基于人工神經網絡技術構建圍術期病人低體溫風險預測模型
2022-03-17 07:23:36項海燕黃立峰朱鋒杰
護理研究 2022年5期
項海燕,黃立峰,朱鋒杰,張 浩
浙江大學醫學院附屬第二醫院,浙江 310009
圍術期低體溫又稱圍術期非計劃性低體溫(inadvertent/unplanned perioperative hypothermia,IPH),指圍術期內發生的非計劃性的體溫下降,核心溫度低于36 ℃,但不包括治療性或計劃性的低體溫[1]。IPH 可引起寒戰、心血管系統風險、感染風險增加、麻醉蘇醒延遲、凝血功能障礙等不良后果[2-4],是手術常見的并發癥之一[5]。科學評估和早期預防是降低IPH 發生率的最有效措施[6]。預測模型(prediction model,PM)是臨床決策支持中用于個體風險預測的有效工具,可以將復雜的臨床指證轉化為數據模型,輔助醫護人員有效篩查、識別目標人群中的高危人群[7]。雖然已有使用回歸模型函數模擬IPH 的預測模型,但其理論方法的局限和預測對象覆蓋范圍的局限[8],影響臨床使用。基于深度學習的人工神經網絡(artificial neural network,ANN)模型,不需要精確的數學假設,對研究數據本身的分布類型無任何分布要求,其處理非線性問題的能力也較傳統的多元回歸統計方法要強大[9]。由臨床實踐可知,IPH 的發生與各相關因素之間不是簡單的線性關系,各因素之間也存在多重共線性,例如麻醉因素、手術因素和自身基礎情況的相互影響關系。因此,本研究認為ANN 技術是適合于IPH 和其影響因素之間數據聯系建模的方法。本研究回顧性收集臨床病例數據,通過循證和臨床相結合的方式篩選出IPH 的建模變量,基于ANN 新技術構建預測模型,并測試統計其相關性能指標,為科學預測IPH 提供一種新的建模思路,提高預測模型的臨床適用性。
1 資料與方法
1.1 臨床資料
