基于LSTM分類器的航空發動機預測性維護模型
2022-03-11 02:33:24藺瑞管王華偉車暢暢倪曉梅熊明蘭
系統工程與電子技術 2022年3期
藺瑞管, 王華偉, 車暢暢, 倪曉梅, 熊明蘭
(南京航空航天大學民航學院, 江蘇 南京 210016)
0 引 言
作為飛機的關鍵部件之一,航空發動機的工作條件通常非常復雜,任何意外故障都可能導致災難性后果。隨著傳感器技術的最新發展,以及通信系統和機器學習技術的顯著進步,預測性維護(predictive maintenance,PdM)已經成為航空發動機故障預測與健康管理(prognostic and health management,PHM)領域的研究熱點。通過建立航空發動機的PdM模型,管理者可以更有效地計劃維護活動,以減少發動機停車時間并降低平均維護成本,保證發動機運行的可靠性和安全性。
隨著工業中實際需求的日益增長,PdM在近十年中受到了學者的極大關注。通常,航空發動機預測維護框架包括兩個相互聯系的關鍵部分:系統剩余使用壽命(remaining useful life, RUL)的預測和維修決策。在航空發動機的性能退化過程中,傳感器數據之間存在緊密的時間相關性。RUL預測就是根據該航空發動機的歷史傳感器時間序列數據,辨識隱含其中的運行規律,進而應用該規律對航空發動機剩余使用壽命進行預測。
提高RUL預測的準確性不僅可以提高安全性和可靠性,降低平均維護成本,并為航空發動機維修決策提供參考。基于預測方法的研究主要分為兩大類:基于物理模型的PdM 框架和基于數據驅動的PdM 框架。但是由于設備結構日益復雜,再加上各種環境的影響,很難用物理模型去準確地預測RUL。隨著大數據時代的到來,以及計算機技術的不斷發展,基于人工智能的數據驅動方法已經成為發動機RUL預測領域的研究熱點。
在最近的研究中,已經開發了許多機器學習技術(尤其是深度學習),并成功應用于預測各種復雜系統的RUL。深度學習算法可通過對歷史性能退化狀態序列的學習,逼近傳感器數據的時間相關性規律,從而預測RUL。在深度學習中,循環神經網絡(recurrent neural network, RNN)包含遞歸隱藏層,非常適用于利用時間序列信息預測RUL。但是,在RNN處理長時間序列數據時,會出現梯度消失現象,導致其在實際應用中性能受限。為了解決RNN的這一問題,文獻[14]提出了長短期記憶(long short-term memory network, LSTM)網絡,其作為一種RNN的變體,將長期內存保存在單元狀態,可有效處理發動機性能退化數據的長期依賴關系,適用于解決RUL預測問題,因此備受關注。
Che等提出了一種結合多種深度學習算法的PHM模型,通過深度置信網絡(deep belief network,DBN)和LSTM的集成來估計RUL。主要思想是使用構造的健康因子(health indicator, HI)和目標標記來訓練神經網絡模型,根據預測的HI,通過設置閾值以獲得發動機RUL的估計值。Tamilselvan等提出了一種使用DBN分類器的新型多傳感器健康診斷方法。Guo等提出了一種基于遞歸神經網絡的健康指標,利用單調性和相關度量從原始特征集中選擇最敏感的特征,用于進行RUL預測。Hinchi等提一種基于卷積和長短期記憶的深度RUL估計框架。首先,使用卷積層直接提取傳感器數據的局部特征,然后利用LSTM層獲得退化過程并估計RUL。