基于MD&A文本和深度學習模型的財務報告舞弊識別
2022-04-03 01:25:48趙納暉張天洋
會計之友 2022年8期
關鍵詞:深度學習
趙納暉 張天洋




【摘 要】 財務報告舞弊是企業舞弊的手段之一,不僅會導致會計信息失真,而且會危害經濟的健康發展,因此,如何克服傳統的人工檢測和基于數值指標的淺層模型識別等方法的弊端,找到一種更為高效的智能化識別方法具有重要的現實意義。選取2015—2019年間存在舞弊行為的A股上市公司定期報告,以其中的管理層討論與分析章節(Management Discussion and Analysis,MD&A)為樣本,同時確定了規模相同的控制樣本,通過實證研究對比了深度學習模型和以往常用的淺層模型在檢測財務報告舞弊時的性能。結果表明,在規模對等的舞弊和非舞弊類財務報告組成的文本數據集上,深度學習模型表現出明顯優于基準模型的分類性能。研究結果為利用MD&A文本數據和深度學習方法識別企業財務報告舞弊的有效性提供了直接的證據。
【關鍵詞】 財務報告舞弊識別; 管理層討論與分析; 文本數據; 深度學習; 卷積神經網絡
【中圖分類號】 F239.1? 【文獻標識碼】 A? 【文章編號】 1004-5937(2022)08-0140-10
一、引言
由于財務舞弊可能引發嚴重的經濟和社會問題,有效識別舞弊成為會計和財務領域的研究熱點。財務報告舞弊因其發生頻率相對較低,且通常由行業內具有豐富知識和從業經驗的人實施,企業很容易掩蓋這類舞弊行為。
2021年《關于依法從嚴打擊證券違法活動的意見》提出,要依法嚴厲查處證券違法犯罪案件,加強誠信約束懲戒,強化震懾效應。上市公司財務報告舞弊現象,嚴重削弱了財務報告本身的風險預警作用。相較于耗時且昂貴的人工檢測方式,開展效率更高的自動化和智能化檢測已成為財務報告舞弊識別研究的關鍵問題。早期關于財務報告舞弊智能化識別的研究大多利用各類會計和財務指標預測企業的舞弊行為,而現實的金融市場中充斥著各種復雜的模式,僅靠一些數值指標構建的識別模型,其預測性能是相對局限的。因此,之后的研究開始逐步重視文本信息對于識別財務舞弊的作用,相當數量的研究也已證實利用定期報告中的管理層討論與分析章節(Management Discussion and Analysis,MD&A)能夠發掘部分財務報告舞弊現象[1]。
在已有研究中,利用機器學習模型對文本數據進行分類預測的方法較為流行。但傳統的機器學習模型,也稱“淺層模型”,在處理文本信息時需要借助先驗知識人工提取樣本特征,這種方式對數據含義的表達能力較弱。為了充分利用文本數據的價值,對能夠更高效地提取和利用文本信息算法的需求愈加強烈。深度學習模型作為機器學習的另一種范式,能夠自動實現特征的多次提取和變換,以實現數據更高層次的抽象表示,從而彌補了淺層模型的不足[2]。
基于此,本文采用了一種字符級卷積神經網絡[3]的深度學習算法,并結合上市公司定期報告中的MD&A文本,構建了識別財務報告舞弊的智能化模型。研究收集了2015—2019年的上市公司舞弊樣本以及同樣規模的控制樣本,利用詞嵌入層將MD&A中的文本轉換為特征矩陣,以識別具有舞弊性質的財務報告。同時,為了比較不同模型的預測性能,研究還選取了部分統計學模型和淺層模型作為基準模型。結果表明,深度學習模型利用MD&A文本識別上市公司財務報告舞弊的性能明顯優于基準模型。本文的貢獻在于,不同于以往基于淺層模型的研究,本文引入了人工智能領域興起的深度學習技術,以構建檢測舞弊的智能化模型;此外,研究還證明了財務報告這種可得性和可靠性更強的文本數據同樣具備識別企業舞弊行為的價值,可以為舞弊識別及相關研究提供新的數據支持。
二、文獻綜述
