基于集成MQHOA和支持向量機的相關反饋圖像檢索
2022-04-15 08:56:52王華秋
重慶理工大學學報(自然科學) 2022年3期
王華秋,劉 倩
(重慶理工大學 兩江人工智能學院, 重慶 401135)
隨著計算機和多媒體技術發展,信息的種類、規模迅速增加。圖像為信息的重要載體,因此,如何從海量的圖片庫中快速、準確檢索出與用戶查詢主觀含義一致的圖像,已成為國內外研究者的研究熱點。圖像檢索主要分為基于文字的圖像檢索(text-based image retrieval,TBIR)和基于內容的圖像檢索(content-basedimageretrieval,CBIR)2個方向。前者的檢索技術已發展得非常成熟,但海量圖像的產生將消耗大量伴隨著較強主觀性的人工標注工作,并且已無法滿足人們對圖像檢索系統與日俱增的需求。90年代以后,基于內容的圖像檢索技術逐漸發展起來[1-5],然而傳統的基于內容的圖像檢索技術無法避免“語義鴻溝”的問題。針對此問題,不少研究者以基于距離度量學習方式[6-8]替換傳統單一的相似度度量方式,還提出多種特征表示方法[9-13],尤其是近年來深度學習技術廣泛應用于CBIR任務提取圖像高層語義特征。
這些技術仍然無法很好地貼合用戶查詢的主觀含義,為此,相關反饋技術(relevance feedback,RF)被大量引入到CBIR任務中,如醫學圖像識別、衛星影像分類等[14-15],通過用戶與系統多次交互,獲取用戶的偏好信息,使檢索結果更符合用戶需求。近期已有大量RF問題的方法被提出:不少研究者結合深度學習技術和相關反饋技術獲得了更好的檢索精度[16-17],但是未能很好地利用反饋信息。Wang等[18]設計了自適應權重檢索系統,驗證了特征權重估計的有效性;Tzelepi等[19]改進了基于NN范式的相關反饋算法,但它們的重點工作是區分好壞特征,使好特征具有更高權重,容易陷入局部最優。