掩碼生成動態調控弱監督視頻實例分割
2023-11-01 01:52:02何自芬張印輝
光學精密工程 2023年19期
何自芬, 徐 林, 張印輝, 黃 瀅
(昆明理工大學 機電工程學院,云南 昆明 650000)
1 引 言
視頻實例分割[1-3]任務旨在對時序變換場景中的多目標同時進行檢測、分割和跟蹤,是當前機器人視覺感知[4-5]、無人駕駛道路場景理解[6-7]、雷達識別與跟蹤[8-9]等新一代智能機器前沿交叉領域的一項核心技術,廣泛應用于交通、工業、醫學和國防等重要領域。
根據分割網絡是否需要提供訓練集精細掩碼標注信息,視頻實例分割可分為全監督和弱監督兩種訓練類型。全監督網絡的訓練數據需要大量精細掩碼標注,但單幀圖像中各實例的精細掩碼標注所需時間大約為54~79 s[10],單個實例邊界框的標注需要7 s,單個實例圖像級類別標注只需要1 s[11]。因此,采用弱標注代替精細掩碼標注的弱監督視頻實例分割能大幅壓縮標注成本,非常適用于需要快速備樣以迅速適應新場景的智能機器視覺系統。
現有的弱監督視頻實例分割方法分為圖像級標注和邊界框標注兩種。Liu 等[12]提出第一個圖像級標注弱監督視頻實例分割網絡,采用像元關系網絡[13]結合目標實例的光流運動信息生成偽掩碼標簽,然后在掩碼組成模塊中利用視頻幀的時間一致性進行實例匹配和分割。但該網絡未實現端到端訓練,且圖像級標注無法使網絡精確聚焦實例區域。邊界框標注視頻實例分割網絡[14]沿用實例分割網絡BoxInst[15]的兩種掩碼監督方式和網絡框架,并計算實例外觀和運動信息的光流相似性,生成偽標簽監督訓練。但該網絡初始掩碼預測分支特征通道維度突降導致實例激活特征丟失,且初始預測掩碼特征在通道和空間中信息缺乏關聯,與實例感知信息的動態交互能力受到制約。另外,光流法受光線變化影響大,計算量大且耗時長,無法使智能機器分割算法適用實時性要求高的任務。
為了解決上述問題,本文構建了多級特征融合模塊,利用特征復用策略相互學習各級特征以生成初始預測掩碼,有效克服掩碼分支預測一組原型實例時通道維度突降導致預測實例激活特征丟失的問題。設計了動態調控機制在初始預測掩碼特征通道和空間中建立依賴關系,使分割網絡初始預測掩碼與實例感知信息動態交互,更多關注實例區域,進一步提升目標分割精度。提出了邊界框與掩碼一致性損失監督預測掩碼僅在實例邊界框范圍內生成,并計算輸入圖像和預測掩碼的二元顏色相似性,約束預測掩碼更加接近實例區域。
2 相關工作
2.1 邊框級弱監督實例分割
為了解決實例分割數據標注量過大的問題,早 期 方 法[10,15,17]僅 對 訓 練 數 據 進 行 邊 界 框 標 注,并尋找實例區域的像元特征信息優化預測掩碼,實現逐像元實例分割。第一個僅用邊界框標注的實例分割框架[10](Simple Does It, SDI),將邊界框以內的區域都標注為實例,以外的都標注為背景,以此作為訓練的先驗信息對分割結果進行迭代優化。然而,此方法先利用目標輪廓檢測算法[16]生成偽標簽,再以全監督的流程訓練網絡,并不能做到端到端訓練。類不可知聯合學習弱監督網絡[17]認為在邊界框的像元區域內,每一行或每一列像元至少有一個像元點屬于實例,將這些行和列稱作正包,邊界框外的則稱作負包,然后將正負包集合作為訓練數據,設計多實例學習方案嵌入到Mask R-CNN[18]全監督流程中完成端到端訓練。由于保留了兩階段實例分割先檢測后分割的范式,依靠大量原圖候選框映射到特征圖相應區域的操作獲得實例掩碼,該方法的訓練和推理速度較慢。BoxInst[15]在一階段實例分割 網 絡(Conditional Convolutions For Instance Seg-mentation,CondInst)[19]的基礎上提出投影損失函數和成對相似性損失函數,利用實例邊界框和掩碼在X軸和Y軸上具有相同的投影、相鄰像元大概率具有相同實例標簽兩個先驗信息,約束網絡生成最終的實例預測掩碼。
