基于自適應(yīng)聚合時(shí)間的半同步聯(lián)邦資源優(yōu)化算法
2024-09-14 00:00:00李鐵莊琲林尚靜韓志博
無(wú)線電通信技術(shù) 2024年4期
關(guān)鍵詞:物聯(lián)網(wǎng)

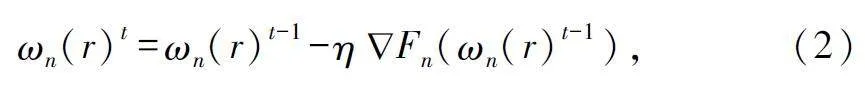



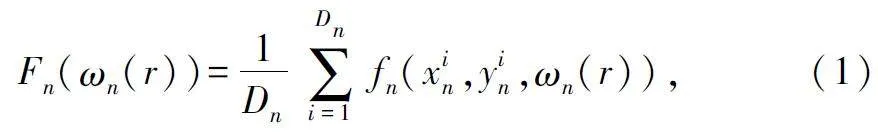

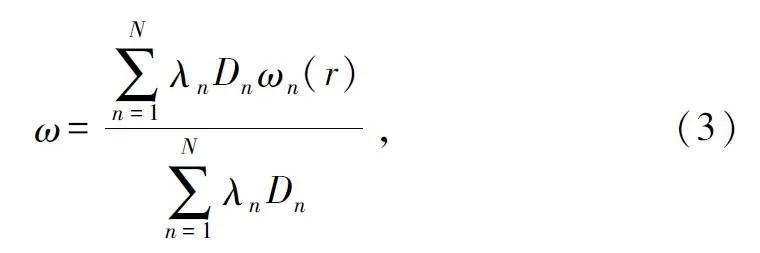
摘 要:聯(lián)邦學(xué)習(xí)是一種高效的分布式機(jī)器學(xué)習(xí)方法,其中多個(gè)設(shè)備使用自己的本地?cái)?shù)據(jù)進(jìn)行分布式模型訓(xùn)練,不需要交換本地?cái)?shù)據(jù),僅通過(guò)交換模型參數(shù)來(lái)構(gòu)建共享的全局模型,從而保護(hù)用戶(hù)的隱私。為了平衡模型性能和通信延遲,在半同步聯(lián)邦學(xué)習(xí)場(chǎng)景下,使用權(quán)重參數(shù)建立了一個(gè)最小化模型性能和聚合時(shí)間的加權(quán)和的優(yōu)化問(wèn)題。優(yōu)化變量包括進(jìn)行全局模型更新的聚合時(shí)間、用戶(hù)調(diào)度以及參與上傳的用戶(hù)的帶寬和發(fā)射功率,通過(guò)使用交替方向乘子法(Alternating Direction Method of Multipliers,ADMM)將所提混合整數(shù)非線性規(guī)劃(Mixed Integer Non-Linear Programming,MINLP)問(wèn)題分解為兩個(gè)子問(wèn)題進(jìn)行求解。仿真實(shí)驗(yàn)證明,所提算法能夠以犧牲4% 模型性能為代價(jià),降低73% 的聚合時(shí)間,顯著提高了通信效率。
關(guān)鍵詞:物聯(lián)網(wǎng);半同步聯(lián)邦學(xué)習(xí);用戶(hù)調(diào)度;資源優(yōu)化
中圖分類(lèi)號(hào):TN92 文獻(xiàn)標(biāo)志碼:A 開(kāi)放科學(xué)(資源服務(wù))標(biāo)識(shí)碼(OSID):
文章編號(hào):1003-3114(2024)04-0696-08
0 引言
隨著通信技術(shù)的快速發(fā)展,未來(lái)將是一個(gè)數(shù)據(jù)爆炸的時(shí)代,海量數(shù)據(jù)將無(wú)處不在,涵蓋從物聯(lián)網(wǎng)設(shè)備到智能終端的各個(gè)領(lǐng)域。面對(duì)如此龐大的數(shù)據(jù)量,如何在保障用戶(hù)隱私的前提下有效地進(jìn)行數(shù)據(jù)處理、分析和利用,成為了一個(gè)亟待解決的問(wèn)題。
聯(lián)邦學(xué)習(xí)[1]正是在這樣的背景下應(yīng)運(yùn)而生。它能夠在保護(hù)用戶(hù)隱私的前提下,允許各個(gè)節(jié)點(diǎn)或設(shè)備利用本地?cái)?shù)據(jù)進(jìn)行模型的訓(xùn)練和優(yōu)化,而無(wú)需將數(shù)據(jù)上傳到中心服務(wù)器。這種分布式的學(xué)習(xí)方式不僅降低了數(shù)據(jù)傳輸和存儲(chǔ)的成本,還提高了數(shù)據(jù)處理的效率和安全性。因此,聯(lián)邦學(xué)習(xí)在移動(dòng)邊緣網(wǎng)絡(luò)中得到廣泛應(yīng)用[2]。
