基于強化學(xué)習(xí)的改進三維A*算法在線航跡規(guī)劃
2023-02-11 12:29:34任智,張棟,*,唐碩
系統(tǒng)工程與電子技術(shù) 2023年1期
任 智, 張 棟,*, 唐 碩
(1. 西北工業(yè)大學(xué)航天學(xué)院, 陜西 西安 710072; 2. 陜西省空天飛行器設(shè)計重點實驗室, 陜西 西安 710072)
0 引 言
飛行器飛行前預(yù)先裝訂的規(guī)劃航跡難以應(yīng)對瞬息萬變的戰(zhàn)場態(tài)勢,在實際飛行過程中需根據(jù)戰(zhàn)場實時態(tài)勢對航跡進行在線規(guī)劃與動態(tài)調(diào)整。在線航跡規(guī)劃技術(shù)是在滿足飛行性能約束與戰(zhàn)場環(huán)境約束等條件下求解規(guī)劃航跡,是提高飛行器在復(fù)雜戰(zhàn)場環(huán)境中生存能力與任務(wù)完成能力的關(guān)鍵技術(shù),對規(guī)劃算法的實時性與規(guī)劃結(jié)果最優(yōu)性有更高的要求。常見航跡規(guī)劃方法包括:人工勢場法[1]、遺傳算法[2]、群智能算法[3-6]、A*算法[7]等。其中,A*算法原理簡單且規(guī)劃結(jié)果穩(wěn)定可靠,已被廣泛應(yīng)用于工程實踐中[8]。
近年來,國內(nèi)外學(xué)者對A*算法的研究與改進主要從啟發(fā)函數(shù)設(shè)計、拓展節(jié)點策略和數(shù)據(jù)處理方法3個角度出發(fā)。文獻[9]通過調(diào)整啟發(fā)函數(shù)中啟發(fā)信息的權(quán)重,增加少許計算時間,以換取航跡結(jié)果的優(yōu)化。文獻[10]引入了跳點搜索的拓展節(jié)點方法,通過對搜索空間直線和對角線方向上冗余節(jié)點的有效剪枝,提升二維柵格空間的搜索速度。文獻[11]采用動態(tài)矩形的雙向搜索路徑方法,進一步提升了算法的遍歷速度。文獻[12]通過引入對算法性能的評價標(biāo)準(zhǔn)為改進A*算法選擇了合適的參數(shù),提升了算法的魯棒性。上述改進方法針對的是二維空間下的航跡規(guī)劃場景,而三維空間規(guī)劃的航跡節(jié)點數(shù)目更多,計算量更大。文獻[13]針對動態(tài)環(huán)境下無人航跡規(guī)劃問題,將稀疏A*算法嵌入到即時修復(fù)式架構(gòu),實現(xiàn)規(guī)定時間內(nèi)可行航跡的生成與威脅連續(xù)機動下的在線航跡規(guī)劃。文獻[14]基于指數(shù)衰減的方法,調(diào)整A*算法在搜索節(jié)點過程中啟發(fā)信息的權(quán)重,改進方法能夠適應(yīng)不同的環(huán)境。
隨著人工智能技術(shù)的發(fā)展,強化學(xué)習(xí)方法在無人系統(tǒng)導(dǎo)航與控制領(lǐng)域得到深入應(yīng)用[15]。強化學(xué)習(xí)在航跡規(guī)劃問題中的應(yīng)用方法主要包括:直接依據(jù)具體航跡規(guī)劃問題建立強化學(xué)習(xí)模型[16-19],常結(jié)合深度神經(jīng)網(wǎng)絡(luò)等方法對強化學(xué)習(xí)方法進行優(yōu)化,但效果有限且訓(xùn)練結(jié)果不穩(wěn)定、變化大[20-23];結(jié)合強化學(xué)習(xí)方法對傳統(tǒng)智能算法進行參數(shù)優(yōu)化設(shè)計,能夠有效解決傳統(tǒng)智能算法早熟收斂、多樣性不足、難以確定搜索參數(shù)等問題[24-27]。
