基于深度強化學習的網絡路由優化方法
2022-06-25 13:04:22孟泠宇郭秉禮張欣偉趙柞青黃善國
系統工程與電子技術 2022年7期
孟泠宇, 郭秉禮,*, 楊 雯, 張欣偉, 趙柞青, 黃善國
(1. 北京郵電大學電子工程學院, 北京 100876; 2. 信息光子學與光通信國家重點實驗室, 北京 100876)
0 引 言
目前,隨著光通信技術、大數據以及云計算的高速發展,網絡的規模逐漸擴大其豐富的應用也不斷出現,用戶的需求也是日新月異,通信網絡正經歷著爆發式的流量增長。傳統的路由優化方法通常需要提前收集大量的網絡的流量信息,并根據這些流量計算路由策略最后進行路由配置。基于最短路徑算法的傳統路由優化方法在整個路由計算的過程中非常耗時,存在收斂緩慢等問題并且需要巨大的網絡資源開銷。傳統優化方法最大的不足是對于網絡實時復雜的變化情況無法及時做出調整,泛化能力較弱。當網絡流量呈指數級增長,不同業務產生的流量也使得網絡流量狀態越來越多樣化,依靠人工和傳統方法來運維現有復雜的網絡環境導致其承載上的業務性能惡化嚴重。在此背景下,對網絡路由優化的性能和收斂速度都提出了更高的要求。因此,智能化、自動化是網絡控制的必然選擇。
隨著軟件定義網絡(software defined network, SDN), IPv6, IPv6+等技術的發展,業界致力于實現算力網絡與IP網絡的融合、云網融合等全新的架構,但現在還存在許多技術難題:如何實現最優的路由、如何最優地分布算力、如何保障算力的服務質量。這都需要借助人工智能等技術克服難題,但目前相關研究也還處于初級階段。近些年來,機器學習成為了人工智能發展的熱門領域,尤其是在大數據處理、聚類以及智能決策方面有著不錯的表現。隨著 AlphaGo在圍棋大戰中擊敗李世石使得深度強化學習(deep reinforcement learning, DRL)引起了學術界重視,這樣的趨勢也指導著人們使用機器學習來控制和運營網絡。很多人工智能的方法被用在了路由優化方面,但這些算法的表現在網絡狀態改變的情況下也是不容樂觀。文獻[7]設計并使用了啟發式算法例如蟻群算法、模擬退火法等來進行網絡路由的優化,但由于啟發式算法的求解結果可能千變萬化并且其自身的局限性,只能針對特殊的問題。當網絡狀態發生變化時,其參數就需要調整,泛化能力差,并且在應對大規模的網絡時,為了尋找最優的路徑會需要大量的時間成本。文獻[8-9]使用了深度Q學習(deep Q learning, DQN)算法,將增強學習引入到了路由優化的應用中來,實驗結果表明DRL在路由選路的問題中有著獨特的優勢,可以實現降低網絡時延和自適應路由,但是DQN算法本身存在著缺陷,不僅自身收斂困難并且只能解決離散時間的優化問題,與網絡的動態屬性并不吻合。文獻[10]針對動態的網絡提出了使用深度確定性策略梯度(deep deterministic policy gradient, DDPG)算法來進行路由的優化。