基于Neo4j的草莓種植管理知識圖譜構建及驗證
2022-01-17 07:17:42郭文忠文朝武龍潔花
現代農業科技 2022年1期
關鍵詞:方法
張 宇 郭文忠 林 森* 文朝武 龍潔花
(1吉林農業大學信息技術學院,吉林長春 130118;2北京農業智能裝備技術研究中心,北京 100097)
隨著物聯網、大數據和人工智能等技術的快速發展,我國農業經歷了傳統農業、半自動化農業、機械化農業到現在的智慧農業階段。智慧農業的發展需要將互聯網、大數據、云計算和人工智能等現代技術與農業深度融合,從而實現現代信息感知、定量決策、精準灌溉的全新農業生產方式。中國作為農業大國,作物品種豐富。與其他作物相比,草莓適應性強、結果早、成熟早、投資少、見效快,是提高農民經濟收入的一種重要農作物[1-8]。2017年我國草莓種植面積達14.13萬 hm2,年產量375.30萬t[9],草莓產業從業人員達到350萬人。目前,國內外的草莓品種較多,關于草莓的信息數據量較大,大量的書籍、論文、報刊、網絡文獻等資料對草莓均有記載,但僅限于文字,查閱資料和文獻需要大量時間,所以將這些知識以簡單、高效的方式展示給草莓種植者具有重要意義。
知識圖譜(knowledge graph,KG)是以圖的形式表現客觀世界中的實體(概念、人、事物)及其之間關系的知識庫[10-14]。知識圖譜通常使用RDF模式來表達數據中的語義,受到了國內外學者的熱捧,并已經應用到智能問答、輔助決策和大數據分析等方面[15],是智慧農業發展必不可少的技術之一。
本文借助知識圖譜構建技術,采用自頂向下的方式構建草莓種植管理知識圖譜。通過圖結構方式將草莓種植管理知識高效、準確地提供給種植者,以節約大量查閱資料、閱讀書籍時間。
1 研究現狀
知識圖譜并非突然出現的新技術,而是很多技術在發展中相互影響和繼承的結果,在20世紀70年代,就有研究者提出了知識圖譜的早期理念Semantic Networks[16-17],后來又相繼提出本體(Ontology)、Web、The Semantic Web、Linked Data。直到 2012 年,谷歌公司正式推出了知識圖譜搜索引擎服務,大大提升了搜索的速度和質量。隨后知識圖譜在輔助智能問答、自然語言理解、大數據分析、智能決策、人工智能、電商領域、醫療領域以及金融領域等方面展現出了豐富的應用價值。
吳賽賽等[18]提出一種基于深度學習的作物病蟲害知識圖譜構建方法,將抽取的知識存儲到Neo4j圖數據庫中,能直觀反映知識圖譜內部結構,實現知識可視化和知識推理。該研究構建的結構化知識圖譜可以為作物病蟲害智能問答系統、推薦系統、智能搜索等下游應用提供高質量的知識庫基礎。袁培森等[19]針對水稻表型知識圖譜中的實體關系抽取問題提出了一種基于本體論對水稻基因、環境、表型等表型組學實體進行關系分類的方法。試驗結果表明,BERT模型的精確率達到了95.10%。劉寶珠等[10]針對RDF圖和屬性圖的不同數據管理、不統一的數據模式和查詢語言限制了知識圖譜的廣泛應用,提出了KGDB(knowledge graph database)是統一模型和語言的知識圖譜數據庫管理系統。試驗結果表明,KGDB平均比gStore和Neo4j節省了30%的存儲空間,同時提高了2個數量級的查詢速度。杜志強等[20]針對“數據—信息—知識”轉化能力的不足,提出了自頂向下和自底向上相結合的自然災害應急知識圖譜構建方法,最后以洪澇災害應急知識圖譜為例驗證。結果表明,該方法能夠形式化表達概念層關系及要素屬性、要素間語義的關系,實現了從多源數據到互聯知識的轉化。
