基于DDPG的無人機追捕任務泛化策略設計
2022-04-22 13:43:42符小衛徐哲王輝
西北工業大學學報 2022年1期
符小衛, 徐哲, 王輝
(西北工業大學 電子信息學院, 陜西 西安 710129)
隨著無人機性能的提升,其在戰場上發揮的作用也將不單單是戰場偵查與監視,更多的應該是執行對地攻擊、防空火力壓制、空戰格斗任務,逐步完成從常規的偵察平臺到作戰平臺的轉換[1]。無人機間的攻防對抗是新型智能空戰的主要作戰樣式,引起了各個國家軍隊和學者的關注。空戰對操控的實時性要求很高,需要完成對無人機準確、實時的操控,提升無人機的智能化水平刻不容緩,也是未來軍用無人機能否成為戰場主力的關鍵[2]。
追逃對抗問題是無人機攻防對抗的核心問題[3],指的是具有利益沖突雙方無人機之間的博弈。其中,追捕無人機通過追捕戰術機動使逃逸無人機進入到自己的火力攻擊范圍內,逃逸無人機通過規避戰術機動策略,逃離敵機的火力攻擊區。
當前對無人機追逃對抗策略研究,主要是通過微分對策法[4]、專家系統法[5]、影響圖決策法[6]等,但這些方法存在的缺點是獲得解析解的難度比較大、靈活性不足、適用性有限。機器學習中的深度強化學習結合了深度學習強大的感知能力和強化學習的試探學習能力,可以讓無人機的決策系統具備自學習的特點[7]。
目前,深度強化學習技術已經被用于無人機的任務決策和運動決策問題。張耀中等[8]基于DDPG算法研究了無人機集群對敵方來襲目標的協同追擊問題,設計了針對具體追擊任務的一種引導型回報函數,經訓練后無人機集群能較好地完成協同追擊任務。陳燦等[9]針對不同機動能力的無人機間攻防對抗問題,基于集中評判-分布執行的多智能體強化學習算法,研究了多無人機協同攻防自主決策的方法,為多無人機系統對抗提供新的研究思路。在對目標的追蹤問題上,史豪斌等[10]嘗試將視覺伺服控制與強化學習結合,利用Sarsa學習算法訓練使得旋翼無人機自主調節視覺伺服增益,驗證了該方法相對于PID控制與基于圖像的視覺伺服控制方法具有更好的追蹤效果。蘇治寶等[11]在未知環境下利用Q-learning算法實現多移動機器人圍捕移動目標,給出具體設計方案并驗證影響圍捕效果的因素。深度強化學習技術在無人機控制技術的落地應用證明了其應用于無人機的追捕對抗機動決策的可行性。對這些文獻分析可知,所研究的任務較為單一,而對多種機動策略的敵機追捕任務不能有效遷移,因此需要研究一種對于不同逃逸策略的敵機可泛化的有效適用方法。
本文以無人機追逃對抗問題為研究背景,基于DDPG算法建立了無人機追逃對抗的數學模型和優化目標,訓練無人機學習追逃對抗策略;在研究的基礎上,設計多種逃逸無人機的對抗機動策略,基于課程學習思想的訓練方式,逐步提高逃逸無人機的智能程度從而遞進式地訓練無人機的追捕對抗策略。所提出的訓練算法能夠成功訓練出泛化性強的無人機追捕對抗策略,能夠追捕不同對抗機動策略的敵機。
1 問題描述與建模
1.1 單無人機追逃對抗問題
針對追逃博弈問題,建立有控制約束的二局中人零和微分博弈模型。無人機追逃的幾何模型如圖1所示。