早期針對財務報告舞弊識別的研究集中在對舞弊影響因素和信號的識別上,并利用統計學模型發現違規披露行為[4],但這種方法取得的成果相當有限,可能和在選取與舞弊相關的財務指標時存在一定的主觀性有關。之后,數據挖掘和機器學習等智能化模型的應用成為舞弊識別研究的一個新趨勢。與統計學方法相比,智能化識別模型對數據的假設更少,且支持非線性決策,這些特征提高了模型的可塑性和分類性能,也使得此類模型很快得到了廣泛的應用[5]。
起初的智能化模型普遍采用數值指標,其樣本屬性有限,且選取過程存在較強的主觀性,嚴重限制了模型的預測性能。因此,研究人員開始更多地關注文本這類具有復雜性和隱藏性的非結構化數據,通過提取文本的特征以判斷它們是否能夠作為識別財務報告舞弊的信息來源[6]。由于財務報告的MD&A部分由企業的管理團隊使用通用且正式的商業語言編輯而成,涵蓋了對企業的財務狀況、經營成果和前瞻性聲明等內容的討論,也被大多數研究用作識別財務報告舞弊的文本來源[7]。本章節之后的內容主要討論基于數值和文本數據以及各類智能化模型識別財務報告舞弊的研究。
(一)基于數值數據的智能化財務報告舞弊識別
目前基于數值數據的智能化財務報告舞弊識別模型主要基于淺層模型和數據挖掘模型構建,包括神經網絡、決策樹、隨機森林、進化算法、支持向量機和混合方法等。
神經網絡主要涉及BP神經網絡、概率神經網絡、數據處理組合算法、徑向基函數神經網絡和生長分層自組織映射網絡。決策樹包括單個決策樹和決策樹的集合,如隨機森林。盡管決策樹和隨機森林模型可以處理舞弊檢測問題中的非線性特征,但訓練過程中容易出現過擬合的問題,即識別模型的泛化性能普遍較差。進化算法(如遺傳規劃和螢火蟲算法)也被用于輔助決策樹模型的設計和訓練。支持向量機能夠通過線性分類的方式解決財務報告舞弊識別這一復雜的非線性問題,而不需要增加計算的復雜度。然而,在處理噪聲較多的數據集時,支持向量機可能表現出性能不佳的問題。混合方法是利用多種模型的優勢組合而成的新模型,在針對特定的問題域時能夠表現出優于單個模型的分類性能。表1按照時間順序總結了基于數值數據實現智能化財務報告舞弊識別的研究。
(二)基于文本數據的財務報告舞弊智能化識別
目前研究所采用的文本主要包括企業披露的定期報告、新聞、金融社交媒體平臺的用戶生成內容(User-Generated Content,UGC)以及各類利益相關者提出的關于企業經營情況以及公開披露信息的分析和討論等。其中,新聞、社交媒體和各類利益相關者產生的數據包含較多噪音,而企業披露的定期報告則具有更易于處理的結構和更可靠的來源,且其中包含很多具有誤導性陳述的語言變量可以作為識別企業舞弊的依據,因而被很多研究用作識別財務報告舞弊的直接證據[16]。
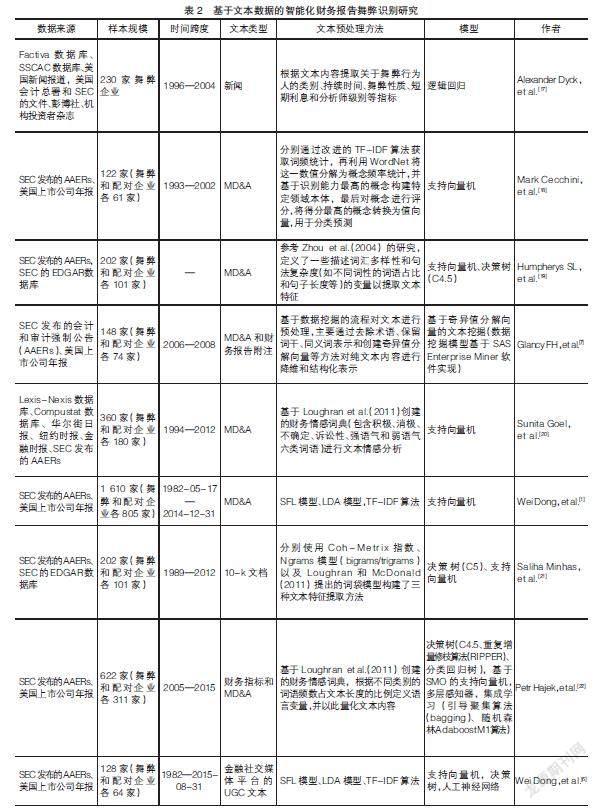
在利用文本識別舞弊性的財務報告時,需要對文本數據進行預處理。由于淺層模型不進行或只進行一次特征選擇的局限,必須借助有效的文本表示方法單獨提取文本特征,以保證下游模型的識別性能。目前研究中應用的文本表示方法大致可以分為兩類:第一類是對某些關鍵詞、關鍵詞元組或詞匯和句子特征等的統計描述。例如文本的情感分析,利用語言模型構建的文本分析框架和基于詞匯多樣性和句法復雜度等語言特征實現對文本數據的量化處理等。第二類是基于某類算法實現特定的文本格式。主要的算法類別有:(1)詞袋模型,即一種預先定義的單詞列表,能夠表示財務報告的負面性、不確定性和訴訟性的單詞列表通常與企業的舞弊行為之間存在關聯;(2)主題模型,例如LDA(Latent Dirichlet Allocation)模型,在企業舞弊的研究中常被用來提取財務報告的語義主題;(3)TF-IDF(Term Frequency-Inverse Document Frequency)算法,該算法能夠實現詞語級的文本特征提取,并基于詞語權重形成的詞向量集合表示文本集合。表2按照時間順序總結了基于文本數據實現智能化財務報告舞弊識別的研究。
