3D/2D卷積神經網絡評估顱內出血的臨床價值
2022-03-11 12:14:48趙施竹
中西醫結合心腦血管病雜志 2022年4期
關鍵詞:研究
楊 光,趙施竹
顱內出血是嚴重威脅健康的重大疾病,病人死亡率較高[1]。早期準確診斷對急性顱內出血管理具有重要意義[2-3]。顱內出血的早期和準確診斷受到多種因素影響[4],急診室環境中,腦部非增強CT(non-contrast CT,NCCT)檢查和報告可能需要較長的時間。這些可能影響病人管理,由于出血擴大導致病情急劇惡化常在癥狀發作初始3.0~4.5 h內發生[5-7]。因此,發現顱內出血快速準確的診斷工具可能有助于及時治療,并最終改善預后。
自動化定量出血工具除可測定顱內出血外,還可為預測和監測病人提供可靠的指標[8-9]。腦實質內出血(intraparenchymal hemorrhage,IPH)的定量臨床標準依賴于簡化公式(ABC/2)計算,該公式通常評估IPH體積達30%[10]。雖然手動劃定出血可準確估算體積,但時間限制這種方法在急診情況下的實現。因此,需要一種快速量化顱內出血體積的全自動和客觀化工具,提供準確詳細的信息,以指導臨床決策。
本研究提出一個基于深度學習的卷積神經網絡(convolutional neural networks,CNN)工具,這種新型技術可進行圖像解析[11]。CNN的有效性基于在無明確的人工編程情況下進行自組織和模式識別能力的算法。Prevedello等[12]研究顯示,通用算法可用于廣泛篩選各種急性NCCT(出血、腫塊效應、腦積水),總體敏感度和特異度分別為90%和85%。通過定制新的基于興趣的掩碼區域CNN(掩碼R-CNN)架構擴展這一初步工作,該架構為顱內出血評估和網絡訓練。除驗證回顧隊列外,還將其在前瞻驗證隊列中進行測試。通過測定現實環境中此種工具的性能,評估其在臨床實踐中實施的可行性。本研究的3個關鍵目標包括深度學習算法的開發和評估最終訓練的CNN性能:①顱內出血包括IPH、硬膜外出血/硬膜下出血(EDH/SDH)和蛛網膜下腔出血(SAH);②顱內出血體積的量化;③作為自動化流程的一部分,對獨立的現實樣本進行前瞻性實時推論。
1 資料與方法
1.1 研究對象 確定兩個單獨的隊列分別用于訓練和前瞻驗證。訓練隊列為2018年1月—2018年7月在研究機構進行的NCCT掃描;驗證隊列時間為2018年10月—2019年2月急診科的NCCT 檢查。對于這兩個隊列,從臨床報告中發現陽性出血病例(IPH、EDH/SDH和SAH),并通過專業放射科醫生確認。使用本研究開發的自定義半自動基于Web的注釋平臺,為所有陽性出血病例生成3D紋理真實掩碼。所有掩碼準確性均由專業放射科醫生目視檢查。
1.2 卷積神經網絡 從掩碼R-CNN算法派生的自定義體系結構用于檢測和分割出血[13]。掩碼R-CNN體系結構為候選區域(region proposal)、對象檢測(分類)和實例分段并為進行評估提供一個靈活高效的框架(見圖1)。測試預先設置的分布在不同形狀和分辨率的邊界框可能存在潛在異常,之后識別排名最高的邊界框,并用于生成候選區域,從而將算法的注意力集中在圖像特定區域上。這些復合候選區域使用非最大抑制法進行修剪,輸入到分類器中確定是否存在出血。在測定陽性出血情況下,使用網絡的最后一個分割分支生成二進制掩碼。

圖1 Mask R-CNN方法(A為測試預先配置的不同形狀和分辨率的邊界框是否存在潛在的異常;B為確定排名最高的邊界框,并用于生成引起算法注意的候選區域;C為使用非最大抑制修剪復合候選區域,并將其輸入分類器中,以確定是否存在出血;D為陽性的出血病例生成分割掩碼)
