多智能體動(dòng)態(tài)目標(biāo)協(xié)同搜索策略研究
2021-09-22 05:17:50趙梓良李博倫馬力超張志彥
航天電子對(duì)抗 2021年4期
趙梓良,劉 洋,李博倫,馬力超,張志彥
(北京機(jī)械設(shè)備研究所,北京 100039)
0 引言
隨著建圖定位、目標(biāo)識(shí)別、機(jī)器學(xué)習(xí)和通信組網(wǎng)等技術(shù)的成熟,無(wú)人智能體以其運(yùn)算速度快、運(yùn)動(dòng)速度快、能長(zhǎng)時(shí)間作業(yè)、能在極端環(huán)境下作業(yè)等特點(diǎn),在目標(biāo)搜索課題中受到青睞,被期望替代人類(lèi)在危險(xiǎn)、惡劣環(huán)境中高效長(zhǎng)時(shí)間執(zhí)行巡邏、偵察和搜救任務(wù)[1]。而多智能體的集群協(xié)作作業(yè)又能大大提升目標(biāo)搜索任務(wù)的完成效率。
多智能體集群搜索策略是多機(jī)器人領(lǐng)域中一個(gè)重要的研究課題,通過(guò)一個(gè)顯示控制平臺(tái)和多個(gè)智能單體(如無(wú)人機(jī))之間的協(xié)同策略規(guī)劃,完成對(duì)一定區(qū)域內(nèi)的靜止、運(yùn)動(dòng)目標(biāo)的搜索任務(wù)[2?7]。多智能體集群搜索策略設(shè)計(jì)主要包括2個(gè)步驟,一是智能體對(duì)待搜索環(huán)境場(chǎng)景的理解與建圖,二是智能體對(duì)待搜索環(huán)境場(chǎng)景的協(xié)同搜索策略設(shè)計(jì)。
目前環(huán)境地圖的典型表示方法包括尺度地圖和拓?fù)涞貓D2種。其中尺度地圖基于直接度量信息表示環(huán)境細(xì)節(jié),為地圖中最小單位區(qū)域(柵格)賦值,如用0表示自由空間而用1表示障礙物。拓?fù)涞貓D則是提取自由空間中的關(guān)鍵節(jié)點(diǎn),并用邊連接相鄰的節(jié)點(diǎn),形成拓?fù)渚W(wǎng)絡(luò)結(jié)構(gòu)[8]。與尺度地圖相比,拓?fù)涞貓D表示相同環(huán)境地圖所需的數(shù)據(jù)信息更少,因此更適合在大型、復(fù)雜環(huán)境下執(zhí)行目標(biāo)搜索和巡邏等任務(wù)[8?10]。
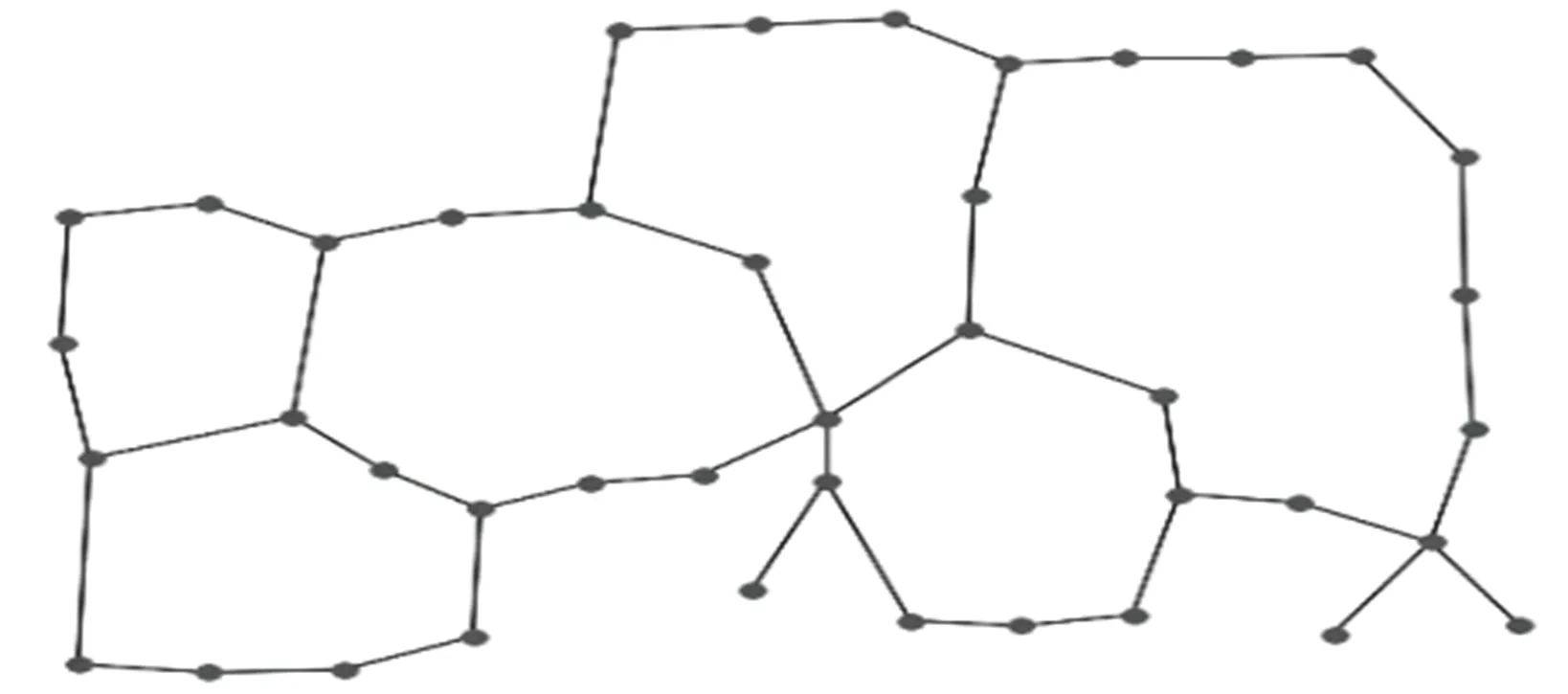
圖2 由示例場(chǎng)景尺寸地圖提取出的拓?fù)涞貓D
目前在多智能體對(duì)環(huán)境區(qū)域進(jìn)行協(xié)同搜索的研究成果中,2種典型的搜索策略為:基于貪心算法的路徑規(guī)劃策略[11?13]與基于拓?fù)涞貓D區(qū)域劃分和分區(qū)最優(yōu)回路求解的多級(jí)子圖巡邏(MSP)策略[14?16]。基于貪心算法的路徑規(guī)劃策略將路徑點(diǎn)盡量平均地分配給每個(gè)智能體,使完成各自路徑需要耗費(fèi)的時(shí)間中最長(zhǎng)的智能體的時(shí)間最短。