(三)文獻評述
在對已有文獻的綜述中,有三點內容值得關注。首先,大多數研究運用的智能化識別方法對數據的假設更小,且允許非線性決策邊界,這些特性提高了模型的靈活性和分類性能;其次,單純使用數值指標構建智能化預測模型的局限性愈發突出,更多的學者開始關注文本這類來源廣泛且數據量龐大,同時包含更多樣本屬性的非結構化數據;最后,對于財務報告舞弊的檢測,淺層模型和數據挖掘算法只能利用數據集中存在的顯式屬性,卻很難發掘同樣存在的其他形式的隱藏屬性。而文本數據恰恰包含較多隱藏的屬性和模式,需要進一步探求更為有效的智能化識別方法。
對比淺層模型,深度學習模型的結構更為復雜,能更好地發掘數據集中存在的特征。而目前,基于文本數據識別財務報告舞弊的研究則是由淺層模型和數據挖掘模型占據主導地位,鮮有基于深度學習模型的探索。因此,本文的研究基于文本數據和深度學習算法構建識別財務報告舞弊的智能化模型,試圖探究人工智能技術是否能更有效地挖掘和利用MD&A文本中預示企業舞弊行為的潛在信號,以識別財務報告舞弊,進而檢驗深度學習方法在財務報告舞弊識別研究中的應用價值。
三、數據選取和樣本來源
我國上市公司各級監管機構的公開披露是判定上市公司是否存在舞弊行為最客觀和有效的依據之一。一方面,研究依據中國證監會、上海證券交易所、深圳證券交易所和地方證監局對上市公司的處罰報告和收錄這些披露文件的CSMAR數據庫,并按照CSMAR數據庫對處罰公告的分類,選取其中涉及虛構利潤、虛列資產、虛假記載、重大遺漏、披露不實和一般會計處理不當六類定期報告舞弊行為的公告確定為舞弊樣本。另一方面,由于2015年之前的部分定期報告將MD&A合并在董事會報告一節中未單獨披露,研究將2015年作為選取舞弊樣本的時間起點。據此,本文選取了2015—2019年存在上述舞弊行為的上市公司定期報告(包含具有MD&A章節的年度報告和半年度報告)共計454份。同時,為了保證控制樣本與舞弊樣本具有相同的規模,研究還依據中國社會科學院金融研究所等在2015—2018年發布的《中國上市公司質量評價報告》和報告中的上市公司價值管理能力排名,以及恒大研究院發布的《中國上市公司質量報告:2019》中的合規質量,選取每年排名前45的上市公司作為控制樣本,得到半年度報告和年度報告共計450份。
圖1總結了研究的分析過程,包括文本數據的選取、文本預處理、樣本特征提取、模型構建和結果評估5個部分。
四、模型構建
文本分類是自然語言處理(Natural Language Processing,NLP)領域的一個經典問題,具體指按照事先定義好的主題類別來劃分數據集中每個文本的類別。研究參考Zhang et al.[3]提出的字符級卷積神經網絡,利用上市公司財務報告中的MD&A文本,構建了一種通過文本分類方式識別舞弊性財務報告的智能化模型,并選取了部分統計學模型和淺層模型作為基準模型,以對比不同模型的分類性能。
對于輸入深度學習模型和基準模型的MD&A文本,研究采用了不同的文本預處理流程,尤其是根據淺層模型和深度學習模型各自的特點選取了不同的文本表示方法,以盡可能提升下游模型的分類性能。后面將詳細闡述深度學習模型和基準模型各自的文本預處理方法,以及深度學習模型的具體架構和實現。對于基準模型,本文只進行簡要的介紹。
(一)深度學習模型
深度學習模型的設計過程主要分為兩個階段:一是文本的預處理;二是模型的構建。
1.文本預處理
深度學習模型的文本預處理主要包括兩個步驟:一是數據集類別的劃分;二是文本字符的初步量化。
