變工況下基于聯合適配與對抗學習的滾動軸承故障診斷
2022-11-23 14:21:30王志超劉維鴿楊延西史雯雯
重型機械 2022年5期
王志超,徐 江,劉維鴿,楊延西,史雯雯
(1.中國重型機械研究院股份公司,陜西 西安 710018;2.西安理工大學自動化與信息工程學院,陜西 西安 710048)
0 前言
旋轉機械在工業生產中發揮著重要作用,如帶鋼冷軋線、帶鋼酸洗線、帶鋼彩涂線等都存在多個轉動軸承,都屬于旋轉機械的范疇,在工業生產中應用廣泛。旋轉機械普遍運行在惡劣的工作環境下并且長期處于高速旋轉,極易發生損壞。一旦某個旋轉機械零部件故障失靈,很有可能導致整體加工系統的損壞,甚至威脅操作人員的安全。目前,針對這類易損零部件,大多工廠車間都是采用定期維護的策略來預防故障的發生,實際效果也不盡理想。況且,一些旋轉機械安裝在一些大型設備的內部,其拆卸與安裝都十分麻煩,對其檢修一次可能會耽誤數小時的生產,對生產計劃有很大影響。因此,了解旋轉機械的故障機理,掌握故障發生的規律,提出科學有效且經濟可行的運維策略是十分必要的。
在現有的大多數數據驅動的智能故障診斷方法中,一個重要前提是訓練數據與測試數據同分布,而在實際工業中,由于機器工況的變化、環境噪聲的干擾、軸承質量等因素,訓練數據與測試數據的分布通常存在差異,導致診斷性能顯著下降,需要建立具有較強泛化性能的故障診斷模型,以適應不同工況的場景。遷移學習為解決這類問題提供了新的思路,可以將相關領域學到的知識進行遷移,以幫助提高訓練數據較少的目標任務的學習性能,放松了源數據集和目標數據集必須具有相同的分布的假設,以減少重新收集足夠大的訓練數據的需要。因此,本文主要以滾動軸承的故障診斷為主要研究內容,以深度學習框架中的卷積神經網絡作為基礎網絡框架,結合遷移學習方法構建模型進行軸承故障診斷,對滾動軸承智能故障診斷的發展具有重要促進意義。
針對全監督情況固定工況下基于卷積神經網絡的滾動軸承故障診斷,提出的模型可以實現較高的準確率,噪聲干擾下也有著較好的魯棒性。然而在許多實際應用中,某些工況下的樣本由于客觀條件的限制可能很難采集,大量的訓練樣本可能來自某個特定工況。除此之外,軸承的運行狀態參量——載荷和速度,也會隨著時間和空間的變化而變化,導致軸承的訓練數據和測試數據工況不同。因此需要用某個工況訓練的模型可以有效地對其他工況的樣本進行故障狀態判別。由于工作條件的不同,測試數據的分布可能與訓練數據的分布不一致。而基于深度學習的“端到端”模型不僅需要大量標記數據,且要求訓練數據集與測試數據集同分布。因此基于卷積神經網絡的模型已不能滿足此類情況的需求,診斷性能會降低。另外,有標簽的數據在某些機器上很難獲得,如果要對某一工況下的數據進行故障診斷,通常只能采集到少量無標簽數據。手動標記數據和從頭開始構建一個模型都是復雜而耗時的。