應(yīng)用該類(lèi)方法的搜索系統(tǒng)在理論上能完成對(duì)區(qū)域的快速覆蓋搜索,但由于各智能單體的規(guī)劃路徑中首末位置距離較遠(yuǎn),在搜索環(huán)境較復(fù)雜、搜索場(chǎng)景中障礙物較多的情況下,智能體返回起點(diǎn)過(guò)程容易宕機(jī),因此不適用于長(zhǎng)時(shí)間復(fù)雜環(huán)境的區(qū)域搜索和巡邏。基于拓?fù)涞貓D劃分和分區(qū)最優(yōu)回路求解的多級(jí)子圖巡邏策略首先根據(jù)多層k劃分法折疊頂點(diǎn)和邊來(lái)減小圖的大小,對(duì)較小的圖進(jìn)行k劃分、再分解和細(xì)化后構(gòu)建原始圖的k路區(qū)域劃分,最后對(duì)劃分后的子拓?fù)涞貓D求解最優(yōu)回路問(wèn)題,依次判定是否存在歐拉回路、哈密頓回路、非哈密頓回路與最長(zhǎng)搜索路徑,并作為子拓?fù)涞貓D內(nèi)單體的搜索路線(xiàn)。應(yīng)用該類(lèi)方法的搜索系統(tǒng)解決了貪心算法規(guī)劃的路徑不閉合、巡邏過(guò)程易宕機(jī)問(wèn)題,能長(zhǎng)時(shí)間循環(huán)執(zhí)行搜索、巡邏任務(wù),并在搜索靜態(tài)目標(biāo)時(shí)有良好的表現(xiàn)。但該策略仍然存在在各智能單體負(fù)責(zé)的區(qū)域邊界地帶搜索效果不佳、巡邏路線(xiàn)過(guò)于規(guī)律、容易被目標(biāo)人或具有感知和決策能力的目標(biāo)智能體掌握并學(xué)習(xí)規(guī)避的問(wèn)題。并且在實(shí)際場(chǎng)景中,智能體的故障會(huì)導(dǎo)致其負(fù)責(zé)巡邏的區(qū)域的搜索失效,該區(qū)域成為盲區(qū)。
目前搜索場(chǎng)景中動(dòng)態(tài)目標(biāo)的躲避策略方面的研究較少,動(dòng)態(tài)目標(biāo)多采取隨機(jī)運(yùn)動(dòng)策略或規(guī)律性巡線(xiàn)運(yùn)動(dòng)策略。而在被廣泛研究的追捕?逃跑模型課題中,模型中目標(biāo)的逃跑策略則能為搜索場(chǎng)景下目標(biāo)人或具有感知和決策能力的目標(biāo)智能體的躲避策略設(shè)計(jì)提供參考。
基于上述目標(biāo)搜索方法的啟發(fā),本文提出了一種防具備躲避策略的動(dòng)態(tài)目標(biāo)的協(xié)同搜索策略。運(yùn)用強(qiáng)化學(xué)習(xí)框架使多智能體和具備躲避策略的目標(biāo)進(jìn)行對(duì)抗性的搜索訓(xùn)練,讓多智能體集群搜索系統(tǒng)不斷訓(xùn)練、修正和優(yōu)化搜索策略,提高針對(duì)動(dòng)態(tài)目標(biāo)的搜索效率和應(yīng)對(duì)單體宕機(jī)問(wèn)題的魯棒性。
1 協(xié)同搜索策略
1.1 拓?fù)涞貓D提取
