基于改進雙重深度Q網絡主動學習語義分割模型
2024-12-31 00:00:00李林劉政南海張澤崴魏曄
計算機應用研究 2024年11期
關鍵詞:主動學習

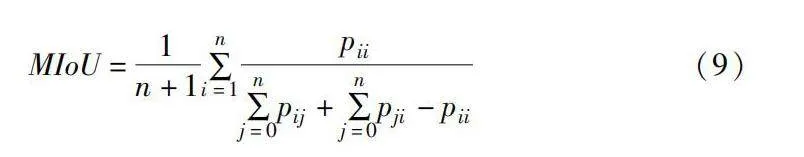

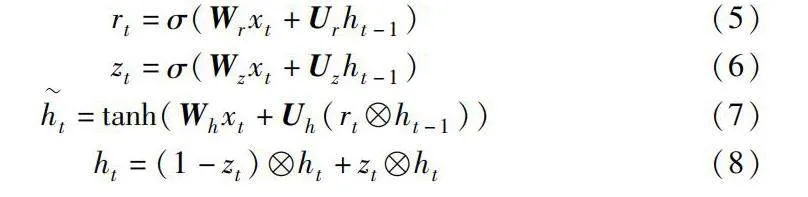


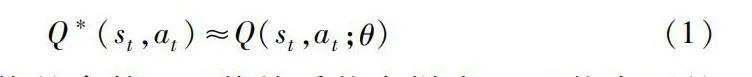
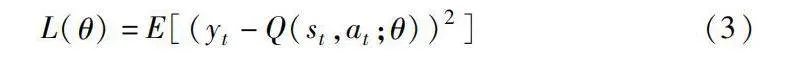
摘 要:針對在圖像語義分割任務中獲取像素標簽困難和分割數據集類別不平衡的問題,提出了一種基于改進雙重深度Q網絡的主動學習語義分割模型CG_D3QN。引入了一種結合決斗網絡結構以及門控循環單元的混合網絡結構,通過減輕Q值過估計問題和有效地利用歷史狀態信息,提高了策略評估的準確性和計算效率。在CamVid和Cityscapes數據集上,該模型相較于基線方法,所需的樣本標注量減少了65.0%,同時對于少樣本標簽的類別,其平均交并比提升了約1%~3%。實驗結果表明,該模型能夠顯著減少樣本標注成本并有效地緩解了類別不平衡問題,且對于不同的分割網絡也具有適用性。
關鍵詞:深度強化學習;主動學習;圖像語義分割;決斗網絡;門控循環單元
中圖分類號:TP391 文獻標志碼:A 文章編號:1001-3695(2024)11-019-3337-06
doi:10.19734/j.issn.1001-3695.2024.02.0070
Active learning semantic segmentation model based on improved double deep Q network
Li Lin, Liu Zheng, Nan Hai?, Zhang Zewei, Wei Ye
(College of Computer Science amp; Engineering, Chongqing University of Technology, Chongqing 400054, China)
Abstract:This paper proposed an active learning semantic segmentation model named CG_D3QN, based on an improved dual deep Q-network, to address the challenges of acquiring pixel labels and class imbalances in image semantic segmentation tasks. The model used a hybrid network structure that integrates a dueling network architecture with gated recurrent units. This structure alleviated the overestimation of Q-value and efficiently utilized historical state information, thereby improving the accuracy and computational efficiency of policy evaluation. On the CamVid and Cityscapes datasets, the model reduced the required sample annotation volume by 65.0% and enhanced the mean intersection over union by approximately 1% to 3% for classes with fewer sample labels. Experimental results show that the model significantly reduces the cost of sample annotations and effectively mitigates class imbalance issues, while being adaptable to different segmentation networks.