掩碼R-CNN架構效率來自一個共同的骨干網絡,該骨干網絡生成一組共享的圖像特征,用于各種并行檢測、分類和分割任務。卷積神經網絡 ConvNet 分為4大層。①圖像輸入Image Input:為減小后續BP算法處理的復雜度,一般建議使用灰度圖像。使用RGB彩色圖像,此時輸入圖像原始圖像的RGB三通道。輸入的圖像像素分量為[0,255],為了方便計算一般需要歸一化,若使用sigmoid激活函數,則歸一化到[0,1];若使用tanh激活函數,則歸一化到[-1,1]。②卷積層(convolution layer):特征提取層(C層)-特征映射層(S層)。將上一層的輸出圖像與本層卷積核(權重參數w)加權值,加偏置,通過一個sigmoid函數得到各個C層,之后采樣subsampling得到各個S層。C層和S層的輸出稱為Feature Map(特征圖)。③光柵化(rasterization):與傳統的多層感知器MLP全連接,將上一層的所有Feature Map的每個像素依次展開,排成一列。④多層感知器(MLP):最后一層為分類器,一般使用Softmax,若是二分類,也可使用線性回歸Logistic Regression,SVM,RBM。詳見圖2。
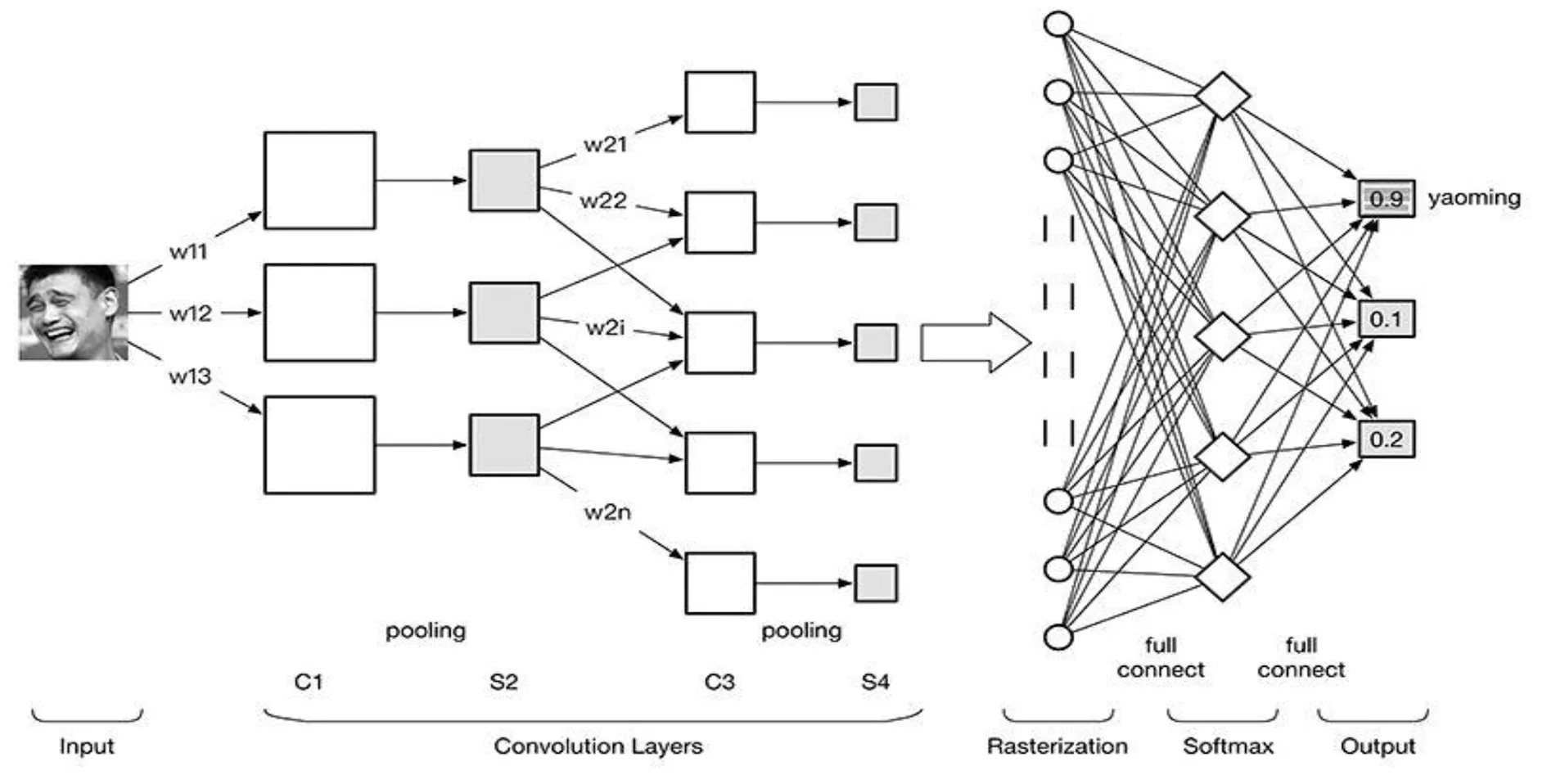
圖2 卷積神經網絡的基本結構
本研究采用的骨干網絡是特征金字塔網絡(feature pyramid network,FPN)的自定義混合3D/2D變體[14]。定制骨干網絡使用標準的瓶頸殘差塊(residual bottleneck blocks)[15],無迭代調整,由于觀察到R-CNN架構,特別是基于FPNS架構,對許多設計選擇均是穩健的。執行過程中,大小為5×512×512的三維輸入矩陣被映射到不同分辨率的二維輸出特征映射圖,使用投影操作匹配矩陣維數,將來自FPN自下而上路徑(bottom-up pathway)的三維輸入添加到自上向下路徑(top-down pathway)的二維輸出特征映射圖中。通過這種方式,網絡利用緊鄰感興趣區域的5個切片的背景信息預測出血的存在和位置。
1.3 實現過程 采用原始快速R-CNN實現中[16]描述的近似聯合訓練方法,對候選區域網絡(RPN)、分類器和分割進行并行優化。掩碼 R-CNN結構使用每張圖像128個采樣ROIS進行訓練,正負樣本比例固定在1∶3。推理過程中,RPN排名前256個候選區域(proposals)使用非最大限度地抑制修剪,并生成用于分類的檢測框。RPN錨跨越4個尺度(128×128,64×64,32×32,16×16)和3個高寬比(1∶1,1∶2,2∶1)。
使用啟發式方法初始化網絡權重[17],最終的損失函數包含一個l2正則化網絡參數術語。應用Adam實現優化,該方法是基于低階矩自適應估計的隨機目標函數一階梯度優化算法[18]。觀察到訓練損失平臺時,初始學習速率為2×10-4。
采用python 3.5編寫軟件代碼,使用開源TensorFlow r1.4程序庫[19]。實驗在一個GPU優化的工作站上進行,工作站上有4塊NVIDIA GeForce GTX Titan X 卡(12 GB,Maxwell architecture)。使用單一GPU配置確定推斷基準速度。
1.4 圖像預處理 對于每一卷,軸向軟組織重建系列自動確定是自定義基于CNN的算法。若有必要,可將該卷調整為平面內分辨率矩陣為512×512。所有矩陣值均小于-240 HU或更高+240 HU,重新調整整卷為[-3,3]。
