基于卷積與自注意力的紅外與可見光圖像融合
2024-11-26 00:00:00陳曉萱徐書胡紹海馬曉樂
系統工程與電子技術 2024年8期
關鍵詞:深度學習
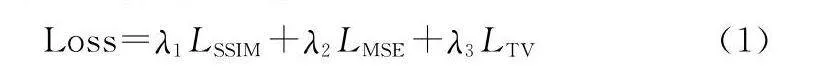

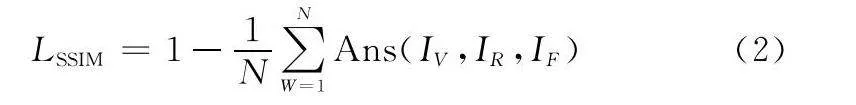






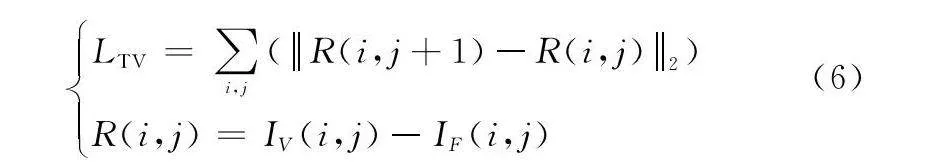
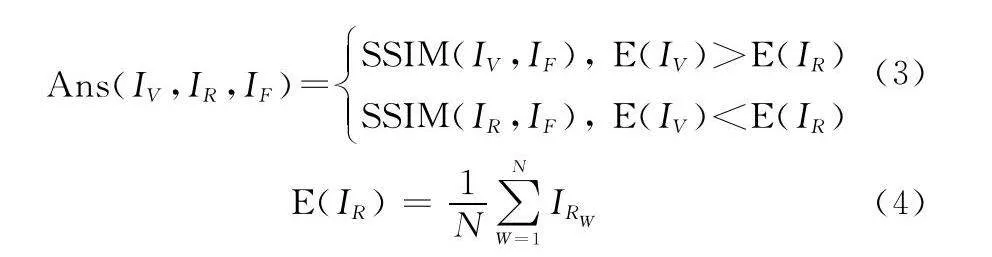
摘 要: 由于卷積運算過于關注圖像的局部特征,在對源圖像進行融合時容易造成融合圖像的全局語義信息丟失。為了解決該問題,提出一種基于卷積與自注意力的紅外與可見光圖像融合模型。該模型在使用卷積模塊提取圖像局部特征的同時,還使用自注意力來提取圖像全局特征。此外,由于簡單運算無法滿足不同層次特征的融合,提出使用嵌入式塊殘差融合模塊來實現多層次特征融合。實驗結果表明,相比無監督深度融合算法,所提的方法在主觀評價與6項客觀指標上的結果具有一定優勢。其中,互信息、標準差和視覺保真度分別提升了6133%、9.96%和19.46%。
關鍵詞: 圖像融合; 全局特征; 自注意力機制; 自編碼器; 深度學習
中圖分類號: TN 911.73
文獻標志碼: A
DOI:10.12305/j.issn.1001-506X.2024.08.12
Infrared and visible light image fusion based on convolution and self attention
CHEN Xiaoxuan1, XU Shuwen2, HU Shaohai1,*, MA Xiaole1
(1. School of Computer and Information Technology, Beijing Jiaotong University, Beijing 100044, China; 2. Research
Institute of TV and Electro-Acoustics, China Electronics Technology Group Corporation, Beijing 100015, China)
Abstract: As convolution operation pays too much attention to local features of an image, which easily cause the loss of the global semantic information of the fused image when fusing source images. To solve this problem, an infrared and visible light image fusion model based on convolution and self attention is proposed in this paper. In the proposed model, convolution module is adopted to extract local features of image, and self attention is adopted to extract