在移動(dòng)邊緣網(wǎng)絡(luò)中,不同的訓(xùn)練任務(wù)在總延遲和準(zhǔn)確度方面具有不同的偏好。例如,對(duì)于語(yǔ)音識(shí)別[3]或視頻處理[4]等實(shí)時(shí)任務(wù),總延遲是關(guān)鍵因素。對(duì)于醫(yī)學(xué)影像診斷[5]或金融風(fēng)險(xiǎn)評(píng)估[6]等任務(wù),準(zhǔn)確度是關(guān)鍵因素。然而,在移動(dòng)邊緣網(wǎng)絡(luò)環(huán)境下,現(xiàn)有的聯(lián)邦學(xué)習(xí)框架很難滿(mǎn)足不同的訓(xùn)練任務(wù)偏好。其主要面臨以下挑戰(zhàn):
一方面,在同步聯(lián)邦學(xué)習(xí)框架中,每一輪的通信總延遲取決于最慢的設(shè)備。然而,由于聯(lián)邦學(xué)習(xí)參與者的設(shè)備存在硬件差異,其計(jì)算和通信能力不同,因此設(shè)備條件較好的用戶(hù)往往需要等待更長(zhǎng)的時(shí)間。這種硬件條件差異所導(dǎo)致的落后效應(yīng)降低了整個(gè)系統(tǒng)的效率。
另一方面,由于帶寬資源有限,當(dāng)大量設(shè)備與服務(wù)器同時(shí)進(jìn)行通信時(shí),會(huì)造成通信擁堵,增加通信延遲。然而,當(dāng)隨機(jī)選擇一部分設(shè)備參與通信時(shí),又會(huì)帶來(lái)精度的顯著降低。
針對(duì)以上問(wèn)題,提出了一種基于自適應(yīng)聚合時(shí)間的半同步聯(lián)邦資源優(yōu)化算法。在聯(lián)邦學(xué)習(xí)每一個(gè)時(shí)間周期內(nèi),根據(jù)設(shè)備的計(jì)算能力、信道條件、存儲(chǔ)數(shù)據(jù)量大小來(lái)選擇參與模型聚合的用戶(hù),通過(guò)引入權(quán)重因子平衡模型準(zhǔn)確度與時(shí)延,最大化用戶(hù)收益,同時(shí)確定等待聚合的時(shí)間,聚合時(shí)間在每個(gè)時(shí)間周期根據(jù)用戶(hù)情況動(dòng)態(tài)變化。建立并求解混合整數(shù)非線性規(guī)劃(Mixed Integer Non-Linear Programming,MINLP)問(wèn)題,完成用戶(hù)的選擇、資源管理與聚合時(shí)間的確定。提出基于增廣拉格朗日法與交替方向乘子法(Alternating Direction Method of Multipliers,ADMM)的方案,將優(yōu)化問(wèn)題分解為設(shè)備調(diào)度和資源分配兩個(gè)子問(wèn)題依次迭代求解,優(yōu)化發(fā)射功率、帶寬資源的分配,確定聚合時(shí)間。
1 研究現(xiàn)狀