考慮到實際戰(zhàn)場環(huán)境下的規(guī)劃任務(wù)需求,飛行器在線航跡規(guī)劃問題并不追求得到問題的最優(yōu)解,而是盡可能快地得到可行解。因此,區(qū)別于傳統(tǒng)改進方法中對啟發(fā)信息的加權(quán),引入收縮因子改進A*算法代價函數(shù)。由于復(fù)雜地形環(huán)境對多約束條件下A*算法性能有著巨大影響,在不同任務(wù)場景中難以根據(jù)工程經(jīng)驗確定收縮因子的大小。對于遺傳算法、梯度優(yōu)化等傳統(tǒng)優(yōu)化算法而言,難以結(jié)合A*算法的整體規(guī)劃過程對其航跡最優(yōu)與求解效率構(gòu)建目標(biāo)優(yōu)化模型,僅能夠針對特定任務(wù)場景下的A*算法收縮因子進行優(yōu)化,故優(yōu)化結(jié)果不具備通用性。而深度確定性策略梯度(deep deterministic policy gradient, DDPG)方法能夠綜合利用神經(jīng)網(wǎng)絡(luò)與強化學(xué)習(xí)無模型學(xué)習(xí)的優(yōu)勢,以提升算法綜合性能為訓(xùn)練目標(biāo)設(shè)計獎勵函數(shù),無需構(gòu)建具體優(yōu)化模型,將A*算法整體規(guī)劃作為學(xué)習(xí)訓(xùn)練的抽象環(huán)境,利用神經(jīng)網(wǎng)絡(luò)擬合改進A*算法代價函數(shù)的收縮因子。因此,首先建立A*算法時間性能與最優(yōu)性能變化度量模型;然后,結(jié)合DDPG方法設(shè)計神經(jīng)網(wǎng)絡(luò)與A*算法搜索的復(fù)合架構(gòu),對不同任務(wù)場景收縮因子策略進行訓(xùn)練;最后,在線飛行時依據(jù)離線訓(xùn)練結(jié)果確定的收縮因子進行三維A*算法在線航跡規(guī)劃。
1 問題描述與分析
1.1 航跡規(guī)劃模型
在線航跡規(guī)劃首先需要考慮戰(zhàn)場環(huán)境約束條件,通過對拓展節(jié)點的篩選實現(xiàn)算法搜索空間的剪枝。典型戰(zhàn)場環(huán)境約束條件包括地面地形約束、禁飛區(qū)約束、平臺安全約束等[28-29]。此外,規(guī)劃航跡節(jié)點的拓展與自身飛行性能約束緊密結(jié)合,確定了航跡節(jié)點在規(guī)劃空間中的搜索邊界。典型飛行性能約束條件包括最短航跡長度約束、最小轉(zhuǎn)彎半徑約束與最大轉(zhuǎn)彎角約束、最大俯仰角約束以及機動能力約束。
(1)
式中:第一式表征最短航跡長度約束,lmin為由飛行器自身性能確定的最小航跡長度,h為拓展節(jié)點步長,hmin為最小步長;第二式表征最小轉(zhuǎn)彎半徑約束,φ為航向角,βmax為最大轉(zhuǎn)彎角,PiPi+1=(xi+1-xi,yi+1-yi,zi+1-zi)表征由相鄰節(jié)點確定的航跡片段;第三式表征最大俯仰角約束,αmax為最大俯仰角,z為節(jié)點高程值;第四式表征機動性能約束與飛行器飛行過程中其他約束的參數(shù)關(guān)系,v為飛行速度,nmax為最大可用過載,g為重力加速度。
1.2 三維A*算法拓展方式
結(jié)合航跡規(guī)劃模型中建立的飛行性能約束,航跡節(jié)點在三維空間中以生成樹的方式展開,進行拓展搜索。搜索過程具體為:以當(dāng)前點為球心、搜索步長為半徑的球面上對上、下、左、右、前與斜對角等9個方向進行搜索,則當(dāng)前飛行器飛行至第k個航跡節(jié)點時在發(fā)射坐標(biāo)系下的姿態(tài)角為
(2)
為保證拓展節(jié)點的搜索粒度,可考慮將水平方向和垂直方向上的搜索范圍按角度等分。由此,根據(jù)算法步長與俯仰角和轉(zhuǎn)彎角約束,將規(guī)劃空間離散成可供拓展的航跡節(jié)點。各節(jié)點包括高程坐標(biāo)信息、俯仰角、轉(zhuǎn)彎角和評價函數(shù)值的六要素信息。設(shè)當(dāng)前搜索節(jié)點Pcur(xcur,ycur,zcur,αcur,βcur,Fcur),對應(yīng)父節(jié)點Ppar(xpar,ypar,zpar,αpar,βpar,Fpar),拓展節(jié)點為Pnext={Pnext,i|i=1,2,…},拓展方式如圖1所示。
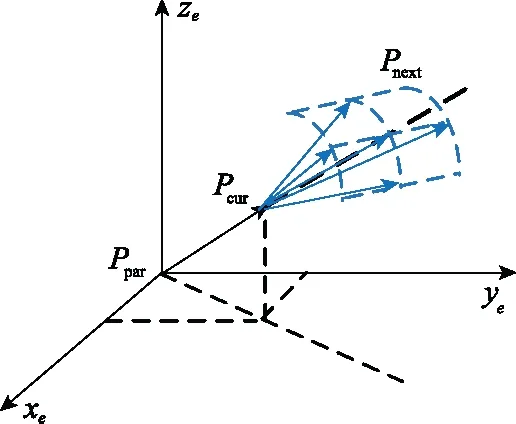
圖1 拓展方式示意圖Fig.1 Schematic diagram of expansion mode
1.3 三維A*算法代價函數(shù)
