視頻描述中多參考語義生成網(wǎng)絡
2022-11-17 03:44:44楊大偉
大連民族大學學報 2022年5期
高 航,楊大偉,毛 琳
(大連民族大學 機電工程學院,遼寧 大連 116605)
視頻語義信息常被用來提升視頻描述性能,但視頻中場景、對象和行為等因素較為復雜,語義特征不能夠?qū)σ曨l內(nèi)容充分表示,影響視頻描述準確性。目前主流的視頻描述模型多采用編碼-解碼框架,提取視頻特征的編碼器一般采用卷積神經(jīng)網(wǎng)絡[1](Convolutional Neural Networks,CNN)、長短時記憶(Long Short-Term Memory,LSTM)[2,3]等循環(huán)神經(jīng)網(wǎng)絡(Recurrent Neural Network,RNN)[4]作為解碼器生成文本描述。語義特征作為一種有效的編碼特征在視頻描述中較為常見,Tu等[5,6]通過Fast R-CNN獲取目標語義特征,將其與卷積特征一同送入LSTM輸出視頻描述,該方法有效捕捉了視頻中的目標,但不能充分地表示其屬性和行為。Nayyer等[7]使用目標檢測算法和3D卷積獲取目標和行為語義信息[8],得到較好的視頻描述結果,表明豐富的特征內(nèi)容有利于提升網(wǎng)絡性能。Vasili等[9]提出多模態(tài)視頻描述,將視覺特征、聲音特征和表示視頻主題的行為語義特征作為輸入,融合多個信息源以求得到準確的文本描述,但并非所有聲音特征都能表達視頻場景,存在特征冗余問題,且少量標簽的語義特征不能充分地表達視頻內(nèi)容。為解決上述問題,Gan等[10]提出用于圖像和視頻描述的語義檢測網(wǎng)絡SCN,采用多層感知機[11](Multilayer Perceptron,MLP)提取更多分類標簽的詞匯語義特征,但視頻或圖像中場景等因素較為復雜,簡單MLP獲取的語義信息不夠豐富,從而影響描述效果。Chen等[12]提出語義輔助視頻描述網(wǎng)絡SAVC(Semantic-assisted video captioning network),采用卷積網(wǎng)絡提取視覺特征,將語義特征作為視覺特征的輔助生成文本描述,與SCN類似,MLP獲取的語義特征表達能力不足,影響文本描述效果。