global features. In addition, since the simple operation cannot handle the fusion of features at different levels, the embedded block residual fusion module is proposed to realize the multi-layer feature fusion. Experimental results demonstrate that the proposed method has superiority over the unsupervised deep fusion algorithms in both subjective evaluation and six objective metrics, among which the mutual information, standard deviation, and visual fidelity are improved by 61.33%, 9.96%, and 19.46%, respectively.
Keywords: image fusion; global features; self attention; auto-encoder; deep learning
0 引 言
紅外相機是通過測量圖像向外輻射的熱量成像,因此圖像具有很強的抗干擾能力,但仍存在噪聲較強、對比度較低等缺點[1]。可見光相機通過捕獲反射光成像,其圖像具有分辨率較高、清晰度較高的特點,但其對于惡劣條件不具有抵抗能力[2]。利用紅外與可見光圖像的互補特性對其進行融合,可以獲得健壯且信息量豐富的融合圖像[3]。因此,紅外與可見光圖像融合如今已廣泛應用于高級視覺任務,在計算機視覺領域發揮著越來越重要的作用[4]。
近年來,隨著深度學習領域的不斷突破,越來越多的學者選擇使用基于深度學習的方法來解決圖像融合問題。文獻[5]通過訓練一個卷積神經網絡(convolutional neural network, CNN),首次將基于深度學習的方法引入到圖像融合領域。該方法解決了傳統方法需要手動設計活動水平測量與融合規則的問題。文獻[6]首次將自編碼器作為融合框架,使用多個卷積層取代全連接層,從而大大提高了融合效率。同樣,文獻[7]將生成對抗網絡(generative adversarial network, GAN)作為融合框架,建立了生成器與判別器之間的對抗博弈,從而解決該無監督問題。
然而,當前基于深度學習的圖像融合方法仍存在一些亟待解決的問題,例如卷積運算的局限性、融合的客觀評價體系不完善、融合的實用目的尚未挖掘等。在特征提取過程中,雖然卷積運算有著其他方法無可比擬的優勢,但其只能挖掘感受野內的交互,難于對長程依賴進行捕獲[8]。文獻[9]提出全局特征編碼U型網絡,引入了全局特征金字塔提取模塊,有效地提取和利用了全局語義信息和邊緣信息。在特征融合過程中,由于手動設計融合規則容易導致融合結果不理想,因此如何利用深度學習的方法合理設計融合模塊,也成為圖像融合領域值得關注的問題。受上述啟發,本文創新點如下。
(1) 本文提出了一個新穎的基于卷積與自注意力的紅外與可見光圖像融合模型。該模型可以兼顧局部特征與全局特征的保留,降低上采樣特征損失造成的影響。