1.1.1 收集數據 本研究經醫院倫理委員會審核,收集某三級甲等醫院2016 年1 月—2020 年9 月近5 年有圍術期體溫監測的手術病人相關數據,統一從醫院電子病歷系統和麻醉監測系統提取,總計107 386 例。納入標準:術前體溫正常;基礎代謝正常;靜脈全身麻醉病人(氣管插管)。排除標準:因手術需要術中實施低體溫的病人(如體外循環手術);圍術期體溫監測不全的病人;術前進行主動加溫干預的病人。剔除標準:數據記錄明顯異常(因醫護人員輸入錯誤等引起,不符合人類臨床特征)的病人;基礎數據不全的病人(如身高、體重等);其他不符合建模要求的個別病例。經過篩選,符合建模要求的病例共19 068 例。
1.1.2 篩選變量 課題組通過檢索PubMed、MedLine、Web of Science、中國生物醫學文獻系統、中國知網、萬方數據庫等數據庫搜集相關文獻,檢索時限為建庫至2020 年9 月30 日。采用澳大利亞Joanna Briggs Institute(JBI)循證中心和Johns Hopkins 標準[10],由2 名課題組成員(經過循證相關課程培訓),以互盲方式對搜集的文獻進行獨立評價。文獻的納入標準:以上數據庫收錄有關IPH 循證研究的文獻。文獻的排除標準:非人體試驗或相關報道;圍術期基礎體溫有異常者或基礎代謝有異常者。通讀相關文獻,歸納圍術期手術病人發生IPH 的風險因素,構建本研究所需的風險因素池,將病例資料中屬于風險因素池的風險因素作為建模變量。同時,依據臨床經驗和觀察結果,課題組認為“手術體位”(風險因素池外)較手術器官部位劃分(風險因素池內)更具有臨床意義,對于IPH 更具有代表性,增加風險因素“手術體位”為變量,其包含平臥位、俯臥位、側臥位和截石位4 種常見體位;將手術病人術前病房最后一次體溫測量作為基礎體溫(T0),手術過程中監測最低體溫為T1,麻醉復蘇室時監測到的最低體溫為T2,比較T1和T2,較低值為此病人圍術期體溫的最低值(T3)。其中,對于個別術中需要變換手術體位且不能明確歸類“手術體位”的病例,給予剔除。
