
淺談OCR識別技術在科技檔案管理中的運用
2021-08-06 07:13:02王瑜
卷宗 2021年21期
王 瑜
(中國電建集團北京勘測設計研究院有限公司,北京 100024)
OCR文字識別技術的英文全稱是Optical Character Recognition,譯為光學字符識別。OCR文字識別是視覺感知中一個重要的技術,目的是從圖片中提取文字信息。它是利用光學技術和計算機技術把印在或寫在紙上的文字讀取出來,并轉換成一種計算機能夠接受、人也可以理解的格式。文字識別是計算機視覺研究領域的分支之一,這個課題已經在很多行業得到應用。OCR識別技術主要可應用的場景有:教育場景文字識別、卡證文字識別、財務票據文字識別、醫療票據文字識別和汽車場景文字識別。
1 OCR技術的流程
OCR文字識別從本質上可以歸類為序列化標注問題,主要目標是尋找文本串圖形到文本串內容的映射。在工作流程上,《DA/T77-2019紙質檔案數字復制件光學字符識別(OCR)工作規范》已有所規定,主要流程是:
1.1 圖像輸入
首先對圖像的分辨率、傾斜度、清晰度、失真度等方面進行評估,并進行適當的調整。然后把不同的格式和壓縮方式的圖像進行解碼。
1.2 圖像預處理
主要包括二值化、去噪、傾斜矯正等。
1)二值化:圖像錄入設備采集到圖像,一般都是彩色圖像。二值化就是將具有灰度級的彩色圖像轉換為黑白圖像,設定任意的閾值,并與各像素值進行比較,當大于閾值時轉換為黑,小于閾值轉換為白。
2)去噪:主要方法是均值濾波器、自適應維納濾波器、中值濾波器、形態學噪聲濾除器、小波去噪。
3)傾斜矯正:對圖像識別前先對相關的內容進行校正。
1.3 對比識別
1)版式分析:對圖片中文字進行分段落、分行的過程,稱之為版面分析。
2)檔案特征分析:通過分析歸檔章、公文要素分析、表格分析、印章分析等方面對檔案進行分析。
1.4 識別和匹配
以特征提取數據庫對比為主。文字的位移、筆畫的粗細、斷筆、粘連、旋轉等因素極大地增加了特征提取的難度。
1.5 成果整理輸出
1)成果整理:按照紙質檔案數字復制件的版式對OCR成果的版式、公文要素、文字符號等內容進行理解與重建。
2)成果輸出:將檔案OCR成果同時保存為純文本形式和雙層版式文件形式。
2 OCR技術在科技檔案管理中運用的幾種場景
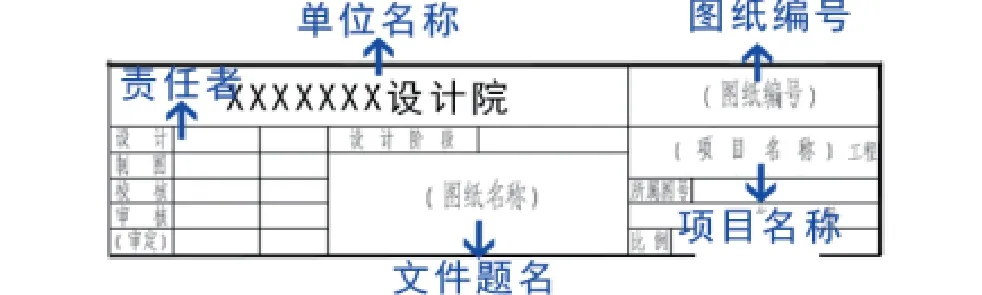
OCR識別在檔案場景的應用,主要針對兩方面:著錄項數據抓取方面和全文OCR識別。在檔案文件元數據抓取的方面的OCR識別技術的應用可以參考卡證文字識別,即把OCR技術和檔案系統集成,讓OCR識別出的文字直接被收錄到相應的部位。這一點科技檔案出版格式的高度標準化給OCR識別帶來了方便。因為文字識別的主要目標是對定位好的文字區域進行識別,主要解決的是將一串文字圖片轉錄為對應的字符的問題。以圖紙圖簽中用于填寫著錄項目數據抓取為例,如圖1所示。在圖紙的圖簽中,我們可以把圖簽按照原有框格把每一個框格都切割成多個框格,對應框格內獲得圖紙名稱、圖號、設計人、制圖人、校核人、審核人等信息。那么在檔案著錄時就可以靠定位和對信息的分析,尋找圖簽上我們需要的信息,然后導入檔案系統中相應的著錄項里。
OCR技術在科技檔案管理中另一個非常重要的運用場景就是全文識別了。全文識別給檔案的利用提供了便利。就我們自己單位來說,曾經在有人需要利用檔案的時候,只能對著錄項中著錄的內容進行檢索,這就需要提供相對準確的圖號或關鍵詞等信息,如果相應關鍵詞關聯的檔案太多,就需要人工篩選。而且沒有全文檢索,也很難再借閱前知道文件內是否有自己需要的內容,不解決這些問題,檔案部門沒辦法提供良好的檔案利用服務。
3 OCR識別技術在科技檔案管理的過程中遇到的問題
3.1 早期檔案不清楚
最近形成的科技檔案紙張干凈、印刷清楚,給OCR識別技術提供了良好的環境。但是早期的檔案就存在紙張泛黃、印刷模糊等問題。甚至很多檔案在最初形成的時候所處環境就極度惡略,比如一些檔案,是在工地上直接形成的,工地上條件不好,檔案也有明顯被水浸泡過的情況,或者沾上了其他的污漬,甚至皺皺巴巴的情況。這就給OCR識別帶來了困難。
3.2 文字難以識別
在科技檔案中存在很多數學公式。另外有的科技檔案是手寫的,雖然文字清晰,但是并不是常規的印刷體。另外檔案中文字的排版也有各種各樣的種類,還有表格和圖片也給OCR識別技術帶來了挑戰。
4 解決辦法
4.1 早期檔案不清楚的問題的解決
