群隊級兵棋實體智能行為決策方法研究
2022-08-17 09:44:50張宏軍徐有為馮欣亮馮玉芳
系統工程與電子技術 2022年8期
關鍵詞:動作
劉 滿, 張宏軍, 徐有為, 馮欣亮, 馮玉芳
(1. 陸軍工程大學指揮控制工程學院, 江蘇 南京 210007; 2. 中國人民解放軍73131部隊, 福建 漳州 363000;3. 陸軍步兵學院, 江西 南昌 330000; 4. 中國人民解放軍71375部隊, 黑龍江 哈爾濱 150000)
0 引 言
多智能體(agent)對抗系統的動作空間復雜度隨智能體的個數呈指數增長,這導致了多智能體集中控制的學習異常困難。騰訊推出的“絕悟”支持王者榮耀1v1全部角色,需要使用1 064塊NVIDIA GPU訓練超過70 h。DeepMind推出的“AlphaStar”支持星際爭霸Ⅱ整場游戲,使用了384塊TPU訓練超過44天。然而,對于普通研究機構,很難擁有這些超大規模的計算資源。計算機兵棋推演平臺能夠對敵對雙方或多方的軍事行動進行隨機性模擬,為軍事智能決策的研究提供貼近真實戰爭的決策背景和試驗環境。兵棋推演是典型的多智能體決策環境,指揮員(兵棋玩家)控制多個同類型或者不同類型的作戰實體(棋子),使之能夠協同配合,達到整體的作戰目標。在戰術級兵棋對抗中,深度強化學習開始得到應用,因訓練難度和計算資源的限制,目前只實現2個同類型棋子的控制,且決策場景單一,無法直接遷移。對于群隊級兵棋對抗平臺,單方約有50個左右的棋子需要控制(人類一般需由5個人組成小隊聯合控制),這種大量作戰實體的聯合行為決策給人工智能技術帶來了極大的挑戰。
傳統的計算機生成兵力(computer generated forces, CGF)對仿真中的虛擬實體進行行為控制,它借鑒了很多人工智能(artificial intelligence, AI)領域中基于知識驅動的決策方法,如有限狀態機(finite state machine, FSM)和行為樹(behavior tree, BT)等。但是這種決策模型主要從定性分析的角度,以邏輯推理的方法得到行為輸出,其模式比較固定,對態勢變化的響應不靈敏,缺乏類人的靈活性。
兵棋推演的復盤數據蘊含了較多的態勢信息和策略信息,可以為兵棋的定量決策提供信息支撐。但是,這種高維、數量巨大的數據并不能直接使用,必須要經過特征提取等方式,才能得到人們容易理解的信息。鄭書奎等人提出了一種棧式稀疏降噪自編碼深度學習網絡模型,用于兵棋演習數據特征提取,取得較好的分類精度。張可等人設計了關鍵點推理遺傳模糊系統框架,有效整合了兵棋專家知識的建模和兵棋復盤數據的學習,從而提高了關鍵點的推理質量。Pan等人提出基于信息素的兵棋敵方位置估計算法,分析地形、威脅等因素,建立8類信息素,最終通過合成信息素值,預測敵方棋子可能的位置,取得了top-3的預測準確率為70%。借助于這些量化信息或特征的提取方法,一些基于量化決策的兵棋AI智能框架被提了出來。田忠良等人設計了以多智能體協同進化為設計理念的群體智能優化算法,解決多智能體、多攻擊目標的火力分配問題,從而輔助指揮員決策。劉滿等人通過挖掘兵棋復盤數據,提取多個位置評價的指標用于棋子的位置選擇,提出了完整的決策框架,設計的兵棋AI展現了較好的智能性。量化分析有效整合了復盤數據中的歷史信息和當前的態勢信息,具有較高的靈活性和魯棒性,但是這種決策方法需要大量高質量的人工復盤數據,這一前提條件往往很難滿足。