基于已收集的大數據病例資料變量種類和前期風險因素的篩選工作,最終確定建模變量包括手術病人年齡、身高、性別、美國麻醉醫師協會(ASA)評分、體質指數(BMI)、基礎體溫、術前血壓(收縮壓和舒張壓)、脈搏(心率)、手術時長、麻醉時長、復蘇總時間(進出麻醉復蘇室時間差)、插管時長(進入復蘇室到氣管插管拔除的時間)、術中尿量、出血量、輸液量、總入量(包括輸液和輸血)、術前最近1 次血紅蛋白(Hb)值、圍術期最低體溫、手術體位等約20 個風險因素。
1.2 數據預處理 將數據中T3≤36.0 ℃的病例記上低體溫標簽,依據人工智能深度學習建模要求,將19 068 例數據分成訓練集和測試集兩部分[11],其中訓練集13 349 例,測試集5 719 例(大數據量建模選擇7∶3的比例,經過多次隨機分割,計算各數據集的基線特征,保證基線資料一致性情況下訓練集和測試集的正負樣本比例相同,即低體溫病例占比相同)。性別、ASA 分級、手術體位為分類變量,采用獨熱(one-hot)編碼[12];其余變量為連續變量,采用z-score 標準化處理,公式為:
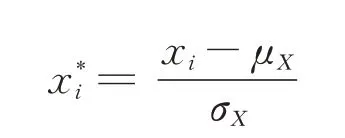
式中,μX是變量X的均值,σX是變量X的標準差,xi是變量X的第i 個取值。
1.3 建模方案 構建多層ANN 模型進行建模。模型包括輸入層、隱藏層和輸出層。見圖1。

圖1 深度ANN 結構邏輯圖
其中,隱藏層有節點數量為16 和8 的2 層網絡層組成(設置多種隱藏層大小,通過參數對比,最后得到16,8 的效果最好)。對二分類問題,模型利用對數損失通過懲罰錯誤的分類,衡量分類器的準確性。記標簽為y,y ∈{0,1}。通過極大似然估計法來估計參數θ,似然函數為:
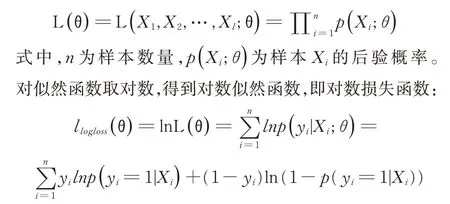
即令每個樣本屬于其真實標記的概率越大越好。
采用Adam 算法對目標函數進行優化[13],學習率為0.08,beta1=0.9,beta2=0.999,epsilon=10-8。輸出層激活函數采用sigmoid[14],其余網絡層激活函數采用線性修正單元(Rectified Linear Units,ReLU)[15]。對數據集進行100 次隨機劃分(通常選擇100,500,1000次等,本研究選擇100 次即可滿足建模需要),得到100 個不同的訓練集和測試集,重復進行試驗,得到模型性能指標的95%置信區間。