為降低用戶的操作復雜度,反饋的樣本往往較小,訓練的樣本的正負反饋樣本通常不均衡,為了解決這幾個問題,Broilo等[20]將期望最大化參數應用于基于SVM分類的相關反饋圖像檢索中;Arevalillo-herráez等[21]提出了一種半監督主動學習算法,將未標記的圖像融入學習以構建更好的分類模型;Kanimozhi等[22]提出了一種基于特征重構的支持向量機相關反饋算法,利用了基于協方差矩陣的核經驗正交互補分量分析;Razavian等[23]通過卷積神經網絡結合用戶反饋重新訓練全連接層,但這些方法不能很好地利用特征空間中的未知區域,即沒能充分利用用戶反饋的信息,無法滿足用戶的檢索需求。針對上述問題,近年來不少研究者已將優化算法結合RF技術應用于CBIR任務中:Yandex等[24]和Gordo等[25]分別構建粒子群與遺傳算法優化器來跟蹤用戶的檢索偏好,但它們都易滯于局部最優。Filip等[26]用螢火蟲算法集SVM算法于RF技術,達到較好的檢索性能,但未充分利用反饋信息,且參數復雜,檢索時間長。
綜上,現有方法存在參數繁多,不滿足檢索實時性需求,無法充分利用反饋信息以探索特征空間等問題。為此,本文將查詢點移動建模成一個優化問題,通過引入多尺度量子諧振子算法(MQHOA)在特征空間中探尋更優查詢點,利用其需設參數少,不易陷入局部最優解,能快速收斂等優點,再將其與SVM算法結合,數輪后將圖像檢索視為圖像二分類任務,同時繼續探索未知相關區域。為解決樣本不均衡等問題,采用SVM間隔帶TOP-K算法,利用前幾輪反饋的圖像信息對訓練集進行有效篩選,可獲得更好分類效果。實驗表明,在用戶反饋過程中,利用MQHOA能對特征空間進行有效搜索,引入SVM后,大部分圖像已被標記為相關時仍能對未知的特征空間進行有效探索,該方法結合兩者的優勢,使反饋信息與特征空間點的相關性最大化,能有效提高圖像檢索的性能,檢索到更多相關圖像。
1 基于MQHOASVM-RF算法的圖像檢索
1.1 特征描述與距離模型
