大數據技術的震后救援信息處理平臺研制與應用
2021-06-26 04:04:30劉慶杰周兆軍李寒莉
科學技術與工程 2021年15期
李 攀, 劉慶杰, 周兆軍, 劉 穎, 李寒莉
(1.防災科技學院信息工程學院, 三河 065201; 2.防災科技學院繼續教育學院, 三河 065201)
中國是地震多發的國家,造成的傷亡極其慘重,因此成為20世紀以來因地震原因死亡人數最多的國家[1]。為避免地震災害造成的人員傷亡,很多國家采取不同的方式去預防并減少各項損失,主要的方法有防震、避震和減震,或是在地震發生后及時開展減災和救災工作[2-4]。不同的國家面對地震類型及所處環境的不同,采取的措施也不盡相同,如日本主要精力就放在建筑減震、震后救災的體系建設中[5-9]。當前,在地震預測方法暫時還未取得突破性進展的情況下,如何安排地震后的黃金72 h內的人道主義救援工作,就成了減少地震傷亡人數的一個關鍵突破口。通過以往的經驗,震后救援一般都是依靠電視、電話和人工調配救援,依靠受災現場搜救犬尋找、受傷人員在廢墟中哭喊求救及地毯式排查方式,存在所能獲得準確救援信息有限,有些危重傷員無法及時發現,救援信息更新滯后等問題。因此結合全球定位系統(global positioning system, GPS)定位,基于大數據技術[10-14]的報警語音文字的快速識別判斷,應用語義識別技術的關鍵信息檢索,建立搜救模型,配合遠程專家協助的大型綜合調度平臺,是目前急需實現的新技術方案。為此,提出一種全新的基于大數據技術的震后救援信息處理平臺,利用語義識別技術的進行地震求救信息決策,可實時處理海量的求救信息,并合理規劃救援力量,以救助危重傷員為優先原則,可極大地減少受災人員傷亡率。
1 系統方案
1.1 平臺規劃
首先,構建震后救援信息處理平臺中很重要的移動端應用,包括地震救援APP及專用救援電話555。該手機地震救援APP和救援電話向地震多發地區進行宣傳推廣,比如四川、云南和新疆等地的應急部門,使當地民眾熟練使用。該救援電話可在地震發生后直接撥打,具備完整的錄音功能,不會出現人工客服。為了便于大數據語義分析,求救電話的用詞用語盡量簡潔清晰,在最短的時間內報出人數、年齡、性別、有無傷亡、震前所在位置和震后所處空間有無危險等基本信息,然后迅速掛斷電話,減少上傳的語音數據量,為后期大數據快速存儲、讀取、語義識別和建立模型等處理過程,起到節省存儲空間、降低硬件成本并提高通信帶寬的作用。
其次,通過地震科普的方式向廣大民眾推廣安裝地震救援APP,該APP占用內存很少,同時發布不同手機操作系統上對應版本。該手機軟件具備一定的手機權限,可在開啟時,自動關閉手機中除網絡服務外其他所有非必須進程,使手機強制進入最省電模式,提供盡可能長的待機時間,為救援工作多創造有利條件。本手機軟件APP開啟后只有2個模塊,分為語音報警和文字報警2個大字體的對話框,便于在地震后被掩埋的傷員,其中包括只能一個手指活動的重傷員,提供快速輸入提示短語,或者說出救援信息能夠第一時間及時發出,給出高效的求救方式。求救信息通過地震救援APP發出后,會自動加上手機所處的位置信息及海拔高度等定位數據,并經過判斷調取該位置監控設備,發送周邊照片或視頻到云服務平臺,為救援人員了解被掩埋的傷員周邊救援條件,交通條件,天氣狀況等因素,提供參考依據。