Zeb等[21]針對KG嵌入模型無法捕獲節點附近存在的有用信息,提出了一種新的KG嵌入學習框架。該框架由雙加權圖卷積網絡的編碼器和新型全表達張量分解模型的解碼器組成,以準確建模三元組。試驗結果表明,該框架在最近的標準鏈路預測數據集上的性能明顯增強。Adibelli等[22]提出一種基于圖表的知識圖譜,將實現各種信息來源之間的迅速集成,主要通過從各種異構來源提取的信息邊緣連接它們,從而捕獲了各種不同實體之間的關系。Tiwari等[23]提出一種強化學習框架中的遠程意識獎勵,為不同的職位分配不同的獎勵。此方法集成了圖自關注(GSA)機制,從相鄰實體和關系中捕獲更全面的實體信息,結合GSA機制和GRU讓模型記住路徑。試驗結果表明,此模型可以顯著降低問題的復雜性,并且為每個關系挖掘更平衡的路徑。Kim等[24]提出了一種基于無監督學習的開放信息提取(OpenIE)系統,該系統不需要預先構建數據集,從大量的文本文檔中獲取知識,并添加到現有的知識圖譜中。試驗結果表明,Co-BERT模型的掩碼預測精度和顯式排序得分明顯優于原始BERT模型。
2 數據庫的選取
目前,尚無針對作物栽培管理的知識圖譜,本文從種植者角度出發,提出采用Neo4j構建草莓種植管理知識圖譜,旨在為種植者提供一種高效快速查詢草莓栽培管理知識的方式。Neo4j數據庫是一種以圖形式來存儲信息的非關系存儲數據庫。相比于傳統的關系型數據庫,Neo4j數據庫為節點、節點屬性、邊以及邊屬性等設計了一種特殊的存儲方案,可以有效解決農業特殊性、開放數據共享、農業數據繁雜和農業知識獲取等問題。相比傳統數據格式,Neo4j數據庫信息更加直觀,而且使用Cypher語言查詢時,不需要復雜的連接運算。Cypher的查詢效率不會隨著數據的增加而降低。因此,本文將構建一種基于Neo4j的草莓種植管理知識圖譜。
3 基于Neo4j的草莓種植管理知識圖譜構建
本文中知識圖譜的構建使用的是Mac 3.5.4版本的Neo4j,電腦為 MacBook Pro,處理器為2.6 GHz六核Intel Core i7,操作系統為macOS Big Sur,驗證語言為Cypher語言。
本文利用實體、關系抽取進行知識獲取,然后構建知識模式層次,最后依次將實體、屬性和關系導入Neo4j圖數據庫中。構建流程如圖1所示,包括知識獲取、構建圖譜、知識更新及圖譜應用等4個步驟。
3.1 知識獲取
關于草莓的知識信息數據來源廣泛,本文的草莓知識來源于文獻[25-27]、專家(北京市農林科學院研究員、中國農業科學院碩士)、網頁和書籍等,最終獲取了87個草莓品種、5種繁殖方式、6個生育時期以及22種常見病害等信息。第1步,對網頁數據進行手動篩選,以及文獻和專家所提供的信息進行半自動補充。但是,這些知識都以普通文本的方式表達,難以滿足知識圖譜構建的結構需求。第2步,基于遠程監督方法[28]對篩選和補充的知識進行半自動實體識別和關系抽取。其中,得到實體和關系包括品種、產地、生育期、繁殖方式、描述、特點、一級序果重或畝產量、葉片常見病、常見病造成原因等。第3步,用第2步中的實體與關系構建一個草莓知識結構表。
3.2 知識結構層次構建