DDPG是一種主要解決連續動作空間的DRL算法,更易針對動態性與實時性較強的網絡系統,彌補了DQN算法無法處理連續控制任務的空白。盡管DDPG解決了很多連續動作空間問題,但是在高維度的動作空間上尋求一個最優的動作仍是一件困難的事情,尤其是在面對大型的網絡拓撲和高維度動作空間的復雜任務中DDPG算法的性能表現出了不穩定、收斂慢的缺點。
因此本文中,在使用DDPG算法解決網絡路由優化的問題方法上提出了兩種優化方法。應對大型的網絡拓撲,在知識定義網絡(knowledge-defined networking, KDN)架構上,提出了一種全新的動態權重構造策略降低了神經網絡的輸入狀態維度。利用流量矩陣直接構造動態鏈路權重,通過對原始數據的預處理,使得流量矩陣預加工為模型想要學習到的動作權重,進而增加了狀態和動作的相關性使得在訓練的過程中神經網絡更易從經驗中獲取到兩者潛在的關聯即策略。通過該方法,智能體能夠在初始的構造策略上進行二次學習,提升了模型的學習效率和智能體在訓練時的穩定性。另一種優化方法是在針對路由優化問題上進行了動作空間的離散化,極大降低了動作空間的復雜度,減小了無效的動作空間探索,使得算法學習經驗時更利于通過梯度下降的更新方法找到最優的更新策略的方向,從而加快了算法的收斂速度。本文設計了一套完整的訓練和測試方案,并驗證了增強后的算法在該方案下對于網絡性能的影響。
本文第1節介紹了DRL的一般原理和如何應用在具體的網路路由優化問題上;第2節詳細描述了DDPG算法原理與現存的缺陷討論了現有的動作選擇復雜度高和泛化性不強的問題和改進辦法,針對網絡路由優化問題提出了一套動態鏈路策略,能夠利用網絡當前的流量狀態生成各條鏈路權重。同時提出了動態空間離散化的方法,將連續動作映射到相對應的離散空間上。第3節對以上理論在仿真環境下進行驗證并對仿真結果做進一步的分析。
1 DRL學習機制和基于KDN的路由框架
DRL是將深度學習的感知能力和強化學習的決策能力相結合,是一種更具有智能化的更接近人類思維方式的學習方法。DRL是一種智能體和環境的交互系統,有著很強的普適性,所有用DRL解決問題的目標都可以被描述成智能體找到一組動作來最大化獎勵值。在時刻,智能體利用深度學習方法來感知并反饋給當前智能體具體的狀態特征,之后智能體通過策略將當前的狀態生成一個確定的動作,并對環境施加該動作并返回給智能體新一輪的狀態特征+1和及時獎勵值。智能體和環境持續不斷的交互最終會使得智能體生成了一個最優策略使得環境反饋的累積獎勵值最大化。