同時,需要規劃安排相應的地質、水文、氣候、電力、消防、建筑、醫療及工程等專家,在這些專業手機端安裝對應的地震救援專家決策APP,通過平時的模擬演練,要求這些專家熟悉掌握多專業團隊配合模式。在地震發生后,其他安全的城市中,能夠快速組建專家組,集合并開始遠程會議信息支撐,為每一個街道,甚至每個大廈都建立一個搜救現場指揮部,及對應的遠程專家決策小組,用于快速輔助現場指揮的搜救行動。
最后,構建對應的震后救援信息處理的大數據平臺,它應用分布式存儲設備,通過完善自身的語義識別模型,建立每個對應城市,對應地方方言,對應的特殊詞匯的字典數據庫,為語義識別求救信息,做出有力的數據支撐。同時召集不同地區方言的志愿者,培訓人工處理平臺的工作,需要緊急時刻能夠召集足夠多的志愿者,為機器難以解析的語音和文字,進行人工審核和錄入工作,這對機器識別是非常重要的補充,避免分析求救信息出現錯誤和遺漏,提高分析的準確性。
1.2 推廣方案
由于大數據技術處理數據的特點,提高求救信息識別精度,需要數據樣本量要有一定的規模,因此,需要從某些地震多發的城市開始,逐步測試推廣此求救平臺和救援體系,并結合當地部門,利用街道宣講、電視宣傳、講座、演習或學校科普等方式,使得求救電話號碼和地震救援APP深入人心,做到大面積普及安裝。同時,對使用者進行專業救援培訓,強調求救信息發送時,內容可靠,冗余減少,杜絕虛假信息,避免頻繁發送等問題。尤其對于虛假報警,明明沒有重傷卻謊報重傷,欺騙救援隊伍先來救援的行為,采取嚴懲,杜絕人們的僥幸心理。在法律法規的約束下,提供真實信息并合理使用救援資源,提高救援效率。最后,現在很多家庭使用智能語音設備,如小米、天貓等各種可以接收語音反饋的物聯智能設備,添加對應報警模塊,在判斷家中有人的時候,甚至可以直接發送人員基本信息和位置信息,這樣可以輔助救援高齡老人或無法行動的病患者,不需要使用智能手機或APP,也能發出自己的求援信息,還能進行人數統計,便于相關搜救人員排查遺漏人員。
1.3 數據處理
該震后救援信息處理平臺采用Hadoop框架和Google的BERT(bidirectional encoder representation from transformers)模型進行語義識別[15],由于中國國土面積大,人口眾多,會在不同地區出現差異化,個性化,具體表現在一些特殊的地名,方言,語言習慣和表述文字的差異化,因此除了考慮普通話的語音文字識別,特殊要考慮方言轉換,建立方言語音識別模型。同時一些特殊字或特殊發音的地名人名,有可能會對語義識別增加識別難度,因此在數據進行識別前,進行數據清洗治理工作,將大段背景噪音去除,將無聲數據去掉,面對特殊地區時,快速調用對應的方言庫。同時,平時加強演練,堅持不斷提升模型的訓練集,豐富訓練樣本,為地震發生時的應用,尤其指黃金72 h內的使用,提供前期的測試和技術保障,面對海量信息不延遲,不宕機,快速建模,快速識別,計算緊急因子并實時更新,為搜救力量的委派,提供信息支持。
2 構建平臺
在實現震后的人員救助時,設計此平臺用于處理各個基層終端的反饋信息,主要是將語音、文字等求助信息,以及外部救援人員的照片、視頻、文字信息、室內外攝像頭采集信息等,關于災情的各種綜合信息,進行海量存儲,快速查詢,語義識別,關鍵字抽取,進行自然語言識別,根據識別成果,判斷救援的先后重點,合理分配救援人工。為了避免類似日本1995年阪神大地震時,北海町作為最嚴重受災地區,卻由于無法及時通報災情,導致救援力量全部分配去了其他地區,而該地區無人安排救援的情況出現,錯失最佳的救援時機[16],也是建設此平臺的重要目的。此平臺為大數據分析[17-19]進行的架構設計,如圖1所示,共分六個層面,分別是存儲計算層、數據層、服務層、管理層、業務層和應用層。

