基于對抗學習的查新檢索式自動生成
2024-08-13 00:00:00曾立英王亭亭劉耀王曉燕
鄭州大學學報(理學版) 2024年6期

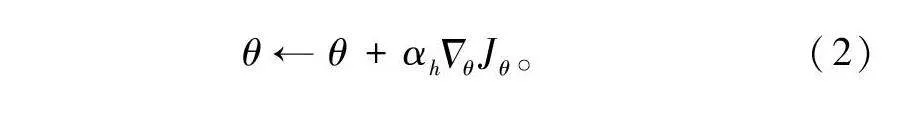



摘要: 科技查新是科研人員獲取前沿信息的重要途徑,但伴隨著信息量的劇增,傳統查新檢索式的構建方法存在效率低、關鍵詞提取不全面、一詞多義等問題,因此提出了融合基于Transformer的雙向編碼器表達與SequenceGAN的查新檢索式自動構建模型BSGAN。通過BiLSTM-CRF構建領域詞表及概念同義詞詞表,解決了查新檢索式構建過程中關鍵詞不夠全面的問題;采用基于Transformer的雙向編碼器表達模型中多頭注意力機制,解決了檢索式中一詞多義問題;使用BSGAN檢索式自動構建模型,實現了查新檢索式的自動生成與邏輯構建,解決了傳統方法中專家手工構建檢索式效率低的問題。最后,通過萬方中文數據庫中的檢索結果來評價檢索式,實驗結果表明,自動構建模型BSGAN生成的查新檢索式在醫藥、化工、計算機等領域均達到了較高的查準率與查全率。
關鍵詞: 查新檢索式; 對抗學習; BiLSTM-CRF; Transformer
中圖分類號: G252.7
文獻標志碼: A
文章編號: 1671-6841(2024)06-0070-07
DOI: 10.13705/j.issn.1671-6841.2023134
Novelty Retrieval Expression Automatic Generation Based on
Adversarial Learning
ZENG Liying1, WANG Tingting1, LIU Yao2, WANG Xiaoyan3
(1.College of International Education, Minzu University of China, Beijing 100081, China;
2.Institute of Scientific and Technology Information of China, Beijing 100038, China;
3.Library, Minzu University of China, Beijing 100081, China)
Abstract: Scientific and technological novelty retrieval was an important way for researchers to obtain frontline information. But with the blooming of information, the traditional construction method of novelty retrieval expression had some problems, including low efficiency, incomplete keywords extraction, polysemy, etc. Regarding the issues above, a new model called BSGAN was proposed that could combine BERT and SeqGAN for automatic construction of novelty retrieval