(2) 為了解決單一融合模塊無法適應圖像不同頻率特征融合的問題,本文提出了嵌入式塊殘差融合模塊。其淺層意在融合圖像的低頻特征,深層意在融合圖像的高頻特征。
(3) 所提出的融合模型在紅外與可見光圖像的多個數據集中得到了目標顯著、紋理豐富的融合結果,并具有不錯的泛化能力。將融合圖像應用于目標檢測任務中,結果證明本文所提方法具有一定的實際應用價值。
1 自注意力機制
全局特征是指圖像的整體屬性,其主要包括顏色特征、紋理特征和形狀特征等。局部特征則是從圖像局部區域中提取的特征,其主要包括邊緣特征和特別屬性的區域等[10]。由于傳統的卷積運算是基于窗口實現的,難以捕獲長程依賴,容易忽視對全局特征的提取。
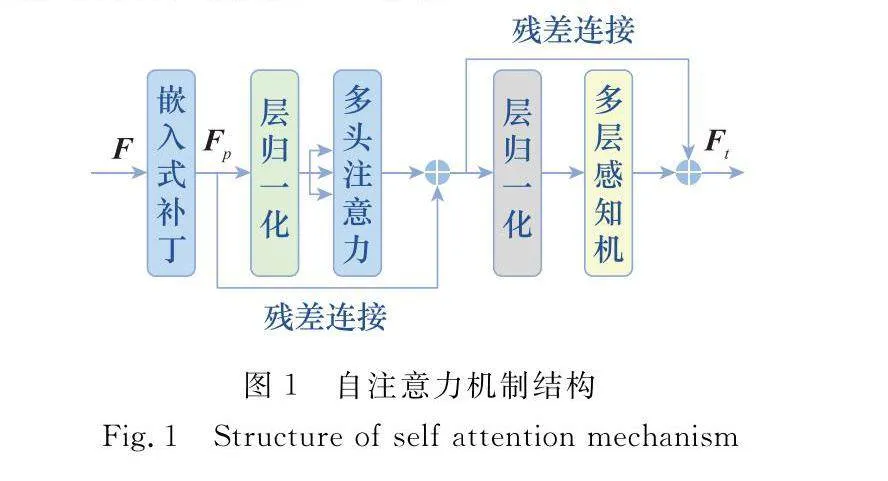
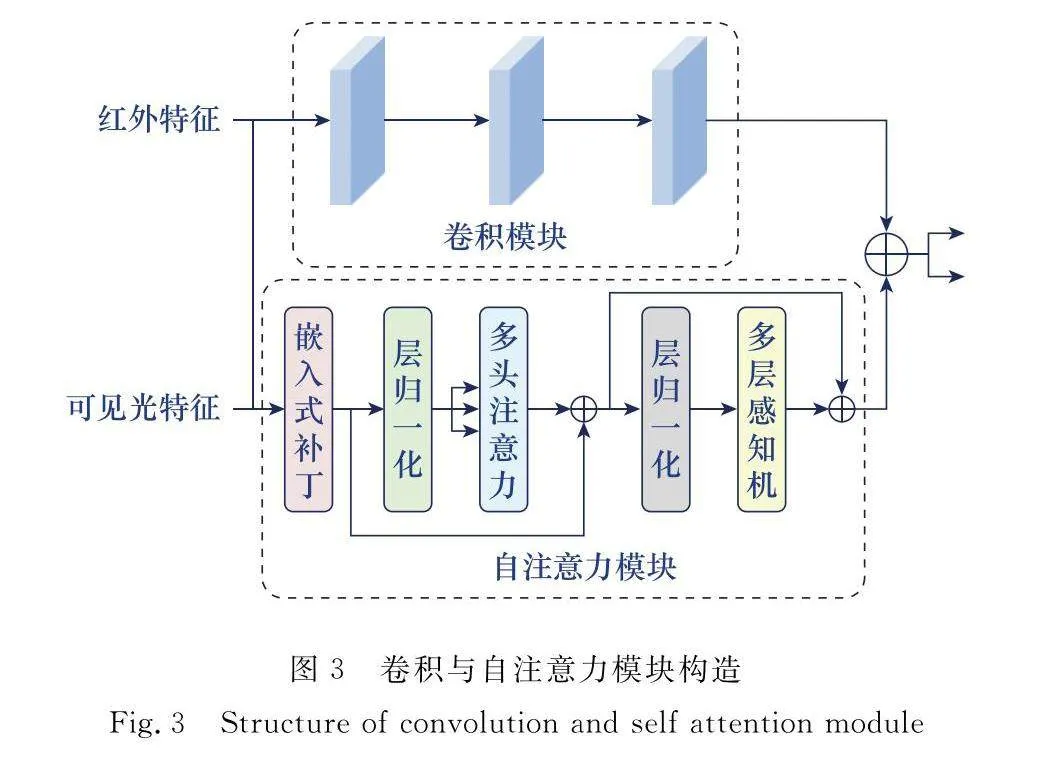
文獻[11]指出,自注意力機制擁有提取圖像全局特征的能力。受此啟發,本文試圖在特征提取部分引入自注意力機制,其具體構造如圖1所示。
自注意力機制主要由以下幾個部分構成:兩個層歸一化、多頭注意力[12]、多層感知機。多頭注意力通過將多個注意力拼接在一起,彌補了自注意力機制過多地將注意力集中于自身位置的缺陷,實現了基于單一注意力學習多種行為。多層感知機就是由全連接層組成的神經網絡,且每個隱藏層的輸出通過激活函數進行變換。在多頭注意力和多層感知機之前本文應用了層歸一化,之后應用了殘差連接。
特征圖F輸入到自注意力機制時,需要先將其破壞,分割成M個一維的補丁Fp,其中M=(H×W)/(P×P),P表示分割后補丁的大小。之后,將這M個一維的補丁進行自注意力機制運算。特征F∈RH×W經過自注意力機制的處理后得到Ft∈RH×W。
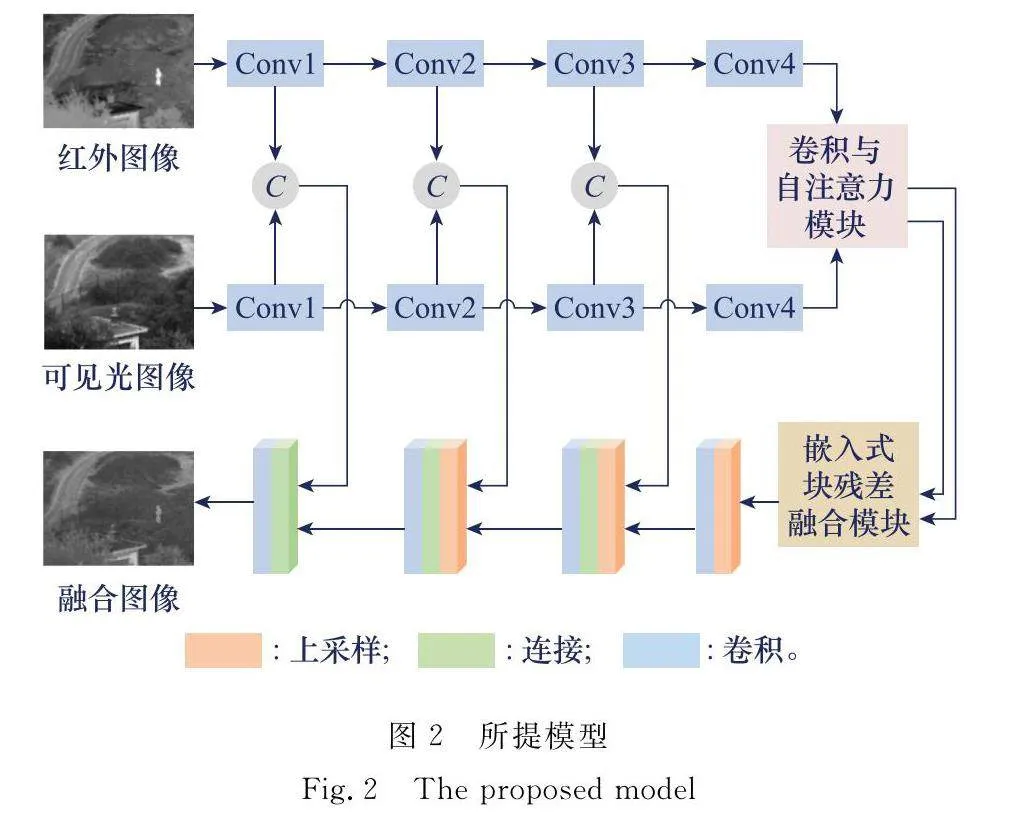
2 所提出的模型
本文針對紅外與可見光圖像融合提出了一個新穎的模型,其具體構造如圖2所示。該模型使用改良后的U型網絡(U-Net)作為融合的基本框架,其具體流程為:紅外與可見光圖像分別經過編碼器的處理,將下采樣后的特征送入卷積與自注意力模塊,得到圖像局部特征與全局特征,之后將其送入融合層。在深層融合特征的指導下,完成淺層特征的上采樣重建,得到最終的融合圖像。
在下采樣與上采樣之間進行跳躍連接時,容易發生大小不匹配的情況。這里本文使用轉置卷積的out_padding參數來控制輸出特征的大小。當特征圖大小為奇數時,out_padding=0;當特征圖大小為偶數時,out_padding=1。
2.1 卷積與自注意力模塊
由于卷積運算專注局部特征的提取,為了使融合圖像既包含局部特征又包含全局特征,本文需要設計一個模塊來挖掘感受野內的交互[13]。受文獻[14]的啟發,本文在特征提取部分使用卷積模塊與自注意力模塊并聯的方式來提取圖像全局特征與局部特征,其具體構造如圖3所示。
本文使用3個3×3的卷積層相串聯,用于提取圖像中的局部特征。之后將卷積模塊的輸出結果與自注意力模塊的輸出結果在通道層相疊加,并繼續向后續模塊進行傳遞。
2.2 嵌入式塊殘差融合模塊
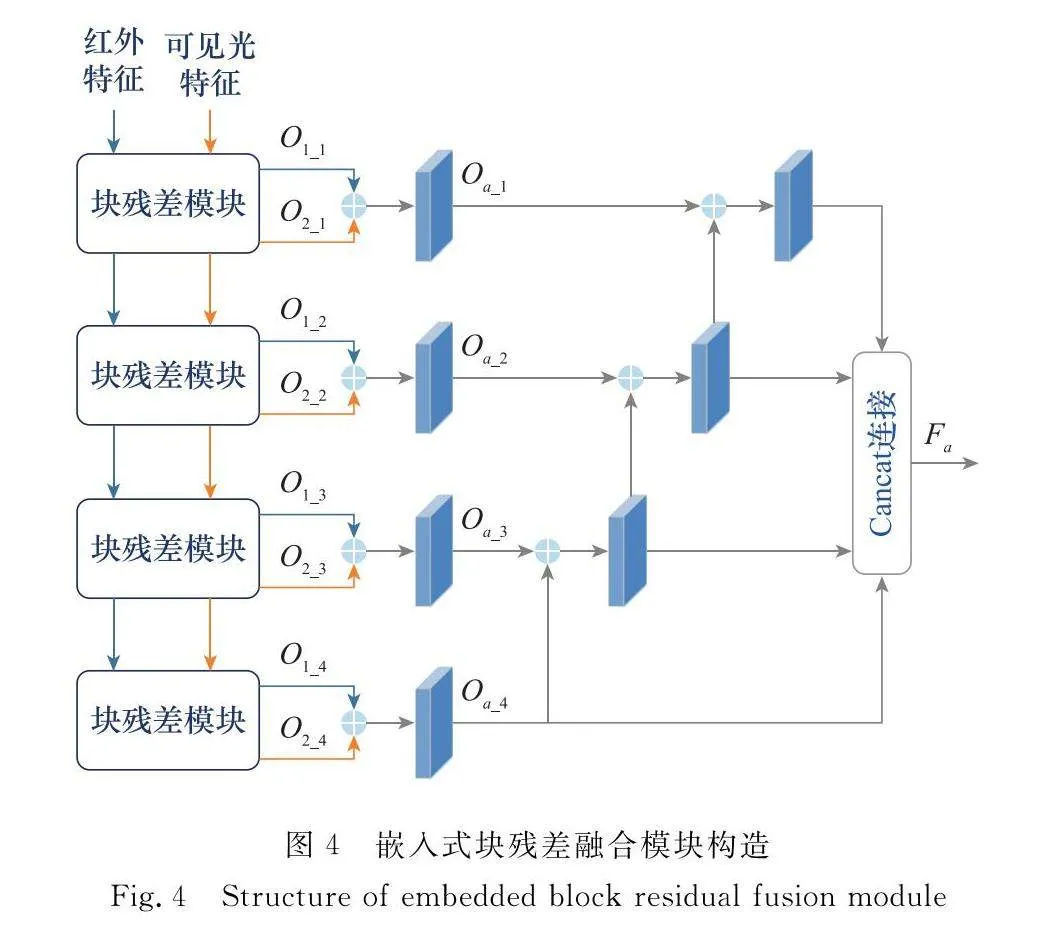
傳統的融合層一般采用直接或加權相加的方式,這種不具備針對性的方式容易造成特征丟失,嚴重影響圖像融合質量[15]。受文獻[16]提出的用于提高分辨率的模型啟發,本文提出了嵌入式塊殘差融合模塊,用于融合不同層次的頻率分量,其具體構造如圖4所示。