利用知識蒸餾方法[16],將神經網絡模型作為復雜模型,訓練簡單的邏輯回歸模型,從而將神經網絡從數據中學到的知識遷移到邏輯回歸模型中,得到輸入特征計算低溫風險的函數表達式。
1.4 模型性能檢測
1.4.1 預測模型的預測指標(見表1)
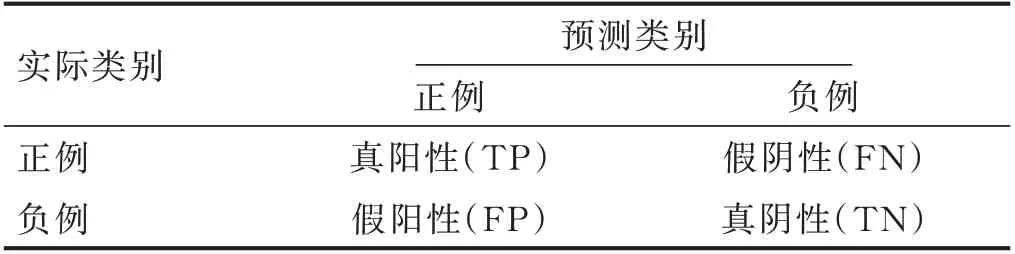
表1 預測模型實際類別和預測類別的關系
準確率表示全體樣本中預測正確的樣本的占比。一般而言,它的值越大意味著模型性能越好。陽性預測值(positive predictive value,PPV)/精確率(percision)表示被預測為正的樣本中正樣本的占比。陰性預測值(negative predictive value,NPV)表示被預測為負的樣本中負樣本的占比,與陽性預測值相對,一般而言,它的值越大意味著模型性能越好。真陽性率(true positive rate,TPR)/敏感度(sensitivity)/召回率(recall)在二分類問題中,真陽性率、敏感度和召回率3 個名詞對應著同一個概念,表示正樣本中被預測為正樣本的占比。真陰性率(true negative rate,TNR)/特異度(specificity)在二分類問題中,真陰性率和特異度對應著同一個概念,表示負樣本中被預測為負樣本的占比,與真陽性率相對。一般而言,它的值越大意味著模型性能越好。本研究主要比較模型的準確率、陰性預測值和特異度。
1.4.2 預測效度分析 模型的預測效度采用受試者工作特征曲線(receiver operating characteristic curve,ROC)進行分析。分別用訓練集和測試集計算ROC曲線及曲線下面積(area under curve,AUC)。通常認為,AUC>0.5,說明模型預測效度大于隨機概率,越接近1,預測效度越好。
1.4.3 決策曲線分析 本研究采用決策曲線分析方法評估模型的臨床實用性[17]。決策曲線以概率閾值為橫坐標,以凈收益(net benefit)為縱坐標繪制。凈收益將模型的利弊與風險閾值結合起來,量化衡量模型對輔助決策帶來的臨床效用。凈收益的計算公式如下[18]:
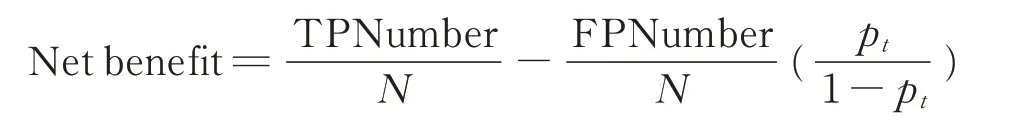
式中,Net benefit 為凈收益,TPNumber 為真陽性病人數量,FPNumber 為假陽性病人數量,N為病人數量,pt為概率閾值。當模型預測風險大于概率閾值時,就界定樣本為正例;否則,界定樣本為負例。
決策曲線以概率閾值為橫坐標,凈收益為縱坐標繪制曲線。分別假設所有病人為正例和負例,得到兩條決策曲線作為臨床實用性比較的參照。如果模型的決策曲線在兩條決策曲線的右上方,則模型的臨床實用性優于隨機方案,不會在臨床使用中產生有害影響。
1.5 統計學方法 本研究使用Excel 2016 建立數據庫。分類變量和連續變量分別采用獨熱編碼和z-score標準化進行預處理。利用χ2檢驗比較分類變量分布之間的差異,利用t檢驗比較連續變量均值之間的差異。模型的性能檢測使用準確率、陽性預測值、陰性預測值、敏感度、特異度及AUC 進行分析。所有的分析都使用R 版本4.0.2 和R 包進行[19],其中,神經網絡模型采用H2O 包實現。
2 結果
2.1 數據資料基線特征比較
2.1.1 IPH 病人和正常病人的基線特征比較 統計發現,IPH 病人和體溫正常病人在年齡、性別、ASA 評分、體重、身高、術前體溫、舒張壓、脈搏、尿量、輸液量、手術時間、復蘇時間、麻醉蘇醒時間、BMI、Hb 和手術體位等方面差異均有統計學意義(P<0.05),說明兩組病人的基線特征存在明顯差異,如IPH 組病人年齡較大、身材偏瘦等。見表2。本研究篩選出的20 個變量整體對于IPH 的敏感度較好,超過50%的變量指標P≤0.001,這些變量能夠反映IPH 病人的基線特征。可以推論,用這些變量指標構建的模型對于IPH會有較好的預測性能。
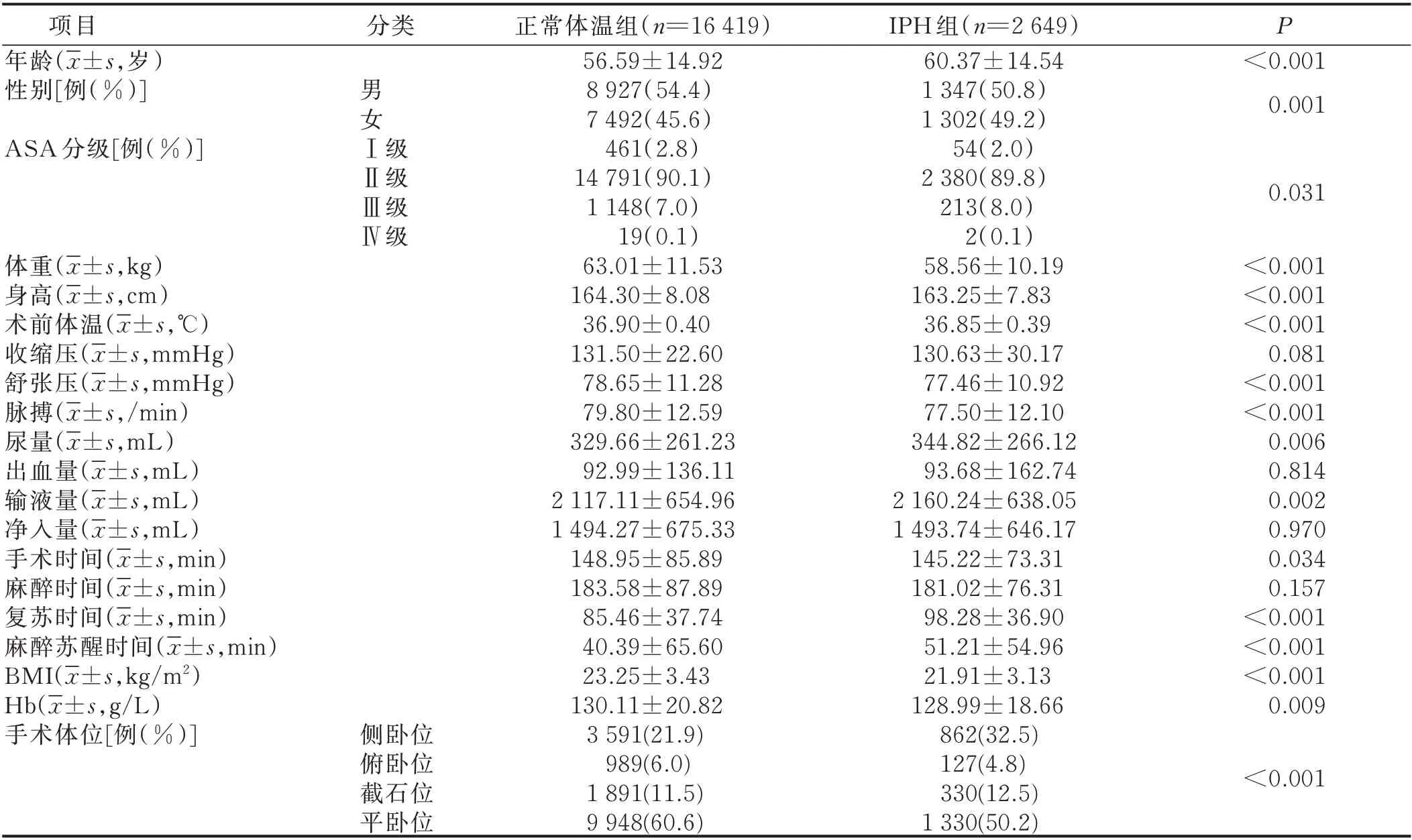
表2 IPH 病人和正常病人的基線特征比較