Aldulaimi等提出了一種用于RUL估計的混合深度神經網絡模型,該方法使用LSTM路徑提取時間特征,而同時使用卷積神經網絡(con-volutional neural networks, CNN)提取空間特征,對復雜系統具有較好的預后效果。Yuan等利用LSTM在復雜操作,混合故障和強噪聲情況下預測發動機的RUL。張妍等提出由多層感知器(multi-layer perceptron,MLP)和進化算法組成的框架,并利用跨步時間窗口和分段線性模型來估計機械組件的RUL。針對航空發動機性能退化和多狀態參數時間序列預測的問題, 車暢暢等構建了基于多尺度排列熵算法和LSTM的RUL預測模型。針對RUL 預測精度低的問題。張永峰等提出基于一維CNN和雙向長短期記憶(bi-directional long-short term memory,BD-LSTM)的集成神經網絡模型,并于其他深度學習模型進行了比較。
在以上RUL預測的研究中,一般可以概括為以下3個步驟:①提取原始數據特征;②建立設備HI曲線;③預測設備RUL。該方法的關鍵是對原有HI曲線進行向后的多步預測,即當 HI 值超過預先設定的閾值時視為失效,從而可計算得到RUL。提出的模型性能嚴格取決于故障閾值定義,這在實踐中并不簡單,不僅需要大量專家經驗參與,而且模型預測的魯棒性和準確性也會受到閾值取值的影響。此外,這些研究為預測RUL值的回歸問題,其準確性嚴格取決于預測范圍(從當前時間到實際系統故障時間的時間段)。因此,若使用預測準確性較低的RUL值可能會導致錯誤的決策。
針對以上問題,本文提出一種新的航空發動機預測性維護模型。采用滑動時間窗口方法標記訓練樣本,充分表征了多元傳感器數據的退化信息。運用LSTM分類器強大的特征提取能力處理時間序列數據,估計系統將來在特定時間窗口內發生故障的概率。與以往研究相比,所提出的預后方法不需要設定故障閾值,而是將預測RUL轉化為二分類問題,即預測設備在特定時間窗口內是否會失效,有效提高了維修決策的準確性。通過分析窗口大小對模型性能的影響,得到最優性能的模型參數。由于這些時間窗口是根據運營計劃者的要求定義的,因此所提出的方法對進一步的維修決策具有重要的研究意義。
1 模型算法描述
1.1 LSTM分類器
LSTM 是在RNN基礎上的改進,通過多個序列的組合和前后連接,RNN能夠根據當前信息和歷史信息來進行預測。然而,隨著神經網絡的復雜度逐漸提高,RNN往往出現信息過載和局部過優化的問題。作為RNN的變體,LSTM 能夠利用門控制單元使網絡的信息提取更有選擇性,從而有效地提高信息的利用率和時間序列預測的準確率。LSTM通過引入長時記憶單元、輸入門、遺忘門、輸出門、短時記憶單元等概念,讓整個網絡模型的運行時間更短、誤差更小。
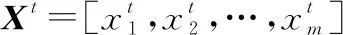
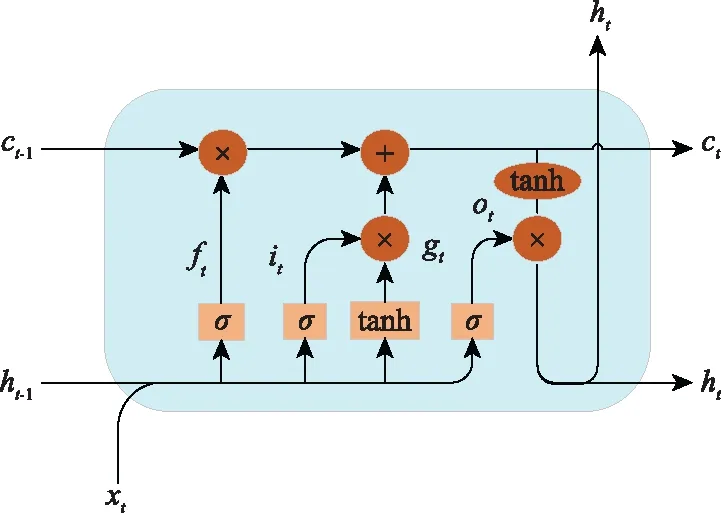
圖1 LSTM單元結構Fig.1 LSTM unit structure
首先,遺忘門控制LSTM層哪些長期記憶可以被遺忘:
=(-1++)
(1)
接下來,輸入門計算可以從輸入中獲取的信息,并了解其中哪些部分應該存儲到單元狀態中:
=tanh(-1++)
(2)
=(-1++)
(3)
然后,更新單元狀態中的長期記憶:
=-1?+?