2.2 視頻實例分割
MaskTrack R-CNN[1]是 第 一 個 提 出 視 頻 實例分割任務的兩階段網絡,它創建了第一個大規模視頻實例分割數據集YT-VIS,并在Mask RCNN[18]基礎上增加新的跟蹤分支,利用外部記憶追蹤不同幀之間的實例,為邊框回歸頭生成候選框并分配實例標簽。但該網絡需利用RoIAlign操作生成大量候選建議框,網絡訓練速度和推理速度緩慢,難以應用在實時性要求較高的任務中。受到一階段實時實例分割網絡YOLACT[20]的啟發,Sipmask[21]引入輕量級空間保存模塊,在每個邊界框中生成單獨空間系數,解決了預測邊界框中空間信息不足的問題,更好地描繪空間中相鄰實例;另外,利用掩碼對齊權重損失和利用可變形卷積進行特征與回歸框位置對齊,將掩碼預測和實例檢測相關聯。Li 等[22]發現單階段實例分割網絡存在卷積特征既不與預測框對齊也不與真實邊界框對齊的問題,這降低了掩碼預測的空間感知能力,因此,為錨框和真實邊界框設計了特征校準策略以獲得更精確的空間特征;同時,利用視頻固有特性構建了一個時間融合模塊聚合當前幀與參考幀的掩碼特征,提高了相鄰幀之間的時間相關性。然而,基于視頻幀的時間建模方法[21-22]僅停留在相鄰幀之間。由于時間維度承載的豐富場景信息對網絡分割、定位和類別預測有重要作用,在線交叉學習網絡[23](Crossover learning for fast online video instance segmentation,CrossVIS)在實例分割網絡CondInst[19]的基礎上建立交叉學習模塊,用視頻序列中豐富的上下文信息,將同一目標在非相鄰兩幀中的位置信息跨幀融合到每幀的預測掩碼,引入位置信息增強實例表示,同時削弱背景和與實例無關的信息。CrossVIS[23]利用全卷積網絡作為初始掩碼預測頭,擺脫了兩階段實例分割方法訓練和推理速度慢的缺點,但存在初始預測掩碼實例激活特征丟失嚴重,無法有效融合實例感知信息的問題。
3 WSVIS 網絡結構
3.1 生成調控部分
本文提出了弱監督視頻實例分割網絡(Weak Supervised Video Instance Segmentation,WSVIS),其整體結構如圖1 所示,分為生成調控部分和交叉預測部分。
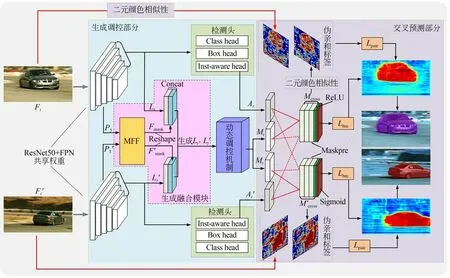
圖1 WSVIS 網絡結構Fig.1 Structure of WSVIS network
WSVIS 網絡在同一視頻序列中隨機抽取兩幀(Ft∈RB×3×H×W,Ft'∈RB×3×H×W,B表示Batch size) 圖像作為網絡生成調控部分輸入。生成調控部分由初始特征提取網絡、檢測頭、生成融合模塊和動態調控機制組成。Ft,Ft'經過參數共享的ResNet50 骨干網絡[24]和特征金字塔網絡(Feature Pyramid Network,FPN)[25])提取圖像初始特征。檢測頭包含分類頭(Class Head)、邊框回歸頭(Box Head)和實例感知頭(Inst-Aware Head)。FPN 輸出特征分別經過檢測頭和生成融合模塊。
檢測頭根據FPN 各層[P3,P4,P5,P6,P7]輸出特征的每個像元預測與之相關聯的類別,并直接回歸錨點到邊框的距離完成實例邊界框預測,同時實例感知頭與分類頭結構相同用于預測掩碼的實例感知信息At,At'。生成融合模塊的輸入 是 FPN 高 分 辨 率 層 的 輸 出 特 征P3∈RB×128×H×W,P3'∈RB×128×H×W,由 于 實 例 預測所需的相對位置信息來自FPN,為了構建兩者的聯系,將初始預測特征Fmask,Fm'ask尺寸重置為N×8×(H×W)(N取決于邊框回歸頭保留的預測實例數量),并與它到FPN 各特征層之間的相對位置信息Lt∈RB×2×(H×W),Lt'∈RB×2×(H×W)在通道維度上進行拼接,然后重置為原始特征圖尺寸,生成初始 預 測 掩 碼It=∈RB×2×(H×W),It'=∈RB×2×(H×W)。動態調控機制生成通道和空間權重加權 ,強化初始預測掩碼在交叉預測部分中與實例感知信息的動態交互能力。
