基于文本挖掘的鴻蒙系統用戶評論情感分析與研究
2021-09-13 08:52:16陳諾祎單菁王佳英石璐璐
科技資訊 2021年16期
關鍵詞:文本挖掘
陳諾祎 單菁 王佳英 石璐璐


摘? 要:隨著科技的進步,由華為自主研發的首個國產手機操作系統成功問世,引起社會強烈反響。該文以網絡爬蟲抓取的用戶評論為例,基于評論數據建立評估模型,主要使用文本描述性分析、SnowNlp情感分析和LDA潛在主題挖掘這3種方法,從不同角度對用戶評論進行文本挖掘分析,找出評論大數據背后隱含的情感傾向、用戶觀點等深層信息,有助于企業了解用戶的使用體驗與口碑動態。該文分析模型的評估效果可信度較高,所采用的研究方法也適用于電商評論分析、社會輿情分析等方面。
關鍵詞:網絡爬蟲? ?情感分析? ?LDA? ?文本挖掘
中圖分類號:TP391.1? ? ? ? ? ? ? ? ? ? ?文獻標識碼:A文章編號:1672-3791(2021)06(a)-0026-04
Sentiment Analysis and Research of User Comments on Hongmeng System Based on Text Mining
CHEN Nuoyi? SHAN Jing*? ?WANG Jiaying? ?SHI Lulu
(School of Information and Control Engineering, Shenyang Jianzhu University, Shenyang, Liaoning Province, 110168? China)
Abstract: With the progress of science and technology, the first domestic mobile phone operating system developed by Huawei has been successfully launched, which has aroused strong social response. Based on web crawler fetching user comments as an example, the evaluation model is established based on the review data. Three methods are mainly used: text descriptive analysis, SnowNlp sentiment analysis and LDA potential topic mining method, conducting text mining analysis on user comments from different perspectives to find out the emotional tendency, user opinions and other deep information hidden behind thebig data of comments. It is helpful for enterprises to understand the user experience and word of mouth dynamic. The evaluation effect of the analysis model in this paper has a high credibility, and the research method adopted is also applicable to e-commerce comment analysis, social public opinion analysis and other aspects.
Key Words: Web crawler; Sentiment analysis; LDA; Text mining
鴻蒙OS是一款“面向未來”的操作系統,一款基于微內核的面向全場景的分布式操作系統,是由華為開發人員打造的國產手機系統。對于鴻蒙系統的正式發布,國內用戶紛紛通過網絡平臺發布對該系統的評論看法,用戶的評論信息包括了客觀評論與主觀評論,而主觀評論占比極高,該文通過采集B站(某自媒體視頻網站)關于鴻蒙系統視頻底部的用戶評論信息,建立相關的文本挖掘模型對評論信息進行深度挖掘。
1? 研究方法
