基于文本挖掘的軟件漏洞信息知識圖譜構建方法
2023-08-21 09:57:42行久紅牛保民
無線互聯科技 2023年12期
關鍵詞:互聯網技術
行久紅 牛保民


摘要:針對現階段互聯網軟件中存在的漏洞問題,文章提出了基于文本挖掘的軟件漏洞信息知識圖譜構建方法。先確定軟件漏洞信息知識圖譜構建的基本架構,應用文本挖掘技術,完成軟件漏洞信息的采集、預處理與特征提取,然后設計本體模型,完成軟件漏洞信息的抽取與融合,最后設計存儲機制,構建軟件漏洞信息知識圖譜。實驗結果表明,文章所構建知識圖譜的軟件漏洞信息完整度均值為93.6%,構建所需時間均值為1.52 s,均優于對比方法,具有較好的應用價值。
關鍵詞:文本挖掘技術;互聯網技術;軟件漏洞信息;構建知識圖譜
中圖分類號:TP751? 文獻標志碼:A
0 引言
隨著科技的發展,互聯網技術、通信技術等廣泛應用,給人民生活、生產帶來了便利[1],但也帶來了一定危機。目前,網絡安全問題已經成為人民最為重視的問題,信息安全漏洞嚴重威脅個人隱私和財產安全,如不及時處理將會給人民造成經濟財產損失[2]。因此,如何高效地排查軟件漏洞成為互聯網技術領域重點研究的課題之一[3]。知識圖譜可以通過抽取知識融合與分析計算,得到整體描述并挖掘隱藏內涵[4],可將其應用其中,提升軟件漏洞的排查效果。基于此,本文研究了基于文本挖掘技術的軟件漏洞信息知識圖譜構建方法,旨在提高網絡安全管理工作的可靠性,維護網絡信息安全。
1 確定軟件漏洞信息知識圖譜構建的基本架構
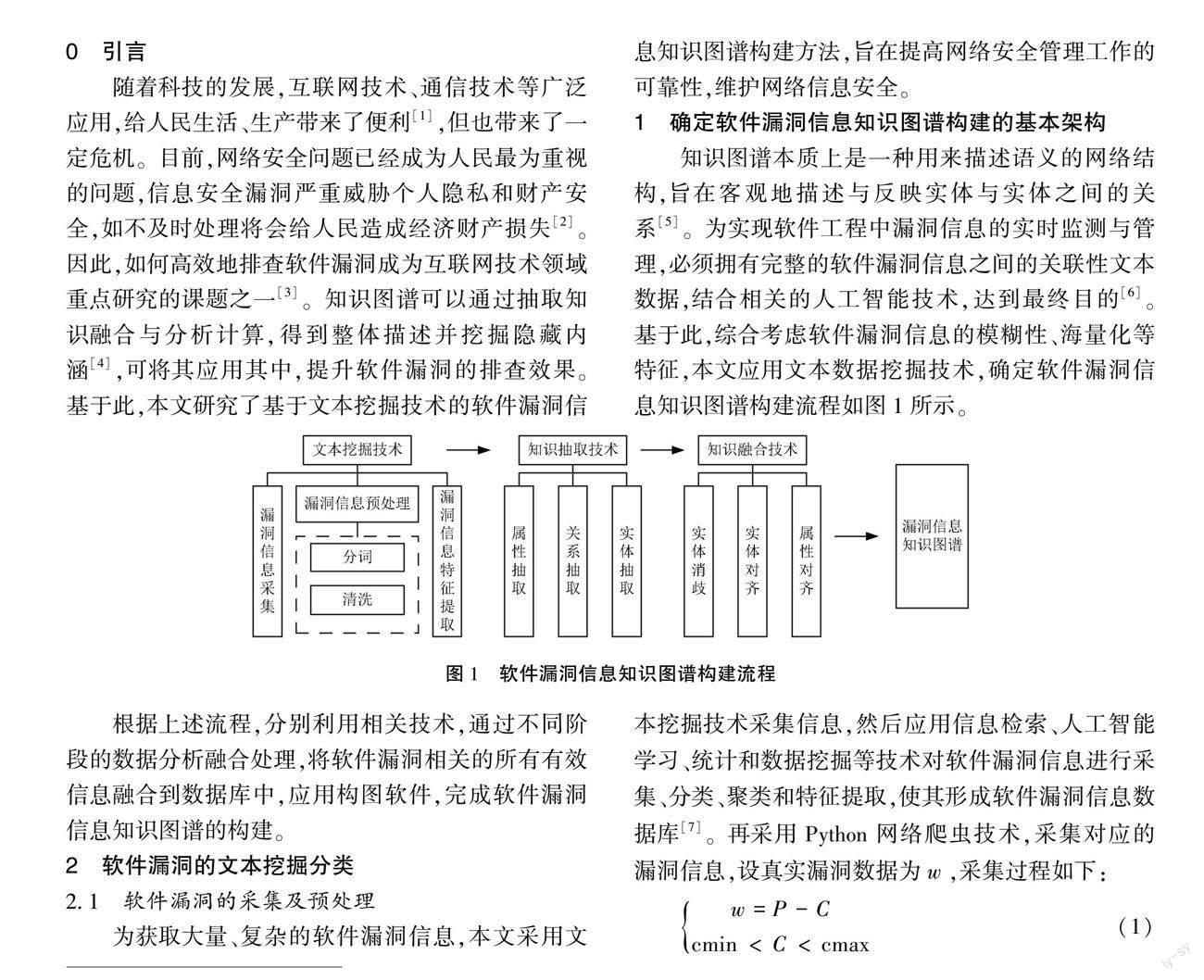
知識圖譜本質上是一種用來描述語義的網絡結構,旨在客觀地描述與反映實體與實體之間的關系[5]。為實現軟件工程中漏洞信息的實時監測與管理,必須擁有完整的軟件漏洞信息之間的關聯性文本數據,結合相關的人工智能技術,達到最終目的[6]。基于此,綜合考慮軟件漏洞信息的模糊性、海量化等特征,本文應用文本數據挖掘技術,確定軟件漏洞信息知識圖譜構建流程如圖1所示。
圖1 軟件漏洞信息知識圖譜構建流程
根據上述流程,分別利用相關技術,通過不同階段的數據分析融合處理,將軟件漏洞相關的所有有效信息融合到數據庫中,應用構圖軟件,完成軟件漏洞信息知識圖譜的構建。
2 軟件漏洞的文本挖掘分類
2.1 軟件漏洞的采集及預處理
為獲取大量、復雜的軟件漏洞信息,本文采用文本挖掘技術采集信息,然后應用信息檢索、人工智能學習、統計和數據挖掘等技術對軟件漏洞信息進行采集、分類、聚類和特征提取,使其形成軟件漏洞信息數據庫[7]。再采用Python網絡爬蟲技術,采集對應的漏洞信息,設真實漏洞數據為w,采集過程如下:
w=P-C
cmin 式(1)中,C為爬蟲檢索出的非有效信息,cmin為漏洞最小信息數據載量,cmax為漏洞最大信息數據載量,P為全部采集信息數據。得到的真實漏洞數據在于中國國家漏洞數據庫中相關的安全漏洞信息核實,并存儲備用。軟件漏洞信息知識圖譜包括軟件信息、漏洞信息、PoC信息以及補丁信息等,需要進行預處理,如分詞和清洗等提高數據信息的有效性,以此來提高構建知識圖譜的準確率和效率。 2.2 軟件漏洞的特征提取 為統一軟件漏洞向量映射的維度,使不同長度大小、不同文本數量、不同計量單位的軟件漏洞信息具有相同維度的向量表示,提高軟件漏洞信息分類的準確性,本文應用文本挖掘技術中的信息增益算法,對軟件漏洞信息的特征信號進行分類與提取[8]。