大多數基于智能化模型的財務預測研究采用了二分法的方式,即將數據集劃分為訓練集和測試集,其中訓練集通常占80%,測試集占20%。為了盡可能避免訓練階段產生的模型出現過擬合的問題,研究增加了驗證集的劃分。同時,為了保持數據劃分的一致性,避免因數據劃分過程中存在額外偏差而影響最終的結果,參照機器學習研究對小樣本集(樣本總數通常小于10 000)的劃分慣例,本文按照 的比例將MD&A文本集劃分訓練集、驗證集和測試集,且每類數據集都保持舞弊類和非舞弊類的樣本數量對等。
樣本在劃分為不同類別的數據集后還需要經過進一步的預處理:首先,去除了MD&A文本中的數字、字母、標點符號和一些特殊符號。這種對文本信息的過濾也是NLP中常用的方法,有助于降低下游分類模型的維數。其次,字符的編碼過程需要為輸入模型的文本構建一個固定規模為m的詞匯表,并采用整數對表中的每個字符進行量化,每個整數表示一個字符的ID。詞匯表通常需要覆蓋文本所包含的95%的詞匯,考慮到研究所采用的文本的字符數量,本文將m的大小設置為3 000,詞匯表會優先量化高頻字符,在達到固定規模3 000后其余的字符將被作為低頻字符過濾掉。最后,利用詞匯表將文本表示為字符的ID列表。此時,每篇MD&A文本序列的長度需要固定為l。這是因為用于訓練卷積神經網絡的張量(即表示為多維數組的數據,由詞匯表量化的文本序列再經過詞嵌入層的處理得到)必須由相同維數的矩陣組成,而每篇文本的長度不同,因此需要截斷較長的文本,同時向較短的文本添加零,這種操作也被稱為填充。研究將文本的固定長度l設置為5 000。此外,不在詞匯表中的字符也將被量化為零。
2.基于詞嵌入的文本表示
文本表示是NLP中的一個核心任務,現有的表示方法主要有離散形式的符號表示和分布式表示兩種形式。詞嵌入屬于詞語的一種分布式表示形式,能夠將詞語映射到一個數十或數百維度的實值向量中,并盡可能保留原始數據的屬性。這種方法能更好地衡量詞語之間的距離(即語義的相似性,距離上更接近的詞語便被賦予類似的表示),以便在顯著降低文本和下游模型維度的同時更好地理解文本的底層語義。
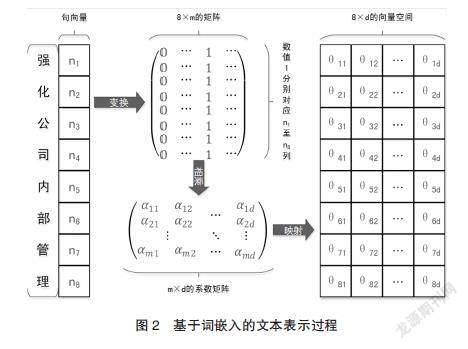
研究以截取自MD&A部分的語句為例,詳細說明基于詞嵌入的文本表示方法,具體過程可以分為4個步驟,結果如圖2所示。第一,根據研究構建的詞匯表,“強化公司內部管理”被轉換為8個整數ID構成的句向量,n1至n8分別表示字符在詞匯表中對應的整數。第二,整數ID構成的句向量被進一步轉換為獨熱編碼表示的8×m的矩陣。獨熱編碼使用稀疏的高維向量表示每個字符(維度等于詞匯表的規模m),該向量除第ni列(i=1,2,…,8)為1外,其余列均為0。第三,詞嵌入層需要訓練一個m×d的系數矩陣,d為語句最終嵌入的向量空間的維度。系數矩陣的參數aij(i=1,2,…,m;j=1,2,…,d)由隨機初始化生成,通過神經網絡模型和反向傳播算法進行訓練與更新。第四,獨熱編碼表示的語句矩陣輸入詞嵌入層后,經過系數矩陣的變換(矩陣相乘),最終被映射到一個8×d的向量空間中,表示為一個8×d的文本特征矩陣。通過詞嵌入的處理,8個字符都被表示成維度為d的向量,每個維度θij(i=1,2,…,8;j=1,2,…,d)則表示由-1到1之間的具體數值構成的特征值。
研究在卷積神經網絡的前端構建了詞嵌入層,每個由整數ID表示的字符構成且長度為l的文本向量在輸入詞嵌入層后被映射到一個l×d的向量空間中。向量空間的維度d屬于模型的參數,經過多次訓練和優化,本文將這一參數設置為64。詞嵌入層通過自訓練的方式實現,更利于針對特定數據和分類任務。
3.字符級的卷積神經網絡
本文采用了一種基于字符層面建模的卷積神經網絡來提取文本的高層抽象概念,具體架構如圖3所示,包括詞嵌入層、卷積層、池化層、全連接層以及輸出層。卷積神經網絡的核心思想是訓練多個卷積核通過卷積操作來檢測樣本的局部特征。在本文的研究中,這些局部特征可能是識別財務報告舞弊的關鍵。