Key words:
deep reinforcement learning; active learning; image semantic segmentation; dueling network; gate recurrent unit
0 引言
語義分割(semantic segmentation)作為一種像素級圖像語義標簽分類任務,其旨在對圖像中的每個像素進行分類,以實現對圖像語義區域的準確劃分[1]。語義分割在自動駕駛[2]、醫學影像、增強現實等熱門人工智能領域發揮著重要作用,而當前研究主要面臨兩大挑戰。首先,相較于其他圖像分類任務,語義分割數據集需要大量高質量的像素標簽,特別是在一些標注門檻較高的領域,如醫學圖像和國防軍事等,對標注者的專業性要求較高,并且在手工標注的過程中容易產生錯誤,其標注工作需要耗費大量時間和人力成本。其次,語義分割結果可能受到分割數據集中數據不平衡的影響,例如在醫學圖像[3,4]中,數據樣本的年齡和性別比例偏差較大,這種樣本數量的偏差會導致模型性能偏向于數量較多的類別。鑒于許多語義分割研究都面臨數據規模龐大和標注成本高的挑戰,主動學習作為一種降低模型對數據依賴性的方法備受關注[5]。
主動學習(active learning,AL)[6]也稱為查詢學習或最優實驗設計,其核心思想是通過自適應地選擇信息量最大的樣本進行標注和訓練,以在不影響模型性能的前提下降低標注成本。主動學習方法大致分為兩類:一類為傳統的手工設計的啟發式方法[7,8],其選擇策略一般是針對于特定的研究目標或數據集,由專家的專業知識或近似理論標準制定。另一類是數據驅動的方法[9,10],其構建基于先前的主動學習經驗,并通過使用標注數據對主動學習策略進行訓練。由于主動學習的過程可以被模擬成序列決策過程,即通過與環境的交互來學習制定一個序列化決策,而強化學習(reinforcement learning,RL)[11]為訓練主動學習查詢策略的方法提供了可能性。
目前,相比圖像分類[12],語義分割主動學習的研究較少,傳統的主動學習語義分割主要依賴于手工設計的啟發式方法,其中最基本的主動學習算法是隨機采樣策略(random),該策略通過隨機選擇未標注樣本池中的樣本進行標注。Cai等人[13]提出了一種基于標記圖像區域的成本設計獲取函數,然而在實際應用中,這些信息并非是靜態固定的,從而限制了其適用性。Mackowiak等人[14]提出了一種不考慮圖像標記成本,而是基于區域的方法來處理大量分割樣本的主動學習算法。Gal等人[15]提出了一種基于預測熵的決策不確定性主動學習(BALD),使用Bayesian卷積神經網絡來進行主動學習。盡管上述方法在解決語義分割領域取得了一些進展,但它們是針對特定數據集的方法,限制了模型的泛化能力和魯棒性。