根據自然語義的漏洞信息轉化為數學向量形式的公式為 U=∑wi=1(ψi/σ)(2) 式(2)中,U表示轉化后的自然語義下的漏洞信息,i表示漏洞信息的特征提取條件,ψ表示特征提取條件下的總數據,σ表示特征提取條件外的非定于數據。以此為基礎,將其轉化后,根據每段漏洞信息數學向量的出現次數確定該漏洞在整體信息集合中的權重值,提取出軟件漏洞信息的特征信號,便于后續知識圖譜的構建。 3 構建軟件漏洞信息知識圖譜 3.1 設計軟件漏洞的本體模型 為表述與反映不同軟件漏洞信息之間的關聯性,結合文本挖掘技術設計軟件漏洞的本體模型ω,模型的目標函數表示為: ω={A,E,G,F,H,T,W,Y}(3) 式(3)中,A表示軟件漏洞名稱;E表示軟件屬性;G表示情報信息;F表示評價標準;H表示PoC;T表示補丁;W表示數據當量值;Y表示模型承載量。將上述本體模型中的信息抽取出來,并建立關聯性,以此來實現軟件信息知識圖譜的構建。 3.2 抽取軟件漏洞信息 為提高軟件漏洞信息知識圖譜構建的可靠程度和效率[9],需要進行實體識別和抽取,過程如下: F1(α)=∑ni∈n,j∈n,i≠j(αi-αj)2(4) 式(4)中,α表示抽取中限制參數,F1表示識別出的抽取數據,i,j表示漏洞信息知識圖譜對應的漏洞信息起始數據和終止數據,n表示實際抽取數量。實體抽取技術使用基于規則和詞典的方法,可識別并抽取出軟件漏洞信息中的七大類實體數據;關系抽取技術可通過使用統計、規則和分類器等方法從軟件漏洞信息中提取實體之間的內在關系。針對軟件漏洞的本體模型實體屬性的抽取,需要應用卷積神經網絡算法進行分類和訓練[10]。 3.3 軟件漏洞信息的數據融合 在軟件漏洞信息的處理中,可能存在錯誤、冗余信息和邏輯模糊等問題,這會影響軟件漏洞信息知識圖譜構建的準確性和可靠性。為解決以上問題,本文采用實體消歧技術,將具有歧義命名的實體映射到具體的概念,然后進行數據融合,過程如下: I=θ{(β+ε+η)λ}(5) 式(5)中,I表示融合后軟件漏洞數據,θ表示融合指標,β表示融合數據模式,ε表示融合工具,λ表示融合參量的權值,η表示現有的漏洞信息數據。這種融合方式可有效降低信息中的邏輯模糊和層次不匹配現象,并實現數據融合。通過概率統計和圖像排序方法,實現軟件漏洞信息實體鏈接的消歧與對齊,使漏洞信息更具體化,同時篩除冗余信息以提高準確度。該步驟能夠有效提高軟件漏洞信息知識圖譜構建的準確性和可靠性。 3.4 數據的存儲與知識圖譜的構建 為使海量化的軟件漏洞信息全面地、動態化地展示在同一圖譜中,本文應用Neo4j圖數據庫存儲軟件漏洞信息,結合可視化技術,完成基于文本挖掘技術的軟件漏洞信息知識圖譜的構建,過程如下: B=(1-y)×L×R(6) 式(6)中,B表示信息知識圖譜表示當量(CVE-2022-N),y表示數據挖掘方向,表示重疊度,L表示知識圖譜像元,R表示知識圖譜內存量。其中信息知識圖譜表示當量CVE-2022-N表示中國國家漏洞數據庫中的軟件漏洞信息及其編號。根據上述軟件漏洞信息的本體模型,并通過相關的處理操作,構成對應的軟件漏洞知識圖譜,充分地為后續相關的軟件漏洞安全管理工作奠定良好的數據基礎。 4 測試與分析 4.1 試驗準備 為檢測本文設計的基于文本挖掘的軟件漏洞信息知識圖譜構建方法的可行性與應用效果,結合其它方法,本文設計了仿真模擬對比試驗。試驗在JAVA語言編程環境下搭建,搭建參數如表1所示。 將中國國家漏洞數據庫中的軟件漏洞信息作為測試樣本數據,存儲在數字數據庫與圖像數據庫中。 