expression. The method solved the issue that keywords were not comprehensive enough in the construction process of novelty retrieval expression by building domain vocabulary and concept synonym vocabulary through BiLSTM-CRF. At the same time, the issue of polysemy in retrieval expression was solved by using the Multi-headed Self-attention mechanism in Bert. In addition, BSGAN was used to implement the automatic generation and logical construction of novelty retrieval expression, which could solve the low efficiency of experts′ traditional manual construction methods. Finally, the retrieval expression was evaluated by the retrieval results in Wanfang Chinese database. The experiment outcome showed that the novelty retrieval expression automatically generated by BSGAN achieved high precision and recall in the fields of medicine, chemical engineering, computer, etc.
Key words: novelty search; adversarial learning; BiLSTM-CRF; Transformer
0 引言
隨著數據科學、人工智能等技術在全球的飛速發展,人類步入了知識經濟“信息爆炸”時代。網絡環境下信息的需求量劇增,傳統的查新手段已遠遠不能滿足科技查新的發展需求,尤其是每年出現的科技查新階段性業務高峰期,給查新機構人員儲備與服務效率都帶來巨大的挑戰。
科技查新工作的核心任務是分析查新委托內容,擬定檢索策略,對檢索結果進行評價,反復優化檢索策略,因而檢索策略的優劣直接影響查新報告的質量。狹義上,檢索策略是指檢索提問表達式,也稱檢索式,是由關鍵詞、關鍵詞之間的邏輯關系組成的邏輯表達式。然而,現有的科技文獻檢索技術存在不完善之處。一方面,檢索本身存在模糊性,面對海量的數據,查新人員很難得到自己需要的信息;另一方面,現有的科技查新檢索式大多是由專家撰寫的,需要花費巨大的人力和時間。因此如何實現查新檢索式的自動構建成為一個重要且有意義的問題。檢索策略的制定需要經過反復優化才能得到良好的效果,而人工所做的反復優化的過程與對抗學習框架中生成器與判別器相互迭代更新參數的過程類似,故生成對抗網絡(generative adversial network, GAN)可適用于檢索式生成。生成對抗網絡啟發自博弈論中的二人零和博弈,由Goodfellow等[1]開創性地提出,包含一個生成模型(G)和一個判別模型(D)。