基于R 語言對演講文本的語言特征多維度分析
2023-04-20 08:24:30秦夢娟
現代英語 2023年5期
秦夢娟
(南京傳媒學院,江蘇 南京 211100)
一、理論背景和研究工具
(一)理論背景
定量研究方法在我國外語教學與研究領域的應用十分廣泛,受到國內外應用語言學界的普遍關注和重視。 所謂定量研究是指搜集用數量表示的資料或信息對數據進行量化處理、檢驗和分析,從而獲得有意義的結論的研究過程,這是一種確定事物某方面量的規定性的科學研究。 在外語教學定量研究中應引入穩健性設計方法和利用統計方法[1]。 在文本的語言特征分析中可以加入定量研究手段,借助統計分析軟件,如Coh-Metrix[2]、SPSS、R 軟件等,以加快分析速度。
(二)研究工具
奧克蘭大學統計學系的羅斯?伊哈卡(Ross Ihaka)和羅伯特?杰特曼(Robert Gentleman)受貝爾實驗室S 語言的啟發,于1991 年開發了R 語言。經過三十多年的發展,R 語言現已發展成為一個集統計計算、制圖和自然語言處理等為一體的編程語言。 它既能運行現有的R 程序,又能對現有程序進行改進,以滿足研究者的特殊需要。 R 軟件有強大的社團提供技術支持和疑難解答,成員包括統計學家、程序員和用戶等。 文章采用R 4.2.1 對兩篇演講文本進行語言特征分析,包括詞匯特點、主題詞和N 元組。 這兩篇演講文本均來自R 軟件下數據包quanteda 中的語料庫data_corpus_inaugural,記為文本1 和文本2。
二、詞匯特點分析
利用R 軟件對兩篇文本進行描述性統計,得到統計結果如下:文本1 使用形符1467 個,類符539個,句子數為105 個,平均句長為13.97,平均詞長為4.55;文本2 使用形符2389 個,類符739 個,句子數為225 個,平均句長為10.62,平均詞長為4.23。 可以發現兩篇文本篇幅差異很大,文本2 篇幅遠遠超過文本1 的篇幅,但文本2 的平均句長和平均詞長略低于文本1。
詞匯密度(lexical density)是通過一篇文本中的實詞數與文本中出現的總詞數的比率來計算[3]。通過R 軟件對兩篇文本的詞匯密度進行計算,得出結果如下(保留兩位小數):文本1 的詞匯密度為0.50,文本2 的詞匯密度為0.47。 兩者差異不大,文本1 所用實詞比例更高。
詞匯復雜性(lexical sophistication)也是評估詞匯豐富性的四個指標之一,是指在文本中能夠適當使用與主題、文體相關的低頻詞,而不只是使用常用的高頻詞。 本研究所用低頻詞為Paul Nation 開發的2000 常用詞表,文本中的低頻詞即剔除常用詞后的詞,低頻詞與總詞數之比即文本的詞匯復雜性。 通過R 軟件進行計算,得到結果如下(保留兩位小數):文本1 的詞匯復雜性為20.71,文本2 的詞匯復雜性為24.56。 兩者差異不大,文本2 所用詞匯較為復雜,低頻詞使用較多。
詞匯多樣性(lexical diversity)可以評估發言者的詞匯知識及他們語言輸出中的詞匯變化特點。類符形符比(type-token ratio,TTR)是傳統上測量詞匯多樣性所使用的最普遍的方法,即用一篇文本中使用的不同詞項(類符)的總數除以文本中所有詞項(形符)的總數。 然而,這種方法已被證明受文本大小的影響。 文本越長,TTR 的值就越低[4]。 本研究中采用移動平均類符-形符比(moving-average type-token ratio,MATTR),即按照固定的窗口(即詞符數)從文本開頭計算TTR,然后在文本中依次移動窗口計算TTR,直至在包括文本最后1 個詞符的窗口中計算TTR,最后計算這些窗口TTR 的平均值[5]。 移動平均類符-形符比不會因為文本長度不足舍棄文本末尾的詞符。 通過R 軟件計算兩文本的MATTR 發現,文本1 的MATTR 為0.68,文本2的MATTR 為0.67,幾乎沒有差異。
文章對兩個演說的詞匯特點進行了分析,可以發現兩篇文本的詞匯密度、詞匯多樣性以及詞匯復雜性的差異不大,為了進一步探究兩篇演說文本的難易度差異,利用R 軟件對它們的文本可讀性進行分析,得到以下結果:文本1 的可讀性適用于美國七年級學生(大約12 歲),而文本2 的可讀性適用于美國五年級學生(大約10 歲),兩篇文本的可讀性都比較高,容易被聽眾所理解,體現了演講文本的可講性。
三、主題詞分析
為了更好地對比兩篇文本的語言特征差異,文章對兩篇文本的高頻詞和關鍵詞進行分析。
(一)高頻詞
圖1 為兩篇文本中頻數為20 及以上的詞頻分布條形圖(左:文本1;右:文本2)。
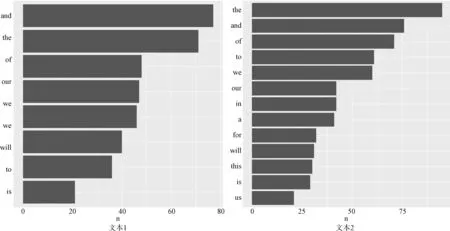
圖1 頻數為20 及以上的詞頻分布條形圖