1)圖片預處理:對于模糊不清的檔案,在數字化掃描過程中,首先應該嚴格按照《DA/T31-2017紙質檔案數字化規范》執行,如為了最大限度保留檔案原件信息,便于多種方式的利用,需要采用彩色模式進行掃描,如果頁面為黑白兩色,也可以采用黑白二值或灰度模式掃描,掃描分辨率應不小于200dpi。褶皺不平影響掃描質量的紙質檔案應先進行壓平等相應技術處理。對于掃描后仍然模糊的檔案就需要應用計算機圖片處理的技術來處理了。比如圖片太黃可以調節亮度,模糊可以調高對比度,或者曲線來找到能使圖片變得最清晰的方法。如果需要局部調節則是 用選框工具對想要修改的局部進行框選,再進行上述調節。如果局部邊緣是不規則形狀的話,則需要用鋼筆工具建立選區進行修復。對于局部污漬的處理我認為可以高低頻的方式進行修復。但是這些方法處理圖片太過耗費精力,在操作時可以只對非常模糊的檔案進行此類操作。
2)選擇適應的二值化方法:常見的圖像二值化方法很多目前二值化的方法主要分為全局閾值方法、局部閾值方法和基于深度學習的方法。全局閾值方法常見的有固定閾值方法和Otsu方法,其原理都是通過人工設定的公式直接找出一個合適的統一閾值對圖像進行二值化。局部閾值方法主要有自適應閾值算法、Niblack算法等。是根據像素的臨域塊的像素分布來確定該像素位置上的二值化閾值。這樣做的好處在于每個像素位置處的二值化閾值不是固定不變的,而是由其周圍領域的分布來決定的。基于深度學習的二值化方法主要有全卷積的二值化方法,在圖像分類和圖像檢測等方面取得了巨大的成就和廣泛的應用,傳統的基于CNN的分割方法的做法通常是:為了對一個像素分類,使用該像素周圍的一個圖像塊作為CNN的輸入用于訓練和預測。
3)選擇適應的降噪方法:圖像噪聲是指存在于圖像數據中不必要的或多余的干擾信息,產生于圖像的采集、量化或傳輸過程,對圖像的后處理、分析均會產生極大的影響,因此一種好的去噪方法在去除噪聲的同時,還需要保持圖像的邊界和細節。早期的去噪方法多為空間濾波,隨著度學習的不斷發展,基于神經網絡的方法不斷涌現。去噪方法很多可以通過實際需要進行選擇。
4.2 文字難以識別的問題的解決
文字識別時首先要做到把圖像增強,常用的圖像增強方法有PCA抖動、顏色增強。隨機尺度變換、隨機剪裁、平移變換等。另外還可以利用深度學習的方法對圖像中的文字進行處理。深度學習方法是合成自然場景文本的方法,非常適合于文字識別。在自然場景中,除了手寫字,大部分文本都市由計算機生成的,只有物理渲染和成像過程不受計算機算法控制。合成的圖像樣本可以由圖像前景層、圖像背景層、邊緣、陰影組合而成。主要可分為如下六步:
1)字體渲染:隨機選取字體,將文本沿著水平文本線或隨機曲線呈現到圖像前景層中。
2)描邊、加陰影、著色:選擇字體,將文本沿水平文本線或隨機曲線呈現到圖像前景層。
3)基礎著色:三個圖像層中的每一層都填充從自然圖像簇中采集的不同均勻色。
4)仿射投影扭曲:對前景和便捷圖像層進行隨機的全息投影變換,模擬3D環境。
5)自然數據混合:每個圖層均從ICDAR203和SVT訓練數據集隨機采樣的圖像進行混合。混合方式與混合程度隨機決定。該操作會產生折中的紋理和組合范圍。三個圖像通道也以隨機方式混合在一起,提供單個輸出圖像通道。
6)加噪聲:應用高斯噪聲、模糊和JPEG壓縮等方法為圖像加噪聲。
5 結語
2020年4 月,工信部印發《關于工業大數據發展的指導意見》,同年5月中宣部改辦下發了《關于做好國家文化大數據體系建設工作的通知》足可見國家大力發展信息化產業的決心。近年來數字檔案館的建設、各項規章制度的發布,都像是在督促我們不斷學習不斷進步,只有這樣才能跟上我們所熱愛的檔案事業進步的腳步,一起成長。
猜你喜歡
甘肅教育(2020年8期)2020-06-11 06:10:02
制造技術與機床(2019年10期)2019-10-26 02:48:08
兒童故事畫報(2019年5期)2019-05-26 14:26:14
電子制作(2018年18期)2018-11-14 01:48:06
意林原創版(2016年10期)2016-11-25 10:28:30
Coco薇(2016年2期)2016-03-22 02:42:52
小學教學參考(2015年20期)2016-01-15 08:44:38
人間(2015年20期)2016-01-04 12:47:10
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年7期)2015-08-11 15:03:12