如前文所述,拓?fù)涞貓D相比于尺度地圖,表示環(huán)境所需的數(shù)據(jù)信息更少,更適用于目標(biāo)搜索任務(wù),其數(shù)據(jù)信息可以表示為G=(V,E),其中V表示地圖中的關(guān)鍵節(jié)點(diǎn)集合,而E表示連接關(guān)鍵節(jié)點(diǎn)的邊以及該條邊的長(zhǎng)度[8]。而實(shí)際建圖的激光雷達(dá)等傳感器獲取的是占據(jù)柵格地圖,因此首先需要將原始的柵格地圖轉(zhuǎn)換成拓?fù)涞貓D[17]。圖1?2展示了從尺度地圖提取出拓?fù)涞貓D的示例效果。
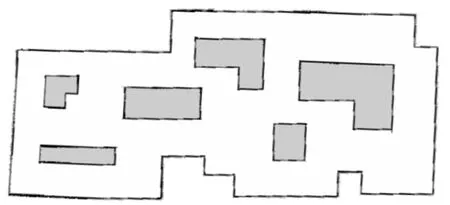
圖1 gmapping算法建圖獲得的場(chǎng)景尺寸地圖
上述拓?fù)涞貓D提取的方法是通過(guò)對(duì)環(huán)境區(qū)域進(jìn)行廣度優(yōu)先搜索,先計(jì)算地圖中自由空間的連通區(qū)域,根據(jù)智能體的尺寸對(duì)柵格地圖中的障礙物邊緣輪廓進(jìn)行填充擴(kuò)展,確保智能體既能在最終拓?fù)涞貓D相鄰的節(jié)點(diǎn)間通行又不會(huì)與障礙物邊緣碰撞;再通過(guò)擴(kuò)展泰森多邊形圖(EVG)的方法以均勻的節(jié)點(diǎn)和邊表示環(huán)境地圖的拓?fù)湫畔8,17]。
1.2 基于強(qiáng)化學(xué)習(xí)的協(xié)同搜索策略
對(duì)于優(yōu)化具有躲避策略的動(dòng)態(tài)目標(biāo)的協(xié)同搜索效率問(wèn)題,難點(diǎn)在于智能體對(duì)環(huán)境場(chǎng)景的搜索經(jīng)驗(yàn)的缺失。而Q-learning強(qiáng)化學(xué)習(xí)框架可以不要求先驗(yàn)數(shù)據(jù),通過(guò)訓(xùn)練不斷優(yōu)化搜索策略。在該強(qiáng)化學(xué)習(xí)系統(tǒng)中,決策者通過(guò)觀察環(huán)境,根據(jù)當(dāng)前狀態(tài)下的觀測(cè)信息做出動(dòng)作嘗試,并接受環(huán)境對(duì)動(dòng)作嘗試的獎(jiǎng)勵(lì)和懲罰反饋來(lái)獲得學(xué)習(xí)信息并不斷更新搜索策略的Q值表。Q值表的行索引對(duì)應(yīng)決策者所處的狀態(tài),列索引對(duì)應(yīng)在某一狀態(tài)下執(zhí)行的動(dòng)作嘗試,更新對(duì)應(yīng)行列的Q值會(huì)不斷修正決策者進(jìn)行動(dòng)作嘗試的概率。在這個(gè)過(guò)程中符合設(shè)計(jì)目的的動(dòng)作會(huì)獲得獎(jiǎng)勵(lì),決策者再次遇到同樣場(chǎng)景會(huì)更傾向于采取這一動(dòng)作,而與設(shè)計(jì)目的不符的動(dòng)作則會(huì)得到懲罰,決策者會(huì)盡量避免這樣的動(dòng)作。經(jīng)過(guò)若干次嘗試,決策者對(duì)其所處的環(huán)境有了充分的理解,知道在某一狀態(tài)下獲得盡可能大的獎(jiǎng)勵(lì)的動(dòng)作[18?20]。Q-learning強(qiáng)化學(xué)習(xí)框架中策略的更新可以表示為:
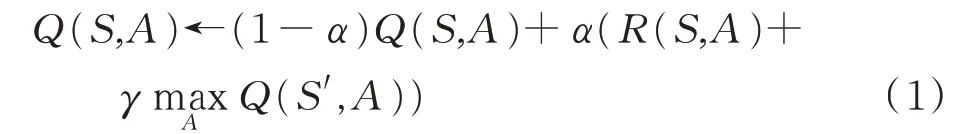
式中,S表示智能體當(dāng)前狀態(tài),A表示智能體在S狀態(tài)下采取的動(dòng)作,Q(S,A)表示在S狀態(tài)下采取A動(dòng)作的Q值,R(S,A)表示在S狀態(tài)下采取A動(dòng)作的即時(shí)獎(jiǎng)勵(lì),S′表示在S狀態(tài)采取A動(dòng)作后的下一狀態(tài),α為學(xué)習(xí)率,γ為折扣因子。
在本文提出的協(xié)同搜索策略中,智能體所處狀態(tài)的集合(狀態(tài)空間)為拓?fù)涞貓D中關(guān)鍵節(jié)點(diǎn)集合V。而智能體在每一狀態(tài)下可采取的動(dòng)作集合(動(dòng)作空間)為拓?fù)涞貓D中與該狀態(tài)對(duì)應(yīng)的節(jié)點(diǎn)相連通的節(jié)點(diǎn),表示由當(dāng)前狀態(tài)對(duì)應(yīng)的節(jié)點(diǎn)向可通行的下一節(jié)點(diǎn)運(yùn)動(dòng)的動(dòng)作。初始策略設(shè)置為隨機(jī)搜索,智能體隨機(jī)選擇在各個(gè)狀態(tài)下的動(dòng)作,該策略表示為值均為0的Q值表。獎(jiǎng)勵(lì)在一次搜索完成后反饋給智能體搜索到目標(biāo)必要路徑上的所有狀態(tài),以激勵(lì)決策者在后續(xù)到達(dá)這些狀態(tài)時(shí)盡可能選擇發(fā)現(xiàn)目標(biāo)概率更大的動(dòng)作。在多智能體系統(tǒng)中,智能單體在各個(gè)狀態(tài)下選擇動(dòng)作的策略具有共通性,因此設(shè)計(jì)系統(tǒng)中的智能體共用一個(gè)Q值表,增加訓(xùn)練效率。而為了避免所有智能單體根據(jù)Q值表采取相同動(dòng)作,參考基于節(jié)點(diǎn)空閑時(shí)間的巡邏策略[18,21]對(duì)即時(shí)策略做出調(diào)整。基于節(jié)點(diǎn)空閑時(shí)間的巡邏策略提出由主控平臺(tái)發(fā)布拓?fù)涞貓D中各節(jié)點(diǎn)的空閑時(shí)間信息,各智能體自由搶占附近空閑時(shí)間長(zhǎng)的節(jié)點(diǎn)作為目標(biāo)點(diǎn)。參照此方法中節(jié)點(diǎn)空閑時(shí)間設(shè)置方式,對(duì)任一智能體,將空閑時(shí)間不超過(guò)某一閾值的節(jié)點(diǎn),即剛被訪問(wèn)過(guò)的節(jié)點(diǎn)的Q值即時(shí)調(diào)整為0,以避免多智能體互相跟隨或在局部回路轉(zhuǎn)圈等問(wèn)題。
2 動(dòng)態(tài)目標(biāo)的躲避策略