隨著深度學習領域的發展,在強化學習領域中引入了深度神經網絡,衍生出深度強化學習(deep reinforcement learning,DRL)。當前使用強化學習的主動學習方法通常采用每次標注一個樣本的策略[16,17],直到達到樣本預算。然而,在處理大規模語義分割數據集時,在每次標注后都需要重新更新分割網絡并計算相應獎勵,導致效率較低。Sener等人[18]提出了基于核心集合選擇的主動學習算法,該算法逐次選擇一批具有代表性的樣本,提高了標注效率。Dhiman等人[19]通過結合深度強化學習(DRL)、主動學習與循環神經網絡(RNN),提出了用于流媒體應用的自動標注模型,提高了檢索的精度和性能。Chan等人[20]通過加權后驗類概率和先驗類概率減少了對分割網絡的影響。Casanova等人[21]提出了基于強化學習的主動學習方法(Rails),這是一種從數據中發現主動學習策略的通用方法,但在其主動學習過程中,仍面臨標簽類別不平衡問題。
為了解決上述問題,本文提出了一種數據驅動的主動學習語義分割方法,通過從未標記圖像集合中選擇并請求最相關區域的標簽,實現了在僅有少量帶注釋的像素標簽樣本下訓練高性能的分割網絡。主要貢獻如下:
a)提出了一種基于改進雙重深度Q網絡的主動學習語義分割模型。該模型將基于池的主動學習過程轉換為馬爾可夫決策過程,使用基于價值的深度強化學習方法,訓練出能夠有效篩選一批標注圖像區域的策略網絡。該方法的設計關鍵在于通過選擇區域而非整個圖像來提取圖像的關鍵信息。
b)針對訓練主動學習查詢策略面臨Q值過估計問題,引入決斗雙重深度Q網絡(dueling double deep Q network,Dueling DDQN)[22]。同時,針對圖像類別不平衡問題,模型引入了卷積神經網絡(CNN)和門控循環單元(gate recurrent unit,GRU)[23]的混合網絡結構(CG),通過提取連續狀態特征和降低算法對當前狀態輸入信息的依賴,提高了算法的魯棒性。
c)使用CamVid和Cityscapes數據集對主動學習模型進行了性能評估。實驗結果顯示,與主動學習基線算法相比,模型的查詢網絡在數量較少的類別上提出了更多的標注請求,從而提高了效率并減輕類別不平衡的問題。同時,將最新的語義分割網絡應用到主動學習模型中,并在CamVid數據集上和原始語義分割算法進行了對比。實驗結果顯示,模型在結合最新的語義分割模型后的性能優于原始語義分割模型。