經過詞嵌入層處理得到的文本特征矩陣T∈Rt×d首先被輸入卷積層(l為文本的固定長度,d為向量空間的維度)。卷積核C∈Rh×d的行數h(即長度)為5,列數d與文本特征矩陣的維度同為64。每個卷積核都會從上到下依次與5行64列的文本矩陣塊做卷積操作,卷積核每次下移的幅度為步長1。每次卷積操作得到的特征可以表示為:
其中,Ti:i+h-1表示由第i個到第i+h-1個字符向量組成的文本矩陣塊,b為偏置項,f(x)為ReLU激活函數。每個卷積核通過卷積計算共能得到l-h+1個特征,由此組成的特征圖可以表示為:
研究共構建了256個卷積核,因此能夠得到256張特征圖。
卷積層提取的特征圖依然具有較高的維度,需要經過池化層的處理,以進一步提取特征和過濾文本信息。研究采用全局最大池化的方法,以每張特征圖為單位,通過選取其中最大的特征值并舍棄其他特征值的方式再一次實現局部特征的提取。
池化層從每張特征圖中提取的局部特征會輸入全連接層進行非線性組合。研究對全連接層的神經元進行了隨機失活(Dropout)處理,即在每輪迭代的過程中隨機使一部分神經元失活(比例設置為0.5),從而減少特征的冗余,防止模型出現過擬合問題。此外,研究還采用ReLU(Rectified Linear Unit)激活函數對全連接層神經元輸出的結果進行非線性變換。
最終,由softmax分類器構成的輸出層會根據全連接層輸入的結果生成每個樣本的分類標簽(舞弊和非舞弊),從而完成文本分類的過程。
4.模型的具體實現
研究基于TensorFlow的架構構建深度學習模型,模型的權重使用高斯分布進行初始化。由于CNN是一種典型的前饋神經網絡,需要利用反向傳播算法完成模型的訓練,損失函數則選擇了交叉熵損失函數。由于完整的訓練集規模較大,耗用的計算資源較多,不利于模型的訓練。因此,研究采用批尺寸為64,且經過Adam算法優化的隨機梯度下降方法(Stochastic Gradient Descent,SGD)進行參數調優,學習率設置為0.0001(過低會導致參數更新速度緩慢,過高則可能跳過局部最小值點)。SGD也是對標準BP算法的一種優化。由于目標函數可以分解在不同的子集上進行計算求和,通過將訓練集劃分為多個較小的子樣本集,可以使SGD算法一次只在一個批次上更新參數(包括詞嵌入層和卷積層的權重矩陣)。樣本的訓練采用10輪迭代的方式,并在模型性能無法改善的情況下使用提前停止方法終止訓練過程。
(二)其他基準模型
研究選取了一些統計學模型和淺層機器學習模型,并以此為基礎對深度學習模型進行了基準測試。統計學模型包括邏輯回歸和樸素貝葉斯模型,淺層模型則包含支持向量機、隨機森林和兩類梯度提升決策樹的變體模型(XGBoost和LightGBM)。基準模型基于scikit-learn機器學習庫提供的方法構建。
1.文本預處理
研究基于同樣的MD&A文本集訓練基準模型,并利用五折交叉驗證方法實現模型的訓練和測試。數據集在進行文本表征和特征提取前依然需要先移除文本中的數字、字母、標點符號和一些特殊符號,保留純文本內容,再完成去除停用詞和分詞處理。研究參照哈爾濱工業大學開發的中文停用詞表去除文本的停用詞,并選用jieba中文分詞工具實現分詞處理。
文本的表示形式和特征提取過程基于卡方檢驗和TF-IDF算法。卡方檢驗的核心思想是通過觀測實際值與理論值的偏差衡量假設是否正確。基于這一原理,在對MD&A文本進行特征選擇時,本文將“特征詞與財務報告舞弊不相關”作為原假設,以提取文本的特征詞匯。具體的計算方法如下:
其中,N表示文本總數,A和B分別表示特征詞在舞弊類和非舞弊類文本中出現的頻率,C和D則分別表示特征詞在舞弊類和非舞弊類文本中不出現的頻率。根據上述的計算方法,研究提取了文本集中的前1 000個詞作為特征詞。