對抗學習基本思想是生成模型捕捉樣本數據的分布。判別模型是一個二分類器,用于判別輸入數據是否真實,這個模型的優化過程屬于二元極小極大博弈問題,訓練時固定一方,更新另一方的參數,交替迭代,使對方的錯誤最大化。最終,生成器能估測出樣本數據的分布。此外,通過對GAN的生成器、判別器做結構上的改進或對目標函數等進行優化,能產生更多種基于GAN的變種以適配不同的任務場景,生成對抗網絡目前廣泛應用于計算機視覺[2]、自然語言處理[3]、半監督學習[4]等領域。
時霽等[5]以較新的查新技術規范為依據,介紹了傳統手動制定查新檢索式的步驟及注意事項。孫可佳等[6]利用雙判別器結構生成詩歌,并通過詩歌的主題與優美詩意作為策略梯度反饋給生成器。龐栓栓[7]利用LeakGAN作為長文本來生成模型。沈杰等[8]利用SGAN(SequenceGAN,SGAN),也稱SeqGAN來解決開放領域中閑聊的問答生成。Yu等[9]提出的SeqGAN中使用的生成器是基于深層神經網絡編碼機制的Seq2seq(sequence to sequence),雖然查新檢索式的生成與問答生成相似,但仍有較大區別。在Seq2seq中,編碼機制將一個可變長度的信號序列變為固定長度的向量表達,這并不適用于查新點的編碼,因此提出了查新檢索式自動生成模型,用基于Transformer的雙向編碼器表達(bidirectional encoder representation from Transformers, BERT)替換SeqGAN的編碼機制,并輔以領域詞表及概念同義詞詞表來生成查新檢索式,可以幫助查新人員高效和精準地提供信息知識咨詢服務。
1 模型設計
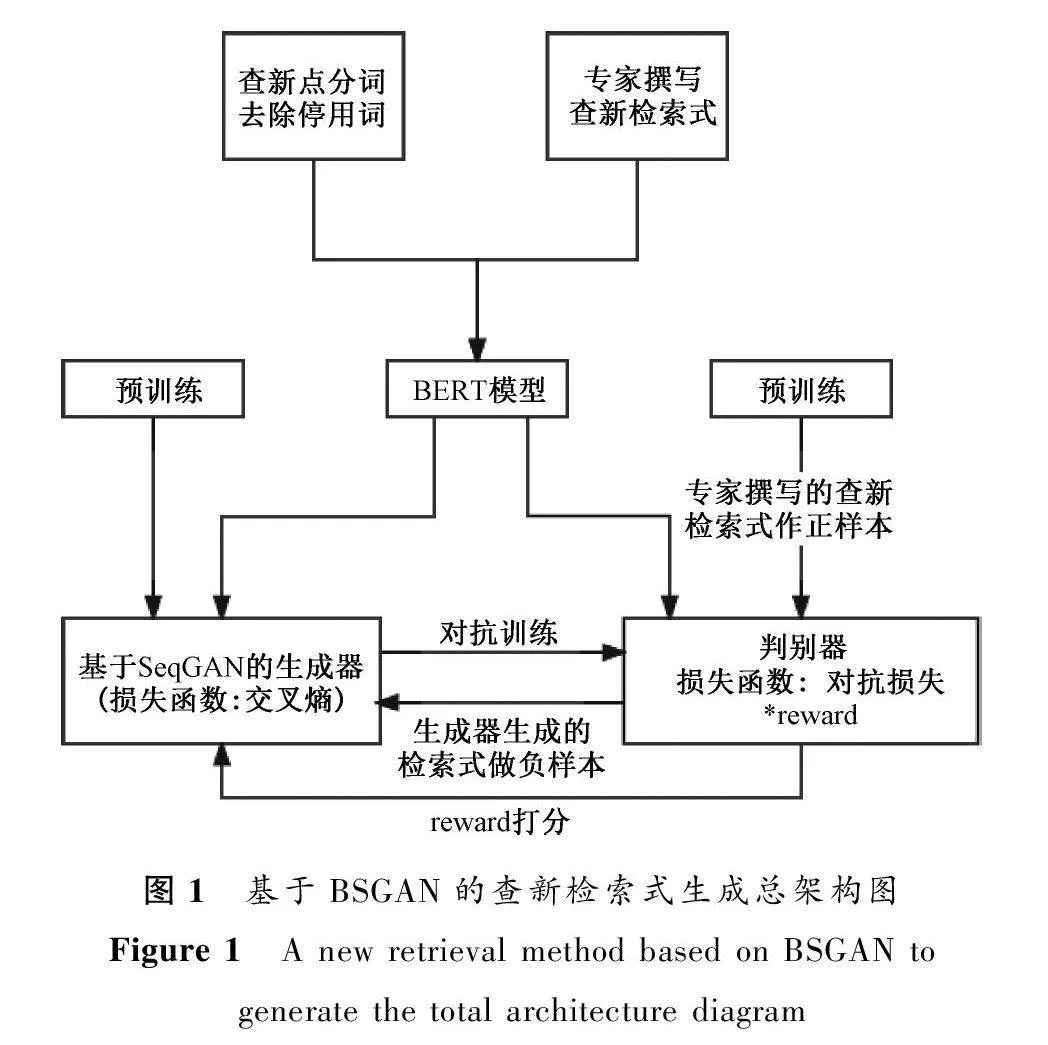
傳統檢索式的構建方式存在效率低下,關鍵詞不夠全面、一詞多義等問題。為有效解決這些問題,本文提出了融合BERT與SeqGAN的BSGAN模型,依據查新委托單中的查新點自動構建檢索策略,查新員可以對自動生成的查新檢索式進行優化和修改以保證檢索結果的準確性。基于BSGAN生成查新檢索式的總架構圖如圖1所示。
圖1中的BSGAN模型融合了SeqGAN模型與BERT模型。SeqGAN利用強化學習(reinforce learning,RL)來解決GAN的缺陷,其輸入和生成的數據都是連續的,是可微分函數與深度神經網絡結合成深度生成式模型的必要條件。在SeqGAN中,判別器為二分類器,生成器為Seq2seq,雖然Seq2seq生成的查新檢索式是連續的,但其自帶的向量表示模型不能解決檢索式中一詞多義問題,因此選取基于Transformer的BERT模型為詞嵌入模型。
圖1總框架中檢索式生成部分,將查新點與查新檢索式分別存儲在txt文本中,且按段落形式一一對應,作為Bert模型的輸入,首先將查新點及查新檢索式分詞、去除停用詞等預處理,預處理后以鍵值對結構存儲于詞匯表中。然后,通過Bert模型的多頭注意力機制——依據詞匯表將文本中的每個字或詞轉換為一維初始向量,在查新點中提取每個字或詞的文本向量和位置向量,并將這三個向量進行線性變化,添加注意力權重后作為模型的輸入。其次引入mask任務并使用雙向語言模型做預訓練,最后通過微調模式解決下游任務。BERT模型輸出的是融合全文語義信息的向量表示,可作為BSGAN算法的輸入。BSGAN算法流程如下。