3.1.1 多級特征融合模塊
CrossVIS[23]原始掩碼預測層如圖2(左下角)所示,包含4 個卷積核大小為3×3,通道數為128的串行卷積層,最后一層通道數從128 減少到8,代表生成8 組實例掩碼。但實例通道突降會導致初始預測掩碼激活特征丟失,因此受人體姿態估計網絡[26]啟發,本文提出多級特征融合(Multilevel Feature Fusion,MFF)模塊。為了增強高分辨率信息,通過將高分辨率和低分辨率卷積并行連接,達到多尺度特征交互的目的。不同的是,MFF 模塊包含5 級通道數不同的串行卷積層,各級卷積層之間采用特征復用機制進行特征融合。如圖2 所示,用Lji代表MFF 的5 級通道變換層,i∈[1,2,3,4,5]代表層級代號,j∈[1,2,3]代表3個串行卷積從左到右的順序代號。MFF 模塊輸入 為 FPN 輸 出 特 征P3∈RB×128×48×80,P3'∈RB×128×48×80。特征經過L11層后并行輸入到L21和L12層,L12層輸出通道為64,然后經過二倍通道上采樣與L21層在通道維度對齊并相加作為L31層的輸入;L21層輸出通過1/2 倍通道下采樣與L22層在通道維度對齊并作為L22層的輸入;然后L12層輸出作為L13層輸入,L31層輸出、L22層輸出和L13層輸出之和作為L32層的輸入。同理,其他相鄰級通道特征也通過這種高級特征與低級特征交互融合的方式建立聯系,能有效緩解激活特征丟失的問題。MFF 模塊各級特征融合計算流程可表示為:
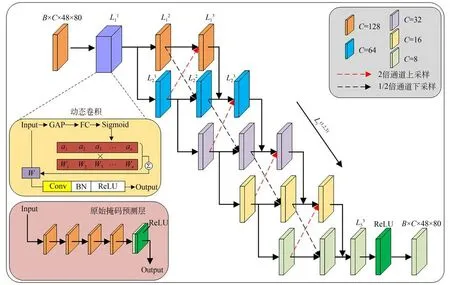
圖2 MFF 模塊結構Fig.2 Structure of MFF module
式中:表示各卷積層輸出,表示輸出經過Lji層。
經過MFF 模塊后,輸入特征尺寸并不會改變,因此最終輸出特征與原始掩碼預測層的輸出維度一致,可表示為為了使網絡從初始預測到交叉預測保持動態聯系,其中L11層是為每個樣本學習一個卷積核參數的 動 態 卷 積CondConv[27],動 態 卷 積 等 同 于 多 個標準卷積的線性組合,每個卷積中根據特征輸入決定卷積核權重,再對這些卷積核加權求和得到一個適合該輸入的動態卷積核權重因子。動態卷積計算過程可表示為:
輸入特征Input(Fmask,F'mask)經過全局平均池化(Global Average Pooling,GAP)層得到由所有通道的特征圖像的像素平均值組成的池化特征向量,然后特征向量經過全連接層(Fully Connected,FC)后通過Sigmoid 函數生成一系列與初始卷積權重ωi一一對應的權重ai,訓練過程中ωi同時學習和訓練,因此對于每個預測實例都會生成特定權重。將ωi和ai分別相乘再相加后與輸入Input 做卷積運算,最后使用ReLU 函數增加各層特征之間的非線性關系。
3.1.2 動態調控機制
為加強初始預測掩碼與動態實例感知信息之間的聯系,本文提出動態調控機制尋找空間和通道上對于區分前背景更有效的信息,提高網絡對實例區域的關注。如圖3 所示,動態調控機制分為通道調控機制和空間調控機制兩個部分,通道調控可以區分網絡預測特征不同通道的重要程度,采取全局最大池化和全局平均池化對動態生成的N維實例特征圖進行壓縮,以此建立各通道特征之間的關系。空間調控在N維實例特征圖上尋找對區分前景和背景起重要作用的像元區域。
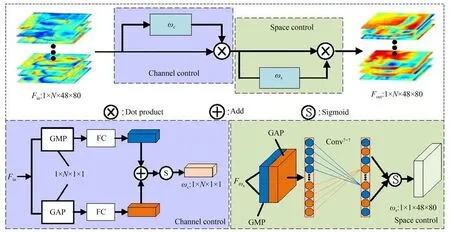