人工勢(shì)場(chǎng)法[22]及其優(yōu)化方法在局部路徑規(guī)劃和追捕?逃跑研究課題中被廣泛應(yīng)用,該類(lèi)方法根據(jù)物體當(dāng)前位置及其周?chē)恼系K物、追捕者和目標(biāo)點(diǎn)的位置關(guān)系,在目標(biāo)周?chē)O(shè)置虛擬力場(chǎng),其中障礙物、追捕者在物體的感知范圍內(nèi)對(duì)物體產(chǎn)生斥力,而目標(biāo)點(diǎn)對(duì)物體產(chǎn)生引力,且力場(chǎng)強(qiáng)度由物體之間相對(duì)距離決定。物體在該虛擬力場(chǎng)影響下進(jìn)行局部路徑規(guī)劃,避開(kāi)障礙物和追捕者向目標(biāo)點(diǎn)移動(dòng)。但在多智能體集群搜索策略研究中,上述基于相對(duì)位置關(guān)系的人工勢(shì)場(chǎng)法并不適用。與追捕?逃跑問(wèn)題中追捕者根據(jù)逃跑者的位置進(jìn)行包圍不同,搜索場(chǎng)景下搜索者在搜索到目標(biāo)前并不能獲知目標(biāo)的位置和與目標(biāo)的距離。因此以與搜索者的距離作為影響動(dòng)態(tài)目標(biāo)的躲避策略的依據(jù)與實(shí)際情況不符。
考慮在實(shí)際搜索場(chǎng)景中,目標(biāo)人物與作為搜索者的智能單體(如無(wú)人機(jī))觀測(cè)、識(shí)別距離相近,而目標(biāo)人物可以依據(jù)無(wú)人機(jī)運(yùn)行過(guò)程中旋翼的槳葉發(fā)出的聲音判斷其感知范圍內(nèi)有無(wú)搜索者靠近或遠(yuǎn)離,然后進(jìn)行躲避的行為,設(shè)置了一種基于動(dòng)作(位置變化)的人工勢(shì)場(chǎng)法的躲藏策略。該策略中目標(biāo)不僅感知一定范圍內(nèi)的搜索者的位置,同時(shí)感知該范圍內(nèi)的搜索者較自己執(zhí)行的動(dòng)作(靠近或遠(yuǎn)離),僅計(jì)算靠近的搜索者施加的斥力作為躲避動(dòng)作的決策依據(jù)。目標(biāo)感知范圍內(nèi)搜索者對(duì)目標(biāo)的斥力場(chǎng)[23]可以表示為:
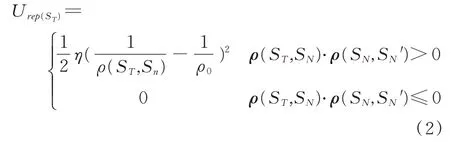
式中,U rep表示該位置的斥力場(chǎng)大小,ST為目標(biāo)位置,SN為N號(hào)搜索者位置,η為斥力尺度因子,ρ為2點(diǎn)之間的距離,ρ0為搜索者影響半徑。目標(biāo)受斥力大小則是其感知范圍內(nèi)斥力場(chǎng)的梯度,可以表示為:
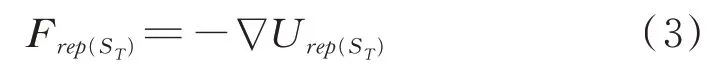
式中,F(xiàn) rep表示目標(biāo)在ST位置受到的斥力。
圖3給出了該躲避策略的示意圖。目標(biāo)當(dāng)前所處位置為ST,圓內(nèi)區(qū)域?yàn)槟繕?biāo)ST的當(dāng)前感知范圍,S1—S5表示其周?chē)阉髡叩奈恢茫瑢?shí)線(xiàn)箭頭方向?yàn)槟繕?biāo)感知的搜索者動(dòng)作方向。在該狀態(tài)下,目標(biāo)ST僅考慮觀測(cè)范圍內(nèi)向其靠近的搜索者S2和S3的動(dòng)作進(jìn)行躲避,圖中虛線(xiàn)表示的向量示意了這一躲避策略的決策過(guò)程。
