基于特征圖融合的對抗樣本生成方法
2023-08-21 08:45:26張世輝張曉微宋丹丹路佳琪
燕山大學學報 2023年4期
張世輝,張曉微,宋丹丹,路佳琪
(1.燕山大學 信息科學與工程學院,河北 秦皇島 066004;2.燕山大學 河北省計算機虛擬技術與系統集成重點實驗室,河北 秦皇島 066004)
0 引言
目前,人工智能領域的安全問題廣受關注[1-2]。深度學習作為人工智能的一個重要分支,在圖像分類[3]、語音識別[4]、生物科學[5]和目標檢測[6]等領域具有廣泛應用。在深度學習帶來極大便利的同時,研究者發現深度學習模型極易受到對抗樣本的攻擊[7-8]。攻擊方通過對原始樣本進行人類視覺系統不易察覺的修改,從而生成可誘導深度學習模型誤分類的對抗樣本,使得深度學習在高安全性需求場景中的部署和應用面臨巨大挑戰。因此,關于對抗樣本生成問題的研究具有重要的現實意義和學術價值。
現有對抗樣本生成方法根據目標網絡信息的已知程度,可分為基于白盒的對抗樣本生成方法和基于黑盒的對抗樣本生成方法。其中,基于白盒的對抗樣本生成方法[9-12]已知目標網絡的結構和參數,該類方法主要通過求解目標網絡的梯度信息生成擾動,并將生成的擾動添加至原始輸入樣本進而生成對抗樣本。本文所提對抗樣本生成方法主要面向黑盒模型,因此下面側重于基于黑盒的對抗樣本生成方法的描述。
在實際應用場景中,攻擊方除目標網絡的輸入輸出結果外通常無法獲得其他信息,故基于黑盒的對抗樣本生成方法可代表更一般的應用場景。2018 年,Dong 等人[13]將動量項整合至迭代攻擊中, 提出 MI-FGSM (Momentum Iterative Fast Gradient Sign Method)方法,通過在迭代過程中累積損失函數的梯度,以穩定優化過程并避免不良的局部最大值,從而生成具有可遷移性的對抗樣本。2019 年,Xie 等人[14]將輸入多樣性策略整合至迭代攻擊中,提出DI2-FGSM(Diverse Inputs Iterative Fast Gradient Sign Method)方法,通過對輸入圖像進行隨機裁剪和隨機填充的變換來增加生成對抗樣本的可遷移性。MI-FGSM 和DI2-FGSM方法均基于FGSM 方法進行相應改進,從而適應黑盒模型的攻擊環境。2019 年,Carlini 等人[15]為了有效評估對抗樣本性能,提出一種難度更大的非交互式黑盒(Non-interactive blackBox,NoBox)模型,NoBox 模型作為黑盒模型的延伸,攻擊方在對抗樣本的生成過程中無法訪問目標網絡的任何信息,包括輸入信息與輸出信息,即無法與目標網絡進行任何交互訪問。在基于NoBox 模型的攻擊環境下,攻擊方僅可依靠對抗樣本的可遷移性來達到攻擊目標網絡的目的。2020 年,Wu 等人[16]基于類ResNet 網絡的跳躍連接操作提出SGM(Skip Gradient Method)對抗樣本生成方法,跳躍連接有助于保留更多的淺層特征信息,使得生成的對抗樣本可有效遷移至其他分類器。該方法雖然可以在一定程度上提高對抗樣本的可遷移性,但遷移后的對抗樣本在NoBox 攻擊環境下的攻擊成功率顯著降低。同年, Avishek 等人[17]提出 AEG(Adversarial Example Games)方法,通過生成器與假設分類器之間的對抗性訓練生成可遷移性對抗樣本。由于對抗性訓練需要有效的約束條件使得博弈雙方達到理想的納什均衡狀態,因此AEG 方法在NoBox 攻擊環境下所構造的對抗樣本圖像可視化結果較差。2021 年,Philipp 等人[18]提出BNMI-FGSM(Batch Normalization Momentum Iterative Fast Gradient Sign Method)方法,通過利用BN 層使卷積神經網絡更傾向于學習非魯棒特征的特點生成具有可遷移性的對抗樣本。雖然該方法生成的對抗樣本具有較好的可遷移性,但在NoBox 攻擊環境下對抗樣本對于不同目標網絡的攻擊成功率波動幅度較大,穩定性較差。