本文提出了知識與數據互補的行為決策方法,有效利用人類專家先驗知識和基于兵棋數據的量化數據進行綜合決策。特別是對于群隊級這種大規模作戰實體聯合決策的情況,進行了針對性改進,提出了按實體類型分組決策、作戰目標指引、位置評價指標并行計算等方法。最終,設計了適用于營級規模作戰實體的行為決策框架,并實現了一個群隊級兵棋AI,實驗結果表明,此AI具有較強的靈活性和遷移能力。
1 兵棋行為決策算法
1.1 群隊級兵棋推演及其行為決策
兵棋是運用規則、數據和階段描述實際或假定的態勢,對敵對雙方或多方的軍事行動進行模擬的統稱,是分析戰爭的重要手段。陸軍戰術級兵棋是指單方兵力規模在營及以下的兵棋系統,一般可以分為分隊級和群隊級。分隊級的兵力一般由連級規模的多種作戰力量組成,包括10個以下棋子(1個棋子代表1個班組或1個排)。群隊級的兵力一般為營級規模的多種作戰力量組成,包括多個分隊級兵力和配屬力量(炮兵、空中力量),棋子個數一般在50個左右。因為需要控制的棋子數量較大,且沒有大量的人類復盤數據供監督學習,群隊級兵棋智能體決策是人機博弈領域有待攻克的挑戰。
因地形遮擋和觀察距離的限制,棋子很多時候不能被對方觀察到,因此不完全態勢是戰術級兵棋的典型特點。戰術級兵棋智能決策的主要內容是根據盤面上的不完全態勢,判斷決策出作戰實體的行動。該實體行動具有4個明顯的特點:規則性、目的性、位置主導和高度協同。規則性是指實體行動必須遵循兵棋系統所有的規則;目的性是指實體行動必須以作戰目標(如奪控某個位置)為導向;位置主導是指實體必須依靠合適的地形、地物才能保護自己并發揮武器效能;高度協同是指各作戰實體間必須相互配合協同作戰。因此,戰術級兵棋智能決策是“多實體在兵棋規則的限制下,高度協同配合,在合適的時間,棋子能夠移動到具有戰術優勢的地點,對敵人實施打擊,最終完成作戰目的”。
按問題的量化程度,決策可以分為定性決策和定量決策。定性決策是指決策問題的諸因素不能用確切的數據表示,只能進行定性分析的決策。定量決策是指決策問題能量化成數學模型并可進行定量分析的決策。戰術級兵棋的具體原子動作可以表示為動作名稱和動作參數的聯合,根據有無動作參數和動作參數的復雜程度,可以將棋子的動作分為宏觀動作和微觀動作,宏觀動作是指動作的組合、參數未知的虛動作或簡單參數的動作,微觀動作是指具有復雜參數的動作。一般來說,宏觀動作不需要求解復雜的動作參數,可以從定性決策的角度,以態勢信息為判斷條件,利用專家知識和兵棋規則進行推理得出;而微觀動作需要求解復雜的動作參數,如機動終點、機動路線、射擊目標等,可以從定量決策的角度,對兵棋數據進行數學計算,利用量化評估的方式選出離散的動作參數。可見,宏觀動作和微觀動作并沒有明顯的區分界限,二者關注動作的方式不一樣,宏觀動作關注的是動作名稱,即要不要執行某個動作,而微觀動作關注的是動作的復雜參數,即動作的具體內容。
1.2 基于知識驅動的決策算法
兵棋行為決策中的知識是指人類在長時間的兵棋推演中認識和總結的行為規律和制勝方法,它能以戰法、策略等形式用文字概略描述出來。編程人員可以和兵棋專家合作,將這些戰法和策略進行梳理、分解,形成領域知識庫,并以邏輯推理的形式模仿專家的推理進行決策。
基于知識的推理是AI技術最早期的經典方法之一,它通過專家知識構建的規則庫,用邏輯的方式實現決策,是符號主義的代表。FSM和BT的模型構建比較簡單,易于維護,在CGF和游戲的行為控制中得到廣泛應用。