輸入: G、D分別是生成器和判別器,Gθ、Dφ為生成器訓練出來的矩陣,檢索式的向量為生成器的輸入,生成器的輸出yt為判別器的輸入。
輸出: G與D是否達到納什均衡。
1) 隨機初始化Gθ網絡和Dφ網絡參數。
2) 通過最大似然估計預訓練G網絡,目的是提高G網絡的搜索效率。
3) 判別器與生成器共享參數。
4) 使用預訓練的Gθ生成一些數據即負樣本,通過最小化交叉熵來預訓練Dφ。
5) 開始GAN的過程,不斷循環迭代。
6) 開始生成檢索式,并使用獎勵函數方程計算reward(這個reward來自G生成的檢索式與D產生的Q值),Y1∶T=(y1,y2,…,yT)~Gθ。
7) for 1∶T里面的各個時刻do
8) 使用公式(1)更新G的參數。
9) 計算獎勵Q值。
10) 通過梯度更新生成器的參數。
11) end for
12) for 判別器的每一個時間步do
13) 通過生成器的序列生成偽檢索式,偽檢索式與真檢索式聯合起來。
14) 更優的G生成更好的檢索式,和真實數據一起通過公式(2)訓練D。
以上7)至14)循環訓練直到收斂。
其中:QGθDφ為Q值;αh代表學習率。
(a=yt,s=Y1∶T-1)=
1N∑Nn=1D(Yn1∶t),Yn1∶t∈MCGθ((Y1∶t,N)),t<T,
Dφ(Y1∶t),t=T,(1)
θ←θ+αhΔθJθ。(2)
2 實驗與結果
2.1 文獻預處理及數據集構建
為使BSGAN模型能夠生成查新檢索式,選取科技文獻中的摘要作為查新需求對BSGAN模型進行預訓練。本文利用萬方接口以“主題:藥學領域and時間:2015年1月1日—2020年12月31日”為檢索式進行檢索,并按照篇章結構的層級關系對論文進行解析與存儲。經觀察發現,在獲取的420篇藥學領域期刊論文中,有303篇論文摘要結構符合“目的,方法,結果與結論”三段式。再選取情報學領域、計算機領域、化學化工領域以及藥劑學領域中的科技文獻作為實驗對象,檢索策略同時包含“目的”“方法”“結果與結論”這三個限定詞,時間設定為2015年至2020年,檢索結果數量分別為1 267、3 675、3 132、4 979篇,共13 053篇。
對獲取的科技文獻進行預處理,從主要論文摘要中解析提取查新需求并觀察提取效果。查新需求提取后以鍵值對的形式存放于json文件中,一個字段表示一個查新需求。一篇摘要分為三個查新需求。以下為《新型冠狀病毒肺炎治療中人免疫球蛋白的合理使用與藥學監護》中文摘要查新點的提取結果。
1) "論文":"新型冠狀病毒肺炎治療中人免疫球蛋白的合理使用與藥學監護.pdf"
2) "目的":"探討人免疫球蛋白在新型冠狀病毒肺炎治療中的合理使用與藥學監護要點。"(“目的”對應查新需求1)
3) "方法":"查閱文獻,整理靜脈用人免疫球蛋白的作用機制、適應證、感染性疾病應用概況、劑量、藥代動力學特點,以及對實驗室指標的影響和不良反應等特點,提出合理用藥建議。"(“方法”對應查新需求2)
4) "結果":"人免疫球蛋白在新型冠狀病毒肺炎的治療中缺乏直接使用證據,不建議常規應用。免疫缺陷或疾病進展迅速的患者可考慮使用,但應把握劑量,注意輸注速率。使用過程中應動態監測患者血漿球蛋白水平,加強藥學監護。"(“結果”對應查新需求3)
對查新需求進行數據收集及預處理,合并重復項、刪除缺失項,提取“標題”和“摘要”字段,形成待分析和處理的語料集,后續對語料進行分詞、停用詞過濾等操作,形成最終實驗數據集。
2.2 領域詞表與同義詞表的構建
