基于排序學習的構件檢索方法的研究*
2021-06-25 09:46:06陳華燁汪海濤
計算機工程與科學 2021年6期
陳華燁,汪海濤,姜 瑛,陳 星
(昆明理工大學信息工程與自動化學院,云南 昆明 650500)
1 引言
隨著軟件復用技術的快速發展,通過構件進行軟件開發的方法已經成為了廣大軟件開發人員的主流開發手段。目前對構件的最新定義為在軟件系統中構件具有獨立功能,并且可以通過遵循相同接口規范來進行連接,從而實現復用。而實現復用最大的依賴對象是構件庫,因此,構件庫管理問題已成為構件技術中的研究熱點。對構件進行描述和檢索的方法很多,目前主流的構件描述方法都是采用基于特征或者XML的刻面描述方法[1]。然而,基于特征的方法缺少對特征模型組織框架的詳細研究和解釋,這在一定程度上導致了特征模型的冗余和混亂。針對通過特征模型產生的多維空間的向量,本文提出了一個使用潛在語義分析[2]對多維空間進行降維的方法,在去除了原始向量空間中“噪音”問題的同時,還凸顯了文本的語義特征。
近年來,排序學習方法的出現受到了越來越多的研究者關注,其優點是:結合并優化了大量的排序特征,同時自動進行參數的學習,最終得到一個高效精準的排序模型。并且此方法已很好地應用于信息檢索的檢索模型中[3]。在信息檢索中排序學習的訓練實例是用戶的特征標簽,所以更多復雜的特征被應用到檢索中,比如可通過網頁的PageRank值、查詢和文檔匹配的單詞個數、網頁URL鏈接地址長度等特征來供排序模型進行訓練。通過研究發現,目前具有代表性的構件檢索技術主要集中于基于信息科學的構件檢索技術,比如基于刻面的構件檢索方法[4]、基于本體的構件檢索方法[5]和基于規約描述的構件檢索方法等,但構件檢索在人工智能中的研究并不多。所以,本文通過研究機器學習中的排序學習方法發現,排序學習不僅可以用于信息檢索,其特點及優勢也適用于構件檢索。因此,本文提出一種構件檢索方法,以進行基于排序學習的構件檢索方面的研究。
2 主要研究內容
傳統的檢索模型是依靠人工標注來擬合排序公式,并通過大量的實驗來確定模型參數。而排序學習的方法與此不同,排序學習只需要提供訓練數據給排序模型,排序模型使用訓練數據和排序學習方法自動學習獲得一個合理的排序模型,通過訓練好的排序模型實現檢索。排序模型的實現分為3個步驟:標注訓練數據、文檔特征抽取和訓練排序模型。
在排序學習中,輸入是查詢和一系列標注好相關性的構件,每個構件由若干特征構成,所以每個構件進入排序學習模型之前先將其轉換成特征向量,具體的構件特征將在下文展開。在信息檢索中是通過利用用戶點擊記錄來模擬人工標注機制得到標注訓練數據[6]。本文先將構件轉換成構件特征向量空間,將用向量空間模型表示的特征通過潛在語義分析映射到低維的空間中,這個映射是通過對構件-特征矩陣進行奇異值分解來實現的。然后通過余弦相似度計算來得到標注構件訓練數據集。
在確定了構件的訓練數據后,將構件轉換為〈x,y〉的形式,x為構件的特征向量,y為特征向量對應的標注好的相關性得分,這樣就形成了一個具體的構件訓練實例。得到構件的訓練實例后,通過訓練數據及排序學習中的Listwise方法來訓練模型的參數,從而訓練出最優構件排序模型。在構件檢索中,可以使用這個構件排序模型根據查詢對構件庫中構件的特征進行打分,得到檢索結果。利用排序學習的優勢改進構件檢索方法,從而得到高效準確的構件檢索方法。本文所提方法的整體框架如圖1和圖2所示。