結合上述關于現有代表性方法的分析,在不與目標網絡產生任何交互信息的前提下,本文通過構建基礎網絡獲取原始輸入樣本的顯著特征信息,并基于顯著特征信息完成對抗樣本生成任務。本文方法主要貢獻如下:
1) 提出利用多層次特征圖進行對抗擾動構造的思想。依據卷積神經網絡分類過程中所提取的不同層次特征圖,選取對圖像分類結果影響較大的部分特征圖進行擾動修改,上采樣至相同尺寸后進行融合操作,得到用于對抗樣本生成的對抗擾動。
2) 提出一種基于特征圖融合的對抗樣本生成方法。基于利用多層次特征圖進行對抗擾動構造的思想,構建基礎網絡用于提取原始輸入樣本的多層次特征圖及其權重向量,依據權重向量進行特征圖選取,并設計擾動修改方法對所選特征圖進行像素級的擾動修改操作,將獲取的對抗擾動疊加至原始輸入樣本生成誤導目標網絡分類的對抗樣本。
3) 與現有代表性方法不同的是,本文方法中的基礎網絡可由任意卷積神經網絡嵌入通道注意力模塊實現,顯著提高了方法的普適性,且對抗樣本生成過程重點關注原始輸入樣本的特征信息,使得生成的對抗樣本具有良好的可遷移性,同時本文方法不需要目標網絡的任何信息,即本方法可完全適應NoBox 攻擊環境。
1 方法概述
本文所提基于特征圖融合的對抗樣本生成方法總體思路如下。首先,基于卷積神經網絡嵌入注意力模塊,構建并訓練基礎網絡;其次,根據基礎網絡中的卷積層與注意力模塊分別獲取原始輸入樣本的不同特征圖及相應的權重向量;再次,根據擾動特征圖獲取方法依次進行特征圖選取和擾動修改操作;最后,將多張擾動特征圖融合為對抗擾動,并逐像素疊加至原始輸入樣本以生成對抗樣本。所提對抗樣本生成方法的總體流程如圖1所示。

圖1 對抗樣本生成方法的總體流程Fig.1 The overall process of the adversarial example generation method
2 基于特征圖融合的對抗樣本生成方法
2.1 問題定義
設(x,y)是符合自然圖像數據分布Pnature的數據集(X,Y)中的一組數據樣本,其中x∈X為原始輸入樣本,y∈Y為對應的數據類別標簽。對抗樣本x?通過對原始輸入樣本x進行像素級的擾動修改,來誘導目標網絡ftarget:X→Y誤分類。給定原始數據集合(X,Y)~Pnature,在目標網絡ftarget的任何信息均未知的情景下(NoBox 攻擊環境),采用有效的對抗樣本生成方法,使得目標網絡誤分類對抗樣本,即ftarget(x?)≠ftarget(x)。
2.2 特征圖擾動修改思想
隨著深度學習的發展,計算機可以快速準確地識別圖像中所包含的目標信息。現有基于深度學習的圖像分類方法中,主要采用多層卷積操作提取輸入圖像的特征信息,這些特征信息直接影響目標類別的分類結果,且在此過程中會生成一系列包含不同信息的特征圖。其中,淺層卷積操作生成的特征圖更多包含紋理與細節特征等信息,而深層卷積操作生成的特征圖更多包含輪廓、形狀、最強特征等影響人類視覺系統感知的全局信息。
針對圖像分類任務,對抗樣本通過向原始輸入樣本中添加精心設計的像素級擾動,達到誘導卷積神經網絡誤分類的目標。結合上述關于卷積操作生成特征圖的特點,本文提出對多層次特征圖進行擾動修改,并用于構造對抗擾動的思想。在具有n個卷積層的卷積神經網絡中,對多層次特征圖進行擾動修改來構造對抗擾動的總體思路如圖2 所示。