為獲取表征能力更強的詞匯語義信息,提升視頻描述性能,本文提出視頻描述中多參考語義生成網(wǎng)絡(Multi-Reference Semantic Generation Network for Video Captioning,MRNet)。該網(wǎng)絡通過多參考MLP結構生成語義特征,在MLP獲取語義特征過程中引入視覺信息,利用視覺信息對特征進行補充和調(diào)整,豐富語義特征內(nèi)容并提高其準確程度。MRNet還具備殘差結構緩解網(wǎng)絡退化現(xiàn)象等優(yōu)點,在保證視覺信息完整表達的基礎上,實現(xiàn)了語義特征表達能力的增強。
1 MRNet算法
MLP獲取的語義信息常被用來提升視頻描述性能。SAVC網(wǎng)絡利用語義信息輔助視覺特征生成文本描述[12],語義信息輔助的網(wǎng)絡一般形式如圖1。
語義生成網(wǎng)絡獲取語義特征y的數(shù)學表達如下:
y=σ3(F3(σ2(F2(σ1(F1(x))))));
(1)
F(x)=Wx+b。
(2)
式中:x為輸入的視覺特征;F1、F2和F3為MLP三層處理函數(shù),獲得途徑如式(2);σ(·)表示相應層激活函數(shù)。
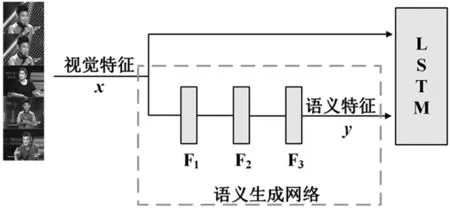
圖1 SAVC結構示意圖
由于常規(guī)MLP結構提取語義特征的能力有限,由此構建多參考語義生成網(wǎng)絡—MRNet,在語義提取過程中融合視覺信息,以視覺信息為參考對特征進行補充和修正,增強特征有效性和準確性,參考型MLP分為單參考和多參考兩種形式,多參考MLP由單參考MLP結構復用而來,可以進一步提升語義特征的表達能力。
1.1 單參考MLP結構
本文在MLP基礎上引入其他通道信息,形成單參考MLP結構,網(wǎng)絡結構如圖2。
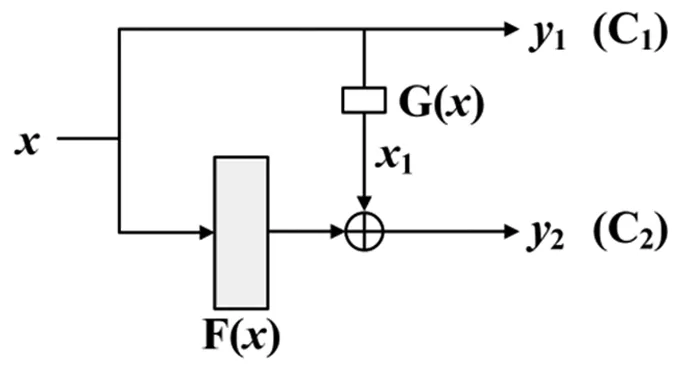
圖2 單參考MLP結構
單參考MLP結構數(shù)學表達如下:
y1=x;
(3)
y2=σ(F(x)+x1);
(4)
F(x)=Wx+b;
(5)
x1=G(x)。
(6)
式中:x是雙通道網(wǎng)絡結構的輸入;C1、C2代表通道1和通道2;y1和y2是兩個通道的輸出;函數(shù)F(x)表示MLP對特征的處理;W和b是權重和偏置,W與x做全連接計算。x1是輸入特征x的恒等映射,當F(x)與x維度不一致時,G(x)采用池化或resize上下采樣等方式調(diào)整x的維度,x可表示為x={s0,s1, …,sn},x1、y2均為此形式特征向量,且x1、y2維度相同。