本文將利用人工智能技術來控制和操作網絡,使用了文獻[15]提出的KDN,其容納并利用SDN、網絡分析和人工智能,提出了互聯網知識平面的概念,這是一種依靠機器學習和認知技術操作網路的新構造。知識平面使用機器學習和深度學習來收集當前網絡狀態,利用收集當前網絡的信息使用SDN提供的集中控制性來控制網絡。圖1顯示了KDN的功能平面三層結構:數據平面負責存儲、轉發和處理數據包;控制平面負責監視網絡流量情況并下發流表規則和最上層的知識平面。KDN中的控制平面管理數據平面上網絡的路由流表,同時通過數據信息搜集模塊監控網絡中的流量情況、網絡時延、丟包率、吞吐量等性能信息上發給知識平面。在知識平面中具有深度強化學習的智能體,用于利用底層上發的有效網絡信息生成有效的網絡策略,從而尋找到當前網絡流量狀態下的鏈路權值信息,下發給控制平面使用路徑規劃模塊生成路由流表并更新到拓撲交換機中,實現了KDN的全局、實時的網絡控制。同時,在知識平面中存在兩個模塊:動作離散化模塊和狀態預處理模塊,分別用于知識平面接收數據平面的信息的狀態優化和下發數據平面的動作優化。
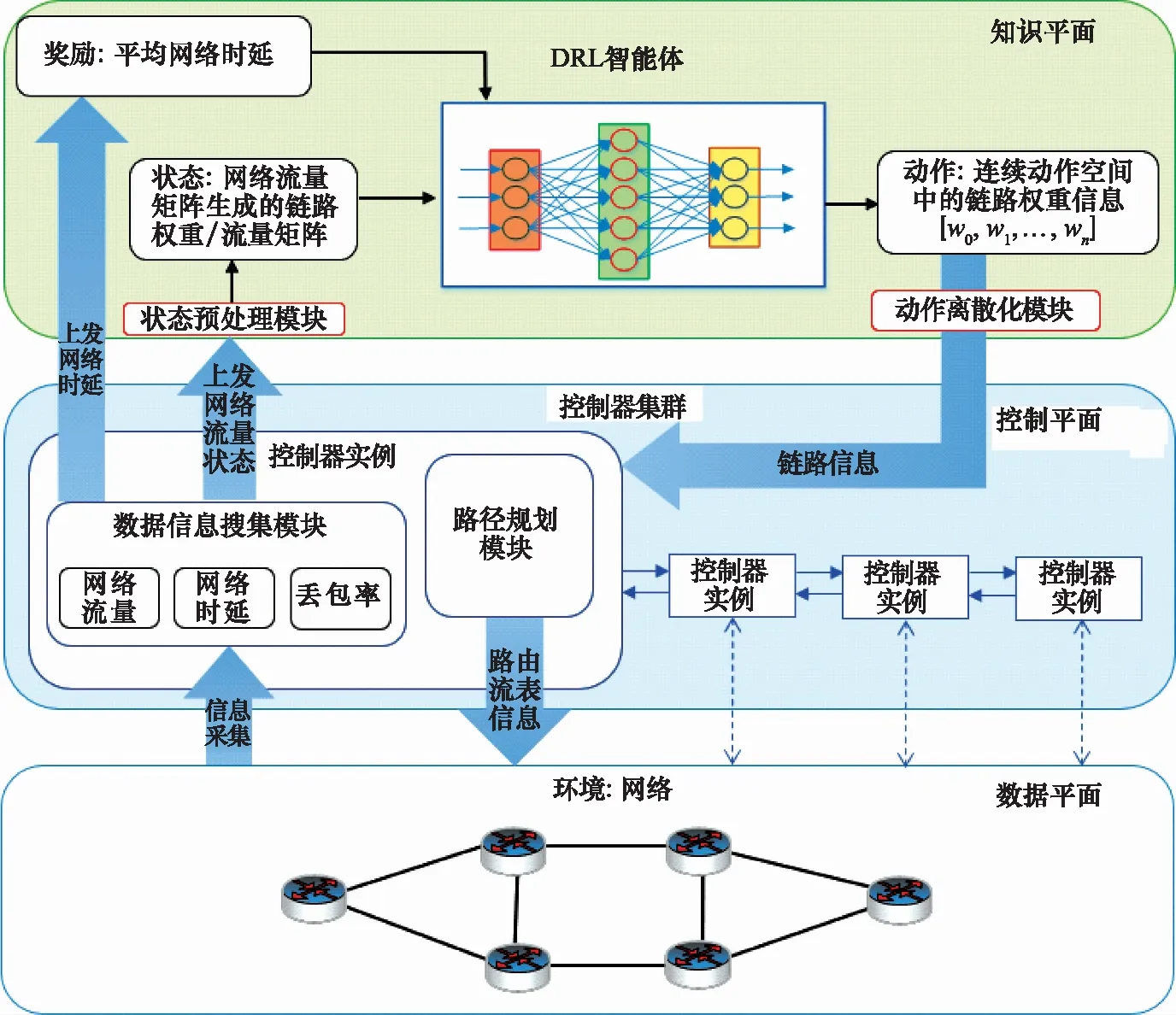
圖1 基于KDN的網絡路由控制框架Fig.1 KDN-based network routing control framework
將DRL的思想引入網絡控制中來解決路由優化問題最重要的是智能體和環境中交互的3個變量,分別是狀態、動作和獎勵值。其中的一個優化方法是在智能體的學習過程中,不再是直接利用由網絡層收集到的狀態信息——流量矩陣作為狀態,而是通過動態權重策略使用當前網絡的流量矩陣構造出輸入神經網絡的鏈路權重信息作為先驗知識。動作表示的是一個目的到源的鏈路權重的集合,智能體通過動作來改變網絡中的路由規劃。本文中,設置智能體的網絡優化策略為最小化網絡的平均時延,因此獎勵值代表平均網絡時延。在知識平面中還加入了動作離散器,在輸入狀態為流量矩陣時,將智能體的連續動作空間區域化成離散的動作空間,并將生成的連續動作空間上的動作映射到離散動作空間上再下發到控制平面中,實現了智能體對于網絡實時分析和優化。本文重點關注連續動作空間下的路由優化和離散動作空間下的路由優化的區別,并提出了一個新的動態權重策略,使用狀態預處理模塊通過網絡流量直接構造動態鏈路權重,在對原始數據的狀態進行預訓練后,生成先驗知識觀察智能體在解決路由優化問題訓練時的影響。
2 DDPG原理與優化策略
2.1 DDPG原理
DDPG不像傳統的強化學習算法只能解決離散動作問題,結合了DQN方法和確定性策略梯度的策略函數,同時使用了Actor-Critic(AC)模型的雙重網絡框架。其中,神經網絡用于擬合策略函數和Q函數。DDPG成為了求解連續動作空間的穩定算法,和分別表示神經網絡擬合的策略函數和Q函數。Actor網絡使用確定性策略梯度方法,Critic網絡使用DQN方法。Actor和Critic網絡都是由兩個神經網絡所組成的,用于訓練學習的策略網絡和減少每條經驗相關性的目標網絡。目標網絡和策略網絡在神經網絡的結構上是一模一樣的,但其參數會將Online網絡參數軟更新給target網絡:
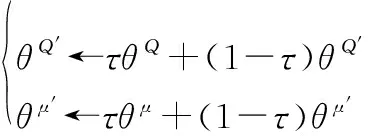
