以機器學習為內核的網絡入侵檢測模型研究
2022-09-14 08:08:28顧凌云
中文信息 2022年6期
顧凌云
(上海冰鑒信息科技有限公司,上海 200120)
引言
網絡安全維護是一項非常復雜的系統工程,僅靠傳統單一的防御手段和低級別的技術手段難以達到理想效果,借助更高水平的網絡入侵檢測技術解決此類問題的趨勢不可阻擋。筆者在此解析了網絡入侵及檢測、機器學習的概念,分析了支持向量機、蟻群算法等原理,然后構建基于機器學習的網絡入侵模型,最后對模型檢測質量予以實驗驗證。
一、基本概念解析
1.網絡入侵及檢測技術
網絡入侵是以網絡為渠道的非法侵害行為。當前較為常見的網絡入侵路徑主要包括經協議缺陷入侵、經系統漏洞入侵和以病毒程序寄生系統。所謂的網絡入侵檢測,是專門針對網絡入侵行為做出的反應,即監測、發現存在的各種已知和未知的網絡訪問異常并對其做出警示,其入侵檢測系統(IDS)主要由數據包嗅探、數據預處理器、網絡檢測引擎、報警和日志模塊四部分構成(見圖1)。數據包嗅探主要負責監聽網絡數據包,對網絡行為進行數據采集;數據預處理器對網絡數據包內容進行初步提煉,發現原始數據中的“異常現象”,形成可供分析的結構化的數據內容;檢測引擎依據預先設置的相關規則來檢查數據包,一旦發現異常立即反饋給報警模塊;報警和日志模塊就是存儲引擎提供的異常信號并發出警示[1]。

圖1 網絡入侵檢測系統結構圖
2.機器學習
機器學習(Machine Learning)是一種基于大數據環境的計算機模擬人類學習行為的過程。它可以在一定程序設定下進行類人學習活動并且具備自動重組已有知識結構實現功能升級的能力。機器學習涉及眾多算法,任務和學習理論,從任務類型來看,機器學習模型可包括回歸模型、分類模型和結構化學習模型;從學習方法層面來看,機器學習可分為線性模型和非線性模型,非線性模型包括SVM、KNN等傳統模型和深度學習模型;此外根據學習理論還可以將其劃分為有監督學習、半監督學習、無監督學習、遷移學習和強化學習幾種[2]。
二、網絡入侵檢測的相關原理
1.支持向量機
支持向量機(SupportVectorMachine,SVM)是一種二分類模型,它的基本模型是定義在特征空間上的間隔最大的線性分類器,其學習策略便是間隔最大化;SVM最基本的應用是分類,其學習算法就是求解凸二次規劃的最優化算法,即求解最優的分類面[3]。SVM性能優異屬于專門針對小樣本的機器學習算法,其工作原理類似于神經網絡,是基于結構風險最小化理論之上在特征空間構建最優分隔超平面,以此讓學習器實現全局最優化,并且在整個樣本空間的期望風險以某個概率滿足一定上界,其原理如圖2所示。

圖2 最優分類平面的示意圖
以函數φ(x)對具有n個樣本的集合{(x1,y1),…,(xi,yi),…,}(xn,yn)進行映射處理,樣本劃分也在映射空間進行,以關系式表示:
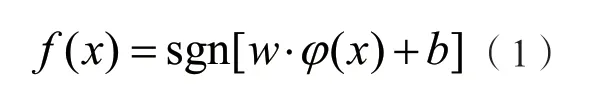
該算式中以w作為權值,以b表示閾值。通過找到最優的w值和b值從而確立最優分類平面,但是要想以直接求解算式(1)而得出最優的w與b值并不容易,可以依據結構風險最小化原理,設置約束關系式:

處于快速建模考慮,可以采用松弛變量ξi來折中處理分類精度及分類誤差,得到如下形式的最優分類平面:

針對上式的越約束條件為:

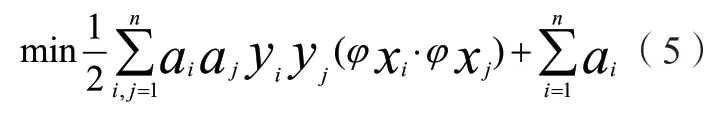
其約束條件設置為:
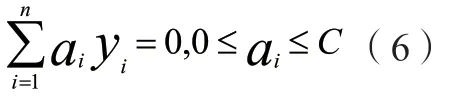
然后基于非線性分類相關問題,將核函數k(xi,xj)引入算式(5)則可以得到:

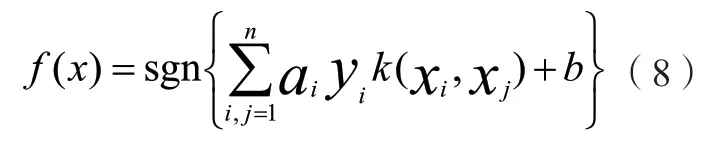
選擇徑向基函數,由此得到:

上面算式中σ代表核寬度參數值。
2.網絡入侵檢測中的參數影響作用
結合以上支持向量機的工作原理,經過分析我們可以發現,參數核寬度參數σ和測算誤差懲罰參數C能夠對機器的學習性能產生一定影響。在此選擇一批訓練樣本,對其不同參數條件下的網絡入侵檢測準確度進行分析,得到如表1所示結果。
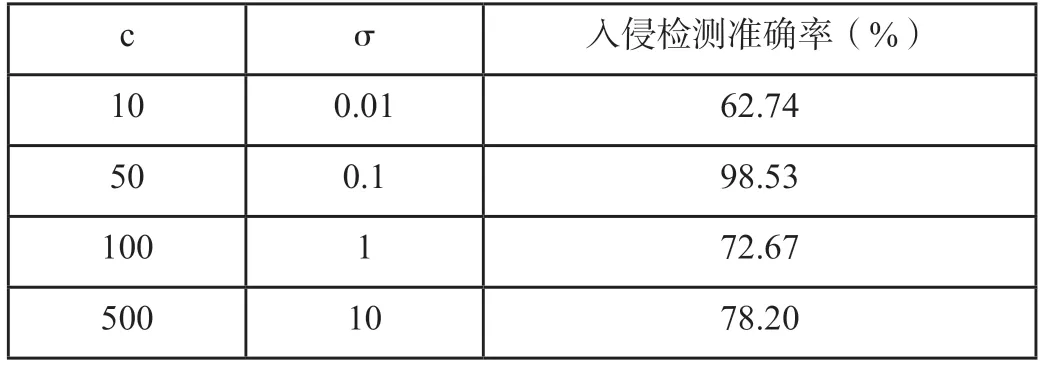
表1 參數C與參數σ對支持向量機學習性能的影響情況
由對表1數據的分析可以發現,即便在相同環境和數據條件下,不同參數的入侵檢測效果依然會出現較大差異,所以必須選擇最優的C和σ參數值。
3.蟻群算法
螞蟻在覓食過程中分工明確,工蟻會在覓食路線和食物附近留下具有自身獨特辨識性的生物信息素,從而便于其他螞蟻跟從,留下的信息素濃度越高則越便于蟻群識別,并將食物順利搬入巢穴[4]。蟻群算法就是基于這種生物特征的一種非常形象的信號線索優化算法。該算法的基本工作原理詳見圖3所示。
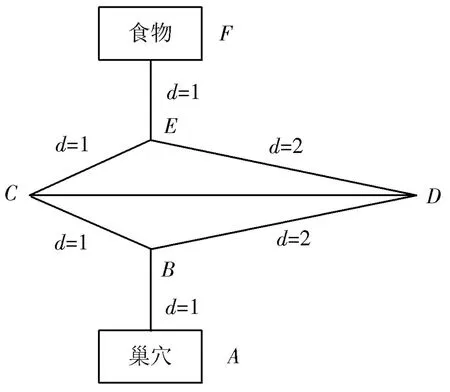
圖3 蟻群算法的工作原理
如果假設螞蟻數量為m,可以得到以下計算公式:

算式中bi(t)指的是 節點i上的螞蟻數量。那么在t時刻,i節點和j節點上的路徑 (i,j) 所留下的螞蟻信息素濃度可以表示如下:

其中τij(t)就是( i,j)路徑上的信息素濃度。
當蟻群算法初始點τij(t)(0)= 0,那么螞蟻對于下一個節點選擇的轉移概率可以按照以下算式進行計算:

上式中:ηj表示從i節點轉移到j節點的局部啟發信息;allowed k代表沒有訪問的節點集合;α與β則代表權重參數。經過一段時間蟻群在完成一次路徑搜索后開始尋找新的路徑信息素,可以表示為以下關系式:


算式中Q是一個常量;LK表示的是該次循環的總時間數。
三、基于機器學習的網絡入侵模型構建
結合上述算法原理,采用如下算法邏輯對網絡入侵檢測中的參數進行優化:

網絡入侵檢測步驟如下:
步驟一:收集有關于網絡狀態的所有信息并從中提取出網絡入侵檢測特征,然后對這些特征進行以下處理:

步驟二:以支持向量機中(c,σ)作為一種蟻群爬行路徑,結合各組參數中的網絡入侵檢測訓練樣本構建檢測模型,從而可以獲得不同的檢測準確率。
步驟三:根據更新操作蟻群信息素以及節點轉移,以此實現路徑爬行,然后按照路徑最優原則找到最佳的(c,σ)參數組合。
步驟四:利用得到的最佳(c,σ)參數組合來構建最優的網絡入侵檢測模型。鑒于支持向量機僅有兩種類型的劃分,而網絡入侵行為多種多樣,文章中的多分類器使用“一對一”的方式來構建。
四、 網絡入侵檢測效果驗證
本次實驗測試對象為KDD Cup網絡入侵檢測數據集,其主要的網絡入侵行為:包括DoS、U2R、R2L幾種。我們從該龐大數據集中隨機選取其1/10數據進行實驗。為測試本文構建的(ACO-SVM)模型效果,將其與BP神經網絡(BPNN)和遺傳算法SVM(GA-SVM)網絡入侵檢測模型進行對比,并進行評價:
結語
加強網絡入侵檢測是確保網絡安全的重要手段,以機器學習為核心的網絡入侵檢測模型相比于傳統網絡防控技術具有獨特的技術優勢。通過試驗證實以機器學習為主的網絡入侵檢測模型,不但可以更加準確地檢測出多種復雜入侵行為,而且檢測的效率更高,因此具有極其廣闊的應用和發展前景。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
