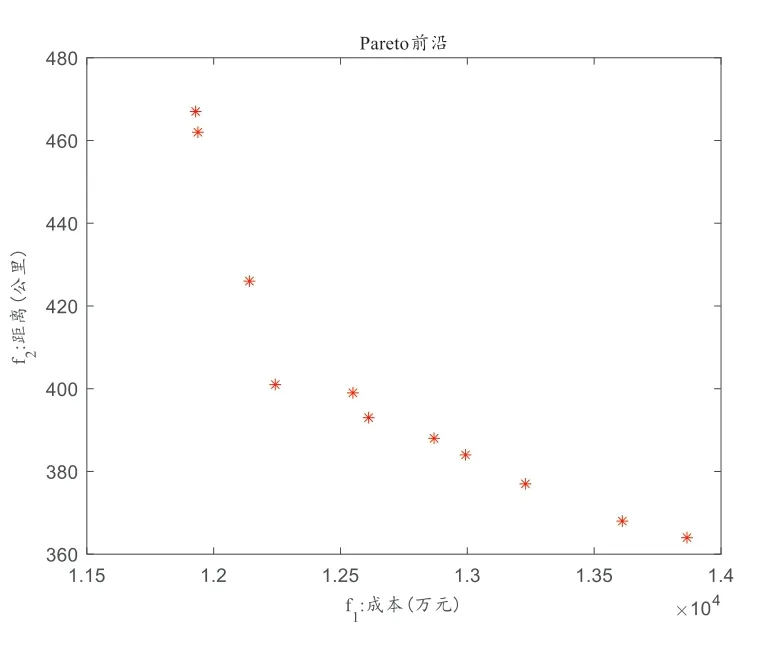
圖7 pareto前沿
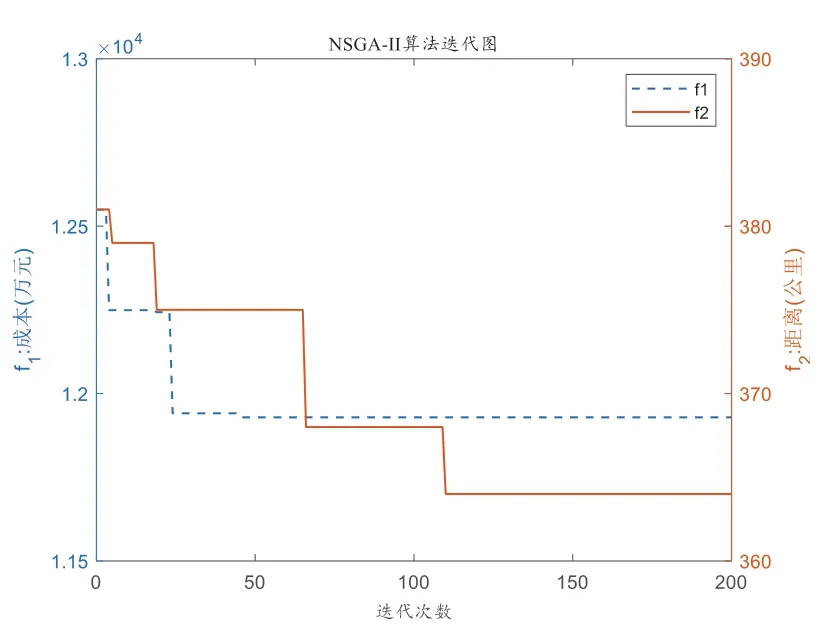
圖8 迭代圖
以圖7中一個區(qū)域劃分方案為例進行展示,模型求解得到4 個區(qū)域中心點分別為11、6、23、13,區(qū)域1 為[11,10,2,21,12,20,8],區(qū)域2 為[6,7,14,9,15,17,18,19],區(qū)域3為[23,26,3,5,24,16,22],區(qū)域4 為[13,30,25,1,28,4,27,29]。區(qū)域劃分方案進一步在空間平面上表示為圖9。
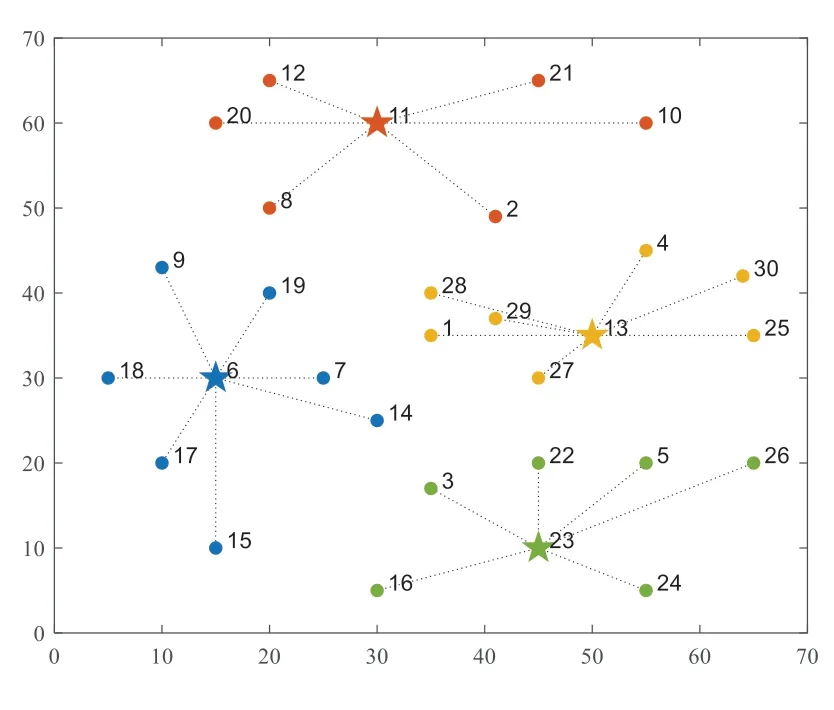
圖9 區(qū)域劃分結(jié)果
3.3 參數(shù)敏感性分析
為了證明不同參數(shù)對區(qū)域劃分結(jié)果的影響,本文對各區(qū)域工作量相對于平均工作量的波動范圍、需求量進行敏感性分析,具體過程如下所示:
(1)各區(qū)域工作量相對于平均工作量的波動范圍δ敏感性分析
本節(jié)針對各區(qū)域工作量相對于平均工作量的波動范圍δ進行敏感性分析,δ值越小代表每個區(qū)域的工作量更加均衡,值越大表示允許波動范圍越大。設(shè)置δ 為15%、25%、40%。如圖10 所示,隨著δ 值的減少,總距離和總成本均上升。因為護理工作量越均衡會導(dǎo)致距離較遠但使得工作量平衡的點分在同一個區(qū)域,導(dǎo)致距離增大,減弱了緊湊性。同時距離增加導(dǎo)致旅行工作量上升,因此總成本也隨之上升。
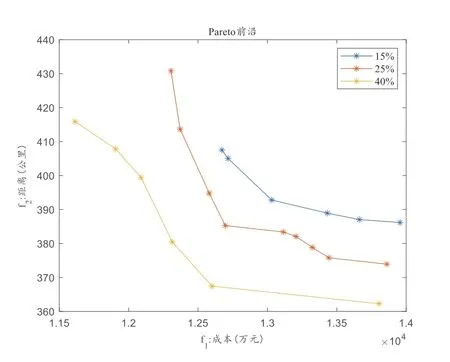
圖10 δ敏感性分析
(2)需求量敏感性分析
本節(jié)對不斷增長的需求進行敏感性分析,假設(shè)3 種層級護理服務(wù)的需求分別增長0%,50%,100%。如圖11所示,需求的增長導(dǎo)致總成本迅速增加,因為需求量的增加導(dǎo)致護理服務(wù)人員數(shù)量增加,工資成本也相應(yīng)的增加。總距離并未顯著變化,因為護理需求量的增加不會導(dǎo)致每個分區(qū)距離之和的較大變化。