4.2 漏洞信息知識圖譜的完整度檢測 記錄不同方法構建知識圖譜中收錄漏洞數量的大小,與實際有效漏洞數量進行對比分析,計算完整度,結果如圖2所示。 由圖2可知,對于隨機選取10組大小、漏洞種類均不同的數據組,試驗組方法融合并構建的知識圖譜軟件漏洞信息的完整度高于對照組1、對照組2。試驗組方法構建的知識圖譜信息完整度均值為93.6%,分別比對照組1、對照組2高28.4%、13.8%,有效提高了對軟件漏洞有效信息采集與存儲的覆蓋范圍。 4.4 漏洞信息處理效率檢測 記錄不同方法從采集漏洞信息到完成知識圖譜構建所用時間,對比結果如圖3所示。 由圖3可知,通過對10組隨機選取的不同大小和漏洞種類的數據組進行試驗組方法的數據處理,發現試驗組知識圖譜構建時間均低于對照組1和對照組2。試驗組方法平均構建時間為1.52 s,比對照組1和2分別快6.02 s和4.11 s。這說明本文設計的軟件漏洞信息知識圖譜構建方法具有高效和實時的特點,能夠準確而快速地完成漏洞信息的采集和預處理,為軟件工程項目的安全管理提供可靠的數據基礎和依據。 5 結語 隨著科學技術與互聯網技術的大范圍應用,相關的軟件漏洞也層出不窮,對用戶的信息安全與個人財產造成了較為嚴重影響。在此背景下,本文通過應用文本挖掘技術,充分結合現代化技術手段,構建完整、精準的軟件漏洞信息知識圖譜,為軟件工程安全管理與防御系統的智能化運行提供數據基礎。本文所提方法構建時間較短、信息完整度更強,可有效保證軟件工程項目運營過程中的安全性與可靠性,為我國網絡科技市場結構的長久穩定發展,奠定良好基礎。 參考文獻 [1]郭軍軍,王樂,王正源,等.軟件安全漏洞知識圖譜構建方法[J].計算機工程與設計,2022(8):2137-2145. [2]張瑞,王曉菲.基于混合深度學習模型的軟件漏洞檢測方法[J].電腦知識與技術,2021(18):72-73. [3]彭佳玲,周茂林,楊青.公眾對上門護理服務的態度和關注點:基于網絡爬蟲的文本挖掘[J].護理學雜志,2023(5):110-113,116. [4]周潔,夏換.基于文本挖掘的微博用戶健康信息關注熱點研究[J].新媒體研究,2023(2):102-106. [5]孫寶生,敖長林,王菁霞,等.基于網絡文本挖掘的生態旅游滿意度評價研究[J].運籌與管理,2022(12):165-172. [6]梁俊毅,陳靜.基于雙向LSTM的軟件漏洞自動識別方法研究[J].信息與電腦(理論版),2021(8):174-176. [7]蔡敏.基于混合深度學習模型的網絡服務軟件漏洞挖掘方法[J].寧夏師范學院學報,2020(7):73-79. [8]王曉輝,宋學坤.基于知識圖譜的網絡安全漏洞類型關聯分析系統設計[J].電子設計工程,2021(17):85-89. [9]劉存,李晉.安卓平臺軟件漏洞挖掘與分析技術淺析[J].保密科學技術,2020(2):33-38. [10]陶耀東,賈新桐,吳云坤.一種基于知識圖譜的工業互聯網安全漏洞研究方法[J].信息技術與網絡安全,2020(1):6-13,18. (編輯 李春燕) Construction method of knowledge graph of software vulnerability information based on text mining Xing? Jiuhong, Niu? Baomin (School of Big Data and Artificial Intelligence, Zhengzhou University of Science