現(xiàn)有聯(lián)邦學(xué)習(xí)資源優(yōu)化算法多基于同步聯(lián)邦學(xué)習(xí)訓(xùn)練方式。Zeng 等[7]提出了帶寬分配和用戶(hù)調(diào)度的節(jié)能策略,在保證聯(lián)邦學(xué)習(xí)性能的前提下降低了系統(tǒng)總能耗。Zhou 等[8]通過(guò)引入權(quán)重參數(shù)制定了一個(gè)最小化總能耗和完成時(shí)間的優(yōu)化問(wèn)題,優(yōu)化變量涉及設(shè)備帶寬、傳輸功率和CPU 頻率,實(shí)現(xiàn)了能耗和延遲之間的平衡。Kim 等[9]聯(lián)合優(yōu)化數(shù)據(jù)數(shù)量和帶寬資源,實(shí)現(xiàn)了學(xué)習(xí)效率和系統(tǒng)總能耗之間的平衡。以上文獻(xiàn)所基于的同步聯(lián)邦學(xué)習(xí)訓(xùn)練方式能夠確保良好的融合性能,但可能會(huì)導(dǎo)致嚴(yán)重的掉隊(duì)問(wèn)題。
為解決同步聯(lián)邦學(xué)習(xí)算法的高延遲問(wèn)題,文獻(xiàn)[10-11]提出了異步模型聚合算法,這種異步更新方式使用戶(hù)能夠在完成本地訓(xùn)練后,立即將模型上傳到服務(wù)器進(jìn)行融合。雖然異步更新方式避免了用戶(hù)等待過(guò)長(zhǎng)時(shí)間,但異步更新造成的梯度停滯將進(jìn)一步降低模型的性能[12]。
新興的半同步聯(lián)邦學(xué)習(xí)算法結(jié)合了同步聯(lián)邦學(xué)習(xí)和異步聯(lián)邦學(xué)習(xí)的優(yōu)點(diǎn),允許部分設(shè)備上傳過(guò)時(shí)的模型進(jìn)行全局聚合。You 等[13]提出了一種半同步算法,該算法緩解了掉隊(duì)問(wèn)題并確保了良好的收斂性能。但該算法使用貪婪算法解決調(diào)度問(wèn)題,貪婪算法屬于啟發(fā)式算法,易于實(shí)現(xiàn),但容易陷入局部最優(yōu)解。因此,在解決資源優(yōu)化問(wèn)題中,需要根據(jù)對(duì)精確性和復(fù)雜度的偏好來(lái)選擇適宜的算法求解凸優(yōu)化問(wèn)題。
2 系統(tǒng)模型
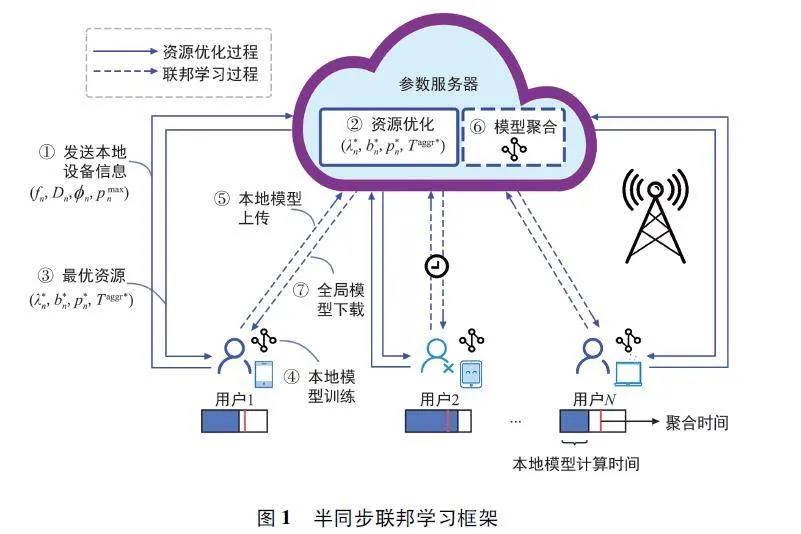
針對(duì)物聯(lián)網(wǎng)場(chǎng)景設(shè)計(jì)的半同步聯(lián)邦學(xué)習(xí)框架如圖1 所示,主要由一個(gè)參數(shù)服務(wù)器和在其通信覆蓋范圍內(nèi)的N 個(gè)用戶(hù)組成。將用戶(hù)集合表示為N={1,2,…,N}。用戶(hù)通過(guò)無(wú)線通信網(wǎng)絡(luò)與參數(shù)服務(wù)器通信。對(duì)于每個(gè)設(shè)備n∈ N,存儲(chǔ)的本地?cái)?shù)據(jù)集為Dn = {(x1n,y1n ),(x2n,y2n ),…,(xin,yin),…,(xnDn,ynDn)},Dn 為設(shè)備 n 上數(shù)據(jù)集的樣本數(shù)。xin 和yin 分別表示設(shè)備n 上第i 個(gè)輸入樣本和對(duì)應(yīng)的真實(shí)標(biāo)簽。
參數(shù)服務(wù)器動(dòng)態(tài)選擇用戶(hù)上傳其本地模型,通過(guò)協(xié)作計(jì)算和通信,完成聯(lián)邦學(xué)習(xí)任務(wù)。