構建知識圖譜首先需要確定其骨架,即知識圖譜的數據結構層次。常見的構建方法包括自頂向下和自底向上的構建方法:當涉及領域較為成熟、知識體系完備、涵蓋面廣時,采用自頂向下構建方法;自底向上是基于數據驅動的構建方法。知識圖譜很少與農業領域相結合,所以本文利用的是自頂向下和自底向上相結合的構建方法,如圖2所示。從獲取的草莓知識數據中抽取出實體、屬性及關系,構建模式層。當有草莓知識更新或者培育出新的草莓品種時,采用自底向上的方法更新知識圖譜。
構建模式層以草莓為一級實體,以品種、常見病害、生育期、繁殖方式等二級實體作為草莓的屬性值,再以豐香、紅顏等三級實體作為品種的屬性值,以概述、特點等四級實體作為豐香的屬性值。實體與屬性值之間以“屬性是”的關系相連(圖3)。
3.3 知識圖譜構建
目前,常見的知識存儲方式包括基于關系數據庫的存儲方案[29]、面向RDF的三元組數據庫[30]和圖數據庫等。因為關系數據庫是利用知識之間的關系進行存儲,所以基于關系數據庫的存儲方式也是目前主要的一種知識存儲方法,包含三元組表[31]、水平表和屬性表。RDF被認定為是語義數據關聯的標準格式,也是Web上知識圖譜的主要數據格式之一。
本文將草莓生產管理知識以RDF三元組的形式呈現給用戶,使用戶清晰了解每個實體之間的相互關系。
3.3.1 知識的導入方法。目前,Neo4j數據庫知識導入方法有3種。第1種是Cypher語言中的CREATE語句。可以隨時插入數據更新知識,但當遇到大規模數據時,會偶爾出現數據重復、缺漏、錯誤等問題。第2種是Cypher語言的Load.csv文件的導入,需要將csv文件放入Neo4j的安裝目錄import下,可選擇本地或者遠程導入,而且不支持即時更新。第3種是官方提供的Neo4j-admin import工具,這種方法占用資源少,但是需要脫機導入,且只適用于初始化導入。
本節基于2.1節知識獲取方法得到的數據規模及知識的更新狀況,選用Cypher語言中的CREATE語句以模塊化的構建方式構建草莓種植管理知識圖譜,因為模塊化Cypher語言中的CREATE語句有很強的靈活性。最后可以通過知識問答查詢方式為種植管理者提供有效知識。
3.3.2 模塊導入。第1步,構建一級節點草莓;第2步,依據得到的知識數據分別構建二級節點模塊,包括品種節點模塊、生育期節點模塊、繁殖方式節點模塊、常見病害節點模塊、灌溉節點模塊、施肥節點模塊、環境控制模塊以及常見病害的造成原因和防治方法模塊。Neo4j圖數據庫會為導入的每個節點自動分配一個整數ID,而且ID是隨著節點的導入順序自動遞增且唯一。現分別對每個模塊的構建進行詳細介紹。
(1)品種節點模塊。品種節點模塊包含若干個三級節點,即不同品種草莓的名字,如豐香、章姬以及紅顏等。每個三級節點都包含節點的名字、產地、介紹以及特點等屬性。以豐香和紅顏節點導入為例,具體的CREATE語句如下:
CREATE(豐香:草莓{name:‘豐香’,nationality:‘日本’,introduce:‘休眠很淺,果實圓錐形,果肉淺紅色,硬度中等,鮮紅色、果面平整、有光澤,外觀艷麗,植株開花早,屬早熟品種。果實風味優,香甜適口,糖度高而穩定,可溶性固形物含量11.25%,一級序果平均單果重達 25 g’,feature:‘抗旱、抗寒,果大,適應性強,花期較能抵抗晚霜危害,抗病性極強,不耐長途運輸、不抗白粉病、授粉能力差、畸形果多、著色不良、長勢弱、繁殖系數低’})