特征x在通道1直接輸出,與簡單MLP結構不同,通道2的單參考MLP結構引入了參考信息x1,在MLP對特征進行萃取的過程中,以其他通道信息作為參考和補充使特征表達更加充分,增強特征的表征能力。且該結構與殘差類似,以捷徑連接方式將MLP處理結果與原始特征相加,通過優(yōu)化殘差單元得到更有效的輸出特征,由于在特征提取過程中融入原始特征x,故可保證原始信息的完整表達。
1.2 多參考MLP結構
隨著分類能力需求的增強,MLP的層數(shù)逐漸增多,由此可將單參考結構復用,形成多參考MLP結構如圖3。
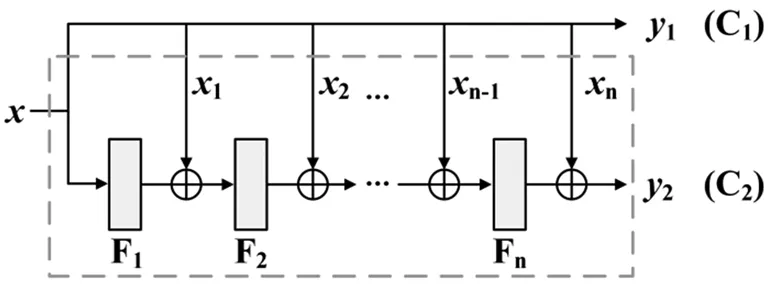
圖3 多參考MLP結構
多參考MLP結構數(shù)學表達如下:
y2=σn(Fn(…(σ2(F2(σ1(F1(x)+x1))+x2))…)+xn);
(7)
Fn=Wnσn-1(Fn-1+xn-1)+bn。
(8)
式中:x是網(wǎng)絡的輸入;y1、y2是兩個通道輸出;F1、F2、…、Fn表示MLP每一層處理;x1、x2、…、xn表示特征x的恒等映射,此處將調(diào)整維度的G(x)省略。
將MLP每一層輸出與x的恒等映射相加,其本質(zhì)是一種逐層嵌套的殘差MLP,利用這種本質(zhì)形式直觀地分析多參考MLP的結構特點如圖4。
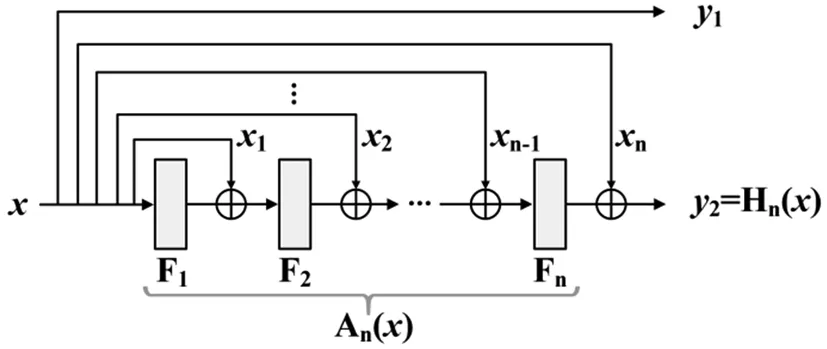
圖4 多參考MLP結構的本質(zhì)分析
多參考MLP結構的本質(zhì)分析數(shù)學表達如下:
Hn(x)=Fn(…(F2(F1(x)+x1)+x2)…)+xn;
(9)
An(x)=Fn(…(F2(F1(x)+x1)+x2)…) ;
(10)
Hn(x) =An(x)+xn。
(11)
將公式(7)中激活函數(shù)省略,且第n層輸出定義為Hn(x),得到公式(9)。將引入xn之前的處理設為An(x),則有公式(11),可知網(wǎng)絡第n層確是一種殘差連接,且進一步可知多參考MLP的每一層均實現(xiàn)了這種殘差連接,可有效解決網(wǎng)絡退化等問題。不同的是,本文在每一層引入原始x,可確保特征中原始信息的完整表達,利用原始特征的補充和參考作用豐富特征內(nèi)容進而提升其表達能力。
1.3 網(wǎng)絡模型
