基于二維概率網格的語義地圖構建
2023-10-17 08:46:56張棟翔鄧一民李天然
汽車工程師 2023年10期
關鍵詞:語義
張棟翔 鄧一民 李天然
(上海汽車集團股份有限公司,上海 200041)
1 前言
近年來,隨著語義分割、目標檢測等領域的快速發展,語義地圖因其穩定、可靠且占用內存空間小等優勢,在智能導航中受到廣泛關注。
通過視覺語義構建地圖的方法可以分為2 類:點云語義地圖構建與概率語義地圖構建。秦通等[1]基于點云配準(Iterative Closest Point,ICP)算法構建停車場的庫位語義地圖,由于點云密集易混淆,而未提取斑馬線。胡佳欣[2]采用航位推算和基于ICP算法的語義點云匹配方法,在鳥瞰視覺(Bird’s Eye View,BEV)頂視圖上采用ORB 特征點(Oriented FAST and Rotated BRIEF Features,ORB Features)進行回環檢測和全局優化,但該方法為構建清晰的斑馬線地圖,需要載體的行駛路徑形成回環,且使用特征點作為輔助手段,增加了系統的復雜性。Zaganidis 等[3]采用正態分布變換(Normal Distance Transform,NDT)方法驗證了語義點云建圖的魯棒性和準確性,利用不同類別點云的法向量構成的NDT直方圖估計局部地圖之間的相似性,并在此基礎上添加語義回環檢測,但該研究對象為立體相機捕獲的點云。
Yang 等[4]融合語義立體框與特征點,提出立方體 建 圖(Cube Simultaneous Localization and Mapping,CubeSLAM)方法,結合圖像的模式識別技術,通過單目視覺提取物體的三維立體框。該方法可有效降低視覺漂移,提高相機位姿估計的精度,同時證明了語義識別和基于特征點的同步定位與地圖構建(Simultaneous Localization And Mapping,SLAM)技術可相互促進,目標識別可提供更大范圍的幾何和尺度約束,SLAM 技術能夠進一步提升目標識別的精度。Bowman 等[5]對識別結果使用期望最大化(Expectation Maximization)進行數據關聯,進一步優化了機器人及地標的位姿。