由圖1 可以得出,文本1 中頻數為20 及以上的高頻詞有8 個,頻數最高的前三個詞為and(出現77次)、the(出現71 次)、of(出現48 次)。 文本2 中頻數為20 及以上的高頻詞有13 個,頻數最高的三個詞為the(出現95 次)、and(出現76 次)和of(出現71次)。 兩文本排列前三的高頻詞相同,均為虛詞,同上文詞匯密度的結果對應,可以發現兩篇文本的虛詞使用較多。 同時,兩篇文本的高頻詞中均出現了we、our 兩個第一人稱代詞和will 情態動詞。 兩位演說者通過三個詞的使用,以此來表達自己強烈的意愿,使聽眾信服他們的觀點,體現了演說文本的鼓動性。
圖2 為兩文本去除停用詞后的、頻數為前100的詞云圖(左:文本1;右:文本2)。
從圖2 可以看出,詞云圖以字體大小顯示詞頻高低,詞頻越高,字體就越大。 文本1 中最醒目的詞是“american”(在形符化時所有的文本詞語均改為小寫字母),“american”一詞在文中出現11 次。其他頻數較高的單詞是“people”(出現10 次)、“country” (出現9 次)、“nation” (出現6 次)、“world”(出現6 次)、“dreams”(出現5 次)。 文本2中最醒目的詞是“american”,“american”一詞在文中出現9 次。 其他頻數較高的單詞是“story”(出現8 次)、“americans”(出現7 次)、“nation”(出現7次)、“days” (出現6 次)、“war” (出現6 次)、“unity”(出現5 次)、“power”(出現5 次)。 可以發現兩篇文本的高頻詞有相似點,也有差異。
(二)關鍵詞對比
關鍵詞(Key words)指某些詞在一個語料庫中出現的頻次明顯高于在另一個語料庫中出現的頻次,能夠體現文本的主題。 圖3 為兩篇文本的關鍵詞對照。
圖3 顯示,文 本1 中“back” “protected” 和“dreams”是最突出使用的3 個詞。 而文本2 中的“us”“can”和“democracy”是最突出使用的3 個詞。基于上文的研究結果,兩篇文本均使用了較多的第一人稱代詞(we/our)和情態動詞(will),文本2 增加了單詞“us”和“can”的使用。 兩篇文本使用不同的關鍵詞體現兩位演說者觀點的差異。
四、N 元組
N 元組是文本中連續出現的長度為n 的形符串,其中n 是不小于1 的整數。 長度n 為1 的元組稱作單元組(unigrams),長度n 為2 的元組稱作二元組(bigrams),長度n 為3 的元組稱作三元組(trigrams),以此類推。 圖4 為兩篇文本中頻次為5 及以上的二元組(左:文本1;右:文本2)。

圖4 高頻二元組
圖4 顯示,文本1 中二元組“we will”出現了24次。 文本1 大量使用第一人稱代詞“we”和情態動詞“will”與對上文的研究結果一致。 而文本2 中除了上文強調的“we can”句式,二元組“we must”也出現了7 次,體現了兩位演說者在演說中情態動詞的選擇差異。 總結上文,可以發現兩篇文本中均大量使用了“we will”句式,文本2 中增加使用了“we can”和“we must”句式,體現了演講稿的鼓動性。
五、結語
文章運用自然語言分析軟件R 4.2.1 進行文本分析,通過分析兩個演講文本的詞匯特點、主題詞和N 元組,從而對兩個演講文本的語言特征進行分析。 研究發現兩個演講文本的語言特征共同點和差異共存。 首先,文本1 的實詞比例更高、更容易為聽眾所理解,因為文本1 的詞匯密度和文本可讀性略高于文本2;而文本2 中低頻詞比例更高,說明文本2 的詞匯復雜性略高于文本1;兩篇文本的詞匯多樣性幾乎一致。 其次,兩篇文本均使用了較多的虛詞,包括the、and、or,也運用了較多的第一人稱代詞和情態動詞,包括we、our、will。 上述單詞的使用,使得兩個文本較容易理解,能使聽眾產生認同感。 但兩個演講文本在關鍵詞、N 元組以及在人稱代詞和情態動詞的選擇上存在差異。 文本2 運用了較多的第一人稱代詞“us”、情態動詞“can”和“must”。 上述結果體現了演講文本具有的鼓動性,也體現了R 軟件在文本分析領域的可行性。
猜你喜歡
音樂探索(2022年2期)2022-05-30 21:01:37
中華胰腺病雜志(2021年1期)2021-02-26 11:28:36
山東醫藥(2020年34期)2020-12-09 01:22:24
制造技術與機床(2019年10期)2019-10-26 02:48:08
中華胰腺病雜志(2019年4期)2019-08-29 08:52:20
小天使·一年級語數英綜合(2019年8期)2019-08-27 02:23:00
電子制作(2018年18期)2018-11-14 01:48:06
小學科學(學生版)(2018年7期)2018-08-13 09:33:04
小學教學參考(2015年20期)2016-01-15 08:44:38
鄭州大學學報(醫學版)(2015年2期)2015-02-27 14:50:46
