
網絡輿情爬蟲系統關鍵技術研究與應用
2024-12-31 00:00:00王小月
中國新通信 2024年19期
關鍵詞:預防
摘要:在網絡輿情業務監測中,以傳統爬蟲的方式進行監測,容易產生監測效率低、成本高等問題,在此背景下,采用分布式爬蟲技術,能夠對網絡輿情數據進行快速監測,進而進行數據的處理與分析,以此能夠高效率感知輿情信息,進一步提升輿情管控與預防能力。
關鍵詞:網絡輿情;分布式;爬蟲;預防
一、 引言
近年來,我國社會進入社交媒體爆炸式發展的階段,信息的傳播速度極快,網絡輿情信息不僅是一個個熱門話題,更是對政府的感知能力和社會治理能力提出了全新的挑戰[1]。基于該現狀,一款能夠自動獲取網絡輿情信息并對輿情信息進行分析的軟件是相關職能部門迫切需要的。相關職能部門可以通過該系統在海量數據中抓取網民對某事件的評論和情感傾向,來了解并把握群眾的情緒,從而對輿情事件做出更加高效、正確的決策。
二、網絡輿情爬蟲系統關鍵技術
(一)Python開發語言
在信息技術體系的開發中,采用Python語言對網絡爬蟲系統實現的過程進行實現,以此明確需求階段、設計階段與實現階段的工作內容與目標。Python語言與Java語言、C語言是彼此相互獨立,采用開發的方式為面向對象的模式,吸取其他開發語言的優點,能夠指導軟件開發過程[2]。
(二)MongoDB數據庫
信息技術的快速發展,推動了數據存儲、前端開發等技術的進步,能夠完成業務數據信息的存儲與處理。目前業務系統需要存儲的數據信息越來越多,主要采用的主要是面向對象的關系數據庫,目前典型的關系數據庫有SQL Server系列的數據庫、Oracle數據庫與MySQL數據庫。目前網絡爬蟲系統開發中,MongoDB數據庫是目前典型的非結構化應用的數據庫。數據信息存儲在一個大倉庫,而是根據數據信息的類別存儲到不同的表格中,能夠有效增加數據信息的靈活性。數據信息的查詢能夠采用標準的SQL語句,方便技術人員快速上手進行操作[3]。
三、需求分析
(一)系統業務分析
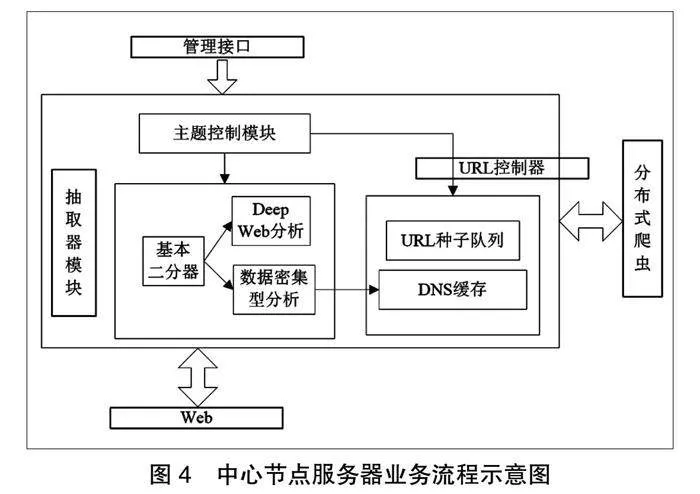