圖2 基于卷積神經網絡的多層次特征圖擾動修改示意圖Fig.2 Sketch map of multi-level feature map perturbation modification based on convolutional neural networks
由于不同卷積神經網絡的下采樣層大小、數量及位置均不相同,因此圖2 中并未考慮下采樣層。考慮篇幅限制,圖2 對所選取的特征圖進行等比例縮放。由圖2 可知,為保證生成對抗樣本與原始輸入樣本在人類視覺系統感知上的相似程度,本文選取對圖像分類結果影響較大的部分特征圖執行擾動修改操作。由于卷積神經網絡在提取圖像特征信息的過程中,每個卷積層產生的特征圖尺寸(通道數×高×寬)并不相同,且淺層特征圖的尺寸大于深層特征圖,因此需要對選取的部分特征圖進行上采樣操作,以便后續特征圖融合操作的執行。
2.3 基礎網絡的構建
由上述關于特征圖擾動修改思想的闡述可知,在對特征圖執行擾動修改和融合操作之前,需要提取輸入圖像的不同層次特征圖,且卷積神經網絡可以根據所提取的特征圖對輸入圖像正確分類。由于不同卷積神經網絡的卷積層和下采樣層的數量并不相同,因此對于輸入圖像的特征圖提取也會因網絡結構的不同而存在差異。在圖像分類任務中,常用的卷積神經網絡包括VGGNet[19]、GoogLeNet[20]、ResNet[21]和 AlexNet[22]等, 其中ResNet 有效解決了網絡性能隨網絡層數增加而退化的問題,使其在圖像分類任務中得到廣泛應用。為了體現所提對抗樣本生成方法的普適性,也為了便于與現有代表性方法進行實驗對比,因此本文選取ResNet 用于構建基礎網絡。
為了實現生成對抗樣本的擾動不可感知效果,本文在ResNet 的各個卷積層之后嵌入通道注意力模塊,從而構造用于提取多層次特征圖及其權重向量的基礎網絡。其中,通道注意力模塊對卷積層生成的多層次特征圖進行權重分配操作,而高權重特征圖包含更多影響卷積神經網絡分類的特征信息,從而僅對高權重特征圖進行擾動修改。綜上所述,本文所設計的基礎網絡如圖3所示。

圖3 基礎網絡Fig.3 Basic network
由圖3 可知,基礎網絡由ResNet 嵌入通道注意力模塊得到。通道注意力模塊可以對卷積層所生成的多層特征圖執行權重分配操作,且后續卷積層會對加權后的多層特征圖執行卷積操作。在實際訓練過程中,通道注意力模塊可以有效地提升ResNet 對于原始輸入樣本的分類準確率。同時,通道注意力模塊的加入不需要額外的損失函數對其進行指導訓練,即基礎網絡的訓練過程為
其中,θ為基礎網絡f的參數,為參數最優值。
2.4 擾動特征圖的獲取
對基礎網絡中各卷積層所提取的特征圖依次執行特征圖選取操作和特征圖擾動修改操作,即可得到用于構造對抗擾動的擾動特征圖。
2.4.1 特征圖選取
現有對抗樣本生成方法多數需要對原始輸入樣本的所有特征圖進行擾動添加操作,造成對抗樣本生成時間過長。根據對抗擾動的可視化圖像可知,對抗擾動的添加區域集中在圖像的顯著特征區域,即人類視覺關注的重要局部區域。鑒于通道注意力模塊可以突出圖像中的顯著信息,且對于無用信息能夠起到一定的抑制作用,因此所提對抗樣本生成方法依據基礎網絡中所嵌入的通道注意力模塊選取對分類結果影響較大的部分特征圖,避免對全體特征圖進行擾動修改操作。同時通道注意力模塊的引入可限制擾動修改區域,有效減少擾動修改量,有利于生成具有良好視覺感知效果的對抗樣本。
本文通過基礎網絡的卷積層和通道注意力模塊分別獲取原始輸入樣本的各層特征圖及相應的權重向量,具體操作流程如圖4 所示。其中,特征圖和權重向量用于特征圖擾動修改操作,加權特征圖則用于基礎網絡的后續卷積操作。

圖4 獲取特征圖及權重向量的操作流程Fig.4 Operation process of obtaining feature maps and weight vectors