FSM是具有基本內部記憶功能的抽象機器模型,表示有限離散狀態以及這些狀態之間轉移的數學模型,其在任意時刻都處于有限狀態集合中的某一個狀態,當滿足轉移條件中的某一確定事件時,FSM會從當前狀態轉移到另一個狀態。BT是適用于控制決策的分層節點樹,可解決可伸縮性問題。行為樹中有葉節點和組合節點,同時把行為劃分成了很多層級,低層級的行為為葉結點,低層級的行為能夠組合成較高層級的行為,以組合結點表示。行為樹在執行的時候,會執行深度優先搜索,依次達到末端的葉節點,從而選擇出葉結點(底層級行為)。BT是FSM的改進,它將狀態高度模塊化,減少了狀態轉移條件,使狀態變成一個行為,從而使模型設計更加容易。但是當決策邏輯復雜時,行為樹的組織結構會迅速擴張,這會造成行為樹的可讀性降低。
對于兵棋多agent行為決策,既要考慮集體行為,也要考慮個體行為,本文提出FSM與BT分層決策的方法。FSM建模兵棋多agent作戰任務的轉換,可以從整場比賽的角度優化決策模型;BT建模單個agent在給定任務條件下行為動作的輸出,完成單個agent在特定任務條件下的局部優化。圖1展示了FSM和BT分層的多agent行為決策框架,FSM根據整場比賽的情況進行任務轉移,輸出作戰任務,單個agent根據作戰任務,考慮局部態勢情況,通過行為樹決策輸出動作。
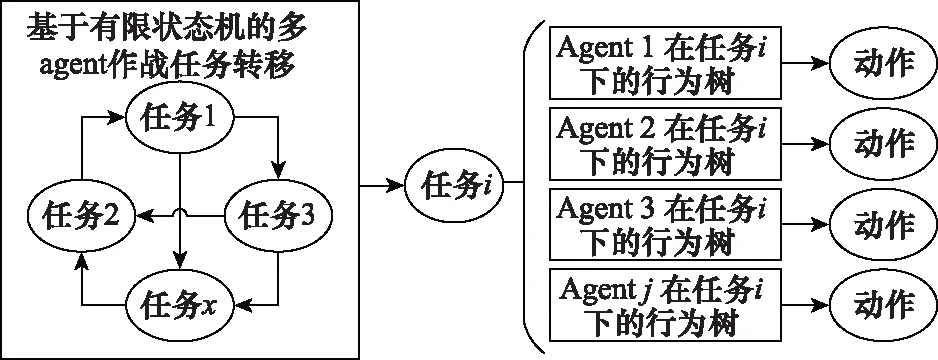
圖1 FSM和BT分層的多agent行為決策框架Fig.1 Hierarchical multi-agent behavior decision-making framework based on FSM and BT
FSM、BT這種行為模型大量地依賴領域相關人員參與構建,能夠較好地模擬人類頂層的推理思維,適宜兵棋智能對抗中宏觀動作的決策。但是,包含復雜參數的微觀動作,需要對態勢數據、地圖數據充分響應,基于知識的推理算法難以精細處理。常用的解決思路是基于方案設計,即領域專家提前預想多種情況,并充分分析地圖,將復雜的參數(如機動終點)提前以腳本的形式固化下來,形成多套方案供決策模型選擇。但是這種做法使模型輸出的行為缺乏靈活性,同時決策模型也難以遷移到其他推演想定。
對于復雜動作參數的優化問題,一個可行的方法是使用定量決策的方法,充分利用兵棋數據進行評估優化。
1.3 基于數據驅動的軟決策算法
兵棋數據按產生的方式可以分為想定數據、環境數據、規則數據、復盤數據和態勢數據。想定數據是指一場兵棋推演對地圖、實體、作戰目標等規定的數據;環境數據是指兵棋系統對戰場環境的量化表示而產生的數據,如地圖數據等;規則數據是指兵棋系統對作戰實體、作戰規則等描述而產生的數據;復盤數據是指兵棋推演系統在推演整個過程中記錄下來的過程數據。態勢數據是指在兵棋推演中實時產生的描述戰場動態情況的數據。這些兵棋數據蘊含了大量兵棋行為決策的知識,可以通過數據挖掘等方法將它們轉化為支持決策的量化數據。
對于戰術級兵棋的棋子移動位置決策,文獻[12]使用兵棋數據挖掘與融合的方法,提取了多個與棋子位置選擇相關的指標,通過多指標綜合評價優選算法,得出棋子的移動位置。
首先對多個標準化之后的指標進行綜合,令
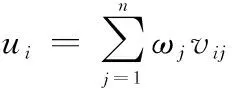
(1)