爬蟲系統的基本工作原理為:爬蟲系統從待抓取URL隊列中取出一個URL作為程序的入口地址,通過DNS解析后找到該URL對應的網站頁面,在頁面中提取到的頁面內容存入MongoDB數據庫[4]。爬蟲系統體系結構如圖1所示。
(二)系統功能需求分析
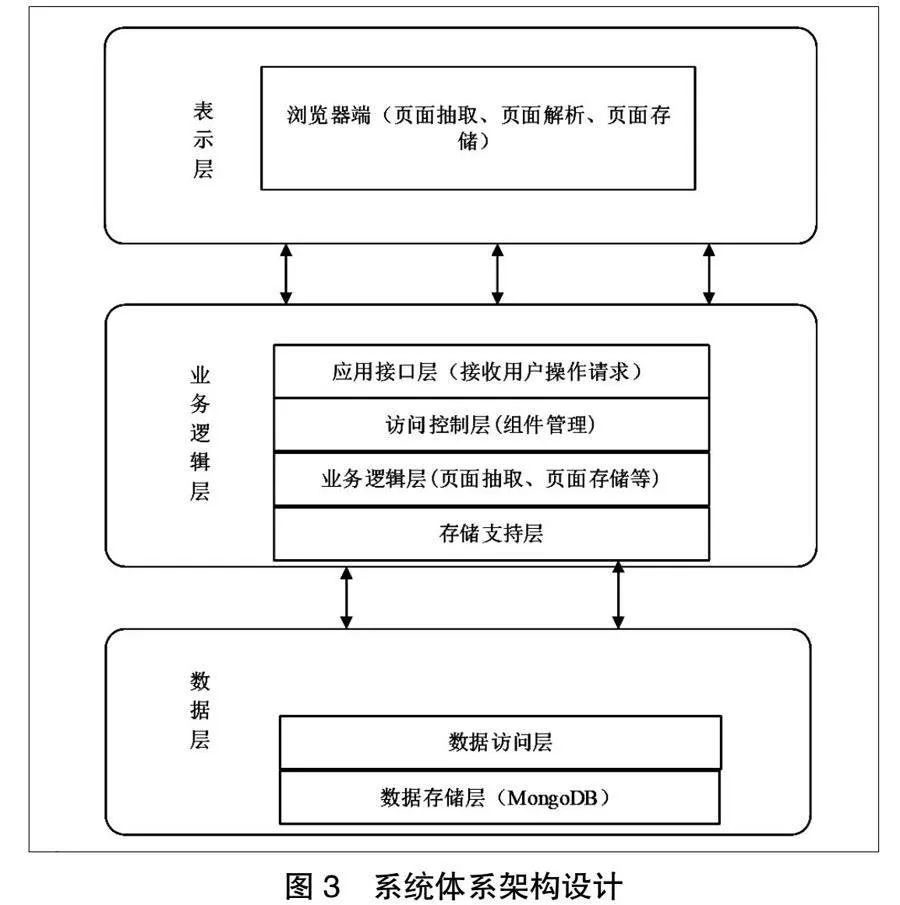
系統業務功能主要包括頁面抓取、頁面解析與頁面存儲,詳細系統總體用例圖如圖2所示。
圖2 系統業務功能用例圖
具體系統業務功能用例內容包括:首先,頁面抓取功能:在頁面抓取的工作過程中,先給出一個URL作為起始點,網絡爬蟲處于該位置點進行檢索提取操作,找到使用的客戶端主機名稱和網絡端口信息[5]。其次,頁面解析功能:對于網絡中的各類網頁,能夠通過正則表達式進行規則搜索及解析。最后,數據存儲功能:在過程中,通過正則表達式來對頁面進行篩選,將信息以JSON的形式存儲[6]。
(三)系統性能需求分析
對這些性能指標明確敘述后,主要的工作需要對系統的性能進行說明,以此保障系統的性能具備良好的運行保障,這些性能方面的內容主要分為響應的時間、系統用戶并發與系統穩定操作方面的內容,詳細的這些性能指標具體闡述:
首先,可靠性方面的指標。一方面是需要確保系統遇到攻擊時候同時具備良好的穩定性,能夠快速恢復穩定運行;另外一方面是系統能夠穩定運行的時間,因此需要系統能夠長時間保持穩定狀態運行[7]。其次,并發人數。對于系統的使用而言,需要考慮并發性的因素,結合系統的需求來確定,系統的并發人數客戶應在500用戶以上,使得系統后期在系統運行時候能夠適應人數的并發使用[8]。最后,系統功能模塊響應時間。對于系統而言,每次用戶操作后,系統進行響應,這些功能模塊的最大響應時間不宜超過5s,如果超過該響應時間,則必然降低系統使用的交互性,以此提升系統的響應效率,滿足用戶的操作需要[9]。
四、關鍵技術研究與應用
(一)體系架構設計
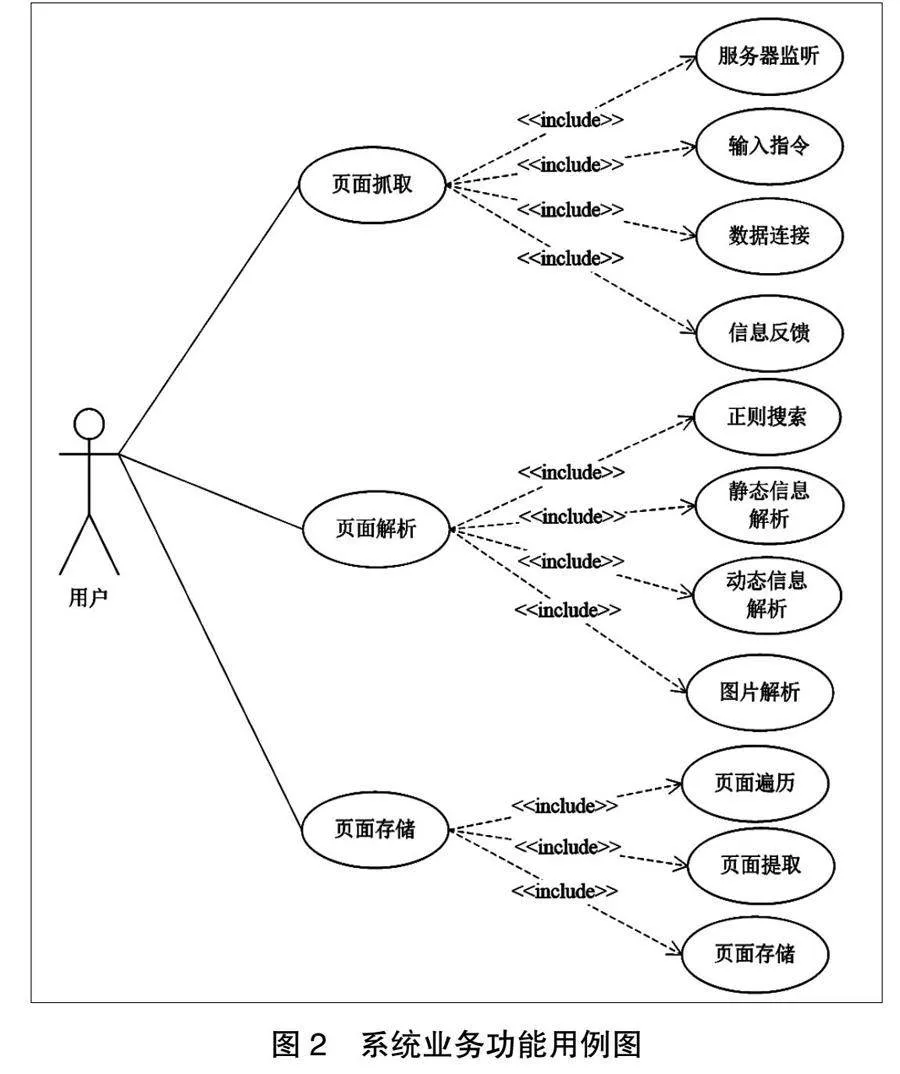