由圖4 可知,特征圖可以直接通過卷積層獲取,而權重向量需要執行兩個計算操作得到。首先使用全局平均池化操作得到每張特征圖的全局信息,計算公式為
其中,c=1,2,…,C,Zc代表第c張特征圖的全局信息,H、W和C分別為通道注意力模塊輸入特征圖的高度、寬度和通道數,Fc(h,w)為第c張特征圖中坐標為(h,w)的像素點值。
然后,將式(2)所獲取的不同層次的全局信息值整合為全局信息向量Z=[Z1,Z2,…,ZC],并通過相應操作得到輸入特征圖的權重向量,具體計算公式為
其中,S∈RC×1×1為經過通道注意力模塊計算所得輸入特征圖的權重向量,σ(·) 為Sigmoid 函數,δ(·) 為ReLU 函數,和分別表示兩層全連接層的權重系數,t為降維系數。
得到各卷積層生成特征圖的權重向量S后,利用排序算法對權重向量中各值進行排序,使用其中權重較高的特征圖作為待擾動特征圖。選取待擾動特征圖的計算公式為
其中,M為待擾動特征圖,IS為權重向量S排序后所返回的特征圖索引序列,F為卷積層所生成的特征圖,TOP 函數依據索引序列IS中前k位的索引值,選取卷積層生成特征圖F中相同索引位置的特征圖,即權重值最高的k張特征圖。
對于基礎網絡中各卷積層生成的特征圖均執行上述選取操作,即可得到不同尺寸的待擾動特征圖。
2.4.2 特征圖擾動修改
卷積神經網絡通過卷積層提取原始輸入樣本中的特征信息用于類別分類,而具有較高權重的特征圖可以代表更為重要的特征信息。因此,對已選特征圖進行擾動修改可以有效模糊卷積神經網絡分類所需的特征信息,從而誘導卷積神經網絡誤分類。為生成高質量對抗樣本,本文設計了一種特征圖擾動修改方法,旨在通過較小的擾動修改改變特征圖所包含的重要特征信息。
鑒于特征圖高亮區域包含顯著特征信息,該區域所對應的像素點值也相應較大,故本文方法通過修改特征圖中較大像素點值來模糊特征圖中所包含的特征信息。具體地,以單張特征圖為例,通過對待擾動特征圖中各像素點值進行排序操作,并返回對應的像素點索引序列,依據索引序列對前l個較大像素點值進行擾動修改,達到對單張特征圖擾動修改的目的。
單張特征圖Mi中像素點索引序列的計算公式為
其中,i=1,2,…,k。
通過像素點索引序列在單張特征圖Mi中定位到前l個最大值像素點位置,進一步對其執行擾動修改操作。為有效模糊特征圖中所包含的特征信息,本文方法將擾動區域內的像素點值均置為相反數,且對于特征圖中非擾動區域內的像素點值均置為0,即原始輸入圖像中的非感興趣區域不作擾動修改。所有待擾動特征圖執行上述擾動修改操作,即可得到相應的僅保留感興趣區域信息的擾動特征圖。
2.5 對抗樣本的生成
由于基礎網絡中具有不同程度的下采樣操作,所提取特征圖的尺寸也均不相同,因此需要對擾動特征圖進行相應的上采樣操作至相同尺寸,并進一步通過融合操作得到最終用于生成對抗樣本的對抗擾動r。
為保證對抗樣本與原始輸入樣本之間的視覺感知效果,本文方法引入縮放因子ε∈ [0,1]用于限制對抗擾動添加量。最終,將對抗擾動r逐像素疊加至原始輸入樣本x中,即可得到高遷移性的對抗樣本x?,用于攻擊未知的目標網絡ftarget,如式
3 實驗結果及分析
3.1 實驗基本設置
3.1.1 實驗環境及數據集
實驗硬件環境為Intel Xeon Gold-5118@2.30 GHz (CPU)、NVIDIA RTX 2080 Ti (GPU);軟件環境為Ubuntu 14.04.5 LTS、CUDA 10.0、Python 3.8.0 和PyTorch 1.6.0。