式中:為第個終點位置的加權綜合評價值;為第個位置的第個標準化指標值;為第個屬性值的加權系數。
將綜合評價值轉換為能夠調控熱度的概率值,并依據概率的大小來選擇方案:
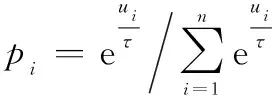
(2)
=random_choice()
(3)
式中:表示由評價值轉換的概率值;>0,稱為“溫度因子”,具有調控概率的作用;為待評估位置的總數;為由組成的離散概率數組;random_choice()為依概率選擇坐標函數;為最后優選出的棋子移動位置。
當→0時,趨向于最大評估值決策;當→+∞時,趨向于隨機選擇決策;當1≤≤e時,決策較好地兼顧質量與變化。
使用這種基于數據驅動的軟決策方法充分利用了兵棋數據特別是態勢數據中的信息,可以部分解決不完全態勢的問題,優選出的棋子移動位置兼顧了質量與變化,配合規則推理,使兵棋AI的決策具有高度的靈活性。另外,這個算法依據數據計算,不依靠專家知識,有很好的可復用性。
但是,大量高質量的人工復盤數據集很難得到,這一前提條件限制了該算法的應用范圍。
2 群隊級兵棋AI關鍵技術和框架
2.1 知識與數據互補的行為決策算法
基于數據驅動的軟決策算法具有靈活的優勢,但是需要人工高質量的復盤數據;基于知識驅動的決策算法利用兵棋專家的領域知識進行決策,無需人工復盤數據,但是難以優化復雜的動作參數。本文將這兩種算法結合起來,提出了知識與數據互補的行為決策算法。
圖2展示了知識與數據互補的行為決策算法框架,在構建知識庫時,專家將不再對地圖具體點進行分析,而是根據戰場進程,設定agent的任務區域和任務區域內選點的指標權重。利用基于知識驅動的決策算法對整場推演進行戰術籌劃,即使用FSM對多agent任務進行決策,使用BT對agent進行行為決策,輸出動作名稱、任務區域和指標權重。任務區域具有全局位置優化的能力。在任務區域和指標權重給定的條件下,利用基于數據驅動的軟決策算法,就可以計算出棋子在任務區域內的移動終點。當然,我們也可以使用定量計算的方法得到其他動作參數,如機動路線、射擊目標等。最后,綜合動作函數和動作參數,就可以解析出原子動作命令。另外,基于數據驅動的軟決策算法需要復盤數據作為支撐,本文使用隨機數據讓決策模型先運行起來,從而得到自我對戰的復盤數據,進而通過迭代優化,提升復盤數據質量,進而優化整個決策模型的決策質量。
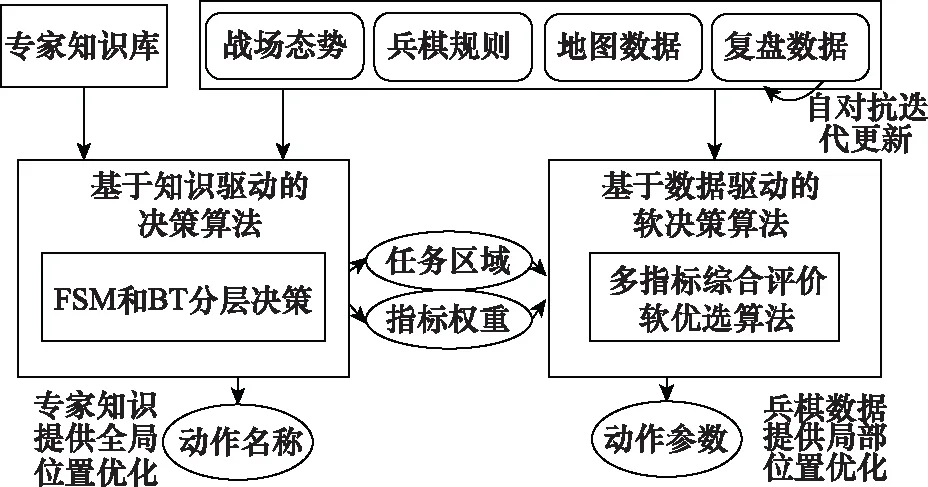
圖2 知識與數據互補的行為決策算法框架Fig.2 Framework of behavior decision-making algorithm based on complementary knowledge and data
知識與數據互補的行為決策算法,將全局規劃、行動推理交給基于知識驅動的決策算法處理,將動作參數的計算和優選交給基于數據驅動的軟決策算法處理,分別發揮了兩種算法的優勢,實現了兵棋AI在無人類復盤數據指導下的靈活決策。
2.2 群隊級兵棋實體行為決策面臨的困難和解決思路
群隊級兵棋的作戰力量一般由多個分隊,以及附屬的多個空中力量和炮兵力量組成,單方控制的棋子數量約50個左右,奪控點約5~10個。使用知識與數據互補的行為決策算法時,這種大量作戰實體的控制將面臨以下幾個困難:
(1) 作戰力量包括多個分隊和配屬的空中力量、炮兵力量,如果以分隊為單位設計有限狀態機和行為樹,專家的工作量將大大增加;