1 語義分割模型描述
1.1 問題定義
給定k張未標記的樣本,將其放入未標注樣本池Ut,主動學習語義分割方法從Ut中選擇樣本區域進行標注,并同時學習一個查詢網絡,使其作為判別選擇標注區域的方法。將標注后的樣本放入已標注樣本池Lt中,使用Lt中的樣本訓練語義分割模型,迭代直到達到標注預算B。為了達到減少標注預算和類別不平衡的影響,樣本的選擇策略是至關重要的。
為此,本文提出一種基于深度Q網絡的主動學習語義分割模型CG_D3QN,將主動學習語義分割問題轉換為馬爾可夫決策過程(MDP),由元組〈S,A,R,St+1〉構成,定義為:
a)狀態集S。表示一組狀態值,對于每一個狀態st∈S,智能體在at∈A執行選擇從Ut中標記哪些樣本區域。
b)動作集A。表示動作at=ant,由n個子動作構成,每一個子動作都表示在樣本上標注一個區域,其依據語義分割網絡、已標注樣本池Lt和未標注樣本池Ut獲得。
c)獎勵集R。表示每次主動學習迭代后獲得的獎勵值rt+1∈R,通過主動學習流程中當前和上一輪分割網絡在DR上性能的差值計算。其中,DR是用來評估分割網絡性能的一個單獨的數據樣本子集。
d)狀態集St+1。表示下一個時間步數的狀態值。
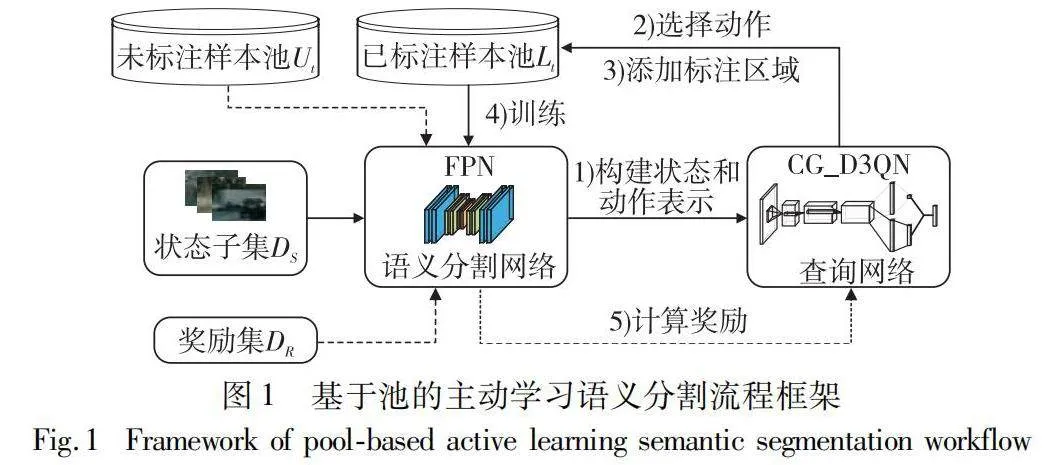
采用基于池的主動學習流程框架作為模型的整體架構,特征金字塔網絡(feature pyramid networks,FPN)[24]作為語義分割網絡,其流程框架如圖1所示。將查詢網絡建模為強化學習的智能體,其他部分建模為強化學習的環境。其中,狀態子集DS包含了所有類別的數據樣本,是整個數據集的代表性樣本子集。訓練時,智能體根據環境獲取狀態和動作表示,使用強化學習模型和來自經驗緩沖區中的樣本來訓練查詢網絡,查詢網絡選擇動作at,并將標注區域添加到已標注樣本池中,語義分割網絡FPN更新并計算獎勵,迭代訓練直到達到標注預算。
綜上所述,基于改進雙重深度Q網絡的CG_D3QN模型的目標是訓練強化學習的智能體,使其根據當前環境自適應的選擇動作,并對樣本區域進行標注,以獲得最大獎勵值rt+1。
1.2 構建語義分割的狀態表示和動作表示
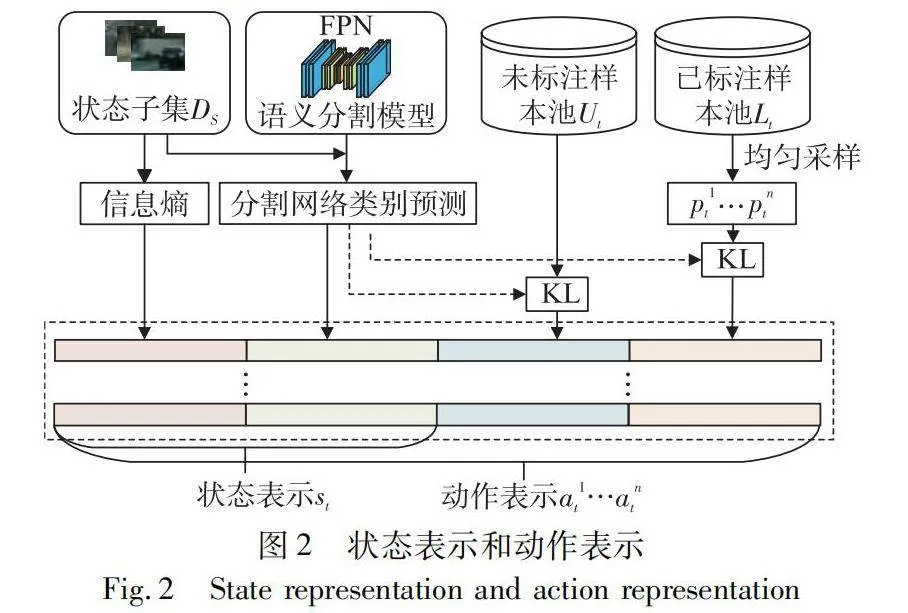