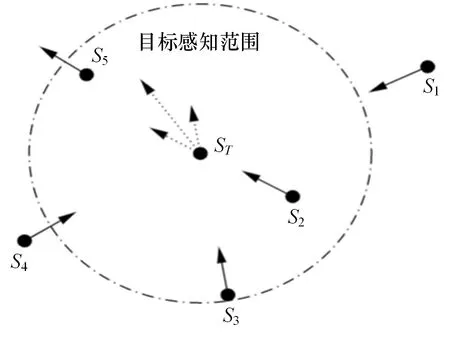
圖3 動(dòng)態(tài)目標(biāo)基于動(dòng)作的躲避策略示意圖
3 仿真校驗(yàn)
為驗(yàn)證動(dòng)態(tài)目標(biāo)躲避策略的效果和經(jīng)過(guò)對(duì)抗訓(xùn)練得到的協(xié)同搜索策略的有效性,在三維仿真平臺(tái)Gazebo中分別設(shè)置靜態(tài)目標(biāo)搜索和動(dòng)態(tài)目標(biāo)搜索仿真實(shí)驗(yàn),校驗(yàn)選用圖1的場(chǎng)景進(jìn)行,場(chǎng)景總面積為450.0 m2,其中可通行區(qū)域約317.9 m2,障礙物區(qū)域面積約132.1 m2。圖4展示了場(chǎng)景和場(chǎng)景中4個(gè)初始狀態(tài)的智能體、1個(gè)隨機(jī)目標(biāo)的仿真可視化實(shí)景。

圖4 Gazebo平臺(tái)中仿真場(chǎng)景和場(chǎng)景中4個(gè)位于初始區(qū)域的智能體(左上黑點(diǎn))及1個(gè)位于隨機(jī)位置的目標(biāo)(右上藍(lán)點(diǎn))
對(duì)于靜止目標(biāo)搜索,在環(huán)境地圖中同一初始區(qū)域(搜索出發(fā)區(qū))內(nèi),分別加載1—10個(gè)配置有定位、感知與識(shí)別、決策與驅(qū)動(dòng)等功能模塊的無(wú)人機(jī)模型作為搜索者,以及1個(gè)初始位置隨機(jī)的目標(biāo)人物模型作為目標(biāo)。搜索者同時(shí)從搜索出發(fā)區(qū)出發(fā),分別對(duì)整個(gè)區(qū)域按照文獻(xiàn)[14]提出的多級(jí)子圖巡邏策略和本文提出的訓(xùn)練后協(xié)同策略(Q值表)展開(kāi)搜索。當(dāng)目標(biāo)人物位置與任一搜索者距離小于1 m且不被遮擋時(shí),視為發(fā)現(xiàn)目標(biāo)并完成一個(gè)校驗(yàn)回合,同時(shí)記錄本次校驗(yàn)的搜索時(shí)間。由于在本文校驗(yàn)中選用的拓?fù)涞貓D邊長(zhǎng)相近(平均邊長(zhǎng)0.499 m,標(biāo)準(zhǔn)差0.031 m)、智能體在各節(jié)點(diǎn)停留的時(shí)間相近但難以測(cè)算,因此統(tǒng)計(jì)搜索者搜索的節(jié)點(diǎn)數(shù)量(即步數(shù))表示搜索時(shí)間,提高訓(xùn)練速度。搜索者數(shù)量從1個(gè)依次增加至10個(gè),分別重復(fù)10 000個(gè)校驗(yàn)回合。