圖1 大數據平臺架構圖Fig.1 Big data platform architecture diagram
2.1 存儲計算層
該平臺布署公有云服務器,搭載分布式存儲、共享存儲、塊存儲硬件,通過配置的CDN(content delivery network),負載均衡模式,實現海量數據流的接收和存儲,通過冷熱數據備份的副本集,實現數據的快速查詢調用。并且為后續數據的涌入,提供了自動擴展設備的接口,允許并行計算,同時調用存儲數據。
2.2 數據層
布署FTP服務器,關系型和非關系型數據庫,存儲海量的救援信息,分別為文本、照片、語音、視頻流等類型,根據業務邏輯的區別,和數據體的區別,分別存儲在MySQL、HBase、Redis或MongoDB中,為之后的查詢調用提供了數據支撐。
2.3 服務層
本層對各項數據庫和FTP的接口管理,以及元數據映射服務,為數據管理層和上層業務模塊的使用,提供了數據服務支撐。
2.4 管理層
該層負責對各項接收數據的存儲管理,大數據模型所需數據的查詢,對中間件的管理,對數據流引擎的管理及數據庫的備份管理。
2.5 業務層
該層對數據質量進行控制,通過數據AI的機械學習,利用可視化圖表和BI(business intelligence)組件,做出不同目標的狀況分析,使用決策引擎,作出緊急程度判斷,得出救援的先后重要次序。
2.6 應用層
開發不同的功能模塊,提供給受傷需要救助的人員匯報傷亡,搜救人員現場匯報現場信息,專家提供遠程決策,其他災害預警平臺的信息監測,綜合信息匯總以及總指揮中心的決策命令發布等。將整個震后救災第一時間的應急指揮體系,完成救助傷員的全部信息匯總,規劃及處理,為在黃金72 h內的救援力量委派,提供了關鍵的信息支撐。
3 系統功能
3.1 地震救援APP
圖2所示手機端用戶為受災人員,界面盡量簡化,提供語音和文字一鍵報警模塊,啟動后會獲得系統最高權限,并關閉手機系統中除網絡及定位等一切無用的后臺服務,進入最大化省電模式,為手機運行時間最大化提供保障。操作方式極度簡化,語音報警模塊可以提供一個手指打開語音模塊,并錄制求救語音并發送。文字報警模塊,可以提供快捷的預制模板,盡量減少用戶操作輸入法,只輸入關鍵信息即可,實現信息的快速歸納。這些也是為了在倒塌建筑中,不能方便操作手機的受傷人員,設置的最簡易報警方法。同時安排的地震災害報警號碼555,可以接收受傷人員的語言通話,全程不提供人工接收,打開聽到提示音后,即開始錄音,將求救的語音信息上傳到分布式數據庫中。
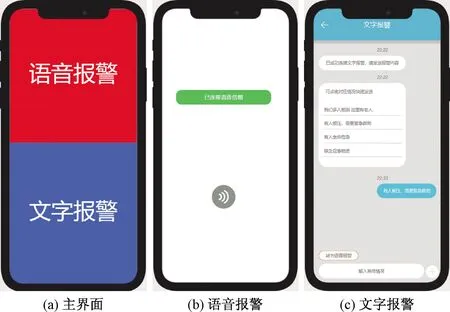
圖2 地震救援APP界面Fig.2 The interface of the earthquake rescue APP
3.2 搜救人員APP
圖3所示手機端用戶為搜救人員,為在室外搜救的工作人員提供定位,呼叫支援,文字、照片、視頻匯報進展的模塊,方便搜救人員通過定位快速找到受傷人員掩埋的位置,并把現場的具體情況,通過文字、圖片、視頻形式匯報指揮中心,為專家的救助方案討論,及總指揮決策提供信息支撐。