由于語義分割是像素級的語義標簽分類任務,為了避免占用大量的內存空間,借助狀態子集DS構建強化學習的狀態表示,將DS的樣本劃分為多個patch,并計算所有patch的特征向量。在狀態表示的構建過程中,首先在狀態子集的圖像樣本區域中,計算每個像素位置的信息熵,并采用最大值、最小值和平均值三種池化操作對信息熵進行下采樣生成第一組特征向量。接著,使用分割網絡對每個類別的像素數量進行預測,并對這些預測值進行歸一化處理,生成第二組特征向量。最后,每個樣本區域由這兩組特征向量串聯形成編碼,用來表示狀態st。
在主動學習語義分割過程中,采取動作表示對未標注區域逐像素進行標注,然而每一次的請求動作都需要計算未標注樣本的每個區域的特征,耗費了大量的成本。針對此問題,首先在構建動作表示過程中,對于每個時間步t,從未標注樣本池中以均勻采樣的方式選取n個未標記的區域池pnt,使其近似表示整個未標記樣本。然后在數據池pnt中選取候選區xt,對每個類別的預測像素歸一化計數。之后計算已標注區域和未標注區域與分割網絡預測類分布的KL散度,構成兩組特征向量。最后,將其和狀態表示串聯構成動作表示ant。語義分割的狀態表示和動作表示如圖2所示。
1.3 網絡模型
1.3.1 雙重深度Q網絡
雙重深度Q網絡(double deep Q network, DDQN)是深度Q網絡(deep Q network, DQN)的一種改進算法。DDQN相對于DQN算法的主要區別在于其采用了雙重Q學習來尋找最優策略,其通過將目標Q值的動作選擇和價值評估過程解耦,以達到消除過度估計偏差的目的。DDQN算法利用深度卷積神經網絡來擬合狀態-動作值函數:
Q*(st,at)≈Q(st,at;θ)(1)
其中:θ表示主網絡的參數。網絡接受狀態樣本st和狀態下的動作at作為輸入,然后輸出相應的Q值。在訓練過程中,選取主網絡產生最大Q值的動作,將該動作輸入到目標網絡以進行狀態-動作值函數的評估:
yt=rt+1+γQ(st+1,arg maxat+1∈pnt+1Q(st+1,at+1;θ);θ-)(2)
其中:θ-表示目標網絡的參數;rt+1為即時獎勵值;γ為折扣因子。訓練的目標在于最小化目標值與預測值之間的誤差,通常被稱為時序差分誤差(TD-error)。主網絡的損失函數定義為
L(θ)=E[(yt-Q(st,at;θ))2](3)
其中:主網絡和目標網絡的參數更新是異步的,這種方式有效地分離了樣本數據和網絡訓練之間的相關性。
1.3.2 決斗網絡
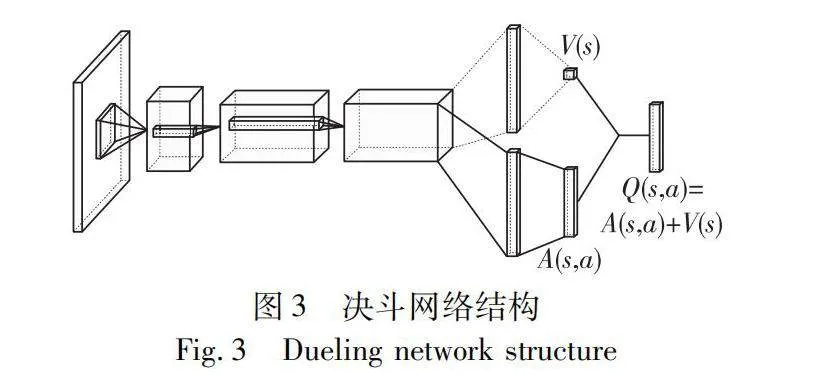