(1)
式中:為Actor網絡中在線網絡參數;′為Actor模塊中目標神經網絡參數;′為Critic模塊的目標神經網絡參數;為Critic模塊的在線神經網絡參數;為遠小于1的常數值。
在更新DDPG算法參數的過程中,Actor模塊中神經網絡使用反向傳輸的策略梯度進行更新,策略梯度更新公式如下所示:
?()=grad[]*grad[]≈
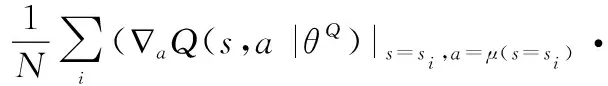
(2)
式中:為衡量策略的性能參數;grad[]是從Critic模塊中在線網絡中得到的動作梯度,指導Actor中在線網絡如何執行動作才能獲得更大的值;grad[]是從Actor中在線網絡中生成,指導Actor修改自身參數使得神經網絡有著更高的概率執行這個動作。式(2) 能使Actor模塊中在線神經網絡向著能獲得更高回報的概率方向上不斷修改其參數。
Critic網絡反向傳輸更新參數為TD_error,TD_error為在線網絡和目標網絡值的均方誤差。
=

(3)
式中:為當前的即時獎勵;為學習時的衰減因子。
式(3)前半部分為Critic模塊中目標網絡基于下一步狀態+1和動作+1生成的值。其中,動作+1是由Actor模塊中目標網絡利用下一步狀態+1和參數′所生成的。式(3)后半部分則是對于Critic模塊的在線網絡值則是對當前狀態和由Actor模塊的在線網絡對當前狀態生成的動作評估并生成值。將式(3)兩部分取均方差用于反向傳遞使其更新Critic模塊在線網絡的參數。
2.2 動態權重優化策略
強化學習算法優化的目標是獎勵的長期累計收益最大化。神經網絡的作用是將原始狀態信息經過層層非線性提煉后轉化為與長期收益高度關聯的形式,并進一步指導生成動作決策。理想情況下,狀態空間應該完全由篩選出的相關信息組成。某個狀態信息所代表的事件在越短時間內得到反饋,神經網絡就越容易學會到如何對其進行加工并建立起決策相關性。在利用深度強化學習解決問題時,往往會因為問題本身設計的狀態和生成動作關聯度不高導致神經網絡在策略學習的時候難度增大,反映出智能體學習效果不穩定。在學習過程中,原始信息都要經過神經網絡的提煉才能轉化為動作輸出,提煉難度與學習效率和最終性能呈反向相關。為了降低神經網絡訓練難度,提前對原始信息做些二次加工,人為提煉出與學習目標更相關的因素從而生成先驗知識。
在利用DRL解決路由優化問題時,定義狀態為初始權重,動作為優化權重,獎勵為全網平均時延。當前網絡環境的流量矩陣上發給智能體時對流量矩陣作為原始狀態進行預處理生成初始權重。可以通過動態權重策略得到滿足當前網絡拓撲下的當前流量矩陣的初始權值。

(4)
式中:表示流量矩陣。

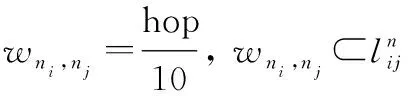
(5)
