面向強化學習的虛擬鏈路智能體仿真環境研究
2022-09-28 10:49:00戢澤民徐野哈樂
科技資訊 2022年19期
戢澤民 徐野 哈樂
(1.沈陽理工大學自動化與電氣工程學院 遼寧沈陽 110159;2.北部戰區總醫院醫學工程科 遼寧沈陽 110000)
1 研究意義
截至2019 年6 月,全國汽車保有量達2.5 億輛,私家車達1.98 億輛。對交通領域發展而言,當前交通安全事故已經成為最大的問題。使用車輛不斷增多,引發的交通安全事故也在不斷增多[1]。人們對于汽車各個方面的性能要求也在不斷升高,自動駕駛汽車便成為了解決這一問題的有效手段,隨著5G 時代的來臨,自動駕駛汽車的發展備受關注[2]。國外著名的汽車公司和IT巨頭正在競相深入研究無人駕駛汽車技術,如IT 互聯網企業、傳統的汽車制造商企業[3]。國內早期自動駕駛汽車由各大高校和研究院所對智能車輛的技術的研究[4]。
強化學習就是研究每個狀態應該以什么樣的策略選擇動作,使得整個序貫決策時最優的[5]。所謂強化學習是一種以環境反饋作為輸入的、特殊的、適應環境的機器學習方法,它的主要思想是與環境交互和試錯,利用評價性的反饋信號實現決策的優化[6]。2013 年,DeepMind 團隊將Q-Learning 與深度學習相結合提出深度Q網絡(Deep Q-Network,DQN)[7]。強化學習算法與理論的研究為人工智能的復雜問題求解開辟了一條新的途徑,強化學習的基于多步序列決策的知識表示和基于嘗試與失敗的學習機制能夠有效地解決知識的表示和獲取的問題[8]。當前,為了提升模型的表征能力,研究者們將深度神經網絡引入強化學習中,二者優勢互補,形成了能在復雜環境中感知并決策的深度強化學習算法[9]。不同于深度學習側重于感知和表達,強化學習側重于尋找解決問題的策略,強化學習中的智能體在與環境交互的過程中,為了獲取更大的累計獎勵值而不斷優化動作策略,當累計的獎賞值達到最大后且穩定,意味著學習到全局或局部最優策略[10]。