A*算法在Dijkstra算法的基礎(chǔ)上,采用貪心策略,通過在搜索過程中引入啟發(fā)信息,使搜索節(jié)點趨向于最優(yōu)路徑。代價函數(shù)包括當(dāng)前節(jié)點到起始點的路程信息和當(dāng)前節(jié)點到目標(biāo)節(jié)點的啟發(fā)信息兩個部分。在傳統(tǒng)代價函數(shù)改進中對啟發(fā)信息加權(quán),具體形式為
f=fg+ε·fh
(3)
式中:fg為采用曼哈頓方法確定的當(dāng)前節(jié)點到起始點間的路程代價;fh為當(dāng)前節(jié)點到目標(biāo)點的啟發(fā)信息;ε為啟發(fā)信息在代價函數(shù)中的權(quán)重系數(shù)。當(dāng)ε=1時,代價函數(shù)中的啟發(fā)信息與路程信息的量級相同,此時為標(biāo)準(zhǔn)A*算法;當(dāng)ε>1時,代價函數(shù)中啟發(fā)信息膨脹,隨著ε的增大,航跡節(jié)點的搜索拓展更傾向于目標(biāo)搜索節(jié)點,最終航跡規(guī)劃結(jié)果的航跡長度增加,求解時間減小。這表明:權(quán)重系數(shù)的增大能夠通過犧牲規(guī)劃結(jié)果最優(yōu)性來提升算法時間性能。特別地,當(dāng)ε=0時,標(biāo)準(zhǔn)A*算法退化為Dijkstra算法。
雖然啟發(fā)信息的加權(quán)能夠提升算法實時性能,但隨著加權(quán)系數(shù)的增大,代價函數(shù)值在A*算法列表搜索時也隨之存在數(shù)值爆炸的問題,影響搜索效率。因此,將啟發(fā)信息的權(quán)重系數(shù)轉(zhuǎn)換為路程代價的收縮因子,使得權(quán)重系數(shù)限定在有限區(qū)間內(nèi),避免搜索過程中列表代價函數(shù)值爆炸,代價函數(shù)變形為
(4)
式中:ω為路程信息在代價函數(shù)中的收縮因子,表征當(dāng)前路程代價的權(quán)重。本文后續(xù)針對路程代價的收縮因子展開對代價函數(shù)權(quán)重系數(shù)的優(yōu)化設(shè)計。
2 結(jié)合DDPG的改進A*算法
2.1 強化學(xué)習(xí)模型
強化學(xué)習(xí)的本質(zhì)是當(dāng)前研究的對象(智能體)與環(huán)境的交互。智能體通過對環(huán)境的感知確定當(dāng)前的狀態(tài),依據(jù)既定策略在環(huán)境中選擇動作,進而完成智能體的動作-狀態(tài)轉(zhuǎn)移。在智能體與環(huán)境的交互過程中,通過值函數(shù)對智能體選擇策略進行獎懲,實現(xiàn)滿足目標(biāo)期望的迭代學(xué)習(xí)優(yōu)化,使得智能體最終能夠獲得最多的累計獎勵。本節(jié)根據(jù)研究問題與對象設(shè)計智能體、狀態(tài)、動作等概念,建立強化學(xué)習(xí)模型。
2.1.1 動作-狀態(tài)設(shè)計
考慮本文研究對象與內(nèi)容,在A*算法求解航跡規(guī)劃過程中,收縮因子的大小影響了規(guī)劃結(jié)果最優(yōu)性和時間性能。其中,由于A*算法中的節(jié)點拓展搜索方法采取定步長策略,規(guī)劃航跡結(jié)果長度與航跡節(jié)點數(shù)目成正比,故可將航跡長度最優(yōu)問題轉(zhuǎn)化為航跡節(jié)點數(shù)目最優(yōu)問題。因此,強化學(xué)習(xí)模型中的智能體即為概念實體A*算法,對應(yīng)的狀態(tài)即為A*算法的算法時間性能和規(guī)劃結(jié)果最優(yōu)性能在當(dāng)前收縮因子影響下的優(yōu)化程度,動作即為選定的收縮因子,則動作-狀態(tài)空間映射可表示為
A={ω|ω∈[0,1]}→S={st,se}
(5)
式中:A為智能體動作集;S為智能體狀態(tài)集;st為A*算法時間性能在當(dāng)前選定收縮因子下相對于標(biāo)準(zhǔn)A*算法時間性能的變化量;se為A*算法最優(yōu)性能在當(dāng)前選定收縮因子下相對標(biāo)準(zhǔn)A*算法最優(yōu)性能的變化量。