圖像特征提取工作對于圖像檢索任務非常重要,近年來許多研究者已成功將卷積神經網絡應用于圖像特征提取工作[27-30],由卷積層和池化層可以構成一個通用性較強的特征提取器,能夠提取圖像中高度抽象性的深層特征。Su等[30]研究證明,VGG16模型比其他常見模型具有更強的可遷移學習能力,Babenko等[31]通過實驗發現,fc7特征相比fc8特征在不同的數據集中具有更強的泛化能力。因此,采用預訓練的VGG16模型,提取其fc7層1 024維圖像特征,為了降低檢索復雜度的同時不損失圖像特征質量,通過奇異值分解求解特征向量協方差矩陣的特征值和特征向量,選取前128個特征值對應的特征向量為圖像特征,從而將VGG16網絡提取的4 096維特征降維為128維,實驗表明,此情況下的特征仍優于傳統方式提取的特征[32-33]。
由于特征向量內不同特征分量的物理意義不同,為保證各特征分量在相似度匹配加權時處于相同地位,將特征進行z-score標準化:
(1)
式中:q=[x1,x2,x3,…,x128];xi表示第i個特征分量;σ表示圖像集特征的標準差;μ表示圖像集特征的均值。
為減小計算復雜度,圖像相似度模型以余弦距離為基礎,計算方式如下:
(2)
式中:Q、qi分別表示檢索圖像和被檢索圖像的特征向量;F={q1,q2,q3,…,qn},表示圖像集特征集合。
1.2 種群初始化和適應度函數確定
將圖像檢索建模成一個優化問題,與經典優化問題的一個重要區別是,需要優化的對象是從每次用戶反饋中收集而來。若僅考慮用戶標記的相關的圖像,如果展示給用戶的相關圖像數量較少,那么停滯的風險就非常高,所以綜合考慮用戶反饋的相關與不相關圖像信息,將第k輪查詢向量定義為式(3)。
Qk=α*Q0+β*relfk-γ*irrfk
(3)
其中,relf與irrf計算方式如下:
(4)
(5)
其中,v計算方式如下:
(6)
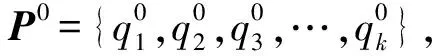
(7)
其中,qi∈XREL,qj∈XIRR,NREL表示XREL大小,NIRR表示XIRR大小,Qk表示查詢向量。適應值越小,表明該特征點更遠離不相關圖像在特征空間中的區域,更靠近相關圖像在特征空間中的區域,即每輪反饋所尋特征點為:
(8)
1.3 訓練集篩選
