基于深度學習的教師課堂提問分析方法研究
2021-09-14 18:50:30馬玉慧夏雪瑩張文慧
電化教育研究 2021年9期
關鍵詞:深度學習
馬玉慧 夏雪瑩 張文慧
[摘? ?要] 課堂提問是教師課堂教學行為的關鍵組成部分,是師生進行課堂交互的主要方式。對教師課堂提問進行分析,是提升教師課堂教學水平的關鍵。視頻分析法是目前進行課堂提問分析的主要方法。但該方法需要花費大量的時間和人力,導致無法進行大規模應用。近幾年,隨著人工智能技術的不斷成熟,越來越多的領域開始利用人工智能替代人工操作。為使課堂提問分析能夠高效、大規模地應用,本研究提出基于深度學習的課堂提問自動分析方法。研究采用卷積神經網絡(CNN)及長短時記憶網絡(LSTM),對80節課的9090條課堂教師提問文本進行分類。實驗結果表明,CNN模型具有更好的分類效果,其在提問內容和提問類型兩個維度上的整體準確率分別是85.17%和87.84%。應用該方法訓練的模型,可替代傳統的視頻分析法,能夠實現大規模的教師課堂提問話語的自動分析。
[關鍵詞] 課堂提問; 自動分類; 深度神經網絡; 深度學習
[中圖分類號] G434? ? ? ? ? ? [文獻標志碼] A
[作者簡介] 馬玉慧(1974—),女,遼寧錦州人。副教授,博士,主要從事人工智能教育應用的研究。E-mail:799493385 @qq.com。
一、引? ?言
課堂提問是教師課堂教學行為的關鍵組成部分,是師生進行課堂交互的主要方式。有效的課堂教學提問不僅能夠吸引學生的注意力,激發學習興趣,而且能夠引導學生深入思考,及時評價教學效果[1-2]。對教師的課堂提問進行質性研究,是區分新手教師與專家教師,促進教師專業發展的有效途徑之一[3-5]。現有的教師課堂提問研究,多采用視頻案例分析法,即對課堂教學進行錄像,課后反復觀看錄像,并將教師教學行為轉錄為文字,再進行編碼統計分析[6-8]。這種分析方法可以較好地對教師課堂提問進行深入的量化與剖析,確定教師課堂上的提問數量、提問方式、提問類型及提問所在教學環節等[9-11]。但該方法面臨的主要問題是需要大量的人工操作,導致該方法無法大規模推廣使用。
深度學習(Deep Learning)是當前人工智能技術發展的主流方向。近幾年人工智能技術在眾多領域的廣泛推廣與使用,大多歸功于深度學習技術的發展。深度學習幾乎成了人工智能的代名詞。隨著訓練數據的不斷增多,算力大幅提升,算法的創新與改進,深度學習訓練得到的智能體越來越多地應用在不同領域,替代人類自動完成各項耗時、耗力的繁雜工作,將人們從大量的重復性工作中解放出來,將更多精力集中于創造性的工作中。
近幾年,深度學習技術已開始應用于教育領域[12-14],教育研究者期望用機器自己學習得到的模型替代部分人類工作,減輕研究者和教師的工作負擔,實現智能教育。在本研究中,針對現有基于視頻分析法進行教師課堂提問研究的不足,本文提出了利用深度學習技術,對教師的課堂提問進行研究的方法,解決視頻分析無法大規模使用的問題,同時為基于深度學習的教師課堂分析提供研究思路與方法的借鑒。
二、研究現狀
(一)教師課堂提問的分類及分析方法研究
課堂提問是教師課堂教學中最普遍的教學行為之一,是教學過程中師生進行溝通和交流的主要方法。課堂提問是教學質量的重要保障,但若能在課堂上進行有效的提問絕非易事[15]。已有研究表明,新手教師在課堂提問方面,與專家型教師存在較大差異[5,16]。因此,對新手教師的課堂提問進行研究,發現新手教師與專家教師在提問環節的差異,對于新手教師提高教學質量,促進專業發展具有重要作用[17]。