記t為A*算法在當(dāng)前選定收縮因子下進行航跡規(guī)劃所需的時間;e為A*算法在當(dāng)前選定收縮因子下進行航跡規(guī)劃最終結(jié)果的航跡節(jié)點數(shù)目。算法性能變化的衡量以收縮因子w=1時對應(yīng)的標(biāo)準(zhǔn)A*算法性能為基準(zhǔn),量化百分比指標(biāo)為
(6)
式中:si為當(dāng)前縮減因子條件下A*算法航跡規(guī)劃后的性能參數(shù)提升百分比;sori為改進前標(biāo)準(zhǔn)A*算法對應(yīng)的性能參數(shù);simp為引入收縮因子后改進A*算法對應(yīng)的性能參數(shù)。
2.1.2 獎勵函數(shù)設(shè)計
獎勵函數(shù)的設(shè)計是強化學(xué)習(xí)模型的難點,決定了強化學(xué)習(xí)方法在學(xué)習(xí)迭代后最終收斂的期望與目標(biāo)。在本文的研究問題中,獎勵函數(shù)是衡量收縮因子的選取對A*算法時間性能和結(jié)果最優(yōu)性能影響的數(shù)學(xué)模型,反映了在解決飛行器航跡規(guī)劃問題時對A*算法時間性能與航跡最優(yōu)性能的需求與側(cè)重。兩者變化的歸一化度量為
(7)
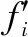
考慮飛行器航跡規(guī)劃問題對算法時間性能與結(jié)果最優(yōu)性能的要求,設(shè)計評價函數(shù):
(8)
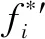
考慮獎懲關(guān)系,時間性能提升程度越大則給定獎勵,最優(yōu)性能降低程度越大則給定懲罰,結(jié)合式(6)設(shè)計獎勵函數(shù):
(9)

2.2 結(jié)合DDPG的改進方法
2.2.1 DDPG原理[30]
強化學(xué)習(xí)方法的基本過程是通過策略優(yōu)化迭代進行動作狀態(tài)轉(zhuǎn)移,從而實現(xiàn)最大獎勵總和,DDPG采用Actor-Critic方法架構(gòu)結(jié)合神經(jīng)網(wǎng)絡(luò)和梯度策略(policy gradient, PG)。一方面,在策略函數(shù)μ模擬的卷積神經(jīng)網(wǎng)絡(luò)中,即Actor動作估計網(wǎng)絡(luò)(策略網(wǎng)絡(luò)),采用行為策略β和離線(off-policy)生成狀態(tài)動作轉(zhuǎn)移策略經(jīng)驗回放的訓(xùn)練數(shù)據(jù)集;另一方面,在狀態(tài)價值函數(shù)Q模擬的卷積神經(jīng)網(wǎng)絡(luò)中,即Critic狀態(tài)估計網(wǎng)絡(luò)(Q網(wǎng)絡(luò)),在策略網(wǎng)絡(luò)訓(xùn)練數(shù)據(jù)集基礎(chǔ)上進行采樣,進而迭代學(xué)習(xí)得到最優(yōu)策略。區(qū)別于PG方法選擇動作的概率策略,DDPG方法采用確定性的行為策略β。特別地,在策略網(wǎng)絡(luò)參數(shù)的訓(xùn)練過程中,動作決策采用Ornstein-Uhlenbeck隨機過程引入噪聲,通過時序相關(guān)的隨機探索,提升算法對潛在更優(yōu)策略的探索效率。
(10)

yt=E[Qμ(st,at)]=
(11)
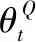
(12)
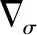
(13)
(14)
通過上述損失函數(shù)計算函數(shù)梯度并更新對應(yīng)網(wǎng)絡(luò)的權(quán)值,采用軟更新方法將網(wǎng)絡(luò)參數(shù)從當(dāng)前網(wǎng)絡(luò)更新到目標(biāo)網(wǎng)絡(luò):
θμ-←τ·θμ+(1-τ)·θμ′
(15)
θQ-←τ·θQ+(1-τ)·θQ′
(16)
式中:τ為軟策略更新因子。
2.2.2 收縮因子訓(xùn)練框架