and Technology, Zhengzhou 450064, China) Abstract:? A method for constructing a knowledge graph of software vulnerability information based on text mining is proposed to address the vulnerability issues in current internet software. Firstly, the basic architecture for constructing a knowledge graph of software vulnerability information is determined, and text mining technology is applied to complete the collection, preprocessing, and feature extraction of software vulnerability information. Then, an ontology model is designed to complete the extraction and fusion of software vulnerability information. Finally, a storage mechanism is designed to construct a knowledge graph of software vulnerability information. The experimental results show that the average integrity of software vulnerability information in the constructed knowledge graph is 93.6%, and the average construction time is 1.52 seconds, both of which are superior to the comparison method and have good application value. Key words: text mining technology; Internet technology; software vulnerability information; construction of knowledge graph
猜你喜歡
建筑建材裝飾(2016年11期)2016-12-29 19:06:50
中國科技縱橫(2016年20期)2016-12-28 12:13:08
現代商貿工業(2016年28期)2016-12-27 09:37:49
科學與財富(2016年18期)2016-12-22 17:55:04
新聞界(2016年15期)2016-12-20 09:45:40
中國高新技術企業(2016年30期)2016-12-20 03:52:33
中小企業管理與科技·上旬刊(2016年11期)2016-11-28 20:33:09
科學與財富(2016年15期)2016-11-24 14:51:09
大經貿(2016年9期)2016-11-16 15:54:21
中國市場(2016年36期)2016-10-19 04:41:16
