基于深度學(xué)習(xí)的農(nóng)產(chǎn)品物流配送中心選址決策優(yōu)化研究
2024-05-14 06:47:12武士文
市場(chǎng)周刊 2024年13期
武士文,奚 雷
(安徽科技學(xué)院,安徽 蚌埠 233000)
0 引言
中國(guó)作為一個(gè)農(nóng)業(yè)大國(guó),近些年人們對(duì)農(nóng)產(chǎn)品的消耗巨大,推動(dòng)了農(nóng)產(chǎn)品物流的快速發(fā)展,國(guó)內(nèi)農(nóng)產(chǎn)品物流市場(chǎng)規(guī)模已超過(guò)5億元[1]。但是,農(nóng)產(chǎn)品配送還存在成本過(guò)高、配送不及時(shí)等問(wèn)題,嚴(yán)重影響了消費(fèi)者的購(gòu)買體驗(yàn)。配送是農(nóng)產(chǎn)品物流的重要環(huán)節(jié),特別是一些冷鏈農(nóng)產(chǎn)品,從商戶轉(zhuǎn)移到消費(fèi)者手中占據(jù)了所需時(shí)間的80%以上。農(nóng)產(chǎn)品物流配送是指以最少的運(yùn)輸時(shí)間和成本將農(nóng)產(chǎn)品等運(yùn)送到不同地點(diǎn)的零售商或超市,配送過(guò)程作為農(nóng)產(chǎn)品物流的重要組成部分,不僅影響客戶服務(wù)水平,還影響物流運(yùn)營(yíng)成本和冷鏈產(chǎn)品質(zhì)量[2]。據(jù)報(bào)道,我國(guó)僅蔬菜、水果等農(nóng)產(chǎn)品在冷鏈運(yùn)輸過(guò)程中因缺乏高效的配送設(shè)計(jì)而造成的經(jīng)濟(jì)損失就超過(guò)千億元。因此,迫切需要綜合考慮農(nóng)產(chǎn)品的配送時(shí)間和建設(shè)總成本,優(yōu)化農(nóng)產(chǎn)品物流配送中心的選址,選取合適的農(nóng)產(chǎn)品物流配送中心地址尤為重要。
國(guó)內(nèi)外的學(xué)者針對(duì)農(nóng)產(chǎn)品物流配送問(wèn)題展開了許多研究。王勇等考慮生鮮商品配送時(shí)效性強(qiáng)的特點(diǎn),建立了生鮮商品配送成本和生鮮商品隨時(shí)間價(jià)值損失最小的雙目標(biāo)優(yōu)化模型[3]。朱亞婕研究了“互聯(lián)網(wǎng)+智慧生鮮”項(xiàng)目的位置選址問(wèn)題,采用了層次分析法確定配送中心的最佳位置[4]。徐超毅和劉濤考慮了在保證滿足客戶需求的同時(shí),構(gòu)建以總成本最小化為目標(biāo)的冷鏈配送中心選址模型,并采用了改進(jìn)的粒子群算法求解,降低了配送中心選址成本[5]。