(4)
最后,使用輸出門根據輸入,單元狀態和先前的隱藏狀態更新當前隱藏層的狀態:
=(-1++)
(5)
=?tanh()
(6)
在以上公式中,,,,是當前隱藏層和先前隱藏層之間的隱藏層權重值,而,,,是當前輸入層和當前隱藏層之間的權重值;,,,是偏差向量;?是逐元素乘法運算符;是Sigmoid函數;tanh是激活函數。
1.2 基于LSTM分類器的預測性維護框架
在生產實踐中,通常需要長期提供預測信息,以制定不同的維護計劃。此外,由于技術和后勤方面的限制,無法在任何時間和任何地方執行航空發動機的維護操作。因此,運營計劃者需要先了解設備在確定時間段內的故障概率,進而根據這些預測信息做出相應的預測性維修決策。
為了解決這一問題,本節提出一個基于LSTM分類器的預測性維護模型,該模型包含從數據預處理、模型的訓練和測試到提供確定時間窗口內故障概率的整個過程,如圖2所示。
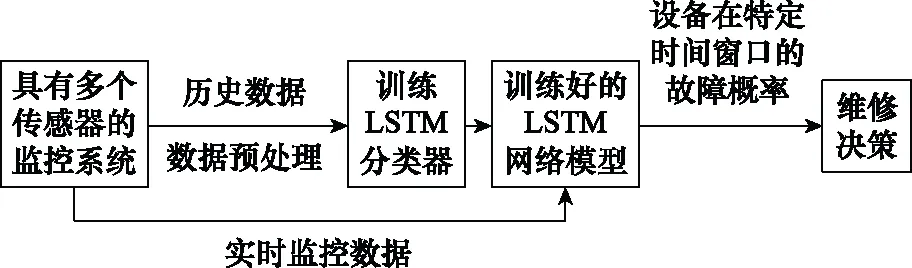
圖2 基于LSTM分類器的預測性維護流程Fig.2 Predictive maintenance process based on LSTM classifier
首先,針對航空發動機全壽命周期的預測性維護過程,利用具有多個傳感器的監控器系統,采集各項發動機運行性能參數,建立數據集。其次,將預處理后的數據集分成訓練集和測試集。將訓練集和測試集輸入到LSTM分類器中,進行模型訓練,通過調整時間窗口得到最優性能的LSTM模型。最后,預測設備在特定時間窗口的故障概率,以指導發動機維修決策。
2 實驗數據處理與模型構建
2.1 數據集描述
本文使用美國國家航空航天局的 C-MAPSS渦扇發動機退化數據集進行模型仿真。C-MAPSS數據集包括4個子集:FD001,FD002,FD003和FD004。其具有不同數量的運行條件和故障模式,每個子數據集進一步分為訓練集和測試集。表1列出了C-MAPSS數據集的構成部分。第1行和第2行分別代表每個引擎的發動機單元編號和退化周期,第3行描述了發動機的運行設置,而最后的21列由來自21個傳感器的多元時間數據組成。在以后的實驗中,將考慮用FD001數據集對所提出模型進行驗證和評估。在該數據集中,包括100個從運行到失效的時間序列,其中包含20 631個不同時間的測試數據,所有序列中測試數據的最大數量和最小數量分別為303和31。

表1 C-MAPSS數據集的構成
2.2 數據預處理
在訓練LSTM網絡之前,有必要對來自多個傳感器源的異構數據進行預處理。
(1) 數據歸一化