訓練集對于SVM分類器構造十分重要,設計SVM間隔帶TOP-K算法,其旨在篩選靠近SVM間隔帶的圖像作為訓練集。如果將圖像檢索視為二分類任務,則圖像庫中的圖像僅分為2個集合:與圖像相關的圖像集合,與圖像無關的圖像集合,它們在數目上相差懸殊。運用相關反饋技術,對檢索結果進行標記,檢索結果中已經標記為不相關的圖像,為與圖像無關的圖像集合中最靠近檢索圖像的圖像,所以它們靠近SVM間隔帶;而已經標記為相關的圖像,是與圖像相關的圖像集合中最靠近檢索圖像的圖像,因此這些圖像遠離SVM間隔帶。基于以上分析,如果用所有反饋圖像信息作為訓練集,無法訓練出理想的超平面,若出現樣本不均衡問題,分類效果將進一步降低。本文充分利用相關反饋圖像集(相關圖像集與不相關圖像集),訓練集選擇不相關圖像集中最靠近檢索圖像的K個圖像,以及圖像庫中除去反饋圖像集后離檢索圖像最遠的K個相關圖像。
為了進一步保障訓練集的質量,考慮采用多距離結合方式選擇TopK圖像。其基本思路如下:
1) 采用VGG16模型提取圖像特征,除前文提到的余弦距離模型,同時引入以下幾種相似度度量模型對圖像集合與檢索圖像進行距離度量:
曼哈頓距離模型:
(9)
歐式距離模型:
(10)
2) 以加權思想分析以上距離模型的度量結果:針對度量結果分別按不同的距離模型以升序排序,即排列越靠前,越靠近檢索圖像。每幅圖片在所有距離模型中排序的序號之和視為該圖像的權重,最后再依據圖像權重排序,選擇排列于前K的圖像。
1.4 算法流程
前幾輪反饋中,主要包括MQHOA算法優化查詢點、用戶反饋2個過程,隨后將伴隨SVM圖像二分類過程。本文圖像檢索系統算法流程如圖1所示。

圖1 基于MQHOASVM的相關反饋圖像檢索系統算法流程框圖
2 圖像數據集及參數設置
2.1 圖像查詢集
為驗證算法的有效性,選擇UC Merced Land-Use遙感數據集作為測試圖像集,其中UC Merced Land-Use數據集共有21類遙感圖像,每類100幅圖。從UC Merced Land-Use數據集中每個類別隨機選取5幅圖片組成105幅圖像查詢集。
2.2 對比算法
為了驗證算法的檢索效果,選取以下算法作為對比算法進行比較:
MQHOASVM-RF與PSOSVM-RF分別表示以MQHOA與PSO算法修改查詢特征以及以反饋信息作為SVM訓練集構造分類器集成的檢索算法,PSO算法參數c1=c2=2,ω=0.7。
MQHOA-RF與PSO-RF[23]分別表示基于MQHOA與PSO算法修正查詢特征點的相關反饋圖像檢索算法。
SVM-RF表示結合用戶反饋信息,采用TOP-K篩選間隔帶附近的圖像作為訓練集構造分類器,將圖像檢索視為二分類問題,每輪將分類結果展示給用戶。
QV-RF[16]表示不使用優化算法修正查詢特征點的相關反饋圖像檢索算法,采用固定的α、β、γ值。
為保證實驗公平性,本文算法、PSOSVM-RF、MQHOASVM-RF與MQHOA-RF,優化算法的種群大小為30。所有算法每輪反饋圖像數目N=50,反饋次數取10,所有實驗在Intel(R)Core(TM)i5-9500CPU、16G內存,windows10系統64位操作系統上完成,圖像檢索系統由MATLABR 2020a編寫。
2.3 評價指標
為了評估算法有效性,選取如下評價指標:查準率、查全率,其計算公式分別如下:
(11)
(12)
式中:S(i)表示第i輪反饋時展示圖像中相關圖像的數量;N表示展示給用戶的圖像數;Nq表示該類圖像在圖像查詢集中所有相似圖像數量。
3 實驗及結果分析
由于優化算法是隨機算法,公平起見,本文算法、PSOSVM-RF、MQHOASVM-RF、PSO-RF和MQHOA-RF重復運行5次取平均值與另外2種算法進行對比。不同方法在查詢集上的檢索精度如圖2所示。
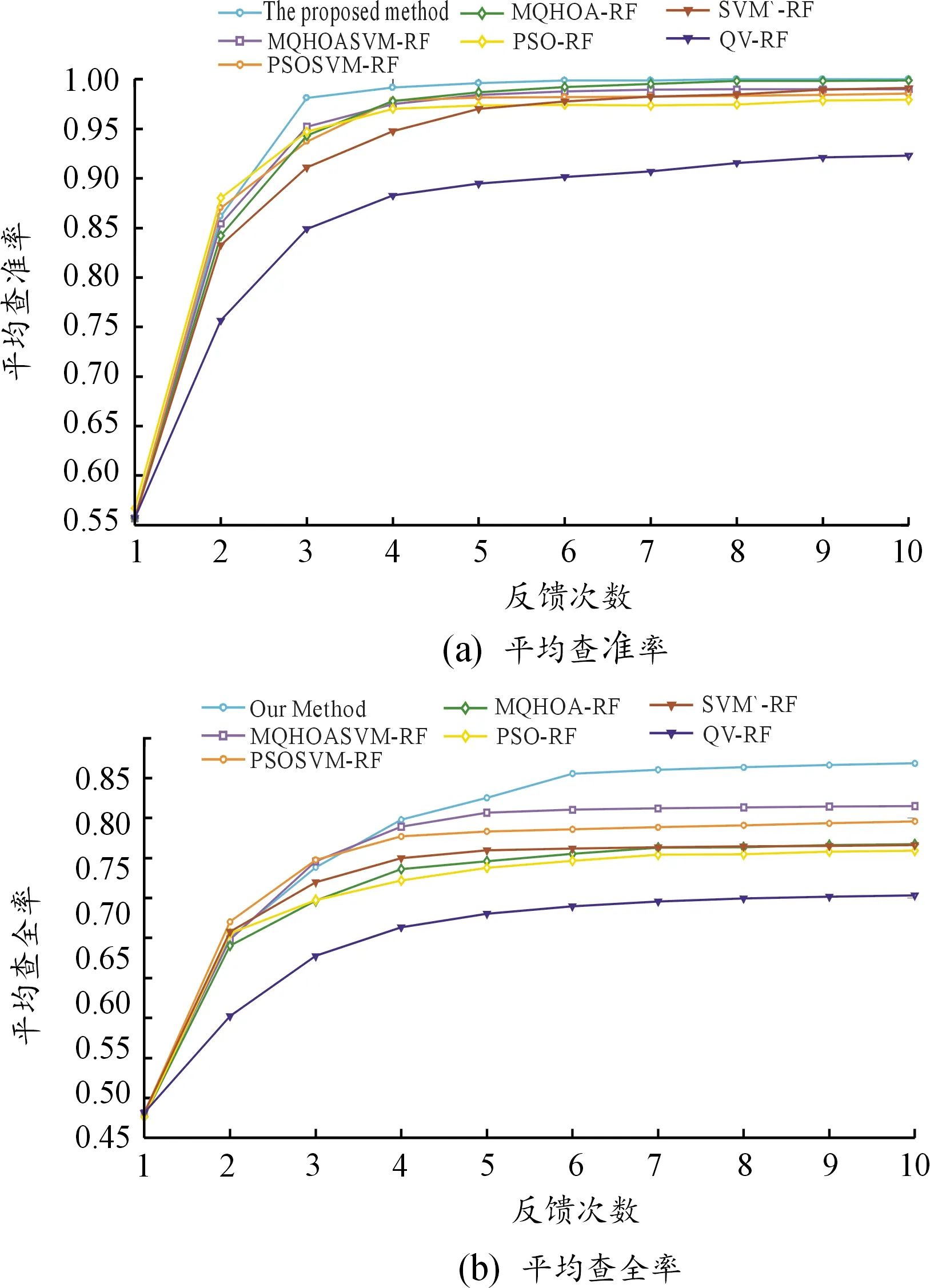
圖2 不同方法在查詢集上10輪反饋的檢索精度曲線
由圖2(a)可知,與SVM-RF相比,MQHOASVM-RF與本文算法分別在其基礎上結合了MQHOA算法,所以不易滯于當前特征區域,能對特征空間進行有效搜索,從而不斷靠近理想查詢點,在后幾輪反饋中查準率仍不斷提升,PSOSVM-RF結合了PSO算法,容易陷入局部最優,后期檢索精度略低于MQHOASVM-RF和本文算法。