基于深度強化學習的四足機器人后空翻動作生成方法
2021-12-02 04:58:00李岸蕎王志成朱秋國
導航定位與授時 2021年6期
李岸蕎,王志成,古 勇,2,吳 俊,2,朱秋國,2
(1.浙江大學智能系統與控制研究所,杭州 310027; 2.浙江大學工業控制技術國家重點實驗室,杭州 310027)
0 引言
相比于輪式機器人,四足機器人在崎嶇地面和障礙物較多的環境中有著更好的移動性能。通過落腳點的自由選擇,可以讓它們在移動時克服與其腿長相當的障礙物。基于這種靈活性,它們可以在樓房和森林中進行搜救任務,在未知地形的隧道中進行勘探,甚至在外星球進行勘察工作。四足機器人的結構形態使得其具有完成人類和四足哺乳動物可以完成的動作的潛力[1],例如跳遠、跳高[2]以及后空翻等。
靈巧運動的實現離不開優秀的控制算法。傳統方法主要通過基于模型的控制方法實現這些運動。針對特定的目標運動,采用開環控制方法,通過預先設定各關節位置軌跡,對各關節進行位置控制,從而使機器人完成運動。這種方法可以呈現較好的效果,但是在機器人本體質量發生變化或與地面摩擦系數發生變化時,容易造成運動失效[3]。因此,這種方法在單一環境下表現較好,但當機器人和環境參數改變時,擴展性不強。
強化學習作為一種基于數據驅動的新型控制方法,在四足機器人的控制領域開始嶄露頭角。在強化學習的框架下,機器人與環境之間不斷進行交互,根據用戶制定的高層獎勵,學習使獎勵最大化的動作,省去了對底層控制器進行大量調參的繁重工作。這種方法訓練出的神經網絡控制器,在每個控制周期內對環境進行觀測,并根據觀測值決定運動軌跡,因此是一種閉環控制方法。而且,其訓練出的端到端控制器也使得機器人可以充分發揮自己的運動潛力,完成更加靈活的運動。2018年,來自Google的T.Haarnoja和J.Tan首次嘗試使用深度強化學習進行四足機器人的運動控制[4],成功地使用端到端的方法,在機器人Minitaur上實現了walk、trot 和gallop步態。同在2018年,加州大學伯克利分校的X.B.Peng等利用對專家經驗進行模仿的方法,在仿真中實現了對視頻中人類或動物靈巧運動的模擬[5]。通過構建和視頻中生物類似的結構,仿真中的智能體可以完成和視頻中幾乎一模一樣的動作。進一步地,X.B.Peng等利用領域自適應的方法,成功地將仿真中模仿狗運動的智能體遷移到了實物上[6],利用現實中的機器人完成了walk等步態。2019年,蘇黎世聯邦理工學院的M.Hutter團隊在機器人ANYmal上成功利用強化學習完成了多種步態[1]和崎嶇路面行走[7],并實現了機器人自動倒地爬起[8]。2020年,來自愛丁堡大學的李智彬團隊利用多網絡切換的方法,在絕影機器人上成功實現了機器人姿勢一摔倒后的恢復動作。通過檢測機器人摔倒后的姿態,利用不同的網絡恢復不同的摔倒姿勢[9]。同在2020年,浙江大學的朱秋國團隊利用帶有預訓練的強化學習方法在四足機器人絕影上實現了Bounding步態[10]。
盡管強化學習在四足機器人的目標動作訓練方面已經取得初步成效,但對于一些較為復雜的運動,由于其本身較難準確量化描述,直接設計符合目標的獎勵函數較為困難,甚至設計獎勵函數所花費的大量時間背離了深度強化學習方法節省人力的初衷。因此,在有目標運動的參考軌跡時,可以選擇采用模仿學習的思路,根據專家數據模仿專家的行為,從而極大減少設計獎勵函數和訓練模型的時間,提高訓練效率。
本文通過對位置控制下的絕影Lite機器人后空翻軌跡進行模仿,利用深度強化學習近端策略優化(Proximal Policy Optimization, PPO)方法,在仿真環境Raisim中訓練出可以使四足機器人進行后空翻的神經網絡控制器。通過設計實驗,改變機器人模型本身和環境參數,證明該神經網絡控制器相比于位置控制器在一些方面具有適應性更高的特點。
1 實驗平臺
1.1 絕影Lite機器人
絕影Lite是一款通用型智能四足機器人,共有12個關節自由度,每個關節由無刷電機驅動,如圖1所示。這款機器人仿生設計、身型小巧、動作靈敏、感知豐富,基于先進的控制算法,具有行走和跳躍等多種運動模態。
絕影Lite四肢強度大,關節扭矩大,質量較小,能完成后空翻等高難度運動,部分參數如表1所示。
1.2 機器人模型
絕影Lite機器人為全肘式(all-elbow)構型。簡化后的關節-連桿模型如圖2所示,所有關節坐標系均保持一致。腿部關節包括髖側擺關節(HipX)、髖俯仰關節(HipY)和膝關節(Knee)。四腿分別表示為FL(左前腿)、FR(右前腿)、HL(左后腿)和HR(右后腿)。機器人軀干質量5.64kg,大腿質量0.55kg,小腿質量0.08kg。左右髖間距11cm,前后髖間距25.6cm,大腿和小腿長度均為18cm。因深度強化學習中無需對機器人進行動力學建模,因此不再詳述該機器人的建模。