郜振華和朱興偉,以及張雪采用灰色關(guān)聯(lián)分析法,根據(jù)具體數(shù)據(jù),確定了農(nóng)產(chǎn)品冷鏈物流配送中心的評(píng)價(jià)指標(biāo)體系,得出最優(yōu)的選址決策[6-7]。盡管針對(duì)農(nóng)產(chǎn)品物流中心選址的問(wèn)題有了許多的研究,但是并沒(méi)有考慮到不同位置的農(nóng)產(chǎn)品需求的預(yù)測(cè)問(wèn)題,不能滿足實(shí)際需求。
深度學(xué)習(xí)是一種機(jī)器學(xué)習(xí)方法,指采用深度且復(fù)雜的人工神經(jīng)網(wǎng)絡(luò)從數(shù)據(jù)中提取模式和特征。深度學(xué)習(xí)方法為不同領(lǐng)域的研究問(wèn)題解決做出了重大貢獻(xiàn),在農(nóng)業(yè)管理中也有涉及[8]。李姣姣等利用深度學(xué)習(xí)優(yōu)化農(nóng)產(chǎn)品訂貨批量,控制庫(kù)存總成本[9]。左敏等利用神經(jīng)網(wǎng)絡(luò)模型預(yù)測(cè)農(nóng)產(chǎn)品的物流需求,提升了對(duì)農(nóng)產(chǎn)品物流需求的預(yù)測(cè)準(zhǔn)確性[10]。此外,深度學(xué)習(xí)在農(nóng)業(yè)食品中也有很廣泛的應(yīng)用[11]。可以發(fā)現(xiàn),當(dāng)前使用深度學(xué)習(xí)方法解決農(nóng)產(chǎn)品物流配送中心位置設(shè)施問(wèn)題還非常少。深度學(xué)習(xí)能夠以更高效、更準(zhǔn)確的方式促進(jìn)發(fā)展和應(yīng)用,解決農(nóng)產(chǎn)品物流配送問(wèn)題。
基于上述研究問(wèn)題,根據(jù)農(nóng)產(chǎn)品需求位置采用K-Means聚類算法預(yù)測(cè)農(nóng)產(chǎn)品物流配送中心的位置,再利用深度學(xué)習(xí)方法將不同的小區(qū)需求點(diǎn)歸屬于設(shè)定的配送中心,最大限度地減少農(nóng)產(chǎn)品配送成本和時(shí)間,最后基于仿真數(shù)據(jù),對(duì)研究區(qū)域的最優(yōu)農(nóng)產(chǎn)品配送中心位置進(jìn)行進(jìn)一步的分析探討。
1 問(wèn)題描述
1.1 問(wèn)題假設(shè)