與CubeSLAM 類似,該方法在采用最大似然估計推導出的最小二乘優化中增加約束,從而提高建圖精度。受Bowman的啟發,Doherty[6]認為數據關聯在概率上呈現非高斯分布,提出使用最大混合類(Max-Mixture-Type)模型,將多個可能性數據關聯進行先驗性建模。在推理過程中,用最大邊緣化法(Max-Marginalization)去除數據關聯中的變量,同時保持標準的服從高斯分布的后驗假設,最終完成基于非高斯概率分布的語義地圖的構建。Bowman和Doherty等人的方法主要針對特征點與目標語義框的數據關聯,并未闡述圖像分割的語義點云匹配問題。
構建語義地圖時,圖像分割引起的語義誤識別、邊界像素分割不佳等問題,將導致無法正確進行語義匹配。因此,本文提出二維概率網格語義法,針對圖像分割得到的語義點云,構建概率語義地圖,對語義觀測的時間先后順序和空間連續性進行建模,無需借助特征點(如ORB Features),不保留短時間內的語義感知錯誤,從而濾除噪聲,構建穩定、清晰的地圖。
2 系統概述
在智能駕駛的應用場景中,通過地平面上的車道線、斑馬線、箭頭、停止線等靜態地標構建語義地圖。本文以上述交通標志為背景,闡述概率網格語義匹配策略。
2.1 框架
如圖1所示,智能車輛可安裝多個相機,能夠在360°范圍內覆蓋車輛周邊視野。慣性測量單元(Intertial Measurement Unit,IMU)、GPS、輪速和轉向盤角度等傳感器信息為視覺語義信息提供先驗位姿。語義信息網格化后,基于先驗位姿對語義信息進行匹配,并將匹配結果轉換為概率化網格。根據匹配過程中的約束,對地圖進行最小二乘優化。其優化和匹配的結果反饋到多源信號的融合端,從而對先驗信息進行糾正。最后,將大于給定概率閾值的網格設為地標物體占據的網格,輸出語義地圖。
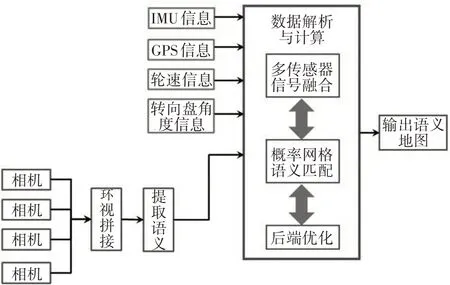
圖1 智能車輛語義地圖構建框架
2.2 環視標定拼接