在現有課堂提問的研究中,教師提問分類問題是眾多研究者關注的重點之一。于國文等對不同國家中學數學教師的課堂提問進行了研究,將教師數學課堂提問分為三個維度:提問對象、提問內容和提問水平。進一步地,將提問對象分為個別學生、小組和全班同學;提問內容分為知識點類、題目信息類和管理類;提問水平分為低水平的回憶型、理解型和應用型,高水平的分析型、綜合型和評價型[18]。顧泠沅將提問類型分為常規管理性問題、記憶性問題、推理性問題、創造性問題和批判性問題五類[19];涂榮豹將提問類型分為回憶性提問、理解性提問、分析綜合性提問和評價性提問[20]。葉立軍等根據教師提問的作用,回答所對應的認知水平,將提問分為管理型提問、識記型提問、重復型提問、提示型提問、補充型提問、理解型提問、評價型問題7種類型[4]。已有研究的提問分類維度為實現教師課堂提問的自動分析提供了很好的研究基礎。
目前常用的課堂提問分析方法是視頻分析法。張文宇等對我國首屆全日制教育碩士學科教學(數學)專業教學技能決賽的33名參賽學生的視頻進行視頻分析,由此發現這些職前教師在課堂提問環節的不足[10]。葉立軍等同樣采用視頻分析法,對兩位從教二十年教師的課堂視頻實錄進行分析。除了對兩位教師的課堂提問類型進行統計分析外,還對提問的總共用時、學生回答的次數、回答的總時長進行了統計分析[4]。于國文等采用基于NVivo對中國、澳大利亞、法國、芬蘭的專家型教師的課堂教學視頻中的課堂提問進行了比較分析,探究不同國家教師課堂提問的各自特點[18]。
通常,課堂教學的視頻分析法的具體步驟如下:(1)將課堂實錄視頻轉錄為文字,生成原始素材;(2)將素材導入視頻分析軟件(如NVivo軟件等);(3)構建課堂提問分類編碼體系,并進行信度和效度驗證;(4)基于提問分類編碼體系,人工進行編碼;(5)利用SPSS軟件進行編碼的統計分析。
視頻分析法能夠有效地對教師課堂提問進行分析,但也存在顯著的不足,即整個分析過程需要投入大量的人力和時間,導致該方法無法大規模推廣應用,無法對更多教師的課堂提問進行精準分析。為此,在人工智能時代,采用自動分析法替代視頻分析法成為大規模促進教師專業發展的切實有效途徑。
(二)基于深度學習的文本分類在教育中的應用
深度學習最早由加拿大多倫多大學教授希頓(Hinton)等提出。深度學習模型的結構模擬了人類大腦神經系統的結構原理,通過多層神經元之間的信息傳遞,實現不同特征的提取,最終形成數據的分層特征表示。理解深度學習,可以從“深度”和“學習”兩個方面著手。“學習”是指深度學習完成任務所需的“知識或技能”并非來源于人們預先編寫的程序規則,而是從大量數據中自動學習獲得。也就是說,深度學習獲取知識的途徑來源于海量數據。“深度”是相對于機器學習的“淺層”而言的。機器學習中的邏輯回歸、支持向量機、最大熵方法等模型,都是基于淺層結構來處理數據的。這些模型只有1層或2層非線性特征轉換層,而深度學習是一個具有多層隱層節點的神經網絡。多層隱層節點的結構不僅能更好地刻畫大量數據中隱含的復雜特征,而且通過逐層初始化,降低了神經元數量和訓練的難度。此外,相對于淺層學習而言,深度學習還有一個顯著優勢,通過多層隱層的模型結構,再加上海量的數據,能夠自動學習隱藏在數據背后的更有用的特征,無須淺層機器學習所必需的特征工程,從而能夠更精準地進行預測和分類[21-22]。