考慮到這些特征詞在文本分類中的重要性,利用詞頻-逆文本頻率(Term Frequency-Inverse Document Frequency,TF-IDF)算法來賦予特征詞不同的權重。基于TF-IDF算法,特征詞的權重可以表示為:
其中,j表示文本,k和l表示文本類別,tfijk表示特征詞i在k類j文本的詞頻,N表示文本總數,n表示包含特征詞i的k類文本總數。由此,由卡方檢驗提取的特征詞表示的MD&A文本被進一步轉換為TF-IDF權重表示的文本向量。
2.統計學模型和淺層模型
邏輯回歸是智能化舞弊識別研究中最常用的模型,它利用一系列輸入向量、一個相關的響應變量以及自然對數來計算回歸結果在特定類別內的概率。對于舞弊識別這種二元分類問題,響應變量可以表示為:
計算MD&A文本所屬類別的公式為:
除了邏輯回歸,本文還采用了另一種統計學中常用的數據分類模型,即樸素貝葉斯(Naive Bayesian,NB)模型。NB算法基于貝葉斯原理,假定MD&A文本的特征向量為,文本屬于某一類別ci的概率為條件概率P(ci),模型的訓練過程就是利用訓練集統計先驗概率P(ci)和特征dj(N為樣本包含的特征數)在類別ci(i={0,1})中出現的概率。具體的計算方法可以表示為:
研究選取的淺層模型包括支持向量機、隨機森林和決策樹,這些模型都是財務預測的研究中最常用的智能化模型。支持向量機通過將樣本空間映射到一個高維的特征空間中,使得很多復雜的非線性問題能夠通過線性分類的方式解決。本文選擇了RBF函數作為支持向量機模型的核函數;隨機森林是一種包含多個決策樹的分類模型,會隨機選擇特征集中的n個特征,每棵樹都對樣本集采用Bootstrap抽樣的方法確定自身的訓練集;此外,研究還構建了兩種梯度提升決策樹(Gradient Boosting Decision Tree,GBDT)的變體模型:XGBoost和LightGBM。GBDT是一種集成學習模型,能基于決策樹實現分類和回歸。模型的訓練過程由多輪迭代完成,每輪迭代產生一個弱學習器,并基于上一輪迭代的殘差進行訓練,通過不斷減小殘差來提高分類精度,直至達到最優。
五、實證結果
(一)模型評估
構建一個具有較好的樣本外預測能力的財務報告舞弊識別模型對本文的研究至關重要。對于深度學習模型和基準模型,研究都采用精確率(Precision)、召回率(Recall)和F1分數(F1-score)三類評價指標衡量模型在測試集上的分類性能。
精確率表示模型預測出的舞弊類樣本中被正確預測的比例,召回率則表示所有的舞弊類樣本中被正確預測的比例。精確率和召回率可以分別表示為:
其中,TP(即真陽性(True Positive,TP))表示被模型預測為舞弊樣本且本身也為舞弊樣本的MD&A文本;FP(即假陽性(False Positive,FP))表示被模型預測為舞弊樣本而本身為非舞弊樣本的MD&A文本;FN(即假陰性(False Negative)),表示被模型預測為非舞弊樣本而本身為舞弊樣本的MD&A文本。F1分數是統計學中常用來衡量模型二分類性能的一種指標,可以表示模型的精確率和召回率的一種調和平均值,具體表示為:
這三類指標的值均介于0和1之間,越接近1表示模型的分類性能越好。然而,以上三類指標的計算過程均假定舞弊類文本為正樣本,而非舞弊類文本為負樣本。為了綜合考察模型在不同類別上的分類性能,研究還引入了宏平均(Macro-Average)的方法,即對舞弊類和非舞弊類樣本分別作為正樣本時得到的評價指標值求算術平均值。
(二)實證結果及分析
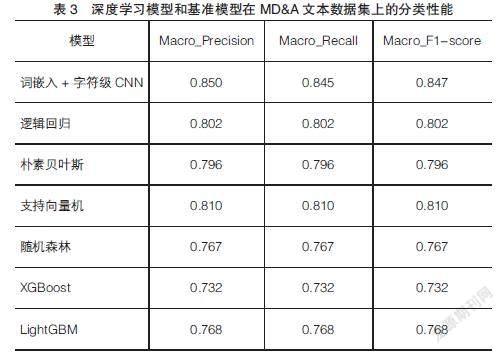