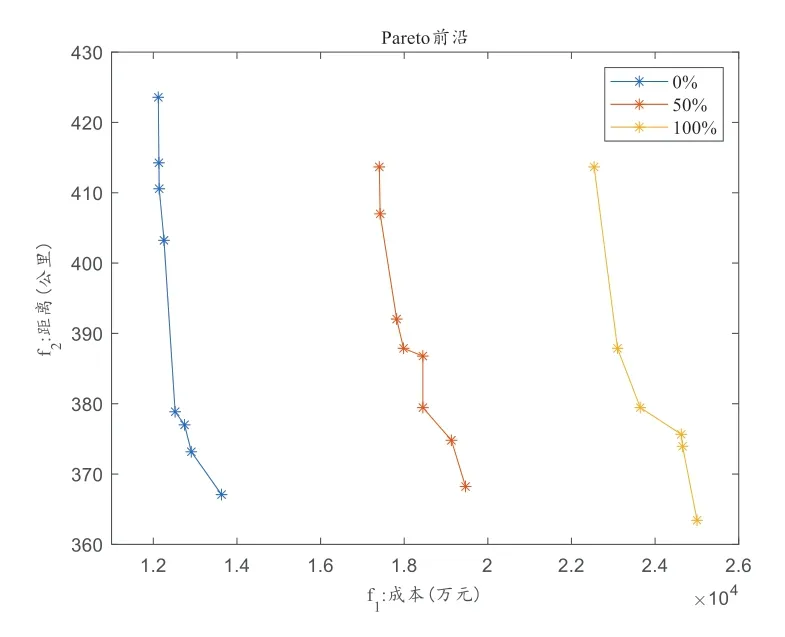
圖11 需求敏感性分析
3.4 成本分析
本文研究分級家庭護理服務(wù)區(qū)域劃分問題的意義在于通過對護理人員、護理內(nèi)容進行分級,合理配置各級工作人員使得各個區(qū)域每個層級的護理工作量平衡以及最小化建設(shè)和運營成本。本文分別對僅使用單層級護理人員和多層級護理人員在總工作量和工資成本的差別進行分析。假設(shè)單層級采用最高層級護理人員進行護理服務(wù),因為高層級護理人員具備優(yōu)于低層級護理人員的專業(yè)能力以及擁有更高的熟練度,所以可以完成低層級的護理任務(wù)并且時間約為低層級護理人員的[16]。因此,同樣的護理工作第三層級護理人員花費時間約為第二層級護理人員的、第一層級護理人員的為了避免實驗結(jié)果具有偶然性,分別進行30 個地理單元、40 個地理單元、50 個地理單元區(qū)域劃分的數(shù)值模擬實驗,每一組實驗進行10次。為了排除由于地理單元數(shù)量增加對總工作量造成影響,設(shè)置區(qū)域劃分數(shù)量分別為4、5、6,其余數(shù)據(jù)產(chǎn)生方式均與表3一致。實驗結(jié)果如表4所示,其中變化量=,MWi為第i 次試驗多層級工作量/總工資,SWi為第i 次試驗單層級工作量/總工資,分別取10 次實驗變化幅度中的最大值、最小值和均值的變化進行展示。計算結(jié)果表示在其他因素保持一致的情況下,多層級與單層級在工作量、工資之間的差別。

表4 多層級和單層級的成本比較