CREATE(紅顏:草莓{name:‘章姬’,nationality:‘日本’,introduce:‘紅顏又稱紅頰,是日本靜岡縣用幸香與章姬雜交育成的早熟栽培品種良種,株態直立,葉片大,新莖分枝多,圓錐形,果面紅色、有光澤。果形、果色明顯優于豐香,可溶性固形物含量11.8%,一級序果平均單果重26 g,最大單果重50 g以上’,feature:‘植株長勢強,易于栽培管理,連續結果能力強,葉綠、花白、果紅、味佳,豐產、品質好、果個大,色紅、味甜、味濃。硬度大于所有日本品種,根系生長能力和吸收能力強,休眠淺,可抽發4次花序,各花序可連續開花結果,中間無斷檔,對炭疽病、灰霉病較敏感’})
構建好模塊內的節點后,需要建立節點之間的關系。本模塊中包括二級節點品種和豐香、章姬等三級節點,所以建立的是上下位關系。同樣以豐香和紅顏節點為例,具體的構建語句為:
CREATE
(草莓)-[:Include]->(豐香),
(草莓)-[:Include]->(紅顏)
構建好品種節點模塊后,輸入“MATCH n:草莓RETURN n”來查詢導入的品種數目是否與知識結構表中的品種數目相同,是否與之匹配。
(2)生育期節點模塊。生育期節點模塊包含二級節點生育期和萌芽期、營養生長期、現蕾期、旺盛生長期、花芽分化期、休眠期等三級節點。每個三級節點中都有節點的名字和特點2個屬性。以旺盛生長期為例,具體的CREATE語句如下:
CREATE(生長旺盛期:生育期{name:‘生長旺盛期’,feature:‘植株開始旺盛營養生長時,腋芽萌發產生大量的匍匐莖,并按一定順序向上長葉、向下扎根,形成新的幼苗,少數腋芽形成新莖分枝,新莖基部相繼發根成苗’})
在導入節點后,下一步與(1)相同,建立節點之間的關系。同樣以生長旺盛期為例,具體語句為:
CREATE
(草莓)-[:Include]->(生育期),
(生育期)-[:Include]->(生長旺盛期)
(3)繁殖方式節點模塊。繁殖方式節點模塊包含二級節點繁殖方式和匍匐莖繁殖、母株分株繁殖、微繁殖、種子繁殖、脫毒組培苗繁殖等三級節點。每個三級節點中都有名字和介紹2個屬性。以匍匐莖繁殖為例,具體的CREATE語句如下:
CREATE(匍匐莖繁殖:繁殖方式{name:‘匍匐莖繁殖’,introduce:‘草莓在生長旺盛時期會抽生大量的匍匐莖,在匍匐莖上產生幼苗。利用這些匍匐莖幼苗進行繁殖,稱為匍匐莖繁殖。匍匐莖繁殖是在專用苗圃中進行的’,feature:‘繁殖系數高;秧苗質量高;有利于輪作,克服重茬;有利于減少病蟲害’})
導入此模塊所有三級節點后,下一步也需要構建節點之間的關系。同樣以匍匐莖繁殖為例,具體語句為:
CREATE
(草莓)-[:Include]->(繁殖方式),
(繁殖方式)-[:Include]->(匍匐莖繁殖)
(4)常見病害節點模塊。常見病害節點模塊包含二級節點常見病害和紅蜘蛛、白粉病等三級節點。每個三級節點都有名字和發病特點2個屬性。以白粉病為例,具體的CREATE語句為:
CREATE(白粉病:常見病害{name:‘白粉病’,發病特點:‘葉背面出現白色菌絲體;葉片向上卷曲呈湯匙狀;葉背面出現白色粉狀物;暗色污斑;多個病斑連接成片;病斑布滿葉片,葉緣萎縮,焦枯;花蕾不能開放;花瓣呈粉紅色;幼果不能正常膨大,干枯;果實有大量白粉,失去商品價值’})
導入此模塊所有三級節點后,下一步也需構建節點之間的關系。同樣以白粉病為例,具體語句為:
CREATE
(草莓)-[:Include]->(常見病害),