不失一般性,本文使用對抗樣本生成領域常用的CIFAR-10[23]和MNIST[24]作為實驗數據集。其中,CIFAR-10 為彩色圖像數據集,包含飛機、汽車、鳥、貓等10 類生活中常見的60 000 張32×32的彩色圖像,其中訓練樣本50 000 張,測試樣本10 000 張。MNIST 為手寫數字數據集,包含10 類共70 000 張28×28 的手寫數字圖像,其中訓練樣本60 000 張,測試樣本100 00 張。
3.1.2 評價指標
為驗證所提對抗樣本生成方法的有效性,本文采用攻擊成功率(Attack Success Rate,ASR)評估對抗樣本生成方法對于目標網絡的誤導能力,采用L2范數評估對抗樣本的圖像質量。為評估對抗樣本生成方法在不同目標網絡中攻擊成功率的穩定程度,引入方差s2作為評價指標。所述三項評價指標具體定義為
其中,N為待分類的數據樣本總量,nadv為成功誤導目標網絡的對抗樣本總量,Z為目標網絡數量,ASRi為對抗樣本生成方法在第i個目標網絡中的攻擊成功率,為對抗樣本生成方法對不同目標網絡的攻擊成功率的平均值。
3.2 關于方法參數的選取實驗
為了驗證方法參數對各性能指標的影響,本節對方法參數的不同取值進行實驗及分析,從而獲取有效的參數設置。其中方法參數包括特征圖選取個數k、像素點修改個數l和縮放因子ε。
對于參數k的實驗過程為:隨機選取基礎網絡中的某一卷積層,利用所嵌入的通道注意力模塊輸出多張特征圖的權重向量,并計算權重最大的前k張特征圖的權重占比總和。實驗結果如圖5 所示。

圖5 關于特征圖選取個數k 的實驗結果Fig.5 Experimental results on the number k of selected feature maps
由圖5 可知,隨著特征圖選取個數k的不斷增加,所選特征圖的權重占比總和也隨之增加。當特征圖選取為3 張(k=3)時,其權重占比總和即可達到97%以上。然而,當特征圖選取大于3張(k≥4)時,權重占比總和趨于平穩,并未出現較大幅度增長。該實驗結果說明卷積層所提取的多張特征圖中僅3 張權重占比最大的特征圖即可代表多數特征信息,故在本文后續的實驗過程中,特征圖選取個數k設置為3。
對于參數l和ε的實驗過程為:基于上述有關參數k的實驗過程及結果分析,隨機改變所選取的3 張特征圖的l個像素點值,將融合后所得對抗擾動乘以縮放因子ε添加至原始輸入樣本并計算相應的攻擊成功率ASR和L2范數。參數l和ε關于攻擊成功率的實驗結果如圖6 所示,其中圖6(a)和圖6(b)分別為基于CIFAR-10 和MNIST 數據集所得攻擊成功率的實驗結果。

圖6 像素點修改個數l 和縮放因子ε 關于攻擊成功率的實驗結果Fig.6 Experimental results on ASR by modifying the number of pixel points l and the scaling factor ε
由圖6 可知,像素點修改個數l和縮放因子ε的變化均影響對抗樣本的攻擊成功率。綜合分析圖6 可知,當像素點修改個數l=4 和縮放因子ε=0.2 時,本文方法在CIFAR-10 和MNIST 數據集上的攻擊成功率均取得最優值。鑒于此,本文將像素點修改個數l和縮放因子ε分別初步設定為4和0.2。
為評估參數l和ε的取值對樣本可視化效果的影響,本文采用L2范數指標作進一步實驗驗證。圖7 給出參數l和ε關于L2范數的實驗結果,該結果亦可說明在不同的l和ε下所生成對抗樣本的圖像質量。由圖7 可知,隨著參數l和ε的不斷增大,相應的L2范數逐漸升高,即對抗樣本圖像質量逐漸降低。由于對抗樣本的生成過程中需同時兼顧對抗樣本的攻擊成功率和視覺感知效果,故所選定的像素點修改個數和縮放因子在保證攻擊成功率較高的同時應使L2范數相對較小。分析圖7 可以發現,在初步選定的l和ε參數下所得到的L2范數較小,即在保證較高攻擊成功率下能兼顧對抗樣本的視覺感知效果,故在后續實驗中,最終將像素點修改個數l設置為4,縮放因子ε設置為0.2。