圖3 動態調控機制Fig.3 Dynamic control mechanism
通 道 調 控 機 制 的 輸 入 為Fin∈R1×N×48×80。首先輸入特征按通道進行全局最大池化(Global Max Pooling,GMP)和全局平均池化(Global Average Pooling,GAP)得到兩組尺寸為N×1×1 的池化特征,然后將兩組特征向量分別送入FC 后對應元素相加,最后利用Sigmoid 函數計算得到通道權重系數ωc∈R1×N×1×1。
其中:θ1,θ2表示全連接層權重系數,S表示Sigmoid 函數。ωc為輸入特征Fin每一個實例通道賦予不同的權重,得到N維通道調控加權的特征輸出Fωc∈R1×N×48×80。通道調控加權后的特征Fωc輸入空間調控機制,首先將Fωc在空間上進行GMP和GAP 并拼接得到尺寸為2×48×80 的池化特征,然后使用一維卷積將兩個池化特征圖在通道維度進行信息交互,最終經過Sigmoid 生成空間注意力權重系數ωs∈R1×N×48×80。
其中:Conv7×7表示尺寸為7×7 的卷積核,Cat表示拼接。然后,ωs與Fωc進行逐像素點積運算得到 最 終 的 動 態 調 控 機 制 輸 出Mt∈R1×N×48×80,Mt'∈R1×N×48×80。
3.2 交叉預測部分
WSVIS 網絡的交叉預測部分包含交叉學習方案和損失計算。Ft,Ft'兩幀經過生成調控部分后得到動態預測掩碼Mt,Mt',以及來自實例感知頭的實例感知信息At,A't。對于視頻實例分割,同一實例可能出現在視頻兩幀中的不同位置,因此兩幀中同一實例的外觀信息和位置信息可以相互引導。交叉學習方案可表示為:
其 中:Maskpre表示最終掩碼預測層,Mt,Mt'是Maskpre的 輸 入 特 征,At,A't提 供Maskpre所 需 的卷積核權重和偏置,Mcross和M'cross表示最終實例預測掩碼。Maskpre第四層使用ReLU 作為激活函數,最后一層使用Sigmoid 得到最終實例預測概率。
3.2.1 邊界框與掩碼一致性損失
本文網絡訓練時不具備精細掩碼標注信息,而已知的先驗信息是:在平面上,實例邊界框與實例掩碼水平方向的長和垂直方向的寬具有一致性。因此,本文利用真實標注實例邊界框約束預測掩碼在邊界框內生成。邊界框與掩碼一致性如圖4 所示。

圖4 實例邊界框與掩碼區域一致性示意圖Fig.4 Consistency images of instance bounding box and mask area
假設真實標注邊界框水平方向長為bl、垂直方向寬為bw,預測掩碼水平方向長為ml、垂直方向 寬 為mw,利 用 相 似 度 度 量 函 數Dice Loss[28]衡量二者偏差,則損失函數表示為:
其中:Lbm應用于所有n個預測實例概率圖和真實邊界框的偏差計算,最終損失值為是Lbm/n。
3.2.2 偽親和標簽生成與二元顏色相似性損失
這里以輸入圖像和預測掩碼二元像元顏色相似性生成的偽親和標簽計算損失優化預測掩碼。首先,將圖片下采樣到與交叉預測部分預測掩碼特征圖的相同尺寸,為了更加直觀地判斷顏色的相似性,將下采樣后的圖像數據從RGB 空間轉換到更加接近人類視覺感知的Lab 空間,然后計算輸入圖像和預測掩碼的二元顏色相似性,以此生成偽親和標簽,最后計算二者損失優化預測掩碼。計算流程如圖5 所示。
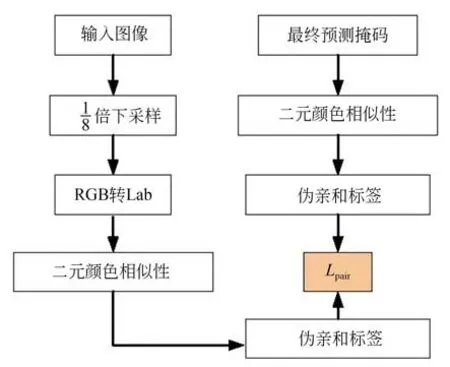
圖5 二元顏色相似性損失計算流程Fig.5 Flow chart for binary color similarity loss calculation
針對下采樣后圖像分辨率降低導致原有像素特征丟失的問題,本文受到空洞卷積[29]的啟發,將鄰域像元點采樣間隔設置為2,在保證像元采樣感受野的同時能獲得最優分割性能。