2 環境分析
2.1 基本要素分析
道路的環境包括天氣、道路等級、道路類型、路況、汽車數據、行駛環境。其中天氣包括晴/陰/多云、雨、雪、霧。道路等級及各道路限速情況如表1所示。
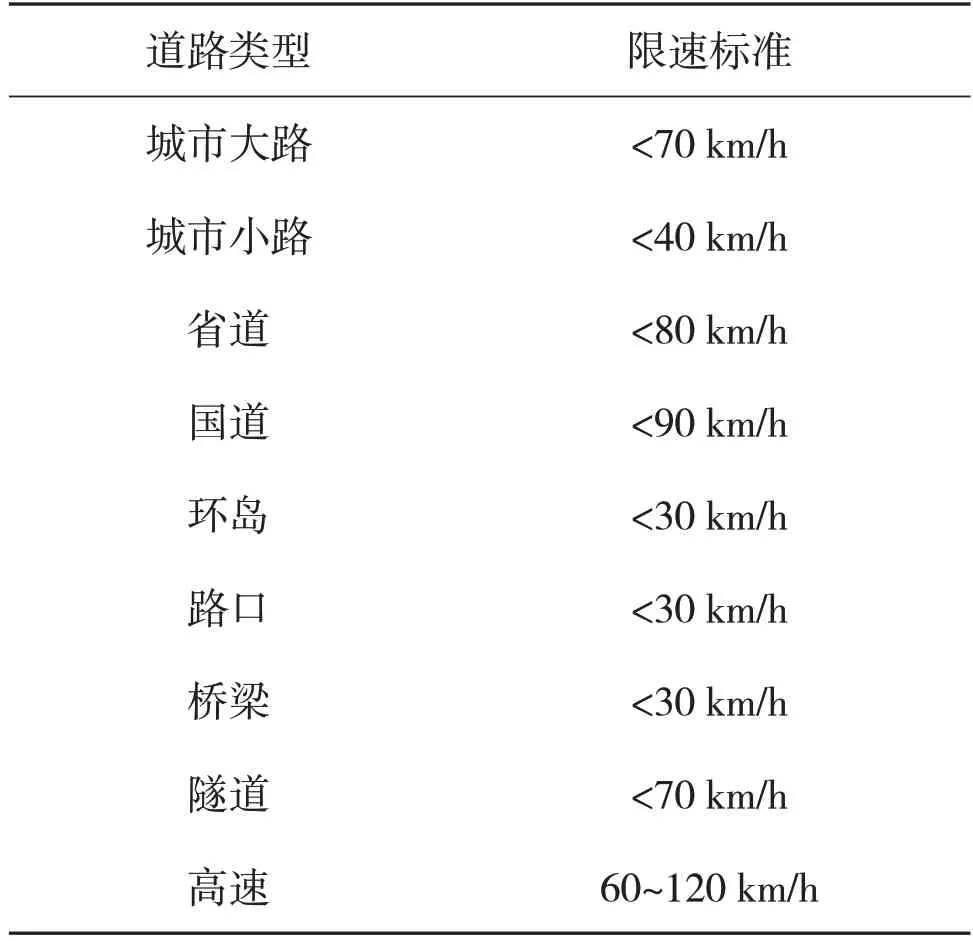
表1 我國各道路類型的限速標準
考慮行駛動作更加直觀,將行駛動作包括加速、減速、急加速、急減速和勻速。擁堵情況的設置考慮真實世界的復雜性與隨機性,將擁堵情況設置為1 000 m之內隨機產生車輛擁堵和紅燈擁堵,汽車數據中的行駛里程按照百分制的方式記錄,速度表示小車行駛的真實速度。速度公式為

2.2 獎勵設置
該文分別設置行駛動作本身所產生的獎勵,行駛動作導致車輛狀態的改變所產生的獎勵,以及小車在行駛途中產生撞車或者到達目的地游戲結束所產生的獎勵,具體如表2所示。
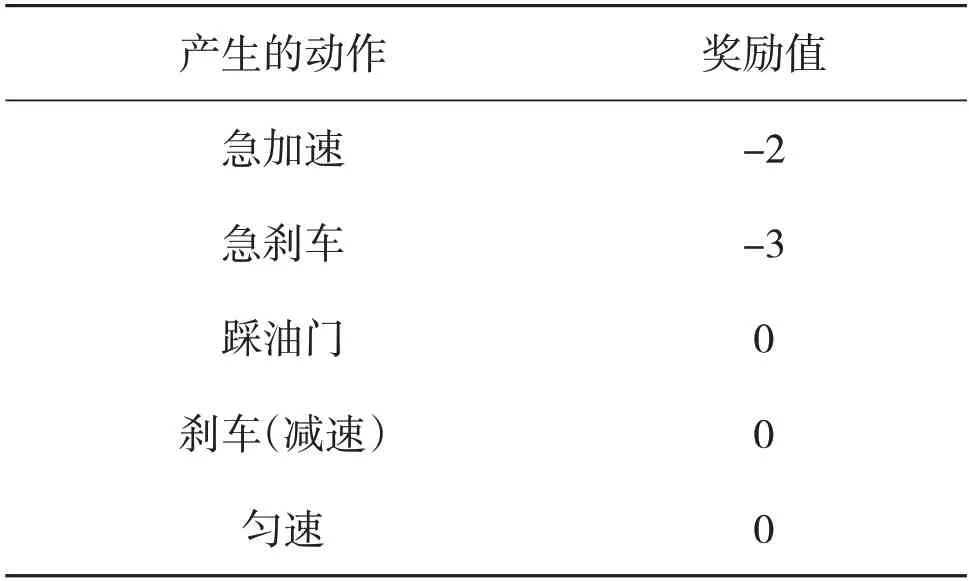
表2 動作本身所產生的獎勵
2.3 其他要素
考慮汽車在行駛途中會進行加速、減速,急加速、急減速等一系列的操作所帶來動作本身的影響和動作導致狀態改變的影響,必須要給出一定的界限來區分。再參考汽車之家的數據,該文對正常加速、正常減速、急加速、急減速的判定:加速度a=-1.11 m/s2為正常減速,加速度a=-3.09 m/s2為急減速。加速、急加速的判定:加速度a=1.11 m/s2為正常加速,加速度a=3.09 m/s2為急加速。
狀態改變所產生的獎勵見表3,天氣對速度影響的獎勵見表4。考慮現實世界中極端天氣對汽車速度的影響,這里也會在加速度后乘以一個折扣因子b,這里的折扣因子會因天氣的改變而改變。在由于折扣因子的影響,此時智能體得到的實際加速度a'=動作本身產生的加速度ax折扣因子b。規定晴天時折扣因子b=1,霧天時b=0.95,雨天時b=0.85,雪天時b=0.6。智能體產生其他動作時與其類似。綜上所述,方案流程圖如圖1所示。
