基于存算分離構(gòu)架消息隊(duì)列的性能預(yù)測(cè)模型
2024-02-19 00:00:00王娟
中國(guó)新通信 2024年23期

摘要:存算分離架構(gòu)的消息隊(duì)列被廣泛應(yīng)用于運(yùn)營(yíng)商的核心計(jì)費(fèi)業(yè)務(wù)場(chǎng)景,其對(duì)消息隊(duì)列的穩(wěn)定性要求極高,對(duì)異常的容忍度非常低。因此,快速識(shí)別、定位消息隊(duì)列的性能異常并及時(shí)止損就變得愈發(fā)重要。針對(duì)消息隊(duì)列性能異常的問(wèn)題,傳統(tǒng)的方式是根據(jù)消息隊(duì)列集群指標(biāo)設(shè)定告警閾值。此方式依賴專家進(jìn)行規(guī)則配置,無(wú)法根據(jù)不同的集群規(guī)模和業(yè)務(wù)場(chǎng)景靈活、動(dòng)態(tài)地調(diào)整規(guī)則或閾值,也無(wú)法預(yù)測(cè)消息隊(duì)列的性能發(fā)展趨勢(shì),因此,極易造成重大故障。基于 AI 的消息隊(duì)列性能預(yù)測(cè)能力,可以基于消息隊(duì)列的歷史表現(xiàn)情況,對(duì)關(guān)鍵指標(biāo)進(jìn)行7×24小時(shí)巡檢,能夠在性能異常尚在萌芽狀態(tài)就發(fā)現(xiàn)風(fēng)險(xiǎn),實(shí)現(xiàn)性能異常的提前暴露。當(dāng)消息隊(duì)列性能偏離正常范圍時(shí),能夠及時(shí)發(fā)出警報(bào),輔助運(yùn)維人員在問(wèn)題惡化前進(jìn)行準(zhǔn)確定位并及時(shí)止損。同時(shí),根據(jù)性能預(yù)測(cè)結(jié)果可以對(duì)資源進(jìn)行合理規(guī)劃,有效地治理集群,找出性能瓶頸,有針對(duì)性地進(jìn)行性能優(yōu)化。本文利用 AI 算法,設(shè)計(jì)了基于存算分離構(gòu)架消息隊(duì)列的性能預(yù)測(cè)模型,能夠在消息隊(duì)列集群正常運(yùn)行狀態(tài)下,對(duì)未來(lái)一段時(shí)間內(nèi)的性能做出較為準(zhǔn)確的預(yù)測(cè),從而有效預(yù)防未來(lái)可能出現(xiàn)的性能問(wèn)題。
關(guān)鍵詞:存算分離;消息隊(duì)列;性能預(yù)測(cè);治理集群;性能優(yōu)化
一、 引言
運(yùn)營(yíng)商計(jì)費(fèi)系統(tǒng)由預(yù)處理、分揀、批價(jià)、扣款、入庫(kù)等多個(gè)模塊組成。各模塊之間的數(shù)據(jù)以話單文件為單位在 NAS 盤上傳輸,模塊之間的耦合度較高。隨著 5G 網(wǎng)絡(luò)的普及、話單量的迅速增長(zhǎng)和業(yè)務(wù)場(chǎng)景的日趨復(fù)雜,對(duì)共享文件存儲(chǔ)的依賴性日益提高,導(dǎo)致NAS 逐漸出現(xiàn) I/O 瓶頸,使得計(jì)費(fèi)系統(tǒng)無(wú)法線性擴(kuò)展。為解決以上問(wèn)題,通過(guò)引入消息隊(duì)列對(duì)計(jì)費(fèi)系統(tǒng)模塊進(jìn)行解耦,以期提升系統(tǒng)性能和擴(kuò)展性。在云原生和 Serverless 時(shí)代,存算分離架構(gòu)的消息隊(duì)列能夠支持按照流量和存儲(chǔ)進(jìn)行獨(dú)立的線性擴(kuò)展。本文以云原生消息隊(duì)列為代表,介紹了對(duì)消息隊(duì)列進(jìn)行性能預(yù)測(cè)的意義,具體包括:
(一)資源優(yōu)化和成本效益
通過(guò)性能預(yù)測(cè),可以準(zhǔn)確評(píng)估云原生消息隊(duì)列在不同業(yè)務(wù)場(chǎng)景負(fù)載下的資源需求,幫助用戶合理配置和調(diào)整資源,避免不必要的成本浪費(fèi)。
(二)可伸縮性
通過(guò)性能預(yù)測(cè),用戶可以了解云原生消息隊(duì)列在不同規(guī)模和負(fù)載下的表現(xiàn),以便根據(jù)業(yè)務(wù)需求進(jìn)行流量和存儲(chǔ)空間的動(dòng)態(tài)擴(kuò)/縮容,確保系統(tǒng)能夠靈活應(yīng)對(duì)負(fù)載變化。
(三)性能優(yōu)化和調(diào)優(yōu)
性能預(yù)測(cè)可以幫助識(shí)別云原生消息隊(duì)列系統(tǒng)中的性能瓶頸和潛在問(wèn)題,指導(dǎo)用戶進(jìn)行性能優(yōu)化和調(diào)優(yōu)工作。針對(duì)特定的工作負(fù)載和場(chǎng)景,可以調(diào)整系統(tǒng)參數(shù)、配置和算法,提高系統(tǒng)的性能和效率。
(四)容量規(guī)劃和資源利用
云原生環(huán)境中的資源是有限的。通過(guò)性能預(yù)測(cè),用戶可以更好地規(guī)劃云原生消息隊(duì)列的容量,合理利用云資源,確保系統(tǒng)能夠滿足業(yè)務(wù)增長(zhǎng)的需求。
(五)自動(dòng)化和智能運(yùn)維
性能預(yù)測(cè)可以為自動(dòng)化的資源調(diào)配、彈性擴(kuò)/縮容等操作提供數(shù)據(jù)支持,實(shí)現(xiàn)更智能的系統(tǒng)運(yùn)維。
(六)應(yīng)用性能保障
無(wú)論是在云原生環(huán)境還是 Serverless 架構(gòu)中,應(yīng)用的性能對(duì)于用戶體驗(yàn)和業(yè)務(wù)開(kāi)展至關(guān)重要。因此,性能預(yù)測(cè)是實(shí)現(xiàn)高效、可靠和可擴(kuò)展的云原生應(yīng)用的關(guān)鍵手段之一。
本文以計(jì)費(fèi)業(yè)務(wù)系統(tǒng)目前使用的云原生消息隊(duì)列為研究對(duì)象,基于歷史表現(xiàn)情況,利用AI 算法對(duì)關(guān)鍵指標(biāo)進(jìn)行分析預(yù)測(cè),并根據(jù)預(yù)測(cè)結(jié)果,實(shí)現(xiàn)優(yōu)化資源利用、確保可伸縮性、進(jìn)行性能優(yōu)化、規(guī)劃容量、實(shí)現(xiàn)智能運(yùn)維、保障應(yīng)用性能等目標(biāo)。
二、 建模思路
(一)模型介紹
性能預(yù)測(cè)模型歸屬于時(shí)間序列預(yù)測(cè)模型。該預(yù)測(cè)模型通過(guò)編制和分析時(shí)間序列,以時(shí)間序列所反映的發(fā)展過(guò)程、方向和趨勢(shì)為基礎(chǔ),類推或延伸下一段時(shí)間可能達(dá)到的水平。根據(jù)實(shí)際應(yīng)用場(chǎng)景,通過(guò)對(duì)數(shù)據(jù)周期性、季節(jié)性、不規(guī)則性的分析以及對(duì)業(yè)務(wù)背景的了解,本方案采用線性回歸模型對(duì)消息隊(duì)列集群過(guò)去7天的5分鐘顆粒度指標(biāo)進(jìn)行分析,輸出未來(lái)一天的預(yù)測(cè)結(jié)果。