輸入數據是從多個傳感器源獲得的,這些傳感器源的范圍不同。為了使用這些異構數據來訓練LSTM分類器,有必要對它們進行歸一化。本文采用Min-Max方法對訓練集與測試集數據進行歸一化,這種歸一化將確保所有功能在所有工作條件下的平等貢獻[26];歸一化的數據將在[0,1]之間。
(2) 時間窗處理
為了對模型進行訓練和測試,需要對訓練集和測試集的數據進行標記。本文采用滑動時間窗口來定義數據標簽。對于幾個連續時間序列的數據,采用滑動時間窗以獲得特征向量,可以獲取更多有用的時間信息,這些信息可能會大大改善RUL分類性能。具體而言,就是利用先前的時間步長預測下一個時間步長,窗口沿時間方向滑動一個時間單位,便構造出單個訓練樣本,最后一個時間節點對應的RUL作為該訓練樣本的標簽。
所提出的方法根據時間窗口來定義數據標簽,在該時間窗口中,運營計劃者需要故障預測信息來安排維護和生產活動。例如,運營計劃者需要系統在規定時間窗中發生故障的概率,則將數據標記為兩個類別。第一類記為Deg0,表示設備RUL大于的情況,即RUL>。第二類為Deg1,表征其中設備RUL小于,即RUL≤。如果RUL屬于給定的類別,則其對應元素將設置為1,而輸出數組的其余元素設置為0。
2.3 網絡模型參數設置
本文提出的深層LSTM分類模型由Python 3.7.6 keras/tensorflow深度學習庫構建,處理器為Intel(R) Core(TM) i7-9700 CPU @ 3.00 GHz 3.00 GHz,內存為8 GB,操作系統為Windows 10。圖3顯示了深度LSTM中3種類型的層:輸入層,隱藏層和輸出層。
圖3 提出的深層 LSTM分類模型Fig.3 The proposed deep LSTM classification model
輸入層是將數據帶入LSTM的網絡層。輸入數據為三維格式,即[樣本,時間步長,特征數量]。這里的時間步長是指每個特征的信息能夠傳遞給下一個特征的長度。為了對全部設備的RUL預測值進行二進制分類,時間步長需要滿足測試集中記錄數據的最小長度。由于數據集FD001中記錄的最小長度為31,則本文設定的時間步長為30。
隱藏層介于輸入層和輸出層之間,是模型訓練和測試的核心部分。在構建的隱藏層中,先后設置了100個和50個單元的層。另外,在每個LSTM層之后應用Dropout,以減少神經網絡訓練數據的過擬合,從而提高網絡的特征提取能力。
輸出層是包含一個前饋神經網絡的全連接層。該層用作網絡和輸出之間的原型。其允許將隱藏層輸出處的三維張量轉換為分類器輸出處的一維數組。在本文中,將分類器輸出定義為兩個元素的向量,這些特征描述了觀察結果屬于兩類的概率:Deg0(RUL>),Deg1(RUL≤)。然后,在輸出層中有兩個單元,并使用“ Sigmoid” 激活函數。輸出層提供了兩個類別(Deg0和Deg1)上的概率分布。