表3和表4分別總結了利用上市公司定期報告中的MD&A文本訓練的深度學習模型和基準模型在樣本外數據集上的預測結果(評價指標采用宏平均后的數值),以及深度學習模型在不同類別上的預測性能。深度學習模型的架構基于詞嵌入模型和一種字符級的卷積神經網絡,基準模型則選取了兩類統計學模型(邏輯回歸和樸素貝葉斯模型)和三類淺層模型(支持向量機、隨機森林和梯度提升決策樹)。根據表3和表4列示的各項評價指標,研究的實證結果可以總結為以下四點:第一,研究所實現的模型,無論是深度學習模型還是其他基準模型,評價分類性能的指標值均大于0.7,表明模型能夠有效利用MD&A中的文本信息進行財務報告舞弊識別;第二,深度學習的各項分類性能均顯著高于其他基準模型,表明相較于傳統智能化財務報告舞弊檢測研究所采用的模型,本文構建的深度學習架構能更好地識別具有舞弊性質的財務報告;第三,邏輯回歸、樸素貝葉斯和支持向量機模型的各項指標均在0.8左右,顯著高于其他決策樹類的模型,表明基于小樣本(樣本數小于1 000)的文本數據集進行財務報告舞弊識別時,邏輯回歸、樸素貝葉斯和支持向量機模型具有更好的預測性能;第四,深度學習模型在兩類MD&A文本集上的評價指標值均大于0.82,表明模型在不同類別的數據集上均表現出較好的舞弊識別能力。
六、結論與啟示
財務報告作為公開披露的信息,直接反映了企業的運營狀況,因此也成為了企業實施舞弊行為的重要媒介。有效識別財務報告舞弊成為規范金融市場運行秩序的重要手段之一。利用深度學習技術在NLP領域取得的各項突破,本文構建了用于識別上市公司財務報告舞弊的字符級卷積神經網絡模型,該模型采用財務報告中的MD&A文本作為分析樣本。結果表明,在淺層模型具有明顯優勢的小樣本數據集上,不需要經過復雜的文本特征定向提取,字符級卷積神經網絡模型依然能夠表現出更優越的分類性能,這一結果也為利用深度學習技術改進現有的財務報告舞弊識別方法提供了直接的證據。此外,研究不僅證明了深度學習模型在識別財務報告舞弊上的優勢,而且所構建的各類模型在MD&A文本上均表現出較好的預測性能,這體現了企業披露的公開文本所具有的效用和信息價值。同時,財務報告的文本披露作為一種可靠性強且易于獲得的數據來源,可以為相關研究提供很好的數據支持。
本文涉及到的很多內容值得進一步探究。首先,深度學習模型和其他使用非結構化數據的人工智能系統類似,訓練擬合出的卷積神經網絡模型是一個黑箱。深入挖掘和分析模型訓練過程中提取的文本局部特征,有利于揭示表明企業存在舞弊行為的財務報告文本的本質;其次,研究只采用了MD&A文本作為訓練數據的唯一來源,而目前依然存在大量的非結構化數據源源不斷地注入金融市場,利用更多不同來源的文本數據可能有助于提升深度學習模型在企業舞弊識別中的性能;最后,研究所涉及的詞嵌入方法和字符級的CNN模型只是深度學習技術的冰山一角。僅就NLP而言,深度學習還存在大量的新興技術值得深入研究,例如知識圖譜、注意力機制、Transformer等文本表示方法,循環神經網絡、自編碼器、受限玻爾茲曼機、對抗生成網絡和強化學習等深度學習的基礎架構,以及基于這些架構及其變體模型組合而成的混合模型等。總之,本文發掘了基于文本數據的深度學習模型在財務和會計預測研究中的部分價值,更多的應用價值值得后續的研究進一步探索。
【參考文獻】
[1] DONG W,LIAO S,LIANG L.Financial statement fraud detection using text mining:a systemic functional linguistics theory perspective[C].Proceedings of the Pacific Asia Conference on Information Systems (PACIS),2016.