(常見病害)-[:Include]->(白粉病)
(5)常見病害的造成原因節點模塊。常見病害的造成原因節點模塊包含二級節點造成因素和因素1、2等三級節點。以因素1為例,具體的CREATE語句為:
CREATE(因素 1:造成因素{name:‘因素 1’,概述:‘土壤水分含量過低;土壤次生鹽漬化導致生理性缺水;根系發育不良’})
導入此模塊所有三級節點后,下一步也需構建節點之間的關系。同樣以因素1為例,具體語句為:
CREATE
(造成因素)-[:Cause]->(常見病害),
(造成因素)-[:Include]->(因素 1)
(6)常見病害的防治方法節點模塊。此模塊包含二級節點解決辦法和方法1、2等三級節點。以方法1和方法2為例,具體的CREATE語句為:
CREATE(方法 1:解決方法 {name:‘方法 1’,概述:‘合理水分管理;增施有機肥,改良土壤結構;農用灌水,淋洗土壤;合理輪作,生物除鹽;正確使用遮陽網;化學藥劑防治’})
CREATE(方法 2:解決方法{name:‘方法 2’,概述:‘農業防治:選擇抗病品種;合理肥水管理;合理密植;加強日常管理。物理防治:調節棚室內溫、濕度;增加透光性。化學防治:藥劑熏蒸;合理噴施化學殺菌劑’})
其中,為了方便構建節點之間的關系,將解決方法與常見病害按列表一一對應。同樣以方法1和方法2為例,具體語句為:
CREATE
(解決方法)-[:Way]->(常見病害),
(解決方法)-[:Include]->(方法 1),
(解決方法)-[:Include]->(方法 2)
(7)灌溉節點模塊。此節點包括二級節點灌溉和萌芽期灌溉、營養生長期灌溉等三級節點。以營養生長期灌溉為例,具體的CREATE語句為:
CREATE(營養生長期灌溉:灌溉{name:‘營養生長期灌溉’,概述:‘營養生長及后面時間宜每天早上在日出時灌溉1次,之后輻射量每積累600 J/cm2,補充灌溉基準灌溉量的20%。根據天氣狀況和植株吐水狀況進行調整。進行植株管理后的第2天,營養生長期以葉片是否吐水作為調整灌溉的依據,果期可以適當控水,不能完全以吐水為指標,基質排液不要超過最大溢流量’})
導入此模塊的節點之后,下一步也需要構建節點之間的關系,而此模塊的三級節點與生育期模塊的三級節點一一對應。同樣以營養生長期灌溉為例,具體的語句為:
CREATE
(草莓)-[:Include]->(灌溉),
(灌溉)-[:Include]->(營養生長期灌溉),
(營養生長期)-[:灌溉]->(營養生長期灌溉)
(8)施肥節點模塊。此節點包括二級節點施肥和萌芽期施肥、營養生長期施肥等三級節點。以營養生長期施肥為例,具體的CREATE語句為:
CREATE(營養生長期施肥:施肥{name:‘營養生長期施肥’,概述:‘草莓營養生長時期,需要補充三大營養元素(氮、磷、鉀)、中微量元素和生根、養根、護根類產品,促進花芽分化。開花前10 d沖施植倍健高磷型水溶肥,以達到促進花芽分化的目的。此階段要補充硼、鈣等中微量元素防止缺素癥的發生,配合施用氨基酸葉面肥以補充葉面營養’})
導入此模塊的節點之后,下一步也需要構建節點之間的關系,而此模塊的三級節點與生育期模塊的三級節點一一對應。同樣以營養生長期施肥為例,具體的語句為:
CREATE
(草莓)-[:Include]->(施肥),
(施肥)-[:Include]->(營養生長期施肥),
(營養生長期)-[:施肥]->(營養生長期施肥)