圖1 二維平面追逃博弈幾何模型
圖1中,P,E分別代表追捕無人機和逃逸無人機,vP,vE分別指追捕無人機和逃逸無人機的速度大小,ψP,ψE分別指追捕無人機和逃逸無人機的航向角,規定航向角逆時針為正方向,δ為目標視線(line of sight,LOS)的夾角視線角,目標視線指追捕無人機P指向逃逸無人機E的射線。追捕無人機的目標是以最短的時間捕獲目標,逃逸無人機的目標是遠離追捕無人機,避免在預設時間段被捕獲或者最大化延遲被追捕無人機捕獲的時間,追逃博弈標準微分博弈數學描述為公式(1)和(2)。
minTc=f(vP,ψP,vE,ψE,L)
(1)
maxTc=h(vP,ψP,vE,ψE,L)
(2)
式中:L為追逃雙方的距離;Tc是追捕無人機P捕獲逃逸無人機E的時刻。公式(1)、(2)分別為追捕無人機和逃逸無人機的優化目標函數。
1.2 無人機運動學模型
無人機的運動學方程為公式(3)。
(3)
式中:ωi表示無人機的角速度;ai表示無人機的加速度大小。無人機的運動控制變量約束為公式(4)。
(4)
式中:vPmin,vEmin是雙方無人機的最小速度;vPmax,vEmax是雙方無人機的最大速度;aPmax,aEmax是雙方無人機的最大加速度;ωPmax,ωEmax是雙方無人機的最大角速度,規定角速度為正值表示航向角逆時針變化,即航向角增大。
無人機初始狀態為公式(5)。

(5)
敵我距離在追捕無人機的捕獲范圍內,即為捕獲成功,如(6)式所示。捕獲范圍lc可以是無人機的載荷作用范圍或者武器攻擊范圍。
dPE≤lc
(6)
式中,dPE是追捕無人機與逃逸無人機的距離。
2 基于DDPG的無人機追捕策略
在用DDPG算法解決無人機追逃對抗問題時,首先需定義無人機的狀態空間、動作空間、獎勵函數。本節先具體介紹模型設計過程,再介紹DDPG訓練算法。
2.1 模型設計
2.1.1 狀態空間
設定無人機攜帶機載GPS設備和陀螺儀,可以獲得自身的位置信息和速度信息即ξP=[xP,yP,vP,ψP];攜帶機載脈沖多普勒火控雷達載荷設備,能獲得探測目標的位置信息和速度信息ξE=[xE,yE,vE,ψE]。
為了增加算法的適應性,減小神經網絡的輸入處理負擔,聚焦于策略優化,本文使用相對位置關系來建立狀態空間模型,其表達式如公式(7)所示。
S=[αP,αE,αPE,dPE,vP,ΔvPE]
(7)
式中:αP,αE分別是追捕無人機和逃逸無人機速度方向與目標視線LOS(由追捕無人機位置指向逃逸無人機的向量)的夾角;αPE是追捕無人機速度方向與逃逸無人機速度方向的夾角;ΔvPE是指追捕無人機與逃逸無人機的速度大小差,其計算如公式(8)所示。
ΔvPE=vP-vE
(8)
2.1.2 動作空間
如公式(3)和(4)所示,無人機的控制輸入為一個二維向量,即動作空間
A=[ai,ωi](i=P,E)
(9)
2.1.3 狀態轉移方程