為了訓練LSTM分類器,將目標函數的損失(loss)定義為“binary_crossentropy”,該函數專門用于解決兩類別分類問題。接下來,本文采用Adam優化算法,其是隨機梯度下降算法的擴展式,具有計算效率高、內存需求小以及對大數據適用性高等優點,被廣泛用于深度學習模型。為了評估模型的性能,將度量功能定義為“ binary_accuracy”。類似于目標函數,其為所有分類問題提供了所有預測的平均準確率。
2.4 性能評價指標
如表2所示,對于二分類問題來說,根據預測的結果得到混淆矩陣,對角線元素顯示每個類別的正確觀測值。

表2 二分類模型的混淆矩陣
本文選擇準確率(Accuracy)、精確率(Precision)、召回率(Recall)、F值(F1-score)來衡量二分類中不同模型算法的好壞,同時選擇ROC(receiver operating characteristic)曲線和ROC曲線下面積(area under ROC curve, AUC)來完善二分類的評價指標。Accuracy表示分類正確的樣本數占總樣本數的比例。但是,對于不平衡數據的表現很差;Precision表示預測為正類的樣本中真正類所占的比例;Recall是在所有正類中被預測為正類的比例;F1-score是Precision和Recall的調和平均,一般用來衡量分類器的綜合性能。ROC曲線又稱作“受試者工作特性曲線”,橫坐標為假正率(false positive rate, FPR),縱坐標為真正率(true positive rate, TPR),曲線越靠近左上角的點,效果越好。AUC定義為ROC曲線下的面積,取值范圍一般為(0.5,1.0)。AUC就越大,表示模型分類性能越好。
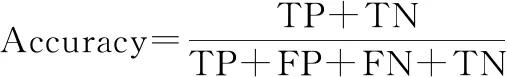
(7)
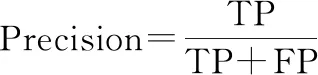
(8)
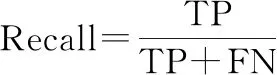
(9)
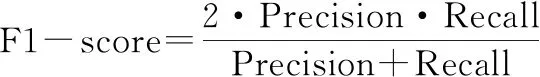
(10)
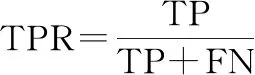
(11)
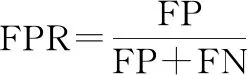
(12)
2.5 概率混淆矩陣
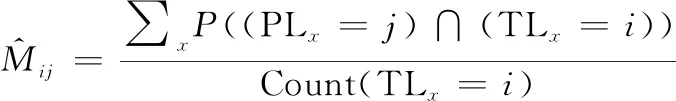