具體地,在每一個(gè)通信輪開(kāi)始前,設(shè)備n 向參數(shù)服務(wù)器發(fā)送本地存儲(chǔ)的數(shù)據(jù)量Dn、本地計(jì)算能力(例如CPU 頻率fn)、位置信息n 和可執(zhí)行的CPU最大發(fā)射功率pmaxn 。服務(wù)器根據(jù)這些信息通過(guò)資源管理算法設(shè)置一個(gè)等待聚合時(shí)間Taggr,選擇一組在等待時(shí)間內(nèi)可以完成本地訓(xùn)練的設(shè)備進(jìn)行通信資源分配以及上傳本地模型。根據(jù)每個(gè)時(shí)刻設(shè)備情況的不同,Taggr 在每個(gè)時(shí)刻動(dòng)態(tài)變化。隨后,在參數(shù)服務(wù)器完成全局模型的聚合。在每個(gè)時(shí)刻重復(fù)以上過(guò)程,直到全局模型收斂。
2. 1 聯(lián)邦學(xué)習(xí)過(guò)程
聯(lián)邦學(xué)習(xí)訓(xùn)練過(guò)程包含本地模型計(jì)算、本地模型上傳和本地模型聚合三個(gè)過(guò)程。詳細(xì)流程如下。
① 參數(shù)服務(wù)器將全局模型ω 下發(fā)給所有用戶(hù)設(shè)備。
② 用戶(hù)設(shè)備n 在本地?cái)?shù)據(jù)集n 上訓(xùn)練本地模型,目標(biāo)是得到最小化模型損失函數(shù)Fn(ωn)的模型參數(shù)值ωn,Fn(ωn)的表達(dá)方式為:
式中:r 為全局輪的索引,Fn(ωn(r))為樣本損失函數(shù),用于衡量輸出與真實(shí)標(biāo)簽yin 之間的誤差。設(shè)備n 在第t 輪本地迭代時(shí)更新參數(shù)的過(guò)程如下:
式中:η 為學(xué)習(xí)率。
訓(xùn)練完成后,被調(diào)度的設(shè)備n 通過(guò)無(wú)線通信將其本地模型參數(shù)ωn(r)上傳到參數(shù)服務(wù)器。參數(shù)服務(wù)器通過(guò)聚合本地模型參數(shù)來(lái)獲得的全局模型為:
式中:λn 表示用戶(hù)調(diào)度指示符,當(dāng)λn = 1 時(shí)表示用戶(hù)被調(diào)度,需要向參數(shù)服務(wù)器上傳其本地模型;λn =0 時(shí)則不被調(diào)度,不需要上傳。
③ 完成全局模型聚合后,參數(shù)服務(wù)器將全局模型參數(shù)ω 發(fā)送給所有用戶(hù)設(shè)備,每個(gè)用戶(hù)設(shè)備n 接收ω 并將局部模型參數(shù)更新為ωn(r+1)= ω。
2. 2 延遲模型
在所提的框架中,用戶(hù)設(shè)備需要通過(guò)與參數(shù)服務(wù)器的通信來(lái)上傳和下載模型參數(shù)。為了保證用戶(hù)設(shè)備與參數(shù)服務(wù)器之間的不間斷傳輸,用戶(hù)設(shè)備與基站之間采用正交頻分多址技術(shù)[14]通信,用戶(hù)設(shè)備在每一輪訓(xùn)練中保持恒定的無(wú)線信道增益,并在不同輪次中改變信道增益。在每一輪中,用戶(hù)設(shè)備n到參數(shù)服務(wù)器之間的信道增益為:
hn =δn PL(dn) n, (4)