2.1.2 訓練集和測試集病人的基線特征比較 訓練集和測試集的病人基線資料比較差異無統計學意義(P>0.05),即兩組病例資料的基線特征一致,具有可比性。見表3。
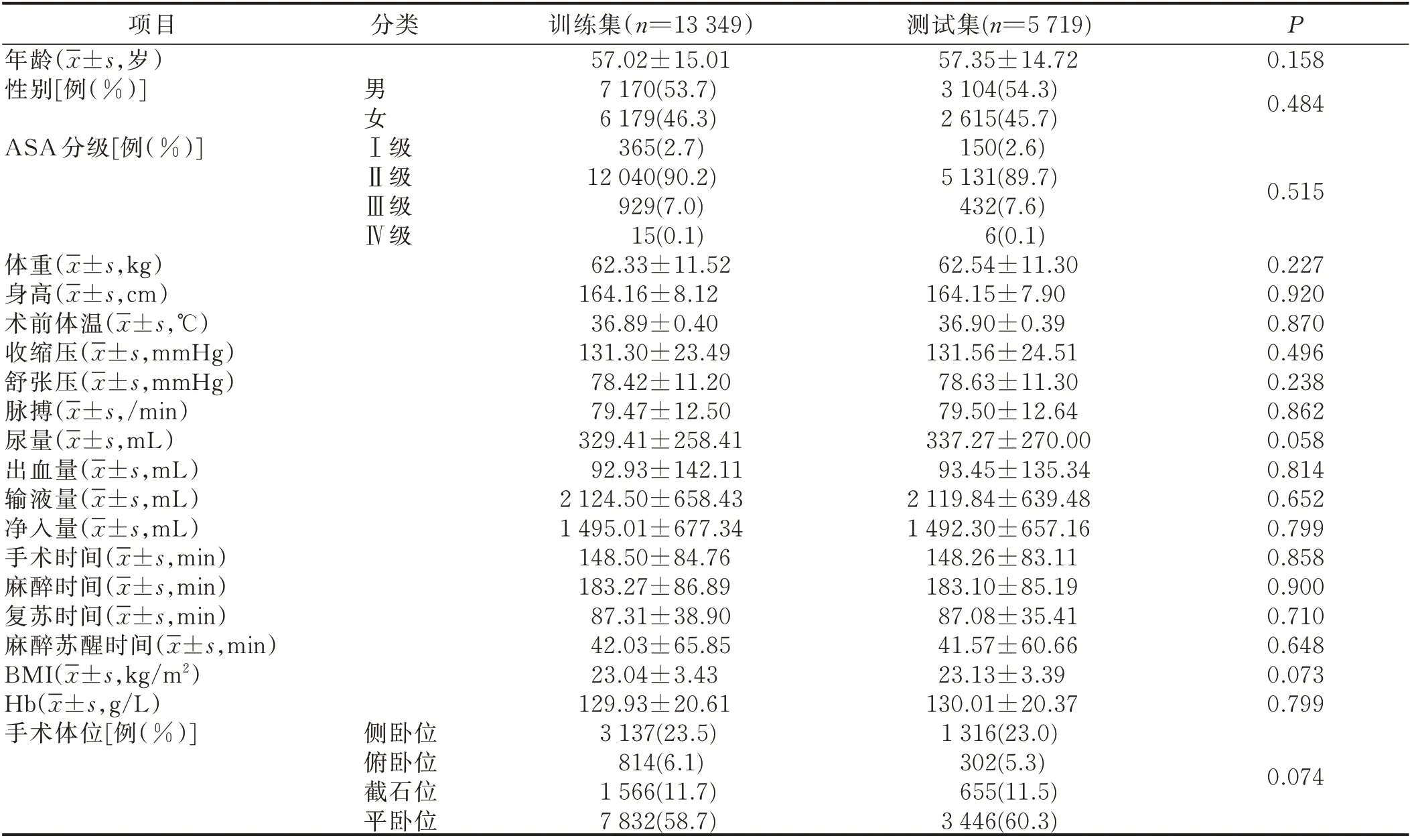
表3 訓練集和測試集病人的基線特征比較
2.2 模型訓練結果 基于知識蒸餾方法,將建模結果遷移到邏輯回歸模型中,得到關于IPH 的建模函數表達式。通過分析發現,病人的性別(女)、ASA 分級、體重、凈入量、手術體位等變量(數據歸一化)對IPH 的發生有較大影響。

2.3 模型性能測試結果
2.3.1 準確率 統計發現,訓練集和測試集的準確率均>75%,臨床適用性較好;特異度均>0.8,認為此模型對于IPH 的特異度較高,符合建模預期。相關性能指標見表4。
表4 模型的各性能指標測試結果(±s)

表4 模型的各性能指標測試結果(±s)
項目訓練集測試集準確率0.780 4±0.013 6 0.778 1±0.027 1陽性預測值0.256 9±0.012 0 0.231 2±0.025 5陰性預測值0.912 9±0.002 4 0.901 2±0.004 8敏感度0.516 4±0.026 4 0.364 0±0.052 6特異度0.823 0±0.020 0 0.844 9±0.039 6 AUC 0.724 3±0.008 6 0.700 3±0.009 3
2.3.2 預測模型的ROC 曲線 由表4 及圖2、圖3 可知,訓練集的AUC為0.724 3,測試集的AUC為0.700 3,兩者的0.5<AUC<1,說明此模型優于隨機猜測,具有預測價值。
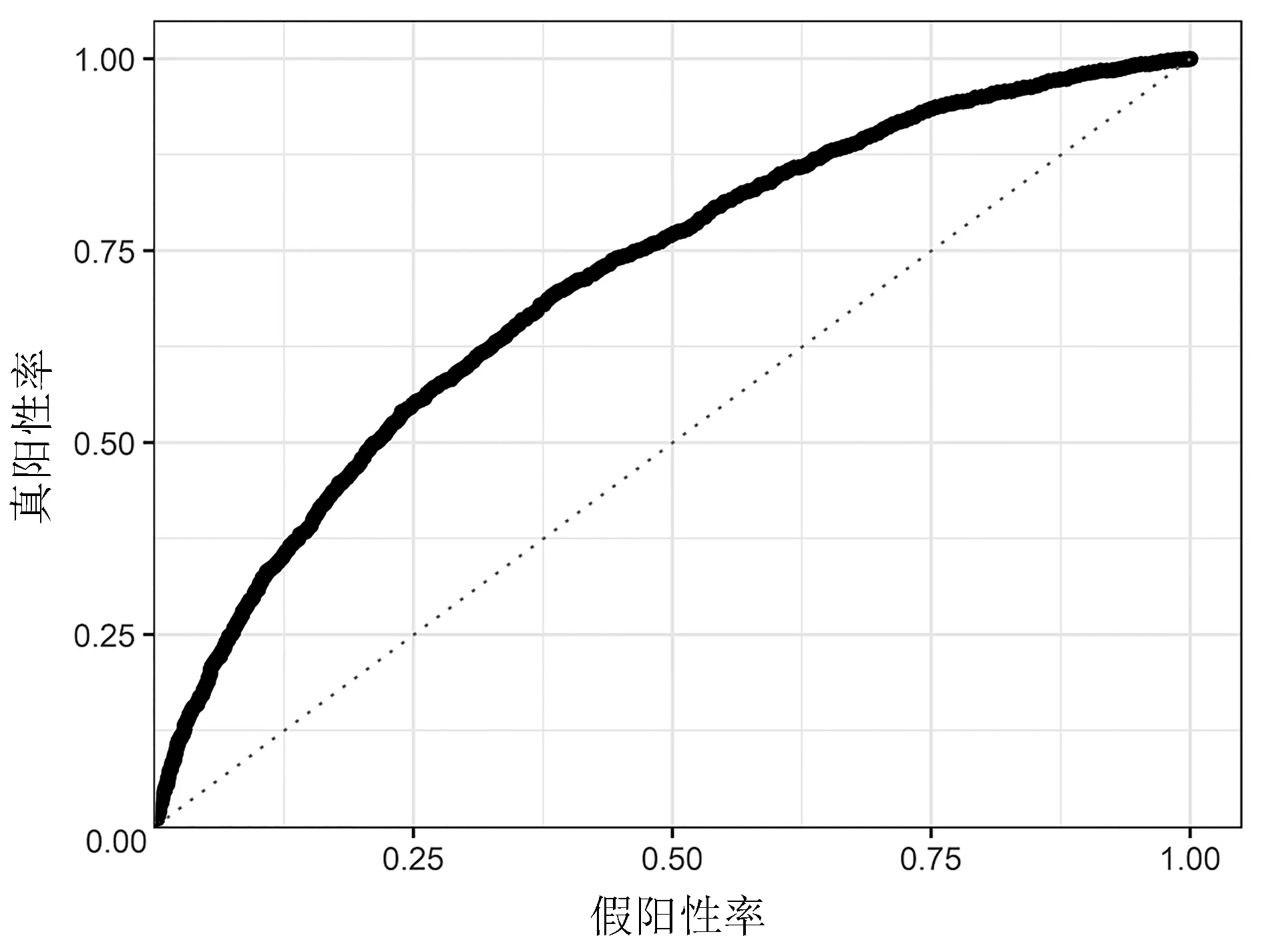
圖2 訓練集的ROC 曲線圖
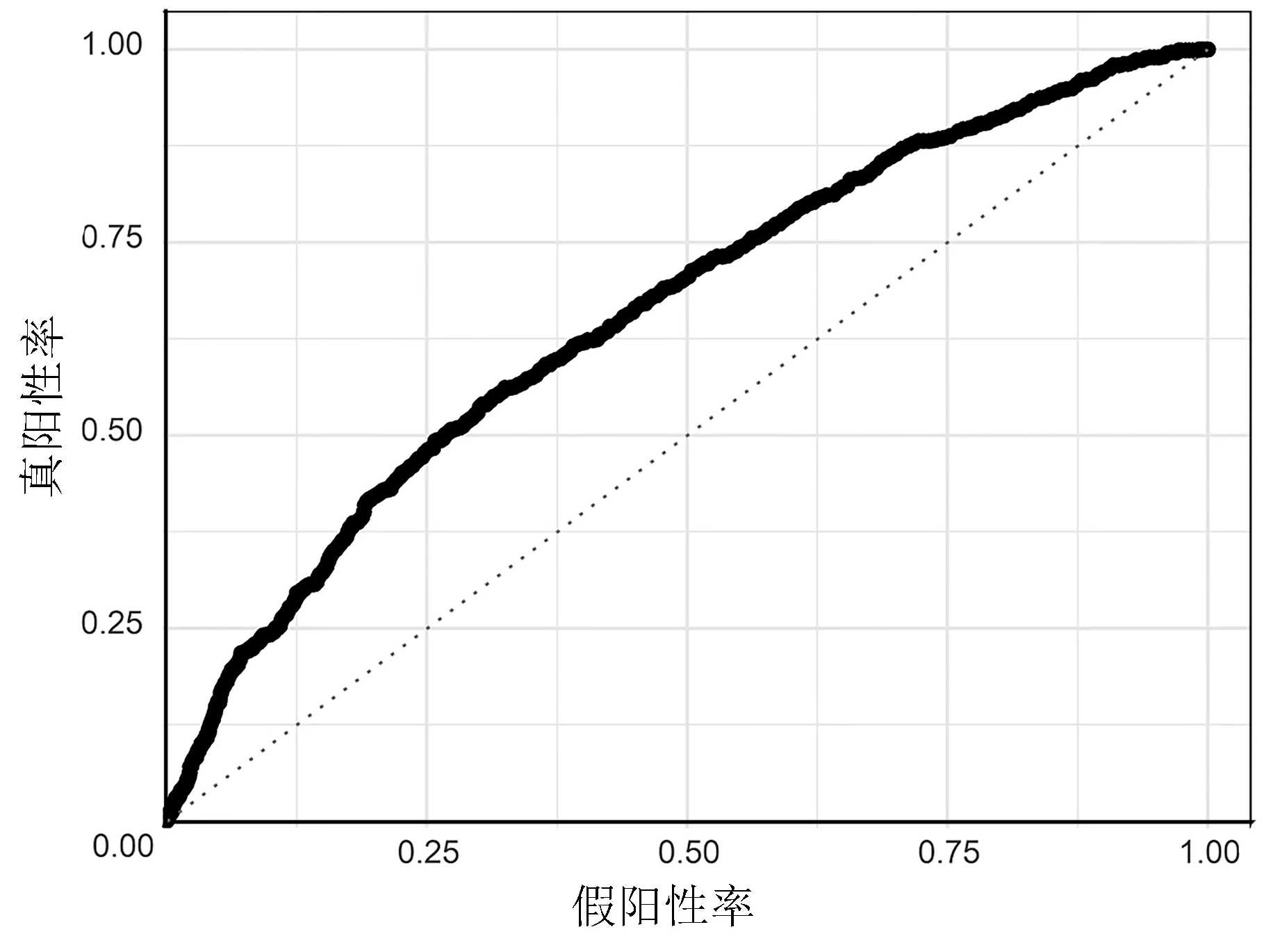
圖3 測試集的ROC 曲線圖
2.3.3 決策曲線分析 由圖4 可知,模型的決策曲線在兩條決策曲線的右上方,模型的臨床實用性優于隨機方案,較適合臨床使用,符合建模預期。
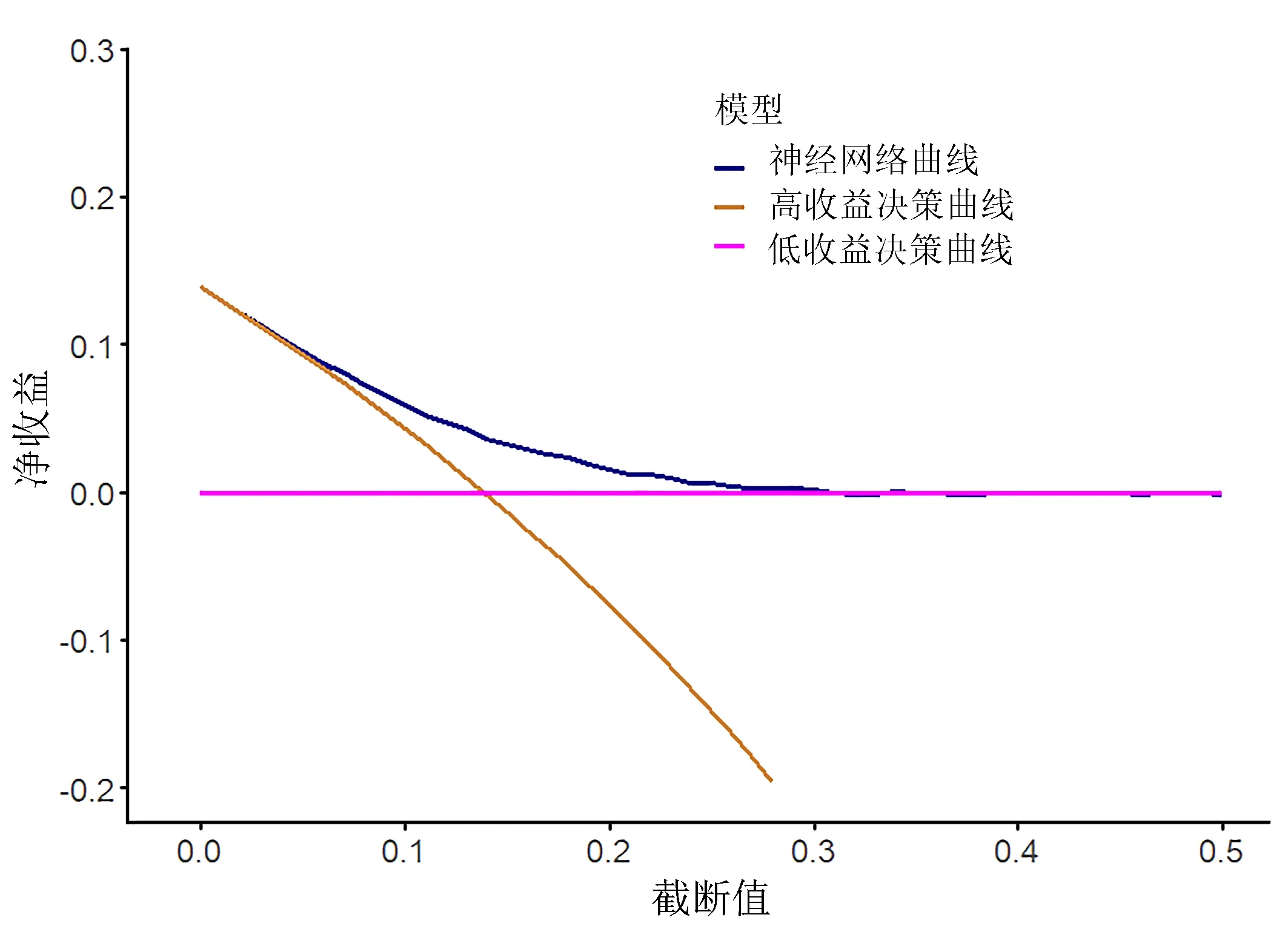