Figure 1 Flow chart of component scheduling model training
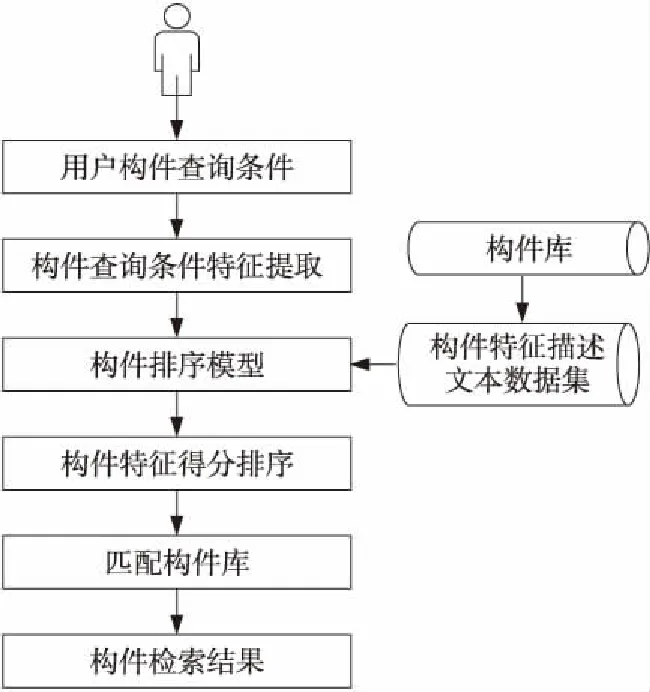
Figure 2 Flow chart of component retrieval system
3 構件相似度計算
本文采用刻面描述的方法,將刻面分為功能語義刻面和非功能語義刻面對構件進行全面描述。刻面分類方案需要遵循4個準則:全面性、一致性、刻面正交和精簡原則[7]。基于以上準則參考3C模型、北大青鳥構件模型[8],選定以下3個刻面:功能刻面、環境刻面和性能刻面,其中功能刻面屬于功能語義刻面,環境刻面和性能刻面屬于非功能語義刻面。這3個刻面由它們的子刻面構成,每個刻面相互無影響,任意2個刻面之間是相互正交的,其術語之間也是相互正交的,本文所用刻面可以描述任意一個構件。具體刻面如圖3所示。

Figure 3 Detailed description of three facets
功能語義刻面描述了構件的詳細功能及其應用領域,如表1中的構件描述信息,出現的形式是一些對構件功能和領域進行描述的具有語義邏輯的自然語言文本段落。傳統的刻面描述只是通過有經驗的專家對文本段落建立構件的刻面值,但隨著構件規模的擴大,越來越多的構件需要分類和檢索,人工建立刻面值的方法越來越不現實和不準確。功能語義刻面也是用戶查詢構件條件的最主要依據。因此,為了減少人為主觀因素,本文提出采用word2vec模型來提取構件的功能語義刻面特征,利用word2vec模型對功能語義刻面中的構件描述信息進行處理轉換成詞向量作為構件特征。而非功能語義刻面是一些特定術語,可應用于多個領域,通過權威文獻[7,8]來設定非功能語義刻面的權重作為構件的非功能語義刻面特征。從構件庫中獲取構件的相關屬性,部分構件表示如表1所示。
對每個構件進行刻面描述后,生成構件刻面描述的特征向量空間。每個構件被描述成由特征詞組成的特征向量,然而此特征向量空間具有高維性和稀疏性,并且構件與構件間的描述特征通常存在一定的相關性,所以向量空間無法解決同義詞和多義詞引起的數據集冗余和詞性歧義的問題[9]。因此,本文引入潛在語義分析中奇異值分解的方法,從而降低向量空間的稀疏性。將提取構件描述文本的特征向量[10]后生成的數據集稱為構件數據集,對構件數據集進行潛在語義分析[6]的具體過程如下所示:
(1)將構件數據集X用成一個v×n的構件-特征矩陣來表示,如式(1)所示:
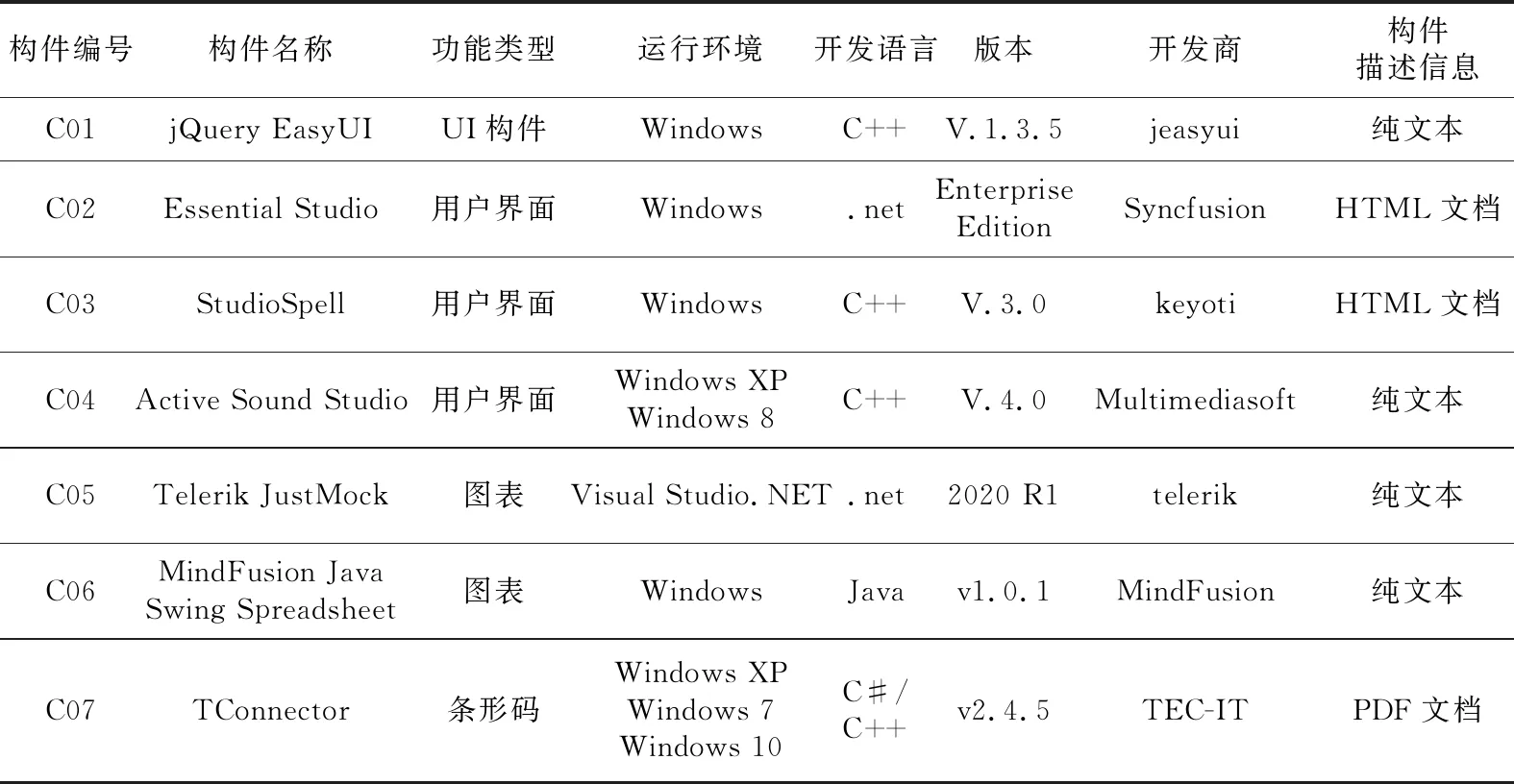
Table 1 List of component-related attributes
A[aij],v?n,1≤i≤v,1≤j≤n
(1)
其中,矩陣A中v為構件的刻面個數,n為同一個刻面下的不同構件的特征向量個數;aij代表矩陣A中構件的特征值的權重。