式中:dn 為用戶(hù)設(shè)備n 與參數(shù)服務(wù)器之間的距離,αn 為包括陰影和路徑損耗的大尺度衰落效應(yīng),陰影δn 服從對(duì)數(shù)正態(tài)分布,路徑損耗PL(dn )= 128. 1+37. 6 lg(n [km])。n 為小尺度衰落效應(yīng),服從瑞利分布[15]。
4 仿真實(shí)驗(yàn)
4. 1 參數(shù)設(shè)置
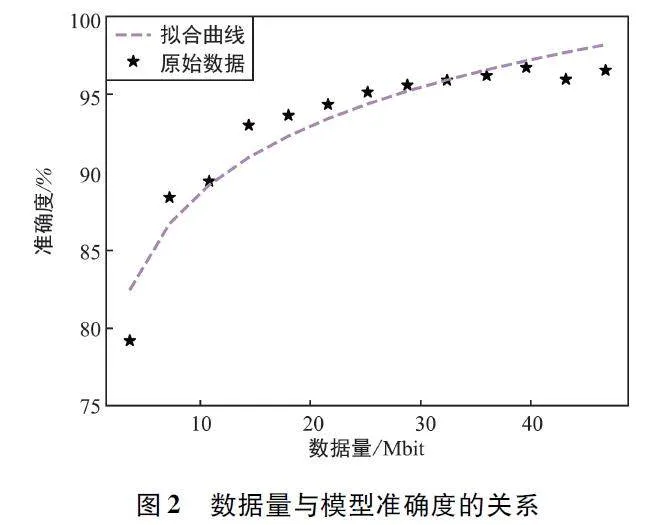
本文的半同步聯(lián)邦學(xué)習(xí)系統(tǒng)由一個(gè)參數(shù)服務(wù)器和10 個(gè)用戶(hù)設(shè)備組成,用戶(hù)設(shè)備的數(shù)據(jù)量Dn 在1 ~4 Mbit 隨機(jī)選擇。設(shè)置參數(shù)服務(wù)器的通信覆蓋以其為中心的半徑600 m 的區(qū)域。噪聲功率σ2 = -114 dBm,CPU 周期ξn = 10 cycles/ bit,本地迭代次數(shù)In 為10,聯(lián)邦學(xué)習(xí)過(guò)程中傳輸?shù)哪P蛥?shù)大小ωn = 0. 316 Mbit。參數(shù)服務(wù)器可分配的總帶寬B=1 MHz。設(shè)備的CPU 頻率fn 為0. 1 ~ 1. 0 GHz,數(shù)據(jù)傳輸功率Pn 為10 ~ 20 dBm,量綱系數(shù)αE = 1。圖2 是對(duì)MNIST 手寫(xiě)數(shù)字識(shí)別數(shù)據(jù)集擬合的結(jié)果,橫坐標(biāo)代表參與聯(lián)邦訓(xùn)練的數(shù)據(jù)量大小,縱坐標(biāo)代表聯(lián)邦學(xué)習(xí)全局模型的準(zhǔn)確度,每個(gè)數(shù)據(jù)點(diǎn)為聯(lián)邦訓(xùn)練100 次得到的均值,設(shè)備在私有數(shù)據(jù)集上的本地訓(xùn)練輪數(shù)設(shè)置為30,一次訓(xùn)練選取的樣本數(shù)為128。式(8)中的系數(shù)q1 =0. 141,q2 =0. 746 2。
4. 2 性能評(píng)估
本節(jié)通過(guò)仿真驗(yàn)證所提出的聚合自適應(yīng)半同步聯(lián)邦學(xué)習(xí)資源優(yōu)化算法的性能。
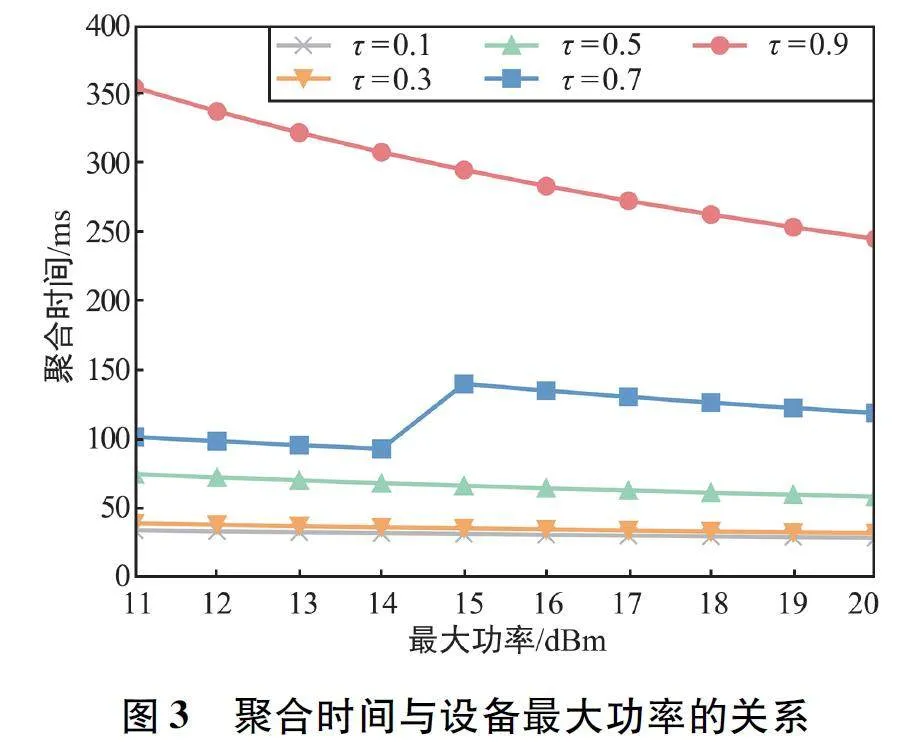
圖3 為所提算法在不同偏好參數(shù)τ 下,聚合時(shí)間隨用戶(hù)設(shè)備最大功率pmaxn 變化的對(duì)比圖,量綱系數(shù)αE 設(shè)置為1。可以看出,整體上,不同偏好參數(shù)所表示的曲線呈遞減趨勢(shì),說(shuō)明其聚合時(shí)間Taggr 隨著設(shè)備最大功率的增加逐漸下降。對(duì)于τ = 0. 7 的曲線,聚合時(shí)間在設(shè)備最大功率從14 dBm 增大為15 dBm 時(shí)發(fā)生上升現(xiàn)象,說(shuō)明最大功率的改變使得調(diào)度策略發(fā)生變化,有新的用戶(hù)被選擇上傳模型。此外,τ= 0. 1 和τ = 0. 3 的曲線基本重合,說(shuō)明在這兩種情況下,調(diào)度策略相同。