(13)
式中:TL表示真實標簽;PL表示預測標簽;∑((PL=)∩(TL=))是觀測值的預測標簽為而其真實標簽為的概率。
3 實驗結果
3.1 實驗設定及說明
定義LSTM分類器的相關參數如表3所示。在模型訓練過程中,本文采用keras.callbacks中的回調機制來加快訓練過程并保存最佳分類模型。當損失值或準確率達到最優值后,就停止訓練,進而提高訓練效率和模型擬合精度。

表3 LSTM分類器的相關參數
3.2 RUL分類結果分析
首先,時間窗和的大小劃分如表4所示,分析對發動機RUL分類效果的影響;其次,將準備好的C-MAPSS FD001數據集分成訓練集、驗證集和測試集;然后,利用滑動時間窗方法對數據集進行標記,將標準化后的數據集輸入建立的深層LSTM分類器中,預測設備在特定時間窗口內的失效概率。通過設置時間窗口大小,輸出如表4所示的9組實驗結果。其中,一個Epoch(時期)表示使用訓練集的全部數據對模型進行一次完整訓練。
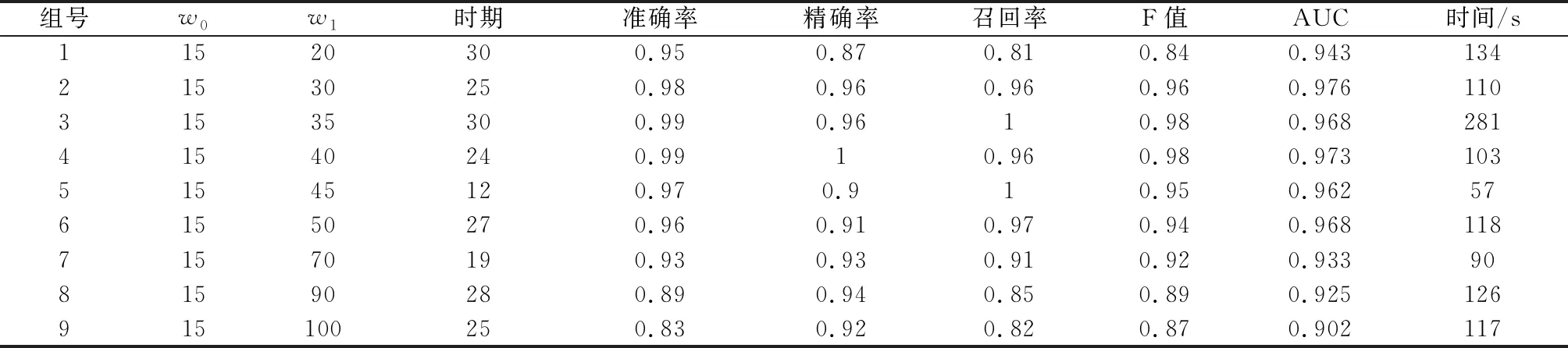
表4 分類模型的實驗結果
圖4 為RUL二分類性能評價指標的可視化展示。可以看出,當=35和=40時,模型的分類準確率最高為099。然后,隨著時間窗口增大,Accuracy逐漸減小到083,降幅為162%;當=35和=40時,F1-score取值達到最大值098,可知兩組實驗具有相近的綜合分類性能。由圖4可知,當>40時,F1-score隨增大而逐漸減小;另外,第3組的AUC取值最大為0976,這與第4組的結果無明顯差別,=40時的二分類ROC曲線如圖5所示;圖6為模型運行時間隨的變化趨勢(紅色虛線為平均運行時間),可以看出第3組的運行時間最長為281,第5組的運行時間最小為57,兩組的AUC取值相近,因此在選擇模型時可優先選擇第5組。另外,與第2組相比,第4組具有更小運行時間,即更高運行效率。
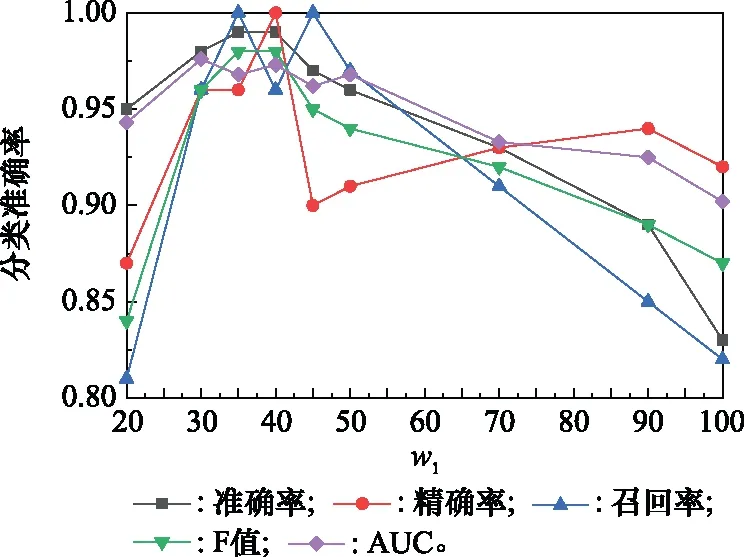
圖4 RUL二分類性能評價結果Fig.4 RUL binary classification performance evaluation results
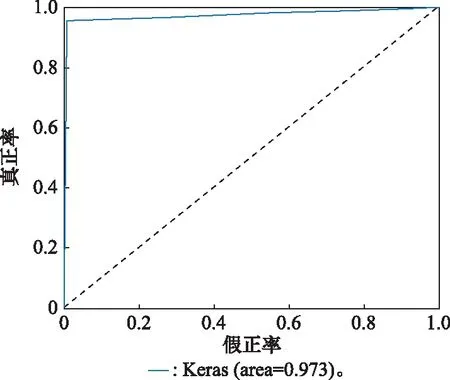
圖5 w1=40時的二分類ROC曲線Fig.5 Two-class ROC curve when w1=40
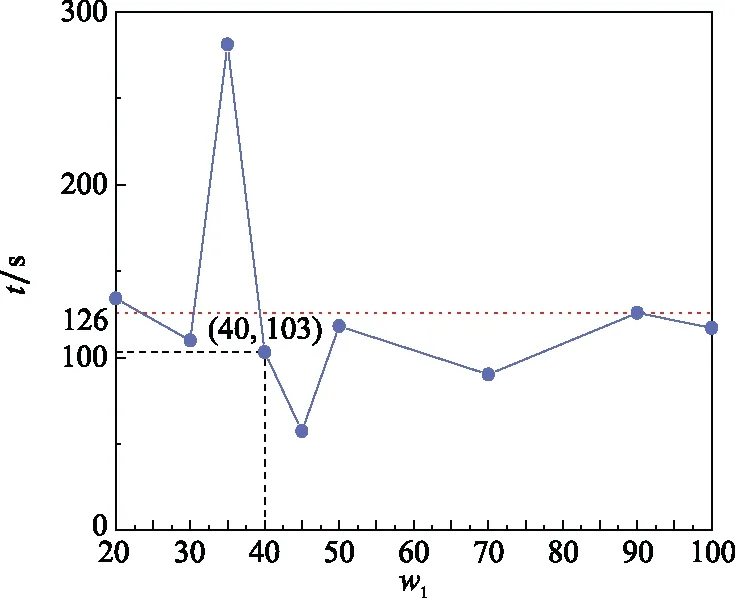
圖6 模型運行時間隨w1的變化趨勢Fig.6 Trend of model running time with w1