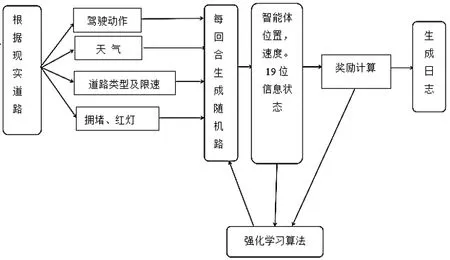
圖1 訓練環境搭建流程圖
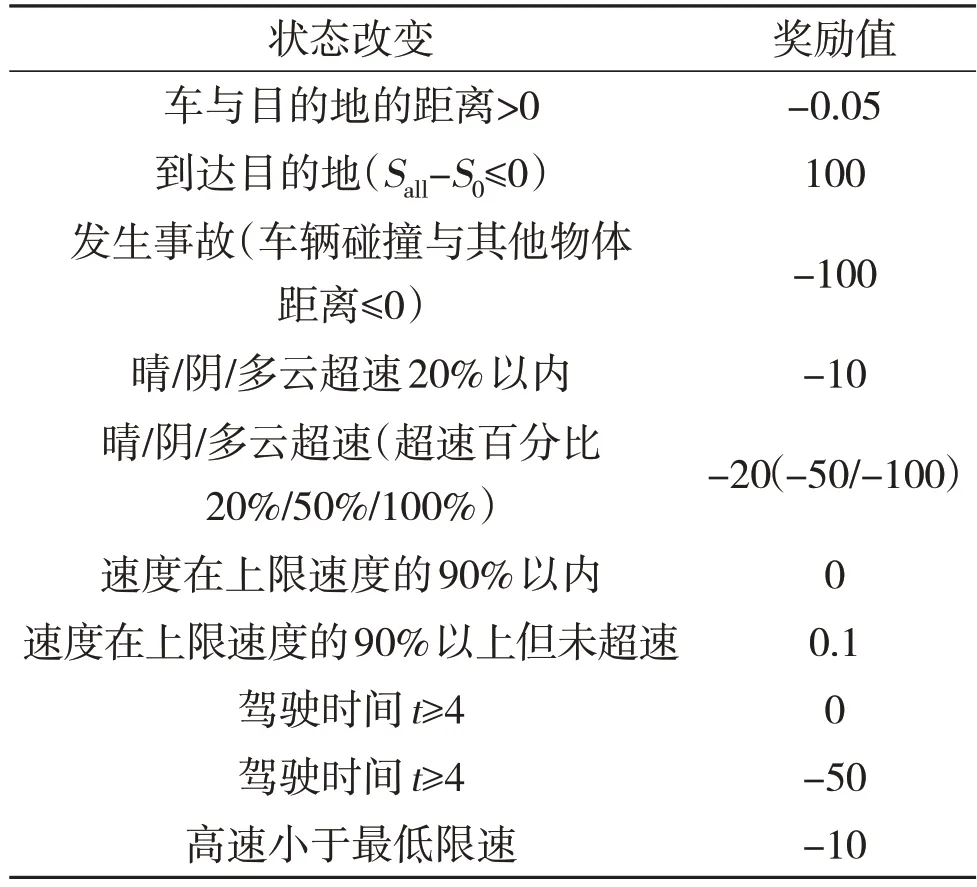
表3 狀態改變所產生的獎勵
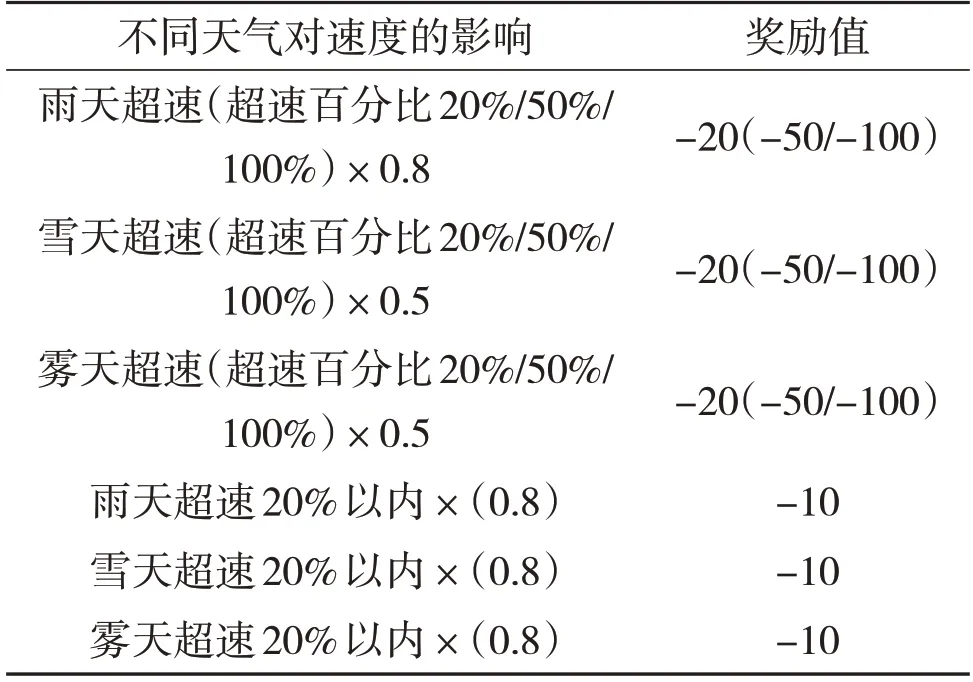
表4 天氣對速度影響的獎勵
3 環境實現
3.1 基本文件配置
該文在pycharm 中通過python 來實現環境道路天氣動作獎勵等。建立配置文件,例如道路類型/天氣狀況/堵車位置/行駛動作等。建立用來隨機的產生一種道路類型。生成一個19位的向量,其中天氣4位,道路類型9位,紅綠燈擁堵1位,總時長1位,疲勞駕駛時長1 位,汽車位置1 位,汽車速度1 位,日夜行駛1 位。該文采用0 或1 來表示無或有,多位向量中其中一位為1,其余則為0來表示。建立一個step,游戲世界的1秒為一幀,計算狀態、獎勵等。
3.2 獎勵的實現
首先要判斷智能體是否達到終點,若沒到達終點,則給予智能體一個負獎勵,其中設置每幀判斷智能體是否到達終點,每幀的獎勵都進行累加。流程圖如圖2所示。
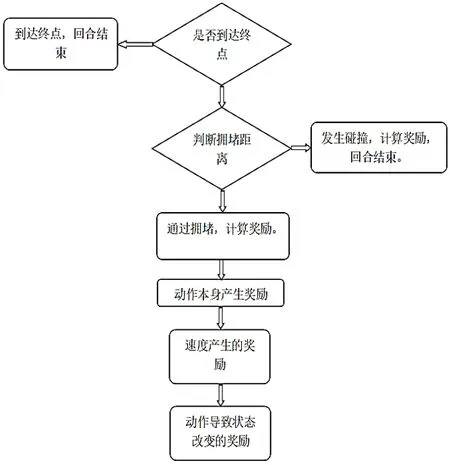
圖2 產生獎勵的順序
3.3 環境與智能體的交互
智能體根據當前狀態和動作,以每秒為一幀,計算獎勵,選出下一動作,作用于環境。環境反饋新的道路、天氣、擁堵、日夜等狀態。每一幀的動作獎勵和動作導致狀態獎勵都在進行累加。每幀過程不斷地重復,直到游戲結束。
4 仿真結果