在系統總體設計中,按目前系統設計模式,需要完成系統架構設計。這些架構設計工作重點是確定三層架構設計,每一層設計架構包括數據層、表現層與業務邏輯層,這些層次架構每一的目標與使用方式不同,設計架構如圖3所示。
圖3 系統體系架構設計
結合系統體系架構設計來說,系統采用微服務的設計方式,主要從三層架構設計的方式進行處理,不同層次架構之間耦合度應盡量降低,每一層工作內容與工作目標不同,以此滿足系統的處理需要。
1.表現層
系統中的用戶角色分為用戶與管理員,這些用戶在表現層對系統的功能進行操作,用戶能夠完成網絡輿情信息的抓取、解析與存儲操作。表現層設計的原則是友好便利化,用戶根據系統的提示能夠快速完成各個模塊的操作[10]。
2.業務處理層
在系統中,系統的主要處理源碼在業務處理層,結合需求分析階段的功能,這部分源碼包括頁面抓取、頁面解析、頁面存儲等功能。用戶與管理員對這些模塊進行操作,每一項業務功能的操作需要完成對應數據的存儲與更新,后將數據信息返回到表現層。
3.數據層
這一層次主要目標是完成系統中所有數據信息的存儲,結合系統處理需要,系統需要存儲表格包括頁面信息等內容,不同的數據庫表格需要確定數據存儲的字段、長度與類型,這些數據庫存儲用戶操作的信息。
(二)系統技術架構設計
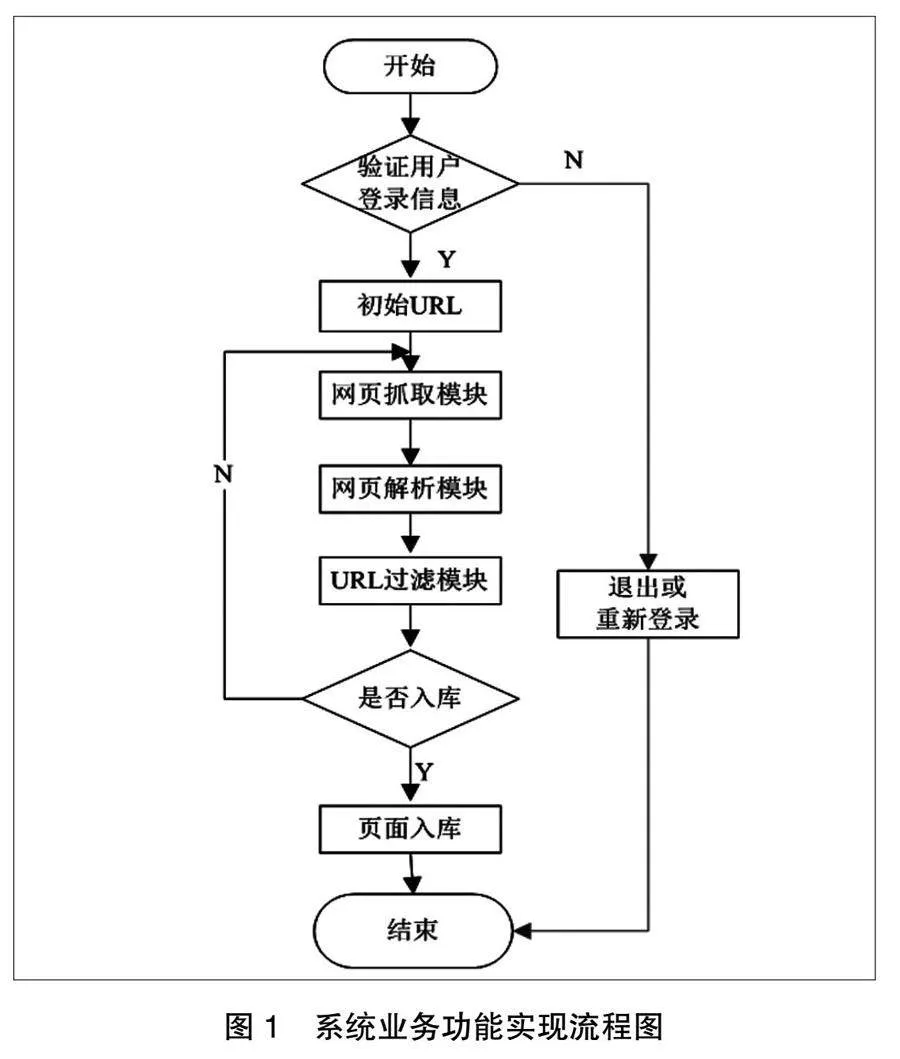
在實現的網絡爬蟲管理系統中,中心節點負責控制,包括URL控制、抽取器學習及主題控制,如圖4所示。
圖4 中心節點服務器業務流程示意圖
在中心節點服務器中,主要包括的模塊:第一,主題控制模塊。本模塊完成關于主題的操作,包括對主題的描述、添加和刪除;控制主題抓取頻率;編輯每個主題種子隊列。第二,抽取器學習模塊。本模塊采用基于內容的網頁分析算法,從URL種子入手,訓練形成針對種子代表的權威站點的數據抽取器。第三,URL控制器。URL模塊主要負責中心節點內的URL隊列的排序,并根據各子節點負載反饋進行任務分割[11]。
(三)系統測試效果分析