本節以藥學領域的科技查新項目為例,對科學技術要點從寫作內容和寫作特征的角度進行分析,挖掘查新點中的關鍵概念,初步構建領域詞表。初步構建的領域詞表因數據量少,不足以支撐整個科技查新項目,需不斷更新,因而利用雙向長短時記憶網絡-條件隨機場(bi-directional long short term memory-conditional randomfield, BiLSTM-CRF)對查新文本(包含查新需求和查新點)進行概念及關系標引,構建領域概念及同義詞表。以下為摘自藥學領域委托單中的兩例查新點。
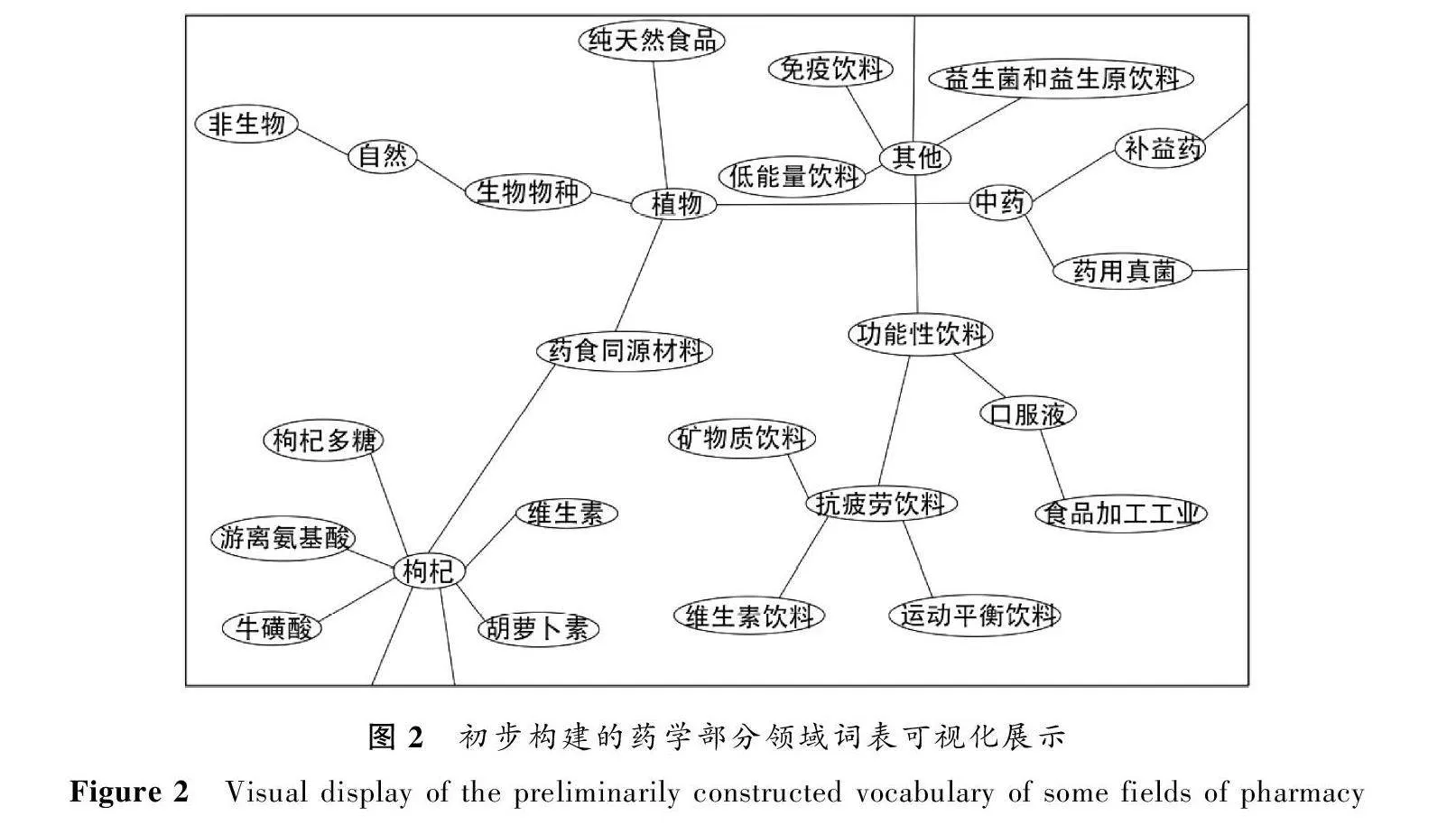
查新點1:“以蛹蟲草、瑪卡、黃精、枸杞為主要原料,輔以菊粉調制成具有增強體質、耐受疲勞的一款飲料。(來源《王府一號腎精液口服液》)”
將查新點1中的關鍵概念通過初步構建的詞表可視化展示如圖2所示,可觀察到,與查新點1相關的概念中,“枸杞”的直接上位類是“藥食同源材料”,“抗疲勞飲料”的間接上位類是“免疫飲料”。領域詞表中“枸杞”還缺乏其別名,如《神農本草經》記載的枸杞的別名有“枸棘子”“杞子”“枸杞果”等,故將這些含有同義詞的概念詞提取并保存在概念同義詞表中,并在概念詞字段后添加其同義詞。
查新點2:“利培酮口服溶液的處方為:利培酮200g,酒石酸1.0Kg,氫氧化鈉100g,苯甲酸200g,純化水加至200L。(來源《利培酮口服溶液》)”
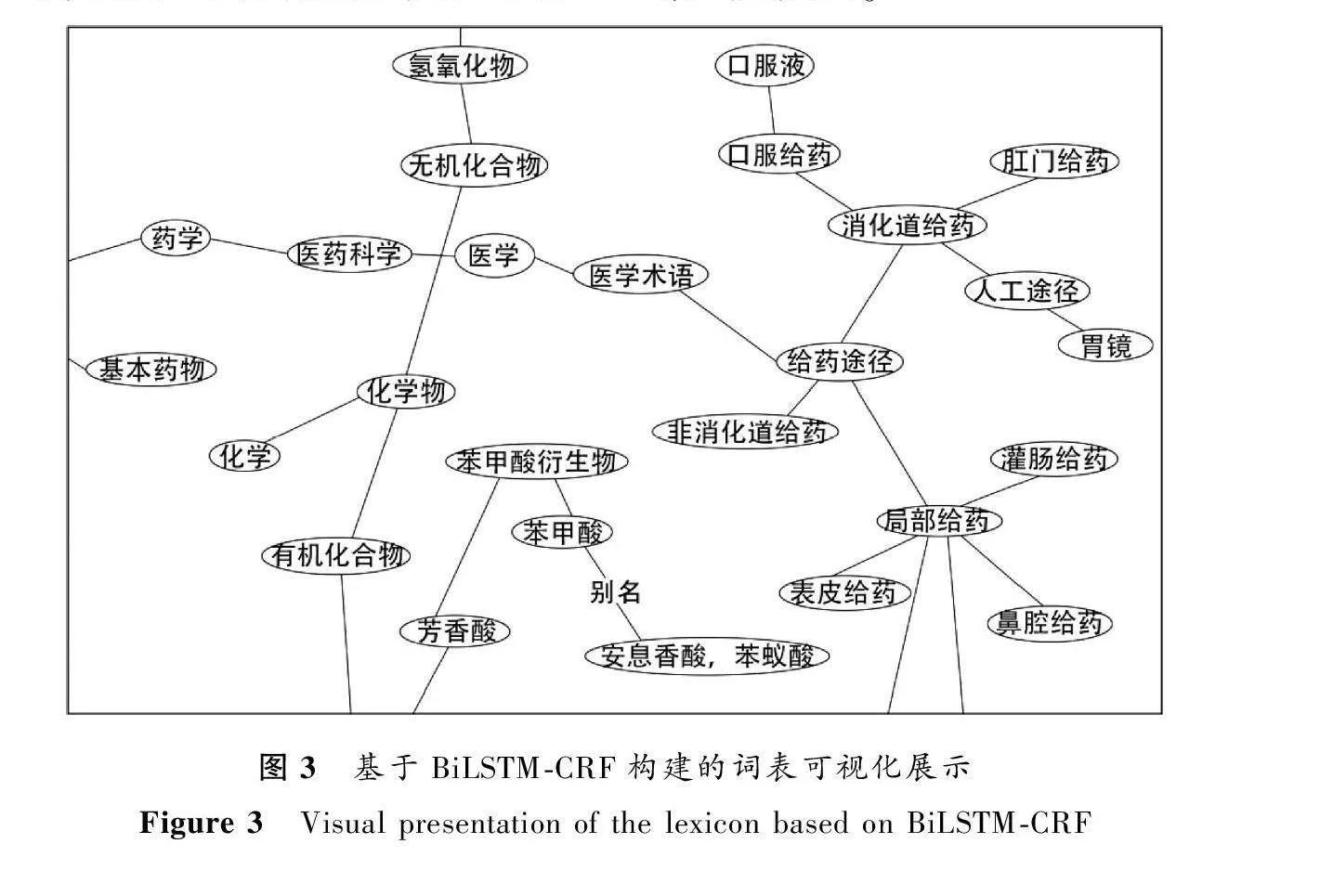
查新點2提出了“利培酮口服液”的處方,通過BiLSTM-CRF模型構建的領域詞表及同義詞表中與“利培酮口服溶液”相關的詞可視化展示如圖3所示。可看出“苯甲酸”的別名有“安息香酸”“苯蟻酸”,說明領域詞表與概念同義詞表的構建與擴充有助于查新檢索式的生成。如“利培酮”的同義詞有“利哌利酮”“瑞司哌酮”“瑞斯哌東”“利司環酮”等,依據領域詞表來構建概念同義詞表可使查新檢索式更完整。
BiLSTM-CRF模型構建領域詞表及同義詞表的流程如下:將查新點與查新需求作為訓練語料,統稱為查新文本。首先對查新文本按領域分類,將不同領域的概念按屬性分類。然后采用概念詞典、規則提取并輔以人工標注的方法對文本中的概念進行初步標引。最后,當詞匯積累到一定程度,得出以下科技查新概念詞的分類體系。如果某一概念屬于多個分類,則選擇頻次最高的分類。可分為五個類別。1) 成分:“菊粉”“蛹蟲草”等;2) 功能:“抗疲勞”“增強體質”“滋陰補陽”“緩解衰老”等;3) 適應證:“焦慮”“抑郁”“負罪感”“懷疑”“幻覺”“妄想”等;4) 劑型:“中藥合劑”“口服液”“注射劑”“凝膠劑”“微球”“膜狀制劑”等;5) 技術:“核磁共振”“腦腫瘤切除”“萃取”“提純”等。
根據相應特點制定分類規則,最后輔以人工標注的方式共標注2 000條查新點。本研究構建并擴充了圖書館、情報與文獻學領域、數學領域、軍事學領域、管理學領域等共26個領域的概念詞表及16個概念同義詞詞表。其中藥學領域詞表中存儲5 453個詞,詞表主要包含從屬關系,藥學領域同義詞表中包含25個概念詞,概念同義詞以并列關系存儲。
2.3 檢索式生成
查新檢索式自動生成的具體流程如圖4所示。生成式對抗網絡的訓練是生成網絡與判別網絡之間博弈的過程。為了以最快的方式達到納什均衡,訓練開始前,用最大似然估計方法將真實查新檢索式數據集置于文本生成網絡中進行預訓練。然后,使用生成網絡生成的數據和真實數據作為判別器的輸入,以最大交叉熵為目標函數預訓練判別網絡。最后生成網絡和判別網絡交替訓練,生成網絡通過一定步驟的更新訓練得到進步,判別網絡通過定期訓練得到進步。