文本分類是深度學習在自然語言理解領域的一個主要應用場景之一。基于深度學習文本分類的一般流程大致為文本預處理、文本表示、基于深度學習模型的文本分類三個部分。不同領域的中文文本分類的應用和研究,其文本預處理的方法大體相同,基本包括中文分詞、去停用詞、規范化等。文本表示是將文字轉換成計算機能夠進行處理運算的數字或向量。深度學習中多采用詞嵌入方法,如Word2Vec、Bert等方法將文本表示成多維的向量,用于后續的基于向量的分類。基于深度學習文本分類的不同應用研究,其主要的不同在于采用了不同的深度學習模型。目前,常見的深度學習文本分類模型有卷積神經網絡CNN[23]、長短時記憶網絡LSTM[24-25]、雙向長短時記憶網絡Bi-LSTM[26]、基于注意力機制的雙向長短時記憶網絡BiLSTM-Attention[27]等。
目前,基于深度學習的文本分類技術已開始應用于教育領域,并取得了一定的研究成果。例如馮翔等為自動識別在線學習過程中學生的學業情緒,構建了基于LSTM模型的學業情緒預測系統。該系統通過爬蟲程序獲取10萬余條在線學習中學生的反饋文本數據,利用LSTM模型實現學習者的學業情感的識別與分類,模型預測的準確率達到89%[14]。甄園宜等人收集了16047條學生在線協作學習過程中的交互文本數據,基于CNN、LSTM、Bi-LSTM模型,將學生在線協作學習過程中的交互文本進行分類,再根據交互文本所屬類別有針對性地進行在線協作學習的實時監測和干預[12]。研究的實驗結果表明,相對于CNN、LSTM模型而言,Bi-LSTM具有更高的準確率,為77.42%。羅梟應用Bi-LSTM結合CNN實現了試卷主觀題的自動評分。采用的方法是將之前主觀題的連續評分(如滿分6分)改為分成3個分數段,相當于將主觀題分為3類(0~1分為第1類,2~4分為第2類,5~6分為第3類),這樣就將主觀題的評分轉換成文本分類問題,在SST-2數據集上其準確率為89.7%[28]。
綜上所述,基于深度學習的文本分類能夠幫助人類減少大量重復、繁雜工作,是實現教育智能化的有力抓手之一。目前該基于深度學習的文本分類在教育領域中的應用尚處于起步階段。不同的應用情境,分類的準確率會受到數據集質量、深度學習模型的選定,以及分類歧義程度等諸多因素的影響。如何挖掘教育領域中的文本分類的教育問題,選擇適當的深度學習模型,是目前我們進行深度學習文本分類教育應用的關鍵所在。
三、基于深度學習的教師課堂提問分類方法
教師課堂教學提問分析本質上是文本分類問題。采用基于深度學習的文本分類方法對教師的課堂教學提問進行分析,能夠很好地解決傳統視頻分析方法無法大規模應用的問題。基于深度學習對教師的課堂提問進行分類,首先要構建分類體系,再利用深度學習的分類方法進行分類。下面以初中數學課堂為例,闡述基于深度學習的教師課堂提問分類方法。
(一)數學課堂提問的分類
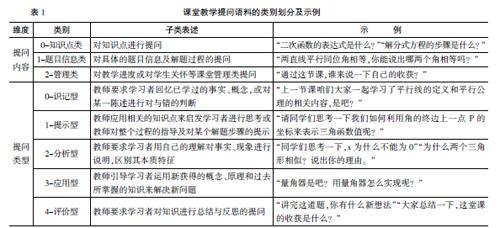
本文主要在于國文等關于數學課堂提問分類研究的基礎上[18],將數學課堂提問分為提問內容和提問類型兩大類。提問內容主要是“提問什么”,提問類型則依據布魯姆的教學目標分類,從提問認知層級的視角進行了進一步劃分。具體地,將提問按提問內容分為知識點類提問、題目信息類提問和管理類提問;將提問類型分為識記型提問、提示型提問、分析型提問、應用型提問、評價性提問。具體的類別劃分及示例見表1。
(二)基于深度學習的課堂提問分類的流程
基于深度學習的課堂提問分類主要包括數據收集、語料標注、數據預處理、數據表示、模型的選擇與訓練、預測六個步驟。