嵌入式塊殘差融合模塊由n個塊殘差模塊構成,且以嵌入式的方式進行排列。其中,塊殘差模塊的具體構造如圖5所示。該模塊分為兩部分,分別為上采樣投影流和下采樣投影流。上采樣投影流通過一個反卷積層實現特征上采樣,再經過3個卷積層得到輸出。下采樣投影流則是將反卷積后的特征進行下采樣,再與源特征圖相減,來獲取上采樣投影流無法處理的較高頻率的特征。之后,將相減后的結果送入殘差層,作為下一個塊殘差模塊的輸入。
如圖4所示,特征融合過程可以概括為以下幾個步驟:輸入的紅外與可見光特征經過塊殘差模塊的處理,得到對應的上采樣投影流與下采樣投影流。下采樣投影流向下繼續進行傳遞,而上采樣投影流的結果O1_i和O2_i(i=1,2,3,4)以遞歸融合的方式,在通道層疊加之后再經過卷積模塊的處理,得到Oa_i(i=1,2,3,4)。最后,將遞歸融合后的結果再次在通道層相疊加,得到融合特征。如此即可實現多層次特征融合。
2.3 損失函數
本文設計的混合損失函數如下所示:
Loss=λ1LSSIM+λ2LMSE+λ3LTV(1)
該損失函數由內容損失以及總變分 (total variation, TV) 損失構成,內容損失由結構相似性指數(structural similarity index, SSIM)與均方誤差(mean squared error, MSE)損失構成。其中,λ1設置為300,λ2和λ3被設置為1。
SSIM損失公式定義如下:
LSSIM=1-1N∑NW=1Ans(IV,IR,IF)(2)
式中:N表示圖像像素數;IV表示可見光圖像;IR表示紅外圖像;IF表示融合圖像。由于本文提出的是一種無監督的訓練方式,因此本文使用Ans(·)來判別SSIM損失作用的對象。
Ans(IV,IR,IF)=SSIM(IV,IF), E(IV)gt;E(IR)
SSIM(IR,IF), E(IV)lt;E(IR)(3)
E(IR)=1N∑NW=1IRW(4)
式中:E表示局部窗口中像素的平均強度。式(3)說明,當可見光圖像的像素平均強度高于紅外圖像時,本文選擇可見光圖像與融合圖像之間的SSIM來計算損失;反之則選擇紅外圖像與融合圖像之間的SSIM來計算損失。
MSE損失的公式定義如下:
LMSE=ω1MSE(IV,IF)+ω2MSE(IR,IF) (5)
式中:ω1與ω2 被設置為0.5。
本文使用TV損失來消減噪聲對融合圖像的影響,其公式定義如下:LTV=∑i,j(R(i,j+1)-R(i,j)2)
R(i,j)=IV(i,j)-IF(i,j)(6)
式中:i,j分別表示圖像像素的行與列數;·表示L2范數。
3 實驗結果與分析
3.1 實驗設置
在訓練集方面,為了獲取數量龐大且健壯的紅外與可見光圖像對作為訓練集,本文從TNO數據集中隨機選取25對紅外與可見光圖像,并從每對圖像中隨機取1 000對64×64的圖像塊。這樣所構造的數據集就包含了25 000對紅外與可見光圖像,數目足以滿足模型訓練的條件。之后,對構建的數據集隨機左右翻轉進行圖像增強,就得到了用于訓練的紅外與可見光圖像對。