圖4中,在訓練查新檢索式生成網絡時,對抗學習的方法可以解決訓練樣本不足的問題。實驗分別以數據集個數為50、100、150、300依次進行。結果發現語料數量為100條時,便可以生成與真實數據相同的查新檢索式。輸入數據為100個查新點時,生成器訓練600次,判別器訓練300次,生成器與判別器達到納什均衡,效果最優,可以輸出與標準集相同的查新檢索式,而將訓練次數提高時,模型生成的查新檢索式與專家撰寫的查新檢索式相同的個數不再增加。通過納什均衡狀態下的生成模型檢驗查新檢索式的生成效果,輸入查新需求如下。
“目的探討不同范圍肝切除術治療肝內膽管結石的臨床療效。
方法對86例肝內膽管結石患者采用手術治療,比較不同范圍肝切除治療的臨床效果。
結果左外葉切除術后結石殘余率明顯高于左半肝切除……
結論肝切除是治療肝內膽管結石最有效的方法,對于非局限在左外葉的肝內結石,左、右半肝切除和肝段切除術優于左外葉切除術。肝切除范圍與術后結石殘留和手術治療效果密切相關。”
基于BSGAN模型生成的查新檢索式為“肝切除and肝內膽管結石and肝內膽管結石and(左外葉切除or左半肝切除or肝段切除術)and殘余率and(肝切除范圍or術后結石殘留or肝段切除術)”,由抽檢的檢索式觀察到,BSGAN模型生成的查新檢索式符合萬方數據庫檢索式的撰寫要求。除此方法外,利用Textrank方法提取查新點中的關鍵詞,通過組配邏輯算符來構成查新檢索式,這也是查新平臺推薦檢索式的方法之一。
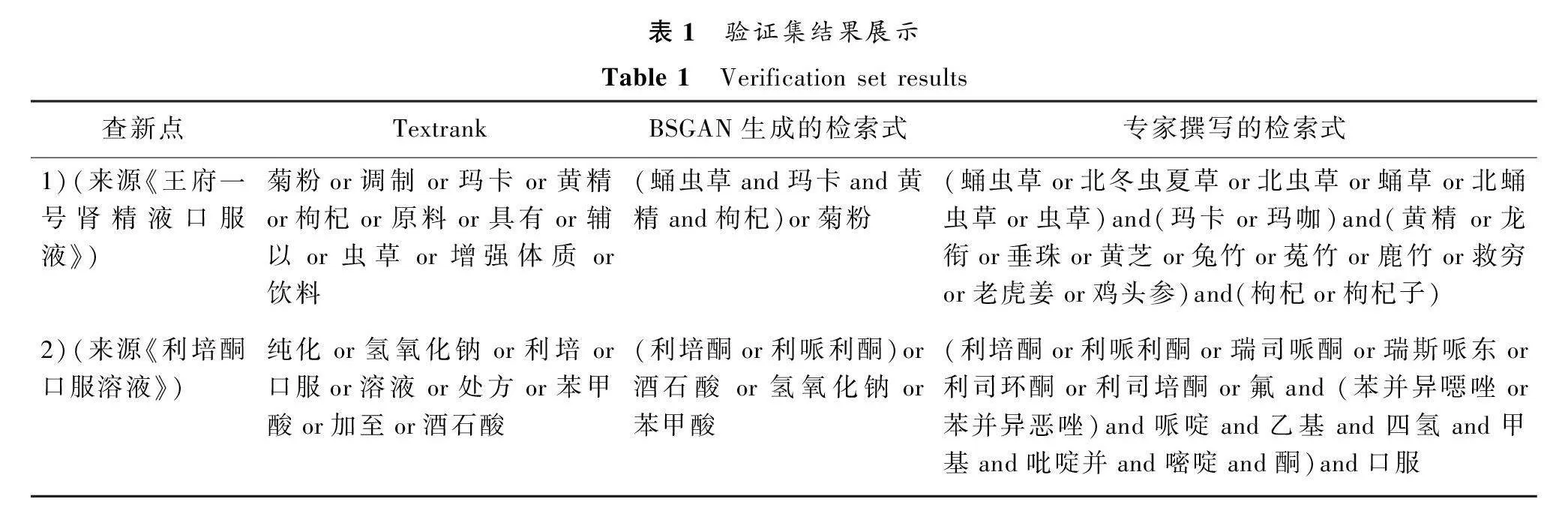
本文將BSGAN模型與Textrank構建的檢索式在萬方中文數據庫中的檢索結果作對比,表1展示了兩個查新點的檢索式生成,并與Textrank和專家手工撰寫的檢索式對比。以查新點1為例,BSGAN模型生成的檢索式經檢索得到1 771條結果,綜合來看檢索結果查準率高,查全率的評判需進一步與專家篩選的目標文獻進行計算。而Textrank生成的檢索式經檢索得到了11 774 534條結果,該方法是關鍵詞的單純組合,并沒有對關鍵詞的上位類或下位類進行邏輯組配導致結果冗余,查準率低導致查全率低。
3 實驗結果評價
由于檢索式的特殊性,無法直接對檢索式進行評價,所以選擇《面向自動處理的科技查新案例解析與實現》[10]中的查新點與專家撰寫的查新檢索式來檢驗模型效果。利用專家撰寫的檢索式與模型生成的檢索式在萬方數據庫中進行檢索,檢索結果都按照相關性排序。查新報告中專家撰寫的檢索式得到的檢索結果作標準集,采用查全率與查準率作為評價標準來評估方法的有效性。對查準率和查全率這兩個評價指標進行定義,具體計算方法為
查準率=檢索出的正確的論文數量檢索出的論文總數量,(3)
查全率=檢索出的正確論文數量查新報告中的檢索結果數量。(4)
當查準率小于50%時,需使用檢索詞匹配領域詞表中該詞的上位類或下位類進行再次檢索,若依舊小于50%,則輸出模型生成的檢索式。經過多次實驗發現,利用BSGAN方法自動生成檢索式的速度快在ms級別,最長時間即再次檢索時間為0.89 s。測試集中平均查全率為75%,平均查準率為82%。其查全率與查準率部分結果如表2所示。