1.5 統計學處理 研究的主要終點是在每次檢查的基礎上測定出血。若在任何給定切片上有任何單個候選區域為出血陽性,認定預測為NCCT有出血。基于此,評估算法性能,包括準確性、敏感度、特異度、陽性預測值(PPV)和陰性預測值(NPV)。通過改變用于出血分類的softmax評分閾值,計算受試者工作特征曲線下面積(AUC)。除完整的數據集評估之外,平衡數據集的性能統計信息(陽性和陰性病例數相等)可同時計算出來。使用平衡分布,準確度根據出血類型(IPH、EDH/SDH和SAH)和出血量多少(點狀、小、中、大;定義分別為<0.01 mL,0.01~5.00 mL,5.10~25.00 mL,>25.00 mL)計算。
研究的次要終點是準確估算出血量的能力,包括2種評估方法:預測出血的二進制掩碼使用Dice評分系數與手動分割進行比較;使用Pearson相關系數(r值)將預測的出血量與金標準進行比較。
1.6 訓練隊列評價 五重交叉驗證方案評估初始訓練隊列,將集中的80%數據隨機分配到訓練隊列中,其余的20%用于驗證。之后重復此過程5次,直到整個數據集中的每項檢查均經過驗證。驗證結果報道整個數據集的累積統計信息。
1.7 獨立測試隊列評估 調整算法設計和參數后,最終訓練網絡應用到新的前瞻隊列。整個推理流程完全自動化,包括將新獲得的檢查從PACS實時傳輸到自定義GPU服務器,識別正確的輸入序列和訓練有素的網絡推理。除初始驗證統計信息,可報道來自獨立測試數據集的結果。
2 結 果
2.1 研究對象選擇 初始訓練隊列共10 159次NCCT檢查,其中901次(8.9%)符合腦出血,包括IPH(358次,3.5%),EDH/SDH(319次,3.1%)和SAH(224次,2.2%);共生成512 598張圖片。中位出血量為28.2 mL。
獨立測試數據集隊列共682次前瞻NCCT檢查,其中82次(12.0%)符合腦出血,包括IPH(23次,3.4%),EDH/SDH(38次,5.6%)和SAH(21次,3.1%);生成2 368張圖片。中位出血量為24.9 mL。詳見表1。

表1 出血類型和出血量大小分布 單位:次
2.2 顱內出血測定 完整數據集總體算法性能,包括訓練隊列預測準確性、AUC、敏感度、特異度、PPV和NPV,分別為0.975,0.983,0.971,0.975,0.793和0.997;前瞻隊列分別為0.970,0.981,0.951,0.973,0.829,和0.993。進行顱內出血類型分層時,訓練隊列中IPH,EDH/SDH和SAH檢測的靈敏度分別為98.6%(353/358),97.4%(311/319)和94.2%(211/224);前瞻隊列分別為100.0%(23/23),94.7%(36/38)和90.5%(19/21)。訓練隊列中2.9%(26/901)出血判錯,前瞻隊列中4.9%(4/81)出血錯判(見圖3、圖4)。根據出血量分層的平衡數據集結果顯示出通用算法精度,出血量>5 mL(0.977~0.999)高于出血量<5 mL(0.872~0.965),兩隊列中僅4例(EDH/SDH)出血>5 mL被錯判。點狀出血<0.01 mL的檢測準確度(0.872~0.883)較少量出血(0.01~5.00 mL)的準確度(0.906~0.965)更具挑戰性。進一步對出血類型分層,最具挑戰性的是點狀SAH或EDH/SDH的測定,訓練隊列為0.830~0.881。平衡數據集完全分層結果見表2。

圖3 顱內出血分割實例[A列為輸入的CT切片;B列為對應的手工分割(藍線);C列為相應的半自動分割(紅線);D列為全自動分割(綠線)]