(2) 奪控點數量增加,且數量不固定,如何為大規模的作戰實體分配合適的奪控點作為作戰目標;
(3) 位置評價指標的總時間與棋子個數的關系為()。群隊級棋子指標的計算時間嚴重拖延了決策速度。
為了解決以上問題,我們提出了以下方法:
(1) 按棋子類型分組
群隊包含多個分隊,分隊包括多個不同類型的棋子,如果按照正常的人類指揮控制方式,為每個分隊確定作戰任務,分隊內棋子根據任務確定行為樹,這樣分解將大大增加專家的工作量,且設計出的決策模型遷移能力較差。本文采用按棋子類型分組的方式,每個類型分組內包含同類型的多個棋子,這些棋子可以共用一個行為樹。類型組的作戰任務將著眼于整個戰場,而不需要考慮不同類型組的作戰地域劃分,作戰任務按照作戰進程進行劃分。類型相同的棋子在作戰任務條件下復用同一個行為樹。為了使同類型棋子的行為輸出多樣化,以作戰目標(奪控點)來確定作戰區域,這樣同類型的不同棋子的作戰區域將會不同。
(2) 類型組內作戰目標(奪控點)自動分配
群隊級兵棋推演一般會設置多個奪控點作為作戰目標,敵對雙方圍繞這些奪控點展開爭奪戰。對于多個奪控點,綜合考慮距離和均勻分配,為類型組內的每個棋子分配一個奪控點作為作戰目標。這樣該棋子行為樹中任務區域的計算將以該奪控點和當前位置為定位點,以扇形、圓形、環形區域及這些區域的集合運算確定任務區域。
(3) 評價指標并行計算
使用多指標綜合評價軟優選算法,一般是已知待選作戰區域后,才調用指標計算函數計算這個區域的多個評價指標。當棋子數量急劇增加后,這種按需計算的方式,嚴重降低了決策環的速度。為此,提出了雙進程指標并行計算的方法。如圖3所示,單進程指標按需計算是指當優選算法需要指標數值時,調用函數計算指標值,其計算可以分為3步。雙進程指標并行計算是指主進程控制決策流程,另外開辟一個子進程,循環計算我方每個棋子周邊區域六角格的指標值供主進程算法調用,其計算分為2步。主進程使用位置評價指標時,可以直接調用子進程計算好的數值,這樣就大大縮短了決策環的時間。
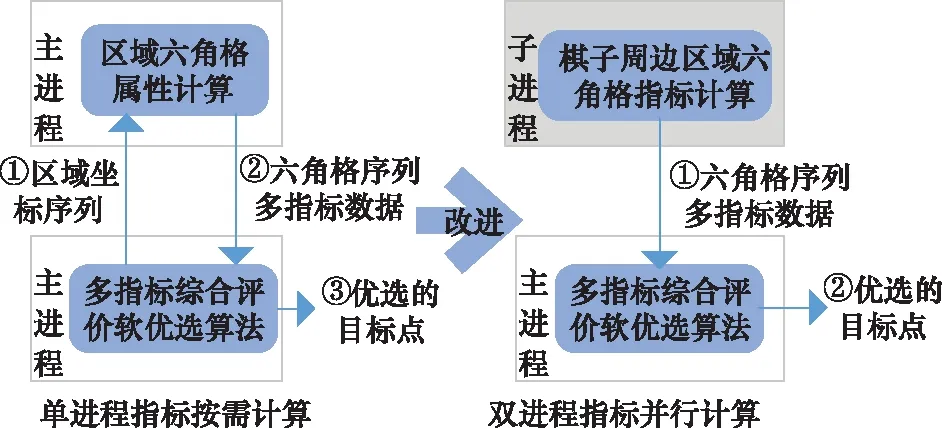
圖3 單進程指標按需計算和雙進程指標并行計算過程對比Fig.3 Comparison of single process attribute on demand computing and dual process attribute on parallel computing
以上3點改進,使知識與數據互補的行為決策算法在群隊級兵棋推演中能夠使用,簡化了專家的工作量,提升了計算效率,也使模型的泛化性大大提升。
2.3 群隊級兵棋AI技術框架
OODA(Observe,Orient,Decide,Act)環理論提供了一種以觀察、判斷、決策、行動循環來描述對抗的方法,被廣泛應用于軍事決策過程模型的研究。反映到決策行為模型中,觀察和行動是與外界環境交互的過程,分別完成了模型的輸入(戰場態勢)和輸出(作戰行動)。態勢判斷和行動決策運行于模型的內部,完成決策的生成。
本文基于知識與數據互補的決策算法,并對群隊級具有大量作戰實體的情況進行針對性改進,依照OODA環的流程,設計了群隊級兵棋AI技術框架。分為5個模塊:離線學習模塊、感知模塊、判斷模塊、決策模塊和行動模塊,如圖4所示。離線學習模塊是對自對抗復盤數據集或其他復盤數據集進行數據挖掘,增量更新知識數據。其他部分對應于OODA環的4個部分。