為獲取表達能力較強的視頻語義特征,基于本文提出的以上結構設計多參考語義生成網(wǎng)絡MRNet,以視覺特征為參考,由3層多參考MLP結構生成語義特征,將該語義生成網(wǎng)絡應用于視頻描述任務,通過獲取表達能力更強的語義特征,提升視頻描述網(wǎng)絡的整體性能,網(wǎng)絡模型如圖5。
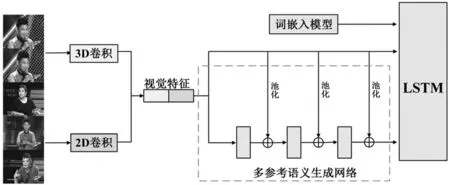
圖5 視頻描述網(wǎng)絡結構圖
算法流程如下:
(1)輸入數(shù)據(jù)集視頻,對視頻預處理得到固定的幀數(shù)和圖像尺寸;
(2)分別采用3D卷積和2D卷積提取視頻特征,將兩種特征級聯(lián),得到視覺特征;
(3)將視覺特征傳遞到雙通道網(wǎng)絡中,在第一通道直接輸出視覺特征,在第二通道MRNet中輸出語義特征;
(4)將視覺特征和語義特征送入LSTM網(wǎng)絡,生成文本描述。
2 實驗結果與分析
2.1 數(shù)據(jù)集
選擇MSR-VTT[13]和MSVD[14]兩個數(shù)據(jù)集進行訓練和測試。MSR-VTT數(shù)據(jù)集包含10 000個長度約為10 s的短視頻,內(nèi)容涉及生活中的各種場景,每個視頻配有人工標注的文本描述作為Ground Truth,在實驗中將7 010個視頻用于訓練,2 990個視頻用于測試。MSVD數(shù)據(jù)集中共有1 970個視頻,將1 300個視頻用于訓練,670個視頻用于測試。
2.2 實驗設計
在TensorFlow深度學習框架下使用Python語言編程實現(xiàn),在Ubuntu16.04系統(tǒng)中采用單張NVIDIA 1080Ti顯卡訓練和測試。
對于整體視頻描述網(wǎng)絡,首先對視頻進行預處理,對每個視頻均勻提取32幀圖像后剪裁為固定尺寸256×256,利用預訓練的ECO[15]和ResNeXt[16]網(wǎng)絡獲取3D和2D特征,得到3 584維視覺特征向量,采用多參考語義生成網(wǎng)絡獲取語義特征,將其與視覺特征共同送入LSTM,重新訓練后輸出文本描述。訓練時將學習率設置為0.000 4,批次大小為64,迭代次數(shù)為50,采用Adam算法優(yōu)化模型。
使用視頻描述任務最常用的四個評價指標衡量文本描述的準確程度,分別為BLEU-4、CIDEr、METEOR和ROUGE-L,四個指標綜合考慮準確度、召回度、句子的流暢性、近義詞等多方面因素對句子進行評價,計算公式如式(12)~式(15)。
(12)
