基于強化學習的個性化學習路徑推薦算法研究
2023-12-14 14:20:10陳耀東
科技風 2023年34期
關鍵詞:學生
陳耀東
長沙師范學院 湖南長沙 410100;湖南省教育科學研究院 湖南長沙 410100
“構建網絡化、數字化、個性化、終身化的教育體系”是實現建設學習型社會的重要條件。在移動互聯網、大數據、人工智能、云計算等眾多新技術的支持下,教育模式、教學方法、學習方式等均在發生深刻變革,促使我國教育向著智慧化、智能化的方向邁進,其中“關注學習者的個體差異”“為每個學習者提供適合的教育”這些理念在社會上逐漸共識,個性化教育與個性化學習成為解決我國當前社會教育供需矛盾的主要途徑。以自媒體為代表的新媒體環境下,學習資源極大豐富,如何利用智能技術為學習者提供定制化的學習路徑是當前個性化學習研究領域的一個熱點。個性化學習路徑推薦問題可以定義為,基于學習者學習能力、知識背景、學習興趣、達成目標等方面的差異,通過智能技術為學習者定制一條符合教育規律且能達到學標的學習路徑,同時實現學習者學習狀態檢測[1]。
一、概述
學習路徑推薦的主要研究范疇有三個方面。一是學習者建模,涉及學習者能力水平、心理狀態、風格興趣[4]等的特征化問題和提取方法;二是學習對象建模,涉及發掘學習推薦對象與學習者個性化參數的關聯信息;三是推薦算法設計,涉及學習者與對象之間策略選擇與最優匹配問題。根據相關研究[2-3],個性化學習路徑推薦問題的數學描述形式如下。給定學習目標g,學習目標相關的知識點kp,學習資源r=(kp1,kp2,…,tp,s),s.t.kpi+1=f(kpi),r是由知識點kp組成的有序向量,這里tp∈{文本,圖片,視頻}代表r的類型,s∈{課程,章節,知識單元,知識點}代表與目標g的層次相關的r的粒度,f(·)是一個轉換函數,表示知識點kpi為kpi+1的先修學習資源。一般采用向量e描述每個學習者的先驗特征,特征向量一般作為各類推薦算法的初始輸入值。學習路徑表示為pn,且有pnt={et,rt},其中e和r分別表示t時間對應的學習者狀態特征和學習資源集合。因此,學習路徑Lp是一條由pn結點組成的、以g為目標的、與指定學習者相關的有序序列,Lp={pn0,pn1,…pnt,…,pnm|pnt=f(pnt+1),g=f(Lp)}。
個性化學習的主流學習框架包括基于機器學習的,基于進化計算的,基于知識圖譜的三種。機器學習框架將路徑推薦轉換為預測問題,分為監督和無監督兩種。進化計算一般采用遺傳算法、蟻群算法等解決路徑搜索問題,目前群體計算和群體智能是其重點研究方向[5]。知識圖譜是基于知識工程和本體論方法,在構建領域圖譜的基礎上運用帶約束條件的路徑搜索方法找出最佳推薦路徑。隨著AlphaGo在2016年戰勝圍棋世界冠軍,強化學習成為當前機器學習的一個研究熱點并逐漸演化成一個熱門分支,其后的升級版本AlphaGo zero,基于深度強化學習框架,在世界圍棋大賽和游戲競技大賽中繼續完勝人類選手。強化學習特別適于解決序列決策優化問題,在個性化學習路徑推薦方面能取得較好效果[6-7]。
二、模型描述
強化學習是將學習者作為智能體,通過不斷“試錯”引導其自主化學習。經典的學習模型基于馬爾可夫決策過程,學習者不斷學習新的知識點,然后利用獲得的獎賞來指導學習行為是否適合,從而最大化累計獎賞以實現特定目標。這一過程可用5元組(S,A,P,R,γ)進行簡單描述,其中S為有限的狀態集,A為有限的動作集,P為狀態轉移概率,R為回報函數,γ為用來計算累計回報的折扣因子。策略π是狀態S到動作A的映射,策略π為每個狀態s指定一個動作概率π(a|s)=p(At=a|St=s)。強化學習的目標就是為學習者發現一個最優策略π*,使得學習者獲得的期望折扣獎勵之和最大化,也即:
Vπ(s)=∑aπ(s,a)[R(s,a)+γ∑s′Pr(s′|s,a)Vπ(s′)]
(1)
公式1當中R(s,a)+γ∑s′Pr(s′|s,a)Vπ(s′)代表在當前s狀態下提供每一個可能決策的累計未來獎勵。學習者在當前狀態下通過“試錯”的方式選擇動作,按照這種狀態→動作→回報的順序循環,最后達到學習者指定目標收益最大化。
用戶反饋。對于一個學習者,假定某個時刻t模型根據前序狀態選取當前轉換的狀態為s,用戶可對此狀態給予一個正面和負面的標簽l+,l-,則對于所有狀態序列S,有:
(2)
進一步對公式1和公式2進行整合,形成基于用戶反饋的參數化策略最優框架:
Gη(C,V)=η·T(θ,V)-(1-η)·L(θ,C)
(3)
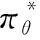
(4)
其中Rl表示學習者l計算到的某次學習路徑。
(5)
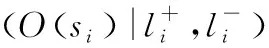
三、實驗分析
(一)數據來源
本文面向計算機專業課程學生學習的過程數據和考核數據進行測試。《移動應用開發》面向計算機和物聯網工程本科學生講授基于Android的程序開發,課程已在2014年開始在超星數據平臺(www.chaoxing.com)開設線上教學,至今近10年,形成了內容豐富、形式多樣、組織科學的教學資源庫(參見表1),累積了近1000名學生線上線下學生情況。由于本專業的學生來源有第一志愿高考錄用、其他非工科專業調劑,專升本等情況,因此學生的學習能力與興趣差異較大。為此,本課程很早開展了人才培養方案的改革創新,將培養目標設定為中階和高階兩個設定為多目標要求,中階目標的核心要求是能夠自主設計移動APP的界面并實現交互,高階目標則要求能面向特定場景需要獨立設計和開發具有完整功能的移動APP。課程PPT、視頻、試題集等均按此分成兩類,即每一類具有閉環的知識學習與能力評估體系。

