基于云計算的異構數據集成模型構建
2023-08-21 09:57:42劉雪芳朱玲
無線互聯科技 2023年12期
劉雪芳 朱玲
摘要:異構數據的集成及處理一直是學者們探究的問題,近年來興起的基于云計算構建的異構數據集成模型,能夠獲得統一的數據處理方式與管理辦法,以供云計算環境下各業務應用,為異構數據統一查詢、檢索、業務應用處置的多元異構數據間的映射和關聯創造便捷條件。文章介紹了國內外云計算異構數據集成模型的構建基本情況,指出了云計算下異構數據集成模型的基本構成,并就現有的模型構建實現的技術展開了論述,以便為用戶提供優質的數據服務。
關鍵詞:異構數據;云計算;構建;集成模型
中圖分類號:TP311? 文獻標志碼:A
1 國內外云計算下異構數據集成模型的構建基本情況
現有國外云計算下的數據庫基本上都是由一些實力雄厚的公司單獨研發設計的,如database.com數據庫出自Salesforge公司之手。微軟以Windows Azure 云操作系統為基礎獨自研發設計了SQL Azure 數據庫,且可開始提供云計算環境下的關系數據庫服務。然而云數據庫出自各個公司,且大部分僅對該公司構建的數據庫體系使用,支持異構數據庫的表現不盡如人意,且缺少統一的規范標準。目前,我國研究此種數據庫才剛開始,還沒有建立成熟完善的理論體系。
大型云端應用注重的對象以存儲海量數據與數據高并發讀寫為主,并進一步優化數據模型與架構的結構,有效提升了可用性、并發性以及延展性等[1]。然而,這種系統大部分在管理數據方面的表現都比較差,僅有數據存儲功能。為使系統具有數據管理功能,系統開發者一般要在“裸”系統的基礎上進行研發設計,自底層著眼設計,從而賦予系統以若干定制的數據管理功能。但是,為了適應云計算的發展,此類數據管理型應用迎來了新挑戰,暴露出一些問題。基于云計算的運行數據管理型應用時,必須確保多數據中心與多數據源協作處理,在云計算下集成信息系統內數據結構的數據與數據庫類型。
所以,有必要建立云計算下的異構數據集成模型。在建立的過程中,必須充分考慮云環境的特征,為各種云存儲數據與主流數據庫的集成提供支持。一方面,用戶對數據庫有著高并發量訪問的需求,且有高效訪問并存儲數據的需求,而此模型恰巧可以滿足這些需求。另一方面,對于數據庫,用戶有數據庫事務一致性、實用價值高、可延展性強的需求,而此模型可以滿足這些需求。
2 云計算下異構數據集成模型的基本構成
2.1 數據結構與任務調度引擎
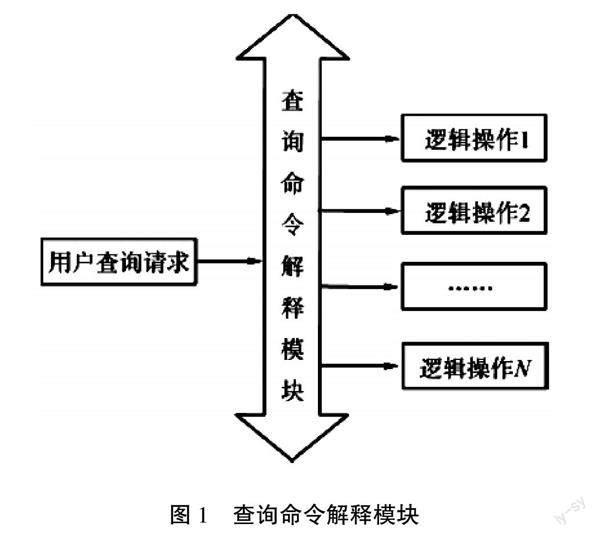
此層的任務是接收來自上層的和用戶查詢任務相對應的一系列邏輯操作,并以虛擬數據庫結構為參考,促使邏輯操作變成與之對應的任何集合,然后向異構數據集成接口傳輸子任務集合,如圖1所示。
進入異構數據集成接口層進行查詢,傳輸結果集,完成后對所獲得的數據予以歸納匯總與整合,緊接著向上層的云端數據查詢獲取分析接口層傳輸結果。這一層,數據獲取分析生成及管理技術發揮著最關鍵的作用。在實施數據查詢處理操作的過程中此層基本上會選用生成子任務集合的途徑,因此,在設計時此層內含的模塊有數據獲取分析用戶管理、數據獲取分析任務管理等,以對用戶數據獲取分析請求生成的數據獲取分析任務的運行以及狀態管理進行監管與控制。
當然,在此層還需用到分布式數據獲取分析執行引擎相關技術。通過使用該項技術,才能順利完成模塊分解的任務,結合所有數據系統與數據庫的具體特征,提高對下層的異構數據集成接口的利用率,結合所有數據系統與數據庫的實際特征執行與之對應的任務[2]。
2.2 云數據存儲和資源管理
在整個系統內部,此模塊居于基礎位置。云環境下,運用資源與數據管理技術可以賦予所有功能層以更多的選擇,從而更好地優化配置系統資源,做好數據管理以及存儲工作,并達到在云環境下存儲并查詢海量、高負載、高并發的數據的目的。
云計算下的元數據與服務管理技術是本層應用的一項關鍵技術,為了使用戶能夠更方便地進行數據管理與數據存儲,此技術必須能為所有數據源配置存儲架構。對于底層而言,各類存儲結構如傳統關系數據庫、分布式數據庫均對其適用,可以將統一的元數據提供給上層,為其進行服務管理等創造條件。
2.3 數據的獲取分析應用接口
此層主要作為云端數據獲取分析應用接口所用,將其作為統一的對外調用接口。在本模型中,為了符合數據查詢的相關要求,本模型可以為傳統關系數據庫、分布式數據庫以及NoSQL數據系統提供自定義的、統一的查詢語言。用戶可以對shell接口下定義,利用標準SQL將用戶數據傳輸進去,從而得到分析調用語句描述,分析并詮釋命令,再一次進行請求查詢,對下層的異構數據集成接口進行調用,然后將用戶所需的數據分析結果返回。此接口的設置為應用開發商將本公司的服務無縫遷移至云計算創造了便利條件[3]。