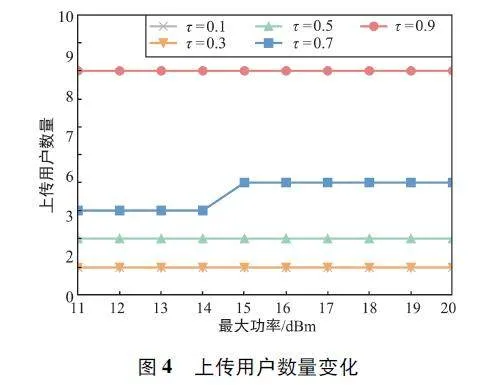
圖4 為所提算法在不同偏好參數(shù)τ 下,上傳用戶(hù)數(shù)量隨用戶(hù)設(shè)備最大功率pmaxn 變化的對(duì)比圖,量綱系數(shù)αE 設(shè)置為1。可以看出,對(duì)于τ = 0. 7 的曲線,在設(shè)備最大功率從14 dBm 增大為15 dBm 時(shí),上傳用戶(hù)數(shù)量從3 增加到了4,證明了圖3 中τ =0. 7的曲線發(fā)生變化的原因。此外,τ=0. 1 和τ =0. 3 的曲線發(fā)生重合,上傳用戶(hù)數(shù)量都為1,證明了圖3 中τ=0. 1 和τ=0. 3 的曲線基本重合的原因。
為驗(yàn)證所提算法中資源分配策略和調(diào)度策略的有效性,將所提算法與以下算法進(jìn)行對(duì)比:
① 基于設(shè)備全調(diào)度的資源分配算法(對(duì)比算法1):基于所提算法,采用選擇所有設(shè)備參與聯(lián)邦學(xué)習(xí)的方案,并利用算法為設(shè)備分配帶寬與功率。
② 基于設(shè)備全調(diào)度的等帶寬資源分配算法(對(duì)比算法2):基于所提算法,且所有設(shè)備均分參數(shù)服務(wù)器的可分配總帶寬B。
③ 基于所提算法的等帶寬資源分配算法(對(duì)比算法3):基于所提算法調(diào)度設(shè)備,且所有設(shè)備均分參數(shù)服務(wù)器的可分配總帶寬B。
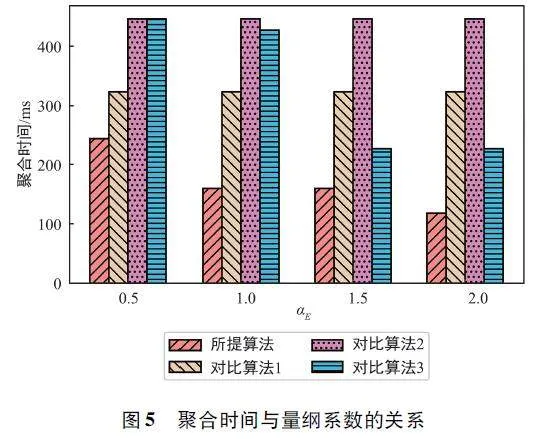
圖5 為不同算法在不同量綱系數(shù)αE 下的聚合時(shí)間對(duì)比圖,設(shè)置偏好系數(shù)τ = 0. 8。可以看出,和對(duì)比算法相比,所提算法在不同量綱系數(shù)下的聚合時(shí)間均為最小值。當(dāng)αE = 0. 5 時(shí),所提算法與表現(xiàn)最差的對(duì)比算法之間的差異最小,聚合時(shí)間降低了42% ;當(dāng)αE =2. 0 時(shí),所提算法與表現(xiàn)最差的對(duì)比算法之間的差異最大,聚合時(shí)間降低了72% 。此外,對(duì)比算法1 和對(duì)比算法2 的聚合時(shí)間不受量綱系數(shù)αE 的影響,原因是這兩個(gè)算法沒(méi)有在模型準(zhǔn)確度和聚合時(shí)間之間進(jìn)行平衡,設(shè)備全部參與調(diào)度,模型準(zhǔn)確度固定。對(duì)于對(duì)比算法3,由于采用了所提算法中的調(diào)度策略,在不同量綱系數(shù)αE 下選擇上傳的用戶(hù)數(shù)不同,聚合時(shí)間也就不同。
圖6 為不同算法在不同量綱系數(shù)αE 下的準(zhǔn)確度對(duì)比圖,設(shè)置偏好系數(shù)τ = 0. 8。由于本文的算法是以犧牲模型性能為代價(jià),所以在圖6 中,與設(shè)備全調(diào)度的對(duì)比算法1 和對(duì)比算法2 相比,所提算法在不同量綱系數(shù)αE 下的模型性能均會(huì)出現(xiàn)不同程度的下降。當(dāng)αE =0. 5 時(shí),所提算法的模型準(zhǔn)確度下降最少,降低了1. 8% ;當(dāng)αE =2. 0 時(shí),所提算法的模型準(zhǔn)確度下降最多,降低了4% 。與對(duì)比算法3 相比,所提算法在αE 為0. 5 和1. 0 時(shí)準(zhǔn)確度較小,因?yàn)樗崴惴▋?yōu)化了模型性能和聚合時(shí)間之間的加權(quán)和,所以性能的降低是為了實(shí)現(xiàn)更低的延遲。