對(duì)于動(dòng)態(tài)目標(biāo)搜索,只需在上述靜態(tài)目標(biāo)搜索仿真校驗(yàn)的基礎(chǔ)上為初始位置隨機(jī)的目標(biāo)人物配置定位、感知與識(shí)別、躲避策略與驅(qū)動(dòng)功能。同樣地將搜索者數(shù)量從1個(gè)依次增加至10個(gè),重復(fù)10 000個(gè)校驗(yàn)回合。
圖5展示了不同數(shù)量智能體應(yīng)用文獻(xiàn)[14]提出的多級(jí)子圖巡邏策略,對(duì)靜止目標(biāo)和具備本文提出的躲避策略的動(dòng)態(tài)目標(biāo)搜索的平均步數(shù)。校驗(yàn)結(jié)果表明,本文提出的基于動(dòng)作的人工勢(shì)場(chǎng)法的躲避策略會(huì)大大增加現(xiàn)有巡邏策略的搜索難度。原因是能精確判斷搜索者動(dòng)作的目標(biāo)可以在多個(gè)智能體各自負(fù)責(zé)的區(qū)域邊界間反復(fù)移動(dòng),規(guī)避搜索者。與隨機(jī)的靜止目標(biāo)搜索相比,應(yīng)用巡邏策略搜索具備躲藏策略的動(dòng)態(tài)目標(biāo)平均搜索步數(shù)增加了2.0倍,證明了動(dòng)態(tài)目標(biāo)躲避策略的有效性以及改進(jìn)現(xiàn)有多極子圖巡邏策略的必要性。
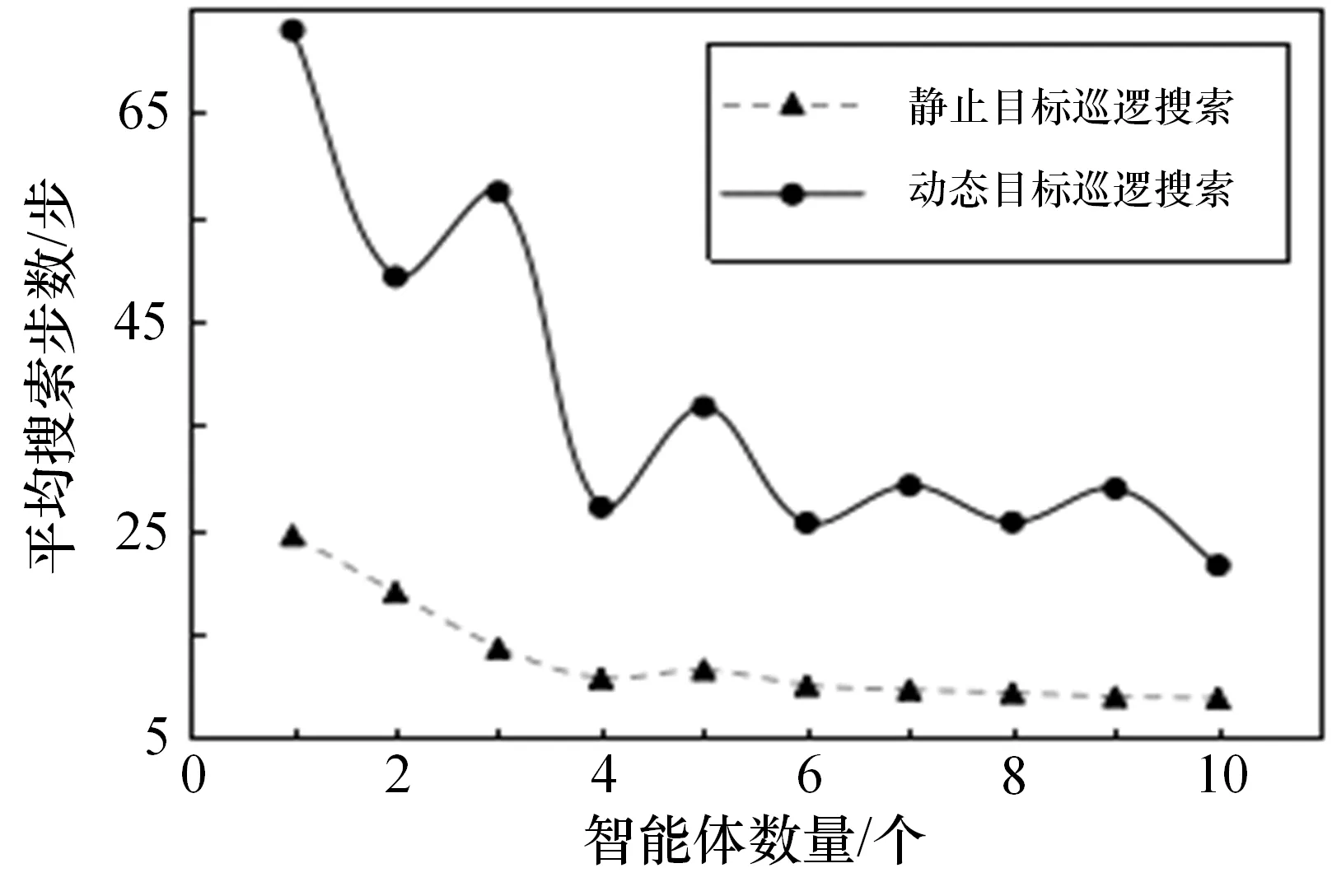
圖5 巡邏策略對(duì)靜止目標(biāo)和應(yīng)用躲避策略的動(dòng)態(tài)目標(biāo)搜索結(jié)果對(duì)比
圖6展示了不同數(shù)量智能體應(yīng)用多級(jí)子圖巡邏策略和訓(xùn)練后的協(xié)同搜索策略(智能搜索策略)對(duì)于靜止目標(biāo)搜索所需的平均步數(shù)。當(dāng)智能單體搜索靜態(tài)目標(biāo)時(shí),巡邏策略表現(xiàn)更為優(yōu)秀。但當(dāng)智能體數(shù)量大于1時(shí),2種策略完成目標(biāo)搜索的整體搜索效率相近。搜索者數(shù)量為3到10個(gè)時(shí),2種策略平均搜索步數(shù)差值均在1.0步內(nèi),且隨著搜索者數(shù)量的增加,2種策略完成目標(biāo)搜索的平均步數(shù)都呈下降趨勢(shì),并最終收斂趨近于9.0步,證明對(duì)于靜態(tài)目標(biāo),2種搜索方式具備相近的整體表現(xiàn)。
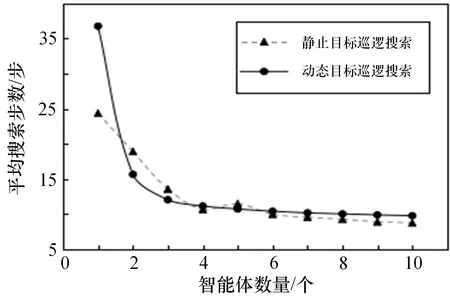
圖6 靜止目標(biāo)搜索效率仿真校驗(yàn)
圖7展示了巡邏策略和智能搜索策略對(duì)于有躲避能力的動(dòng)態(tài)目標(biāo)進(jìn)行搜索所需的平均步數(shù)。其中單個(gè)搜索者的情況下,智能搜索策略所需時(shí)間過(guò)長(zhǎng),視為無(wú)法完成搜索任務(wù)。對(duì)于有躲避能力的運(yùn)動(dòng)目標(biāo),智能搜索策略比巡邏策略整體表現(xiàn)更佳。當(dāng)智能體數(shù)量大于1時(shí),智能搜索策略較巡邏策略,平均搜索效率提升了48.5個(gè)百分點(diǎn),且隨著搜索者數(shù)量的增加,2種策略完成目標(biāo)搜索的平均步數(shù)都呈下降趨勢(shì)。