在測試集方面,為了驗證本文所提出的方法不受數據集的限制且具有不錯的泛化性能,本文在多個紅外與可見光圖像數據集上進行實驗驗證。本文所采用的數據集有:TNO數據集[17]、LLVIP數據集[18]、M3FD數據集[19]。TNO數據集側重于自然場景,LLVIP數據集側重于夜晚交通場景,M3FD側重于城市小目標場景。本文取以上3種數據集各25對進行實驗驗證。
該實驗的訓練階段與測試階段是在TITAN_X_Pascal上執行的,并且本實驗使用
PyTorch環境。本文選擇Adam優化器進行迭代優化,設置batch_size的值為8,設置學習率的值為0.001,設置epoch的值為100。
3.2 主觀評價
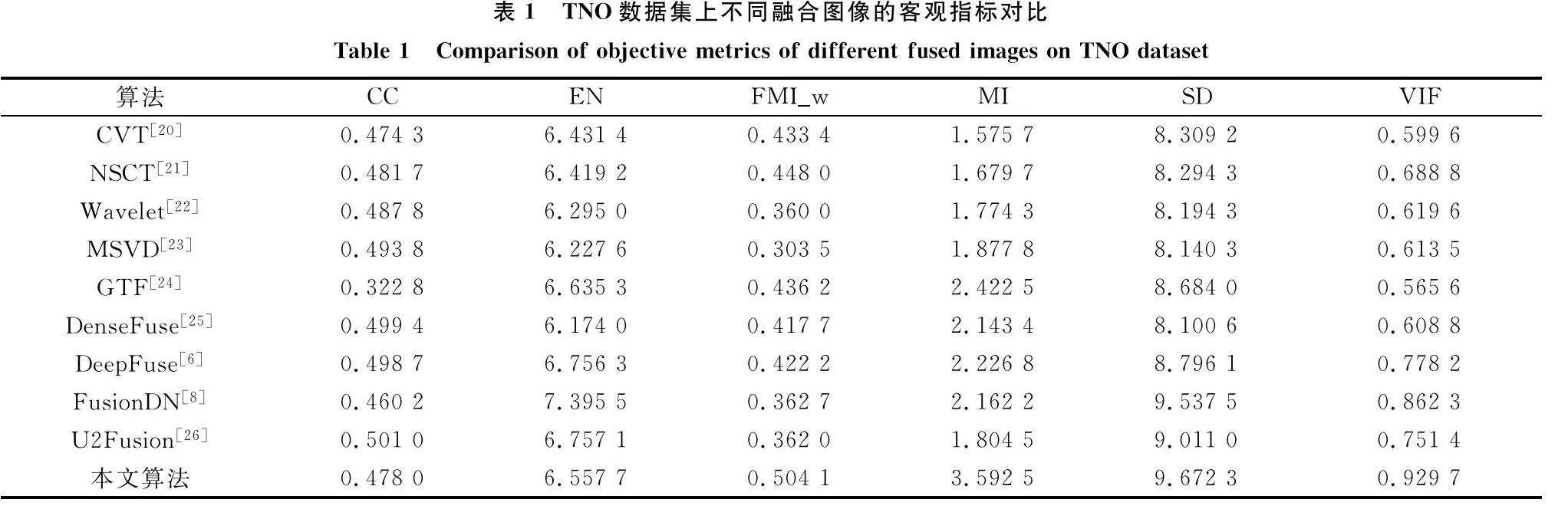
本文選擇了9種經典融合算法作為對比實驗,分別是:曲波變換(curvelet transform, CVT)[20]、非下采樣輪廓波變換(nonsubsampled contourlet transform, NSCT)[21]、小波變換(wavelet transform, Wavelet)[22]、多分辨率單值分解(multi-resolution singular value decomposition, MSVD)[23]、引導濾波(gradient filter, GTF)[24]、密集塊融合(dense block fusion, densefuse)[25]、無監督深度融合(unsupervised deep fusion, Deepfuse)[6]、密集連接融合(densely connected fusion, FusionDN)[8]、統一的無監督融合(unified unsupe-rvised fusion, U2Fusion)[26]。其中,CVT、NSCT、Wavelet、MSVD、GTF屬于傳統方法,Densefuse、Deepfuse、FusionDN、U2Fusion屬于基于深度學習的方法。以上對比實驗的代碼在網絡上均可找到。
圖6展示的是在3個數據集上本文所提方法與源圖像以及其他經典融合方法對比的結果。其中前兩列、中間兩列、最后兩列分別表示在TNO數據集、LLVIP數據集以及M3FD數據集上的主觀圖像對比結果。為了更好地對比,本文在圖中用紅色框與綠色框標注放大區域。相較于源圖像,融合圖像既能保留紅外圖像中顯著的熱輻射信息且不受惡劣視覺條件的影響,同樣也可以保留可見光圖像中豐富的紋理細節信息。如圖6第一列所示,融合的難點在于樹下的行人以及脈絡清晰的樹干。圖6(c)~圖6(e)人影較為模糊,圖6(f)樹干脈絡不夠清晰。圖6第二列中雖然GTF可以得到飛機目標較為顯著的圖像,但云層細節丟失嚴重。相比較而言,本文所提出的方法具有一定優勢。接著,在LLVIP數據集與M3FD數據集上驗證所提融合方法在主觀評價方面的泛化能力。圖6(c)~圖6(h)、圖6(k)中信號燈的對比度不高,缺失一部分細節。圖6(e)~圖6(i)中紅色框內植物細節較為模糊,而圖6(c)~圖6(h)中密集人影目標不夠顯著。綜上,本文所提出的方法能夠獲得豐富紋理細節與顯著熱輻射信息,且具有一定泛化能力。
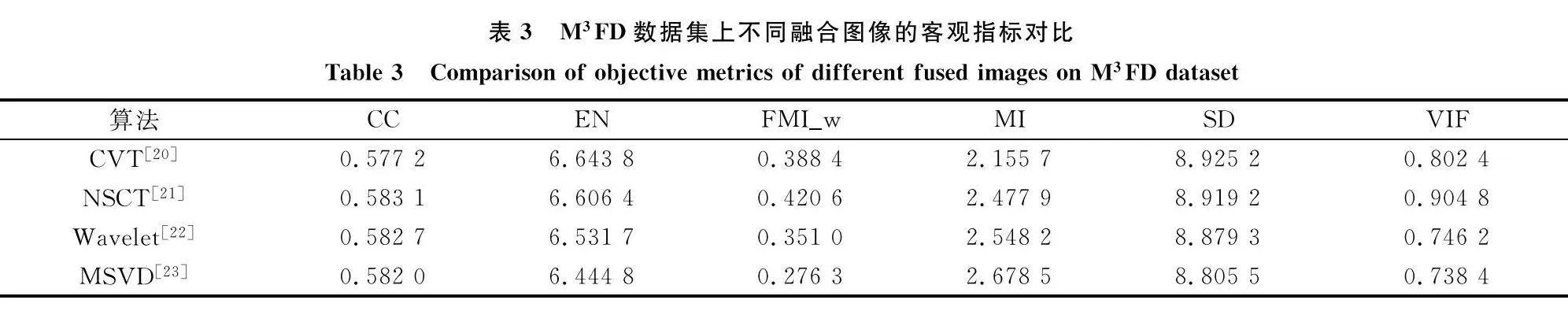
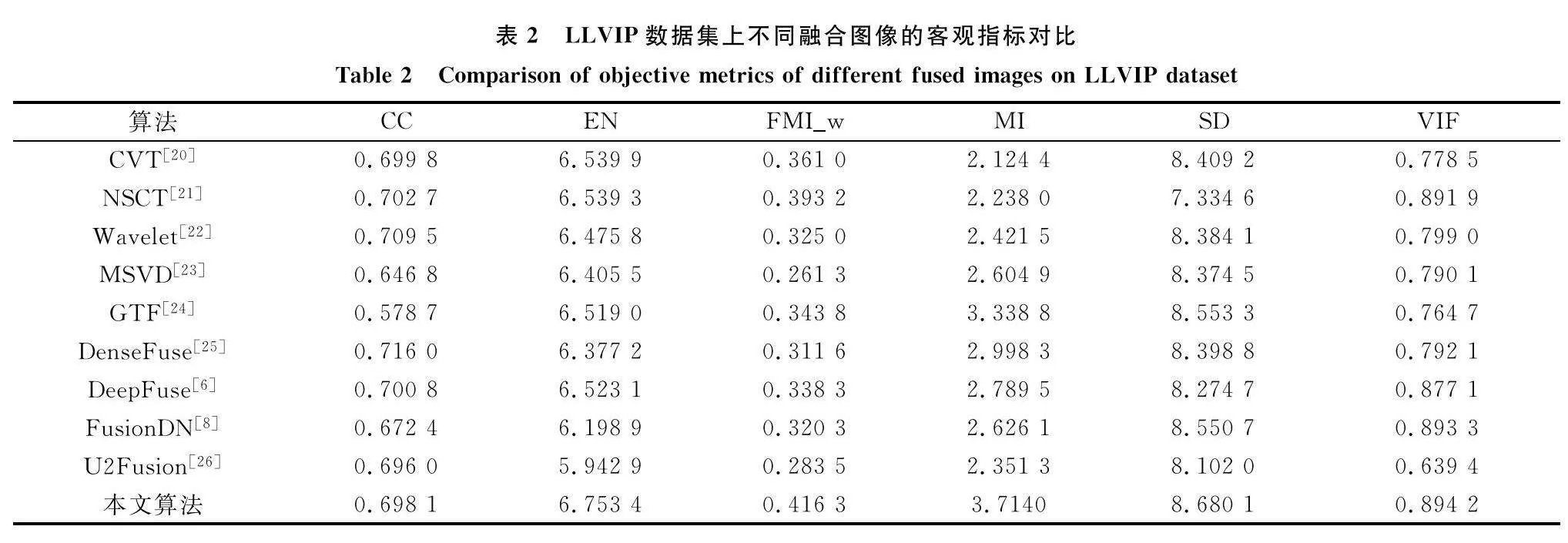
3.3 客觀評價
為了進一步闡述該模型在紅外與可見光圖像融合方面的優越性,本文使用客觀指標來對比不同融合算法。本文所采用的指標有:相關系數CC、信息熵EN、小波特征的互信息FMIw、互信息MI、標準差SD、視覺保真度VIF。以上指標從與源圖像的相關性、圖像本身的質量等方面入手,使數據更具備說服力。