(2)根據奇異值分解的性質,將矩陣A進行奇異值分解,可表示為:
A=USVT
(2)
其中,U和VT是左奇異向量和右奇異向量構成的矩陣,兩兩相互正交;S是奇異值構成的對角矩陣。
(3)將(2)中分解后的矩陣U、S、V進行降維,使用UK、SK、VK重建構件-特征矩陣:
AK=UKSKVKT
(3)
其中,SK表示矩陣S的前K個奇異值,UK、VK表示相應的保留矩陣U、V的前K個列向量。
使用構件數據集中的一部分數據作為查詢條件數據集Q={q1,q2,…,qq},其中,q1,q2,…,qq為q個構件,將查詢條件數據集也映射到潛在語義空間中。再利用余弦相似度計算查詢條件數據集中的每個查詢條件與構件數據集中的所有構件的相似度。采用余弦相似度的具體計算過程如下所示:
(1)將查詢條件通過潛在語義分析的方式構造查詢向量,并映射到語義空間:
(4)
其中,q*是映射到語義空間的查詢條件向量。
(2)計算q*和xj的相似度:
(5)
其中,xj是第j個構件的特征向量,k是向量空間的維數,aqm,ajm分別為q*、xj中的第m維權值。
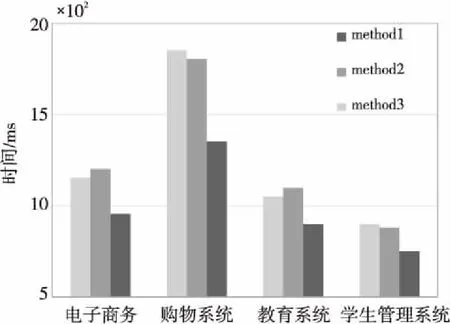
使用潛在語義分析與余弦相似度得到排序學習中準確度高的構件訓練數據集,以利于排序模型訓練得到高精確性的排序模型。當得到關于查詢條件數據集與構件數據集中的相對關系后,將該關系進行標注。例如:若Sim(q*,xj) σ∈Ω,且σ={σq1,σq2,…,σqi},1 (6) 其包含T個獨立查詢條件數據集,Ω為構件數據集的全排序集合。 常見的排序學習方法分為3種,即逐點方法(Pointwise Approach)、成對方法(Pairwise Approach)和列表方法(Listwise Approach)[11]。其中,Pointwise方法將訓練集中每一個文檔視為一個訓練實例;Pairwise方法將同一個査詢的搜索結果中任意2個文檔對作為一個訓練實例;而本文采用的Listwise方法是將每一個查詢的所有搜索結果列表整體作為一個訓練實例[8]。 本文提出的構件排序學習模型,使用Listwise方法把訓練的樣本空間定義為對構件數據集的所有可能的排列,而每個排列出現的概率是在構件特征選擇過程中對構件特征的打分決定的,所以可以合理地使用概率模型定義一個構件排序之后任意排序所出現的概率。因此,本文使用P-L(Plackett-Luce)概率排序模型[12]來訓練構件排序模型,通過Listwise方法對P-L模型構造排序模型的損失函數,同時,通過增加次要函數對預測的特征得分進行約束,并將最大似然估計MM(Minorize-Maximization)算法用于P-L模型的參數估計,從而提高排序性能,得到最優構件排序模型。 Plackett和Luce提出的P-L模型是一種典型的基于分數的概率排序模型,本文采用Plackett-Luce概率排序模型進行模型訓練。而P-L模型的另一個特點是可以處理訓練實例的不完整信息的排序。 (7) 其中,M是評分向量的個數。 構件訓練數據集并不是具有完整構件信息的排序,構件與查詢條件相似度閾值的設置去除了相似度太低的構件排序信息。