圖4 網絡預測實例[該算法的假陽性和假陰性網絡預測包括異常區域的邊界框候選區域(以聚焦算法注意力)和最終的網絡預測結果的置信度。假陽性的出血預測(紫色)包括運動偽影和/或后顱窩束的硬化(A)或高密度模擬皮質鈣化(C)。排除性出血的假陰性預測通常包括小的體積異常,密度相對較低,從而降低顯著性。此病例包括沿右額葉后部(B)和右頂下葉(D)的微小蛛網膜下腔出血]

表2 平衡數據集出血類型和大小分層性能
2.3 顱內出血量化 與手工分割比較,由CNN分割評估IPH、 EDH/SDH和SAH的Dice系數分別為0.931,0.863和0.772。CNN分割IPH、EDH/SDH和SAH出血量的Pearson相關系數r值分別為0.999,0.987和0.953。與簡化公式ABC/2得到的IPH相比,Pearson相關系數r值為0.954。平均而言,ABC/2得到的出血量高估約20.2%,CNN得到的出血量低估約2.1%。
2.4 網絡統計值 收斂前每個網絡進行相應的驗證折疊訓練約100 000次迭代。根據用于訓練分配的GPU卡數量,此過程每一折疊平均需要6~12 h。訓練后,掩碼R-CNN網絡在平均0.121 s確定新測試案例中是否存在出血,這一過程包括單個GPU工作站上的所有預處理步驟。
3 討 論
本研究測定IPH、EDH/SDH和SAH顱內出血準確,CNN通過Dice評分系數反映出高精度的顱內出血定量(0.772~0.931)和Pearson相關(0.953~0.999)。將自動推理流程用于前瞻隊列,深度學習工具通過NCCT檢查準確測定和量化顱內出血。
較多傳統學習技術用于顱內出血測定,如模糊聚類[20-21]、Bayesian分類[22]、設置閾值水平[23]和決策樹分析[24]。目前給定的NCCT進行頭部檢查存在大量圖像多樣性,最終限制從先驗規則和硬編碼的假設中得到算法的準確性。有研究使用決策樹分析進行IPH測定的靈敏度為0.60,PPV為0.447[25]。硬編碼邏輯傾向于產生僅針對單項任務。一種用于出血的水平設定技術,量化產生的Dice得分為0.858~0.917[23],該算法對出血的測定是有限的,由于其未在設計中排除陰性檢查出血。
鑒于對醫學成像深度學習潛力的認識不斷提高,越來越多的研究傾向于使用CNN方法。開發了用于肺結節的多尺度CNN對CT圖像進行測定[26],相關研究設計了一個12層的CNN預測乳房X線照片上的心血管疾病[27]及脊柱轉移的測定[28]。有研究報道了一種深度學習方法,將幾個預先訓練的網絡用于20個案例的小型測試集[29]。
這些初步工作十分重要,仍存在一些關鍵限制,臨床應用深度學習工具前需解決這些問題。首先,除具有較高的算法性能外,臨床上可行的工具必須解決傳統無法合理化給定的解釋。一些技術通過生成顯著性地圖[30]或類活化地圖[31]改善,這是傳統的基于整體CNN圖像分類(或數據卷)的已知局限性。候選的自定義掩碼R-CNN體系結構通過將基于注意力的物體檢測網絡與傳統的分類和分割組件結合,允許算法明確定位可疑CT發現并提供某些發現可能代表顱內出血的視覺反饋或模仿。