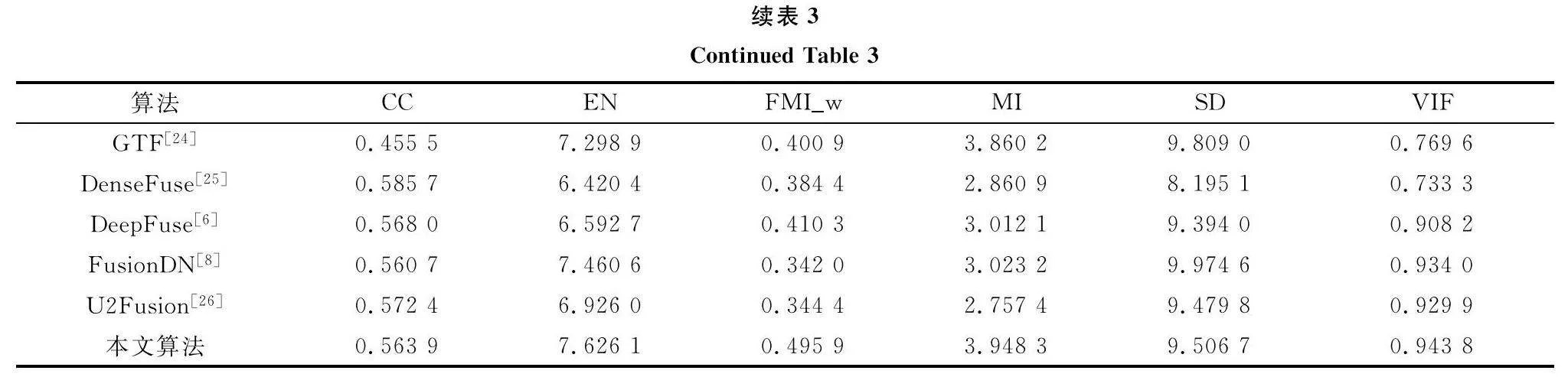
如表1所示,本文所提出的方法在其中4個指標(FMIw、MI、SD、VIF)取得了最優的結果。FusionDN雖然在EN上實現了最優,但其在MI等指標上表現不佳。同樣的,在LLVIP數據集上的實驗結果如表2所示。可以觀察到,本文所提方法在其中的5個指標(EN、FMIw、MI、SD、VIF)取得了最優值。從表3中可以觀察到本文所提方法在M3FD數據集上能夠在其中的4個指標(EN、FMIw、MI、VIF)上取得最優值。雖然本文所提方法在CC上未取得過最優值,但仍在強相關的范圍內。綜上,本文所提的方法相比較而言具有不錯的客觀評價結果。
3.4 消融實驗
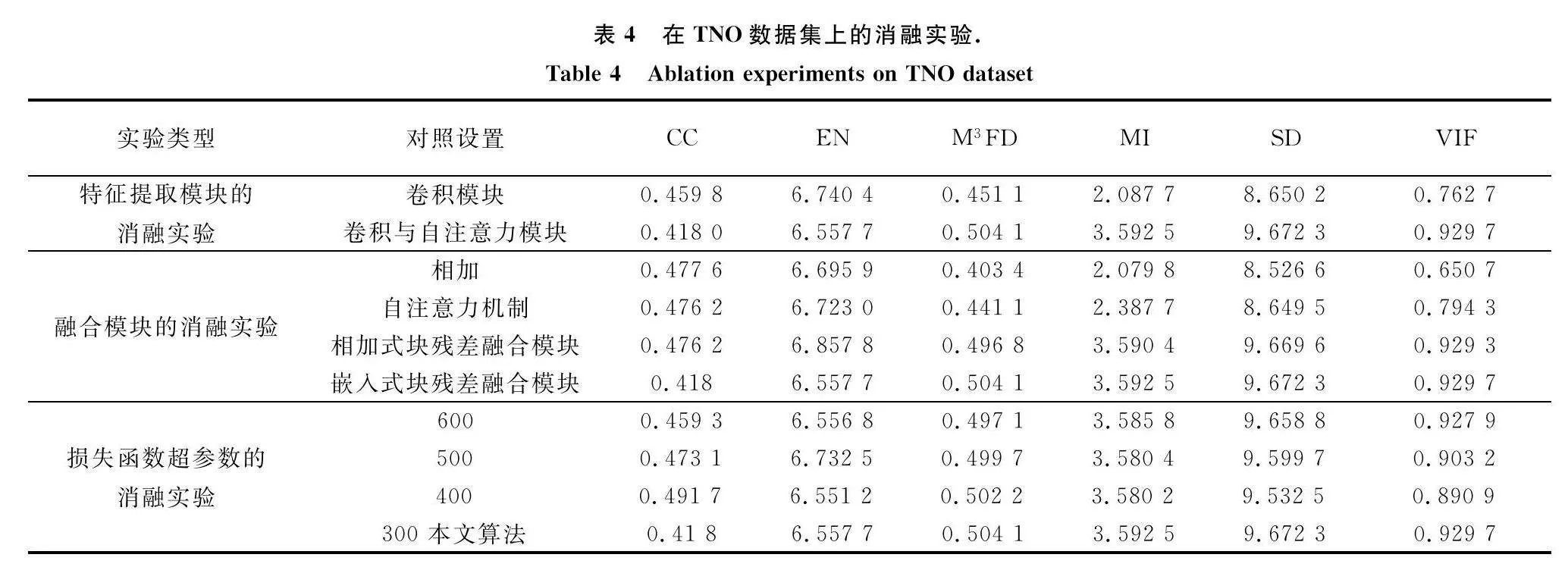
本文共進行3組消融實驗,分別針對所提出的特征提取模塊、融合模塊以及損失函數的超參數設置,其具體結果如表4所示。
首先驗證本文所提出的卷積與自注意力模塊的優越性。將本文所提出的特征提取模塊與卷積模塊相比較,可以在其中4個指標(FMIw、MI、SD、VIF)取得最優的結果。接著驗證本文所提出的嵌入式塊殘差融合模塊在融合紅外與可見光圖像時的優越性。從表4可以觀察到,所提出的融合模塊相較于其他常見融合方法(直接相加、注意力機制),能夠在其中5個指標(EN、FMIw、MI、SD、VIF)取得最優的結果。在損失函數的構建中,需要確定SSIM損失,MSE損失和TV損失所對應的權重,因此本文通過消融實驗來確定λ1參數的最佳取值。從表4還可以觀察到,當λ1取值為300時,相較于其他取值,所得到的融合圖像能夠取得更為優越的客觀評價結果,因此在損失函數中,λ1被設置為300,λ2和λ3被設置為1。
3.5 目標檢測的擴展實驗
為了驗證所提出的方法具有實際的應用價值,本文將源圖像和所得到的的融合圖像應用于目標檢測任務,并且選擇5種經典的目標檢測模型即SSD(single shot detector)[27]、快速區域卷積神經網絡(faster region CNN, Faster RCNN)[28]、YOLO(you only look once)v3[29]、YOLOv4[30]、YOLOvx[31],來驗證不同圖像的檢測性能。在數據集的選擇方面,由于LLVIP數據集大多為夜晚交通場景,包含豐富的熱輻射目標信息,因此本文從該數據集中選擇25組源圖像與融合圖像來驗證。
如圖7所示,檢測難點在于密集的行人目標以及行人所騎車輛。由于夜晚環境下燈光較暗,難以對可見光圖像中的行人進行檢測。紅外圖像由于缺乏車輛細節,容易造成車輛誤檢,將自行車檢測為摩托車。而本文所提方法得到的融合結果相比較而言能夠較為全面地對行人進行檢測。綜上,可以證明本文所提出的融合方法能夠提升目標檢測的精度,具有實際應用價值。
4 結 論
本文提出了一種基于卷積與自注意力的紅外與可見光圖像融合模型。該模型基于改良后的U-Net框架,能夠兼顧全局特征與局部特征的保留,從而豐富融合圖像的細節。在編碼器部分,本文提出了卷積與自注意力模塊來提取圖像全局特征與局部特征。此外,本文還提出了嵌入式塊殘差融合模塊用于融合圖像的不同頻率分量。本文的實驗在TNO數據集、LLVIP數據集和M3FD數據集上進行驗證。大量的對比實驗以及消融實驗表明,所提出的融合方法在主觀評價和客觀評價上均有著良好的表現,且具有不錯的泛化能力,更重要的是,本文所得到的融合圖像能夠提升目標檢測的精度,從而更好地輔助各種高級視覺任務,具有實際應用價值。