圖2 機器人模型Fig.2 Robot model
2 算法介紹
2.1 深度強化學習算法
本文將對機器人的控制過程視為馬爾可夫過程。在每一個時間步Δt中,機器人獲得觀測值ot∈O,執行動作at∈A,并獲得一個標量獎勵rt∈R。對于一段時間為Δh個步長的運動,用Ot=
(1)
其中,γ∈(0,1)為折扣系數;τ(π)表示機器人的運動軌跡,受機器人的策略π和環境的共同影響。在基于策略的強化學習算法中,策略π一般用神經網絡來實現。這種使用神經網絡作為策略的強化學習算法被稱為深度強化學習。
為了獲得目標策略,本實驗采用的深度強化學習算法為PPO算法以優化此策略。該算法為基于策略的深度強化學習算法,與Policy-Gradient算法相比,減少了優化步長的選擇對于優化過程的影響;相比于信任域策略優化(Trust Region Policy Optimization,TRPO)算法,增強了對整體策略空間的搜索能力。另外,該算法采用了 Actor-Critic框架,優化過程同時優化Actor和Critic這2個網絡,保證了對于狀態的價值估計和策略的優化同時進行[11-13]。
2.2 軌跡模仿框架
DeepMimic是一種基于模仿學習思想構造的深度強化學習框架[14],其使用的優化算法仍然是PPO算法。DeepMimic框架主要由PPO算法和精巧設計的獎勵函數構成。它的主要作用是通過設計獎勵函數來實現多關節智能體對已知動作的模仿。在DeepMimic框架中,根據設置的獎勵函數,神經網絡的目標是縮小智能體的當前運動軌跡和目標運動軌跡的差值。如圖3所示,在每一步動作之后,參考軌跡和當前狀態的差值被輸入到優化器中,優化器對控制器的優化目標為使智能體每一次完成動作后都與參考軌跡非常接近。
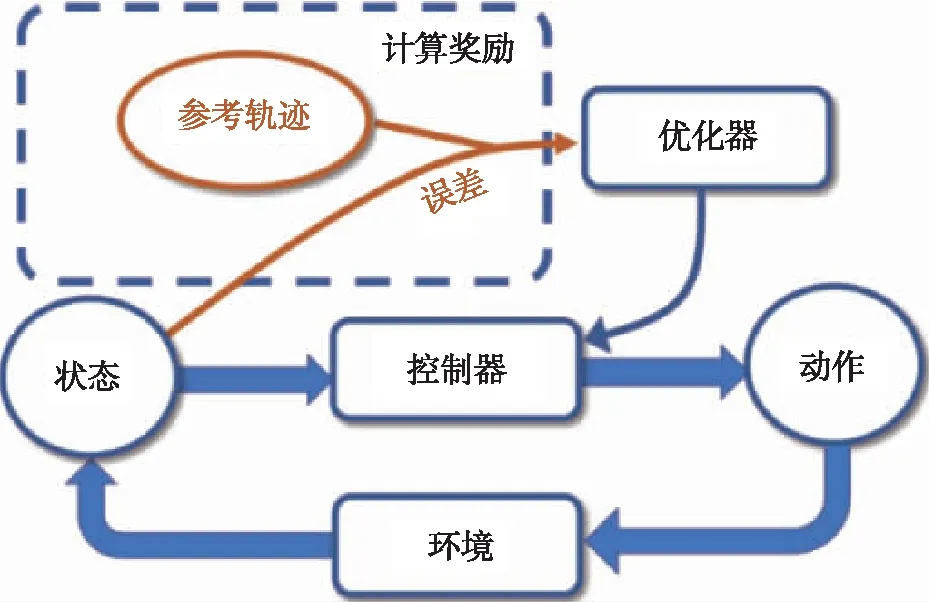
圖3 DeepMimic流程圖Fig.3 Workflow of DeepMimic
2.3 參考軌跡選擇
在DeepMimic算法中,若想讓神經網絡對目標動作有良好的模仿效果,選擇合適的參考軌跡至關重要。本文選擇的參考軌跡包括以下幾類(采樣參考軌跡的頻率與控制器的頻率保持一致,均為1ms):
1)機器人軀干質心在世界坐標系下的位置(3維);
2)機器人軀干在世界坐標系下的姿態(4維,采用四元數表示,因為身體在旋轉過程中由程序解算出的歐拉角可能會發生突變,導致智能體在學習過程中產生和參考軌跡相似的角度,但由于解算問題會出現2個數值差距巨大的歐拉角表示,因此采用四元數更加方便、快捷);
3)機器人各關節位置(12維);
4)機器人各關節速度(12維);
5)機器人各關節力矩(12維);
6)機器人足部距離身體質心的距離(4維,四足機器人的4條腿相當于連接在浮動基上的4個機械臂,末端位置相當于對機械臂末端位置的限制,在關于機械臂的強化學習中經常用到,在腿足系統中也被證明是有效的[9])。
2.4 獎勵函數選擇
參考DeepMimic算法中對于參考軌跡的模仿,本文使用如下4個獎勵函數進行模型的訓練。
(2)
(3)
(4)
(5)
采用指數函數的目的是使智能體動作和參考軌跡動作越接近時,該獎勵的增益越小,這樣可以防止機器人完全刻板地模仿參考軌跡,達到機器人在大體模仿參考軌跡的同時平衡各項獎勵收益的目的。上述獎勵函數中帶有^值均代表期望值。