(10)
2.1.4 回報函數
本文回報函數的設計采用稀疏回報和引導型回報函數相結合的方式,如公式(11)所示。
(11)
式中:rt代表無人機總獎勵;rt1是設計的引導型獎勵回報,為追逃雙方的距離變化回報,即只有當雙方距離變小時追捕無人機獲取正獎勵;dt,dt-1分別代表t和t-1時刻追捕無人機和逃逸無人機的距離,k是比例系數;rt2表示追捕無人機離逃逸無人機過遠的稀疏獎勵;rt3表示追捕無人機完成任務的稀疏獎勵,定義分別為公式(12)和(13)。
(12)
式中,Dfar表示相對距離閾值,如果相對距離超過閾值,則認為追捕無人機離逃逸無人機過遠,給予無人機負回報Rfar。
(13)
式中:lc的物理意義同公式(6),當追捕無人機完成對逃逸無人機的捕獲任務,給與無人機正回報獎勵Rfinish。
2.2 DDPG算法
DDPG算法是由DeepMind團隊提出的,并在連續動作空間下經驗證取得了很好的效果。它是基于Actor-Critic(AC)算法框架,采用DQN中經驗回放機制和雙網絡結構進行改進,是一種深度確定性策略梯度算法[12]。
DDPG框架主要包括環境、存放樣本的經驗池、actor網絡模塊及critic網絡模塊。強化學習中智能體通過與環境的不斷交互產生樣本數據,將這些樣本存入到一個經驗池中,在經驗池中采用隨機策略抽取一定數量的樣本(mini batch samples)來訓練網絡參數。為了提高算法的學習效率,DDPG算法采用雙網絡結構,無論是actor網絡還是critic網絡,都包含eval網絡和target網絡,2個target網絡與eval網絡對應,是一對結構完全相同的神經網絡,eval網絡會在每步訓練更新網絡參數(θu,θQ),而target網絡參數(θu′,θQ′)則定期通過軟更新方式復制eval網絡參數,更新公式如(14)式所示。

(14)
式中,τ為軟更新系數,一般取0.01。同時為了提高智能體對環境的探索能力,需要在actor中的eval網絡輸出動作μ(st),增加隨機噪聲N。一般設定動作噪聲服從正態分布,即公式(15)。
N~N(μ,σ2)
(15)
取μ=0,σ隨著迭代步數的增加逐漸減小,降低對環境的探索性,同時無人機不同于其他模型,需要考慮無人機的機動性能約束,因此最終動作a是經過噪聲和機動約束限定后的實際動作,如公式(16)所示。
a=f(πθ(S)+N)
(16)
式中,f為無人機動作約束函數,其定義參考公式(17)。
(17)
actor網絡與critic網絡使用不同的損失函數進行訓練。在使用批數據時,critic網絡的損失函數,如公式(18)所示。
(18)
式中:K為批數據的樣本個數;Q(si,ai|θQ)為eval網絡評價當前時刻狀態與actor中的eval網絡生成動作的價值;yi的定義如公式(19)所示。
yi=r(ri,ai)+γQ′(si+1,μ′(si+1|θu′)|θQ′)
(19)
式中:r(ri,ai)為當前時刻狀態執行動作ai后的即時獎勵;γ為獎勵衰減系數;Q′(si+1,μ′(si+1|θu′)|θQ′)為target網絡評價下一時刻狀態st+1和actor中的target網絡對下一時刻狀態所選動作μ(si+1)的價值。
critic網絡的參數更新如公式(20)所示。