由于基于卷積神經網絡的模型已不能滿足某些工況的需求,且診斷性能低,數據采集困難等,需要通過遷移學習的方法對模型和帶有標簽的數據進行重用。因此本文在深度卷積神經網絡模型中引入了遷移學習,提出了一種多尺度卷積聯合適配對抗網絡,來有效解決變工況情景下的故障診斷問題。通過對不同的遷移學習算法進行分析,設計了故障診斷模型,并進行實驗對模型進行了驗證。在進行實驗時,專門研究了比較壞的一種情況,即目標域為無標簽數據,該探索對于無標簽數據智能故障診斷的發展具有重要意義。
1 特征遷移學習算法
遷移學習方法多種多樣,其核心思路就是通過利用已有樣本、參數或特征,使用已有領域知識來完成目標領域知識的學習。其中,基于實例的遷移學習方法當某些特征是源(目標)域特定使用時,重新加權樣本不能減少域差異,適用于源域和目標域相似度較高的情況。基于模型的遷移學習方法所遷移的知識被編碼到模型參數、模型先驗知識、模型架構等模型層次上,不過其大多假設目標域是有標簽的樣本。基于特征的遷移學習算法可以應用在域間相似度不太高甚至不相似的情況。考慮到本文研究的是半監督變工況條件下的軸承故障診斷,因此決定采用基于特征的遷移學習算法,將來自源域和目標域的數據映射到共同的特征空間,通過距離度量將域差異最小化。然后使用映射之后的源域和目標域數據在新的特征空間上訓練目標分類器。
基于特征的遷移學習重點就是要找到一個距離度量準則,這是量化遷移學習中兩域差異的重要手段,可以用來衡量源域和目標域的相似性。選擇一個好的度量準則對于遷移學習模型的訓練至關重要,不僅可以很好地度量源域和目標域間的差異,量化兩域的相似程度,還要能夠作為準則,在進行遷移訓練時可以利用方法或模型對該度量進行優化,以增加源域目標域的相似性,從而完成遷移學習。本文模型用到了特征遷移學習中的JMMD距離,后續對比實驗用到MK-MMD距離及CORAL。
1.1 MK-MMD
許多研究人員通過最大均值差異(Maximum Mean Discrepancy,MMD)來減小域差異,MMD最早在文獻[1]中提出,并被許多其他研究人員用于遷移學習。可以用作衡量兩個數據分布差異的度量準則,MMD的主要思想是當兩個數據的分布線性不可分時,將數據映射到一個高維空間中,然后在此空間衡量兩個數據分布的差異。MMD在計算兩數據分布差異時引入了核函數,可以解決數據在高維空間難以計算的問題,在遷移學習領域應用廣泛。
再生核希爾伯特空間(RKHS)中定義的MMD算法就是求得兩數據集在高維空間的均值差異,具體公式為
(1)
式中,xi為數據集X的第i個樣本;yj為數據集Y的第j個樣本;n為數據集X的樣本個數;m為數據集Y的樣本個數;φ(·)為到高維空間的映射函數;H為距離,是由φ(·)將數據映射到RKHS中進行度量的。