區(qū)別于確定性策略梯度(deterministic policy gradient, DPG)方法的Actor-Critic雙網(wǎng)絡(luò),DDPG方法將各網(wǎng)絡(luò)擴增為當(dāng)前網(wǎng)絡(luò)和目標(biāo)網(wǎng)絡(luò)。Actor當(dāng)前網(wǎng)絡(luò)負(fù)責(zé)策略網(wǎng)絡(luò)參數(shù)的迭代更新,而Actor目標(biāo)網(wǎng)絡(luò)則負(fù)責(zé)根據(jù)經(jīng)驗回放池中的狀態(tài)采樣選擇最優(yōu)動作。Critic當(dāng)前網(wǎng)絡(luò)負(fù)責(zé)Q網(wǎng)絡(luò)參數(shù)迭代更新,而Critic目標(biāo)網(wǎng)絡(luò)負(fù)責(zé)當(dāng)前值函數(shù)計算,具體結(jié)構(gòu)如圖2所示。
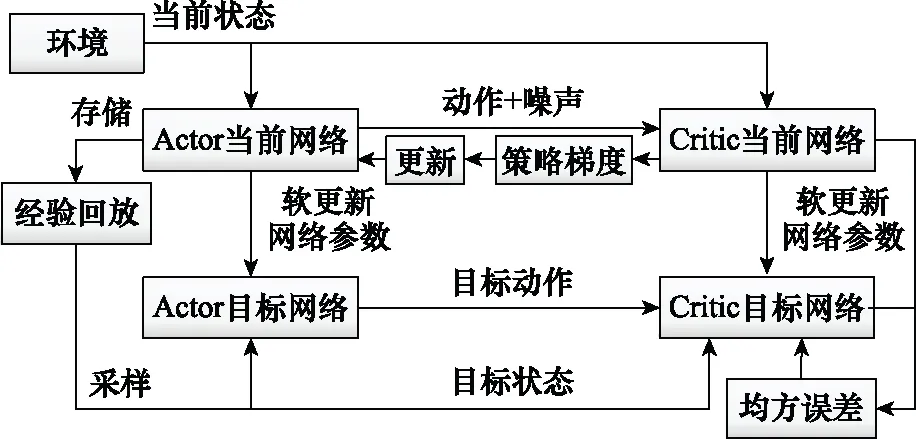
圖2 Actor-Critic雙網(wǎng)絡(luò)架構(gòu)示意圖Fig.2 Schematic diagram of Actor-Critic network
結(jié)合A*算法代價函數(shù)中權(quán)重系數(shù)的優(yōu)化設(shè)計,DDPG算法的循環(huán)結(jié)構(gòu)如圖3所示。
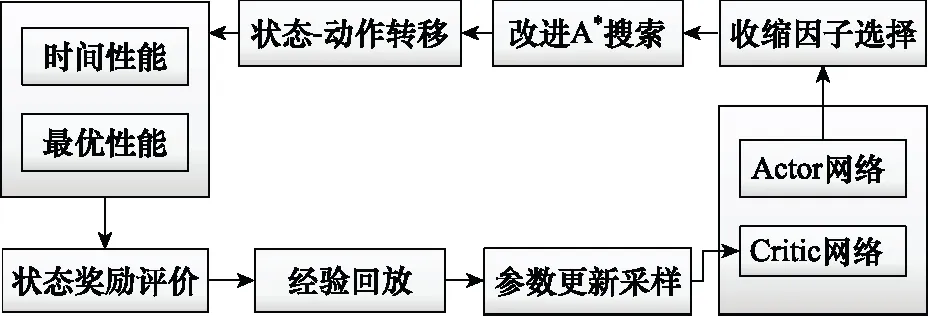
圖3 算法循環(huán)結(jié)構(gòu)示意圖Fig.3 Schematic diagram of algorithm cycle structure
綜上,基于DDPG方法的A*算法代價函數(shù)中的權(quán)重系數(shù)優(yōu)化設(shè)計方法流程如圖4所示。首先,對卷積神經(jīng)網(wǎng)絡(luò)參數(shù)與經(jīng)驗回放池進行參數(shù)初始化;然后,Actor-Critic網(wǎng)絡(luò)從經(jīng)驗回放池中選取與動作對應(yīng)的收縮因子;接著,由改進A*算法求解任務(wù)點間航跡規(guī)劃,并得到算法求解時間與規(guī)劃結(jié)果節(jié)點數(shù)目;進而,完成狀態(tài)-動作轉(zhuǎn)移并計算即時獎勵與損失函數(shù);重復(fù)上述訓(xùn)練步驟直至完成最大迭代次數(shù)后,隨機更新A*算法航跡規(guī)劃任務(wù)點信息,重復(fù)訓(xùn)練直至達到最大學(xué)習(xí)次數(shù);最終,由此得到對應(yīng)固定環(huán)境下的收縮因子策略。
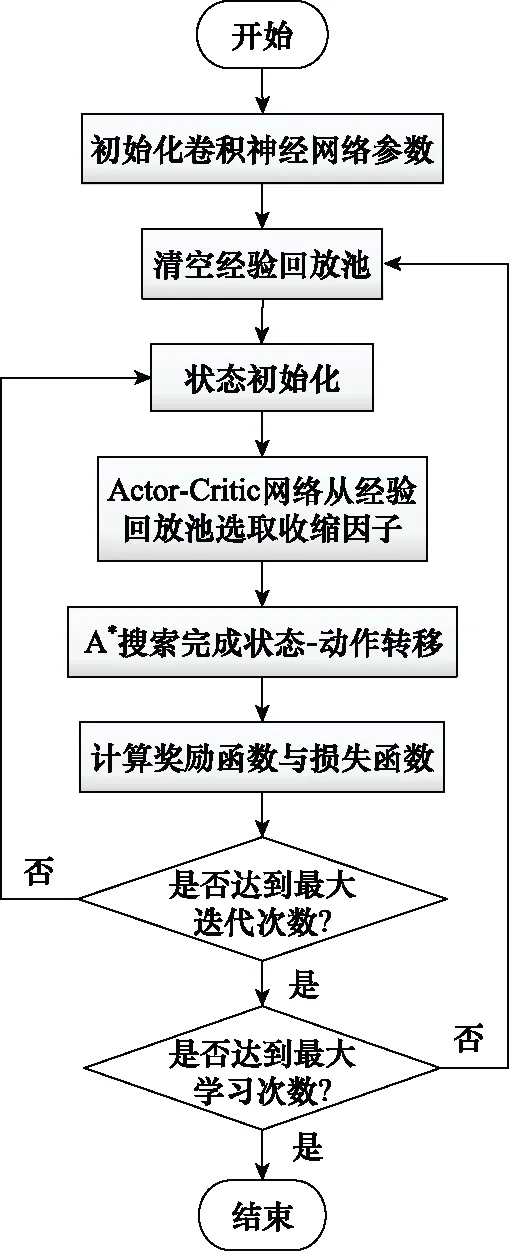
圖4 結(jié)合DDPG算法流程圖Fig.4 Flow chart of algorithm combined with DDPG
分析訓(xùn)練過程可知,在每一代訓(xùn)練前將任務(wù)點等信息隨機初始化,在訓(xùn)練過程中反復(fù)調(diào)用A*算法對航跡規(guī)劃問題進行求解,收縮因子策略的訓(xùn)練時間較長。因此,在線航跡規(guī)劃采用離線訓(xùn)練在線應(yīng)用的策略,在飛行器出發(fā)前對既定戰(zhàn)場環(huán)境下的收縮因子確定策略進行離線訓(xùn)練,而在飛行器在線飛行過程中則根據(jù)由離線學(xué)習(xí)結(jié)果而確定的收縮因子,采用改進A*算法實現(xiàn)三維航跡在線規(guī)劃。訓(xùn)練完成后,Actor網(wǎng)絡(luò)中存放了可最大程度提升算法綜合性能的收縮因子策略。由第2.1節(jié)可知,模型中狀態(tài)為收縮因子對時間性能與最優(yōu)性能的優(yōu)化程度,動作對應(yīng)收縮因子,環(huán)境指A*算法的整體規(guī)劃過程。因此,本文提出的強化學(xué)習(xí)模型具有通用性,訓(xùn)練的收縮因子策略能夠適用于不同作戰(zhàn)任務(wù)場景。
3 仿真分析