(9)環境控制模塊。此節點包括二級節點環境控制和溫度環境控制、光照環境控制等三級節點。以溫度環境控制為例,具體的CREATE語句為:
CREATE(溫度環境控制:環境控制{name:‘溫度環境控制’,概述:‘草莓根系生長溫度5~30℃,適溫15~22℃,莖葉生長適溫為20~30℃,芽在-15~10℃發生凍害,花芽分化期溫度須保持5~15℃,開花結果期4~40℃。草莓越夏時,氣溫高于30℃并且日照強時,需采取遮陰措施’})
導入此模塊的節點之后,下一步也需要構建節點之間的關系。同樣以溫度環境控制為例,具體的語句為:
CREATE
(草莓)-[:Include]->(環境控制),
(環境控制)-[:Tempreture]->(溫度環境控制)
由以上模塊構建后相結合組成初步構建好的草莓種植管理知識圖譜,如圖4所示。
3.4 知識圖譜更新
構建草莓種植管理知識圖譜的目的是讓更多學者方便、快速了解草莓知識,但是本知識圖譜的內容可能無法包含所有的草莓品種以及與草莓相關的知識,而且隨著科技發展,會出現越來越多的草莓品種。本文所選用的知識導入方法的最大好處就是可以隨時更新知識,可以實現更新的知識第一時間出現在知識圖譜中。
本文構建的知識圖譜中刪減、更新內容是利用從底到端的方式進行的,一步一步逐層進行,防止刪除正確的知識或者導入更新知識導致關系構建錯誤。
3.5 知識圖譜的試驗驗證
3.5.1 Cypher語言查詢驗證。完成草莓知識圖譜構建后,利用Cypher語言對知識圖譜進行驗證。因為本文是關于草莓的知識圖譜,所以主要是草莓知識的查詢應用,下面舉例介紹。
查詢草莓品種的名字以及哪些品種產地為中國:
MATCH(n:草莓)
RETURN n.name
CASE n.nationality
WHEN′中國′
THEN 1
ELSE 2 END AS result
上述語句為查詢圖譜中所有草莓的品種名字,并且標記出產地為中國的草莓,標記為1,其他產地的標記為2。查詢結果如圖5所示。查詢時間僅需32 ms,即可得到準確的草莓產地信息。其中,圖中若result=1,說明第一行草莓的產地是中國;如果result=2,說明第一行草莓的產地為其他國家。
查詢草莓白粉病以及白粉病的防治方法:
match(p:常見病害{name:"白粉病"})return p 或者 match(p:常見病害)where p1.name="白粉病" return p1;
match(p1)-[:WAY]->(缺鋅癥:常見病害{name:‘缺鋅癥’})return p1.概述
查詢結果如圖6所示,查詢時間僅需22 ms,要比其他查詢方法節省很多時間。
查詢營養生長期的特點:
match(p:生育期{name:"營養生長期"})return p.feature 或者 match(p:生育期)where p1.name="營養生長期" return p1.feature
查詢結果如圖7所示,查詢時間僅需21 ms。
通過上述的一些舉例,本文構建的知識圖譜可以利用Cypher語言查詢到使用者需要的草莓知識,查詢效率高于網絡查詢和書籍查閱,而且想要查詢的內容消息都是最新更新的,準確率也較高。