計算出中所有路徑中各自對應的鏈路權值集合,,從,中找到各條鏈路的最小權值,從而生成源目的對(,)所對應的鏈路權值集合(, )(,=1,2,…,)。該策略保證了兩點之間最短路徑優先的原則使得跳數越小的鏈路優先級越高權值越小,通過拓撲可直接求出所有源目的對(,)的鏈路權值集合。利用拓撲生成的源目的節點對的權值集合和流量矩陣進行運算,通過式(6)與對應節點對進行相乘并累加生成初始權重做用于神經網絡輸入端。
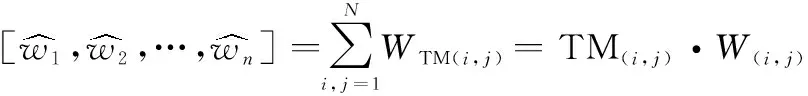
(6)
該方法使得業務量大的端到端的所經過的鏈路權重小,確保了大流量業務的穩定性。整體流程如算法1所示。

算法 1 獲取當前拓撲topologyL=DFS(topology),由DFS生成該拓撲下所有點到點的鏈路集合L;wni,nj=hop10,wni,nj?lij,得到wni,nj的權值并生成集合Wni,nj;Sraw=TM,流量矩陣作為原始狀態[w1,w2,…,wn]=∑Ni,j=1WTM(i,j)=TM(i,j)*W(i,j),生成初始權值St;[w1,w2,…,wn]=πθ(w1,w2,…,wn),初始權重通過Actor網絡生成優化權重。
在知識平面上將狀態傳入Actor網絡,而Actor會根據當前的狀態選擇合適的動作,影響策略神經網絡參數的迭代更新。而DDPG為確定性策略算法,不像隨機性策略一樣是在同一個狀態時采用的動作是基于一個概率分布的。而是取最大概率的動作,去掉隨機分布,在一個狀態下,動作是唯一確定的,即策略為
π()=
(7)
DDPG的策略決策直接受到Critic網絡的價值函數的影響,價值函數表示了在不同狀態下的選擇的不同的動作所對應的價值。一般情況下,價值函數是一個參數函數,在該算法中則是狀態和動作為Critic全連接神經網絡(deep neural networks, DNN)的輸入端,該神經網絡則利用價值函數計算出當前狀態所執行動作的價值(,,),為Critic價值神經網絡參數。在利用DNN搭建網絡時,將Actor網絡輸入端的維度設置為狀態維度,輸出端設置為動作維度,而Critic網絡輸入端為狀態維度加上動作維度。DDPG算法是基于兩組神經網絡進行訓練和擬合的,神經網絡擬合的速度反映了算法的質量。策略神經網絡參數θ決定了策略函數,通過神經網絡進行反向的策略梯度更新尋找到狀態空間和動作空間潛在關聯。
如圖2所示,在路由優化中狀態預處理過程,利用從網絡產生的流量矩陣作為原始狀態,使用策略生成當前流量狀態下的初始權值作為狀態輸入到Actor網絡中。此時輸入神經網絡中狀態維度等于動作維度,在減少了神經網絡的狀態維度后,使得Actor網絡在低維狀態中更容易找到潛在的規則。并且,使用策略通過對流量矩陣構造初始權值作為狀態值輸入到神經網絡中提升了狀態和動作之間的相關性,使得Actor模塊中的DNN更容易找到從當前流量矩陣中映射到優化權重的最優策略,進而提高了DDPG算法的收斂速度和學習效率。