式中:pn表示生成句子中連續(xù)的n個詞語(n元詞)的預測精度,即統(tǒng)計n元詞是否在生成句子和參考句子中同時出現(xiàn);wn表示該n元詞的權重(本文n=4);BP是對過短句子的懲罰因子。
(13)
式中:c是生成句子;s是參考句子;M是參考句子的數(shù)量;gn(·)表示基于n元詞的TF-IDF向量(統(tǒng)計一個詞語在語料庫或文件中出現(xiàn)的頻率進而判斷其重要程度)。
Meteor=Fmean(1-p) 。
(14)
式中:Fmean表示1元詞的調(diào)和平均值(將精度和召回率以一定權重組合);p為懲罰因子(抑制1元詞的調(diào)和平均值,有利于生成準確的詞組)。
ROUGE-L=(1+β2)RlcsPlcs/(Rlcs+β2Plcs)。
(15)
式中,Rlcs和Plcs是根據(jù)生成句子和參考句子的最大公共子序列長度計算獲得的召回率和準確率。
對于MRNet,將MLP每一層神經(jīng)元個數(shù)設置為512、512、300。學習率為0.000 2,批次大小為128,迭代次數(shù)設置為1 000。語義特征的Ground Truth是人工標注的300維特征向量,第i個視頻的語義Ground Truth可表示為
(16)
其中每個值代表某個詞匯在視頻中是否涉及。在網(wǎng)絡中,采用準確率accuracy衡量語義特征的準確程度,如式(17),Nt為預測的全部單詞個數(shù)300,Nr為300維向量中預測正確的單詞個數(shù)。accuracy值越大,說明語義特征越準確。
(17)
2.3 視覺特征參考強度的實驗與分析
為驗證MRNet參考結構的有效性,引入不同數(shù)量的視覺特征參考如圖6,分析參考強度對性能的影響。

a)No reference b)R=1 c)R=2 d)R=3圖6 參考強度示意圖
圖6a為無參考的語義生成網(wǎng)絡為基準,圖6b、圖6c和圖6d為逐漸增加參考數(shù)量,且由相關實驗可知參考特征的位置和順序?qū)π阅軣o顯著影響。在MSR-VTT和MSVD數(shù)據(jù)集上不同參考數(shù)量的性能對比結果見表1。
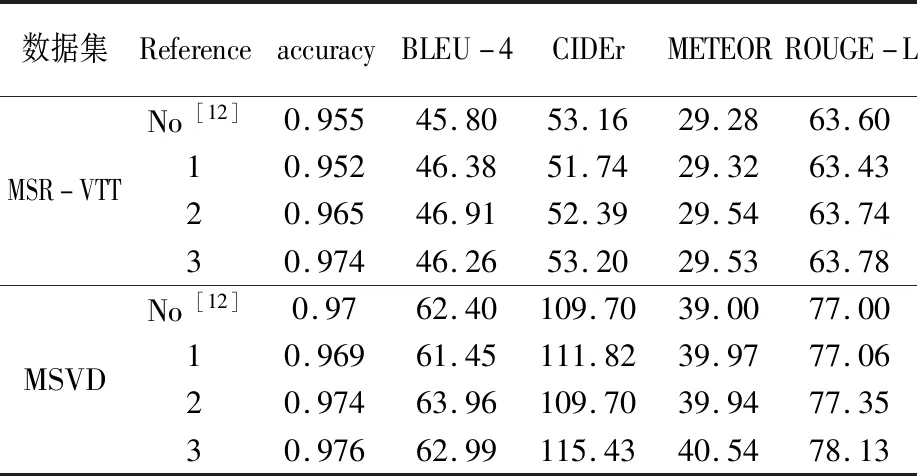
表1 兩數(shù)據(jù)集不同參考數(shù)量性能對比結果