但是,P-L模型可以處理不完整信息的排序,基于式(7)表示如下: Boys enjoy rugby,but the most popular sport for girls is netball(無擋板籃球).It is similar(相似的)to basketball,but players don’t run with the ball. (8) 其中,k表示構件訓練數據的排序構件數量,由式(8)可以看出,構件的排序數量是影響其概率分布的唯一要素。 通過Listwise方法來定義關于真實排序y(i)和預測排序的損失函數[13],并通過訓練損失最小化來學習排序函數的參數。將所有構件訓練數據集的可能性損失之和最小化,即可將似然損失函數定義如式(9)所示: l(〈w,x(i)〉,y(i))=-logP(y(i)|x(i),w) (9) 其中,logP(y(i)|x(i),w)可以通過P-L模型計算得到,所以,根據P-L模型得到以下關系: (10) 其中,y(i)表示真實排序,〈w,x(i)〉為u的分解向量,x(i)為構件訓練數據集中的構件排序,R為構件訓練數據集中每個構件排序中的排序數量,x(i,y-1(l))為當排序在y-1(l)時x(i)的排序,l和k′為計數變量,最大似然估計由最大化對數似然函數給出: (11) 為了擬合L(u),本文采用不等式來構造次要函數: -lna≥1-lna-a/b (12) 其中,向量a和b中各元素都大于0。使用w和w(t)來替換a和b,并采用MM 算法來求解P-L模型的最大似然估計參數[14],通過每次迭代最大化一個初始函數求解式(12)。通過構造次要函數改進P-L模型的對數似然函數,得到以下改進的對數似然函數: Qt(w|w(t))= (13) (14) 可以由排序空間Ω上的概率分布P(·|u*)得到與查詢文本相關的預測排序,即具有最高后驗概率的排序: x*∈arg maxx∈Ωp(x|u*) (15) 算法1構件排序模型 輸入:查詢條件集qi,構件數據集X。 輸出:最優排序x*。 步驟1使用刻面描述方法得到構件信息文本集,通過word2vec模型和權重設定來提取構件信息文本集的特征向量作為構件數據集,將其作為輸入數據,對構件數據集生成的特征向量矩陣使用奇異值分解構造潛在語義空間。 步驟5使用MM算法對改進的對數似然函數Qt(w|w(t))進行迭代更新參數wt+1,直到得到最大化參數w*,最后通過得到的參數w*按降序的關系對構件進行排序,得到最優構件排序模型。 實驗分為2步,第1步是構件排序模型訓練,使用潛在語義分析與余弦相似度得到的標注構件訓練數據集,結合構件數據集通過P-L概率排序模型進行排序模型訓練。第2步是實現構件檢索系統,以構件排序模型為核心開發實現一個構件檢索系統。 模型訓練所用數據集為RepoReapers公開數據集,其中包含100多萬條離線的GitHub數據鏡像。本文在RepoReapers上隨機收集了大約10萬條構件數據集,采用word2vec模型將功能語義刻面的構件描述信息文本轉換成詞向量,所用的語料庫是中文維基百科與構件訓練數據中的描述信息語料。