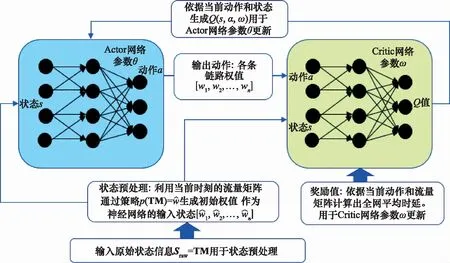
圖2 狀態預處理Fig.2 State preprocessing
2.3 動作空間的離散化
在網絡路由優化方法中,一般利用Actor網絡生成的各條鏈路上的權重矩陣作為動作,從而通過Dijkstra算法求出最優的流表再下發給網絡層。雖然DDPG可以解決連續動作空間問題,但在動作維數過高、動作連續區間過大構成的高維度連續動作空間上利用批處理梯度下降法尋找最優動作增加了難度,而基于價值的策略網絡是通過評估和優化參數來學習的,動作維度過高導致了參數函數的評估過程復雜,利用DNN評估的復雜度會隨著動作維度和量級的增加呈指數型上升。策略網絡的梯度更新完全由Critic網絡輸出,Q函數的擬合誤差會直接傳遞給策略網絡導致DDPG穩定性不足。降低動作空間復雜度對于AC網絡參數的評估是必要的。
:→′,()=′
(8)

圖3 動作離散化過程Fig.3 Action discretization process
映射到離散動作空間后,通過減少動作空間的取值范圍從而降低了動作空間的復雜度,使得Critic網絡在擬合最優函數時更易找到最優參數并反饋給Actor網絡,有利于策略網絡的參數更新。動作空間離散區塊化后,動作空間自由度大大降低,算法穩定,同時加快收斂速度。在路由問題中,該方法減小了智能體探索無效動作空間的可能性,提升了神經網絡策略更新參數時的效率。
3 實驗結果與性能分析
3.1 試驗平臺設置
本節對優化算法進行了網絡路由優化的性能評估與測試。所用操作系統為Ubuntu18.04,同時使用機器學習框架Keras+Tensorflow搭建了學習環境,并在基于OMNet++離散時間仿真器上構建了目標網絡環境,實現了兩個平臺的交互仿真。對于網絡拓撲,采用了14個節點和21條鏈路的拓撲節點度為3的網絡拓撲,并假設各條鏈路帶寬相同,鏈路上無時延。實驗中設置了分別占據全網總帶寬不同的10種流量強度從12.5%到125%,對于每個流量強度在相同的流量總量情況下使用重力模型生成了100個二維14×14的流量矩陣。從而生成了具有差異化的流量總量與不同流量分布的1 000個流量矩陣用于智能體的訓練與測試。此外,設計了一套完整的訓練和測試方案使得智能體在10種混合網絡負載下的訓練集合進行訓練。通過對訓練后模型的性能測試驗證了算法優化的有效性與收斂性。首先驗證了在不同流量強度等級下DDPG算法動作空間離散化的性能優勢,之后評估了智能體在使用了動態權重策略下進行原始信息處理后的優化性能。
3.2 動作空間離散化訓練測試