圖7 像素點修改個數l 和縮放因子ε 關于L2 范數的實驗結果Fig.7 Experimental results on the L2 norm by modifying the number of pixel points l and the scaling factor ε
基于上述選定的參數,本文方法生成的對抗樣本可視化結果如圖8 所示。觀察圖8 可知,對于兩種不同的數據集,使用該方法生成的對抗樣本均較少地改變了圖像顯著特征信息,原始樣本中具體的語義信息得以保留,目標細節信息清晰,視覺感知良好。

圖8 對抗樣本可視化結果Fig.8 The visualization results of the adversarial examples
3.3 特征圖選取層數對比實驗
為進一步驗證所提方法采用多層次特征圖用于對抗樣本生成的優越性,本節分別采用深層特征圖和多層次特征圖執行對抗樣本生成過程,并進行實驗結果比較及分析。其中深層特征圖為基礎網絡后六層卷積層所提取的特征圖,且兩組實驗的其余條件均一致。具體實驗結果如表1。
分析表1 可知,深層特征圖僅包含全局信息,如輪廓、形狀、最強特征等,由于缺少細節信息的輔助,使得僅依據深層特征圖所構造對抗樣本的攻擊效果較差,而在信息量較少的簡單數據集(MNIST)中,細節信息對于整張對抗樣本的影響則更加顯著。基于此,本文方法采用多層次特征圖用于對抗樣本生成,旨在最大程度地減少對抗樣本中全局信息和細節信息的丟失,使得對抗樣本在近似原始樣本的視覺感知效果時,達到較高的攻擊成功率。由表1 可知,所示實驗結果驗證了多層次特征圖相比深層特征圖用于對抗樣本生成的優越性。
3.4 不同對抗樣本生成方法的比較實驗
為了評估本文方法的有效性和先進性,本節將本文方法與現有代表性的MI-FGSM[13]、DI2-FGSM[14]、SGM[16]、AEG[17]和BN-MI-FGSM[18]方法在NoBox 攻擊環境下針對不同目標網絡進行實驗結果比較及分析。其中,目標網絡分別為VGG-16[19]、Wide ResNet(WR)[25]、DenseNet-121(DN-121)[26]和Inception-V3(Inc-V3)[27]。為便于多種方法的實驗結果對比,已知網絡結構設置為圖像分類任務中常用的ResNet-18[20]。對抗樣本生成方法可獲取ResNet-18 網絡信息,而目標網絡的任何信息均未知。考慮篇幅限制,本節實驗數據集采用相對復雜的CIFAR-10 彩色數據集,實驗所得結論在MNIST 數據集中同樣適用。具體實驗結果如表2 所示,其中加粗字體為最優值,加下劃線字體為次優值。

表2 不同對抗樣本生成方法針對不同目標網絡的攻擊成功率比較結果Tab.2 Comparison results on ASR of different adversarial example generation methods against different target networks%
由表2 可知,相比于MI-FGSM、DI2-FGSM 和SGM,本文方法所生成的對抗樣本在不同目標網絡中均達到了較高的攻擊成功率。MI-FGSM 和DI2-FGSM 均屬于FGSM 方法的變體形式,分別通過動量整合和隨機變換操作來適應黑盒攻擊環境,雖然可以提高對抗樣本的可遷移性,但面對更加復雜的NoBox 攻擊環境,并未取得較好的攻擊效果。SGM 方法依據黑盒模型訓練替代模型,從而完成關于黑盒模型的對抗樣本攻擊。但在NoBox 攻擊環境下,替代模型的訓練過程不允許訪問目標網絡的任何信息,導致SGM 方法生成的對抗樣本對于目標網絡的攻擊效果較差。與上述方法不同的是,本文方法關注卷積神經網絡在圖像分類任務中所依據的特征信息,通過對特征信息進行有效修改來生成具有可遷移性的對抗樣本,使得對抗樣本在任何卷積神經網絡中均可達到穩定的攻擊成功率。