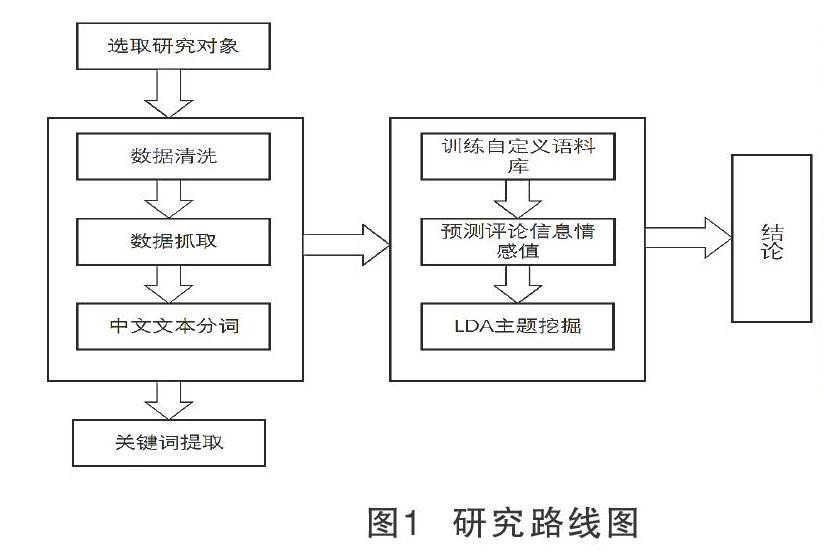
該文對選取的關于鴻蒙系統在線評論利用八爪魚采集工具,設定采集規則。主要抓取的內容為用戶評論信息。對于抓取的數據進行數據清洗,包括文本去重、去空值、剔除廣告信息與無意義評論、中文文本分詞等操作。通過將自主構建的關于手機系統的語料庫導入到snownlp情感分析模型中進行無監督訓練,以提高模型預測準確率,并利用TF-IDF算法的思想,提取評論中的關鍵詞以及詞頻;利用LDA潛在主題挖掘模型深入分析好評集和差評集。最后通過上述分析結果,剖析鴻蒙系統產品問題。圖1為研究主要路線圖。
2? 在線評論獲取
挖掘用戶關于華為鴻蒙系統在線評論中隱含的信息,首先需要利用網絡爬蟲獲取大量的在線評論。獲取在線評論數據主要通過編寫數據采集程序(稱為網絡爬蟲),網絡爬蟲可以自動爬取網頁,獲取網頁的內容[1]。該文通過一款完全自主研發的分布式云平臺——八爪魚采集器,自動獲取B站用戶在線評論數據,爬取的評論數據見表1。
3? 數據預處理
利用網絡爬蟲工具從網站采集的用戶評論數據存在較多的無用數據,會對實驗結果產生較大的影響。數據預處理主要去除不完整的、不一致的數據并排除低質量的數據,預處理過后的數據可以提高實驗結果的準確率,下面將主要闡述對原始數據集進行預處理的過程。
3.1 數據清洗
爬取到的評論文本中存在較多重復行、特殊字符及英文字符,并且用戶可以自由發表對評論主體的主觀意見,評論內容具有極強的隨意性,評論質量得不到保證。在研究過程中,主要使用Python語言編寫相關程序對文本長度大于20的重復評論以及特殊字符、英文字符進行剔除。對于滿足基本格式,但是無法進行情感分析的無意義語句進行手動剔除[2]。
3.2 中文文本分詞
在中文文本中,詞與詞之間的界限往往比較模糊,而在模型分析過程中,尤其是關鍵詞提取、潛在主題詞挖掘等,合理地進行中文文本分詞尤為重要。該文采用Python中優秀的中文分詞第三方庫jieba,jieba分詞主要利用中文詞庫,確定漢字之間的關聯概率,漢字間關聯概率大的組成詞組,從而形成分詞結果,其分詞準確率較高[3]。另外,對于一些分詞不太理想的詞匯可以通過jieba庫中的load_userdict函數導入用戶自定義詞典的方法解決,對于一些無意義的停用詞,如“的”“我們”“@”“!”等,可以利用set_stop_words函數導入停用詞詞典,并通過extract_tags函數去除文本中的停用詞,部分文本的分詞結果如圖2所示。
4? 評論文本描述性分析
4.1 基于TF-IDF算法提取關鍵詞
TF-IDF是一種統計方法,用于評估一字詞對于一個文檔集或者一個語料庫中某個文件的重要程度,字詞的重要性隨著其在文件中出現的次數呈正比增加,但同時隨著其在語料庫中出現的頻率呈反比下降。利用TF-IDF對鴻蒙系統在線評論分詞進行統計,得到top50關鍵詞及其權重,部分內容見表2。
其中,TF為一篇文檔中字詞的詞頻;IDF為逆文檔頻率,用于衡量字詞在所有文檔中出現的普遍程度;TF-IDF則為兩者乘積。上述公式中,Ni,j為字詞在文檔D中出現的頻次;為文檔D中詞條的總數,D為語料庫中總文檔數量;為包含詞條T的總文檔數[4]。
4.2 可視化評論描述
基于wordart在線詞云圖生成工具實現鴻蒙系統評論的描述性可視化,通過詞云圖(見圖3)可以直觀地突出評論文本中出現頻率較高的關鍵詞,從而形成“關鍵詞渲染”。
5? 在線評論情感傾向分析
關于在線評論文本的描述性分析能夠在一定程度上對鴻蒙系統的評價進行描述,但不能挖掘出這些評論信息所蘊含的情感傾向,為了更加深入地挖掘評論文本中的信息,需要對在線評論進行情感分析,利用Python類庫SnowNlp預測評論文本的情感傾向,并分別對正面評論與負面評論進行分類,分析其各自蘊含的主題[5]。
5.1 情感分析結果
該文使用手機系統在線評論的自定義語料庫訓練情感分析模型,以提高情感預測準確率,SnowNLP 情感分析將短文本的情感程度表示為[0,1]區間的情感分值,得分在0~0.5之間為負面評價,在0.5~1.0之間為正面評價,得分為0.5則視作中性評價[6]。通過統計實際數據,得到分類效果的評價,筆者把從網絡上搜集的2 185條評價進行人工情感極性標注,作為情感分析測試集,測試結果表示,經過訓練的SnowNlp情感分析模型的預測準確率達到87.3%,準確率較高。該文使用訓練好的模型對鴻蒙系統評論進行情感分類,得到正面評論和負面評論兩個文檔。其中正面評論共有38 897條,負面評論10 084條,中性評論856,分別占總評論數的比重為78.05%、20.23%、1.72%。