決斗深度Q網絡(dueling deep Q network,Dueling DQN)在主網絡和目標網絡上均加入了決斗網絡結構,其主網絡結構如圖3所示。
在決斗網絡結構中,顯式地將Q值函數Q(s,a)分解為兩個部分:一部分是狀態s下的價值函數V(s);另一部分是在狀態s下,采取a動作的優勢函數A(s,a)。
Dueling DQN通過這種將價值函數解耦的方式,進一步提高了動作價值函數的預測準確性,其最終輸出的動作Q值函數表達式為
Q(s,a;θ,α,β)=
V(s;θ,β)+A(s,a;θ,α)-1|A|∑a′A(s,a′;θ,α))(4)
其中:θ為公共的網絡參數;β為狀態價值函數的網絡參數;αt為動作優勢函數的網絡參數;V(st;θ,β)為狀態st的價值函數,表示當前狀態是否有利于獲取未來的累計獎勵;A(st,at;θ,αt)為動作優勢函數,表示各個可選的動作對當前狀態的有益程度;a′t為可能采取的動作;1|A|∑a′A(s,a′;θ,α)為動作優勢函數的平均值。組合這兩個評估值并計算每個動作的優勢,能夠更好地理解狀態值和不同動作之間的差異,從而更有效地估計Q值。
1.3.3 門控循環單元
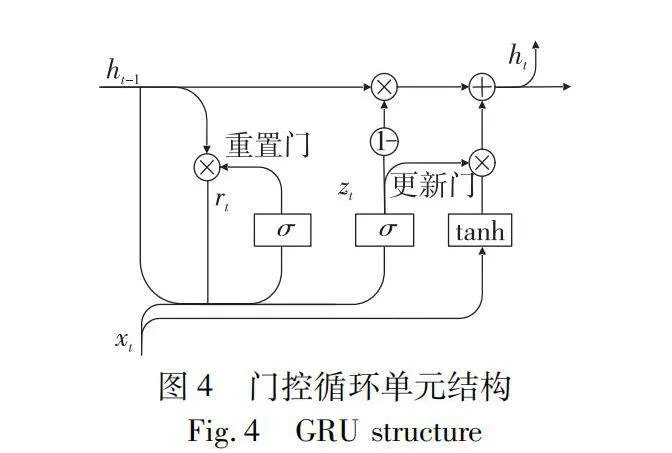
門控循環單元(GRU)在循環神經網絡(RNN)的基礎結構上引入了門控機制,解決了RNN的梯度消失問題,并進一步提高了模型的性能,其結構如圖4所示。
GRU的門控機制包括重置門rt和更新門zt。通過控制重置門打開或關閉操作,可以達到遺忘信息的目的;更新門決定當前對于前一時刻信息的保存或者遺忘,獲得數據之間的長期依賴關系。GRU的輸入為當前時刻輸入xt和上一時間步的隱藏狀態信息ht-1,輸出為當前時間步隱藏狀態信息ht:
rt=σ(Wrxt+Urht-1)(5)
zt=σ(Wzxt+Uzht-1)(6)
ht=tanh(Whxt+Uh(rtht-1))(7)
ht=(1-zt)ht+ztht(8)
其中:σ為sigmoid函數,將t時刻的門控信號rt和zt的輸出范圍控制在[0,1];tanh為激活函數,將候選隱藏狀態ht的值范圍控制在[-1,1];Wr、Wz、Wh、Ur、Uz、Uh為門控機制的權重矩陣。
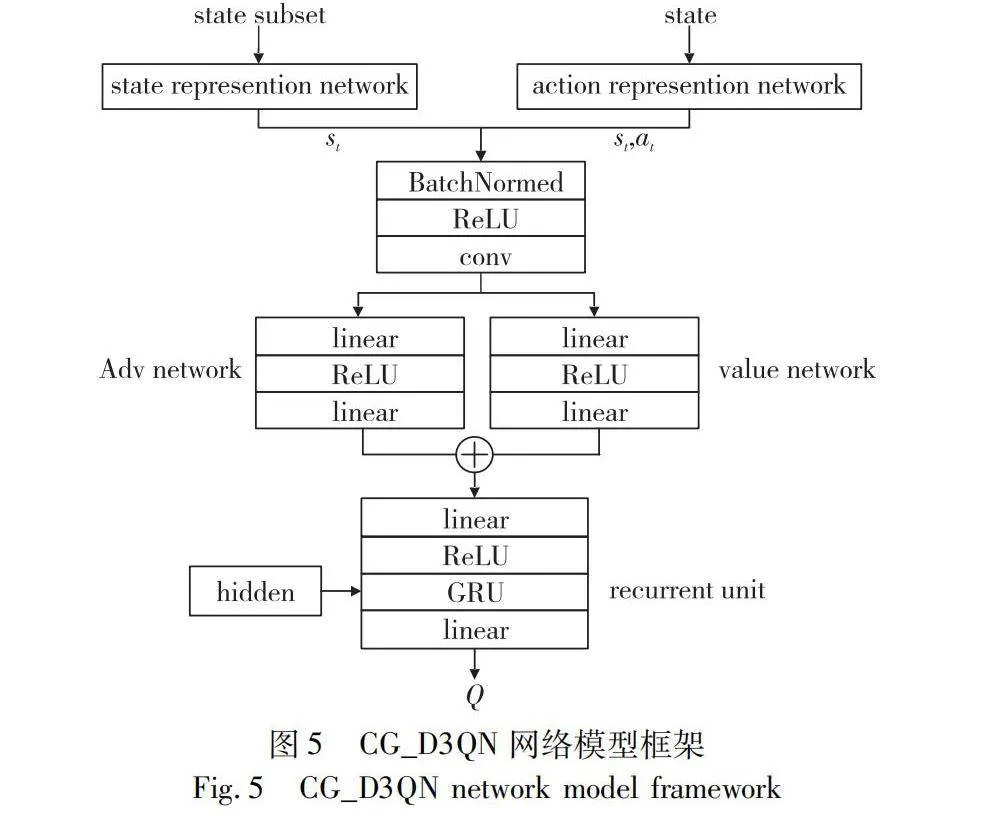
1.3.4 CG_D3QN網絡模型