與AEG 和BN-MI-FGSM 方法相比,本文方法在Inc-V3 網絡上達到了最優值,在VGG-16、WR和DN-121 網絡上達到了次優值。從方法原理上講,AEG 方法通過對抗性訓練構造生成器模型,并使用有效約束條件生成具有可遷移性的對抗樣本,但該方法的穩定性不好,從而導致對于不同目標網絡無法實現穩定的攻擊效果,且原始輸入樣本過于復雜時,AEG 方法會陷入鞍點優化問題,使得攻擊成功率下降。BN-MI-FGSM 方法生成的對抗樣本雖然在WR 網絡中的攻擊成功率略高于本文方法,但該方法需要對原始輸入樣本整體區域進行擾動修改,而本文方法僅對顯著區域添加擾動,且在其余目標網絡中的攻擊成功率均高于BNMI-FGSM 方法。總體而言,同已有方法相比,本文方法所生成的對抗樣本在保持較高攻擊成功率的同時,由于重點關注卷積神經網絡分類所依據的顯著特征信息,使得擾動修改區域可威脅到任意卷積神經網絡,因此對抗樣本具有擾動信息量少、擾動不可感知、攻擊穩定性及樣本遷移性俱佳等顯著優點,故在綜合考慮方法性能、健壯性及實用性等多種因素的條件下,本文方法不失為一種具有競爭力的方法。
為了進一步展示不同方法的穩定性,圖9 將表2 中不同對抗樣本生成方法在不同目標網絡中的攻擊成功率的方差進行了可視化展示。該展示結果反映了不同對抗樣本生成方法攻擊成功率的波動幅度,亦即反映了不同對抗樣本生成方法的穩定性。由圖9 可知,與現有代表性方法相比,本文方法所生成的對抗樣本在不同卷積神經網絡中均可獲得穩定的攻擊成功率,特別是與近兩年攻擊性能較好的AEG 和BN-MI-FGSM 方法相比,本文方法的穩定性具有明顯的優勢,從而進一步驗證了本文方法在取得較高攻擊成功率的同時具有較好的穩定性和可遷移性。
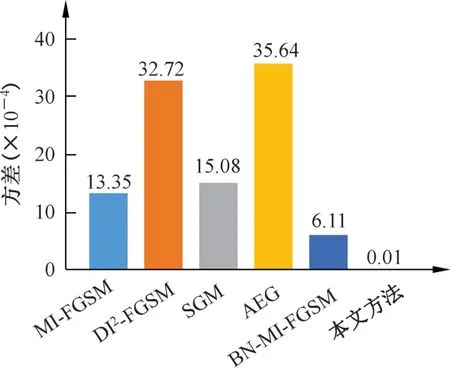
圖9 不同對抗樣本生成方法對不同目標網絡的攻擊成功率的方差結果Fig.9 Results of ASR′s variance on different adversarial example generation methods against different target networks
4 結論
本文提出一種基于特征圖融合的對抗樣本生成方法。該方法從原始輸入樣本的特征信息出發,通過引入通道注意力模塊并構建基礎網絡,依次提取、選取和修改包含不同特征信息的特征圖,最終融合不同尺寸的特征圖生成對抗樣本。該方法重點關注用于圖像分類的特征信息,不與目標網絡產生任何交互信息。基于CIFAR-10 和MNIST 數據集的實驗結果表明,本文方法所生成的對抗樣本可兼顧攻擊成功率與視覺感知效果。與現有代表性對抗樣本生成方法相比,本文方法所生成的對抗樣本可遷移性高,在不同卷積神經網絡中可穩定達到90%以上的攻擊成功率。
猜你喜歡
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
中華手工(2017年2期)2017-06-06 23:00:31
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
中外會展(2014年4期)2014-11-27 07:46:46
河南科技(2014年23期)2014-02-27 14:19:15
祝您健康(1987年3期)1987-12-30 09:52:32