表1 實驗所用數據來源
為確保有效性,本實驗從線上空間篩選抽取活躍度強、互動性高的學生,根據中階和高階不同目標等級分別設置兩組學生集。目標測試數來源于期末試卷庫,每套試卷對應1個目標測試數。課程自主錄制教學短視頻集,其中中階的74個涵蓋87個知識點,高階的132個涵蓋144個知識點,為輔助學生更好地理解知識點,從互聯網收集知識點相關的學習資料,其中中階32個,高階51個,每個學習資料對應一個PDF文檔。每位學生在測試過程中對選取的知識點進行正反評價,因此反饋標簽數=學生數×知識點×2。
(二)實驗測試集
考慮學生在知識學習與測試考核的不可重復性,實際測試的每個數據集進一步分離成測試數據集。以表1當中的中階1為例,145名學生經自愿后隨機分成三個類,分別包含25名、60名、60名學生,同時衍生出M-1-Normal、M-1-NoTagged、M-1-Tagged共3個測試集,M-1-Normal表示對第一類25名學生按教師預設的學習路徑進行學習,即未采用強化學習進行個性化學習路徑推薦;M-1-NoTagged表示對第二類60名學生,采用本文強化學習框架在不整合反饋標簽條件下進行路徑選擇計算;M-1-Tagged表示對第三類60名學生,采用本文強化學習框架在不整合反饋標簽條件下進行路徑選擇計算。按同樣的方式,實驗對其他5個數據集進行分類測試。實驗分別以學生平時作業和期末考核的分數作為評價標準。
(三)結果與分析
表2展示了4×3共12個測試集的結果。

表2 中階目標測試結果
(四)結果分析
表2的測試結果說明,強化學習能明顯增強學習路徑推薦的有效性,通過強化學習后,學習者的平均成績和期末考核均有顯著提升,在整合反饋標簽后,學習路徑推薦的效果進一步得到提升,測試集1分別提升平時成績分別提升3.3分和5.9分,期末考核分別提升4.2分和4.7分。測試集2在三個算法上的表現與測試集1類似。表3展示了高階目標測試結果情況。表3當中的3個算法的結果與表2類似,同時注意到,表3中基于反饋的強化學習路徑推薦算法的效果約為8~9分,高于測試集1的提升效果6分和3.5分,效果相差很大,這說明強化學習在高階目標環境下效果更強,分析認為,高階目標具有更多的知識點和補充學習資料,同樣的,基于標簽反饋的算法給出大量學習者評價標簽,用于指導策略函數找到折扣獎勵最大的路徑,由此證明了本算法的有效性。

表3 高階目標測試結果
結語
強化學習模仿智能體反復“試錯”的學習方式達到自主學習目的,特別適于解決序列優化問題,本文基于強化學習框架提出了一種基于標簽反饋的策略優化算法,在策略尋優過程中加入學習者對當前狀態轉換的標簽評價,指導和提高強化學習參數優化性能。實驗采集計算機專業課程線上教學與考核數據,對比非強化學習、強化學習和本文提出的算法,實驗結果證明了本文算法的有效性,下一步將標簽反饋運用到其他強化學習優化策略。
猜你喜歡
作文大王·笑話大王(2021年4期)2021-04-26 19:00:35
英語文摘(2020年9期)2020-11-26 08:10:12
甘肅教育(2020年6期)2020-09-11 07:45:16
甘肅教育(2020年22期)2020-04-13 08:10:54
甘肅教育(2020年20期)2020-04-13 08:04:42
當代陜西(2019年5期)2019-11-17 04:27:32
電影(2018年9期)2018-11-14 06:57:21
作文世界(小學版)(2018年4期)2018-10-16 17:13:34
快樂作文·低年級(2016年12期)2017-01-03 20:52:44
快樂作文·低年級(2016年6期)2016-06-24 18:58:40