MMD的關鍵在于如何找到一個合適的φ(·)作為一個映射函數。但是這個映射函數在不同的任務中都不是固定的,所以是很難去選取或者定義的。如果不能知道φ(·),MMD的求解步驟如下,首先對式(1)的平方進行分解,可以得到:
(2)
MMD的目標函數中含有類似內積的計算,這可以聯想到SVM中核函數的定義:
k(x,y)=φ(x)·φ(y)
若將核函數引入MMD的目標函數中,可以避免內積無法計算的問題,則可以表示如下:
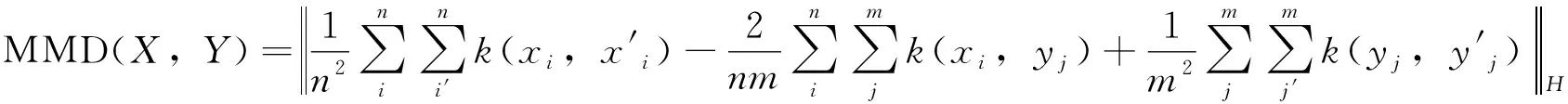
考慮到高斯核函數可以把數據映射到無窮維空間,因此通常選用高斯核作為核函數。高斯核函數的定義為
k(x,x′)=exp(-‖x-x″‖2/(2σ2))
式中,βu不同核的加權參數(本文βu=1)。
1.2 CORAL
CORAL即相關對齊算法,也可以作為一種度量準則,描述兩個數據間的分布差異。核心思想是先計算出源域數據和目標域數據的協方差,隨后白化并重著色源域數據的協方差,通過調整網絡參數,使得兩域數據分布的協方差損失最小,從而使源域和目標域分布的二階統計數據保持一致。此方法的思想比較簡單,旨在對齊數據的二階特征,而最大均值差異是將數據映射到高維空間,對齊數據的一階特征。CORAL不用再進行進行核函數的選擇,對源域和目標域進行的非對稱變換,而最大均值差異對兩個數據域進行的是同一種核函數的變換。CORAL算法具體定義如下:
(3)
式中,Cs為源域數據的協方差矩陣;Ct為目標域數據的協方差矩陣; ‖‖F為范數,用來衡量兩個矩陣的距離。
由式(3)可以知道,如果要使目標函數最小,需要尋找到一個矩陣,當其對應的線性變換作用于源域時,目標函數值可以盡可能地小,從而源域和目標域數據的二階統計特征差異達到最小。在傳統機器學習的跨域遷移中可以直接使用CORAL算法,但對于深度學習網絡來說,網絡每一層都是對輸入數據進行卷積、激活或者池化后的特征表示,因此無法獲得矩陣的值。針對這一問題,文獻[4]提出了Deep CORAL算法,對原始CORAL算法進行了改進,使得CORAL算法可以應用于深度學習網絡,進行深度遷移學習模型的訓練。CORAL損失定義為源域目標域特征的二階協方差距離,用式(4)表示。
(4)
式中,d為每個樣本的維數。
源域數據的協方差矩陣Cs和目標域數據的協方差矩陣Ct分別按照式計算得到:
式中,Xs為源域訓練樣本;Xt為目標域訓練樣本;ns為源域訓練樣本個數;nt為目標域訓練樣本個數;1為元素均等于1的列向量。
利用微積分的鏈式求導法可以輸入特征的梯度進行計算,計算方法如下:
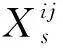
1.3 JMMD