農(nóng)產(chǎn)品物流配送中心選址問(wèn)題是對(duì)農(nóng)產(chǎn)品在配送點(diǎn)和需求點(diǎn)之間的合理需求進(jìn)行分配,以達(dá)到合理利用車輛與物資的目的。該問(wèn)題可描述為農(nóng)產(chǎn)品物流配送中心為多個(gè)需求點(diǎn)提供配送服務(wù),第一,要求配送中心點(diǎn)與需求點(diǎn)的距離最短;第二,如果給定多臺(tái)車輛,車輛如何分配給配送中心安排;第三,配送中心的車輛如何形成配送路線。圖1是農(nóng)產(chǎn)品物流配送示意圖,包括配送中心、需求點(diǎn)和車輛等參數(shù)。
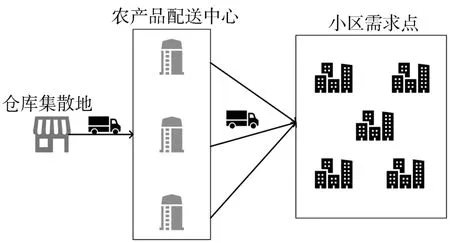
圖1 農(nóng)產(chǎn)品物流配送示意圖
配送中心選址優(yōu)化模型需要做以下幾點(diǎn)假設(shè):①小區(qū)需求點(diǎn)位置確定;②小區(qū)需求點(diǎn)和配送中心之間距離能夠計(jì)算;③已有的配送中心的位置確定;④每輛車承載能力有限,并且每輛車開始和結(jié)束都在同一配送中心,同時(shí)完成交付送貨的需求點(diǎn),每個(gè)需求點(diǎn)只訪問(wèn)一次,物品的分配路線是不確定的;⑤車輛勻速前進(jìn)運(yùn)輸。
1.2 農(nóng)產(chǎn)品物流配送中心選址模型
農(nóng)產(chǎn)品物流配送中心選址需要考慮降低配送中心建設(shè)成本,以及減少配送距離,以降低農(nóng)產(chǎn)品配送成本。此外,小區(qū)需求點(diǎn)的農(nóng)產(chǎn)品需求量不應(yīng)超過(guò)配送中心物資總量,在滿足農(nóng)產(chǎn)品需求的情況下盡可能降低配送成本。(表1)
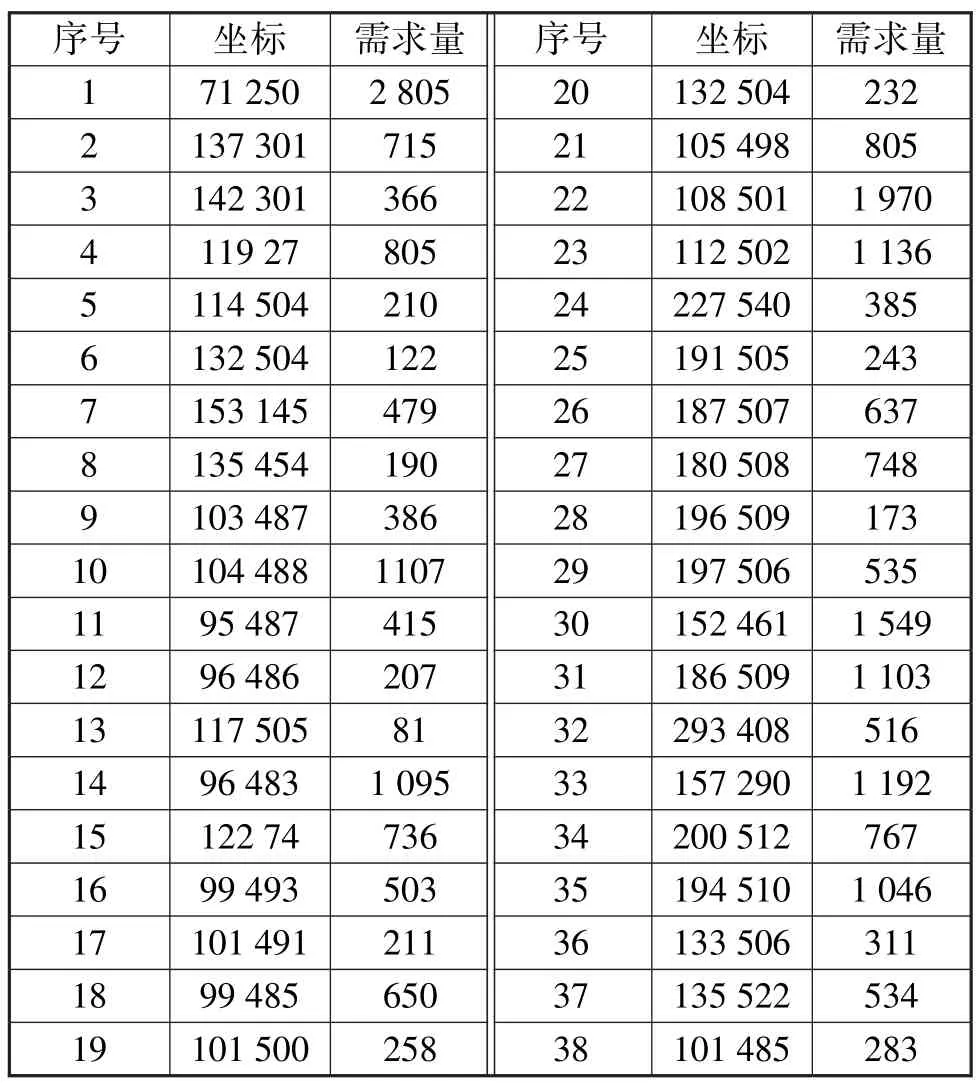
表1 需求點(diǎn)數(shù)據(jù)情況
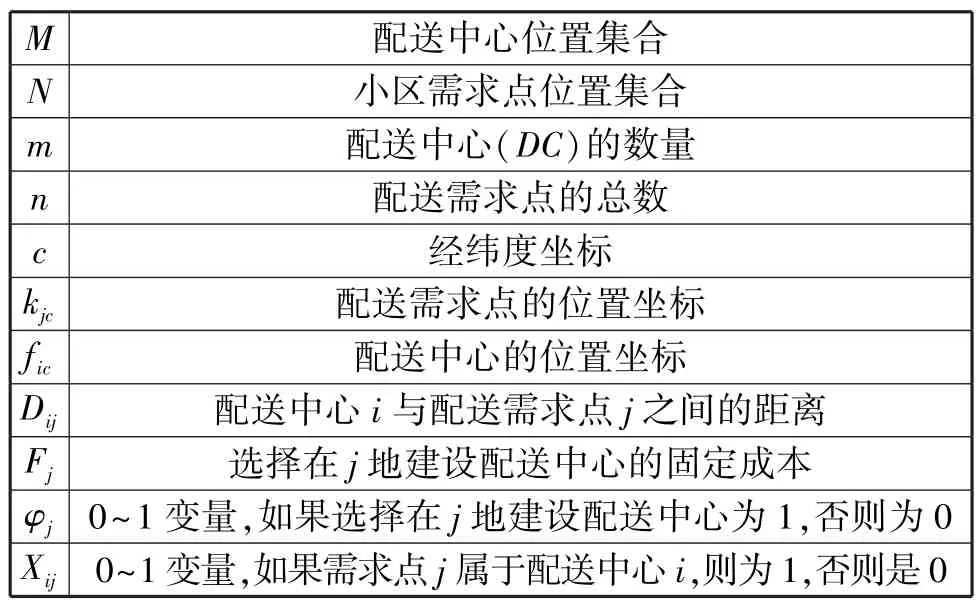
表1 模型參數(shù)變量及公式
城市農(nóng)產(chǎn)品物流配送中心選址模型第一個(gè)目標(biāo)是考慮配送中心與需求點(diǎn)之間的最短距離,具體模型如下:
公式(1)~公式(2)是目標(biāo)函數(shù),前者是最小化配送中心i與需求點(diǎn)j集合之間的距離,后者是最小化配送中心建設(shè)成本,公式(3)~公式(5)是模型的約束條件,約束(3)是確保所有需求點(diǎn)j與配送中心i位于同一簇組中。約束(4)根據(jù)歐幾里得距離公式計(jì)算配送中心i與需求點(diǎn)j之間的距離,而約束(5)表示二元決策變量。
1.3 選址模型求解
深度學(xué)習(xí)方法確定選址配送路徑優(yōu)化模型如圖2所示,存在不確定性參數(shù),即購(gòu)買農(nóng)產(chǎn)品的小區(qū)需求點(diǎn)。基于深度學(xué)習(xí)K-Means聚類算法,將根據(jù)相似的需求點(diǎn)分組,確定農(nóng)產(chǎn)品物流配送中心,然后再基于配送中心與小區(qū)需求點(diǎn)位置,通過(guò)機(jī)器學(xué)習(xí)算法預(yù)測(cè)最優(yōu)的配送路徑。