網(wǎng)絡僅引入一條特征參考時,生成的詞匯語義特征準確率有所降低,卻得到了視頻描述性能的顯著提升,可知參考型MLP結構可以增強語義有效性。整體來看,語義特征的準確率隨參考數(shù)量的增加逐步提升,視頻描述的四個評價指標也整體呈上升趨勢,當參考特征數(shù)量為3時性能達到最佳,驗證了在每一階段引入視覺特征參考的必要性和有效性。
2.4 與殘差結構對比的實驗與分析
為驗證MRNet優(yōu)于殘差MLP結構,對兩種結構進行對比如圖7。圖7a和圖7b分別是殘差MLP和多參考MLP結構,除捷徑連接方式,兩種結構的參數(shù)均相同。
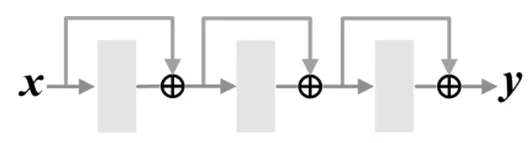
a) 殘差MLP b) 多參考MLP圖7 MLP結構對比示意圖
在MSR-VTT和MSVD數(shù)據(jù)集上兩種結構的性能對比結果見表2。
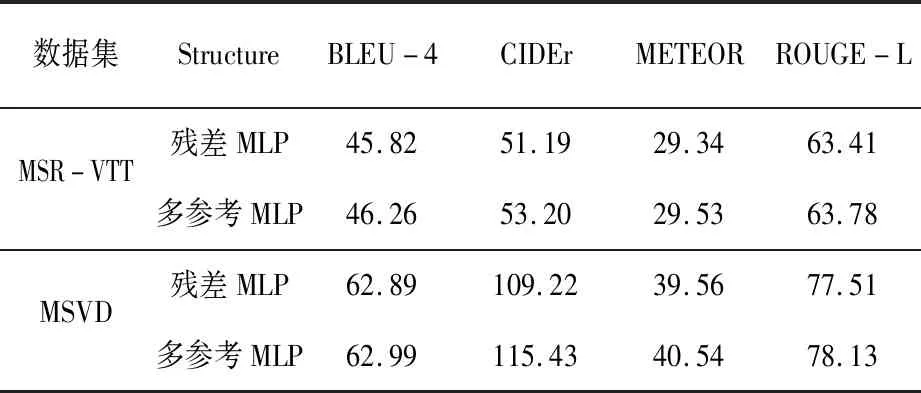
表2 在兩個數(shù)據(jù)集上兩種結構的性能對比結果
在兩個數(shù)據(jù)集中,多參考MLP在四個評價指標上均優(yōu)于殘差MLP結構,表明多參考MLP結構并非捷徑連接的簡單堆疊,在具備殘差優(yōu)點的基礎上,可以增強語義特征的表達能力,進而提升視頻描述模型性能。
2.5 多參考MLP層數(shù)確定
為確定多參考MLP最佳網(wǎng)絡層數(shù),進行如下對比實驗。MLP網(wǎng)絡層數(shù)由1到5逐漸遞增,且在每一層都引入視覺特征參考。視頻描述性能對比見表3。當層數(shù)為1時性能較低,從1層到3層網(wǎng)絡性能逐漸提升且達到最優(yōu),此后趨于穩(wěn)定,且未發(fā)生明顯網(wǎng)絡退化現(xiàn)象。

表3 在MSR-VTT和MSVD數(shù)據(jù)集上網(wǎng)絡層數(shù)性能對比
2.6 算法整體性能對比
在兩個數(shù)據(jù)集上進行實驗仿真,得到了較好的視頻描述結果,在MSR-VTT數(shù)據(jù)集上,將MRNet與其他13種現(xiàn)有模型進行對比,結果見表3。BLEU-4和ROUGE-L兩個評價指標優(yōu)于現(xiàn)有同類方法,CIDEr和METEOR兩個指標也表現(xiàn)較好。
在MSVD數(shù)據(jù)集上的性能對比見表4。四個評價指標均有不同程度的提升,且優(yōu)于現(xiàn)有同類方法。