以表2中的查新項目2為例,考察其在科技查新報告(編號為20161100100049)中的查全率,選取專家標注的四篇國內文獻作為目標文獻。將Textrank與BSGAN模型的檢索結果按相關度排序,分別取前50篇相關文獻。BSGAN完全命中專家選取的目標文獻,而Textrank模型生成的檢索式涵蓋范圍廣,查準率低,檢索到目標文獻的概率更低。綜上,本文提出的BSGAN模型檢索結果更接近查新報告中的目標文獻,與專家檢索結果差異小。但BSGAN模型生成的部分查新檢索式也存在如括號缺失或冗余、部分專業詞匯如“苯并異噁唑”未被準確識別而導致關鍵詞不夠全面和邏輯關系缺失等問題。為確保檢索式能正常使用,實驗采取部分措施加以彌補,包括:1) 將檢索式中丟失或冗余的括號利用正則補充完整;2) 通過領域詞表及概念同義詞表解決專業詞匯未能準確識別的問題,進而解決關鍵詞不全面的問題;3) 檢索式中缺失的邏輯關系,檢索詞若為從屬關系則添加“and”關系,若為概念同義詞關系則添加“or”關系。
4 結論
為了解決傳統構建查新檢索式方法效率低下的問題,本文針對科技查新類文本的特點,提出了基于對抗學習的查新檢索式自動生成模型BSGAN。研究并實現了查新檢索式自動生成關鍵技術。首先從論文中提取摘要并將其解析為查新點,然后基于領域專家的先驗知識通過BiLSTM-CRF構建了領域詞表及概念同義詞詞表,最終實現查新點中的概念和概念關系自動匹配,并通過領域詞表和概念同義詞表解決了查新檢索式生成過程中關鍵詞不全面的問題,通過BERT模型的多頭注意力機制,解決了檢索式中一詞多義問題,通過使用對抗學習模型解決了查新檢索式的自動生成問題。
參考文獻:
[1] GOODFELLOW I J, POUGET-ABADIE J, MIRZA M, et al.Generative adversarial nets[C]∥Proceedings of International Conference on Neural Information Processing Systems. Cambridge: MIT Press,2014:2672-2680.
[2] 張敏情, 李宗翰, 劉佳, 等. 基于邊界平衡生成對抗網絡的生成式隱寫[J]. 鄭州大學學報(理學版), 2020, 52(3): 34-41.
ZHANG M Q, LI Z H, LIU J, et al. Generative steganography based on boundary equilibrium generative adversarial network[J]. Journal of Zhengzhou university (natural science edition), 2020, 52(3): 34-41.
[3] 張得祥, 王海榮, 鐘維幸, 等. 融合軟獎勵和退出機制的WGAN知識圖譜補全方法[J]. 鄭州大學學報(理學版), 2022, 54(2): 67-73.
ZHANG D X, WANG H R, ZHONG W X, et al. WGAN knowledge map completion method integrating soft reward and exit mechanism[J]. Journal of Zhengzhou university (natural science edition), 2022, 54(2): 67-73.
[4] 胡彬. 半監督對抗魯棒模型無關元學習方法的研究與實現[D]. 南京: 南京郵電大學, 2022.