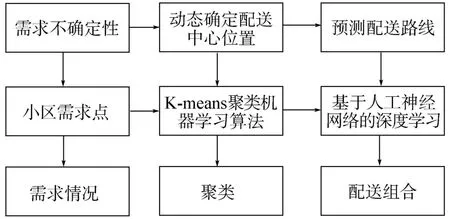
圖2 基于深度學(xué)習(xí)選址路徑優(yōu)化模型
圖3是小區(qū)需求點(diǎn)聚類分組的過(guò)程,首先要確定小區(qū)的坐標(biāo)位置,根據(jù)位置及小區(qū)人數(shù)劃定分組。
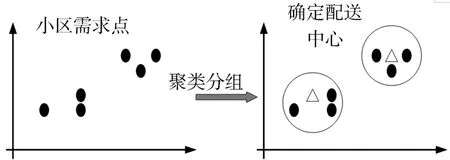
圖3 小區(qū)需求點(diǎn)聚類示意圖
在得到圖3中的分組結(jié)果后,下一步需要確定農(nóng)產(chǎn)品配送中心的位置,該配送中心可根據(jù)需求點(diǎn)的數(shù)量和位置而變化。為了實(shí)現(xiàn)最小距離的目標(biāo)函數(shù),配送中心根據(jù)完成聚類后的結(jié)果,選擇配送中心點(diǎn)的位置,然后根據(jù)最新的配送中心位置與數(shù)量對(duì)需求點(diǎn)分組。在獲取配送中心位置和需求點(diǎn)分組后,可生成最優(yōu)配送路線,該步驟將采用深度神經(jīng)網(wǎng)絡(luò)架構(gòu)的深度學(xué)習(xí)方法,考慮配送中心、車輛數(shù)量、需求點(diǎn)數(shù)量和需求數(shù)量等因素以確定最佳配送路線組合。圖4展示了配送中心選址聚類過(guò)程。
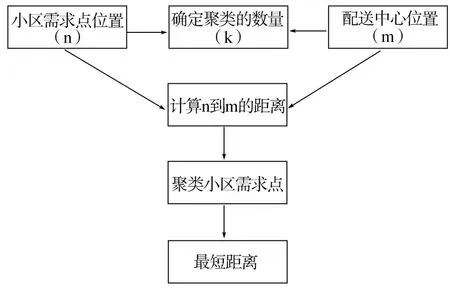
圖4 配送中心選址聚類過(guò)程
在生成配送路徑之前,圖4中的第一步是使用深度學(xué)習(xí)聚類算法確定建設(shè)配送中心的位置點(diǎn),并根據(jù)配送中心和分配的車輛對(duì)需求點(diǎn)進(jìn)行分組。配送中心的位置是根據(jù)配送需求點(diǎn)的位置動(dòng)態(tài)確定的,然后利用配送中心的位置信息生成配送路徑,確定配送中心位置后,采用人工神經(jīng)網(wǎng)絡(luò)用于創(chuàng)建從配送中心到配送需求點(diǎn)的物資配送路線網(wǎng)絡(luò)。輸入層由配送中心位置數(shù)據(jù)和一個(gè)集群中的需求點(diǎn)組成,隱藏層表示請(qǐng)求點(diǎn)位置的分布,輸出層顯示位置分布組合形成最優(yōu)路徑結(jié)果。
2 仿真模擬