使用智能車輛的多個單目相機采集圖像,結合相機外參標定和圖像拼接技術,將載體周邊空間的物體的體素投影到與地面平行的平面,空間維度由三維降低到二維,物體的尺度在水平方向上保持不變。通過時序同步將采集的圖像實時拼接成覆蓋車輛周圍360°范圍的頂視圖。而對于位于載體行駛軌跡一定空間范圍內的物體,在一段時間內,智能載體對其覆蓋的平面進行多次觀測,將平面的各點映射到頂視圖像。
2.3 語義像素的分割提取
從2.2節的頂視圖中提取所有組成車道線、斑馬線、箭頭、停止線以及可通行空間邊緣線等語義的像素。上述語義信息大多屬于靜態的背景,對光照變化不敏感,不受天氣變化影響,因而可鑒別性強。典型的車輛周邊不同類別的語義信息如圖2所示。
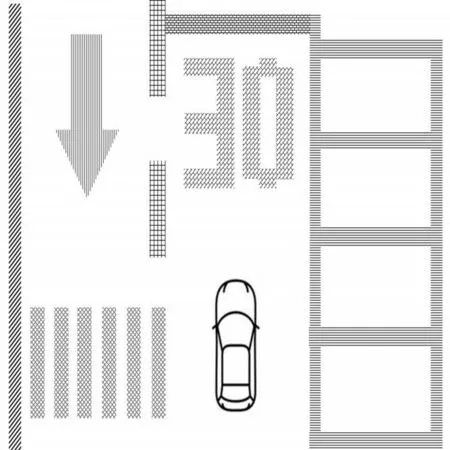
圖2 頂視圖的語義類別
2.4 網格語義預處理
對車輛周邊的語義空間進行二維網格化預處理,如圖3 所示,車輛周邊以分辨率λ進行網格化。對含有語義信息的網格標記為“1”,沒有語義信息的網格標記為“0”,同時對不同類別的語義進行標記。
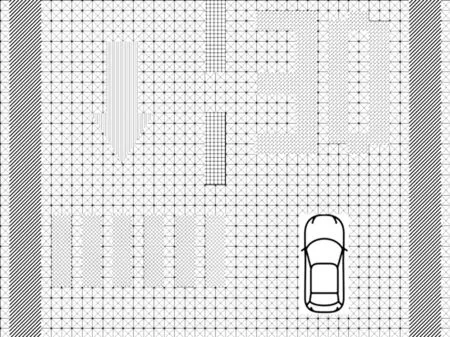
圖3 語義網格化
2.5 多源信息融合的位姿估計
將多傳感器信號進行時間戳對齊,利用卡爾曼濾波或因子圖(Georgia Tech Smoothing and Mapping,GTSAM)融合車載慣導、輪速計、轉向盤角度等信息,為車輛的位姿估計提供初始值χa=(Pa,θa),其中,Pa為車輛的位置坐標,θa為車輛的姿態朝向。
2.6 概率網格語義匹配
對語義網格進行概率化處理,采用最大化后驗概率的方法進行匹配。圖4所示為車輛頂視圖轉換的網格,通過概率網格語義匹配構建概率網格語義地圖。其中,交通標志的網格概率大于背景網格。具體步驟如下:
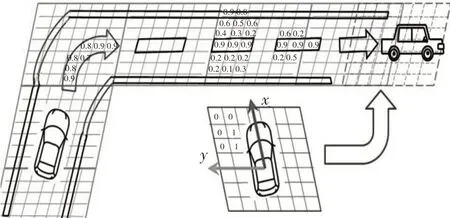
圖4 網格匹配過程
a.定義地圖上某位置的網格(網格A)有語義(Hit,標記為“1”)的概率為α,無語義(Miss,標記為“0”)的概率為(1-α),并對網格A 的概率P進行初始化:
隨著車輛移動,相機對網格A 在不同時刻進行觀測,同時對網格A的概率進行更新:
式中,Pt為t時刻網格A 的概率;z=1、z=0 分別表示觀測結果為有語義、無語義;Chit、Cmiss分別為觀測結果為有語義和無語義時傳感器的更新系數,由傳感器的屬性決定;f-1()為式(1)的反函數。