3.3 專家決策APP
圖4所示手機端用戶為相關救援專家組成員,救助傷亡人員時,需要不同部門的地質、水文、氣候、電力、消防、建筑、醫療及工程專家提供專業化的綜合信息參考,在地震開始后的前幾個小時,很難將所有人匯聚到一起開會,只能是采用手機視頻或桌面遠程會議模式,將具體匯報的各項信息,發給對應專家,再由不同方向的專家提供信息支撐。這樣就可以快速匯聚全國各個地區的專家組成小組,例如針對B市某大廈的救援方案,可以臨時抽調A市的8名專家及委派一個現場指揮,在前期專家或在家中,或在交通工具中使用APP獲取信息,提供參考建議,一個小時后聚集在A市救援中心的大會議室中集中討論,這樣節省了開始時的路程等待時間,可以最高效的處理龐雜信息,而現場指揮需要坐鎮此大廈,根據遠程專家組意見,現場協調人力物力,組織專項救援。
3.4 專家管理平臺
專家管理平臺存儲全國各個地質、水文、氣候、電力、消防、建筑、醫療及工程專家的詳細信息,平時可以規劃技術昨天,模擬救災演習等。在災害發生的第一時間,可快速更新各個專家的位置信息,并根據位置所在城市就近原則,迅速組建多行業協同專家組,通知各個專家立刻前往具體地點的會議室,參與遠程會議,開始確定地區或建筑的救援方案的展開。同時災害發生現場第一手資料,包括文字、圖片、視頻等資料及對應地區,建筑的相關地質、水文、建筑等信息及時發送至對應專家的決策APP,使其快速了解基礎信息,并盡量第一時間回復現場指揮人員注意事項,救災人員、物資的需求等情況。在救災的第一時間,極易發生對受傷人員的二次傷害,因此要重視余震危害,所以在所有專家的建議中,除了醫學專家判斷的傷勢緊急程度,最需要關注的就是根據地質地層數據,進行的余震預測,只有掌握接下來余震的烈度,發生范圍和大概時間,才能最合理的部署救援工作。
3.5 災害監測平臺
災害監測平臺,提供調用城市其他部門的數據庫,獲取包括天氣、地質、水文、電力、熱力、能源、危險品及次生災害預警的信息,為調集救災人員,分配救災物資提供信息支撐。尤其是震后的泥石流災害、地質次生災害、海嘯災害、危險建筑信息預警及惡劣天氣預警、疫情預測等信息,這些震后較容易出現的伴生危害,及時進行預警,為總指揮的綜合決策,提供信息支撐,避免由于伴生災害造成的二次傷亡和救災進程中斷,通過各個部門信息一體化的方式,將全部的人力物力,應用到震后的救災現場中,盡量降低人員傷亡。
3.6 信息治理平臺
信息治理平臺,即求救信息的大數據處理平臺,根據每個不同的求救語音、文字,需要先將對應的語言都轉化成文字,再進行語義識別,這里采用的是基于Google的Transformer模型的語義識別模型BERT,本文以Transformer作為算法的主要框架,這樣便于捕捉到語句中的雙向關系,還使用MLM和NSP模型進行多任務訓練,擴大機器訓練數據的規模,使BERT的訓練結果精度得到進一步提高[20-23]。根據語義識別結果,配合基于地理位置信息,救援人員現場匯報信息,路面視頻監控信息,專家決策信息等,進行綜合的大數據分析,為不同求救目標做定義,按人數、傷情、醫護風險、緊急程度、伴生災害可能性、余震危害等多維度的因素做出判斷,確定救助目標的類型及權重,提供給綜合決策平臺,為指揮部的決策提供信息支撐。
3.7 綜合決策平臺