使用10種不同流量分布的流量矩陣分別在連續動作空間上智能體和離散化動作空間的智能體進行10萬步的訓練。算法的批量梯度下降值設置為256,并利用占總網絡容量分別為25%,50%,75%,100%的4種流量強度重新利用重力模型分別生成100個TM進行測試。在智能體進行10萬步的訓練過程中,每隔2 000步則會記錄下當前智能體神經網絡參數用于測試。由OMNet++離散仿真環境返回的網絡時延作為獎勵值。為保證數據的可靠性,相同訓練步數和相同負載下的流量矩陣所得的測試結果取平均值,作為優化算法的測試標準。通過不同的動作離散化程度進行了測試結果的比較。該仿真中設置了Δ=0.2和Δ=0.1用于對比分析其性能。
實驗結果如圖4所示,在不同的網絡負載下,智能體通過訓練后可以有效地降低網絡的平均時延,并隨著訓練步數增大網絡時延不斷減少。在不同網絡負載的情況下利用動作空間離散化方法相較初始算法性能上有了巨大的提升,當Δ取值越小時劃分的動作空間越精細其空間離散化維度越高,則需要更多步數訓練來使智能體收斂。在中低網絡負載下,由于整體網絡狀態空閑,網絡性能優化空間有限需要在更精細動作空間上探索,當Δ=0.1時有利于在優化空間較小的網絡拓撲中尋找到最優鏈路權值,在網絡負載25%的情況下全網平均時延優化提升了9%。當網絡負載較高時網絡優化空間大,需要從網絡整體上把控主要緩解個別擁堵的鏈路,此時用Δ=0.2劃分動作空間,智能體極大程度上減少了無效動作的探索,同時防止了陷入局部最優和降低向回報值小的梯度方向更新的概率,利于最優策略探索并且加速了智能體收斂速度,在網絡負載75%和100%的情況下全網平均時延優化分別提升了5.41%和6.85%。

圖4 優化模型性能測試Fig.4 Optimize model performance test
3.3 狀態預處理訓練測試
在進行狀態預處理模型測試時,使用重力模型生成十種流量負載下的1 000個流量矩陣分別用在已訓練10萬步的兩個模型上,模型可以依據當前流量矩陣在不同訓練步數下通過一步預測輸出符合當前網絡流量狀況的理想路由,之后對所有的時延數據構造箱型圖用于數據分析。矩陣模塊中的上部與底部分別代表的是所得時延觀測到數據的上四分位數和下四分位數值,并且矩形中間橫線所代表的時延觀測數據的平均值數,而由矩陣延伸出來的直線的上端與下端分別代表了在上四分位數和下四分位數的1.5·IQR(IQR為四分位數范圍:上四分位數-下四分位數)內的最低和最高的數據值,在上端和下端之間為外限,外限之外的數字為異常值并顯示為一個小型菱形。
如圖5所示,在進行了狀態預處理的智能體能夠隨著訓練步數的增加而不斷減小全網的平均時延,訓練10萬步后的智能體比第2千步有了巨大的提升。在進行了狀態預處理過程后的智能體在學習的過程中表現得更加平穩,減小了神經網絡向錯誤梯度更新方向概率整個學習效果呈現逐步變優的趨勢。表1展現了不同流量負載下8種測試步數下的異常值總數,使用網絡流量矩陣訓練的模型在測試過程中異常值總數為91個,而在經過狀態預處理后測試過程中為43個,異常情況大量減少驗證了預訓練后智能體的模型有著更強的穩定性和魯棒性。
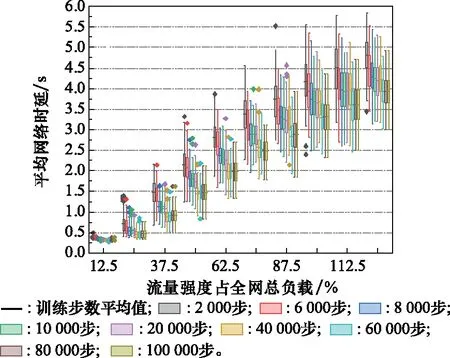