自注意力機制具有較深的層次,時間復雜度較高,本文所提出的方法以時間復雜度較低的U-Net作為框架,并且以輕量級的嵌入式塊殘差融合模塊進行融合。雖然這在一定程度上降低了融合的時間復雜度,但仍有改良的空間。這也是今后工作中需要改進的地方,未來將繼續探索如何通過輕量級模塊更好地提取全局特征并且降低時間復雜度的問題。
參考文獻
[1]李舒涵, 許宏科, 武治宇. 基于紅外與可見光圖像融合的交通標志檢測[J]. 現代電子技術, 2020, 43(3): 45-49.
LI S H, XU H K, WU Z Y. Traffic sign detection based on infrared and visible image fusion[J]. Modern Electronics Technique, 2020, 43(3): 45-49.
[2]BIKASH M, SANJAY A, RUTUPARNA P, et al. A survey on region based imagefusion methods[J]. Information Fusion, 2019, 48: 119-132.
[3]李霖, 王紅梅, 李辰凱. 紅外與可見光圖像深度學習融合方法綜述[J]. 紅外與激光工程, 2022, 51(12): 337-356.
LI L, WANG H M, LI C K. A review of deep learning fusion methods for infrared and visible images[J]. Infrared and Laser Engineering, 2022, 51(12): 337-356.
[4]王新賽, 馮小二, 李明明. 基于能量分割的空間域圖像融合算法研究[J]. 紅外技術, 2022, 44(7): 726-731.
WANG X S, FENG X E, LI M M. Research on spatial domain image fusion algorithm based on energy segmentation[J]. Infrared Technology, 2022, 44(7): 726-731.
[5]LIU Y, CHEN X, PENG H, et al. Multi-focus image fusion with a deep convolutional neural network[J]. Information Fusion, 2017, 36: 191-207.
[6]RAM P K, SAI S V, VENKATESH B R. DeepFuse: a deep unsupervised approach for exposure fusion with extreme exposure image pairs[C]∥Proc.of the IEEE International Conference on Computer Vision, 2017: 4714-4722.