5.2 基于LDA模型的主題挖掘分析
LDA主題模型是文本挖掘領域的典型模型,可以在語料文本中抽取潛在主題,為研究者提供了量化分析主題的方法[7],該文從好評集和差評集這兩個文檔分別進行主題劃分,從而進行評論數據的情感分析研究。以上兩個文檔的主題挖掘結果見表3和表4。結果顯示,該手機系統正面評論較多,用戶對鴻蒙系統總體滿意,由好評集主題詞推測得出4個主題,從主題1得出國內用戶普遍看鴻蒙,認為鴻蒙是一款讓國人引以為豪的自主研發的國產手機操作系統,并且絕大部分用戶希望鴻蒙系統通過不斷優化以提升系統的穩定性和用戶體驗。從主題2中的高頻特征詞可以看出,隨著HarmonyOS 2.0內測版的推出,廣大用戶對申請獲得內測版系統的體驗資格滿懷期待。主題3通過“流暢”“絲滑”“操作”“厲害”等特征詞可以得出鴻蒙操作系統在流暢度方面深受用戶贊揚。主題4中的“兼容”“安卓”“適配”“軟件”等詞反應鴻蒙系統對安卓應用有很好的兼容性,減小了更換操作系統的成本,受到用戶的普遍好評。而差評集主要存在兩個潛在主題,通過主題1中的“抄襲”“安卓”“iOS”“懷疑”等特征詞可以得出,有部分用戶因鴻蒙系統與安卓應用的兼容性高,操作界面與iOS及安卓系統存在相似部分而懷疑鴻蒙系統是基于原生安卓開發的一款套殼系統,但經過查閱相關資料發現,其觀點是不成立的,屬于對國產操作系統的惡意詆毀。主題2中的“蘋果”“生態”“軟件”“掉幀”等詞說明部分用戶認為鴻蒙系統目前的軟件生態圈不及iOS,并且在細節以及優化方面遜色于iOS,偶爾會出現掉幀的情況。
6? 結語
該文結合描述性分析與情感傾向分析兩個角度挖掘評論中隱藏的信息。在描述性分析方面,主要使用TF-IDF算法提取關鍵詞,并結合詞頻生成詞云圖進行可視化分析。在情感傾向分析方面,該文通過訓練自定義語料庫的方法,基于SnowNlp情感分析模型判斷鴻蒙系統在線評論情感傾向,并使用LDA主題模型分別挖掘好評集與差評集的潛在主題,對用戶評論進行深度分析。有利于對鴻蒙系統用戶評論進行客觀整體的分析,反映用戶群體的真實感受,并對其他手機系統用戶是否使用鴻蒙系統具有參考和實踐意義。
參考文獻
[1] 吳薛凱,劉天波,胡文馨.基于網絡爬蟲的Java行業的就業分析[J].科技資訊,2021,19(2):13-16.
[2] 楊春曉,張鶴馨,黃家雯,等.卷煙在線評論的文本情感分析[J].中國煙草學報,2020,26(2):92-100.
[3] 周歡,秦天琦.基于在線評論情感分析與LDA的物流服務質量影響因素研究[J/OL].重慶工商大學學報:社會科學版:1-17[2021-08-17].https://www.kns.cnki.net/kcms/detail/50.1154.C.20210528.0837.002.html.
[4] 辛雨璇,王曉東.基于文本挖掘的電影評論情感分析研究[J].牡丹江師范學院學報:自然科學版,2021(1):25-28.
[5] 劉敏,王向前,李慧宗,等.基于文本挖掘的網絡商品評論情感分析[J].遼寧工業大學學報:自然科學版,2018,38(5):330-335.
[6] 吳瑞媛.線上用戶評價信息的文本挖掘分析[D].天津:天津財經大學,2019.
[7] 陳亮,王剛,王震.并行LDA主題模型在電力客服工單文本挖掘中的應用[J].科技創新導報,2017,14(12):245-248,250.
猜你喜歡
科技資訊(2017年5期)2017-04-12 15:18:52
電腦知識與技術(2016年33期)2017-03-21 08:13:37
商情(2016年32期)2017-03-04 00:27:28
軟件導刊(2016年12期)2017-01-21 15:55:21
電子技術與軟件工程(2016年22期)2016-12-26 20:29:58
商(2016年34期)2016-11-24 16:28:51
中國遠程教育(2016年9期)2016-11-19 12:26:00
中國中醫藥圖書情報(2016年4期)2016-10-20 23:35:25
湖南師范大學學報·自然科學版(2016年3期)2016-06-25 06:47:25
語文教學之友(2016年5期)2016-06-15 12:15:44