像元采樣如圖6 所示,以圖像上顏色相近的兩像元點大概率具有相同實例標簽作為先驗,中心像元與領域8 個像元分別計算相似度,然后利用顏色相似度閾值過濾相似度低的一對像元,計算二元顏色相似度生成交叉預測部分所示的偽親和標簽。
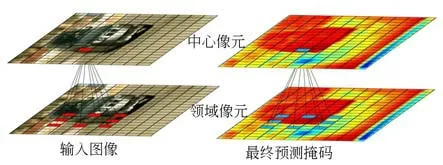
圖6 像元采樣示意圖Fig.6 Pixel sampling diagram
假設p1表示中心像元,p2表示中心像元鄰域任一像元,那么在Lab 空間中p1和p2的顏色相似度可表示為:
其中‖Labp1-Labp2‖表示p1和p2在Lab 空間中的感知相似度。
本文相似度閾值λ是預先設置的超參數,延續 弱 監 督 實 例 分 割 網 絡BoxInst[15]的 設 置,λ設 置為0.1。當S≥λ時,兩像元點相似且具有相同的實例標簽;當S<λ時,兩像元點所屬標簽不相同。對于預測掩碼,上述標簽學習問題轉化為像元對是否同屬于實例和背景的二分類概率問題,在某個實例的預測掩碼Mcross,M'cross中某對像元g同為實例的概率表示為P(g=1),其余為背景的概率表示為P(g=0)。二分類概率計算像元對采樣方式與偽標簽相似度計算方式一致。
邊界框與掩碼一致性損失函數約束掩碼僅在預測框內生成,最后采用二元交叉熵(BCE)損失函數優化預測掩碼與輸入圖像偽親和標簽之間的差距。二元顏色相似性損失函數可寫為:
其中:N表示經顏色相似度閾值過濾后保留的相似像元對數量,Gb表示邊界框內的像元對的集合。當S≥λ時,τ=1; 當S<λ時,τ=0。
3.2.3 總損失函數
本文聯合邊界框與掩碼一致性損失和二元顏色相似性損失,實現僅邊界框標注的WSVIS網絡,端到端進行檢測、分割和跟蹤,每個訓練樣本的多任務損失函數表示為:
其 中:Lcls,Lbox和Lid與CrossVIS[23]一 致,分 別 表示分類損失、邊界框損失和跟蹤損失,Lbm和Lpair為本文邊界框與掩碼一致性損失和二元顏色相似性損失。
4 實驗結果及分析
4.1 實驗數據
本文數據集BoxSet 由382 段視頻數據組成,其中329 段視頻用于訓練,53 段視頻用于測試。訓練集僅使用邊界框和類別標注,測試集的標注方法與全監督數據集一致并用于網絡模型分析和調優。
為了驗證WSVIS 網絡的穩定性,在大型視頻 實 例 分 割 數 據 集YT-VIS[1]2019 上 與 現 有 弱監督視頻實例分割網絡FlowIRN[12]和FlowSimi[14]進 行 對 比。YT-VIS[1]數 據 集 共 包 含2 883段視頻,其中訓練集視頻2 238 段,測試集338 段,訓練時不使用精細掩碼標注信息。
4.2 訓練細節
實驗硬件環境如下:基于Ubuntu18.04 操作系統,CPU 型號為Intel(R)Core(TM)i5-11400,GPU 型 號 為NVIDIA GeForce RTX2080Ti。軟件環境如下:深度學習框架為PyTorch1.8.1,python 版 本 為3.7,采 用CUDA10.2 運 算 平 臺 和CUDNN8.3.2 工具包加速模型訓練。超參數設置如表1 所示。

表1 訓練參數設置Tab.1 Training parameter settings
4.3 視頻實例分割評價指標
本文的網絡評估指標與MaskTrack RCNN[1]一致,其中平均精度(Average Precision,AP)是交并比(Intersection Over Union, IoU)從50%到95%之間步長為5%的10 個閾值的總平均 精 度,AP50,AP75分 別 代 表IoU 閾 值 為50%和75%時的平均精度;AR1,AR10則表示限定條件下的平均召回率。與靜止圖像實例分割不同的是,視頻中每一個實例在整個視頻序列中都包含了一系列掩碼,因此視頻實例分割評估時IoU 的計算不僅需要在空間域上進行,也要在時間域上進行,則IoU 定義為每一個實例的預測掩碼與真實標簽的交集與并集的商,即[1]:
在測試階段,計算預測值與真實值的IoU 是否大于給定閾值,若IoU 大于閾值表示為TP,小于閾值則表示為FP。則總平均分割精度定義為:
其中:C代表數據集中的類別數量,c為當前類別,thr閾值數,t為當前閾值。
4.4 實驗結果分析
實驗對比了WSVIS 與其他視頻實例分割網絡在BoxSet 和YT-VIS[1]上的各項平均精度,結果如表2 所示。3 種全監督視頻實例分割網絡均為單階段視頻實例分割網絡,在BoxSet 上AP 分別達到了36.2%,37.5%,39.9%,WSVIS 網絡的AP 超 過 了Sipmask[21],與STMask[22]相 近,僅比CrossVIS[23]低2.4%,AP50優 于 其 他3 個 全 監督 網 絡,達 到64.7%。 由 于FlowIRN[12]和FlowSimi[14]網 絡 并 未 公 開,因 此 在YT-VIS[1]上對3 種弱監督網絡進行對比。圖像級弱監督視頻實例分割網絡FlowIRN[12]的AP 為10.5%,邊界框弱監督視頻實例分割網絡FlowSimi[14]的AP為29.0%,WSVIS 網 絡 的AP 為30.1%,相 比FlowIRN[12]提升19.6%,比最先進的FlowSimi[14]網絡高1.1%。
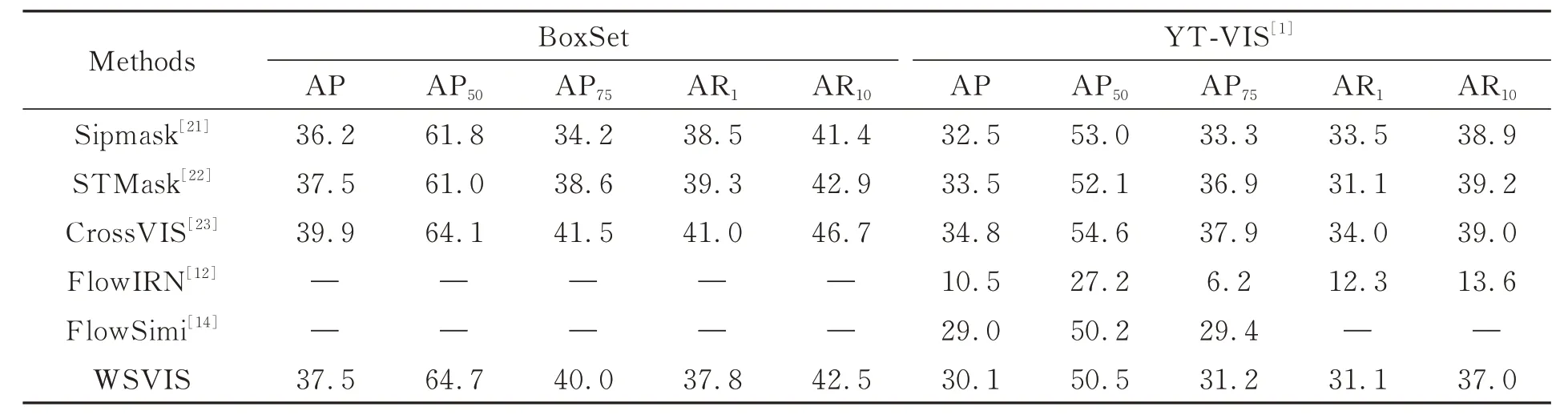
表2 不同視頻實例分割網絡的實驗結果對比Tab.2 Comparison of experiment results for different video instance segmentation networks (%)
在YT-VIS[1]上,3 種 弱 監 督 視 頻 實 例 分 割網絡精度分割均低于全監督視頻實例分割網絡。由于全監督視頻實例分割網絡采用精細掩碼標注,網絡利用優質的監督信息在迭代訓練中能學習到更優的參數,因此在測試中通常能獲得更好的分割精度和效果。而不論是圖像級標注或是邊界框標注,弱監督視頻實例分割網絡都缺乏精細的真實掩碼標注,僅有接近真實標注的偽親和標簽監督網絡訓練,網絡不可避免地會引入錯誤監督信息,導致分割精度降低。WSVIS 網絡在弱監督學習范式下超過了目前最先 進 的FlowSimi[14],分 割 精 度 和 分 割 效 果 接 近于全監督視頻實例分割網絡,同時由于不需要精細掩碼標注,與全監督網絡相比,數據標注量大大減少,加快了各類場景弱監督網絡的開發進程。
圖7 展 示 了WSVIS 網 絡 與CrossVIS[23]網 絡的3 段視頻分割結果。從分割效果可以看到,WSVIS 網絡具有與全監督網絡相近的分割性能。在3 段視頻中,均可以看到CrossVIS[23]網絡將一些稀疏背景區域或實例部分區域錯誤分割,而WSVIS 卻不存在此類問題,這得益于WSVIS網絡邊界框與掩碼一致性損失的良好性能,使實例預測掩碼總是在邊界框中生成。總體來看,WSVIS 網絡在訓練數據僅包含邊界框標注的情況下獲得了準確的分割結果,具備良好的視頻場景感知和分析能力。

圖7 視頻分割結果Fig.7 Video segmented results
4.5 消融實驗
為證明MFF 模塊、動態調控機制、邊界框與掩碼一致性損失Lbm和二元顏色相似性損失Lpair對WSVIS 網絡的有效性,將各模塊和損失在BoxSet 數據集上進行消融實驗。
4.5.1Lbm和Lpair實驗
Lbm和Lpair消融實驗結果如表3 所示。可以看出,當僅使用邊界框與掩碼一致性損失Lbm監督網絡掩碼分支訓練時,總平均分割精度為23.7%;僅使用二元顏色相似性損失Lpair監督網絡掩碼分支訓練時,總平均分割精度為22.5%;而當WSVIS網絡同時使用二者監督訓練,總平均分割精度提升10%左右。由此可見,邊界框與掩碼一致性損失Lbm和二元顏色相似性損失Lpair共同使用能顯著提升WSVIS 網絡的弱監督分割性能。