通過3 組實驗可知分級護理服務(wù)增加了總工作量,工作量平均值較單層級分別增加了23.79%、22.47%、19.08%,原因可能是高層級護理人員的工作效率高于低層級護理人員,單層級全部采用高層級護理人員將減少總的護理時間,因此總工作量少于分級護理的總工作量。分級護理的工資成本少于單層級護理,工資成本平均值較單層級分別減少了26.51%、26.27%、27.87%。這是因為現(xiàn)實中大部分護理活動由低層級護理人員即可滿足,高層級護理服務(wù)需求較少,需要較少的高層級護理人員,同時由于低層級護理人員的工資低于高層級護理人員,分級護理服務(wù)區(qū)域劃分可減少了人員工資成本,更加合理的決定所需護理人員結(jié)構(gòu)。
接下來分析各個層級護理人員之間工資差異對總工作量和工資成本的影響,相鄰兩級之間的工資差值分別設(shè)置為0、20、40、80,其余參數(shù)設(shè)置與表3一致。將工資差值為20、40、80 與工資差異為0 進行總工作量和總工資比較,每一組實驗進行10 次,并取其中變化幅度的最大值、最小值并計算均值的變化,其中變化量=,HWi為工資差值為20、40、80 時第i 次試驗的工作量/工資,NWi為工資差值為0 是的第i 次試驗的工作量/工資。實驗結(jié)果由表5所示,工資差異對總工作量并無顯著影響,但隨著工資差值的擴大,總工資成本的平均值較工資無差異時分別減少9.40%、16.22%、34.06%,這主要是由于低層級的需求比例高于高層級的需求比例,因此低層級的護理人員數(shù)量明顯多于高層級護理人員,當各級工資差值過小時會導(dǎo)致低層級護理人員工資過高,進而導(dǎo)致總工資成本增加。這也說明了當各級工資差異越大時,多層級模型相對于單層級模型具有更大的成本優(yōu)勢,因而分層級護理也更為必要。
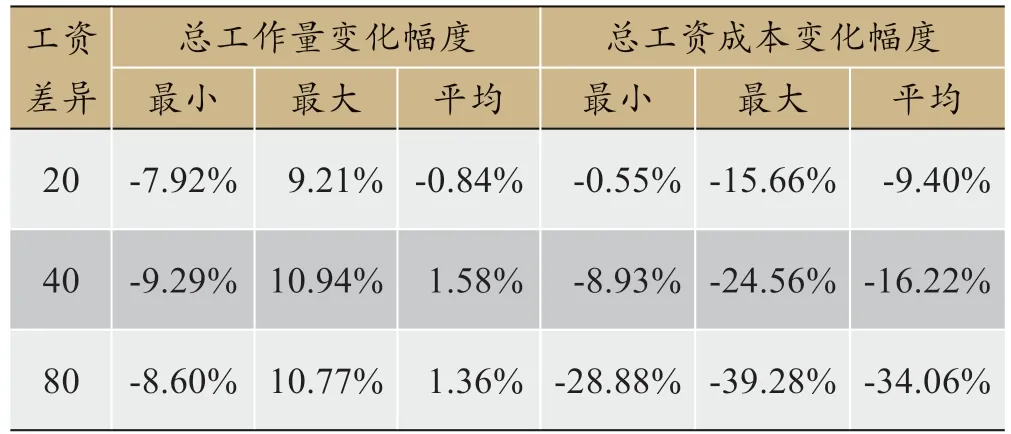
表5 護理人員工資差異的成本比較
4 結(jié)論與建議
本文基于現(xiàn)實生活中所面對的養(yǎng)老需求多樣性,在家庭護理區(qū)域劃分模型中考慮分層級護理服務(wù),以成本最小化和區(qū)域緊湊性為目標建立混合整數(shù)規(guī)劃模型,更好的平衡了護理工作量,提高護理的質(zhì)量和效率。