通常深度神經網絡的輸入數據會經過多層的特征變換和抽象,提取到的特征隨著網絡層數的增加逐漸從一般特征過渡到具體特征,以此學習輸入數據的特征與輸出標簽之間的復雜映射關系。最大均值差異已經被廣泛用于衡量源域邊緣分布和目標域邊緣分布的差異,由于聯合分布不容易于操作和匹配,MMD或者MKMMD還不能解決此類問題。所以當輸入數據與輸出數據的聯合分布發生變化時,如何有效地進行遷移學習是一個難點。另外當源域和目標域的差異增大時,數據特征和分類器的可遷移性會極大地降低,也不利于遷移學習模型的訓練。為解決問題, 而定義的MMD和MK-MMD不能用于解決由輸入和輸出的聯合分布,聯合最大均值差異(JMMD)被設計為測量源域和目標域之間的經驗聯合分布差異。考慮到在把源域數據和目標域數據輸入深度神經網絡后,即使經過多層特征變換和抽象,源域聯合分布和目標域聯合分布的變化仍然會停留在多個域特定高層的網絡激活中。因此,可以使用這些域特定層的激活的聯合分布來近似推出原始的聯合分布,從而實現源域和目標域的域適應。JMMD為希爾伯特空間中兩個聯合分布的差異,具體定義為
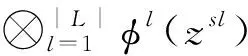
由于在深度卷積神經網絡中,多個域特定層中網絡激活的聯合分布的變化與輸入數據的特征與輸出標簽的聯合分布的變化相似。因此JMMD可以通過測量源域數據和目標域數據的經驗聯合分布的核平均嵌入之間的希爾伯特-施密特范數(Hilbert-Schmidt Norm),來對齊多個域特定層的激活的聯合分布。
JMMD經驗估計值可以表示為經驗核平均嵌入之間的平方距離,
式中,ns為源域樣本數量;nt為目標域樣本數量;L為適配的總層數。
2 多尺度卷積聯合適配對抗網絡
2.1 網絡模型
不同工況下進行軸承故障診斷,源域數據和目標域數據差異性增大,因此比起固定工況下診斷難度更大。針對此場景提出了一種多尺度卷積聯合適配對抗網絡(MSCJACN),通過縮小兩域數據間的分布差異,使得源域訓練的模型可以很好地遷移到目標域。提出的MSCJACN模型框架由故障識別和域自適應兩大模塊組成,模型總體框架如圖1所示。
(1)故障識別。故障識別模塊包括特征提取器和故障狀態分類器兩部分,通過一維多尺度卷積神經網絡來實現。具體網絡參數見表1。包括一個輸入層,一個多尺度特征融合層、四層卷積池化層,兩個全連接層和一個Softmax輸出層。Softmax層之前為特征提取器,Softmax層為故障狀態分類器。特征提取器試圖從原始輸入信號中自動學習故障特征。故障狀態分類器基于提取的特征來識別軸承故障類型,并且在對網絡進行訓練時,損失函數會依據源域輸入的真實標簽和分類器的預測輸出計算誤差,然后將誤差進行反向傳播來訓練網絡。故障狀態分類器使得網絡可以利用有標簽的源域數據進行有監督訓練,以提高分類準確性。
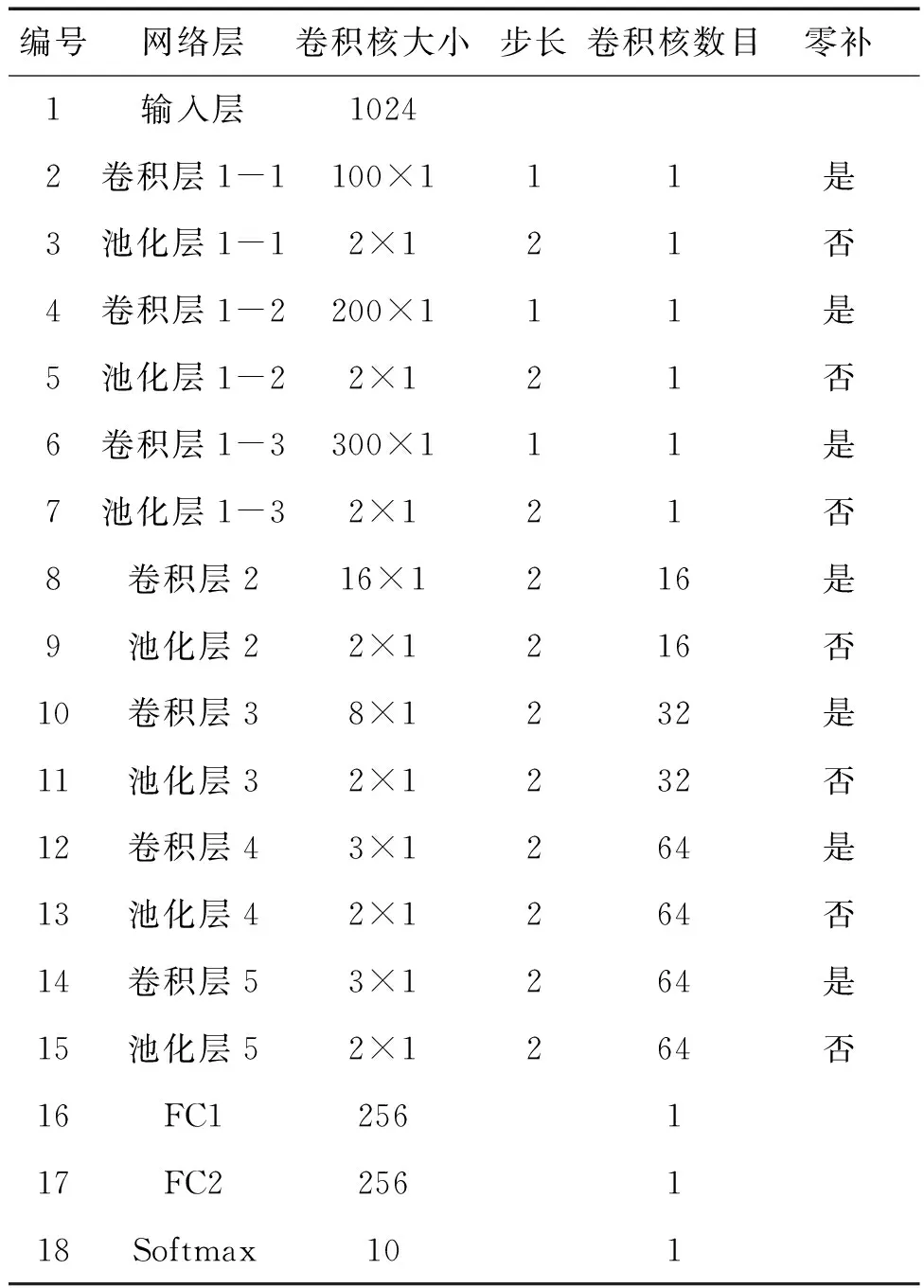
表1 一維卷積神經網絡結構參數