2.5 神經網絡輸入輸出選擇
在基于神經網絡的深度強化學習下,選擇合適的輸入輸出對于模型表現效果至關重要。另外,深度強化學習選擇的觀測量要與選擇的獎勵函數具有一定的相關性,這樣對神經網絡優化更有利。神經網絡在優化時的指標是當前狀態的獎勵,如果獎勵和神經網絡的輸入(即觀測量)關系較小,實際上是增加了神經網絡尋找最優解的壓力。最終選擇的網絡輸入如下所示:
1)機器人軀干質心在世界坐標系下的高度(1維);
2)機器人軀干在世界坐標系下的姿態(4維,理由同選擇參考軌跡時的理由);
3)機器人各關節位置(12維);
4)機器人各關節速度(12維);
5)機器人一組起跳腿和一組非起跳腿的髖俯仰關節和膝關節的差值(8維,對于后空翻來講,即前2條腿的髖俯仰關節和膝關節的差值、后2條腿的髖俯仰關節和膝關節的差值,這種方法類似于在大數據處理中的特征工程,目標在于根據先驗知識預先提取出部分特征,達到減輕網絡擬合壓力的效果,加快訓練速度[19],另外為了使三種翻滾運動的輸入統一,選擇對每相臨的2條腿都做這一處理);
6)機器人大腿和足部距離身體質心的距離(24維,理由同選擇參考軌跡時的理由);
7)時間標簽(1維,在翻滾動作下,會出現一些與機器人狀態量類似的情況,例如初始狀態和最終結束狀態,這時神經網絡控制器需要一個時間標簽來判別這兩種不同的情況);
神經網絡的輸出選擇為12維目標位置和12維目標速度信息,底層關節PD控制器接收到指令之后輸出力矩信息。
綜上所述,神經網絡的輸入為65維,輸出為24維。另外,神經網絡的控制頻率設置為1ms,即該神經網絡預測的信息為1ms后關節應到達的位置和速度。
2.6 深度強化學習網絡結構
在Actor-Critic框架下,Actor和Critic各需要一個神經網絡來實現。本文實驗中的2個神經網絡控制器均由具有2個全連接隱藏層的神經網絡來實現,第一個隱藏層為1024個神經元,第二個隱藏層為512個神經元,對每一個神經元選擇的激活函數為LeakyRelu[15],該激活函數有效解決了常用的激活函數Relu中的神經元死亡問題。
在訓練過程中,本文神經網絡輸出的24維關節位置和關節速度實際上是24個高斯分布,即輸出為24個均值和24個方差,經過采樣后得到24個數值。在訓練結束后的測試模式下,控制器直接將24個均值作為目標量輸送到關節。以下為簡化表達,神經網絡的輸出均表示為一個24維的向量。
3 實驗結果
3.1 仿真環境
本實驗使用Raisim仿真軟件進行仿真。其對于接觸力的解算采用了鉸接體算法(Articulated Body Algorithm,ABA)[16],大大增加了對于鉸接系統的接觸力求解速度,相對于機器人關節數目的計算時間復雜度為O(n)。
3.2 模型訓練結果
深度強化學習訓練所用計算機中央處理器(Central Processing Unit, CPU)為Intel 9900K,圖形處理器(Graphics Processing Unit, GPU)為RTX2080Ti。當訓練次數為8100次左右時,四足機器人第一次可以完成較為完整的后空翻運動,如圖6所示。訓練過程中的獎勵變化曲線如圖4所示。