表3 Lbm 和Lpair 的有效性驗證Tab.3 Effectiveness verification for Lbm and Lpair(%)
4.5.2 MFF 模塊實驗
MFF 模塊的消融實驗結果如表4 所示。當WSVIS 網絡僅利用Lbm和Lpair兩項損失進行監督時,在本文數據集上的總平均分割精度為32.9%。加入MFF 模塊后,網絡總平均分割精度從32.9%提高到36.3%。
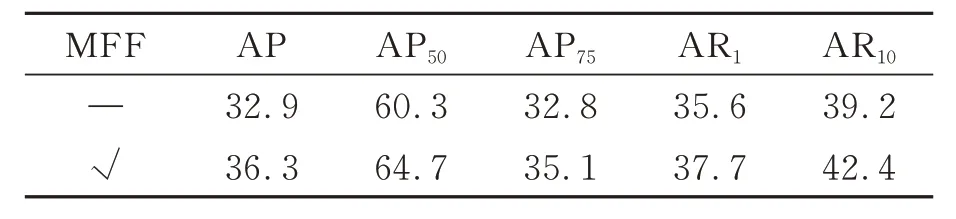
表4 MFF 模塊的有效性驗證Tab.4 Effectiveness verification of MFF module(%)
為了驗證MFF 模塊5 級特征通道逐級融合對提升網絡分割精度的有效性,對MFF 模塊采用不同層級通道融合與使用標準卷積和動態卷積作為L11層進行對比實驗,結果如表5 所示。當L11層使用標準卷積時,MFF 模塊層級從3 級到5級的總平均分割精度增加2.2%;而使用動態卷積CondConv[27]時,MFF 模 塊 層 級 從3 級 到5 級精度增加2.0%。CondConv 為5 級時,MFF 模塊提升網絡的總平均分割精度最大。

表5 MFF 模塊不同級、L11 層不同的卷積實驗結果Tab.5 Convolution experiment results of different MFF module levels and different L11 layers (%)
4.5.3 動態調控機制實驗
WSVIS 網絡在加入動態調控機制后的總平均精度從36.3%提高到37.5%,如表6 所示。如圖8 所示,特征經過動態調控機制后,實例區域得到了更多關注,從而更有利于初始預測掩碼與動態感知權重和偏置之間進行交互。

表6 動態調控機制的有效性驗證Tab.6 Effectiveness verification of dynamic regulation mechanism (%)
僅邊界框與掩碼一致性損失、二元顏色相似性損失共同監督時,WSVIS 網絡的總平均分割精度為32.9%,通過構建MFF 模塊和動態調控機制,WSVIS 網絡的分割精度提升至37.5%。
由于MFF 模塊采用多級特征復用策略進行通道特征融合,在一定程度上解決了由于掩碼預測分支特征通道突然下降導致實例激活特征嚴重丟失的問題。原始預測掩碼經過特征激活后前景和背景區域的差別并不明顯,實例激活特征丟失嚴重,而MFF 模塊增強了圖像中屬于實例的目標區域特征信息。動態調控機制在空間和通道維度上進一步增強了網絡對于實例和背景的感知能力。
對比圖8(d)和8(b)可看出,MFF 模塊和動態調控機制不僅有效增強了網絡對實例區域的關注,一些稀疏的背景區域也得到了增強。然而,這些稀疏背景區域會在交叉預測部分受到交叉學習方案、邊界框與掩碼一致性損失和二元顏色相似性損失的共同抑制,使預測掩碼更接近真實實例區域,如圖8(e)所示。
4.5.4 交叉學習和幀間隔實驗
WSVIS 網絡設計了交叉預測部分,將同一實例在不同幀的外觀和實例信息關聯起來實現幀交叉學習,在加入MFF 模塊和動態調控機制的WSVIS 網絡基礎上驗證兩幀交叉學習的有效性以及不同采樣幀間隔對網絡的影響,實驗結果如表7 所示。采樣幀間隔最小為1,最大為35。