由圖2(b)可知,相比其他算法,MQHOASVM-RF、PSOSVM-RF與本文算法的查全率顯著高于其他算法,可見集成優化算法與SVM算法的檢索系統具有較好的檢索精度。集成算法里,未篩選訓練集的算法由于訓練樣本小、不均勻等問題造成了分類器及特征在前期比較穩定,在后期最高適應度對應最佳參數不變,導致在后幾次反饋里查準率幾乎不再增長,分類效果差。兩輪反饋后,本文算法對訓練集進行了有效篩選,得到更優的超平面,使得分類效果更顯著,查準率高于MQHOASVM-RF與MQHOA-RF,查全率遠高于其余算法。
由于本文算法、MQHOASVM-RF與MQHOA-RF的查準率都顯著高于其余對比算法,為了進一步驗證所提算法的有效性,圖3為在第5輪反饋時3種算法在UC Merced Land-Use查詢集上7個類別的檢索精度。這些類別在數據集中包含分別與之特征相似度較高的類別,比如高爾夫球場和棒球場特征相似度較高,河流和森林的特征相似度較高。由圖3(a)可見,3種算法用于上述類別圖像的檢索,仍能取得良好的查準率,對于高、中密度住宅區,本文算法表現更突出。由圖3(b)可知,本文算法在大部分類別中的查全率均顯著高于其余2種算法。
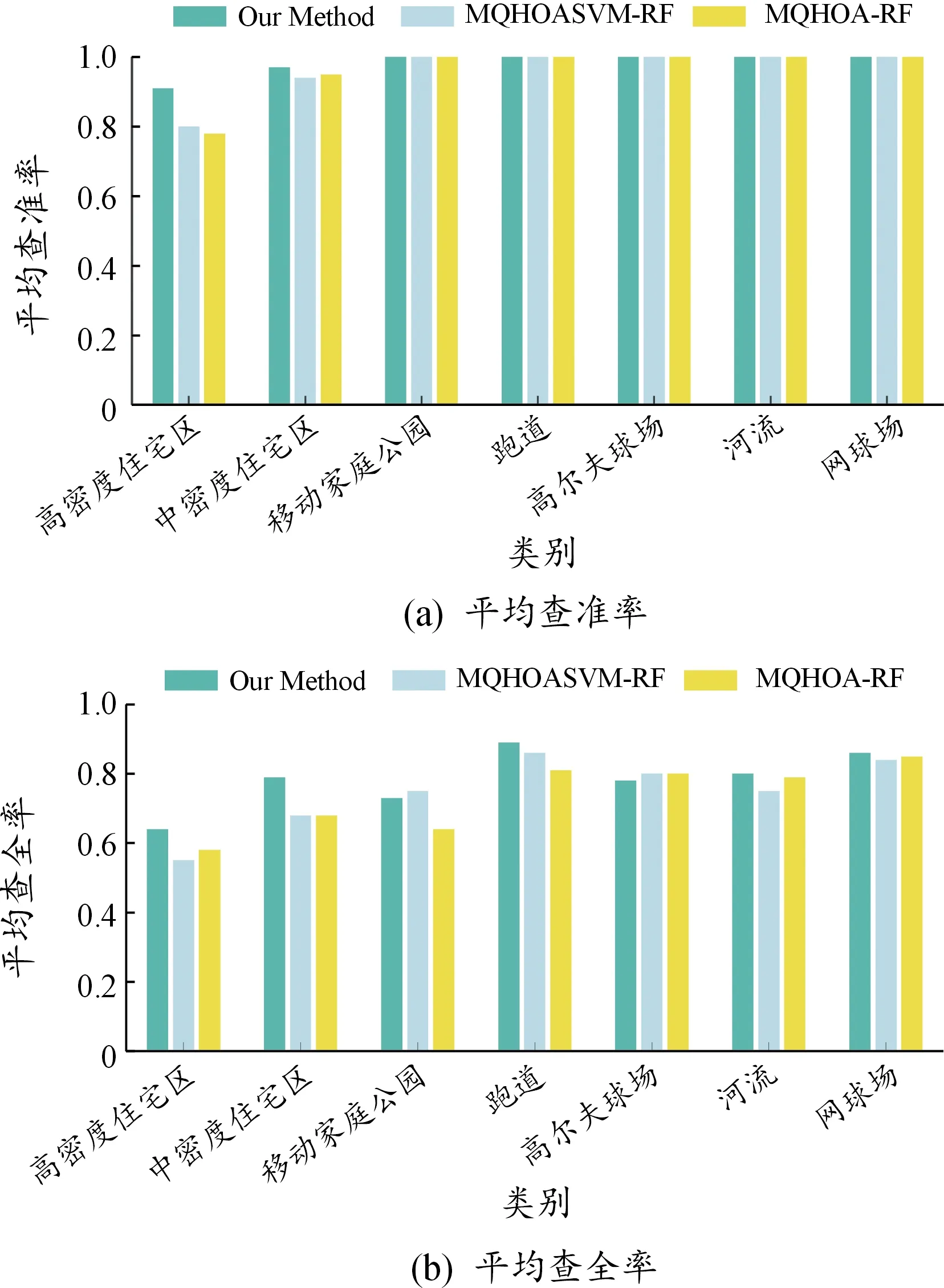
圖3 不同類別遙感圖像上第5輪反饋的檢索精度直方圖
大部分圖像已相關的情況下,查全率決定了其能否進一步探索空間,為了進一步對比上述3種算法的檢索相關圖像的能力,表1列舉了本文算法(1),MQHOASVM-RF(2)以及MQHOA-RF算法(3)在上述7個類別上的平均查全率。其中1~7類分別表示高密度住宅區、中密度住宅區、移動家庭公園、跑道、高爾夫球場、河流和網球場類別。由表1可知,MQHOASVM-RF與MQHOA-RF在后面幾次反饋里無法繼續對特征空間進行有效搜索。而本文算法不容停滯于特征空間中的某一區域,能不斷探索出新的相關圖像區域,對特征空間進行有效搜索。
高密度類別圖像上各算法的平均查全率如圖4所示。

表1 UC Merced Land-Use查詢集7類的平均查全率