物流配送中心選址問(wèn)題通常在多項(xiàng)式時(shí)間復(fù)雜度上被歸類為NP-hard問(wèn)題,因此,本文提出利用深度學(xué)習(xí)方法解決農(nóng)產(chǎn)品物流配送中心選址問(wèn)題,模型包括:①動(dòng)態(tài)選址模型,可以使用K-Means方法根據(jù)需求點(diǎn)的位置推薦設(shè)立配送中心的數(shù)量;②基于深度學(xué)習(xí)方法用于預(yù)測(cè)配送中心(DC)需求點(diǎn)位置。為了驗(yàn)證模型方法的有效性,下面結(jié)合模型設(shè)計(jì)了仿真案例。
2.1 數(shù)據(jù)準(zhǔn)備
以某城市的農(nóng)產(chǎn)品需求為例,其中包括38個(gè)小區(qū)需求點(diǎn),共25 516的農(nóng)產(chǎn)品物資需求量,表1給出了具體數(shù)據(jù)。
2.2 K-means聚類分析
K-means聚類算法是根據(jù)每個(gè)簇內(nèi)成員之間的相似性以及與其他簇中成員的不相似性,將一組n個(gè)對(duì)象劃分為K個(gè)簇。與簇的相似度是通過(guò)每個(gè)對(duì)象與簇平均值(稱為簇質(zhì)心)的接近程度來(lái)衡量的。K-means算法的核心概念是迭代搜索聚類中心,聚類中心是根據(jù)每個(gè)數(shù)據(jù)點(diǎn)與聚類中心之間的距離來(lái)確定的。聚類過(guò)程首先要?jiǎng)澐志垲惖臄?shù)據(jù),表示為Xij(i=1…n;j=1…m),其中n表示要聚類的數(shù)據(jù)點(diǎn)總數(shù),m表示聚類變量的數(shù)量。在迭代開始時(shí),每個(gè)簇的中心Ck(k=1…K)被獨(dú)立且能夠被任意分配。
接下來(lái),計(jì)算每個(gè)數(shù)據(jù)點(diǎn)和每個(gè)聚類中心之間的距離。一般使用歐幾里得公式用于計(jì)算第i個(gè)數(shù)據(jù)點(diǎn)和第K個(gè)聚類中心Ck之間的距離dik。如果數(shù)據(jù)點(diǎn)與簇中心之間的距離小于與其他簇中心的距離,則將該數(shù)據(jù)點(diǎn)指定為該簇的成員。將數(shù)據(jù)點(diǎn)分配到各自的簇后,下一步是將屬于每個(gè)簇的數(shù)據(jù)進(jìn)行分組。新的聚類中心值可以通過(guò)聚類成員的數(shù)據(jù)點(diǎn)的平均值計(jì)算確定。
在K均值聚類中,確定最佳組數(shù)K是一個(gè)重要的考慮因素,本文采用肘部法對(duì)聚類數(shù)K分析確定最佳聚類數(shù),以此得到最合適的配送中心數(shù)量,將其作為設(shè)定配送中心的潛在候選集群。肘部法是確定數(shù)量的常用方法,它利用總平方和(WSS)作為確定最佳K的標(biāo)準(zhǔn)。圖5是不同數(shù)量簇的距離平方和的聚類肘部示意圖,突出顯示了顯著彎曲或減小的點(diǎn)。該點(diǎn)表示配送中心設(shè)定應(yīng)考慮的最佳集群數(shù)量。圖5顯示當(dāng)K=3時(shí),在最小值附近類似彎頭的直線發(fā)生急劇變化,此時(shí)達(dá)到了最優(yōu)數(shù)量。