圖4 預測模型的決策曲線
3 討論
3.1 ANN 技術的特性適合IPH 的模型研究,基于大數據使其具有普適性 多元線性回歸、Logistic 回歸或Cox 回歸模型等方法是目前醫學領域中對于多變量研究常采用的建模類型。但以上方法對資料分布和類型有著較為嚴格的要求,影響其結果的適用性,有一定的局限。例如,有研究團隊對IPH 進行回歸分析下的模型研究,但其對年齡、手術類別等有較大限制,預測的準確率也有待驗證檢測[8],難以推廣。目前,新興的ANN 技術基于人工智能的深度學習理論,對資料類型和分布無特殊要求,具有良好的非線性處理能力、強大的容錯性、較高的分類精確度等優點[11]。它在分析自變量和因變量之間復雜的非線性關系時,能夠從訓練集中挖掘規律,并給出具有確定算法與結構參數的網絡結構,這對那些根本不能找到或模擬出準確數學表達公式的變量關系提供了新的思路。而醫學領域的生理病理模型,從生物內外環境的復雜性來說,是一個綜合體系,傳統回歸模型以統計和概率的方式篩選主要變量后建立函數模型,容易忽略其他次要變量隱含的影響。將ANN 技術用于IPH 的預測模型研究,可以充分利用各種變量之間的關系挖掘規律,避免了傳統回歸模型中可能存在的問題。
同時,ANN 技術的使用是基于大數據病例資料的計算,而通過大數據構建的預測模型通常其準確率和適用性都要優于小數據下的預測模型,大數據模型有更好的容錯性和普適性。本研究預測模型的準確率>75%,且適用范圍涵蓋絕大部分全身麻醉手術病人(體外循環手術除外),較已報道的預測模型[8]更具有普適性。
3.2 預測模型性能檢驗結果良好,具有實用價值 從統計結果可知,本次ANN 技術建模的結果反映此預測模型的綜合性能較好,其覆蓋范圍廣(使用局限小)、良好以上(預測準確率>75%,特異性>0.8)的性能使其推廣應用具有可行性。ROC 曲線分析結果顯示,神經網絡模型對低體溫風險預測的AUC 為0.724 3,最佳臨界點為0.175,對應特異度為0.823 0。在測試集上的AUC 為0.700 3,對應特異度為0.844 9。在臨床實用性評價方面,圖3 中預測曲線大部分完全處于兩條決策線的右上區域或重疊,說明本次建模的預測模型具有較好的臨床實用性。從以上幾個主要反映預測模型性能的指標判斷,基于ANN 技術的IPH 預測模型具有良好的性能,適合臨床使用。