本層的核心技術為自定義數據獲取分析命令解釋模塊,該模塊支持在云計算環境下使用。該層可以統一地接收用戶發出的數據獲取分析語句的請求,對數據獲取分析語句進行解析,從而得到可與不同數據源相對應的邏輯操作,如圖1所示。
2.4 本體基礎下的異構數據集成接口
異構數據集成接口在云計算下異構數據集成模型內起到了十分關鍵的作用,是建立云計算下異構數據集成模型的關鍵要素,主要負責建立上層中的數據、對引擎任務實施調度,并呈現最終結果。在該接口內,異構數據語義映射集成技術發揮著十分重要的作用,在研發此技術的過程中,必須將相關工作做到位,促進局部環境語義向所有環境語義實現轉移。換言之,在不同的數據語義環境下,基于本體之上會完成數據語義相似、數據集成一致的映射,在分布式環境下提高對有關技術的利用率。此外,在異構數據集成接口內部有異構數據格式集成技術這項技術,該技術效果顯著,可以實現轉換數據系統類型與內容,如可以實現XML文件數據與關系數據之間的轉變以及映射。
3 模型實現的核心技術
3.1 數據獲取分析語句語義分析方法
通過應用此法,可以實現對系統內部應用的數據獲取分析與管理命令的處理,完成執行命令、解析命令等諸多操作。此模型基于云存儲訪問操作以及傳統的SQL語法創造了一種語言——CHDI-SQL,以用于在云計算下訪問并管理異構數據源,并對其進行執行與解析,從而讓使用人員能便捷、高效地描述獲取分析請求,得到所需數據。同時,可用此模型對CHDI-SQL 語言實施語義擴展接口的定義,便于其新增自定義語義描述。
3.2 云計算下異構多數據源并發控制及協同獲取分析方式
基于云計算環境獲得異構多數據源狀況時,因為位于任一節點的數據源或許僅僅涵蓋了需要的一些信息,在獲取并處理相關數據時無可避免地要進行并行計算、網絡通信、協同處理以及數據源異構性等,對進行數據獲取分析提出了難題。針對若干異構數據源,將其打造成虛擬數據庫,由其負責對特定的數據進行分析。
3.3 云計算下的異構數據集成方式
通過對傳統異構數據集成進行研究后發現,大部分均運用的是訪問者與DBS服務接口直接交互的方式,這難免會讓用戶在應用中處理數據集成以及數據訪問等一系列問題時要面臨更高的異構數據集成難度。通過應用云計算下的異構數據集成技術,可以做到智能化地處理異構數據集成問題。基于此,文章建立了聯合虛擬數據庫系統,所有虛擬節點的接口與實際的相同,在實際數據源節點上其主要工作包括:查詢執行原子操作任務的進度、分析并處理異構數據語義。而聯合虛擬數據庫系統不具備貯藏數據的功能,僅支持整合優化異構數據源。服務聯合模型支持調用虛擬DBS服務,并和組成聯合的所有DBS接口實現交互[4],使用圖中列出的結構進行異構數據集成。
3.3.1 聯邦虛擬數據庫
在具體應用中,結合系統負載的實際狀況在云內若干臺服務器上可自動部署該數據庫。此數據庫在與位于云端的異構數據集成接口連接的過程中主要依托的是異構數據結果集成接口,并對源于異構數據集成接口的統一語義、數據格式實施集成處理,優化整合云內所有的異構數據源,從而得到統一的聯邦虛擬數據庫。
3.3.2 異構數據集成接口
通常在進行設置時,設計人員會將該接口設置在云端,讓其以云端的異構數據為對象實施異構數據語義與格式的集成處理。異構數據格式集成可實現對表沖突與物理沖突的處理,物理沖突指因數據源存儲所產生的沖突;而表沖突指命名沖突、表結構沖突以及表關系沖突等,如在對異構數據格式進行集成處理的過程中,可以考慮選擇采取基于 XML 的數據格式解析中間件的方式重新對數據格式予以整理,從而妥善處理沖突問題[2]。異構語義集成可用于對數據語義沖突進行處理,語義沖突指在對同種現實世界事物進行描繪的過程中,在刻畫結構、方式以及內容里兩個對象產生的語義的不一致性。通過預處理、分析異構數據源將數據的統一性提取出來,得到建立局部本體的語義內容,能使數據集成過程中出現的物理沖突得到妥善的處理。語義沖突監測機制可以發現數據集成時產生的語義沖突,對表沖突進行處置,將異構清除、語義沖突解決,達到集成異構數據的目的。
3.4 云計算下大規模數據存儲與資源管理辦法
Hadoop可用于分布式處理許多數據,是當下被普遍使用的一種用于開發大規模數據存儲及資源管理的軟件框架。在進行分布式處理時,其采取的方式具有高效、可靠、可伸縮的特點。系統的核心框架為MapReduce、Hadoop 分布式文件系統(HDFS),后者為Nam-eNode/DataNode結構,其集群內部有1組DataNode節點、1個 Nam-eNode節點,是依靠NameNode節點對DataNode節點進行一致性地調度,對其發布刪除、創建、復制的命令,而DataNode節點主要承擔著處理所有節點內的數據等事務。
MapReduce的主要功能是對大數據集進行并行處理,在處理過程中,其先對系統內設置的總任務進行分割處理,然后得到大量子任務,任一子任務基于集群節點里均可實施并行處理操作。為了確保所有子任務節點安全、可靠、穩定,在創建數據塊副本時,HDFS往往會創建兩個以上。