1. 數據收集與整理
數據收集是進行深度學習模型訓練的第一步,也是很關鍵的一步。數據集的數量、各類別數據量的均衡程度,都會對分類效果產生影響。教師課堂提問的數據多來源于課堂實錄,因此要先利用語音轉換軟件,將視頻中的語音轉換成文本。
2. 語料標注
將收集的數據以句子為單位進行標注。在本研究中將提問按其對應的提問內容分別標注為0、1、2三類,按提問類型標注為0、1、2、3、4五類。例如,將“解分式方程的步驟是什么?”按提問內容標注為0,按提問類型標注為0;“為什么兩個三角形相似?說出你的理由”按提問內容標注為1,按提問類型標注為2。
3. 數據預處理
數據預處理的目的是將收集的數據集轉換成符合深度學習模型訓練要求的數據。本研究中的預處理包括去除過長或過短語句、打亂語料順序,以及數據采樣。去除過長或過短語句,用于減少課堂語料數據集的噪聲。打亂語料順序即亂序學習,是在送入程序之前打亂語料的順序,使得深度學習效果更好。為避免各類別中訓練樣本的數據不均衡,本研究采用合成少數類過采樣與下采樣相結合的混合采樣方式,以降低因各類數據不均衡而導致的分類誤差。
4. 數據表示
數據表示一般有詞向量與字向量表示。詞向量是以詞為單位的向量表示,字向量是以字為單位的向量表示。在不同應用場景中,基于詞向量與字向量的深度學習會有不同的應用效果[29]。由于本研究的數據量不大,因此采用字向量進行數據表示。
5. 模型的選擇與訓練
從常用的深度學習模型中選擇模型作為分類器進行訓練,本研究選取CNN模型和LSTM模型作為課堂提問文本的分類器模型。
(1)CNN模型。CNN模型是卷積神經網絡(Convolutional Neural Networks)的簡稱。典型的CNN模型的結構包括輸入層、卷積層、池化層、全連接層和輸出層。其中卷積層是CNN模型的核心。這些卷積層具有小尺寸但可以在整個矩陣上移動的過濾器,即卷積核。卷積計算作為一種有效提取特征的方法,每一個步長卷積核會與輸入矩陣出現重合區域,重合區域對應的元素相乘、求和再加上偏置項得到輸出特征的一個像素點;池化用于減少卷積神經網絡中的特征數據量;全連接層中每個神經元與前后相鄰層的每一個神經元都有連接關系,輸入是特征,輸出為預測結果。CNN模型的基本原理:假設一個k維向量,首先將每個字的字向量拼接形成句向量送入神經網絡;之后使用卷積核對句子進行卷積操作,形成新特征;然后設置卷積核步長,得到句子矩陣的特征集;最后對特征集作最大值池化計算,找出最大的特征值與某一特定卷積核作對應,最終得到分類結果。
(2)LSTM模型。LSTM模型全稱長短時記憶網絡(Long Short-Term Memory),是一種特殊的循環神經網絡模型(RNN),它通過三個門結構(遺忘門、輸入門和輸出門),較好地解決了循環神經網絡的梯度消失、梯度爆炸,以及無法處理序列中長距離依賴問題。目前,LSTM已廣泛應用于不同領域的序列預測。LSTM模型的基本原理是通過三個門結構控制信息的輸入、更新和輸出,也就是通過門結構,有選擇地決定應丟棄、更新和輸出哪些信息。具體地,LSTM利用遺忘門,將前一時刻的隱藏狀態ht-1和當前輸入xt,經過Sigmoid函數δ,決定保留或丟棄前一時刻記憶單元Ct-1中哪些信息,計算方法為:ft=δ(Wf·[ht-1,xt]+bf),其中ft表示信息遺忘值,ft=0表示全部舍棄,ft=1表示全部保留。Wf和bf分別表示遺忘門的連接權重和偏置。