本節(jié)首先在三維靜態(tài)環(huán)境下驗證收縮因子對A*算法航跡規(guī)劃時間性能與規(guī)劃結(jié)果最優(yōu)性能的影響;然后結(jié)合DDPG方法對收縮因子進行訓(xùn)練,并考慮多組不同任務(wù)點與禁飛區(qū)的仿真場景,對比文獻[13]提出的指數(shù)衰減加權(quán)方法,驗證本文提出的改進A*算法在靜態(tài)場景下的規(guī)劃性能;最后在動態(tài)場景下驗證結(jié)合DDPG訓(xùn)練收縮因子策略的改進A*方法的在線航跡規(guī)劃能力。
3.1 引入收縮因子的改進A*算法仿真實驗
仿真選定北緯38°至北緯39°與西經(jīng)112°至西經(jīng)113°的單元經(jīng)緯網(wǎng)格作為戰(zhàn)場環(huán)境,戰(zhàn)場環(huán)境地面地形如圖5所示,飛行器性能參數(shù)如表1所示,敵方禁飛區(qū)經(jīng)緯坐標(biāo)與威脅半徑參數(shù)如表2所示。
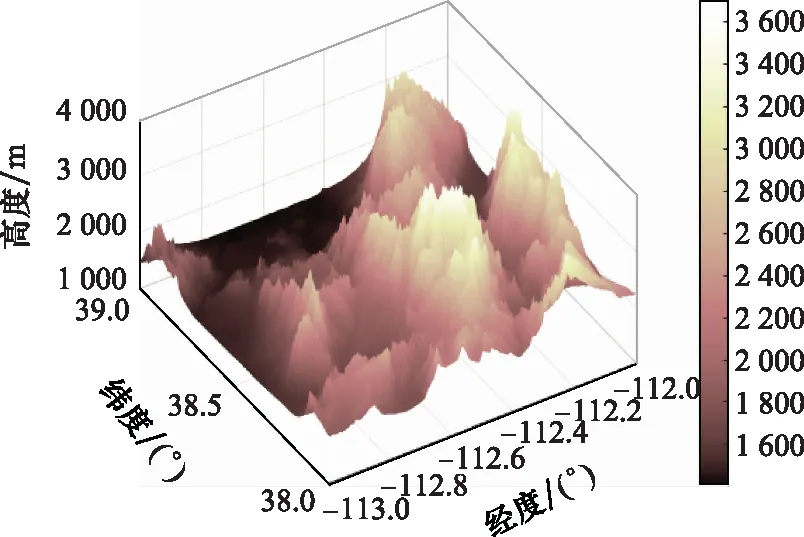
圖5 戰(zhàn)場環(huán)境地面地形圖Fig.5 Topographic map of battlefield environment

表1 飛行器性能參數(shù)表
為進一步提升算法時間性能,考慮算法存儲空間與排序搜索方法:① 為避免A*算法中開放列表中的拓展節(jié)點數(shù)目過多,消耗大量排序與計算時間,考慮引入存儲空間約束以進一步提升算法計算效率;② 考慮采用二叉堆方法對代價函數(shù)值進行排序[31],若當(dāng)前開放列表中節(jié)點數(shù)目超過預(yù)設(shè)存儲空間上限,則根據(jù)排序結(jié)果將代價函數(shù)值最大的拓展節(jié)點移除,以保證拓展節(jié)點搜索效率。

表2 禁飛區(qū)參數(shù)表
選定收縮因子值區(qū)間邊界驗證收縮因子對算法時間性能的影響,進而確定后續(xù)DDPG方法訓(xùn)練收縮因子時所需的值函數(shù)。兩者規(guī)劃結(jié)果對比如圖6與圖7所示。
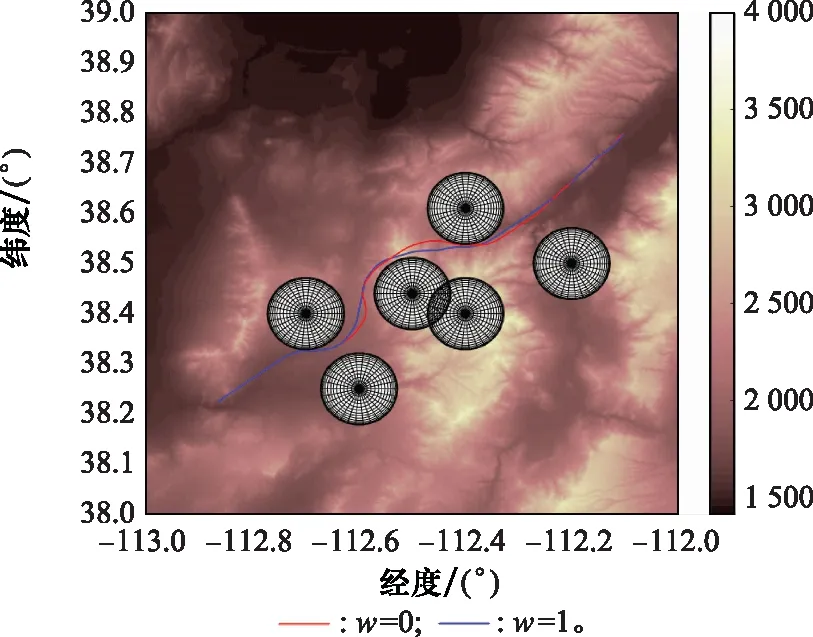
圖6 標(biāo)準(zhǔn)A*算法與改進A*算法規(guī)劃結(jié)果平面圖Fig.6 2D comparison diagram of planning results between standard and improved A* algorithm
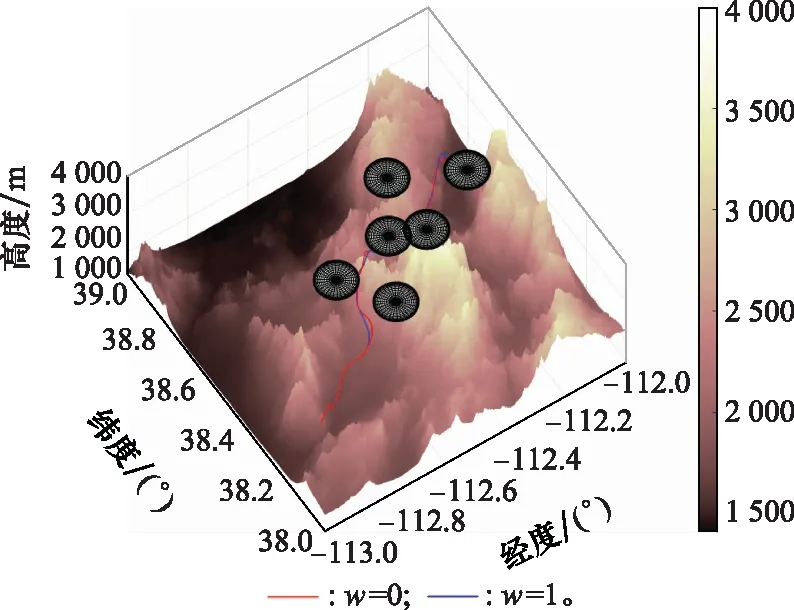
圖7 標(biāo)準(zhǔn)A*算法與改進A*算法規(guī)劃結(jié)果三維圖Fig.7 3D comparison diagram of planning results between standard and improved A* algorithm
當(dāng)w=1時,標(biāo)準(zhǔn)A*算法的仿真時間為264.13 s,規(guī)劃結(jié)果節(jié)點數(shù)目為49個;當(dāng)w=0時,改進A*算法運行時間為0.932 s,規(guī)劃節(jié)點數(shù)目為53個。分析兩者仿真時間、規(guī)劃結(jié)果節(jié)點數(shù)目以及規(guī)劃路徑結(jié)果可以發(fā)現(xiàn),引入收縮因子后,改進A*算法的規(guī)劃結(jié)果滿足戰(zhàn)場環(huán)境約束與飛行器性能約束,能夠在保證航跡規(guī)劃結(jié)果可行的前提下提升算法時間性能。
3.2 結(jié)合DDPG方法的收縮因子訓(xùn)練仿真實驗
結(jié)合DDPG方法對收縮因子進行迭代訓(xùn)練,在每一代訓(xùn)練前更新任務(wù)點信息,依據(jù)收縮因子值區(qū)間邊界的A*算法航跡規(guī)劃仿真結(jié)果。以第3.1節(jié)仿真場景為例確定獎勵函數(shù)對應(yīng)參數(shù),如表3所示。

表3 獎勵函數(shù)參數(shù)表
DDPG卷積神經(jīng)網(wǎng)絡(luò)參數(shù)如表4所示。
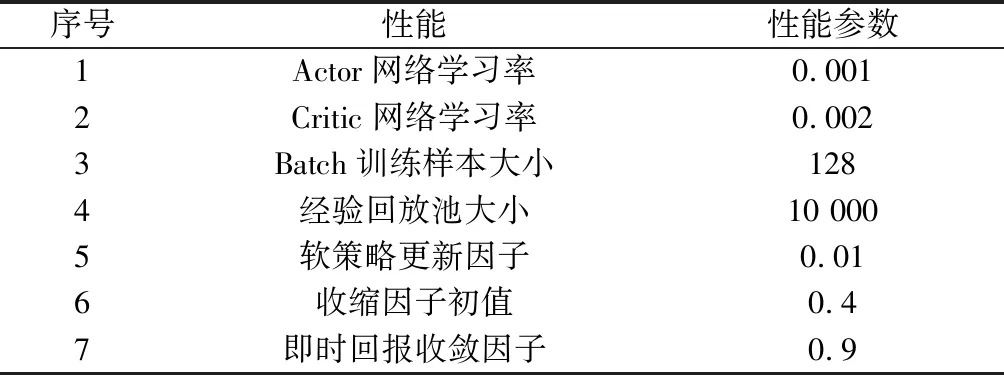