同時,在區(qū)域劃分過程中考慮了最小化建設(shè)成本和護理人員工資兩類運營成本,使得模型更具有經(jīng)濟意義。模型求解采用快速非支配排序遺傳算法,根據(jù)區(qū)域劃分模型特點設(shè)計固定分段的實數(shù)染色體編碼方式,并設(shè)計依概率選擇的3種交叉算子、選擇算子,擴大了染色體的采樣空間。通過對工作量波動范圍、需求量進行敏感度分析驗證了模型和算法有效性,最后通過比較多層級護理人員和單一層級護理人員在成本上的差異證明了多層級護理的必要性。
基于上述研究結(jié)論,本文提出以下建議:
(1)大力發(fā)展家庭護理服務(wù),緩解老齡化壓力。我國家庭護理處于起步階段,應(yīng)在借鑒加拿大、日本等家庭護理起步較早國家成功經(jīng)驗的基礎(chǔ)上完善頂層設(shè)計,建立制度、政策層面的保障。例如建立家庭護理服務(wù)法律體系,明確各方主體職責邊界[17]。其次,制定行業(yè)標準,對家庭護理服務(wù)機構(gòu)的進入嚴格把關(guān),并對其服務(wù)質(zhì)量進行評估和監(jiān)督。最后,加大資金支持,吸引多元主體加入,激發(fā)市場活力。
(2)在家庭護理運營管理中合理分級,提高供求適配度。在需求側(cè)方面借助科學(xué)的需求評估工具在考慮自理情況、經(jīng)濟條件等因素的情況下掌握老年人基本信息并精準評估需求,根據(jù)護理需求的不同性質(zhì)、所需時間、護理服務(wù)的復(fù)雜度等因素并結(jié)合實際合理劃分需求等級,以便進行人力資源配備。在供給側(cè)方面培養(yǎng)多層次養(yǎng)老護理服務(wù)人才,提供多元化服務(wù)滿足各種層次的需求。由于我國護理人員護理水平、學(xué)歷參差不齊,需針對從中職到研究生不同學(xué)歷的人員開展不同層次的培養(yǎng)。