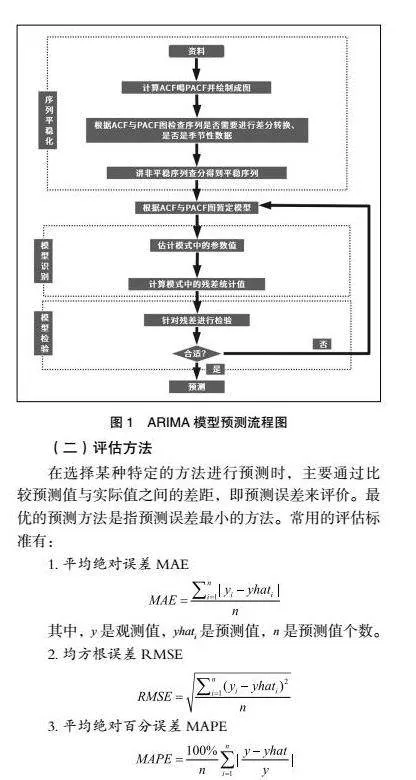
本文采用ARIMA模型對(duì)未來(lái)一段時(shí)間內(nèi)的性能指標(biāo)進(jìn)行預(yù)測(cè)。結(jié)合了自回歸(AR)機(jī)制、移動(dòng)平均(MA)策略與差分(I)技術(shù),通過(guò)差分處理使原始的非平穩(wěn)時(shí)間序列數(shù)據(jù)得以轉(zhuǎn)化為平穩(wěn)形態(tài),推導(dǎo)出差分自回歸移動(dòng)平均模型ARIMA(p,d,q),括號(hào)內(nèi)d表示對(duì)數(shù)據(jù)進(jìn)行差分處理的階數(shù)。ARIMA模型預(yù)測(cè)流程圖如圖1。
自回歸模型(AR)是一種時(shí)間序列分析工具,它揭示當(dāng)前值與歷史值之間的關(guān)聯(lián)性,通過(guò)變量本身的歷史數(shù)據(jù)來(lái)預(yù)測(cè)其未來(lái)的趨勢(shì)。此模型的應(yīng)用基于一個(gè)核心前提:時(shí)間序列數(shù)據(jù)需滿足平穩(wěn)性條件。
回歸模型(AR)在構(gòu)建時(shí),首先需要確定一個(gè)關(guān)鍵參數(shù)—階數(shù)p。這個(gè)階數(shù)p代表了我們?cè)陬A(yù)測(cè)當(dāng)前值時(shí),將回溯并使用多少期的歷史數(shù)據(jù)。p階自回歸模型的公式定義為:
自回歸模型在應(yīng)用時(shí)確實(shí)面臨一些局限性和前提條件:
1、自我預(yù)測(cè)特性:自回歸模型主要依賴變量自身的歷史數(shù)據(jù)來(lái)進(jìn)行預(yù)測(cè)。這種自我預(yù)測(cè)的方式雖然簡(jiǎn)潔,但可能限制了模型捕捉外部影響因素的能力。
2、平穩(wěn)性要求:為了確保預(yù)測(cè)的準(zhǔn)確性,時(shí)間序列數(shù)據(jù)必須滿足平穩(wěn)性的條件。這意味著數(shù)據(jù)的統(tǒng)計(jì)特性(如均值、方差)在時(shí)間上是恒定的。如果數(shù)據(jù)呈現(xiàn)非平穩(wěn)性,自回歸模型的預(yù)測(cè)效果可能會(huì)大打折扣。
3、適用范圍限制:自回歸模型最適合用于預(yù)測(cè)那些與自身前期緊密相關(guān)的現(xiàn)象。對(duì)于受到外部隨機(jī)因素或復(fù)雜系統(tǒng)動(dòng)態(tài)影響的時(shí)間序列,自回歸模型可能無(wú)法提供準(zhǔn)確的預(yù)測(cè)。此外,它也不適用于具有長(zhǎng)期記憶性或非線性特征的數(shù)據(jù)。
(二)評(píng)估方法
在選擇某種特定的方法進(jìn)行預(yù)測(cè)時(shí),主要通過(guò)比較預(yù)測(cè)值與實(shí)際值之間的差距,即預(yù)測(cè)誤差來(lái)評(píng)價(jià)。最優(yōu)的預(yù)測(cè)方法是指預(yù)測(cè)誤差最小的方法。常用的評(píng)估標(biāo)準(zhǔn)有:
1.平均絕對(duì)誤差MAE
其中,y是觀測(cè)值,yhati是預(yù)測(cè)值,n是預(yù)測(cè)值個(gè)數(shù)。
2.均方根誤差RMSE
3.平均絕對(duì)百分誤差MAPE