那進獻釣竿的部下難免有些不悅,但還是強打精神討好說:“下端重才穩得住,用起來更順手。”說著就將握把那一截擰下,使勁在地面方磚上敲打,篤篤有聲,這還不算,他還高高舉起那一截,朝地上摔去。一聲脆響之后,那一小截釣竿完好無損。
b.考慮到角度對語義匹配結果的影響,以2.5節的初始位姿朝向θa為中心,在窗口(-τ,+τ)內,以δ為角度間隔,在已有地圖上對當前幀進行匹配,并在窗口內找到使式(3)最大的值,即當前車輛的朝向估計值θb,保持朝向不變,以2.5 節的初始移動車輛位置Pa為中心,在窗口內找到使式(3)概率最大的值Pb,令χb=(Pb,θb):
建圖過程中車輛位姿和地圖中地標狀態(包括網格的位置估計和網格概率)聯合概率的最大似然估計[7]為:
式中,Zt為t時刻的2D 語義網格,包括由頂視圖轉換的像素網格、以初始位姿χa為參考位置的周邊語義網格的狀態;Zt j為上述2D語義網格中各網格的語義狀態;χt為t時刻的位姿;ut為t時刻車輛的運動狀態;m為地圖中的網格狀態;P(·|·)為條件概率。
當式(3)取得最大值時,式(4)為最大概率值。
c.為了得到精確值,建立誤差模型,在初值χb附近添加擾動,采用最小二乘優化法得到精確解:
式中,Zhit為有語義的網格,表示此時精確解χ*使當前頂視圖中含有語義網格與已有地圖中含有語義網格相互匹配。
確定車輛的位姿χ*后,通過式(2)更新地圖中已有網格的概率,同時創建新網格并賦予初始概率。
隨著頂視圖轉換的網格持續更新,按照上述步驟執行,從而增量地構建地圖,見圖4(地圖中數字表示概率的取值,無實際意義)。基于頂視圖的多次觀測產生的2D語義網格,對網格A的概率進行迭代更新。同理,地圖中各網格的概率可多次更新,且不易受到偶爾的語義錯誤影響。因此,短時間內的語義識別錯誤或像素分割錯誤不會在地圖上留下痕跡,從而提高地圖的準確性。
3 試驗結果
3.1 試驗算法流程
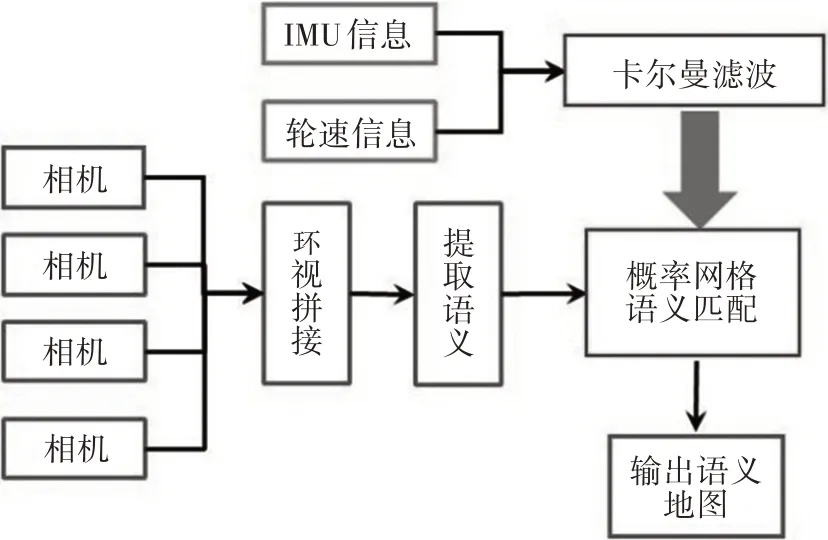
圖5 算法實現框架
3.2 試驗環境