(a)關節位置模仿獎勵

(b)身體姿態模仿獎勵

(c)身體位置模仿獎勵
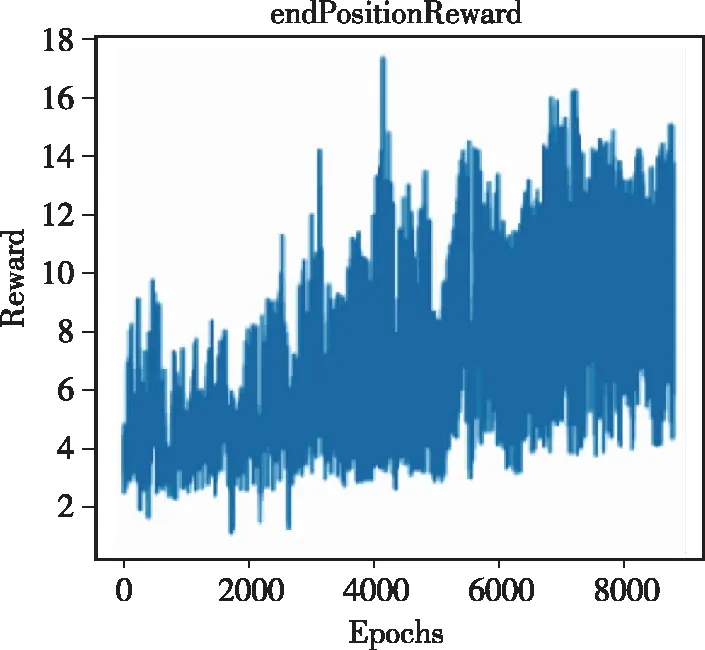
(d)末端位置模仿獎勵圖4 訓練過程中獎勵變化曲線Fig.4 Four kinds of reward verse time in training
每個訓練回合(epoch)設置為1.4s,在運動時間達到0.7s時,恢復機器人為初始狀態,即在一個訓練回合中,機器人可以獲得2次翻滾運動的模仿結果數據,目的為在保證每個訓練回合訓練時間不過長的同時增強神經網絡的收斂效果。
因為在后空翻中主要產生俯仰角(pitch)的變化,因此通過對比兩種控制器下后空翻的俯仰角軌跡,可以清晰地觀察到學習效果,如圖5所示。俯仰角的最大差值為0.58,平均差值為0.11,即神經網絡控制器在模仿位置控制器的后空翻時,平均誤差在6°左右。結合圖6可以看出,神經網絡控制器在模仿位置控制器的基礎上完成了后空翻運動。另外,由圖7可以看出,各關節輸出的關節力矩均未超出設定的物理限制。綜上所述,利用深度強化學習成功實現了使用神經網絡控制器對位置控制器下后空翻運動的模仿。
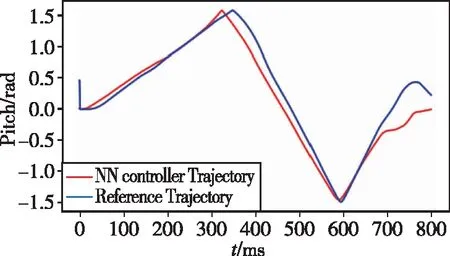
圖5 神經網絡控制器(紅)和位置控制器(藍)下 后空翻俯仰角軌跡對比Fig.5 Comparison of the pitch angles under the neural network controller (red) and the position controller (blue)
3.3 兩種控制器下適應性對比
為進一步證明帶有實時狀態反饋的神經網絡控制器具有比開環位置控制器適應性更高的特點,分別通過改變軀干質量和地面摩擦系數來觀察2個控制器的表現,這2個變化分別對應機器人本身的性質和外部環境性質。在該對比實驗中,選擇關節的底層控制器均為Raisim仿真環境中帶有前饋重力補償的PD控制器。
3.3.1 改變軀干質量
機器人原軀干質量為5.64kg,改變機器人質量為15.64kg后,原位置控制因無法支撐身體達到后空翻所要求的高度而無法完成整個動作,而神經網絡控制器仍可以完成運動,如圖9所示。