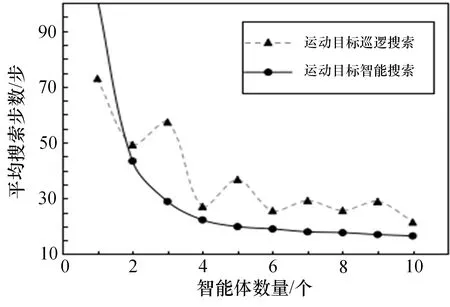
圖7 運(yùn)動(dòng)目標(biāo)搜索效率仿真校驗(yàn)
4 結(jié)束語(yǔ)
本文提出了一種在已知環(huán)境下搜索靜態(tài)目標(biāo)和具備躲避能力的動(dòng)態(tài)目標(biāo)的協(xié)同搜索策略。在該搜索策略中,地圖信息的提取采用了拓?fù)涞貓D,以較少的數(shù)據(jù)量表示環(huán)境信息。初始搜索策略采用隨機(jī)搜索策略,通過(guò)Q-learning強(qiáng)化學(xué)習(xí)框架不斷訓(xùn)練更新并基于節(jié)點(diǎn)空閑時(shí)間即時(shí)調(diào)整。目標(biāo)的躲避策略參照路徑規(guī)劃和追捕問(wèn)題中基于位置的人工勢(shì)場(chǎng)法設(shè)計(jì)了基于動(dòng)作的人工勢(shì)場(chǎng)法。通過(guò)仿真校驗(yàn),校驗(yàn)了動(dòng)態(tài)目標(biāo)躲避策略的有效性,并通過(guò)與現(xiàn)有多極子圖巡邏策略的對(duì)比仿真,證明了對(duì)于靜態(tài)目標(biāo),本文所提協(xié)同搜索策略與多級(jí)子圖巡邏策略整體表現(xiàn)相近,而對(duì)于具備躲避決策能力的動(dòng)態(tài)目標(biāo),本文所提協(xié)同搜索策略的搜索效率有較大提升。同時(shí)協(xié)同搜索策略解決了多級(jí)子圖巡邏策略中單體故障會(huì)導(dǎo)致其轄區(qū)成為盲區(qū)的問(wèn)題。后續(xù)將進(jìn)行算法移植,開(kāi)展實(shí)物驗(yàn)證實(shí)驗(yàn),并針對(duì)優(yōu)化目標(biāo)躲避模型或增加環(huán)境信息復(fù)雜度等方向開(kāi)展進(jìn)一步研究。■
猜你喜歡
中學(xué)生數(shù)理化(高中版.高考理化)(2020年2期)2020-04-21 05:32:50
小學(xué)生作文(低年級(jí)適用)(2019年9期)2019-10-08 08:37:10
文苑(2018年23期)2018-12-14 01:06:06
文苑(2018年19期)2018-11-09 01:30:14
文苑(2018年17期)2018-11-09 01:29:26
文苑(2018年21期)2018-11-09 01:22:32
小學(xué)生作文(低年級(jí)適用)(2018年3期)2018-04-17 00:58:35
數(shù)學(xué)大世界(2018年1期)2018-04-12 05:39:14
少年博覽·小學(xué)低年級(jí)(2017年4期)2017-06-09 16:22:28
作文評(píng)點(diǎn)報(bào)·低幼版(2017年7期)2017-03-11 20:49:41