本文使用乘用車的4個環視相機采集的原始圖像數據,在時間戳同步的基礎上,將原始圖像拼接為頂視圖,其覆蓋范圍為14 m×14 m,網格化分辨率為288×288。試驗運行的處理器為Intel@CoreTMi7-4710MQ, 主頻2.5 GHz,內存8 GB。根據經驗,Chit和Cmiss分別設置為0.55和0.49。
使用深度層聚合(Deep Layer Aggregation,DLA)為網絡的主干結構,通過U-Net[8]進行語義分割,從頂視圖中提取不同類型的語義。
由于環境具有復雜性,圖像分割時均會存在不同程度的噪聲。圖6所示為地下車庫典型場景中不同類型的語義噪聲。此外,圖中均存在斑馬線界限不清晰以及部分條紋線未識別的問題。圖6b 中道路間的地面由于白熾燈光反射被誤識別為車道線。

圖6 語義分割的噪聲
3.3 試驗結果
比較本文提出的概率網格匹配法與NDT 語義點云匹配法所構建的語義地圖。如圖7 所示,DNT法不能抵抗語義分割產生的噪聲,其構建的語義地圖存在語義邊界不清晰,甚至無法區分紋理的現象,在U形轉彎處語義混淆現象尤其明顯。
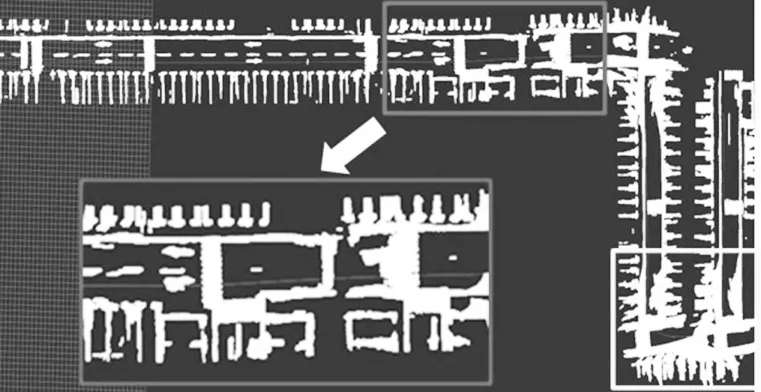
圖7 NDT法構建的語義點云地圖
本文提出的概率網格匹配法構建的語義地圖如圖8 所示。與圖7 相比,概率網格匹配法能有效抵抗語義噪聲,U 形轉彎區域所包含的斑馬線條紋清晰可見。從細節上看,NDT 法構建的點云地圖語義輪廓粗糙、混疊不清晰,完全無法區分與條紋狀斑馬線相似度高且容易匹配錯誤的語義,而本文提出的概率網格匹配法構造的斑馬線紋理清晰且正確。
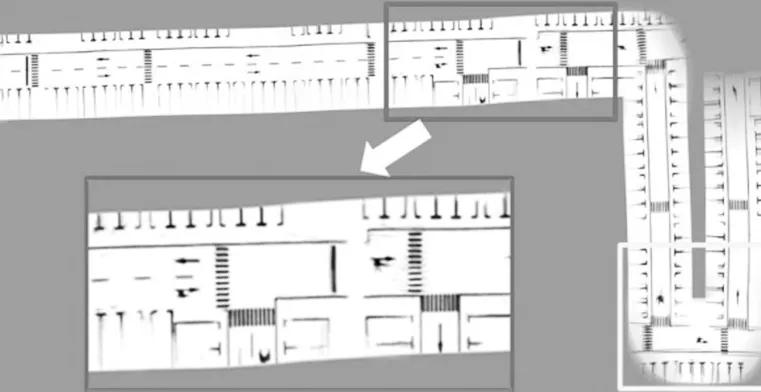
圖8 概率網格匹配法構建的語義點云地圖
圖9 所示為卡爾曼濾波融合的里程計軌跡(簡稱里程計軌跡)、基于NDT 語義點云匹配的建圖軌跡和基于概率網格匹配的建圖軌跡。
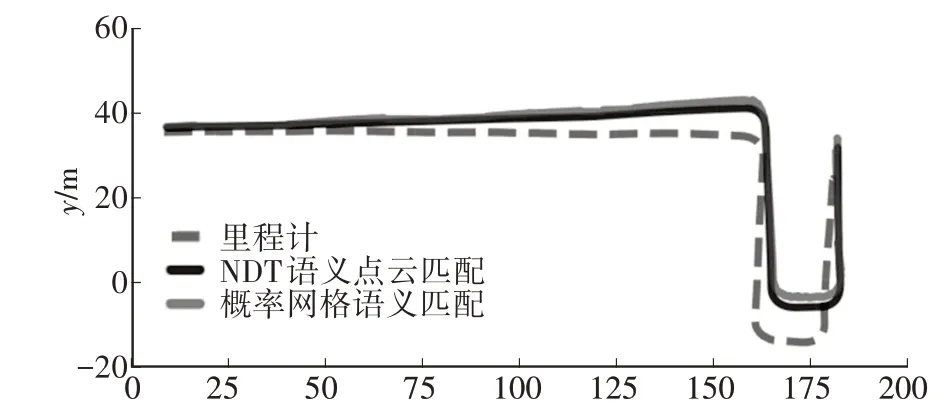
圖9 里程計、NDT及概率網格建圖軌跡
以里程計軌跡為基準,比較其他2 種方法的建圖軌跡與里程計軌跡之間的相對位姿誤差(Relative Pose Error,RPE),如圖10所示。