綜合以上分析可知,本文選擇第4組為最優二分類模型,即時間窗口為=15和=40。圖7描述了=40時的模型訓練過程,隨著時間的增加,訓練集和驗證集的loss逐漸減少。在運行20 Epochs以后,訓練集與驗證集的loss誤差趨于平穩,并在Epoch=24時達到最優的模型訓練性能。訓練集和驗證集的Accuracy呈現出與loss相反的變化趨勢,同樣在Epoch=24時達到最優值。圖8為二分類模型測試集的概率混淆矩陣(=15,=40)。當系統屬于Deg1時,對于測試集,系統預測狀態為Deg0的概率非常低,僅為3.57%,而預測狀態為Deg1的概率為96.43%;當系統屬于Deg0時,對于測試集,系統預測狀態都為Deg0,這表明此時模型具有優良的分類性能。
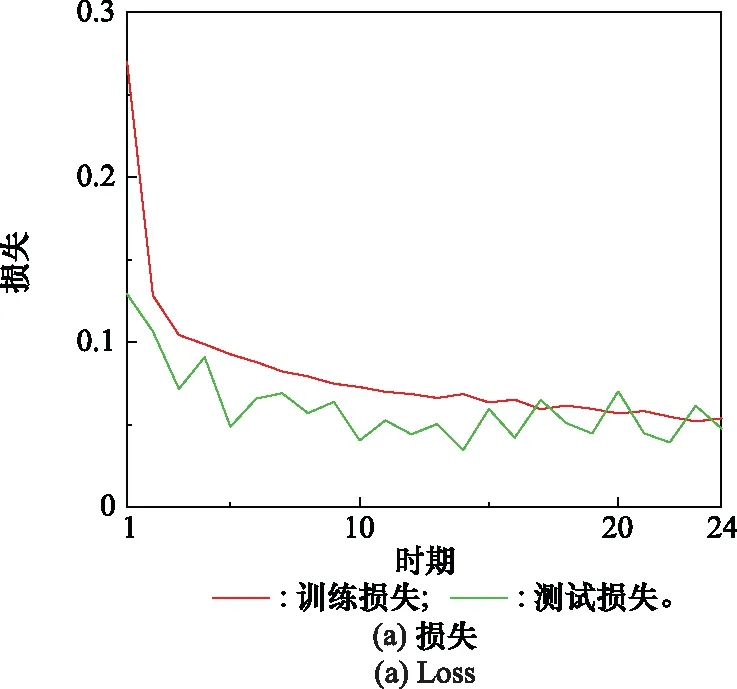
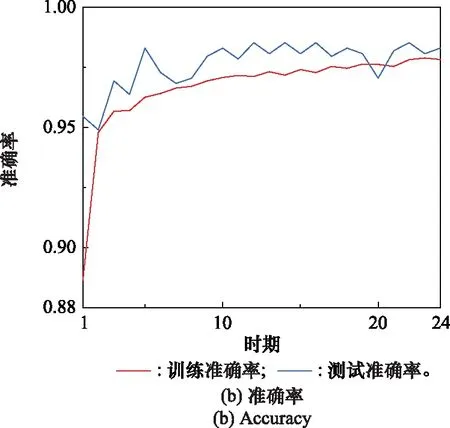
圖7 w1=40時的模型訓練過程Fig.7 Model training process when w1=40
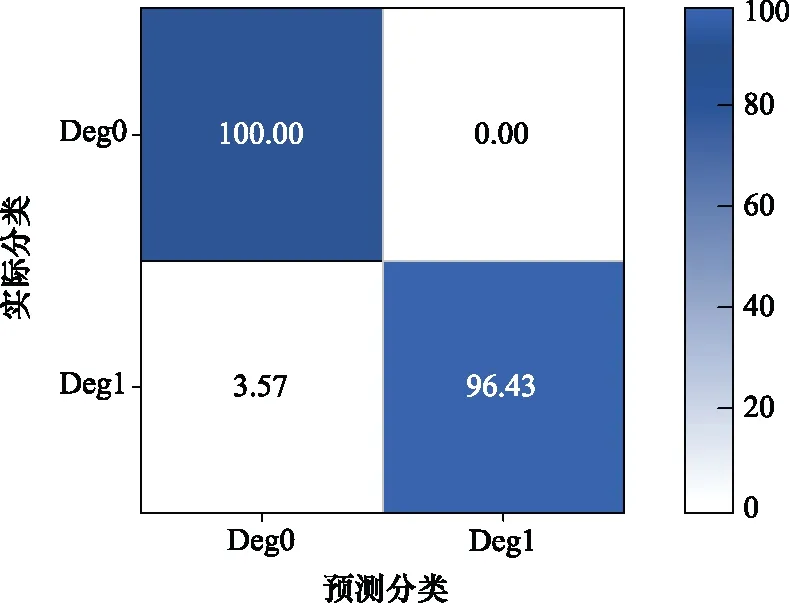
圖8 測試集的概率混淆矩陣(w0=15,w1=40)Fig.8 Probability confusion matrix of the test set (w0=15, w1=40)
3.3 與其他方法的比較
本文將提出的方法與Python scikit-learn庫中現有方法進行了對比,包括邏輯回歸、決策樹、隨機森林(random forest, RF)、支持向量分類(support vector classification,SVC)、K近鄰(K-nearest neighbors,KNN)、高斯樸素貝葉斯分類器(Gaussian naive Bayesian classifier, Gaussian NB),各種方法的窗口大小設置均為=15和=40。
在Logistic Regression中,分類方式參數為“ovr”,并采用“lbfgs”作為求解器,利用海森矩陣對損失函數進行迭代優化,最大迭代次數為100;在Decision Tree中,特征選擇標準為“entropy”,決策樹最大深度為4,最小葉子節點為1,最小內部節點為2,不考慮葉子節點的權重;在Random Forest中,特征選擇標準為“entropy”,決策樹最大深度為6,最小葉子節點為1,最小內部節點為2,決策樹個數為50,并行工作數為1;在SVC中,核函數為“rbf”,函數維度為3,核函數參數為“auto”,不限制最大迭代次數,停止訓練的誤差值為0.001;在KNN中,數的大小為30,樹的距離度量為歐幾里德度量,并行工作數為1,近鄰數為13,預測的權函數為平均加權;在Gaussian NB中,先驗概率priors=None,即獲取各類別的先驗概率。