輸入門決定了在當前節點中應添加哪些信息,輸入門先通過一個Sigmoid函數,用于控制要更新的信息it,it=δ(Wi·[ht-1,xt]+bi),Wi和bi分別表示輸入門的連接權重和偏置,再經過tanh函數生成候選向量■■,■■=tanh(WC·[ht-1,xt]+bC),WC和bC分別表示更新值連接權重和偏置值,則當前記憶單元的狀態Ct=ft*Ct-1+it*■■。輸出門決定了最后輸出什么信息,確定具體的輸出信息。最后的輸出經過了Sigmoid函數和tanh函數,Ot=δ(Wo·[ht-1,xt]+bo),ht=Ot*tanh Ct,Ot表示輸出門狀態,Wo和bo分別表示輸出門的權重和偏置,ht表示最終輸出值,Ct表示當前記憶單元狀態。確定好模型后,應用經過預處理的數據對模型進行訓練,并調整模型參數,直至模型在測試集上的評價指標不再增加。
6. 預測
選擇具有更好分類效果的模型作為分類器,將待分析的提問句子經過數據表示轉換后輸入到模型中進行分類,達到最終的分類結果。
四、實驗及結果分析
(一)實驗數據集
表2? ? ? ? ? ? ? ? ? 各提問類型語料分布表
本研究收集80節初中數學優秀課堂實錄,共收集到9090條課堂提問語料。為保證課堂提問數據的有效性和數據均衡性,本研究刪除了部分數據。將調整后的教師課堂提問語料分為訓練集、驗證集和測試集,即分別選取每類數據中的60%作為訓練集、20%作為驗證集和20%作為測試集。數據集在提問內容、提問類型維度上的分布情況見表2。
(二)評價標準
本研究通過繪制準確率(Accuracy)和損失率(Loss)變化趨勢圖來直觀得知模型訓練過程表現情況。使用精確率(Precision)、召回率(Recall)、F1值和準確率(Accuracy)作為課堂教師提問分類效果的評價指標,并延伸二分類的評價標準。計算公式如下:
Precision = ■? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? (1)
Recall = ■? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ?(2)
F1 = ■? ? ? ? ? ? ? ? ? ? ? ? ?(3)
Accuracy = ■? ? ? ? ? ? ? ? ? ? ?(4)
其中,TP表示預測正確的正樣本數量,FP表示預測錯誤的正樣本數量,TN表示預測正確的負樣本數量,FN是預測錯誤的負樣本數量。Precision針對預測結果而言,表示在被所有預測為正樣本中實際為正樣本的概率,即精確率;Recall針對原樣本而言,表示實際為正樣本中被預測為正樣本的概率,即召回率;精確率和召回率又被叫作查準率和查全率,F1分數同時考慮精確率和召回率,讓兩者同時達到最高,取得平衡,即對分類器的性能進行綜合評判。Accuracy表示預測正確的結果占總樣本的百分比,代表整體的預測準確程度,包括正樣本和負樣本。
(三)實驗模型設置
實驗的硬件環境為Intel(R) Core(TM)i7-9700K CPU、64GB內存,操作系統是64位Windows10。采用Keras框架來搭建基于深度神經網絡的兩個分類模型。其中“epochs”設置為100輪、“batch_size” 設置為64、“dropout”設置為0.2、“learning_rate”設置為1e-3。模型的其他參數的設置為:(1)CNN模型。使用256個大小尺寸為5的卷積核來提取文本特征,經過全局最大值池化操作后,全連接層神經元的個數是128,最后使用Softmax函數對提問文本分類。(2)LSTM模型。使用128個LSTM隱藏層的神經單元進行語義信息學習,連接2個隱藏層層數進入全連接層,使用Adam方法進行優化,最后使用Softmax函數對提問文本分類。