在網絡爬蟲系統的測試操作中,系統的測試目標需要滿足穩定運行,因此需要確定系統在功能、接口與性能等多個方面的反應需要。在功能方面,通過系統的功能測試能夠有效發現每一個前臺與后臺功能可能出現的缺陷,有效識別這些可能出現的缺陷,滿足系統的穩定可靠運行。對于系統的性能,需要結合性能需求方面提出的目標,主要是響應時間、并發性與可靠性方面的要求,測試階段需要滿足這些具體的性能指標;對于系統的接口,需要判斷數據處理的流程、前后臺接口能否正常完成數據的流轉處理,以此滿足系統穩定可靠地運行,實現網絡輿情信息的抓取、解析與存儲等操作[12]。
五、 結束語
對于網絡輿情爬蟲系統實現來說,開發關鍵的內容主要是確定兩個方面,第一個是確定系統采用的開發技術,充分對比不同開發技術的優劣,確定采用Python開發語言;第二個方面是以實現系統的需求為核心,以此完成系統的功能模塊的分析、設計與測試,核心功能包括頁面抓取、頁面解析與頁面存儲等內容。目前系統在測試后,其總體的功能保持穩定可靠地運行,后期主要在系統穩定可靠性方面不斷進行持續改進優化,第二個方面結合用戶的具體使用意見完善系統的操作界面。
作者單位:王小月 江蘇宿遷澤達職業技術學院
參考文獻
[1]李琳.基于Python的網絡爬蟲系統的設計與實現[J]. 信息通信,2017,(09):26-27.
[2]趙茉莉. 網絡爬蟲系統的研究與實現[D].電子科技大學,2013.
[3]張明杰.基于網絡爬蟲技術的輿情數據采集系統設計與實現[J].現代計算機,2015,(12):72-75.
[4]Aghamohammadi A, Eydgahi A. A novel defense mechanism against web crawlers intrusion. Electronics, Computer and Computation (ICECCO), 2013 International Conference on. IEEE, 2013:269-272.
[5]段兵營. 搜索引擎中網絡爬蟲的研究與實現[D].西安電子科技大學,2014.