(20)
式中:αQ是critic網絡的學習率;actor網絡的參數更新如公式(21)所示。

(21)
式中,αu是actor網絡的學習率。
3 基于課程學習的DDPG算法流程
3.1 基于課程學習的訓練方法
深度強化學習存在的問題是無人機在學習復雜任務時訓練算法收斂比較慢,原因是樣本探索效率比較低。本文利用課程學習方式,提高樣本探索效率,增快訓練算法的收斂速度。課程學習是指機器學習任務中逐漸增加任務難度以增快學習速度的方法。課程學習核心思想是需要逐步調整學習的任務分布,智能體更容易在簡單任務中獲得獎賞回報,先選擇相對簡單的任務進行策略學習,然后將策略遷移到復雜任務上,能夠有效降低復雜任務的探索難度[13]。
本文針對無人機追逃對抗決策問題,設計了基于課程學習核心思想的訓練方法,訓練方法總共分為3個步驟,具體如表1所示。3個步驟中不同的是逃逸無人機的機動決策方式,逃逸無人機的智能程度呈現遞增。在DDPG的訓練過程中通過不斷提高逃逸無人機的決策模型智能程度進而設置從簡而難的學習任務,遞進式地訓練無人機的追捕對抗策略,能夠有效提升模型的泛化性。
運用DDPG算法學習訓練之前,需要無人機與環境進行交互,獲取大量的實驗數據作為訓練樣本。本文實驗雙方無人機的初始位置和速度在設定的范圍內服從均勻分布,隨機產生作為各自初始狀態,追捕無人機根據actor策略網絡輸出并經過動作限制處理得到控制動作信號,而逃逸無人機依據表1的步驟選擇自身逃逸策略,雙方無人機根據當前狀態及動作信息,利用公式(10)更新計算得到下一時刻的狀態,然后追捕無人機獲得環境反饋的立即獎勵,這樣一個追捕無人機與環境的交互經驗[st,αt,rt,st+1]就產生,存入經驗池中,等待無人機與環境交互一定的步數后,按照隨機抽樣方法抽取一定數量的樣本,進而對4個網絡的參數按公式(20)、(21)和(14)進行更新。在等待經驗池填滿時候開始訓練。
3.2 DDPG離線算法訓練流程
本文實驗中,控制周期設置為仿真步長。需要注意的是,狀態st和αt的下標t代表時間步而不是實際飛行時間,實際飛行時間為T=tΔT。基于DDPG的無人機追捕機動策略訓練算法流程如下所示:
1.初始化存儲量大小為M的經驗池D
2.初始化actor網絡和critic網絡的策略網絡eval:μ(s;θu)和Q(s,a|θQ);
將eval網絡的參數拷貝給對應target網絡:θu′←θu,θQ′←θQ
actor網絡和critic網絡的目標網絡target初始化完成:u(s;θu′)和Q(s,a|θQ′)
3.For episode=1 to MaxEpisode do
4. 初始化OU過程N(t)
5.在設定范圍內隨機初始化追捕無人機、逃逸無人機初始狀態,獲得仿真環境初始狀態s0
6.Fort=1 to MaxStep do
7.通過狀態st選擇追捕無人機動作at=fclip(u(st|θu)+Nt),Nt是OU隨機噪聲,fclip表示動作限制處理過程(超過約束范圍采取邊界值)
8.根據訓練方式為逃逸無人機選擇機動策略,決定機動動作
9.將控制信號輸入到仿真環境中的無人機中,積分得到下一步時間無人機狀態,計算得到環境狀態st+1
10.同時得到環境的立即回報
11.將經驗樣本[st,at,rt,st+1]存儲在D中
12.從D中隨機抽樣得到大小為BatchSize的樣本集{[st,αt,rt,st+1]}
13.更新critic動作網絡的策略網絡eval參數θQ
14.更新actor動作網絡的策略網絡eval參數θu
15.更新2個網絡中target網絡參數θQ′,θu′
16.If滿足回合結束機制,Break
17. End For
4 仿真驗證
4.1 實驗驗證
實驗采用圖1場景想定,同時采用常見的紅藍對抗作戰法,設定紅方為追捕無人機,藍方為逃逸無人機。仿真環境全部基于Python語言編寫,利用Pycharm Community 2020.2和Anaconda3平臺,深度學習環境采用Tensorflow 1.14.0,計算機配置為CPU Inter i7-9700F@3.00GHz,內存16 GB。
實驗設定的訓練超參數介紹如下:折扣因子γ取0.9,經驗池M大小取30 000,抽取樣本數取64,actor和critic網絡學習率分別取0.001和0.002,單次回合最大時間步取300,總共訓練4 000回合,仿真步長取0.1。實驗環境參數如表2所示。