[2] 胡越,羅東陽,花奎,等.關于深度學習的綜述與討論 [J].智能系統學報,2019,14(1):1-19.
[3] ZHANG X,ZHAO J,LECUN Y.Character-level convolutional networks for text classification[C].Proceedings of the Advances in Neural Information Processing Systems,2015.
[4] 張莉.基于國家治理的上市公司舞弊審計實證檢驗 [J].財會月刊,2018(6):20.
[5] MAI F,TIAN S,LEE C,et al.Deep learning models for bankruptcy prediction using textual disclosures[J].European Journal of Operational Research,2019,274(2):743-758.
[6] DONG W,LIAO S,ZHANG Z.Leveraging financial social media data for corporate fraud detection [J].Journal of Management Information Systems,2018,35(2):461-487.
[7] GLANCY F H,YADAV S B.A computational model for financial reporting fraud detection[J].Decision Support Systems,2011,50(3):595-601.
[8] 皇甫冬雪.基于Lib-SVM的損益調整類財務報告舞弊識別模型研究——來自中國證券市場的證據[J].會計之友,2011(25):75-79.
[9] RAVISANKAR P,RAVI V,RAO G R,et al.Detection of financial statement fraud and feature selection using data mining techniques[J].Decision Support Systems,2011,50(2):491-500.
[10] PAI P-F,HSU M-F,WANG M-C.A support vector machine-based model for detecting top management fraud[J].Knowledge-Based Systems,2011,24(2):314-321.
[11] HUANG S-Y,TSAIH R-H,YU F.Topological pattern discovery and feature extraction for fraudulent financial reporting[J].Expert Systems with Applications,2014,41(9):4360-4372.
[12] CHEN S,GOO YJ J,SHEN ZD.A hybrid approach of stepwise regression,logistic regression,support vector machine,and decision tree for forecasting fraudulent financial statements[J/OL].The Scientific World Journal,2014.
[13] PRADEEP G,RAVI V,NANDAN K,et al.Fraud detection in financial statements using evolutionary computation based rule miners[C].Proceedings of the International Conference on Swarm,Evolutionary,and Memetic Computing,2014.
[14] KIM Y J,BAIK B,CHO S.Detecting financial misstatements with fraud intention using multi-class cost-sensitive learning [J].Expert Systems with Applications,2016,62:32-43.
[15] 馮炳純.基于數據挖掘技術的財務舞弊識別模型構建[J].財會通訊,2019,805(5):93-97.
[16] XING F Z,CAMBRIA E,WELSCH R E.Natural language based financial forecasting:a survey [J].Artificial Intelligence Review,2018,50(1):49-73.
[17] DYCK A,et al.The corporate governance role of the media[J].The Journal of Finance,2008,63(3):1093-1135.
[18] CECCHINI M,AYTUG H,KOEHLER G J,et al.Making words work:using financial text as a predictor of financial events[J].Decision Support Systems,2010,50(1):164-175.
[19] HUMPHERYS S L,MOFFITT K C,BURNS M B,et al.Identification of fraudulent financial statements using linguistic credibility analysis [J].Decision Support Systems,2011,50(3):585-594.
[20] GOEL S,UZUNER O.Do sentiments matter in fraud detection? Estimating semantic orientation of annual reports [J].Intelligent Systems in Accounting,Finance and Management,2016,23(3):215-239.
[21] MINHAS S,HUSSAIN A.From spin to swindle:identifying falsification in financial text [J].Cognitive computation,2016,8(4):729-745.
[22] HAJEK P,HENRIQUES R.Mining corporate annual reports for intelligent detection of financial statement fraud a comparative study of machine learning methods[J].Knowledge Based Systems,2017,128(6):139-152.
猜你喜歡
中國教育技術裝備(2016年19期)2016-12-27 19:23:52
中國遠程教育(2016年11期)2016-12-27 18:07:31
現代商貿工業(2016年25期)2016-12-26 09:58:02
江蘇教育·中學教學版(2016年11期)2016-12-21 11:45:08
江蘇教育·中學教學版(2016年11期)2016-12-21 11:36:29
現代情報(2016年10期)2016-12-15 11:50:53
考試周刊(2016年94期)2016-12-12 12:15:04
新教育時代·教師版(2016年23期)2016-12-06 06:02:38
法制與社會(2016年32期)2016-12-01 15:25:53
軟件導刊(2016年9期)2016-11-07 22:20:49