基于本項(xiàng)目的應(yīng)用場(chǎng)景,時(shí)間序列算法的數(shù)值預(yù)測(cè)均適用于以上三種評(píng)估方法,其中,MAE最為常用;MAPE比較好理解,且MAPE通過(guò)轉(zhuǎn)換即可得到平均準(zhǔn)確率,因此,本文后續(xù)將以MAPE為基礎(chǔ),通過(guò)準(zhǔn)確率來(lái)進(jìn)行模型評(píng)估。
(三)模型思路
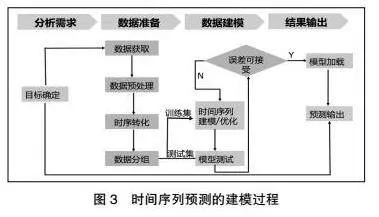
首先,分析消息隊(duì)列各指標(biāo)的數(shù)據(jù)波動(dòng)情況,確定使用機(jī)器學(xué)習(xí)的方式進(jìn)行預(yù)測(cè)。
其次,針對(duì)使用機(jī)器學(xué)習(xí)方式預(yù)測(cè)的指標(biāo),根據(jù)歷史數(shù)據(jù)特征確定時(shí)序模型,并對(duì)數(shù)據(jù)進(jìn)行平穩(wěn)性檢驗(yàn)和白噪聲檢驗(yàn),以保證數(shù)據(jù)符合時(shí)序預(yù)測(cè)標(biāo)準(zhǔn)。
最后,利用訓(xùn)練集樣本構(gòu)建合適的時(shí)間序列預(yù)測(cè)模型,輸出未來(lái)天數(shù)的指標(biāo)預(yù)測(cè)值,并通過(guò)測(cè)試樣本對(duì)模型效果進(jìn)行評(píng)估。
三、 建模過(guò)程
(一)樣本數(shù)據(jù)準(zhǔn)備
用于預(yù)測(cè)消息隊(duì)列性能的指標(biāo)數(shù)據(jù)取2024-01-24到2024-01-30的數(shù)據(jù)為訓(xùn)練集,之后的數(shù)據(jù)為測(cè)試集。
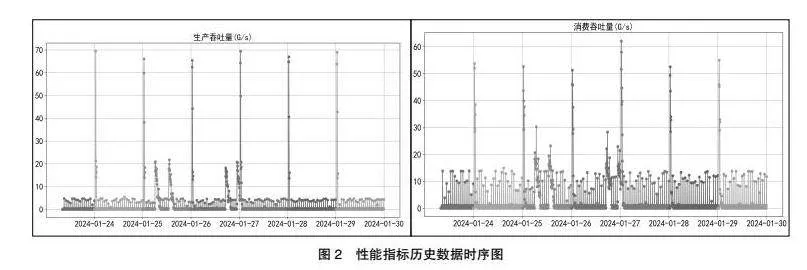
(二)數(shù)據(jù)描述性分析
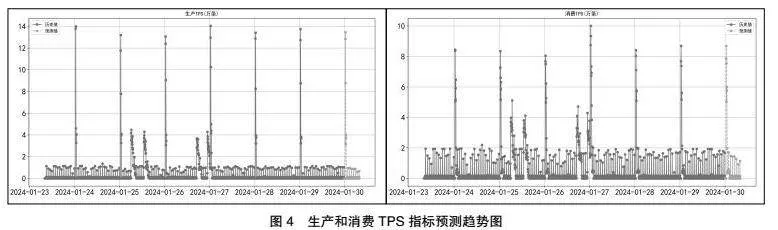
圖2為消息隊(duì)列各指標(biāo)2024-01-24到2024-01-30的歷史數(shù)據(jù)的指標(biāo)分布圖。運(yùn)營(yíng)商的業(yè)務(wù)分為忙時(shí)和閑時(shí)。通常情況下,白天忙時(shí)是網(wǎng)絡(luò)繁忙的時(shí)間段,這時(shí)候通過(guò)手機(jī)上網(wǎng)的人群比較多,屬于上網(wǎng)高峰時(shí)間段;晚上閑時(shí)是上網(wǎng)低峰時(shí)段。從圖2可以看出,數(shù)據(jù)變化主要呈現(xiàn)周期性狀態(tài)。
(三)數(shù)據(jù)預(yù)處理
1.缺失值處理
時(shí)間序列預(yù)測(cè)需要保證數(shù)據(jù)無(wú)缺失。雖然目前所獲數(shù)據(jù)中均無(wú)缺失值,但算法流程中仍需配備缺失值處理機(jī)制。對(duì)于少量的隨機(jī)缺失數(shù)據(jù),可采用線性插值的方式進(jìn)行填充。這種方式對(duì)時(shí)序數(shù)據(jù)的原始規(guī)律性影響較小。
2.異常值處理
基于對(duì)應(yīng)用場(chǎng)景的了解,性能指標(biāo)數(shù)據(jù)理論應(yīng)該大于等于0,對(duì)于小于0的數(shù)據(jù),應(yīng)將其刪除后采用線性插值的方式進(jìn)行填充。
3.平穩(wěn)性檢驗(yàn)