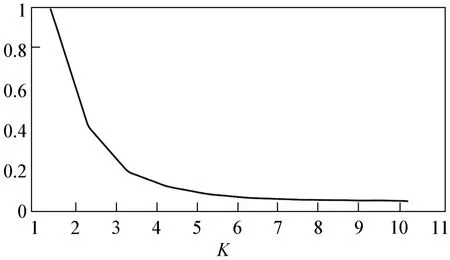
圖5 聚類肘部圖
根據(jù)前文給出的38個(gè)需求點(diǎn)的位置數(shù)據(jù),首先將收集小區(qū)需求點(diǎn)的坐標(biāo)作為K均值算法的輸入內(nèi)容,隨機(jī)選擇初始中心點(diǎn)代表需求點(diǎn)的分布,采用K-means算法計(jì)算每個(gè)需求點(diǎn)與初始中心點(diǎn)之間的距離。根據(jù)距離遠(yuǎn)近,每個(gè)點(diǎn)都被分配給距離它最近的簇組中。對(duì)每形成一個(gè)新簇組聚類,重復(fù)此過(guò)程。為了進(jìn)一步細(xì)化集群,利用其中兩個(gè)最遠(yuǎn)的需求點(diǎn)將每個(gè)現(xiàn)有集群一分為二,這將形成新的集群。通過(guò)1 000次優(yōu)化迭代后,算法確定了配送中心的最優(yōu)位置以及基于該中心的需求點(diǎn)分組。新聚類配送中心點(diǎn)的坐標(biāo)結(jié)果如表2所示。

表2 配送中心點(diǎn)位置及小區(qū)需求點(diǎn)聚類結(jié)果
采用深度學(xué)習(xí)預(yù)測(cè)配送中心位置、車輛需求、小區(qū)需求點(diǎn)分配,結(jié)果顯示配送中心1分配了4輛車,共需服務(wù)21個(gè)小區(qū)需求點(diǎn);配送中心2分配了2輛車,服務(wù)7個(gè)小區(qū)需求點(diǎn),配送中心3分配了4輛車,服務(wù)10個(gè)小區(qū)需求點(diǎn)。
3 結(jié)束語(yǔ)
農(nóng)產(chǎn)品配送中心位置預(yù)測(cè)模型利用深度學(xué)習(xí)方法和人工神經(jīng)網(wǎng)絡(luò)(ANN)算法,該模型使用實(shí)際小區(qū)需求位置模型生成的數(shù)據(jù)進(jìn)行訓(xùn)練,該模型包括三個(gè)開放配送中心和38個(gè)需求點(diǎn)。其目的是根據(jù)新開通的需求點(diǎn)的地理坐標(biāo)來(lái)預(yù)測(cè)指定的配送中心的位置。通過(guò)將這些新的需求點(diǎn)的坐標(biāo)輸入模型中,可以準(zhǔn)確預(yù)測(cè)所分配的配送中心的對(duì)應(yīng)位置。這種預(yù)測(cè)能力有助于在城市農(nóng)產(chǎn)品物流配送規(guī)劃中做出高效且有效的決策。