綜合決策平臺用來匯總信息治理平臺傳輸的信息,通過動態曲線、圖表、照片、文字和視頻影像的方式,結合遠程視頻會議,以綜合的方式,對人員救援行動發布指示。同時管理各個小范圍區塊的現場指揮人員,關注救援進展,實時提供遠程協助,提供后續救援力量,安排新的救援團隊部署,將現場、指揮部、遠程專家和后援力量統一管理起來,綜合部署,哪里危機去哪里,以人民群眾的生命安全為第一要務。
通過圖5所示流程圖,可以明確災后第一時間平臺需要做到的就是迅速擴展自身的數據庫,第一時間接收海量的求援信息,并以地理位置為標準,劃分各個小的救援區域,通過向全市派遣的觀察員,了解當地發生災情的詳細信息,并結合求援的語音、文字信息,進行語義識別分詞識別,快速統計受傷人員的位置、年齡、人數、受傷情況,有無生命危險等基本信息,根據外部觀察員及室外監控視頻的信息,總結受災地區的建筑、水文、消防、醫療等綜合信息。同時快速建立異地專家組,發送第一手資料到專家手中,并安排專家集合開會,提供遠程提供輔助信息決策。
根據大數據分析的結果,配合專家的參考信息,根據熵值法給各項參數權重,綜合得出某地某區域人員所需救助的緊急情況因子,并匯總全部求救信息到決策總指揮處,由總指揮決定向何處,及如何調撥救援人員,同時派遣出現場指揮,負責某一地區具體的救援工作,現場指揮只負責本地區救援工作,同時跟遠程專家組溝通情況,實時修正救援方案即可,救援的情況直接向總指揮匯報,不再出現在決策平臺中,具體救助過程如圖6所示。
4 算法實現
本平臺采用的大數據存儲和語義識別技術[24],其核心模塊是快速存儲及處理海量的求救信息,并提供語義識別技術快速提取關鍵語義,匯總得出實際的真實情況,為指揮中心了解現場的綜合情況,提供快速便捷的數據支撐。本平臺的大數據架構,采用的是基于Hadoop的分布式架構,以HDFS形式存儲語音視頻等數據[25-27],以MySQL數據庫存儲各個救援地區的關系數據,提供REDIS數據庫記錄日志類數據,以FTP形式存儲關于城市地質、水文、建筑圖紙等基本信息。通過Hadoop的深度學習框架,調用語義識別技術,快速識別文字信息,并加以歸類處理。
4.1 語義識別技術
核心技術語義識別以BERT模型為基礎,通過自身已有的地名信息,人名信息,建筑信息,醫療信息庫等專業字典數據庫,進行快速匹配及比對,提前關鍵字,對一條求救信息中的關鍵詞組加以語義分析,匯總人員的人數、年齡、傷亡情況,所在位置等核心內容,并為其建立數據模型,通過熵值法賦予權重,并結合專家組意見,得出緊急情況因子,給總指揮的決策提供數據支撐,具體流程如圖7所示。
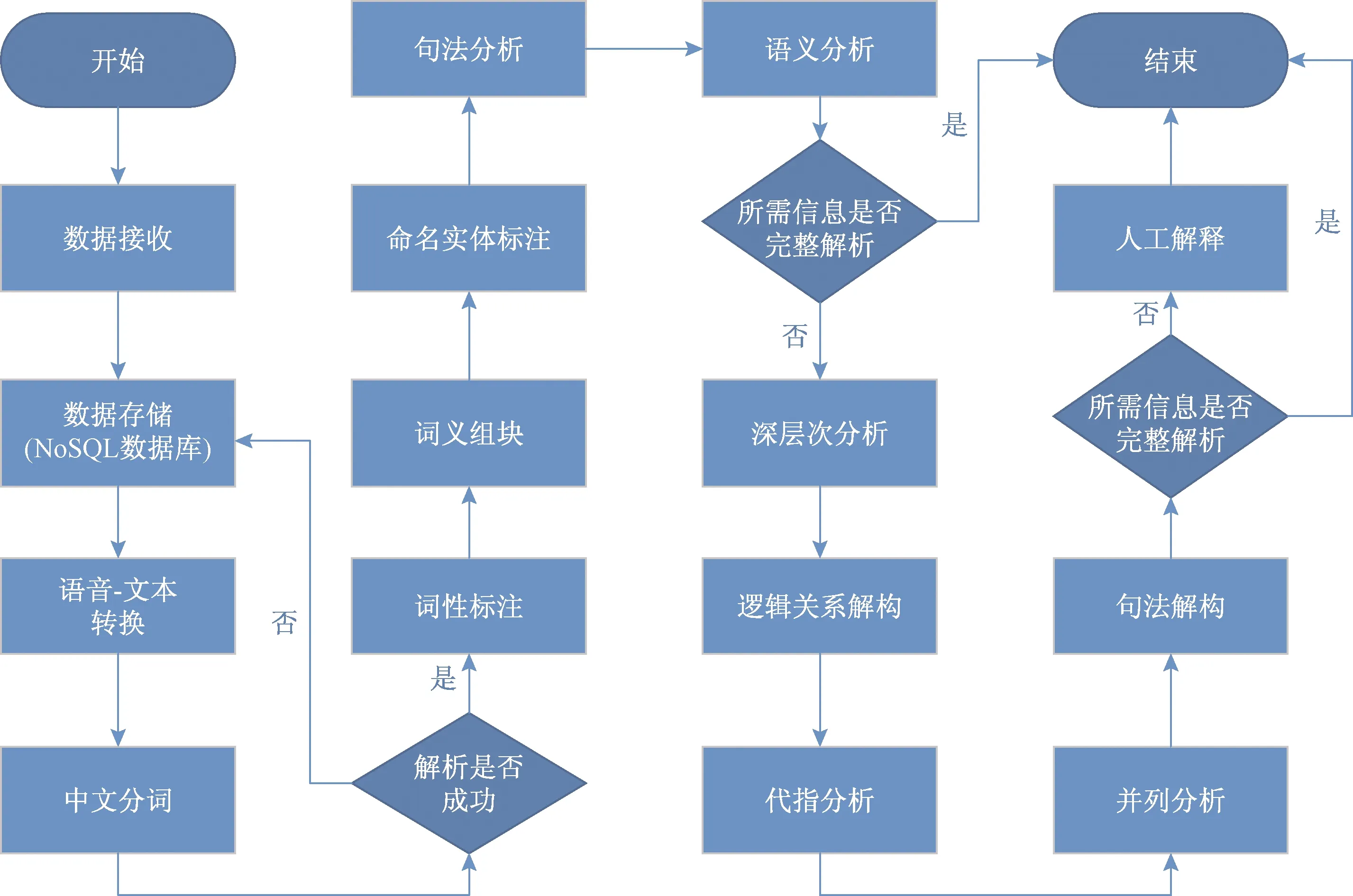
圖7 語義識別模型流程圖Fig.7 Semantic recognition model flow chart
構建BERT模型,可以通過將一個編碼結構和一個解碼結構,建立一層連接,組合為一個編解碼組件,數個編碼組件組成一個編碼器,數個解碼組件組成一個解碼器。圖8所示編碼器由2部分組成:1個自注意力層和1個前饋神經網絡,自注意力層可以分析當前詞語,并獲取到上下文的語義。解碼器包含編碼器提到的兩層網絡,這兩層中間有一層為注意力層,幫助當前節點獲取到當前需要關注的重點內容。該模型對輸入數據進行嵌入操作,然后該數據輸入到編碼器,自注意力層處理完數據后把數據送給前饋神經網絡,并行前饋神經網絡的計算,將得到的輸出,輸入到下一個編碼器。通過最新的語言識別技術,可以做到對語言的高精度識別,及關鍵詞提取,獲取救援最需要的關鍵信息。