表4 卷積神經(jīng)網(wǎng)絡(luò)參數(shù)表
DDPG方法訓(xùn)練A*算法收縮因子策略的仿真環(huán)境為Pycharm 2020.3.1,處理器配置為Intel(R)CoreTMi9-10885H CPU @ 2.40 GHz,累計訓(xùn)練迭代次數(shù)為1 000次,總訓(xùn)練時間為20.2 min。狀態(tài)變量隨訓(xùn)練迭代次數(shù)的變化結(jié)果如圖8與圖9所示,反映了改進A*算法在引入收縮因子后相對于標(biāo)準(zhǔn)A*算法的時間性能與最優(yōu)性能隨迭代次數(shù)的變化。在此基礎(chǔ)上,進一步分析迭代訓(xùn)練下的收縮因子變化與獎勵函數(shù)總回報隨迭代次數(shù)的變化關(guān)系,訓(xùn)練結(jié)果如圖10與圖11所示。
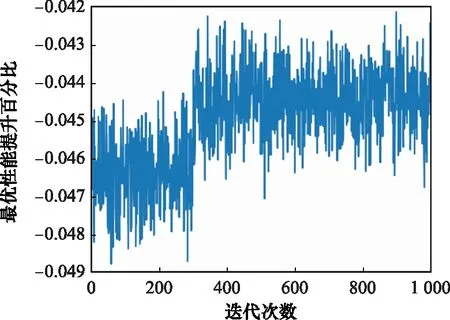
圖8 改進算法最優(yōu)性能變化圖Fig.8 Variation diagram of improved algorithm optimal performance
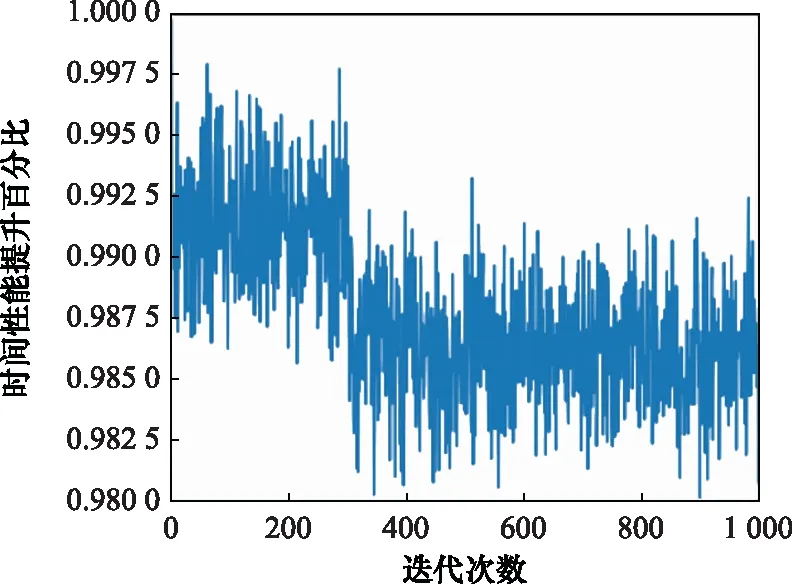
圖9 改進算法時間性能變化圖Fig.9 Variation diagram of improved algorithm time performance

圖10 迭代收斂的收縮因子圖Fig.10 Diagram of shrinkage factor of iterative convergence
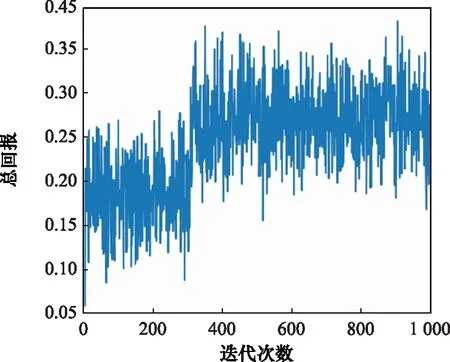
圖11 迭代收斂的總回報圖Fig.11 Diagram of total reward of iterative convergence
分析收縮因子迭代訓(xùn)練結(jié)果可知,在訓(xùn)練初期收縮因子在給定初值附近進行探索,收縮因子越小,算法時間性能越可以得到顯著提升,規(guī)劃的航跡結(jié)果軌跡長度最優(yōu)性能略微下降。收縮因子策略訓(xùn)練在300代后逐漸收斂,獎勵函數(shù)總回報穩(wěn)定在[0.121.0.372],最終確定收縮因子穩(wěn)定在[0.415,0.429]。
3.3 靜態(tài)對比仿真實驗
在第3.1節(jié)場景基礎(chǔ)上設(shè)計不同任務(wù)點與禁飛區(qū)位置的任務(wù)場景,根據(jù)第3.2節(jié)中訓(xùn)練的收縮因子策略結(jié)果,對多任務(wù)場景進行航跡規(guī)劃仿真,并與文獻[13]提出的指數(shù)衰減加權(quán)方法進行對比。設(shè)多組不同任務(wù)點與禁飛區(qū)的經(jīng)緯坐標(biāo)如表5所示。其中,第1、2、3組與第4、5、6組的任務(wù)點不同且禁飛區(qū)位置相同;第1、4組與第2、5組與第3、6組的任務(wù)點相同且禁飛區(qū)位置不同。表6給出了設(shè)計的6組任務(wù)場景下,兩種改進A*算法的仿真時間與規(guī)劃結(jié)果節(jié)點數(shù)目的仿真結(jié)果。

表5 仿真場景參數(shù)表

表6 各場景仿真結(jié)果表
以表5中的場景1為例,指數(shù)衰減加權(quán)方法的改進A*算法運行時間為9.612 s,規(guī)劃結(jié)果節(jié)點數(shù)目為69個;結(jié)合DDPG方法訓(xùn)練收縮因子策略的改進A*算法的運行時間為1.373 s,規(guī)劃結(jié)果節(jié)點數(shù)目為52個,兩種改進方法的航跡結(jié)果對比如圖12與圖13所示。
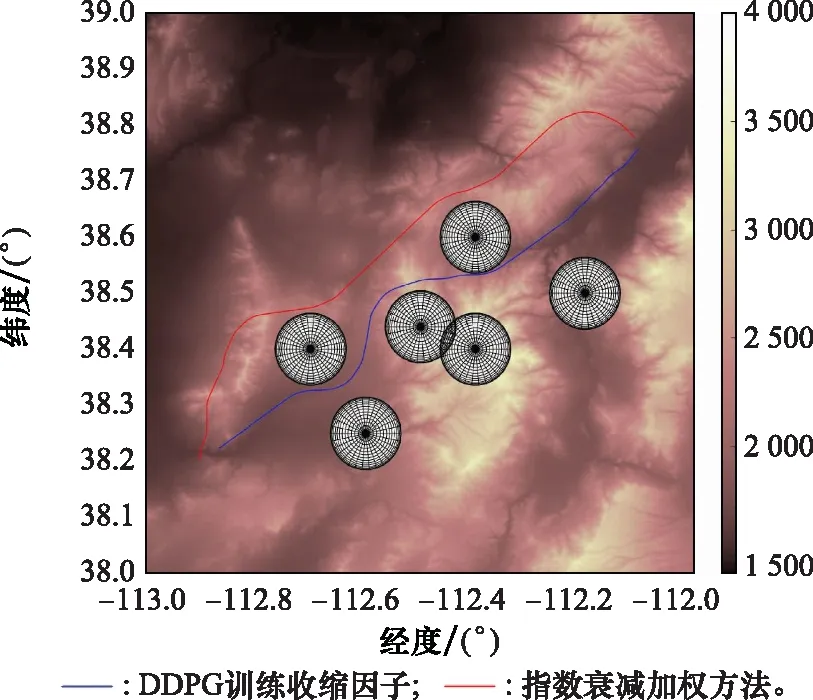
圖12 兩種改進A*算法規(guī)劃結(jié)果平面圖Fig.12 2D comparison diagram of planning results between two improved A* algorithms