將兩種視頻描述方法的結果進行對比如圖8。相比于無參考的視頻描述方法,MRNet可以得到更準確的文本描述。圖8a中MRNet可以準確識別“數(shù)學”這一視頻語義;圖8b中可以準確表達“一個男孩正在與一組評委談話”這一場景;圖8c更全面地指出活動地點為籃球場;圖8d則表達了“正在被采訪”這一具體行為。以上四個實例驗證了MRNet的優(yōu)越性。
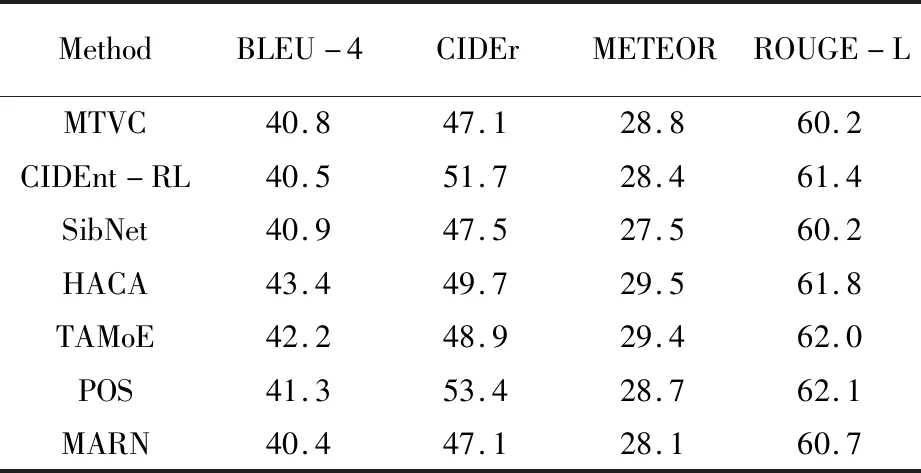
表4 MSR-VTT數(shù)據(jù)集視頻描述性能對比
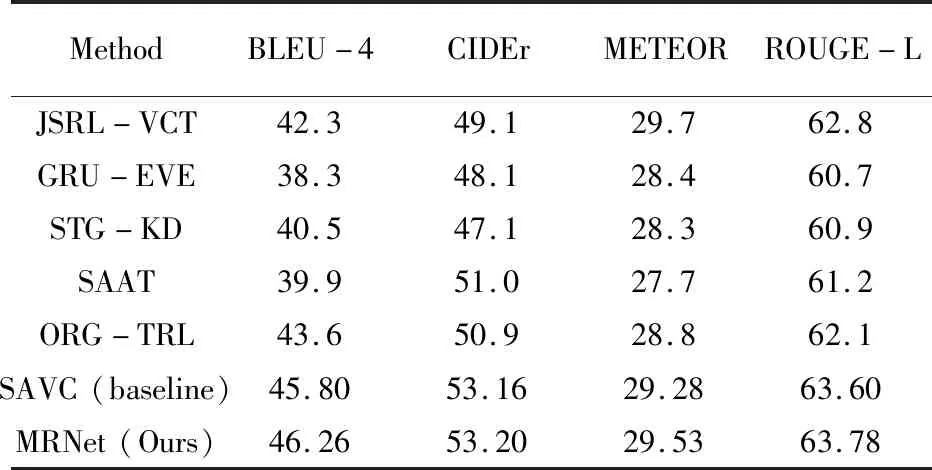
續(xù)4 MSR-VTT數(shù)據(jù)集視頻描述性能對比
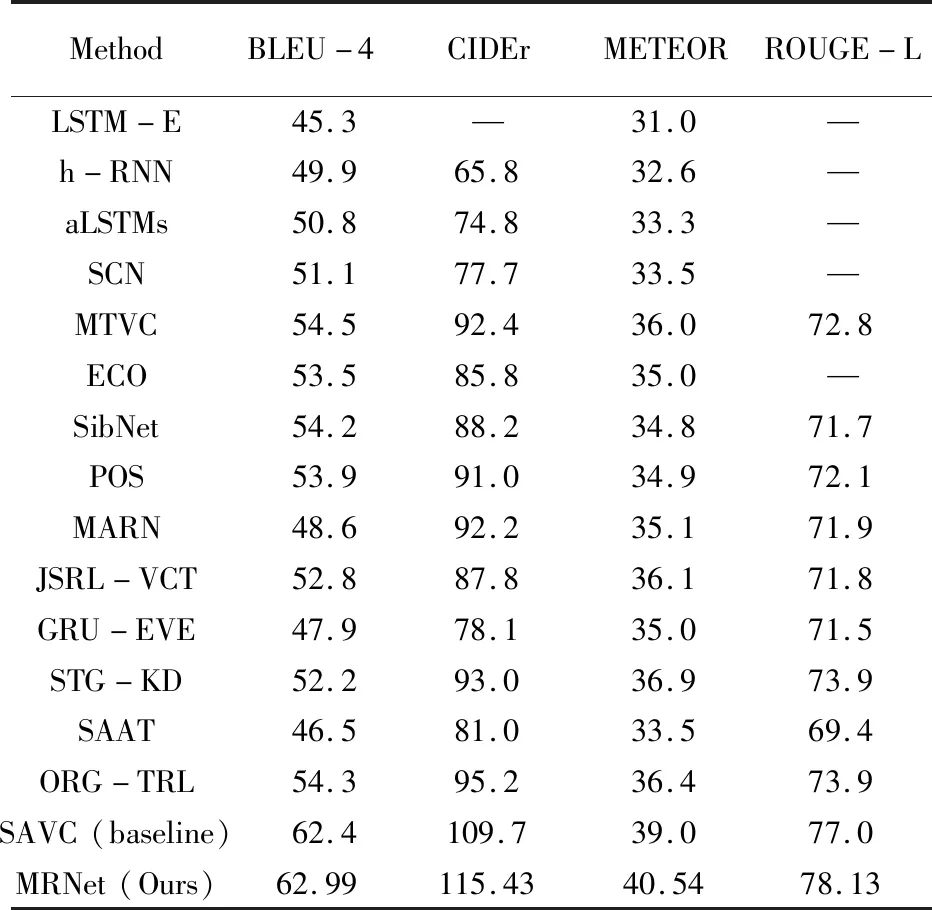
表5 MSVD數(shù)據(jù)集視頻描述性能對比
3 結 語
針對視頻描述中語義特征表達能力不足導致的文本描述不準確問題,本文提出多參考語義生成網(wǎng)絡MRNet。該網(wǎng)絡采用多參考MLP結構獲取語義特征,在MLP語義萃取過程中融入視覺信息,以視覺信息為參考對特征進行修正和補充,且該結構具備殘差網(wǎng)絡的優(yōu)點,可以消除網(wǎng)絡退化現(xiàn)象,增強特征的表達能力,同時確保視覺信息的完整表達。通過對比實驗驗證了多參考結構的有效性和必要性,且MRNet優(yōu)于現(xiàn)有同類方法,在ROUGE-L指標上平均提升了0.99%。在后續(xù)工作中,將對通道間特征的參考方式做進一步研究。

圖8 視頻描述結果對比
猜你喜歡
哲學評論(2021年2期)2021-08-22 01:53:34
開放教育研究(2020年2期)2020-03-31 01:54:14
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
中華詩詞(2019年7期)2019-11-25 01:43:04
當代陜西(2019年10期)2019-06-03 10:12:04
數(shù)學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
影視與戲劇評論(2016年0期)2016-11-23 05:26:01
現(xiàn)代語文(2016年21期)2016-05-25 13:13:44
現(xiàn)代企業(yè)(2015年9期)2015-02-28 18:56:50
大連民族大學學報(2015年2期)2015-02-27 08:28:11