時(shí)間序列通過(guò)分析隨機(jī)變量的歷史與當(dāng)前狀態(tài)預(yù)測(cè)未來(lái)。假定這些變量狀態(tài)具代表性且可延續(xù),其核心特征(如均值、方差、協(xié)方差)在未來(lái)應(yīng)保持穩(wěn)定,即平穩(wěn)性。實(shí)踐中,平穩(wěn)性檢驗(yàn)多基于樣本值的統(tǒng)計(jì)特征分析,常用方法分為主觀圖形判斷和客觀統(tǒng)計(jì)檢驗(yàn)。本場(chǎng)景采用客觀檢驗(yàn)中的單位根檢驗(yàn),若顯著性水平小于0.05,則認(rèn)為數(shù)據(jù)平穩(wěn)。
4.白噪聲檢驗(yàn)
如果一個(gè)時(shí)間序列是平穩(wěn)的,接下來(lái)就要判斷數(shù)據(jù)是不是白噪聲。白噪聲表示數(shù)據(jù)為隨機(jī)性數(shù)據(jù),沒(méi)有研究意義。通常可以通過(guò)LB檢驗(yàn)來(lái)檢驗(yàn)時(shí)間序列是否為白噪聲。若LB檢驗(yàn)的p值小于0.05,則認(rèn)為樣本時(shí)間序列數(shù)據(jù)非白噪聲。
綜上所述,消息隊(duì)列各性能指標(biāo)均滿足平穩(wěn)性檢驗(yàn),且為非白噪聲序列。
(四)建模構(gòu)建
四、 模型評(píng)估
(一)模型效果
5個(gè)消息隊(duì)列性能指標(biāo)均使用日數(shù)據(jù)進(jìn)行預(yù)測(cè)。可以看出,隨著歷史數(shù)據(jù)的累計(jì),性能指標(biāo)預(yù)測(cè)的準(zhǔn)確率也在逐步提升。根據(jù)模型評(píng)估結(jié)果,整體準(zhǔn)確率在90%左右,還有優(yōu)化空間。目前性能指標(biāo)數(shù)據(jù)累計(jì)時(shí)間較短,待數(shù)據(jù)不斷累計(jì)之后,同時(shí)結(jié)合業(yè)務(wù)角度分析影響各指標(biāo)值波動(dòng)的關(guān)鍵因素,則可挖掘出更多的數(shù)據(jù)規(guī)律,通過(guò)構(gòu)建更復(fù)雜的模型來(lái)提升預(yù)測(cè)準(zhǔn)確率。
(二)性能預(yù)測(cè)應(yīng)用
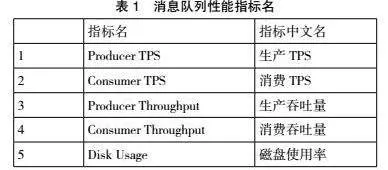
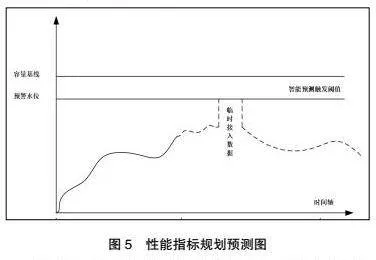
基于消息隊(duì)列的性能指標(biāo)預(yù)測(cè),方便用戶分析當(dāng)前集群的性能和穩(wěn)定性,能夠更好地治理集群。本模型允許用戶針對(duì)生產(chǎn) TPS、消費(fèi) TPS、生產(chǎn)吞吐量、消費(fèi)吞吐量和磁盤使用率創(chuàng)建容量規(guī)劃項(xiàng),支持用戶對(duì)每個(gè)容量規(guī)劃項(xiàng)設(shè)置上限和預(yù)警水位。
用戶可以配置容量規(guī)劃任務(wù),實(shí)現(xiàn)對(duì)特定集群的容量管理和預(yù)測(cè)告警,從而提前感知用量增長(zhǎng)趨勢(shì),提前規(guī)劃資源,從容應(yīng)對(duì)擴(kuò)/縮容操作。
在一些特殊情況下,用戶需要進(jìn)行臨時(shí)業(yè)務(wù)規(guī)劃,這部分性能指標(biāo)難以預(yù)測(cè)。容量規(guī)劃支持手動(dòng)操作功能,幫助用戶調(diào)整預(yù)測(cè)曲線。