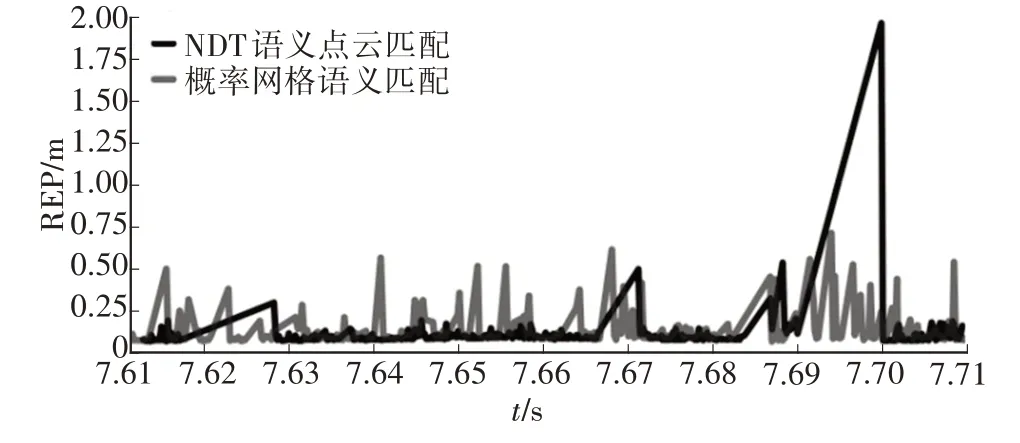
圖10 NDT與概率網格建圖RPE曲線
表1列出了基于NDT語義點云匹配及基于概率網格語義匹配的RPE參數。由表1可知,概率網格匹配法與NDT 點云語義匹配法多項指標接近,但概率網格匹配法最大RPE 遠小于NDT 點云匹配法的RPE。RPE 比較的是不同軌跡上相鄰兩幀之間的位姿變換,作為計算RPE 基準的車輛里程計軌跡是相對精確的。RPE 越大,表明建圖軌跡與車輛里程計軌跡之間的誤差越大,NDT 法建圖軌跡在部分區域與實際路徑相差甚遠。
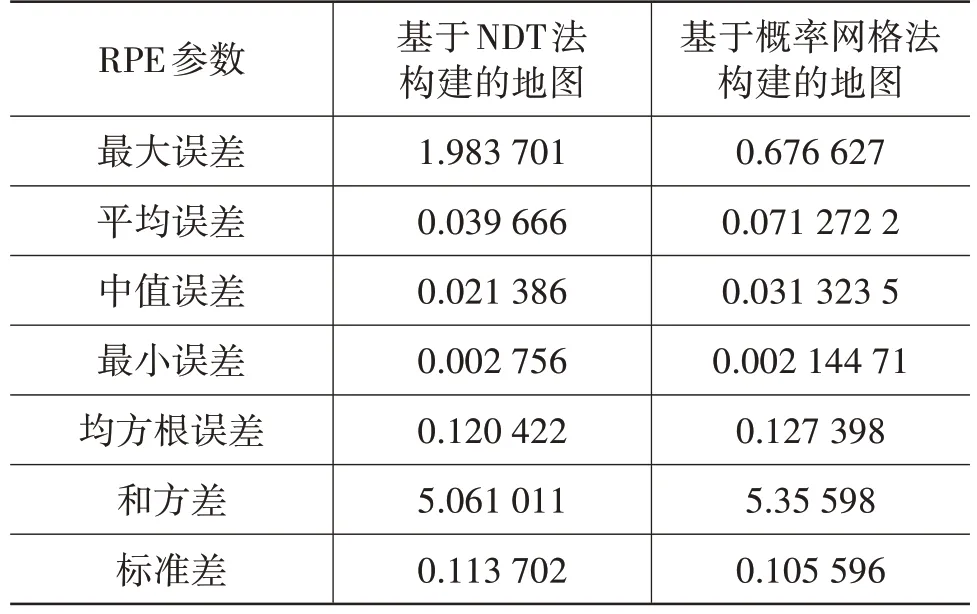
表1 相對位姿誤差比較 m
4 結束語
本文提出二維概率網格語義法進行概率語義地圖構建,基于多源信息融合提供位姿先驗信息,在聯合概率的最大似然估計框架下,先確定角度,后確定位置,通過窗口搜索得到初始匹配位姿,再使用最小二乘法優化網格概率更新,得到智能載體的最終位姿。利用語義觀測在空間和時間上的連續性,對各網格的概率進行多次更新,從而消除噪聲的影響,獲得了清晰的語義地圖。試驗結果證明了所提出方法的有效性。
此外,本文提出的方法無需多次使用相機采集原始圖像信息(例如從原始圖像上提取特征點),在計算過程中避免使用和存儲原始圖像,可節約計算資源和存儲資源,降低成本。
未來,將構建大范圍的三維語義地圖,如在多層地庫的場景中嘗試利用本文提出的網格匹配和概率更新法構建語義地圖。本文提出的語義匹配方法還可用于開發代客泊車定位算法。需要指出的是,本文所述的方法不限于智能駕駛,其他類似可獲取行駛軌跡的頂視圖場景均適用。
猜你喜歡
開放教育研究(2020年2期)2020-03-31 01:54:14
現代語文(2016年21期)2016-05-25 13:13:44
大連民族大學學報(2015年2期)2015-02-27 08:28:11
當代修辭學(2011年6期)2011-01-29 02:49:50
外語學刊(2011年1期)2011-01-22 03:38:33
當代修辭學(2010年1期)2010-01-23 06:35:10