云計算下大規模數據存儲與資源管理模塊可用于分布式處理許多數據;為了保證支持重新分布處理失敗的節點,每一層都得對若干個工作數據副本進行維護;可考慮選取可伸縮數據處理和存儲模式,如此便可以實現對PB級的數據的高速處理[3]。
4 結語
目前,在國內外的許多大型制造業領域云計算下異構數據集成模型已得到了大范圍的運用,且許多分公司均完成了信息化建設,同時建立了大量異構信息管理系統。在未創建并執行此模型的過程中,企業必須安排專人負責歸納匯總分公司的信息與數據,以給決策者作出準確決策提供借鑒,云計算下的異構數據集成模型大大提高了效率。執行此模型以后,分公司的所有數據均可以得到及時整理,便于企業制定準確決策,強化企業市場應對能力。
參考文獻
[1]周俊暉,趙聰浩,馮振儉,等.多源異構數據集成的實景三維數據模型[J].北京測繪,2022(5):563-570.
[2]王夢林,龔智煌,淵博,等.基于BIM的綠色建筑運維多源異構數據集成路徑研究[J].土木建筑工程信息技術,2022(4):68-73.
[3]李帥,郭妍彤,周文迪.基于Neo4j的數據空間多源異構數據集成管理研究[J].現代計算機,2021(12):36-42.
[4]溫浩宇,李京京.大數據時代的數字圖書館異構數據集成研究[J].情報雜志,2013(9):138-141.
(編輯 王雪芬)
Construction of heterogeneous data integration model based on cloud computing
Liu? Xuefang, Zhu? Ling
(Jingdezhen College, Jingdezhen 333000, China)
Abstract:? The integration and processing of heterogeneous data have always been a problem that scholars have explored. In recent years, the heterogeneous data integration model has been constructed under the basis of cloud computing. The following business applications create convenient conditions for the mapping and associations between the unified query, retrieval, and business application disposal of heterogeneous data. To this end, this article first introduces the basic situation of the construction of cloud computing heterogeneous data integrated models at home and abroad, and then specifically pointed out the basic composition of heterogeneous data integration models under cloud computing, and finally develops the technology of the existing model construction implementation. It is discussed to create high-quality services for users in terms of data.
Key words: heterogeneous data; cloud computing; construction; integrated model
猜你喜歡
現代經濟信息(2016年19期)2016-10-20 15:57:03
中國科技博覽(2016年19期)2016-10-19 12:39:29
電腦知識與技術(2016年21期)2016-10-18 23:34:52
電腦知識與技術(2016年21期)2016-10-18 23:24:44
電腦知識與技術(2016年21期)2016-10-18 22:11:15
科學與財富(2016年28期)2016-10-14 00:42:15
大學教育(2016年9期)2016-10-09 08:54:03
大學教育(2016年9期)2016-10-09 08:38:54
成才之路(2016年26期)2016-10-08 12:01:17
成才之路(2016年25期)2016-10-08 10:30:56