(2)域自適應。域自適應模塊由聯合分布適配器和域判別器組成,域自適應模塊連接到故障識別模塊的特征提取器,來幫助一維CNN學習域不變特征。學習域不變特征意味著,無論從中學習源域數據還是目標域數據,這些特征都應服從相同或幾乎相同的分布。如果特征是領域不變的,則使用源領域數據訓練的健康狀況分類器能夠有效地對從目標領域數據中學到的特征進行分類。
聯合分布適配器用來對網絡高層提取的具體特征進行適配。前面已經對深度神經網絡的可遷移性進行了分析,低層網絡提取的是通用特征,高層網絡提取的是具體特征,高層中特征的可遷移性低,因此需要對高層的特征進行適配,在網絡最后兩個全連接層上添加適配網絡,使用聯合最大均值差異(JMMD)來減小源域數據和目標域數據的分布距離。
域判別器采用了對抗學習的思想,用來判斷輸入的訓練樣本是源域樣本還是目標域樣本,同時計算域判別損失。在特征提取器和域判別器之間添加一個特殊的梯度反轉層(GRL),使得特征提取器和域判別器的訓練目標相反,從而形成一種對抗關系。在反向傳播更新參數的過程中,域判別器的訓練目標是盡可能地將輸入的訓練樣本分到其所屬的域。由于GRL的存在,特征提取器的訓練目標是使域判別器不能正確判斷輸入的訓練樣本來自哪一個域。當域判別器不能正確區分源域樣本和目標域樣本時,特征提取器的任務就完成了。此時,在某個空間內源域數據和目標域數據已經被混合在一起了,即源域和目標有了相同或相似的分布。MSCJACN使用了兩層完全連接的二進制分類器作為域判別器,第一層全連接層后的特征經過ReLU激活之后,采用Dropout進行隨機丟棄,再經過一層全連接層,最終提取的特征傳遞到最后的Softmax層,Softmax輸出層具有2個神經元判斷輸入的訓練樣本是源域樣本還是目標域樣本。
2.2 目標函數
為了使得源域訓練的模型能夠很好地遷移到目標域,本文提出的MSCJACN網絡模型具有三個優化對象。
(1)最小化源域數據集上的故障狀態分類錯誤。為了完成遷移故障診斷,MSCJACN應該能夠識別軸承的健康狀況并學習域不變特征。故障識別模塊旨在識別機器的健康狀況。因此,MSCJACN的第一個優化目標是最小化源域數據上的健康狀況分類錯誤。對于具有健康狀況類別的數據集,其目標函數采用交叉熵損失函數為
式中,Gf為是參數為θf的特征提取器;Gc為是參數為θc的類預測器。
因此,目標一的優化目標為
ψ1=minL1(θf,θc)
(2)最小化源和目標域數據集之間的JMMD距離。域適應模塊旨在學習域不變特征。域適應模塊包括分布差異度量和域分類器。高級特征直接影響遷移故障診斷的有效性。為了減小從不同域學習到的特征之間的分布差異距離,采用聯合分布適配器直接測量兩域之間的分布差異距離。因此,MSCJACN的第二個優化目標是使源域數據和目標域數據之間的聯合分布差異距離JMMD最小。為了計算高級學習特征在不同域之間的分布距離,JMMD損失為