圖5 DRL訓練過程Fig.5 DRL training process
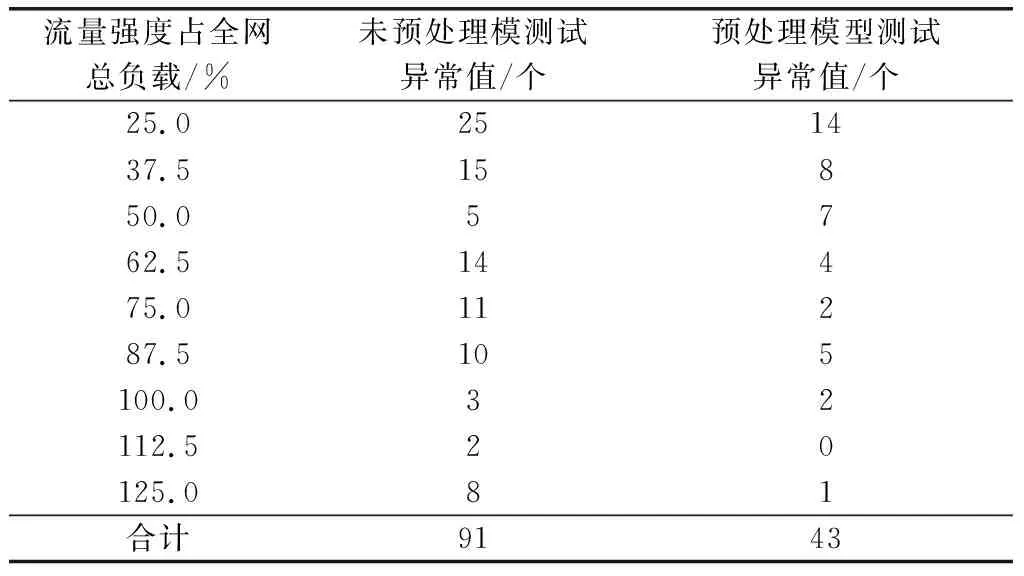
表1 異常值數據對比統計
由于狀態動作信息的非相關性導致利用流量矩陣學習網絡鏈路權重的訓練過程過于復雜,盡管其優化效果明顯但是訓練過程表現出了不穩定的情況,智能體在訓練的后期無法穩定在已學習到的優秀策略上如圖6所示。在智能體學習過程中,流量矩陣的狀態復雜性使得沒有經過狀態處理過的智能體并未充分學習到在當前流量狀況下的最優路由,在測試模型的后期仍有往不好策略探索的趨勢。而在減少了神經網絡輸入的狀態維度并對輸入的網絡流量狀態進行了預訓練后,增強了狀態與動作的關聯度,輸入的狀態信息和動作信息成為了直接相關信息,降低了尋找最優策略的難度。在流量強度過高的情況下超過負載75%情況下,經過狀態預處理的智能體有著更強的穩定性和可靠性并相較于未預處理模型能學到更優的路由策略網絡平均時延的收斂值更低。

圖6 智能體性能對比Fig.6 Agent performance comparison
4 結束語
針對高維度大規模的網絡的路由優化,在原有深度強化學習DDPG算法上進行了提升和改進,使得增強后的DDPG算法更適合解決網絡路由優化的問題。本文提出了動態權重策略,可利用當前網絡流量構造出符合當前網絡流量狀態的鏈路權重,提前對原始信息做了二次加工生成了智能體的先驗知識,增強了神經網絡中動作狀態的潛在關聯度。神經網絡在初始權重上繼續學習,降低了其學習依據流量狀態到路由策略動作的困難,減少了朝向錯誤策略參數梯度更新的概率,增強了模型學習的穩定性。并針對高緯度大規模網絡的連續動作空間進行了動作空間離散化處理,有效降低了動作空間的復雜度加快了收斂速度。實驗表明:與原有的DDPG算法相比,兩種優化方法對于路由優化和訓練的穩定性有著良好的提升,在網絡擁塞、網絡負載大的情況下尤為突出。該優化方法與訓練方法可以適應不斷變化的流量和鏈路狀態,提升了強化學習訓練模型后應對不同網絡狀態的穩定性,降低了網絡平均的時延,提升了網絡性能。
猜你喜歡
房地產導刊(2022年5期)2022-06-01 06:20:14
建材發展導向(2021年12期)2021-07-22 08:06:48
建材發展導向(2021年7期)2021-07-16 07:07:52
中學生數理化(高中版.高二數學)(2021年12期)2021-04-26 07:43:48
文苑(2018年23期)2018-12-14 01:06:06
文苑(2018年19期)2018-11-09 01:30:14
文苑(2018年17期)2018-11-09 01:29:26
文苑(2018年21期)2018-11-09 01:22:32
小學生作文(低年級適用)(2018年3期)2018-04-17 00:58:35
少年博覽·小學低年級(2017年4期)2017-06-09 16:22:28