(四)實驗結果與分析
使用訓練集對上述兩個文本分類器模型進行訓練,經由驗證集調整參數后,獲得的分類模型在測試集上進行分類測試的各項指標見表3。
表3? ? ? ? ? ? ? 提問內容分類的實驗結果
表4? ? ? ? ? ? ? ?提問類型分類的實驗結果
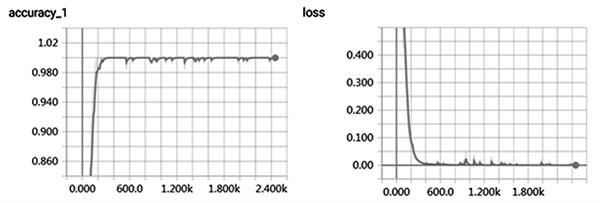
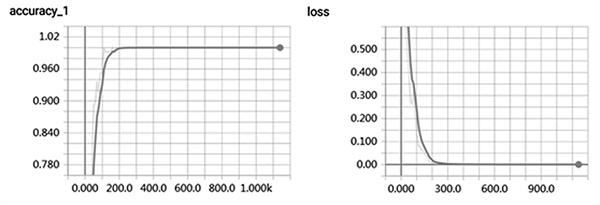
觀察表3和表4可知,CNN模型的整體準確率較LSTM模型高。其中,在提問內容維度上相較于LSTM模型提高了5.27%;在提問類型維度上相較于LSTM模型提高了4.59%。結果表明,在課堂內容維度及提問類型維度的分類中,CNN模型可以更好地提取短文本信息。此外,CNN模型在訓練集和驗證集中的準確率和Loss值的變化曲線如圖1和2所示。可知,CNN模型在訓練數據集的過程中,模型準確率逐漸升高,Loss值逐漸縮小,模型的訓練過程表現良好。
五、結? ?語
課堂提問是教師課堂教學的重要教學技能之一,是教師專業發展中的關鍵環節。現有的視頻分析法,通過人工編碼和看視頻,能夠對教師的課堂提問進行分析,挖掘課堂上教師提問的數量、提問的類型以及提問的內容等。但這種方法耗時耗力,無法進行大范圍推廣與應用。本研究提出了基于深度學習文本分類技術的教師課堂提問分析方法。該方法先收集教師課堂提問數據,經過預處理后對深度學習模型(卷積神經網絡和長短時記憶網絡)進行訓練,使得深度學習模型能夠自動對課堂提問進行預測分類。從實驗結果的評價指標上看,該方法可以替代基于人工的視頻分析方法,能夠對教師課堂提問分析進行大規模應用,有助于促進教師專業發展。本研究的實驗結果表明,基于深度學習的智能文本處理方法可替代,或部分替代原有的人工操作,成為助力教師專業發展,乃至整個教育領域發展的利器。
[參考文獻]
[1] 洪松舟,盧正芝.我國有效課堂提問研究十余年回顧與反思[J].河北師范大學學報(教育科學版),2008,10(12):34-37.
[2] 盧正芝,洪松舟.教師有效課堂提問:價值取向與標準建構[J].教育研究,2010,31(4):65-70.
[3] 陳薇,沈書生.小學數學教學中深度問題的研究——基于專家教師課堂提問的案例分析[J].課程·教材·教法,2019,39(10):118-123.
[4] 葉立軍,鄭欣.專家型數學教師代數復習課提問行為研究——以一次函數和反比例函數為例[J].數學教育學報,2018,27(2):46-49.
[5] 鄭友富.專家型教師與新手教師課堂提問的比較研究[J].教育科學研究,2009(11):57-60.
[6] 葉立軍,斯海霞.基于錄像分析背景下的代數課堂教學提問研究[J].教育理論與實踐,2010,30(8):41-43.
[7] 周瑩,王華.中美中學數學優秀教師課堂提問的比較研究——以兩國同課異構的課堂錄像為例[J].數學教育學報,2013,22(4):25-29.
[8] 胡啟宙,孫慶括.初中數學教師課堂提問的方式和反饋水平實證研究——基于三位教師課堂錄像的編碼分析[J].數學教育學報,2015,24(4):72-75.
[9] 葉立軍. 數學教師課堂教學行為比較研究[D].南京:南京師范大學,2012.