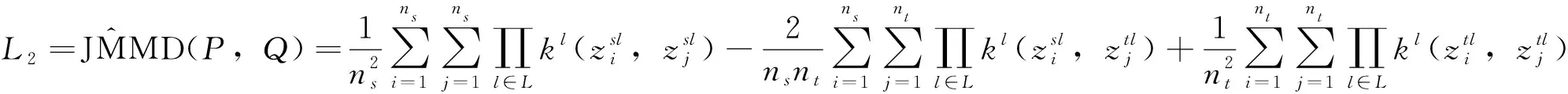
因此,目標二的優化目標為
ψ2=minL2
(3)最大化源和目標域的域分類錯誤。如圖1所示,域分類器與特征提取器連接。如果域分類器無法區分源域和目標域之間的特征,則特征是域不變的。因此,MSCJACN的第三個優化目標是最大化源和目標域數據上的域分類誤差。域分類損失采用二分類交叉熵損失函數:
因此,目標三的優化目標為
ψ3=maxL3(θf,θd)
最終的目標損失函數可以寫成
L=L1(θf,θc)+λL2-μL3(θf,θd)
式中,λ為JMMD損失L2的懲罰系數;μ為域分類損失L3的懲罰系數。
因此,最終的網絡優化目標為
ψ=minL=min{L1(θf,θc)+λL2-μL3(θf,θd)}
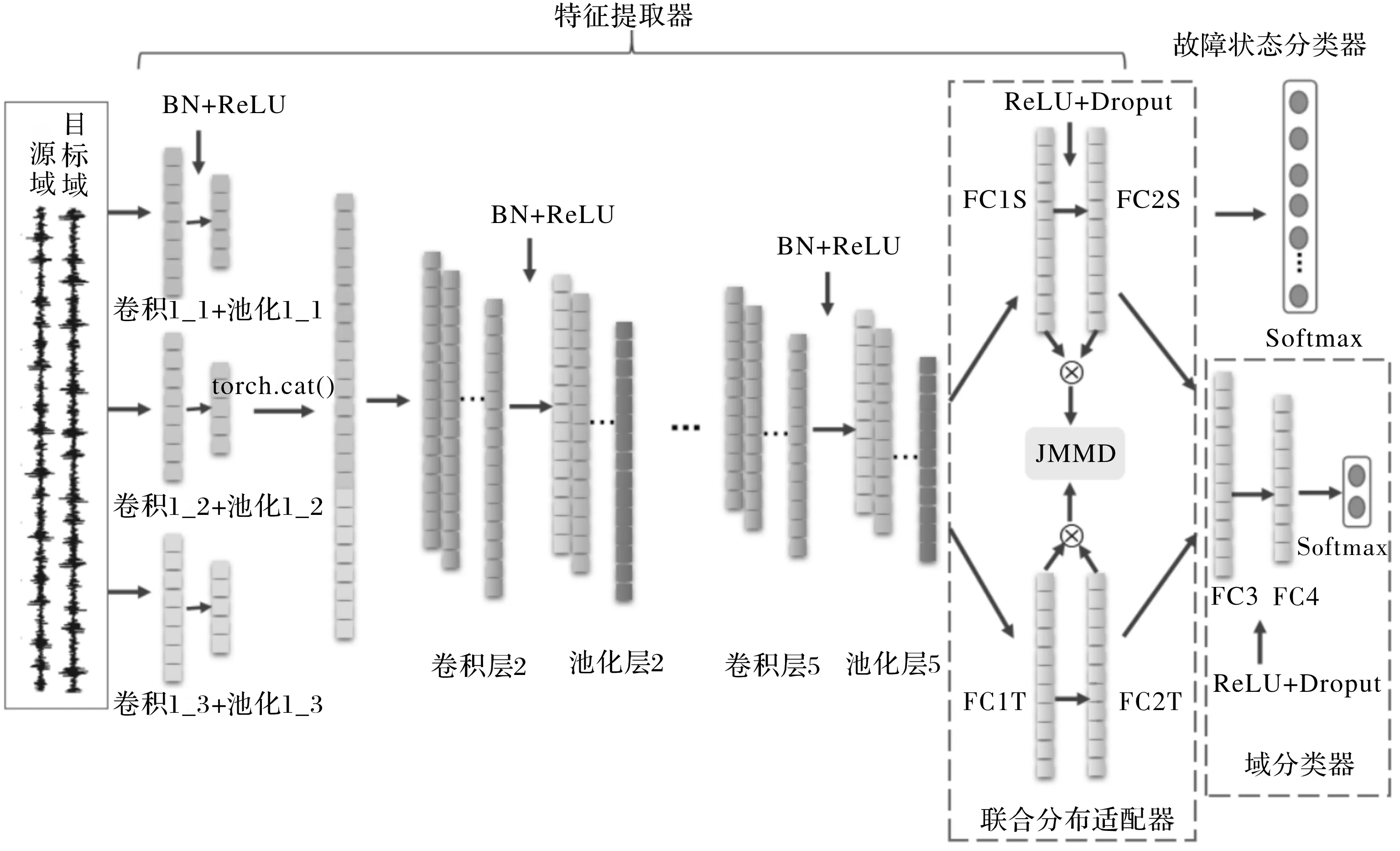
圖1 多尺度卷積聯合適配對抗網絡(MSCJACN)框架圖
3 實驗驗證
3.1 數據集構建
依舊采用CWRU數據集對實驗模型進行驗證,如表2所示,數據集是在四個不同的電動機負載(0HP,1HP,2HP和3HP)下采集,分別對應于四個不同的運行速度(1 797 r/min、1 772 r/min、1 750 r/min和1 730 r/min)。對于遷移學習任務,將這些不同的工作條件視為不同的遷移學習任務,因此仍然將CWRU軸承數據集分為四個子數據集,包括數據集A、B、C和D。在不同的數據集之間進行遷移故障診斷,任務A→B表示源域是電機負載等于0 HP的數據,而目標域是電動機負載等于1 HP的數據。因此,此數據集中總共有十二種遷移學習設置。
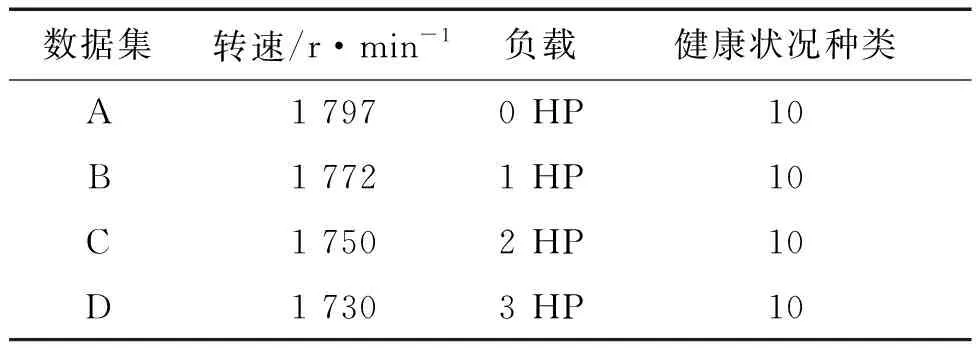
表2 CWRU軸承數據集
負載不同,加速度傳感器采集的信號也會有差異。如圖2所示,是故障尺寸為0.007 inch對應的四種負載(0HP,1HP,2HP和3HP)下的外圈故障信號,可以看出在負載不同時,信號的幅值、相位及波動周期也具有較大差異。因此變負載情況下的故障診斷比固定工況下的故障診斷更具難度。
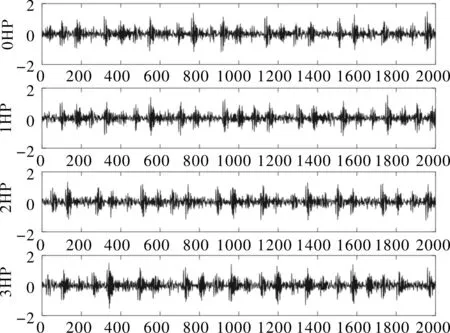
圖2 四種負載下的軸承外圈故障信號
變工況診斷一般應用場景的限制是源域有充足的帶標簽數據,而目標域只有少量的無標簽數據,為了使得源域訓練的模型遷移到目標域,可以實現對目標域數據故障狀態的準確判別,需要對此場景進行準確模擬。因此在構建數據集時,應該對源域數據集進行增強,目標域數據集不需要增強,并且源域數據帶標簽,目標域數據不帶標簽。以數據集A為源域,數據集B為目標域舉例。