對每個構件描述信息文本的輸入長度進行處理,設置輸入序列長度為500,長度小于500的序列補零。通過word2vec模型和權重設定提取構件的特征向量作為構件數據集。設置數據集上的五折交叉驗證范圍,將構件數據集分為5個部分,在每次實驗中,3/5用于訓練,1/5用于驗證,1/5用于測試,并將3/5的訓練數據中的1/4的數據作為查詢條件數據集。進行余弦相似度計算時設置相似度閾值為Ths。 本文使用改進的P-L模型(model1)、Mallows模型[15](model2)和廣義線性模型[16](model3)進行性能對比。采用NDCG(Normalized Discounted Cumulative Gain)作為評估指標。NDCG是用來衡量排序質量的指標,實驗設置排序列表中序列k分別為{5,10,15,20}的值進行評估。 該實驗基于構件排序模型實現了一個構件檢索系統,其開發環境為CPU:i7-9750H 2.60 GHz,操作系統為Windows 10,開發語言為Python,數據庫使用MySQL;開發工具是PyCHarm,實驗數據從CodeProject、GitHub網站和中國BIM構件庫網上下載相關構件285個,其中包含以下幾個領域:教育系統76個、網購系統82個、電子商務43個和高校學生管理系統84個。將285個構件通過刻面進行描述后入庫,利用Python進行文本分詞及關鍵字提取,采用TF-IDF方法計算構件描述文本中關鍵詞權重。 實驗中,主要使用基于刻面的構件檢索方法(method1)、基于本體的構件檢索方法(method2)和本文提出的基于排序學習的構件檢索方法(method3)進行對比實驗,評估標準主要是查全率(查全率=檢索到的相關構件數/所有相關構件數)、查準率(查準率=檢索到的相關構件數/檢索到的構件數)[17]和檢索效率。 對各個模型的排序準確度評估如圖4所示,由圖4可以看出,本文提出的排序模型在構件中的使用是有效的,采用3種概率模型對構件訓練實例進行排序評估。圖4中,Mallows模型(model2)與改進的P-L模型(model1)具有一定的競爭力。因為Mallows模型善于解決構件完整信息的模型分布,而P-L模型可以很好地處理不完整的排序信息,所以當設置相似度閾值后,出現不完整的標注信息時,P-L模型的準確度高于Mallows模型的。廣義線性模型(model3)首先對訓練數據進行分類,在預測每個構件的類別概率后進行排序,僅使用廣義線性模型不能很好地處理復雜決策邊界問題,因為線性方法的強偏差妨礙了數據的良好分離。因此,model3的排序性能低于model1和model2的。 Figure 4 Comparison of NDCG sorting accuracy 在大量實驗的基礎之上,本文將幾個領域內的構件進行多次測試檢索實驗并與傳統檢索方法對比,綜合數據統計檢索結果如圖5~圖7所示。 Figure 5 Comparison of the recall Figure 6 Comparison of precision 從圖5和圖6可以看出,本文提出的基于排序學習的構件檢索方法(method3)的查全率和查準率高于傳統的基于刻面的構件檢索方法(method1)和基于本體的構件檢索方法(method2)。