在該文中,配置了text.py 用來進行測試本環境的搭建是否可用。如圖3所示,第一行運行時間為1 s,第三行路長為567 100,進行歸一化的位置=智能體當前位置/路總長。速度為9.455 4 km/h。19個狀態對應參考該文第3.1節。圖4為新一回合的智能體的信息,這里可以看到相較于圖1 有較多的改變。圖5 為使用強化學習算法DDQN 對該環境進行150 回合訓練的結果。在進行了20回合左右,智能體已經能夠得到較高的獎勵,說明智能體在面對該靜態虛擬鏈路時效果有所提高。

圖3 運行1秒時的智能體信息

圖4 新一回合的智能體信息
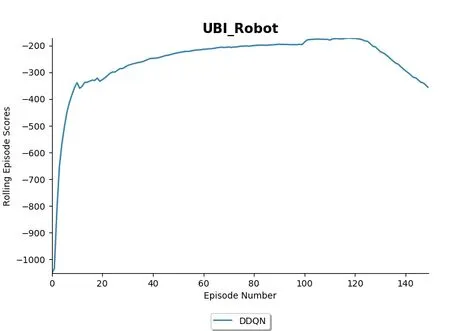
圖5 使用DDQN進行訓練
5 結語
基于強化學習靜態虛擬道路用戶駕駛行為的智能體訓練環境研究。將現實世界汽車行駛的道路、天氣、路況等對用戶駕駛的影響考慮到虛擬環境中。使用DDQN 算法對其進行測試,智能體每回合得到的獎勵逐步提高,說明搭建的環境以及設置的獎勵值可靠有效。
猜你喜歡
文苑(2018年23期)2018-12-14 01:06:06
文苑(2018年19期)2018-11-09 01:30:14
文苑(2018年17期)2018-11-09 01:29:26
文苑(2018年21期)2018-11-09 01:22:32
小學生作文(低年級適用)(2018年3期)2018-04-17 00:58:35
兒童時代·快樂苗苗(2017年7期)2018-01-24 18:28:45
少年博覽·小學低年級(2017年4期)2017-06-09 16:22:28
作文評點報·低幼版(2017年7期)2017-03-11 20:49:41
作文大王·低年級(2016年4期)2016-04-18 00:24:37
少兒科學周刊·少年版(2015年4期)2015-07-07 20:56:37