基于存算分離架構(gòu),可實(shí)時(shí)分析集群性能預(yù)測(cè)的指標(biāo)。當(dāng)磁盤使用率出現(xiàn)瓶頸時(shí),通過(guò)增加磁盤或云存儲(chǔ)空間應(yīng)對(duì)數(shù)據(jù)存儲(chǔ)的壓力。當(dāng)網(wǎng)絡(luò)使用率出現(xiàn)瓶頸時(shí),通過(guò)增加主機(jī)應(yīng)對(duì)網(wǎng)絡(luò)傳輸?shù)膲毫Α?/p>
五、 結(jié)束語(yǔ)
本文針對(duì)消息隊(duì)列性能預(yù)測(cè)進(jìn)行了深入研究。通過(guò)分析和實(shí)驗(yàn),得出了以下結(jié)論:本文提出的一種基于機(jī)器學(xué)習(xí)的消息隊(duì)列性能預(yù)測(cè)方法,能夠準(zhǔn)確預(yù)測(cè)消息隊(duì)列的性能指標(biāo)。通過(guò)實(shí)驗(yàn)驗(yàn)證,本文提出的方法在不同場(chǎng)景下具有較高的準(zhǔn)確性和泛化能力。本文的研究為消息隊(duì)列的性能優(yōu)化和資源規(guī)劃提供了有價(jià)值的參考。當(dāng)然,本文的研究還存在一些局限性,未來(lái)的研究可以從以下幾個(gè)方面進(jìn)行深入探討:進(jìn)一步提高預(yù)測(cè)模型的準(zhǔn)確性和泛化能力,以適應(yīng)更多、更復(fù)雜的實(shí)際場(chǎng)景;探索其他影響消息隊(duì)列性能的因素,并將其納入預(yù)測(cè)模型中;結(jié)合實(shí)際應(yīng)用需求,開(kāi)發(fā)更加實(shí)用的性能預(yù)測(cè)工具和系統(tǒng)。希望本文的研究能夠?yàn)橄㈥?duì)列性能預(yù)測(cè)領(lǐng)域的發(fā)展作出貢獻(xiàn),并為相關(guān)實(shí)踐提供有益的指導(dǎo)。
作者單位:王娟 中國(guó)移動(dòng)通信集團(tuán)江蘇有限公司
參考文獻(xiàn)
[1] 陳虹.模型預(yù)測(cè)控制[M].北京:科學(xué)出版社,2013.
[2] 席裕庚.預(yù)測(cè)控制(第 2 版)[M].國(guó)防工業(yè)出版社,2013.
[3] 冉小慶.Oracle 性能分析與預(yù)測(cè)研究[D].大連:大連海事大學(xué),2003.
[4] 博克斯著,王成璋等譯.時(shí)間序列分析:預(yù)測(cè)與控制[M].機(jī)械工業(yè)出版社,2011.
[5] 張美英,何杰.時(shí)間序列預(yù)測(cè)模型研究綜述[J].數(shù)學(xué)的實(shí)踐與認(rèn)識(shí), 2011.41(18):189-195.
[6] 薛可,李增智,劉瀏,等.基于ARIMA模型的網(wǎng)絡(luò)流量預(yù)測(cè)[J].微電子學(xué)與計(jì)算機(jī),2004,21(07):84-87.

- 中國(guó)新通信的其它文章
- 現(xiàn)代信息技術(shù)和小學(xué)音樂(lè)教學(xué)的融合對(duì)策
- 基于云平臺(tái)的小學(xué)美術(shù)高效課堂教學(xué)實(shí)踐研究
- 基于移動(dòng)互聯(lián)平臺(tái)的高中化學(xué)教學(xué)實(shí)踐研究
- “互聯(lián)網(wǎng)+”視域下初中物理教學(xué)優(yōu)化策略研究
- 初中科學(xué)教學(xué)中數(shù)字化實(shí)驗(yàn)的實(shí)踐研究
- 教育信息化2.0背景下小學(xué)科學(xué)教學(xué)評(píng)一致性實(shí)踐研究