3.5.2 對比驗證。本節針對不同使用人群通過使用不同查詢途徑做了試驗對比。具體使用人群為種植農戶、農學學者以及普通用戶,本文從中各選擇了2位;傳統查詢途徑包括文獻、書籍以及網絡;測評標準包括時間、準確率以及全面性。其中,時間定義為用戶使用不同方法查詢到結果的使用時間;準確度定義為由草莓種植專家對每個用戶查詢得到的知識進行的準確性評價;全面性定義為某個查詢方法的知識庫的內容是否全面,知識是否能滿足使用人群的需要。現以草莓常見病害的查詢為例,將傳統查詢方法與基于Neo4j知識圖譜查詢方法對比,結果見表1。
在調查過程中發現,不同使用人群的查詢習慣不同。比如,種植用戶通過網絡去查詢或詢問有經驗的種植者;而農學學者通過知識圖譜查詢方式進行文獻和書籍查詢;普通用戶使用網絡和文獻相結合的方法查詢。
從表1可以看出,在查詢時間上,基于Neo4j知識圖譜查詢方式占據了絕對的優勢;在準確率上,種植農戶和農學學者傳統查詢方式準確率要高于知識圖譜查詢方式,但是知識圖譜查詢方式的平均準確率要高于傳統查詢方式;從全面性來看,知識圖譜查詢方式處于劣勢,因為Neo4j知識庫初步構建,需要經過不斷完善。從總體考慮,Neo4j可以作為一個新型的知識庫逐漸代替傳統的知識庫。
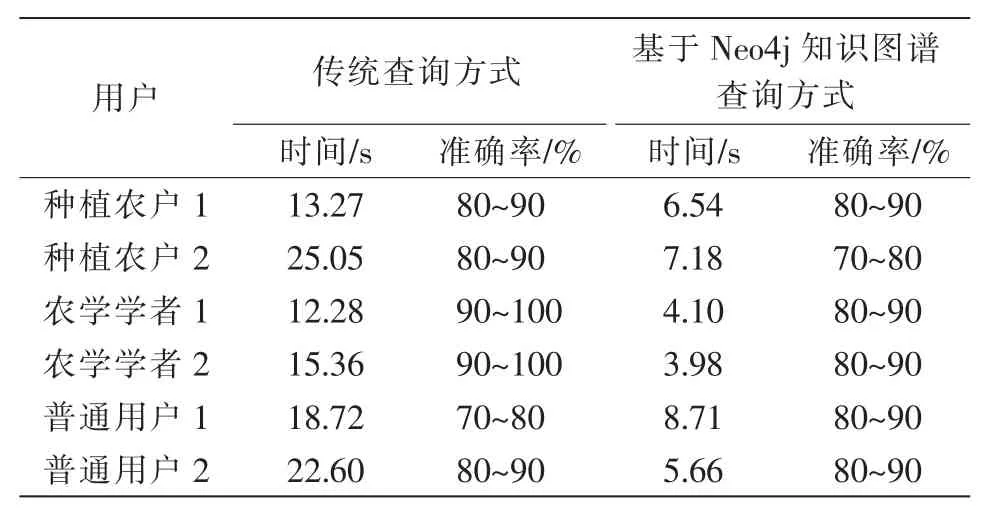
表1 草莓常見病害不同查詢方式對比
4 存在的問題
本文在構建知識圖譜過程中,遇到了一些不可避免的問題。一是在構建知識圖譜時,利用csv文件將草莓知識進行分類,用loadcsv方式將csv文件導入Neo4j中,但發現如何對知識結構進行整理是一大難題,因為一級、二級、三級節點以及它們的屬性各自交叉,因而對草莓知識的整理不是那么理想。二是采用CREATE語句構建時,發現語句頗為繁瑣,而且當導入大量語句時,會出現導入速度緩慢問題。
5 結語
本研究提出了一種基于Neo4j的草莓知識圖譜,該方法根據草莓知識的特征,在實體的基礎上對半結構化和非結構化知識進行半自動抽取,并利用CREATE語句將知識圖譜存儲于Neo4j圖數據庫中,實現實體交互關系的可視化展示和研究應用。該知識圖譜在農業智能問答、草莓栽培決策和草莓栽培數據分析等方面得到應用。
本文采用的是自頂而下與由下而上相結合的模塊化構建方式,完成了知識的導入和關系的構建,確定了清晰的邏輯層次,彌補了CREATE語句導入大數據速度慢的缺點,精準度較高。模塊化不僅提高了導入效率,還解決了速度緩慢的問題。
本文初步構建了草莓種植管理知識圖譜,但仍然有著很大的改進空間,未來可以在導入方式、知識抽取、自動更新甚至自動推理新品種等方面進行研究。隨著網絡數據不斷更新,需要對知識圖譜知識進行及時更新和補充,通過知識融合、知識推理等技術,實現知識圖譜的自動更新。
猜你喜歡
中老年保健(2021年9期)2021-08-24 03:52:04
河北畫報(2021年2期)2021-05-25 02:07:46
中學生數理化(高中版.高考理化)(2020年2期)2020-04-21 05:33:04
兒童繪本(2020年5期)2020-04-07 17:46:30
兒童故事畫報(2019年5期)2019-05-26 14:26:14
Coco薇(2016年2期)2016-03-22 02:42:52
山東青年(2016年1期)2016-02-28 14:25:23
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年7期)2015-08-11 15:03:12
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