[10] 張文宇,范會勇.基于 NVivo10 分析的數學教育專業碩士課堂提問研究——以首屆全國全日制教育碩士學科教學(數學)專業教學技能決賽視頻為例[J].數學教育學報,2019,28(1):92-96.
[11] 葉立軍,周芳麗.基于錄像分析背景下的教師提問方式研究[J].教育理論與實踐,2012,32(5):52-54.
[12] 甄園宜,鄭蘭琴.基于深度神經網絡的在線協作學習交互文本分類方法[J].現代遠程教育研究,2020,32(3):104-112.
[13] 魏艷濤,秦道影,胡佳敏,姚璜,師亞飛.基于深度學習的學生課堂行為識別[J].現代教育技術,2019,29(7):87-91.
[14] 馮翔,邱龍輝,郭曉然.基于LSTM模型的學生反饋文本學業情緒識別方法[J].開放教育研究,2019,25(2):114-120.
[15] 邵懷領.課堂提問有效性:標準、策略及觀察[J].教育科學,2009,25(1):38-41.
[16] 黃會來,王迎.數學高效與低效教師課堂提問教學行為的案例比較[J].數學教育學報,2011,20(3):90-92.
[17] 黃友初.教師課堂教學行為的四個要素[J].數學教育學報,2016,25(1):72-74.
[18] 于國文,曹一鳴.“中澳法芬”中學數學課堂教師提問的實證研究[J].數學教育學報,2019,28(2):56-63.
[19] 顧泠沅,周衛.課堂教學的觀察與研究——學會觀察[J]上海教育,1999(5):14-18.
[20] 涂榮豹.數學建構主義學習的實質及其主要特征[J].數學教育學報,1999(4):16-20.
[21] 余凱,賈磊,陳雨強,徐偉.深度學習的昨天、今天和明天[J].計算機研究與發展,2013,50(9):1799-1804.
[22] 張建明,詹智財,成科揚,詹永照.深度學習的研究與發展[J].江蘇大學學報(自然科學版),2015,36(2):191-200.
[23] 馮帥,許童羽,周云成,趙冬雪,金寧,王郝日欽. 基于深度卷積神經網絡的水稻知識文本分類方法[J]. 農業機械學報,2021(2):1-13.
[24] 趙明,杜會芳,董翠翠,陳長松.基于word2vec和LSTM的飲食健康文本分類研究[J].農業機械學報,2017,48(10):202-208.
[25] 曾誰飛,張笑燕,杜曉峰,陸天波.基于神經網絡的文本表示模型新方法[J].通信學報,2017,38(4):86-98.
[26] 翁洋,谷松原,李靜,王楓,李俊良,李鑫.面向大規模裁判文書結構化的文本分類算法[J].天津大學學報(自然科學與工程技術版),2021,54(4):418-425.
[27] 馮斌,張又文,唐昕,郭創新,王堅俊,楊強,王慧芳.基于BiLSTM-Attention神經網絡的電力設備缺陷文本挖掘[J].中國電機工程學報,2020,40(S1):1-10.
[28] 羅梟. 基于深度學習的課程主觀題自動判卷技術研究與實現[D].杭州:浙江農林大學,2019.
[29] 劉敬學,孟凡榮,周勇,劉兵.字符級卷積神經網絡短文本分類算法[J].計算機工程與應用, 2019,55(5):135-142.
猜你喜歡
中國教育技術裝備(2016年19期)2016-12-27 19:23:52
中國遠程教育(2016年11期)2016-12-27 18:07:31
現代商貿工業(2016年25期)2016-12-26 09:58:02
江蘇教育·中學教學版(2016年11期)2016-12-21 11:45:08
江蘇教育·中學教學版(2016年11期)2016-12-21 11:36:29
現代情報(2016年10期)2016-12-15 11:50:53
考試周刊(2016年94期)2016-12-12 12:15:04
新教育時代·教師版(2016年23期)2016-12-06 06:02:38
法制與社會(2016年32期)2016-12-01 15:25:53
軟件導刊(2016年9期)2016-11-07 22:20:49