5 結(jié)束語(yǔ)
針對(duì)移動(dòng)邊緣網(wǎng)絡(luò)環(huán)境中現(xiàn)有的聯(lián)邦學(xué)習(xí)框架難以滿(mǎn)足不同的訓(xùn)練任務(wù)偏好的問(wèn)題,本文提出了基于自適應(yīng)聚合時(shí)間的半同步聯(lián)邦資源優(yōu)化算法。該算法使用權(quán)重因子,在模型準(zhǔn)確度和聚合時(shí)間方面對(duì)不同的訓(xùn)練任務(wù)偏好進(jìn)行建模,充分考慮了設(shè)備異構(gòu)性、可用帶寬資源和信道條件等因素,自適應(yīng)地設(shè)置合理的聚合時(shí)間以選擇部分用戶(hù)上傳模型,同時(shí)為這些用戶(hù)分配帶寬、設(shè)置功率。仿真實(shí)驗(yàn)證明所提算法能夠以損失4% 模型性能為代價(jià),降低73% 的聚合時(shí)間,實(shí)現(xiàn)了模型性能和延遲之間的平衡,顯著地提升了通信效率。
參考文獻(xiàn)
[1] MCMAHAN H B,MOORE E,RAMAGE D,et al. Communicationefficient Learning of Deep Networks from Decentralized Data[C]∥The 20th International Conference onArtificial Intelligence and Statistics. Ft Lauderdale:JMLR,2017:1273-1282.
[2] 孫兵,劉艷,王田,等. 移動(dòng)邊緣網(wǎng)絡(luò)中聯(lián)邦學(xué)習(xí)效率優(yōu)化綜述[J]. 計(jì)算機(jī)研究與發(fā)展,2022,59 (7):1439-1469.
[3] HAEBUMBACH R,HEYMANN J,DRUDE L,et al. Farfield Automatic Speech Recognition [J]. Proceedings ofthe IEEE,2021,109(2):124-148.
[4] PRIANDIKA A T,PERMATA P,GUNAWANR D,et al.Video Editing Training to Improve the Quality of Teachingand Learning at SMK Palapa Bandarlampung[J]. Journalof Engineering and Information Technology for CommunityService,2022,1(2):26-30.
[5] CHEN X X,WANG X M,ZHANG K C,et al. Recent Advances and Clinical Applications of Deep Learning inMedical Image Analysis [J]. Medical Image Analysis,2022,79:102444.