圖8 BERT模型架構Fig.8 BERT model architecture
4.2 緊急情況因子
已知各個外部數據接口,專家組的評價意見,語義識別結果和大數據分析結果,可以創建一個基于多維數據的緊急情況因子模型,采用數學多元統計方法,根據不同具體情況,賦予不同模型參數,進行計算。目前已知的輸入數據有:天氣影響、地質變化影響、水文情況影響、電力供應影響、熱力情況影響、能源情況影響、危險品及次生災害影響,傷者危險情況,醫療資源情況,道路交通情況,現場匯總情況,室外設備采集信息等多維度數據,可以用來建立模型。其中受傷人員面臨的危險情況來自于APP提交的信息和醫生專家組分析;現場匯總情況由現場情況觀察員提供,室外設備采集信息由室外攝像頭,監測設備,衛星導航等多種外部設備提供;道路交通情況由交通部門數據庫提供;醫療資源情況由醫療資源體系數據庫提供;天氣影響、地質變化影響、水文情況影響、電力供應影響、熱力情況影響、能源情況影響、危險品及次生災害影響等影響因子,由遠程專家組了解信息后,綜合自己專業背景做出判斷。
基于這些多維度數據,平臺使用層次分析法[28-32]構建一個面對不同情況的城市的指標判斷矩陣[33-34],并開始構建評價模型。建立層次結構模型,根據地震救援的特殊情況,將影響人員安全的判斷因子分解為以下因素:傷者提交情況、醫生專家分析、現場匯總情況、道路交通情況、醫療資源情況、天氣影響、質變化影響、水文情況影響、電力供應影響、熱力情況影響、能源情況影響和危險品及次生災害影響等。這12個因素,為方案對象層,也稱作指標層。
(1)使用此12項指標構建判斷矩陣,用成對比較法,以1~9個比較尺度級別進行比較。
(2)求解特征向量,此處采用求解矩陣的特征值,并取最大特征值并進行歸一化,然后再對得出的特征向量作一致性檢驗,如果檢驗失敗,需要再重新設計判斷矩陣。設定矩陣第i行第j列的原始對此列的元素進行重要性濱江,相對權重記錄為aij,設共有9個原始參與比較,aij在1、3、5、7、9及其倒數中間取值[35],即
(1)
通過式(1)計算,得到表1所示判斷矩陣A(當i=j時,aij=1)。

表1 判斷矩陣Table 1 Judgment matrix
通過分析,如果A是完全一致的判斷矩陣,應該滿足條件
aijajk=aik, 1≤i,j,k≤n
(2)
設定衡量一個判斷矩陣A(n>1階方陣)不一致程度的指標為
(3)
當n=12時,求判斷矩陣A的特征向量最大值λmax,再計算CI。然后設定CI的標準,當CI=0時,完全一致;當CI接近于0時,基本一致;CI越大,不一致越嚴重。同時為了衡量CI,引入隨機一致性指標RI[36],即
(4)
可看出A基本一致,該不一致程度是可接受的。根據判斷矩陣A,通過特征值法求權重,一致矩陣有一個特征值為n,其余特征值均為0,并且當矩陣的特征值為n時,其對應的特征向量Wi公式為
(5)
其次,通過層次分析法,構建了指標權重后,使用功效系數法,對各個相關指標進行調整,通過無量綱化處理,將部分指標的量綱統一到一個分值體系。再進行統計和評估,從而算出整體的評價分數。具體分析流程如下:
(1)確定所有指標的多個評估標準,獲取不同維度的指標數據xi(i=1,2,…,n)。
(3)對各個指標進行處理,使得各個指標無量綱化,其具體公式為
(6)
(4)對每個指標的分數進行計算,即生成單項指標的評分公式為