表5中比較了所提方法和在發動機測試數據集FD001中的性能,性能指標的可視化對比結果如圖9所示。與其他方法相比,本文所提方法具有最大的Accuracy、Precision、Recall和F1-Score。特別地,F1-Score為反映模型分類性能的綜合指標,由圖9可以直觀地看出所構建的LSTM分類器較現有方法具有顯著的優越性,尤其適用于多元長序列傳感器數據的處理過程。對比其他方法中最優方法的性能,所提方法的準確率提高了5.31%,而F1-Score提高了10.11%。這意味著所提出的方法具有最好的分類性能,表明了所提方法對發動機RUL分類問題的有效性。
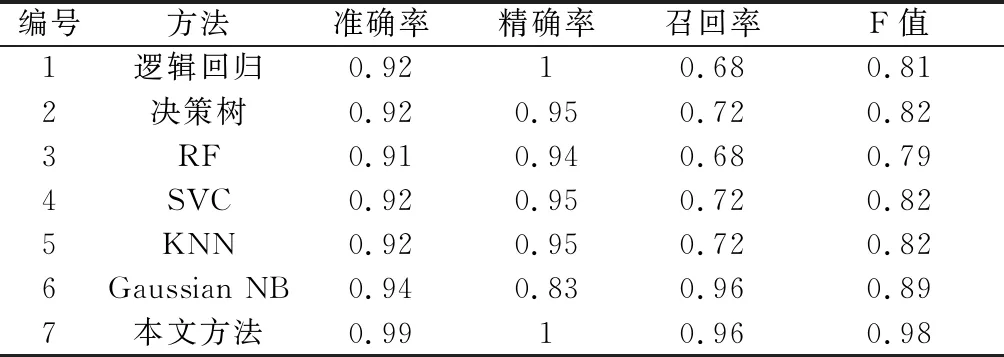
表5 與現有方法的性能對比
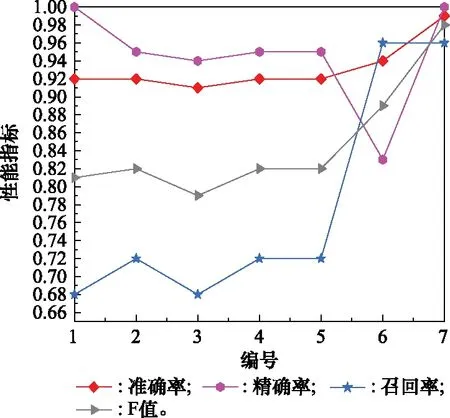
圖9 與其他方法的性能指標對比Fig.9 Comparison of performance indicators with other methods
4 結 論
(1) 本文提出了基于LSTM分類器的航空發動機預測性維護模型,與一般預測RUL值的方法不同,所提方法提供了設備RUL落入特定時間窗口的概率。
(2) 采用滑動時間窗口定義訓練樣本標簽,然后將預處理后的數據集輸入建立的深層LSTM分類器中,預測設備在特定時間窗口內的失效概率。通過分析對故障概率的影響,得到最優性能的LSTM分類模型,以更好地適應實際維護需求。在特定的時間窗口內,維護工程師可以根據RUL分類信息來安排維護和生產活動。
(3) 提出的模型在美國國家航空航天局的 C-MAPSS的數據集上進行了驗證,評價指標均優于其他現有分類模型,驗證了LSTM分類器的有效性。同時,更加準確的RUL分類模型可降低維護成本,提高維護效率。
猜你喜歡
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
民用飛機設計與研究(2019年2期)2019-08-05 01:33:40
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
汽車與新動力(2015年1期)2015-02-27 12:11:01
汽車與新動力(2013年5期)2013-03-11 16:08:17