為了使查詢網絡模型更好地理解在語義分割中狀態值和不同動作之間的差異,提高模型的學習效率并緩解深度Q網絡的過度估計問題,將DDQN與決斗網絡結構融合,構成了決斗雙重深度Q網絡(Dueling DDQN,D3QN)。同時,由于狀態信息來自于對圖像樣本的局部區域,表明環境是一個部分可觀測的馬爾可夫決策過程(POMDP),Q值的大小不僅與狀態、動作有關,也和歷史狀態信息有關。因此,將CNN與GRU的混合網絡模型(CG)引入D3QN中,構成了CG_D3QN模型。CG_D3QN模型使用CG網絡進行Q函數的擬合,并通過D3QN網絡對整個網絡結構進行優化,實現使用少量的標注數據得到高性能的分割網絡。CG_D3QN網絡模型框架如圖5所示。
CG_D3QN網絡模型的設計思路如下:
首先將狀態和動作信息進行組合,并進行特征提取,利用由Bias網絡計算出動作表示的KL距離分布特征作為系數,對狀態動作值進行加權,以獲取更準確的動作狀態價值;然后對得到的動作狀態價值分別進行價值評估和優勢評估;最后通過CG網絡對狀態的歷史信息進行編碼,并將其記錄到隱藏層中,使得在進行Q值評估時,模型可以充分學習到先前的狀態信息,提高了模型的決策性能。
1.4 CG_D3QN算法流程
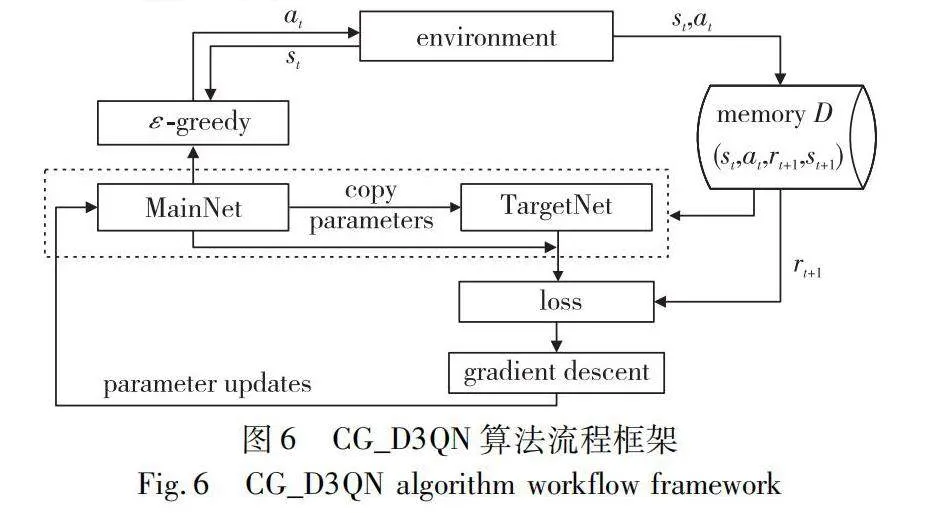
在CG_D3QN算法流程中,使用主網絡MainNet選擇動作,使用目標網絡TargetNet估計價值,其流程框架如圖6所示。作為智能體的查詢網絡從環境中獲取狀態st,使用ε-greedy策略選擇動作at,并將其傳遞給環境,環境更新并計算獎勵值rt+1。將每次與環境交互的結果以(st,at,rt+1,st+1)的形式存儲到經驗池memory D中,每次從中隨機采樣樣本數據到主網絡MainNet和目標網絡TargetNet中,根據兩個網絡的輸出結果和獎勵值rt+1,計算損失函數并更新主網絡的網絡參數。當訓練達到規定的周期,將MainNet的網絡參數復制給TargetNet,完成對目標網絡的優化。
CG_D3QN算法流程如算法1所示。
算法1 CG_D3QN主動學習框架
輸入:分割網絡f;狀態子集DS;訓練子集DT;回合數N;經驗回放池pnt;標注預算B。
輸出:策略π。
a) 初始化分割網絡權重σ,構建區域池pnt。
b) for episode in 1,2,…,N:
c) 通過分割網絡和狀態子集DS計算當前狀態st;
d) while 選取的區域數小于預算B:
e) 查詢網絡采用ε-greedy策略選取動作at,從區域池pnt中選取n個未標注像素區域,并計算下一狀態st+1;
f) 使用更新的標注樣本池來訓練分割網絡f;