[7]MA J Y, YU W, LIANG P W, et al. FusionGAN: a generative adversarial network for infrared and visible image fusion[J]. Information Fusion, 2019, 48: 11-26.
[8]XU H, MA J Y, LE Z L, et al. FusionDN: a unified densely connected network for image fusion[C]∥Proc.of the AAAI Conference on Artificial Intelligence, 2020: 12484-12491
[9]XIAO B, XU B C, BI X L, et al. Global-feature encoding U-Net (GEU-Net) for multi-focus image fusion[J]. IEEE Trans.on Image Processing, 2021, 30: 163-175.
[10]FANG Y M, YAN J B, LI L D, et al. No reference quality assessment for screen content images with both local and global feature representation[J]. IEEE Trans.on Image Processing, 2018, 27(4): 1600-1610.
[11]QU L H, LIU S L, WANG M N, et al. TransMEF: a transformer-based multi-exposure image fusion framework using self-supervised multi-task learning[C]∥Proc.of the AAAI Conference on Artificial Intelligence, 2022: 2126-2134.
[12]MA J Y, TANG L F, FAN F, et al. SwinFusion: cross-domain long-range learning for general image fusion via swin transformer[J]. IEEE/CAA Journal of Automatica Sinica, 2022, 9(7): 1200-1217.
[13]TANG W, HE F Z, LIU Y, et al. DATFuse: infrared and visible image fusion via dual attention transformer[J]. IEEE Trans.on Circuits and System for Video Technology, 2023, 33(7): 3159-3172.
[14]PENG Z L, HUANG W, GU S Z, et al. Conformer: local features coupling global representations for visual recognition[C]∥Proc.of the IEEE/CVF International Conference on Computer Vision, 2021: 367-376.
[15]WANG J X, XI X L, LI D M, et al. FusionGRAM: an infrared and visible image fusion framework based on gradient residual and attention mechanism[J]. IEEE Trans.on Instrumentation and Measurement, 2023, 72: 5005412.
[16]QIU Y J, WANG R X, TAO D P, et al. Embedded block residual network: a recursive restoration model for single-image super-resolution[C]∥Proc.of the IEEE/CVF International Conference on Computer Vision, 2019: 4179-4188.
[17]TOET A. The TNO multiband image data collection[J]. Data in Brief, 2017, 15: 249-251.
[18]JIA X Y, ZHU C, LI M Z, et al. LLVIP: a visible-infrared paired dataset for low-light vision[C]∥Proc.of the IEEE International Conference on Computer Vision, 2021: 3496-3504.
[19]LIU J Y, FAN X, HUANG Z B, et al. Target-aware dual adversarial learning and a multi-scenario multi-modality benchmark to fuse infrared and visible for object detection[C]∥Proc.of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2022: 5802-5811.
[20]EMADALDEN A, UZAIR A B, HUANG M X, et al. Image fusion based on discrete cosine transform with high compression[C]∥Proc.of the 7th International Conference on Signal and Image Processing, 2022: 606-610.
[21]ZHU Z Q, ZHENG M Y, QI G Q, et al. A phase congruency and local laplacian energy based multi-modality medical image fusion method in NSCT domain[J]. IEEE Access, 2019, 7: 20811-20824.
[22]GUO H, CHEN J Y, YANG X, et al. Visible-infrared image fusion based on double-density wavelet and thermal exchange optimization[C]∥Proc.of the IEEE 5th Advanced Information Technology, Electronic and Automation Control Conference, 2021: 2151-2154.
[23]NAIDU VPS. Image fusion technique using multi-resolution singular value decomposition[J]. Defence Science Journal, 2011, 61: 479-484.
[24]MA J Y, CHEN C, LI C, et al. Infrared and visible image fusion via gradient transfer and total variation minimization[J]. Information Fusion, 2016, 31: 100-109.
[25]LI H, WU X J. DenseFuse: a fusion approach to infrared and visible images[J]. IEEE Trans.on Image Processing, 2019, 28(5): 2614-2623.
[26]XU H, MA J Y, JIANG J J, et al. U2Fusion: a unified unsupervised image fusion network[J]. IEEE Trans.on Pattern Analysis and Machine Intelligence, 2022, 44(1): 502-518.
[27]LIU W, DRAGOMIR A, DUMITRU E, et al. SSD: single shot multibox detector[C]∥Proc.of the European Conference on Computer Vision, 2016: 21-37.
[28]REN S Q, HE K M, GIRSHICK R, et al. Faster R-CNN: towards real-time object detection with region proposal networks[J]. IEEE.on Pattern Analysis and Machine Intelligence, 2017, 39(6): 1137-1149.
[29]REDMON J, FARHAD A. Yolov3: an incremental improvement[EB/OL]. [2023-05-29]. http:∥arxiv.org/pdf/1804.02767
[30]ALEXEY B, WANG C Y, LIAO H Y. Yolov4: optimal speed and accuracy of object detection[EB/OL]. [2023-05-29]. https:∥arxiv.org/abs/2004.10934.
[31]GE Z, LIU S T, WANG F, et al. Yolox: exceeding Yolo series in 2021[EB/OL]. [2023-05-29]. https:∥arxiv.org/abs/2107.08430.
作者簡介
陳曉萱(1998—),女,博士研究生,主要研究方向為圖像融合、目標檢測。
徐書文(1954—),女,研究員,博士,主要研究方向為信號處理、信息融合。
胡紹海(1954—),男,教授,博士,主要研究方向為信號處理、信息融合。
馬曉樂(1991—),女,講師,博士,主要研究方向為信號處理、信息融合。
猜你喜歡
中國教育技術裝備(2016年19期)2016-12-27 19:23:52
中國遠程教育(2016年11期)2016-12-27 18:07:31
現代商貿工業(2016年25期)2016-12-26 09:58:02
江蘇教育·中學教學版(2016年11期)2016-12-21 11:45:08
江蘇教育·中學教學版(2016年11期)2016-12-21 11:36:29
現代情報(2016年10期)2016-12-15 11:50:53
考試周刊(2016年94期)2016-12-12 12:15:04
新教育時代·教師版(2016年23期)2016-12-06 06:02:38
法制與社會(2016年32期)2016-12-01 15:25:53
軟件導刊(2016年9期)2016-11-07 22:20:49