F=40fi+60
(7)
(5)進行總分統計,結合層次分析法求出的權重計算總分,最終匯總的總分,即是本平臺需要的緊急情況因子評分(表2),將其按五檔分類排序,得出救援的急迫程度。

表2 緊急因子評分情況表Table 2 Emergency factor score situation table
如表3所示,根據模擬輸入的5個不同傷員(分別為甲、乙、丙、丁和戊)的分數示例,結合上述模型得出總分,可以分別把人員歸納為危急、危險、中風險、低風險、安全共計5種情況。但是這種模型具有一定的局限性,可以作為中國普通城市的一種通用模型,考慮到存在山區城市和沿河沿海城市,不同的地質條件下,地質和水文等因子的權重應該完全不同,存在一定的差異化,這也是后期需要重點研究的方向,為每個城市建立自身的權重模型,符合當地實際情況。2008年5月12日,四川省汶川縣發生8.0級地震,遇難人員69 227人[37-38],傷亡巨大的原因主要是因為山體崩塌和泥石流造成的房屋損毀,民眾防震意識不足,救災減災的演練不足,山區救援工作不好開展等原因。通過本平臺的使用,相應防震措施實施和地震救援APP的使用,會使得群眾的防災意識上升,同時快速溝通專家決策,使得救援工作能夠第一時間展開。

表3 緊急情況因子測試分析表Table 3 Emergency factor test analysis table
5 結論
從實際應用角度出發,為地震災害人員快速救助,提供了數據平臺和算法支持,配合規劃的地震救援宣傳體系的普及,會大大提高震后人員救助的效率,尤其快速救援生命垂危的人民群眾,取得的成果如下。
(1)建立了一套完整的救災報警體系,通過宣傳可以增強人民減災自救的意識。通過地震救援APP及語音方式獲取的求援信息,會得到快速反饋,減少了人工繁雜的處理模式,為災害發生時通信設備的使用節省了網絡信息流量和帶寬,減輕了通信壓力。
(2)可以快速匯集遠程專家組的力量,調動相關力量,參與某一塊地區,甚至一個大廈的救援行動,為當地的救援提供了科技化、信息化、專業化的力量支撐,為快速救援提供了可靠的信息技術保障。
(3)通過大數據平臺,面對進行海量的求救數據,可以快速處理每個求援請求,并根據語義識別的結果,結合專家組和現場信息,對求救人員的緊急程度做出判斷,在地震救援的黃金時間,為危重傷亡人群,優先提供救援。
(4)提供緊急度因子排序的方法,為總指揮決策提供了參考依據,更方便安排救災人員,工程車輛,醫療救護力量,生活物資的調配和統籌,極大地提高救援效率,降低受災人員傷亡率。
猜你喜歡
開放教育研究(2020年2期)2020-03-31 01:54:14
中華手工(2017年2期)2017-06-06 23:00:31
現代語文(2016年21期)2016-05-25 13:13:44
大連民族大學學報(2015年2期)2015-02-27 08:28:11
中外會展(2014年4期)2014-11-27 07:46:46
當代修辭學(2011年6期)2011-01-29 02:49:50
外語學刊(2011年1期)2011-01-22 03:38:33
當代修辭學(2010年1期)2010-01-23 06:35:10
建筑創作(2001年3期)2001-08-22 18:48:14
祝您健康(1987年3期)1987-12-30 09:52:32