表2 無人機追逃對抗仿真實驗參數
actor網絡的target網絡和eval網絡采用單隱層的前饋神經網絡,每層神經元個數為[6,128,2],隱藏層采用relu(x)作為激活函數,輸出層采用tanh(x)作為激活函數,讓智能體的輸出動作限定在一定的范圍內;critic網絡也采用單隱層的前饋神經網絡,網絡輸入為無人機的狀態與actor網絡生成的動作,所以其target網絡和eval網絡每層神經元個數為[8,128,1],隱藏層采用relu(x)作為激活函數,輸出層采用tanh(x)作為激活函數。訓練使用Adam Optimizer作為網絡參數的優化器。
4.2 方法有效性實驗
本文定義4種不同的訓練方式,4種學習訓練方式前3種分別只采用表1的3種學習訓練方式,第4種則采用課程學習的方式。第4種訓練方式訓練時,步驟1先基于第1種訓練方式訓練追捕無人機的機動決策網絡,然后將訓練好機動決策網絡的參數(網絡權值、閾值)進行遷移,然后步驟2利用第2種訓練方式再次訓練追捕無人機的機動決策網絡,同理步驟3以第3種訓練方式再次訓練追捕無人機的機動決策網絡。
4.2.1 訓練過程
本文采用平均獎勵指標觀察所設計訓練算法的訓練情況和收斂情況,定義每100回合的平均總獎勵作為統計值,開始不足100回合時使用僅有所有回合總獎勵的平均值。
如圖2a)~2c)所示,分別為第1種、第2種、第3種學習訓練方式下DDPG算法的平均獎勵曲線,橫坐標表示訓練回合數,縱坐標表示每個回合相應的平均獎勵(每100回合的總獎勵值平均)。從圖中可以看出,當只采用單一訓練方式時,DDPG訓練算法會在500回合內穩定收斂。
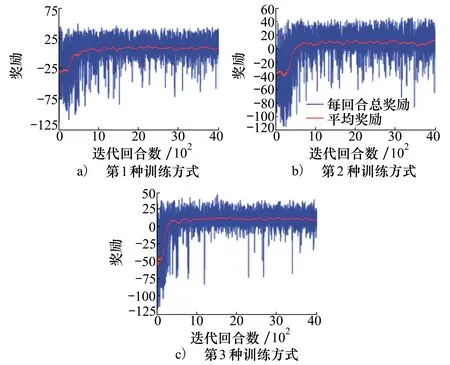
圖2 單一訓練方式平均獎勵曲線圖
深度強化學習訓練的策略網絡一般只適用于具體特定的環境,而在現實環境下,逃逸無人機的對抗機動策略可能隨時改變,而訓練好的機動決策網絡執行的效果可能不佳,適用性較差,這也是強化學習普遍存在的模型泛化性缺點。而本文針對此問題,首先在一個簡單的環境中預先訓練機動決策網絡,而當環境逐漸復雜,在面對不同智能程度的逃逸無人機時,將適用于簡單環境的策略遷移到該任務上來,進行一次重訓練,而不用從隨機初始化的網絡參數開始,從而降低在復雜任務上的訓練難度,這也是第4種訓練方式的目的所在。它的本質是根據逐漸復雜的樣本分別,逐步調整學習網絡的參數,以適用于更為復雜的學習任務。
為了表現基于課程學習的訓練方法的優勢,將第4種訓練方式中步驟2和步驟3的平均獎勵曲線分別和第2種訓練方式、第3種訓練方式的平均獎勵曲線圖2b)、圖2c)進行對比,如圖3a)~3b)所示。

圖3 第4種訓練方式平均獎勵曲線圖
在圖3a)和圖3b)都表明了在已經訓練好的網絡參數上再進行新環境(逃逸無人機的逃逸對抗策略不同)的重訓練,相比于直接在新環境上從零開始的訓練,都更快取得了算法收斂效果。
4.2.2 驗證過程
為了進行充分的仿真測試,本文分別對4種訓練方式得到的訓練結果進行試驗。追逃雙方無人機的初始位姿、初始速度均隨機產生,逃逸無人機采用經典的逃逸策略機動,共進行10 000次蒙特卡洛測試。測試的數據結果如表3所示,分別包含追捕任務的成功率、捕獲時間、平均獎勵。