模型訓(xùn)練結(jié)果在50次迭代后達(dá)到了96.15%的準(zhǔn)確率。高準(zhǔn)確率表明該模型能夠有效地從訓(xùn)練數(shù)據(jù)中學(xué)習(xí)并可以做出準(zhǔn)確的預(yù)測(cè)。準(zhǔn)確率隨著每次迭代逐漸增加,表明模型不斷改進(jìn)其內(nèi)部參數(shù)以增強(qiáng)其性能,具有可靠預(yù)測(cè)的巨大潛力,并且可以有效地應(yīng)用于各種環(huán)境中,包括位置預(yù)測(cè)和數(shù)據(jù)分類任務(wù)。
本文介紹了基于深度學(xué)習(xí)下農(nóng)產(chǎn)品物流配送中心選址位置問(wèn)題,該模型方法能用于解決相似的選址問(wèn)題。利用K-means算法來(lái)確定農(nóng)產(chǎn)品配送中心的最佳選址,并且運(yùn)用肘部法確定配送中心的數(shù)量,還基于深度學(xué)習(xí)模型中的人工神經(jīng)網(wǎng)絡(luò)(ANN)形式的人工智能進(jìn)行位置預(yù)測(cè),能夠幫助企業(yè)快速高精度地確定配送中心位置,進(jìn)一步提高配送中心到需求點(diǎn)的配送效率。對(duì)農(nóng)產(chǎn)品配送問(wèn)題,下一步需要考慮利用機(jī)器學(xué)習(xí)預(yù)測(cè)與規(guī)劃配送路線等問(wèn)題。
猜你喜歡
童話王國(guó)·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學(xué)生數(shù)理化·七年級(jí)數(shù)學(xué)人教版(2020年11期)2020-12-14 06:59:52
中學(xué)生數(shù)理化·七年級(jí)數(shù)學(xué)人教版(2020年10期)2020-11-26 08:24:50
數(shù)學(xué)物理學(xué)報(bào)(2020年2期)2020-06-02 11:29:24
藝術(shù)品鑒證.中國(guó)藝術(shù)金融(2018年8期)2019-01-14 01:14:28
藝術(shù)品鑒證.中國(guó)藝術(shù)金融(2018年10期)2019-01-08 02:44:26
藝術(shù)品鑒證.中國(guó)藝術(shù)金融(2018年6期)2019-01-08 02:43:04
藝術(shù)品鑒證.中國(guó)藝術(shù)金融(2018年12期)2018-08-26 06:03:48
光學(xué)精密工程(2016年6期)2016-11-07 09:07:19
核科學(xué)與工程(2015年4期)2015-09-26 11:59:03