HU B. Research and implementation of semi-supervised adversarially robust model-agnostic meta-learning[D]. Nanjing: Nanjing University of Posts and Telecommunications, 2022.
[5] 時霽, 邵如潔. 科技查新檢索策略制定分析[J]. 電子技術與軟件工程, 2023(2): 198-201.
SHI J, SHAO R J. Analysis on the formulation of retrieval strategy for sci-tech novelty retrieval[J]. Electronic technology & software engineering, 2023(2): 198-201.
[6] 孫可佳, 李啟南. 基于改進生成對抗網絡的詩歌生成[J]. 蘭州交通大學學報, 2020, 39(2): 64-70.
SUN K J, LI Q N. Poetry generation based on improved generative adversarial nets[J]. Journal of Lanzhou Jiaotong university, 2020, 39(2): 64-70.
[7] 龐栓栓. 基于LeakGAN的誘餌文檔生成研究與實現[D]. 北京: 北京交通大學, 2019.
PANG S S. Research and implementation of bait document generation based on LeakGAN[D]. Beijing: Beijing Jiaotong University, 2019.
[8] 沈杰, 瞿遂春, 任福繼, 等. 基于SGAN的中文問答生成研究[J]. 計算機應用與軟件, 2019, 36(2): 194-199.
SHEN J, QU S C, REN F J, et al. Chinese question answer generation based on sgan[J]. Computer applications and software, 2019, 36(2): 194-199.
[9] YU L T, ZHANG W N, WANG J, et al. SeqGAN: sequence generative adversarial nets with policy gradient[C]∥Proceedings of the AAAI Conference on Artificial Intelligence. Menlo Park:AAAI Press,2017:2852-2858.
[10]劉耀, 曹燕. 面向自動處理的科技查新案例解析與實現[M]. 北京: 科學技術文獻出版社, 2019.
LIU Y, CAO Y. Analysis and implementation of sci-tech novelty retrieval case oriented to automatic processing[M]. Beijing: Scientific and Technical Documentation Press, 2019.