(3)進行家庭護理服務(wù)區(qū)域劃分時應(yīng)考慮不確定因素。區(qū)域劃分是在需求確定、護理服務(wù)時間確定的假定下進行研究的,但在護理服務(wù)中由于老齡化加劇會導(dǎo)致需求量、需求種類的增加,同時護理服務(wù)時間、旅行時間等具有波動性,將其作為確定性參數(shù)會惡化工作量平衡導(dǎo)致不能得到最優(yōu)區(qū)域劃分。
(4)將區(qū)域劃分與家庭護理運營其他決策統(tǒng)籌考慮。區(qū)域劃分往往作為一個獨立的領(lǐng)域進行研究,但資源分配、調(diào)度等問題決策時是在區(qū)域劃分的基礎(chǔ)上進行研究,區(qū)域劃分在很大程度上決定了資源分配、調(diào)度等決策結(jié)果,因此在區(qū)域劃分時將影響短期、超短期決策問題的影響因素納入考慮范圍有助于求解最佳的區(qū)域劃分結(jié)果。
本文通過數(shù)值模擬分析可以得出在區(qū)域劃分模型中考慮分級服務(wù)可更好的平衡工作量和最小化運營成本。但為了簡化模型,本文未能考慮需求、護理時間等因素的不確定性以及未統(tǒng)籌考慮短期、超短期決策問題的影響因素而對模型進行相應(yīng)調(diào)整,后續(xù)將對此做進一步研究。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2020年10期)2020-11-26 08:24:50
數(shù)學(xué)物理學(xué)報(2020年2期)2020-06-02 11:29:24
今日農(nóng)業(yè)(2019年12期)2019-08-15 00:56:32
今日農(nóng)業(yè)(2019年10期)2019-01-04 04:28:15
今日農(nóng)業(yè)(2019年16期)2019-01-03 11:39:20
商周刊(2017年9期)2017-08-22 02:57:56
光學(xué)精密工程(2016年6期)2016-11-07 09:07:19
中國科技博覽(2016年2期)2016-04-25 20:32:39
小學(xué)生導(dǎo)刊(2016年34期)2016-04-11 00:49:44