圖6 后空翻運動的訓練結果(右側機器人在位置控制下進行后空翻運動,左側機器人通過訓練模仿右側機器人在 神經網絡控制器下進行后空翻運動。圖片時間間隔為0.05s,總時長為后空翻0.7s加關節恢復初始位置0.1s)Fig.6 Result of backflip training

圖7 右前腿和右后腿各關節輸出力矩變化(由于腿的對稱性,只繪制了右側雙腿的關節力矩曲線)Fig.7 Output torque in each joint of the right front leg and right hind leg
改變軀干質量前后的俯仰角軌跡對比如圖8中同顏色虛線和實線所示,兩種控制器下的俯仰角軌跡對比為圖中紅線和藍線所示。
3.3.2 改變環境摩擦系數
仿真環境中機器人與環境的摩擦系數設置為0.7,在降低該摩擦系數為0.15后,位置控制器出現了明顯的打滑現象,從而無法完成完整的后空翻運動,但是訓練8000次后的部分神經網絡控制器仍然可以使機器人完成完整的后空翻運動,分別如圖10和圖11所示。

圖8 改變軀干質量前后的俯仰角軌跡對比和 兩種控制器下俯仰角軌跡對比Fig.8 The pitch angle trajectories under the two controllers before and after changing the torso mass
圖9 改變軀干質量的訓練結果(右側機器人在位置控制下進行后空翻運動,左側機器人通過訓練模仿右側機器人在 神經網絡控制器下進行后空翻運動。圖片時間間隔為0.05s,總時長為后空翻0.7s加關節恢復初始位置0.1s)Fig.9 Traing result after changing robot base mass

圖10 改變摩擦系數,位置控制器出現打滑現象 (圖片時間間隔0.02s)Fig.10 After changing the friction coefficient between the robot and ground, the robot controlled by position controller appears to skid

圖11 改變摩擦系數,神經網絡控制器下的后空翻 (圖片時間間隔0.1s)Fig.11 Backflip under neural network controller after changing friction coefficient
從實驗結果可以看出,神經網絡控制器在工程應用中的一個優點,即可以在訓練產生的上百個模型中挑選合適的模型。雖然部分模型對環境的適應能力較差,但由于學習過程具有一定的隨機性,仍可以找到部分符合條件的模型。
4 總結與展望
本文利用基于模仿專家經驗的深度強化學習方法實現了可以控制四足機器人進行后空翻運動的神經網絡控制器,并通過改變機器人的軀干質量和機器人與環境之間的摩擦系數,證明了訓練得到的神經網絡控制器相比于傳統位置控制器在環境適應性上有一定程度的提高。
神經網絡控制器不僅具有良好的環境適應性,也具有很強的泛化能力。在通過模仿學習獲得了能進行參考運動的神經網絡控制器后,可以將該控制器作為預訓練模型,根據需求加入新的獎勵函數,從而使機器人具備原控制器所不具備的能力。這種預訓練可以大大節省人力物力,值得進一步探索。