表3 4種訓練方式測試結果
從表3可以看出,在表格每一列中,用加粗字體標出了每列的最值(平均獎賞和成功率為最大值,捕獲時間為最小值),第4種訓練方式基于課程學習的DDPG算法訓練流程取得了最大的平均獎賞、成功率和最短的捕獲時間,可見基于課程學習的DDPG算法取得了最好的訓練效果和魯棒性。
設置相同的實驗設定,無人機追逃對抗過程的仿真如圖4~7所示。從圖4~7的a)圖可以看出,4種訓練方式都使得追捕無人機能夠在一定程度上實現了追捕逃逸無人機的效果。而圖4~7的b)圖可以看出,在設置相同的實驗初始條件下,由于訓練時設定敵機的逃逸策略分別為第1種(固定航向勻速直線的逃逸策略)和第2種(隨機運動的逃逸策略)方式,與實驗時敵機的逃逸策略(采用經典逃脫策略)不同,因此取得了較差的結果(第1種雙機距離最終不穩定,追捕效果極差,第2種雙機最終距離(28 m)也較遠)。第3種訓練和試驗時的敵機的逃逸策略均相同,因此相較前2種,雙機最終距離(26 m)有所減小。而本文設計的第4種采用課程學習的訓練方式所訓練的決策網絡使得追捕無人機的追捕能力有了一定的提升,相較于前3種取得了較好的追捕效果,雙機的最終距離(22 m)進一步減小。

圖4 第1種訓練方式對戰飛行軌跡和測試結果 圖5 第2種訓練方式對戰飛行軌跡和測試結果

圖6 第3種訓練方式對戰飛行軌跡和測試結果 圖7 第4種訓練方式對戰飛行軌跡和測試結果
綜上所述,第4種訓練方式,基于課程學習的思想,通過逐漸提升逃逸無人機的逃逸對抗策略智能程度,設置任務從簡到難,應用時取得了不錯的戰術效果,具有一定的魯棒性。
5 結 論
本文針對空戰中無人機追逃博弈問題,基于DDPG算法設計了無人機的追捕對抗策略。利用課程學習的訓練方式,在DDPG的訓練過程中逐漸提升逃逸無人機的智能程度,遞進式地訓練無人機的追捕對抗策略,研究的主要結論為:
1) 仿真表明了所設計的模型經過DDPG算法的學習能夠達到穩定收斂,使得追捕無人機能夠較好地追捕具有多種策略的逃逸無人機,成功率均達到95%以上。
2) 針對逐步提升智能程度的逃逸無人機,基于課程學習的訓練方法,相較于前3種對簡單任務直接訓練的方法,能夠快速收斂;并能夠適用于多種對抗機動策略的敵機,有效地提升了無人機追捕對抗決策模型的泛化性,為無人機執行較難任務的研究提供了新的思路。
下一步工作主要是研究如何簡化基于課程學習的訓練過程,以及將研究工作擴展到三維空間。
猜你喜歡
教學考試(高考化學)(2021年2期)2021-05-30 06:15:52
動漫界·幼教365(大班)(2021年4期)2021-05-23 21:33:16
中學生數理化·高一版(2020年3期)2020-04-21 08:03:20
中學生數理化(高中版.高考理化)(2020年2期)2020-04-21 05:32:50
小學生作文(低年級適用)(2019年9期)2019-10-08 08:37:10
小學生作文(低年級適用)(2018年3期)2018-04-17 00:58:35
數學大世界(2018年1期)2018-04-12 05:39:14
少年博覽·小學低年級(2017年4期)2017-06-09 16:22:28
作文周刊·小學一年級版(2016年28期)2017-06-03 00:28:49
作文評點報·低幼版(2017年7期)2017-03-11 20:49:41