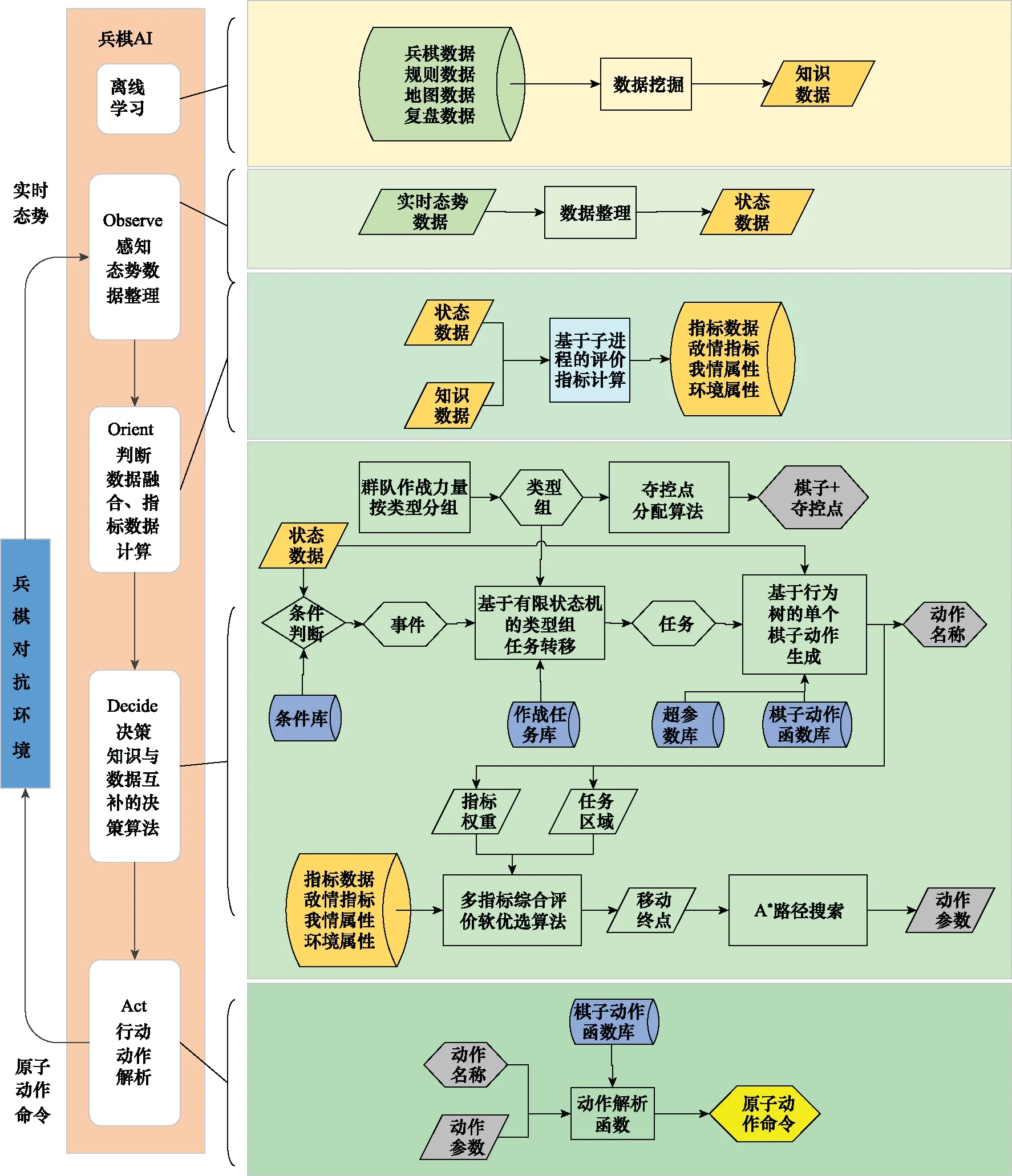
圖4 群隊級兵棋AI技術框架Fig.4 Group-level wargame AI technology framework
離線學習模塊設計按照文獻[12]中數據挖掘部分的框架和流程進行設計,提取兵棋數據中一些支持決策的知識數據(棋子歷史位置概率表、奪控熱度表、觀察表等)。
感知模塊對兵棋推演平臺推送的態勢數據進行格式整理和分類存放,形成狀態數據(全局狀態、我方棋子狀態、敵方可見棋子狀態、奪控點狀態等),便于后續模塊使用。
判斷模塊設計參考文獻[12]中數據融合的方法,但是在計算方式上采取子進程并行計算,即狀態數據不斷循環更新,指標數據也不斷循環計算更新。得到的多個指標傳輸到主進程中存儲,供多指標綜合評價軟優選算法查詢調用。
決策模塊是兵棋智能決策引擎的核心部件,它主要由3部分組成:一是專家知識庫,二是基于知識驅動的決策算法,三是基于數據驅動的決策算法。專家知識庫和基于知識驅動的決策算法聯合設計,可以復用的部件放入專家知識庫中,形成作戰任務庫、條件庫、超參數庫和動作函數庫。基于知識的決策算法主要負責行為的推理決策,以FSM、BT的形式編程。群隊級所有作戰力量按照類型進行分組,而后為每個類型組設計有限狀態機,為了簡單起見,本文為所有類型組設計了通用有限狀態機。另外,我們需要為類型組內的每個棋子分配合適的奪控點作為作戰目標。基于知識的決策算法完成多agent的動作名稱輸出,即FSM生成類型組當前的作戰任務,BT生成當前作戰任務下單個agent的動作名稱、任務區域和指標權重。基于數據驅動的決策算法以任務區域和指標權重為參數,調用任務區域對應的多個評價指標,根據軟概率優選和路徑算法,最后生成棋子移動路徑作為動作參數。
行動模塊為每一個棋子生成原子動作命令。原子動作命令是兵棋對抗環境能夠識別的棋子動作。專家建模了動作函數庫,動作函數以動作名稱和動作參數為輸入,經過基于兵棋規則的合法性篩查后,輸出多agent原子動作序列。需要特別指出的是,動作參數并不是都需要計算,如狀態轉換、上車、下車、奪控等只需要實體對象作為參數,通過簡單的邏輯判斷就可以得出。但是機動路線、行軍路線、射擊目標選擇等都是需要計算評估后才能得到合適的動作參數。
3 群隊級兵棋AI主要模塊設計
3.1 作戰目標點分配和通用有限狀態機設計
群隊級兵棋AI的棋子按照類型進行分組,小組內每個棋子可以復用相同的行為樹進行決策,但是為了避免小組內棋子行為趨于一致,需要為小組內每個棋子指定不同奪控點為作戰目標。我們以距離為匹配標準,均勻分配奪控點給同類型的棋子。以士兵為例,分配算法如下。

* 設定未被選擇奪控點集合open,包括所有奪控點,集合close為空集* 對每個步兵棋子i進行循環:* 從open集合中找到與i機動時間最小的奪控點j,將j分配給棋子i,open集中去除j,close集中增加j* 當open集合為空時,初始化open和close集合
為了減小設計工作量,給全部作戰力量按照棋子類型進行分組后,我們僅設計一個通用有限狀態機供紅藍雙方所有類型組使用,如圖5所示,作戰分為3個階段:機動滲透階段、中遠攻擊階段和奪控階段,并且設計了轉移條件。這些狀態和轉移條件組成作戰任務庫和條件庫。
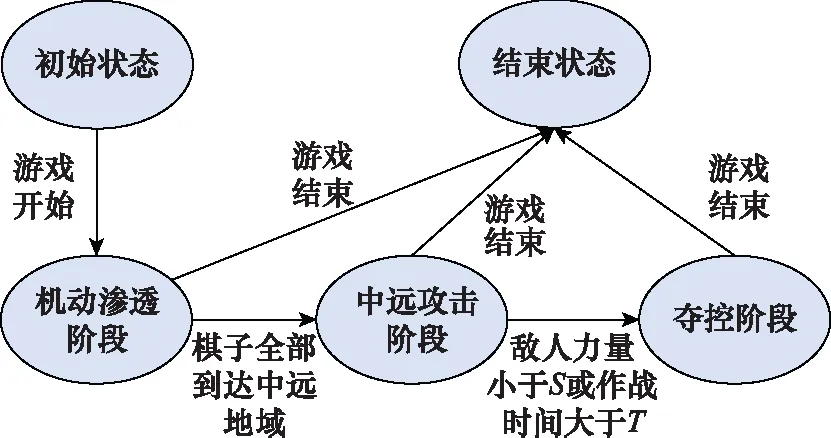