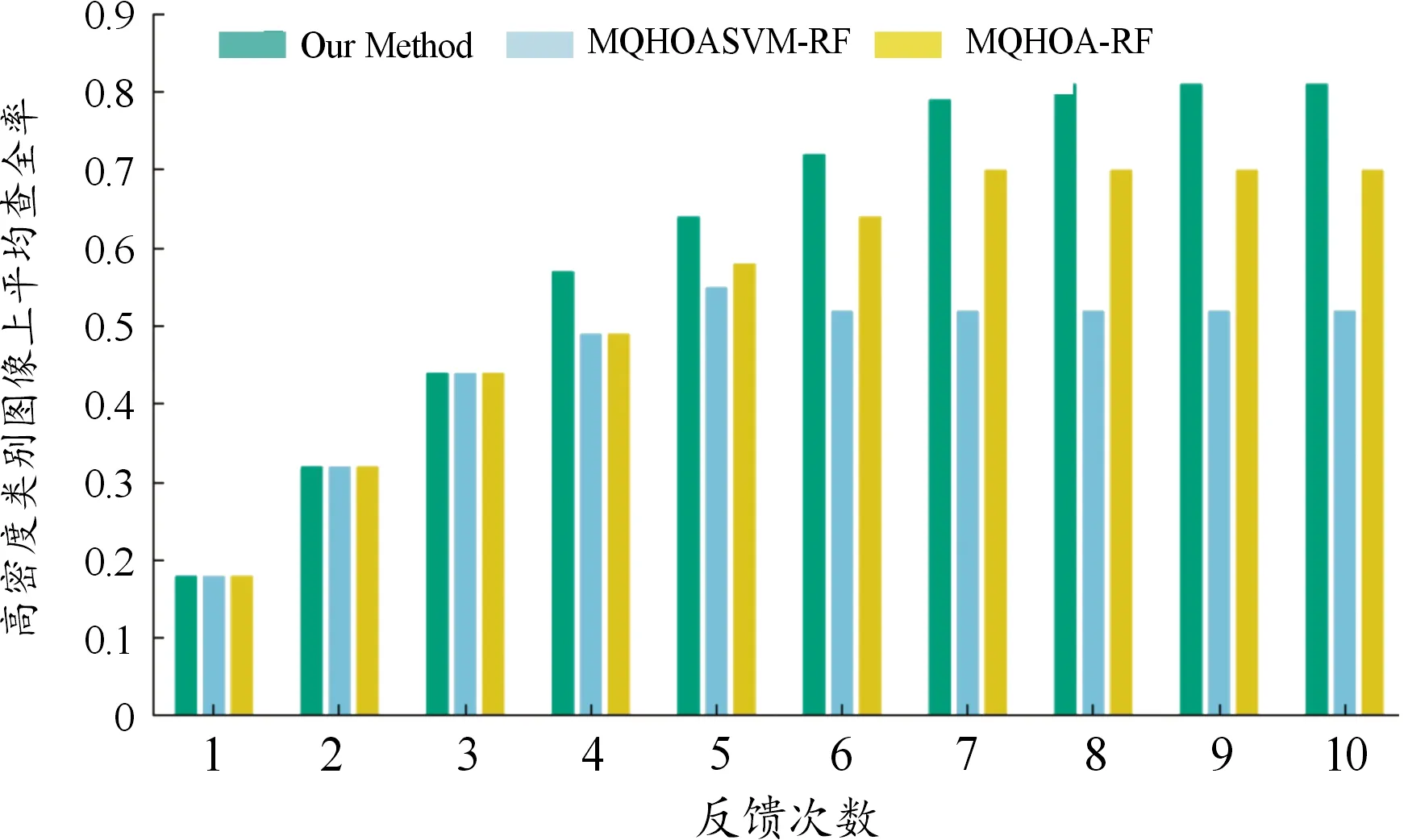
圖4 高密度類別圖像上各算法的平均查全率直方圖
隨著圖像集規模逐漸增大,檢索效率也成為圖像檢索系統的重要評判標準,圖5為上述算法分別在查詢集10輪反饋的平均時間。由于沒有優化過程,QV-RF耗時最短,其次是MQHOA-RF。MQHOASVM-RF、PSOSVM-RF與本文算法均集成了2種算法,耗時高于其他幾種算法,由于PSO所有粒子需要不斷迭代來更新自己,所以PSOSVM-RF檢索耗時最長。由于對訓練集的有效篩選,本文算法效率高于其余幾種集成算法。綜合考慮檢索精度與檢索效率,本文算法能有效提升系統的檢索性能。

圖5 不同算法平均檢索速度直方圖
4 結論
針對現有相關反饋圖像檢索系統需設參數多、無法充分利用用戶反饋信息對特征空間進行有效搜索、檢索性能低等問題,利用遷移學習提取圖像深層特征,引入SVM算法應用于基于MQHOA算法修正查詢特征點的圖像檢索系統中,并依據用戶反饋信息對訓練集進行有效篩選,保證對特征空間的有效搜索,從而獲得更高的檢索性能。在UC Merced Land-Use遙感數據集上的實驗結果可證明本算法能有效提升檢索性能,尤其是在特征相似度較高的類別上,檢索精度顯著高于其他方法。下一步的工作就是進一步提升系統的檢索效率,將提出的算法應用到更多領域的大型圖像庫中。
猜你喜歡
數學小靈通·3-4年級(2024年2期)2024-05-15 02:02:28
世界科學技術-中醫藥現代化(2020年2期)2020-07-25 02:05:36
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
商用汽車(2016年11期)2016-12-19 01:20:16
商用汽車(2016年6期)2016-06-29 09:18:54
商用汽車(2016年4期)2016-05-09 01:23:12
創業家(2015年10期)2015-02-27 07:55:08
創業家(2015年10期)2015-02-27 07:54:39