采用滑動窗口對數據集A的樣本數據進行重疊采樣來擴充數據,每個數據集的每種故障類型的樣本取固定長度120 000,按照樣本長度為1 024,采樣間隔為132去采樣,可得到每個數據集每種故障類別的樣本數為902,數據集A中有十種故障類別,取80%作為訓練數據,20%作為測試數據,因此數據集A的訓練集=902×10×80%=7 216,數據集A的測試集=900×10×20%=1 804。數據集B不需要進行數據擴充,就按照樣本長度1024去采樣,可得到每個數據集每種類別的樣本數為117,同樣80%作為訓練數據,20%作為測試數據,最終數據集B的訓練集=117×10×80%=936,測試集=117×10×20%=234。其他的遷移學習設置數據集構建方式和上述舉例一樣,作為源域的數據訓練集大小為7 216,測試集大小為1 804,作為目標域的數據訓練集大小為936,測試集大小為234。最終構建的數據集如表3所示。
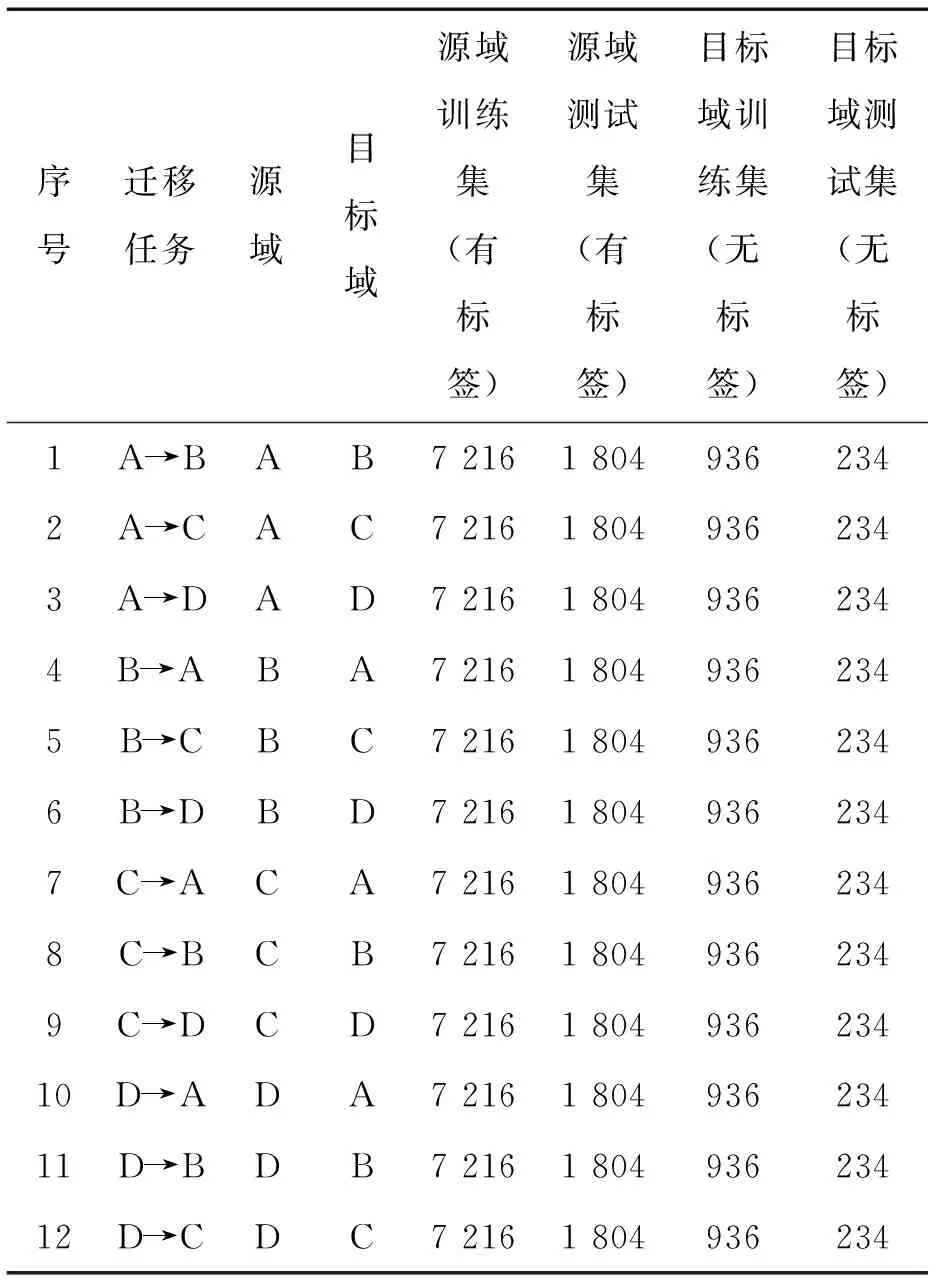
表3 實驗數據劃分
3.2 實驗設置及結果分析
實驗平臺在Python3.7.10+Pytorch1.3.1上搭建模型并進行實驗。模型迭代周期epoch設置為60。前30 epoch先利用數據量充足的帶標簽源域樣本訓練網絡,此時網絡的目標函數只有交叉熵損失函數,得到預訓練模型。第30 epoch激活遷移學習策略,網絡中同時輸入帶標簽源域數據和無標簽目標域數據,此時網絡的目標函數為交叉熵損失函數、JMMD損失及域分類損失三部分,對預訓練模型的參數進行微調。訓練時采用小批量的Adam算法來進行反向傳播,每批大小batch_size設置為64。初始學習率設置為0.001,并分別在第40 epoch和50 epoch中衰減,即學習率乘以0.1。JMMD損失和域分類損失的懲罰系數和采用漸進式訓練,使用公式從0增加到1, 表示從0變為1的訓練進度。達到最大迭代周期,即可得到最終的故障診斷模型,可對不同工況的目標域數據進行故障類別診斷,具體診斷框圖如圖3所示。
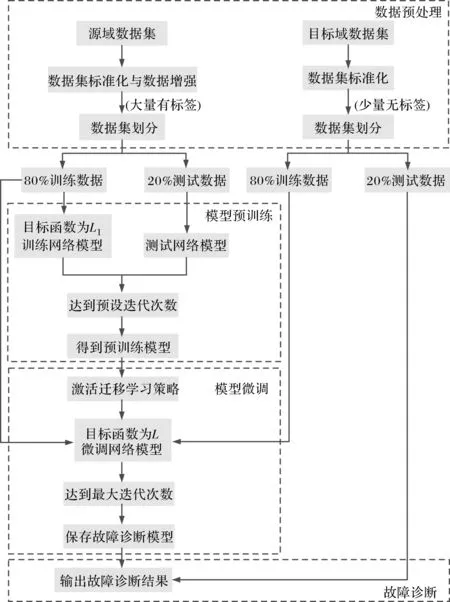
圖3 基于MSCJACN的軸承故障診斷框圖
為了驗證本文提出的MSCJACN網絡在變工況場景故障診斷的有效性,將本文模型與MS-1DCNN模型,在12種遷移任務下進行實驗模型,應用于CWRU數據集。最終測試集的診斷結果如圖4。
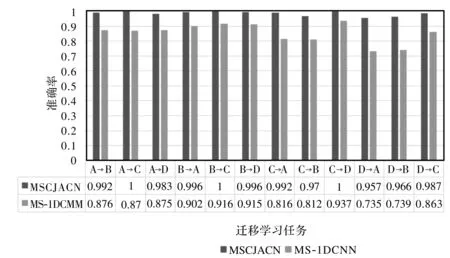
圖4 MSCJACN與MS-1DCNN在12種遷移任務上的診斷結果對比
本文模型和僅由源數據訓練的MS-1DCNN之間的唯一區別是,在本文模型中添加了域自適應模塊,而結果表明,本文的MSCJACN比僅由源數據訓練的MS-1DCNN具有更高的分類精度。可以看出MSCJACN在加入域自適應模塊后,在變工況場景診斷精度仍然很高,而沒加遷移學習的MS-1DCNN模型診斷性能不穩定,且識別精度都低于MSCJACN。尤其在工況差距比較大時,MS-1DCNN模型診斷性能大大降低,比如D→A的遷移,診斷準確率只有73.4%,而MSCJACN依然可以達到約95.7%的識別率。這意味著,遷移學習可能是促進具有未標記數據的機器的智能故障診斷成功應用的有前途的工具。