[6] BARRA S,CARTA S M,CORRIGA A,et al. DeepLearning and Time SeriestoImage Encoding for FinancialForecasting[J]. IEEE/ CAA Journal of Automatica Sinica,2020,7(3):683-692.
[7] ZENG Q S,DU Y Q,HUANG K B,et al. EnergyefficientRadio Resource Allocation for Federated Edge Learning[C]∥2020 IEEE International Conference on Communications Workshops (ICC Workshops). Montreal:IEEE,2020:1-6.
[8] ZHOU X Y,ZHAO J,HAN H M,et al. Joint Optimizationof Energy Consumption and Completion Time in FederatedLearning[C]∥2022 IEEE 42nd International Conferenceon Distributed Computing Systems (ICDCS). Bologna:IEEE,2022:1005-1017.
[9] KIM J,KIM D,LEE J,et al. A Novel Joint Dataset andComputation Management Scheme for EnergyefficientFederated Learning in Mobile Edge Computing[J]. IEEEWireless Communications Letters,2022,11(5):898-902.
[10]JIANG Z F,WANG W,LI B C,et al. Pisces:EfficientFederated Learning via Guided Asynchronous Training[C]∥ The 13th Symposium on Cloud Computing. NewYork:ACM,2022:370-385.
[11]PAN C,WANG Z,LIAO H J,et al. AsynchronousFederated Deep Reinforcement Learningbased URLLCaware Computation Offloading in Spaceassisted VehicularNetworks[J]. IEEE Transactions on Intelligent Transportation Systems,2023,24(7):7377-7389.
[12]XU C H,QU Y Y,XIANG Y,et al. AsynchronousFederated Learning on Heterogeneous Devices:A Survey[J]. Computer Science Review,2023,50:100595.
[13]YOU C Q,FENG D Q,GUO K,et al. SemisynchronousPersonalized Federated Learning Over Mobile Edge Networks[J]. IEEE Transactions on Wireless Communications,2023,22(4):2262-2277.
[14]CIMINI L. Analysis and Simulation of a Digital MobileChannel Using Orthogonal Frequency Division Multiplexing[J]. IEEE Transactions on Communications,1985,33(7):665-675.
[15]SKLAR B. Rayleigh Fading Channels in Mobile DigitalCommunication Systems. I. Characterization [J ]. IEEECommunications Magazine,1997,35(9):136-146.
[16]REN J K,YU G D,DING G Y. Accelerating DNNTraining in Wireless Federated Edge Learning Systems[J]. IEEE Journal on Selected Areas in Communications,2020,39(1):219-232.
[17]MISENER R,FLOUDAS C A. ANTIGONE:Algorithms forcoNTinuous / Integer Global Optimization of NonlinearEquations[J]. Journal of Global Optimization,2014,59(2-3):503-526.
[18]KUHN H W,TUCKER A W. Nonlinear Programming[M]∥GASS S I,FU M C. Traces and Emergence of Nonlinear Programming. Basel:Springer Basel,2013:247-258.
作者簡(jiǎn)介:
李 鐵 男,(1999—),碩士研究生。主要研究方向:邊緣計(jì)算、聯(lián)邦學(xué)習(xí)。
莊 琲 女,(2000—),碩士研究生。主要研究方向:邊緣計(jì)算、聯(lián)邦學(xué)習(xí)。
林尚靜 女,(1986—),博士,講師。主要研究方向:邊緣計(jì)算、分布式計(jì)算、深度學(xué)習(xí)。
韓志博 女,(1999—),碩士研究生。主要研究方向:邊緣計(jì)算、聯(lián)邦學(xué)習(xí)。
基金項(xiàng)目:湖北省工程研究中心2024 年開(kāi)放課題
猜你喜歡
軟件導(dǎo)刊(2016年9期)2016-11-07 21:56:29
軟件導(dǎo)刊(2016年9期)2016-11-07 21:32:45
中國(guó)科技博覽(2016年22期)2016-11-01 15:02:01
中國(guó)科技博覽(2016年22期)2016-11-01 13:21:09
中國(guó)科技博覽(2016年19期)2016-10-19 14:58:22
電腦知識(shí)與技術(shù)(2016年21期)2016-10-18 22:33:02
科技視界(2016年22期)2016-10-18 17:23:30
中國(guó)新通信(2016年16期)2016-10-18 11:01:39
中國(guó)新通信(2016年16期)2016-10-18 11:00:54
科學(xué)與財(cái)富(2016年28期)2016-10-14 01:24:06