圖5 通用FSM狀態轉移圖Fig.5 General state transition diagram of FSM
3.2 基于棋子類型的行為樹設計
通用FSM設計好之后,需要按照3個作戰階段為每個類型的棋子設定行為樹,這里以紅方步兵、裝甲車為例,描述這些類型棋子的作戰內容,如表1所列。最后根據作戰內容,為每類棋子設計行為樹。
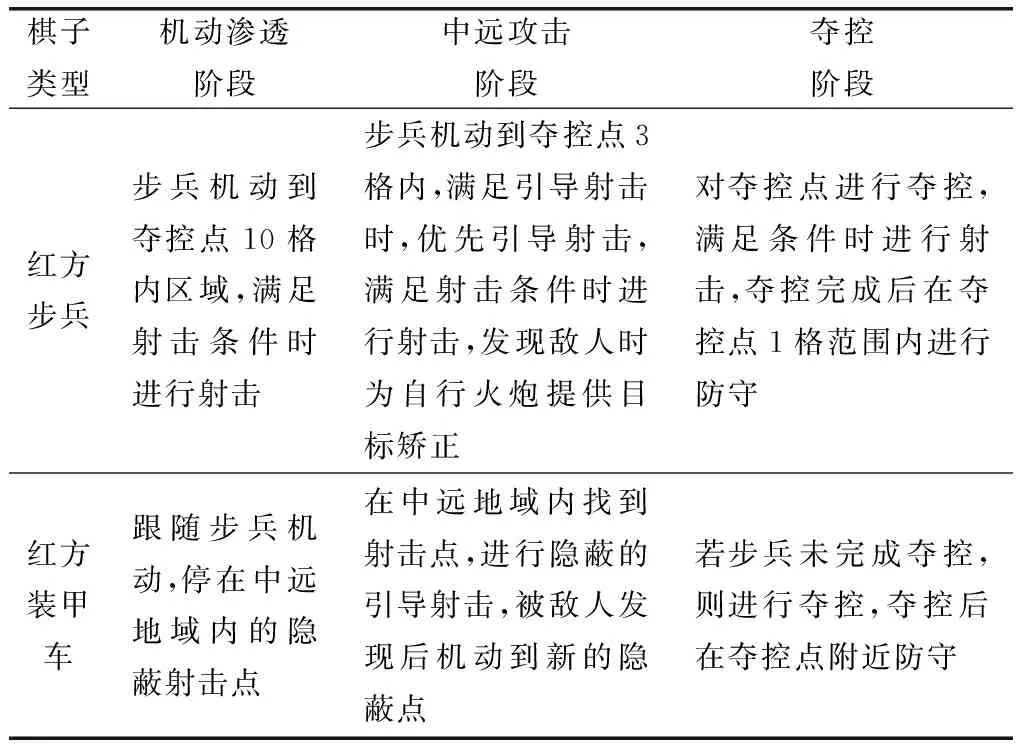
表1 紅方步兵和裝甲車各作戰階段的作戰內容
3.3 基于共享內存的多進程機制
Python語言環境有兩種方式支持并行計算:多線程(調用threading模塊)和多進程(調用multiprocessing模塊)。但是Python多線程受全局解釋器鎖(global interpreter lock, GIL)限制,不能實現真正意義上的并行計算。本文使用多進程實現多指標并行計算。共享內存是最快的IPC(inter-process communication)方式,它是針對其他進程間通信方式運行效率低而專門設計的,本文采用這種方式進行IPC。共享內存的方法就是在主進程中建立共享內存對象,它包括3個方法:初始共享內存建立、數據存儲和數據讀取。這個共享內存對象可以被不同進程調用,并傳遞數據。本文以多進程和共享內存通信實現文獻[12]介紹的位置評價指標的并行計算。
4 兵棋AI實現和對抗性能
4.1 兵棋AI編程實現
本文基于戰術級兵棋即時策略推演平臺“廟算·智勝”開發實現了一個群隊級兵棋AI。該群隊級兵棋AI使用python語言,采用結構化、對象化的思想進行編程。兵棋AI能夠運行之后,還需要對決策模塊進行優化:
(1) 優化知識數據。開啟自對戰模式,收集復盤數據并離線增量更新知識數據。如果有其他復盤數據集,也可以基于這個復盤數據集更新知識數據。
(2) 優化超參數。專家根據機機對抗的復盤回放,觀察兵棋AI的動作執行效果。針對AI決策效果弱的地方,調整超參數庫中的任務區域和指標權重,使兵棋AI在移動位置選擇上策略更優。
我們實現的群隊級兵棋AI支持2張地圖共3個想定,命名為“道·思-group”。
4.2 對抗性能分析
“道·思-group”參加了全國“先知·兵圣-2019”戰術級人機對抗挑戰賽,取得前8名。因為比賽使用的是預設想定,其他隊伍可以按照專家制定的作戰方案指導棋子的行為決策。相比較而言,我們的兵棋AI在作戰效果上并不特別突出。
隨后,“道·思-group”參與了“廟算·智勝”人機對抗平臺組織的AI綜合能力測評。測評對象為國內主要的5個兵棋AI團隊開發的群隊級兵棋AI。
表2給出了5支AI隊伍的機機對抗勝率。在既定想定的機機對抗中,“道·思-group”排名第4,展現了一定智能性。另外,測試組設置了臨機想定。臨機想定改變了作戰力量的規模和奪控點的個數。在臨機想定測評中,“道·思-group”的勝率由24%上升到46.5%,展現了基于通用FSM的設計,其可移植性較強的特點。
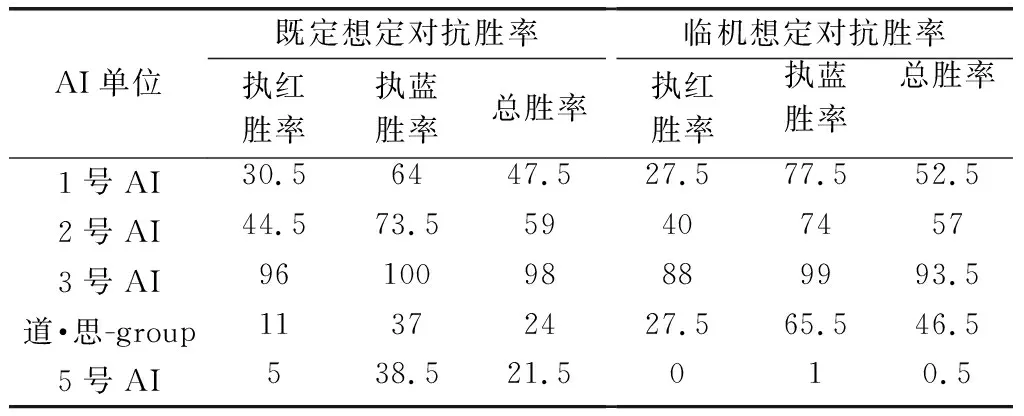
表2 群隊級兵棋AI對抗勝率
但是總體對抗成績不高,也反映了只使用通用FSM,使多agent作戰任務的劃分不夠精細,棋子間的協同配合不夠,整體作戰策略優化不好。使用雙進程指標并行計算方式,對計算資源的要求較大,指標計算子進程運算耗時長,計算出的指標與實時態勢不匹配,從而影響了決策質量。