為了進一步證實本文提出的模型在變工況遷移故障診斷時的優越性,把本文模型的域自適應部分替換為其他經典的遷移學習方法。如圖5所示,構建的模型只有域自適應部分不同,故障識別部分的結構相同。即JMMD+域判別器、多核最大均值差異MK-MMD、相關對齊算法CORAL。三種方法在12種遷移學習任務上的結果如表4所示,將此結果繪制成折線圖如圖6所示。
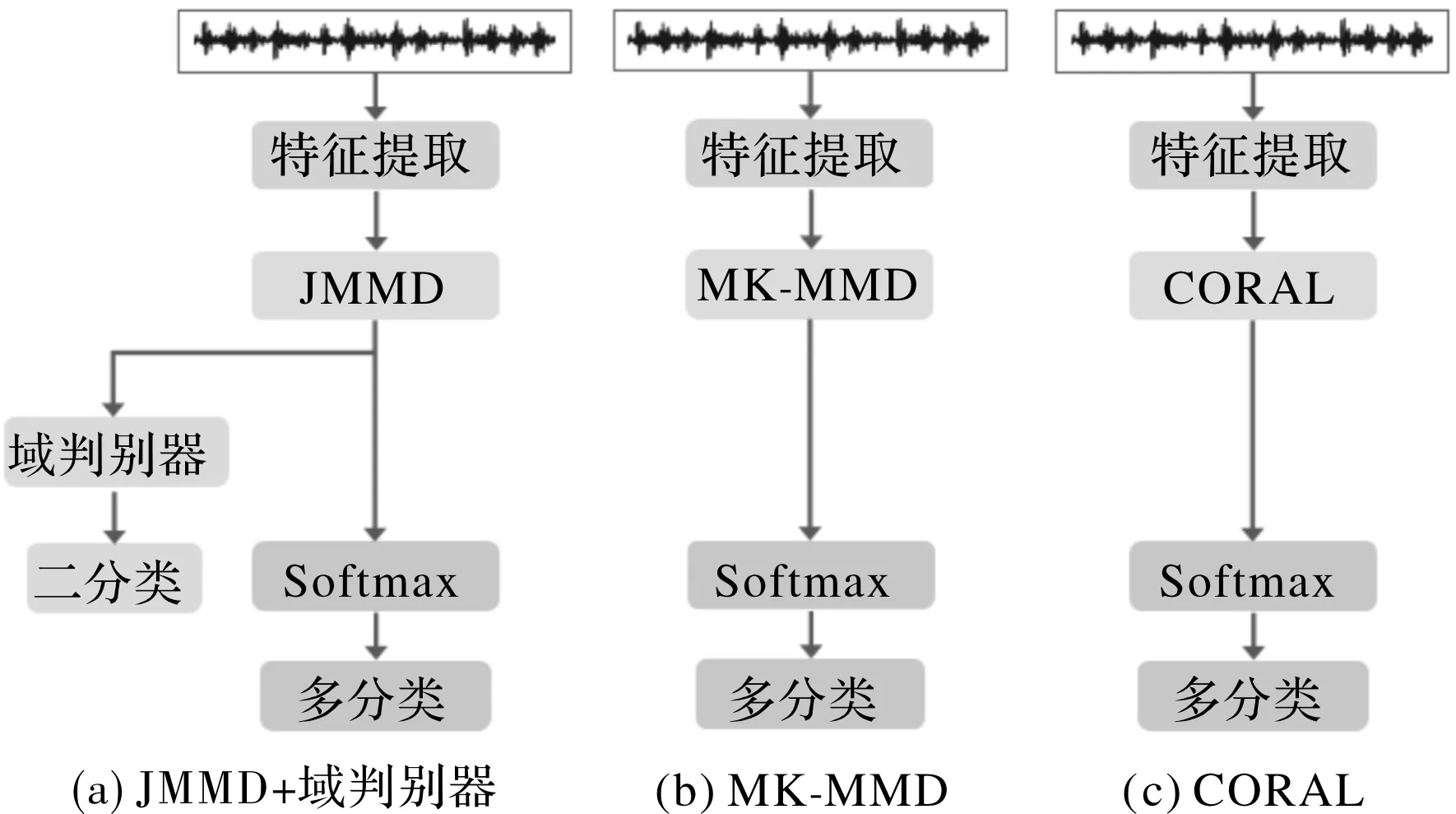
圖5 不同的域自適應模塊
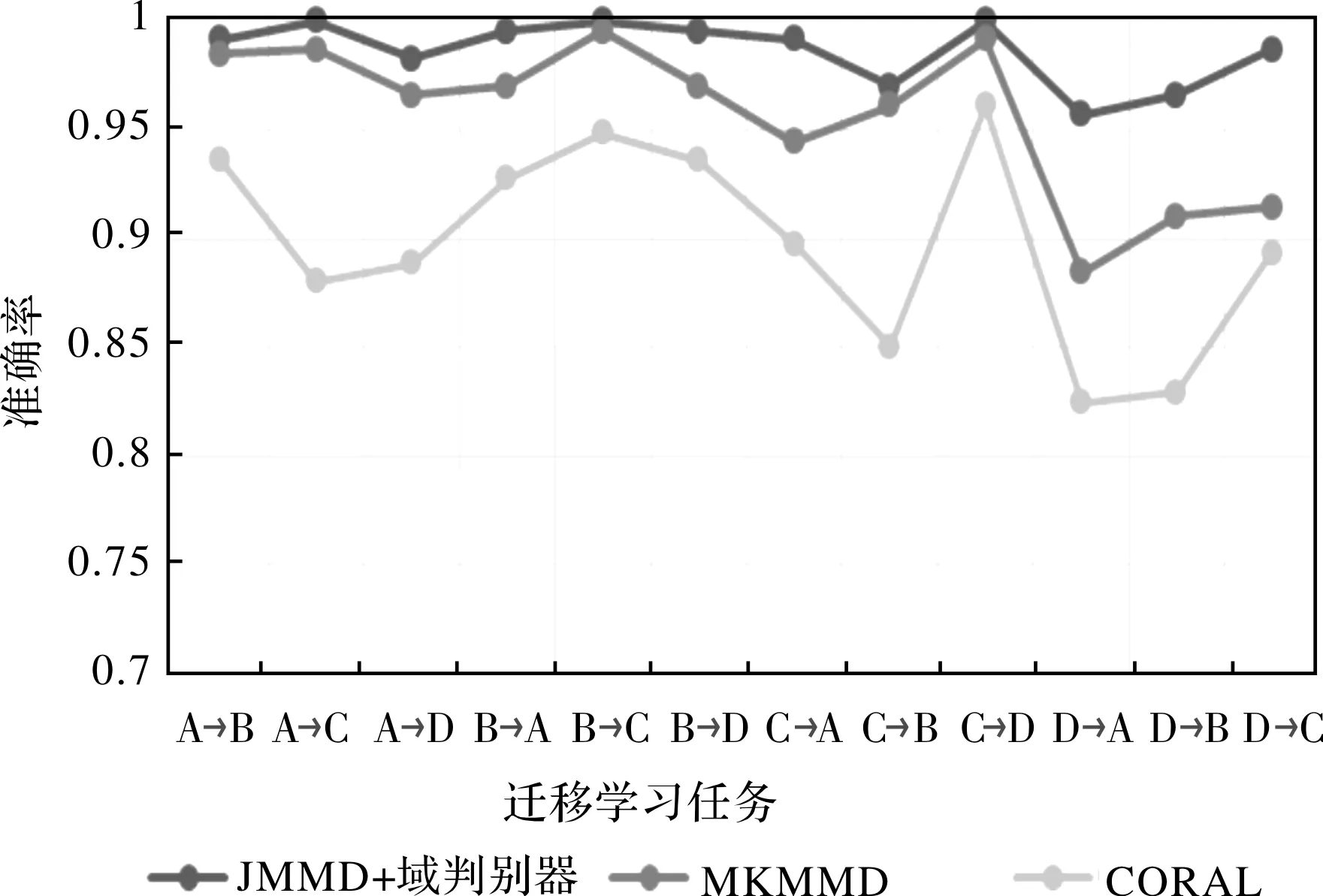
圖6 三種域自適應模塊在12種遷移任務上的診斷結果
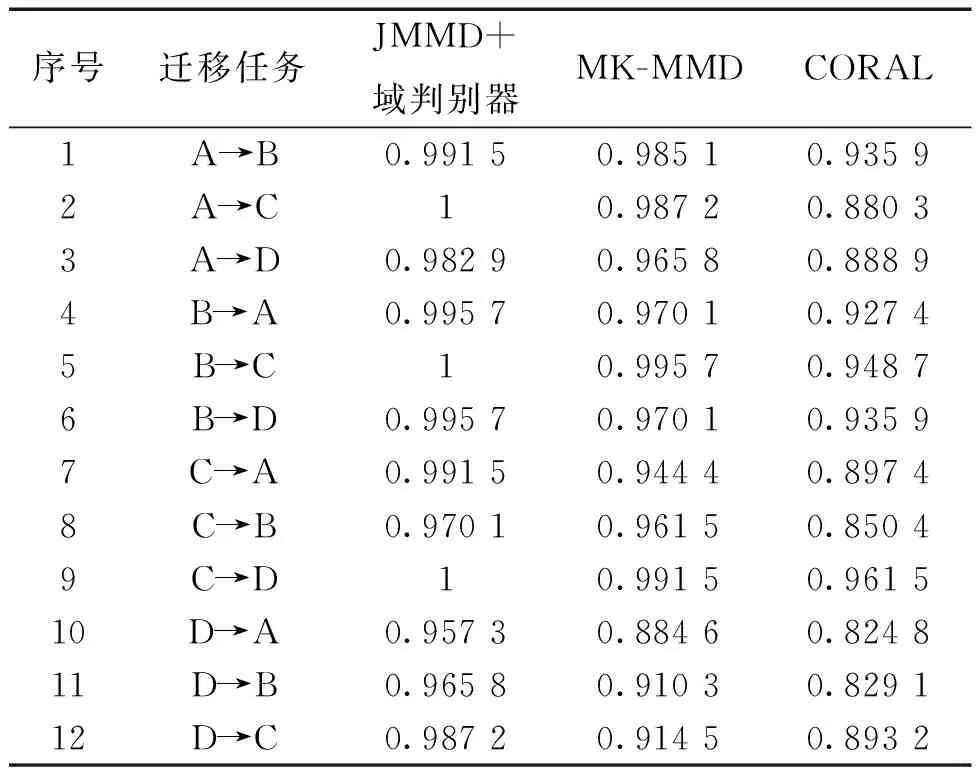
表4 不同的域自適應模塊在12種遷移任務上的診斷結果
從實驗結果可以看出,本文提出的JMMD+域判別器的方式比起其他遷移學習方法在遷移故障診斷上更具優勢,并且診斷效果依次為:JMMD+域判別器最優,其次是MK-MMD,最后是CORAL。JMMD+域判別器的方式最高可以達到百分之百識別正確,在D→A識別效果最差,但也可以達到95.7%識別準確,而MK-MMD只有88.46%,CORAL只有82.48%。
4 結束語
針對變工況故障診斷問題,在深度學習框架中引入了遷移學習,提出了一種多尺度卷積聯合適配對抗網絡(MSCJACN),通過縮小兩域數據間的分布差異,使得源域訓練的模型可以很好地遷移到目標域,可有效解決目標域可用訓練樣本不足的問題。并且專門針對比較壞的一種情況,即目標域只有少量的無標簽數據,在12組遷移學習任務上進行實驗,均達到了很高的準確率。與其他遷移學習方法進行對比實驗,MSCJACN的性能表現也更優。
猜你喜歡
汽車維修與保養(2019年7期)2020-01-06 03:30:42
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
汽車維護與修理(2016年10期)2016-07-10 08:17:41
重慶工商大學學報(自然科學版)(2015年10期)2015-12-28 07:43:58
汽車維修與保養(2015年6期)2015-04-17 03:31:50
汽車維護與修理(2015年2期)2015-02-28 12:15:39
振動、測試與診斷(2014年5期)2014-03-01 01:14:21
機械與電子(2014年1期)2014-02-28 02:07:31