3.3 本研究的意義、局限與展望 本研究使用ANN的新方法來建立IPH 的預測模型,為臨床科學預測IPH 提供了一種新的建模思路,是人工智能技術服務于臨床護理的跨領域運用。研究結果顯示,其模型具有良好的臨床使用價值,可信度較好,在普適性上優于已有的研究報道結果,能夠更加科學、有效地預測IPH的發生,為臨床護理提供指導。
由于本研究是回顧性數據分析,雖然依托于電子病歷系統和信息化技術較方便地收集了大量病例數據資料,但受限于資料完整性和監測數據收集種類,加上對于IPH 的風險因素的臨床認知和研究還未完全透徹,不能完全搜羅自然狀態下圍術期病人發生IPH 的各個變量,從而影響預測模型的準確率。隨著醫護人員對于IPH 相關問題研究的不斷深入和拓展,未來或許會發現更多的影響變量,能使構建的預測模型更接近臨床。另外,隨著信息化的普及,數據收集更加方便,數據種類更豐富,基于多中心的大數據建模也會提高預測模型的適用性。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
昆明醫科大學學報(2021年2期)2021-03-29 07:42:46
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
河北畫報(2020年10期)2020-11-26 07:20:50
數學物理學報(2020年2期)2020-06-02 11:29:24
光學精密工程(2016年6期)2016-11-07 09:07:19
中國衛生標準管理(2015年3期)2016-01-14 03:41:47
核科學與工程(2015年4期)2015-09-26 11:59:03
西南軍醫(2014年5期)2014-04-25 07:42:48
中國中醫藥現代遠程教育(2014年13期)2014-03-01 04:26:36