[6]Bhushan R, Nath R. Web Crawler–A Review. International Journal of Advanced Research in Computer Science and Software Engineering. 2013, 8(03): 54-57.
[7]郭麗蓉. 基于Python的網絡爬蟲程序設計[J]. 電子技術與軟件工程,2017,(23):248-249.
[8]龔千軍. 基于網絡爬蟲的多媒體課件下載系統設計與實現[J]. 電腦編程技巧與維護,2016,(9):70-71.
[9]Brin, Sergey, and Lawrence Page. “The anatomy of a large-scale hypertextual Web search engine.” Computer networks and ISDN systems30.1 (1998): 107-117.
[10]褚宏爽.主題搜索引擎網絡爬蟲的設計與實現[D].北京郵電大學,2013.
[11]姜杉彪,黃凱林,盧昱江,等. 基于Python的專業網絡爬蟲的設計與實現[J]. 企業科技與發展,2016,(08):17-19.
[12]惠瑩.基于爬蟲技術的校園網絡輿情監測元數據管理研究[J]. 電腦編程技巧與維護,2018,(01):116-118.
猜你喜歡
文藝生活·中旬刊(2016年10期)2016-11-04 06:41:44
人間(2016年26期)2016-11-03 18:09:39
中國科技博覽(2016年22期)2016-11-01 16:54:22
體育時空(2016年8期)2016-10-25 20:49:09
商業會計(2016年15期)2016-10-21 08:39:00
中學課程輔導·教師教育(中)(2016年9期)2016-10-20 15:42:46
中國科技博覽(2016年19期)2016-10-19 13:39:32
中國實用醫藥(2016年24期)2016-10-17 05:47:48
科學與財富(2016年28期)2016-10-14 21:11:35
科學與財富(2016年28期)2016-10-14 01:19:24