分析表6仿真結(jié)果可知,結(jié)合DDPG方法訓(xùn)練的收縮因子策略相較于指數(shù)衰減加權(quán)方法,改進效果好且魯棒性強,而指數(shù)衰減加權(quán)方法規(guī)劃結(jié)果最優(yōu)性差強人意,且對于不同地形環(huán)境與任務(wù)場景的改進效果不穩(wěn)定。
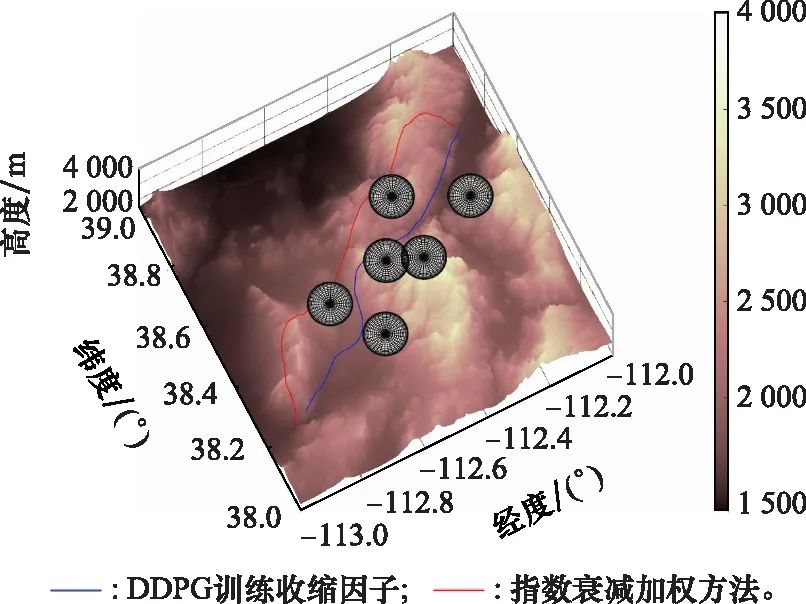
圖13 兩種改進A*算法規(guī)劃結(jié)果三維圖Fig.13 3D comparison diagram of planning results between two improved A* algorithms
3.4 三維動態(tài)仿真實驗
為驗證改進A*算法在線航跡規(guī)劃方法的可行性與有效性,在第3.1節(jié)場景基礎(chǔ)上設(shè)計動態(tài)威脅,飛行器飛行性能參數(shù)與表1 設(shè)置相同。設(shè)禁飛區(qū)3向南以15 m/s的速度勻速運動,禁飛區(qū)5向北以15 m/s的速度勻速運動,禁飛區(qū)6沿北偏西45°方向以15 m/s的速度勻速運動。在第3.2節(jié)收縮因子訓(xùn)練結(jié)果的基礎(chǔ)上,采用改進A*算法,設(shè)拓展節(jié)點的步長為2 km,以10 s為滾動規(guī)劃周期對三維動態(tài)場景進行在線航跡規(guī)劃,最終全過程仿真結(jié)果如圖14與圖15所示。
分析仿真結(jié)果,飛行器全段飛行仿真時間為580.0 s,總航跡節(jié)點數(shù)目為58個,規(guī)劃航跡結(jié)果滿足地形環(huán)境與飛行器性能約束。仿真結(jié)果表明,結(jié)合DDPG方法訓(xùn)練收縮因子策略改進后的A*算法能夠滿足飛行器在線航跡規(guī)劃的時間性能要求。
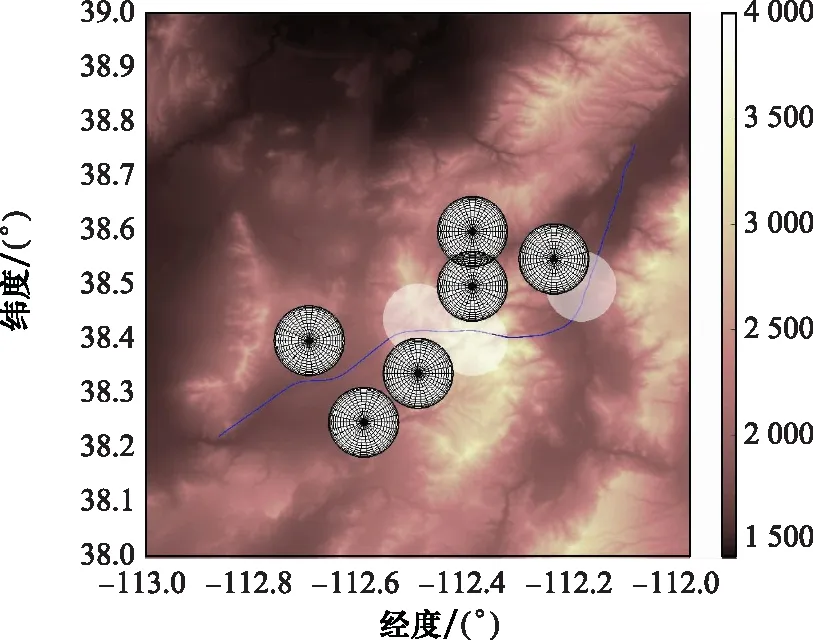
圖14 動態(tài)場景改進算法規(guī)劃結(jié)果平面圖Fig.14 2D diagram of planning results for improved algorithm in dynamic scenario
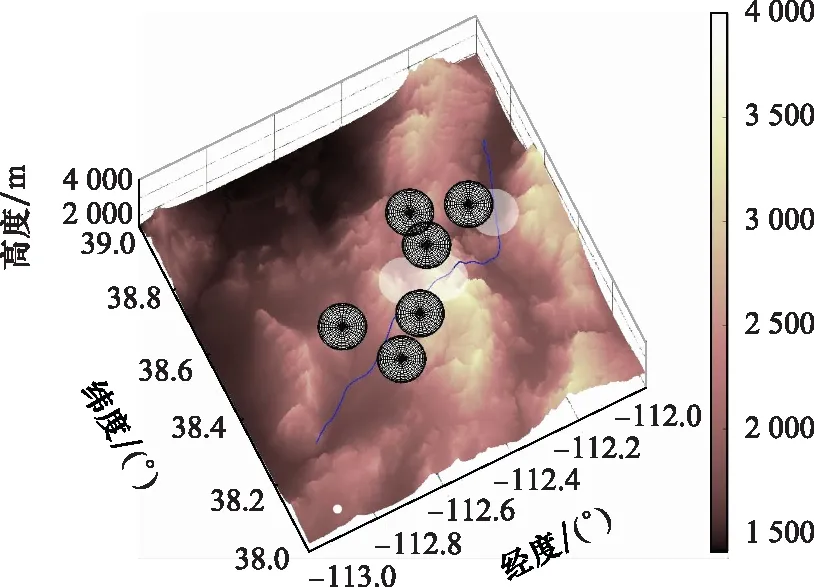
圖15 動態(tài)場景改進A*算法規(guī)劃結(jié)果三維圖Fig.15 3D diagram of planning results for improved algorithm in dynamic scenario
4 結(jié) 論
基于強化學(xué)習(xí)方法改進三維A*算法,在保證飛行器三維航跡規(guī)劃結(jié)果最優(yōu)性的同時提升了算法的時間性能。引入收縮因子改進A*算法代價函數(shù)加權(quán)方法,解決了啟發(fā)信息加權(quán)后在A*搜索時列表中代價函數(shù)值過大而影響搜索效率的問題,進一步提升了算法時間性能。考慮收縮因子對規(guī)劃結(jié)果最優(yōu)性與實時性的影響,建立綜合指標(biāo)模型,并結(jié)合DDPG方法對收縮因子進行訓(xùn)練優(yōu)化。針對復(fù)雜約束條件與地形環(huán)境的不同仿真場景,改進算法的時間性能均能滿足在線航跡規(guī)劃的實時性要求,且算法規(guī)劃結(jié)果滿足飛行器自身性能條件與戰(zhàn)場環(huán)境約束。
猜你喜歡
公民與法治(2020年11期)2020-07-25 02:02:06
兒童故事畫報(2019年5期)2019-05-26 14:26:14
領(lǐng)導(dǎo)決策信息(2018年50期)2018-02-22 06:17:16
商周刊(2017年5期)2017-08-22 03:35:26
中國衛(wèi)生(2016年2期)2016-11-12 13:22:16
華東科技(2016年10期)2016-11-11 06:17:41
Coco薇(2016年2期)2016-03-22 02:42:52
中國工程咨詢(2016年4期)2016-02-14 07:28:28
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年7期)2015-08-11 15:03:12