因為相比于基于刻面的構件檢索方法和基于本體的構件檢索方法,本文采用的潛在語義分析彌補了刻面描述的單一性,有效地改善了一詞多義或者詞性發生歧義的情況。在排序學習階段,通過余弦相似度計算得到了高準確度的構件訓練數據,在排序模型訓練時訓練數據集的數據越準確,訓練出的排序模型的準確度就越高,所以使用排序模型也提高了構件檢索的查準率。當構件檢索系統根據用戶查詢條件進行檢索時,每個領域的所有構件在通過構件排序模型時,都需要經過特征提取從而與查詢相關的特征進行概率預測,因此也提高了構件檢索的查全率。 從圖7可以看出,本文提出的方法在時間性能上也優于傳統的2個方法。將訓練好的模型應用于構件檢索,實現了訓練模型與使用模型的分離,構件檢索時使用訓練好的模型不需要再次進行復雜的相似度比較,所以相對于傳統的方法降低了時間復雜度,從而提高了檢索效率。 Figure 7 Comparison of retrieval efficiency 本文提出了一種基于排序學習的構件檢索方法,實驗結果顯示,本文將排序學習算法應用于構件檢索的方法具有明顯的優越性。在排序模型訓練中,使用潛在語義分析和余弦相似度來為排序學習提供準確的標注信息;在排序學習中,為了減少模型估計時存在的偏差,將P-L模型進行改進并采用最大似然估計的方法補充標準擬合模型,進一步提高了排序模型的準確度。在構件檢索實驗中,用戶查詢條件直接通過排序模型進行構件檢索,將所有構件都加入排序,與傳統的基于刻面的構件檢索方法和基于本體的構件檢索方法相比,本文所提方法提高了檢索的查準率、查全率和效率。 本文方法為構件檢索研究提供了新方法,但仍有不足之處需要改進。例如,在得到構件相關性時,可使用現在最新的語義推理方法進行構件相關性判斷,這樣就不需要使用余弦相似度進行特征向量計算,從而降低得到訓練數據的時間復雜度。因此,下一步將對構件的訓練數據進行更深層次的研究。
4 基于排序學習的構件檢索方法
4.1 排序學習方法
4.2 Plackett-Luce概率排序模型





5 實驗
5.1 構件排序模型訓練
5.2 構件檢索系統
5.3 實驗結果及分析



6 結束語
猜你喜歡
中學生數理化·七年級數學人教版(2022年11期)2022-02-14 07:14:12科普童話·學霸日記(2020年1期)2020-05-08 16:45:11開放教育研究(2020年2期)2020-03-31 01:54:14小天使·一年級語數英綜合(2019年2期)2019-01-10 11:57:30兒童繪本(2018年5期)2018-04-12 16:45:32現代語文(2016年21期)2016-05-25 13:13:44Coco薇(2016年2期)2016-03-22 02:42:52Coco薇(2015年1期)2015-08-13 02:47:34小雪花·成長指南(2015年4期)2015-05-19 14:47:56大連民族大學學報(2015年2期)2015-02-27 08:28:11