由表7 可知,當采樣幀間隔趨向于1 時,網絡總平均分割精度逐漸下降,這是因為當采樣間隔較小時,采樣兩幀圖像信息非常相似,這會使得網絡退化為靜止圖像分割的形式,交叉學習不能獲得最大的增益。隨著采樣幀間隔變大,采樣的兩幀中實例位置和場景上下文信息有明顯的位置和外觀差異,交叉學習方式能更好地利用實例外觀信息和位置信息,將兩個采樣幀中的同一實例進行關聯;當采樣幀間隔為20 時,WSVIS 網絡獲得了最好的總平均分割精度,為37.5%;而當采樣幀間隔大于20 時,同一實例在兩幀中的位置和外觀差異較大,網絡的總平均分割精度逐漸下降,因此兩幀交叉學習獲得了相反的引導。此外,當選擇最優采樣幀間隔20 時,不使用交叉學習方案的網絡總平均分割精度僅為34.6%。由此可知,交叉學習方案可以有效利用不同采樣幀的實例信息,當采樣幀間隔為20 時,交叉學習的作用最大。
4.6 計算復雜度分析
WSVIS 網絡除去在數據集上有良好表現外,在模型復雜度和推理速度上也具有一定優勢。由于弱監督視頻實例分割網絡FlowIRN[12]和FlowSimi[14]未 公 開 其 原 始 算 法,因 此 對 比 了WSVIS 網絡和全監督視頻實例分割網絡Sipmask[21],STMask[22]和CrossVIS[23]的 模 型 參 數量、模型計算量和推理速度,結果如表8 所示。分析實驗在YT-VIS[1]測試集上進行,推理速度不計算數據加載和測試后處理,僅統計所有視頻推理完成后的平均推理速度。

表8 不同網絡的模型復雜度和推理速度對比Tab.8 Comparison of model complexity and inference speed of different networks
實驗表明,相比Sipmask[21]網 絡,WSVIS 網絡模型的參數量降低74%、計算量降低29.4%;相 比STMask[22]網 絡,WSVIS 網 絡 模 型 的 參 數量降低76.7%、計算量降低69.3%。 相比CrossVIS[23]網絡,MFF 模塊、動態調控機制、邊界框與掩碼一致性損失和二元顏色相似性損失使WSVIS 網 絡 僅 有0.22M 參 數 量、6.61G 計 算量的增長;另外,WSVIS 網絡在弱監督學習模式下仍然具有實時(FPS>30)推理的表現,推理速度降低了5.4 frame/s,仍高于Sipmask[21]網絡和STMask[22]網絡4~6 frame/s,能夠滿足智能機器快速適應新場景實現實時環境感知和理解的需求。
5 結 論
本文提出了WSVIS 網絡,首先構建多級特征融合模塊MFF 生成初始預測特征,有效緩解了網絡通道下降帶來的激活特征丟失;其次,通過動態調控機制在初始預測掩碼特征通道和空間中建立依賴關系,有效加強網絡對實例目標區域的敏感度;最后,利用邊界框與掩碼一致性損失約束預測掩碼在邊界框內生成,同時計算輸入圖像和預測掩碼的二元顏色相似性,約束預測掩碼更加接近實例區域。實驗結果及熱力圖可視化表明,MFF 模塊解決了初始預測特征丟失問題;動態調控機制能有效增強網絡對實例區域的關注;視頻幀采樣間隔為20 時,交叉學習方式能夠最大程度提升網絡的分割精度。WSVIS 網絡在BoxSet 數據集上的總平均分割精度為37.5%,達到與全監督網絡相近的分割精度和分割效果;在YT-VIS[1]測試集上各項分割精度均優 于 先 進 的FlowSimi[14]網 絡,分 割 速 度 為34.4 frame/s,具備視頻場景實時環境感知和分析理解的能力。
猜你喜歡
數學小靈通·3-4年級(2024年2期)2024-05-15 02:02:28
人大建設(2020年4期)2020-09-21 03:39:12
世界科學技術-中醫藥現代化(2020年2期)2020-07-25 02:05:36
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
人大建設(2017年2期)2017-07-21 10:59:25
人大建設(2017年9期)2017-02-03 02:53:31
浙江人大(2014年5期)2014-03-20 16:20:28
浙江人大(2014年4期)2014-03-20 16:20:16