“廟算·智勝”測試組最后總結:測評的AI可以分為基于算法驅動和基于方案設計2類,基于算法驅動的智能體具有更好的地形分析計算和利用能力,火力使用更為敏捷和激進;基于方案設計的智能體則表現更為保守,射擊頻次和戰果更少,但卻通過更少的戰損,以及較高的有效射擊效率贏得對抗的勝利。臨機想定中設置了與既定想定較大的差異,基于方案設計的團隊多采用精細化方案設計,智能體模型更擅長打“有準備之仗”,但遇到新情況后,原方案可能會失效;基于算法驅動的團隊多采用算法驅動的智能體模型,在戰場態勢發生突變時,具有更好的應變與穩定性。
得益于知識與數據互補的決策算法,我們的兵棋AI應屬于算法驅動類型。有以下優點:
(1) 兵棋AI構建較為快速。FSM和BT分層決策的方法符合軍事組織指揮的架構和任務分解模式,且免除了具體地圖點的分析。基于數據驅動的決策方法無想定限制。基于可復用的領域知識庫,只需要對FSM與BT進行簡單的再設計,即可構建新的兵棋AI。
(2) 模型具有較高的靈活性和遷移性。每個兵棋想定中奪控點、起始點為已知點,以這兩類點為定位點,設計相對位置的任務區域,并且增大任務區域范圍,就可以提高決策模型的遷移性。另外,多指標綜合評價軟優選算法中探索因子增大后,決策模型的靈活性就會大大增加。
5 結 論
本文分析了群隊級兵棋智能對抗中控制大量兵棋實體面臨的困難,提出了知識與數據互補的決策算法,解決了無人類復盤數據情況下,實現棋子行為的靈活決策。我們提出了按棋子類型分類、分配奪控點為作戰目標、位置評價指標并行計算等方法,解決了知識與數據互補的決策算法控制大量實體存在的困難,設計了群隊級兵棋AI的技術框架。最后我們實現了群隊級兵棋AI“道·思-group”,此AI在全國智能兵棋比賽和第三方測評中性能表現優異,顯示出了設計簡單、決策靈活和可遷移的特點。
但是使用通用有限狀態機,雖然簡化了設計難度,但是整體策略不夠精細,導致高層策略并不是很優。另外,并行計算只是部分解決了計算時間問題,此兵棋AI依然存在計算量大、占用內存大的問題。下步將從3個方面做深入研究,一是設計更為通用的FSM和BT決策體系,并研究HTN等自動規劃算法,使模型的可遷移能力更強,并可以自主規劃作戰任務;二是優化基于數據驅動的軟決策體系,提升計算效率,同時利用深度神經網絡的感知能力對評價指標進行計算;三是研究超參數的自動優化方法,減少專家工作量,同時提升模型決策能力。
猜你喜歡
作文周刊·小學一年級版(2022年16期)2022-05-07 11:28:30
作文周刊·小學一年級版(2021年8期)2021-07-07 11:00:47
動漫界·幼教365(大班)(2021年4期)2021-05-23 21:33:16
小學生作文(低年級適用)(2018年3期)2018-04-17 00:58:35
少年博覽·小學低年級(2017年4期)2017-06-09 16:22:28
作文周刊·小學一年級版(2016年28期)2017-06-03 00:28:49
作文評點報·低幼版(2017年7期)2017-03-11 20:49:41
少兒科學周刊·少年版(2015年4期)2015-07-07 20:56:37
電影故事(2015年30期)2015-02-27 09:03:12
七彩語文·低年級(2014年10期)2015-01-14 14:46:27