其次,臨床使用工具需在非過濾數據進行測試。本研究通過將訓練好的網絡應用在一個完全自動化的推理流水線中模擬這一過程,這個流水線可執行所有支持算法預測的必要步驟,從PACS圖像傳輸到序列識別,再到GPU啟用的推理,這些均不需要人工監控。這種背景下使用前瞻性獨立測試集,是目標人群的抽樣樣本,這些樣本是在急診放射學檢查的NCCT頭部掃描。算法性可在前瞻測試中保持良好,表明深度學習工具具有潛在的臨床應用價值,同時指出適應算法驗證所需的數據庫大小。雖然大型數據集在醫學影像學中少見,但病理學代表性樣本對算法精確性的驗證是重要的。本研究結果顯示,神經網絡難學習和歸納[點狀出血<0.01 mL,約占所有檢查的0.5%(56/10 841)],因此,需要大量具有代表性的數據集評估這些關鍵的罕見現象。大型數據庫可促進算法學習,通過增加訓練樣本多樣性,幫助網絡選擇通用的預測特征。無顱內出血的病例和顱內出血的病例同樣重要,由于算法必須正確識別無出血的多數病例,盡管可能存在任何潛在的病例。為了解決這些問題,本研究利用大型訓練數據集優勢,該數據集包括512 598張圖片,較以往研究數量較多。
準確的出血檢測工具突出的用例是分診系統,可提示醫生潛在的陽性檢查,以便加快判讀,從而有助于減少全程結果回報時間(TAT)。有研究顯示,超過80家機構將減少TAT達標的重要性作為優先考慮的事件之一,總分6.0分得到5.7分[32],從而加快病人的治療分流。快速識別IPH病人將有助于在癥狀出現的最初3.0~4.5h控制血壓,避免癥狀急劇惡化[5-7]。INTERACT-2試驗進一步證實了這一點,結論是早期診斷提供的強化治療與功能改善有關[33]。
除出血測定,顱內出血的定量指標可精確和有效量化疾病初始負擔和后序變化,可能具有重要的臨床意義[34-35]。IPH發病2~3 h,出血量可急劇變化[5-7]。出血量是30 d死亡和并發癥發生的已知預測因子[8-9]。目前,臨床估計腦出血量的標準是ABC/2公式,其中A、B、C分別代表血腫長、寬和厚度[10,36]。雖然易于使用,但這種方法的局限性是對所有IPH來說血腫均是橢圓形。本研究結果顯示,這一方法高估出血量20.2%,與手工分割比較相差30%[10]。雖然手工標測是黃金標準,但急診應用中這種方法既費時間又存在技術的挑戰。經過訓練CNN可快速、準確地定量IPH體積,與手工測量的相關系數為0.999,可方便臨床,同時作為手工測量的一種變通方法。
本研究存在一些局限性:①研究結果是在單一中心得到的,結果普適性可能不高,今后將其用于其他機構掃描儀和不同掃描設備進行預測性能評價。CT檢查本質上采用hounsfield單位標準化,并顯示出較X平片或磁共振成像較少的影像變異性。②深度學習算法易受到對抗性噪聲的影響,圖像中微小但高度模式化的擾動可能導致不良的預測結果[37]。目前數據集并未遇到這種情況,使用網絡集成和去噪音自動編碼器可一定程度降低這種可能性[38]。
總之,高性能全自動、深入的學習算法可對頭部NCCT掃描檢測和定量IPH、EDH/SDH和SAH。嵌入在自動化推理環境中的前瞻性獨立測試集算法的高性能表現,這種深度學習工具在今后具有臨床可行性,可作為一種快速量化顱內出血體積的方法,加快病人治療的分流,并提供準確、詳細的信息指導臨床決策。
猜你喜歡
體育科技文獻通報(2022年3期)2022-05-23 13:46:54
天津外國語大學學報(2021年3期)2021-08-13 08:32:18
遼金歷史與考古(2021年0期)2021-07-29 01:06:54
科技傳播(2019年22期)2020-01-14 03:06:54
遼金歷史與考古(2019年0期)2020-01-06 07:45:20
民用飛機設計與研究(2019年4期)2019-05-21 07:21:24
電子制作(2018年11期)2018-08-04 03:26:04
汽車工程學報(2017年2期)2017-07-05 08:13:02
國際商務財會(2017年8期)2017-06-21 06:14:14
電子制作(2017年23期)2017-02-02 07:17:19