g) 通過上一時間步的分割網絡和使用新增區域訓練后的網絡性能差值計算智能體獎勵rt+1;
h) 將軌跡(st,at,rt+1,st+1)存入經驗回放池;
i) 從回放池中均勻采樣出部分經驗,訓練策略網絡并更新網絡參數θ,得到區域選擇策略π;
j) end while
k) end for
2 實驗與結果分析
2.1 數據集與評價指標
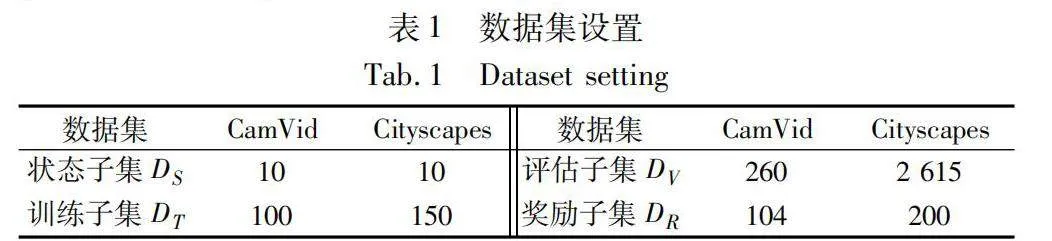
為了驗證CG_D3QN模型的可行性,選用CamVid和Cityscapes數據集評估語義分割性能。CamVid數據集由車載相機拍攝采集,包含370張訓練集圖像,104張驗證圖像以及234張測試圖像,圖像分辨率為360×480,提供11個類別的像素級標簽,涵蓋道路、建筑、汽車、行人等類別。Cityscapes數據集是一種城市街道場景的大規模數據集,包含3 475張2048×1024分辨率的高質量圖像,其中2 975張用于訓練,500張用于驗證,共涵蓋19個類別。實驗數據集被劃分為四個子集,其詳細信息如表1所示。
其中,訓練子集DT用于在固定的標注樣本的像素區域預算B下訓練查詢網絡;狀態子集DS和訓練子集DT均通過均勻采樣訓練集獲得;獎勵子集DR來自于驗證集或訓練集中均勻采樣獲得的剩余數據;評估子集DV來自于經過采樣后保留的大量訓練集數據樣本。
實驗采用平均交并比(mean intersection over union, MIoU)作為分割網絡的性能評價指標。MIoU通過計算所有類別的交并比的算術平均值,對數據集整體的像素重疊情況進行綜合評估,計算公式如下:
MIoU=1n+1∑ni=1pii∑nj=0pij+∑nj=0pji-pii(9)
其中:pii表示分類正確的像素數量;pij表示屬于第i類卻被預測為第j類的像素數量;n表示類別總數。
2.2 實驗環境與參數設置
實驗的編程語言為Python 3.6,使用的程序框架為PyTorch1.10.2;實驗的硬件環境為:顯卡為NVIDIA GeForce RTX 2070 SUPER,處理器為i7 9700 3.0 GHz,顯存8 GB,操作系統為Windows 10。
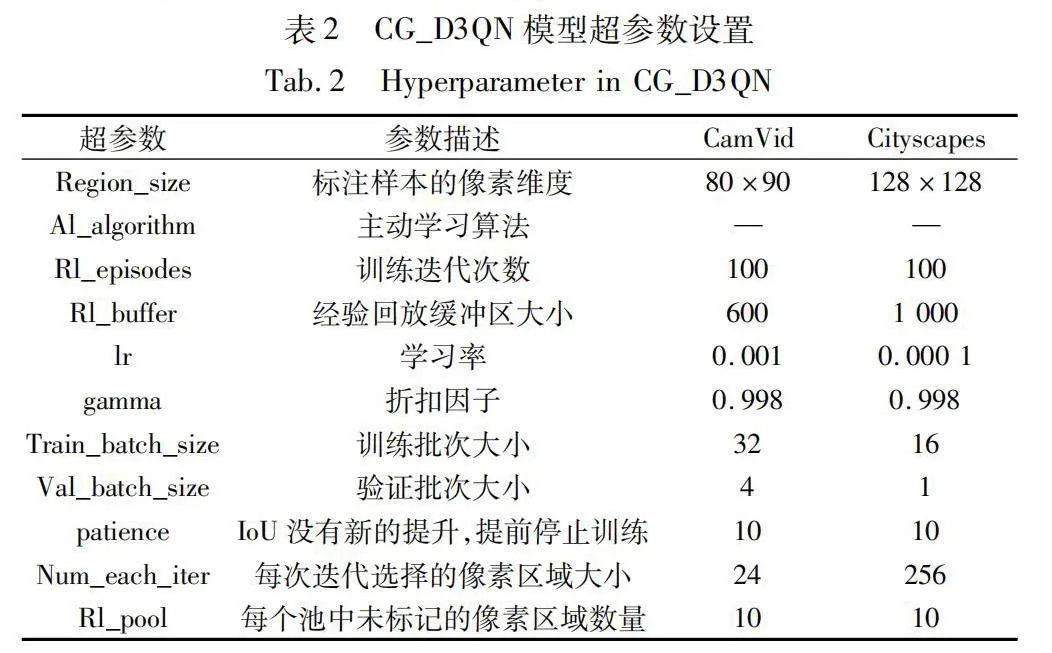
為了提高實驗效率,每次從經驗回放緩沖區中按批次更新網絡參數。強化學習模型的超參數設置如表2所示。
2.3 主動學習對比實驗
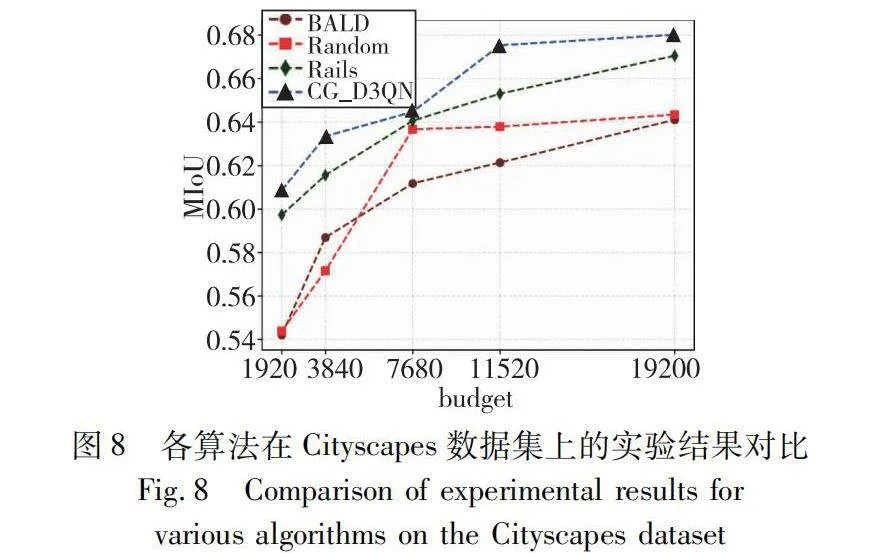
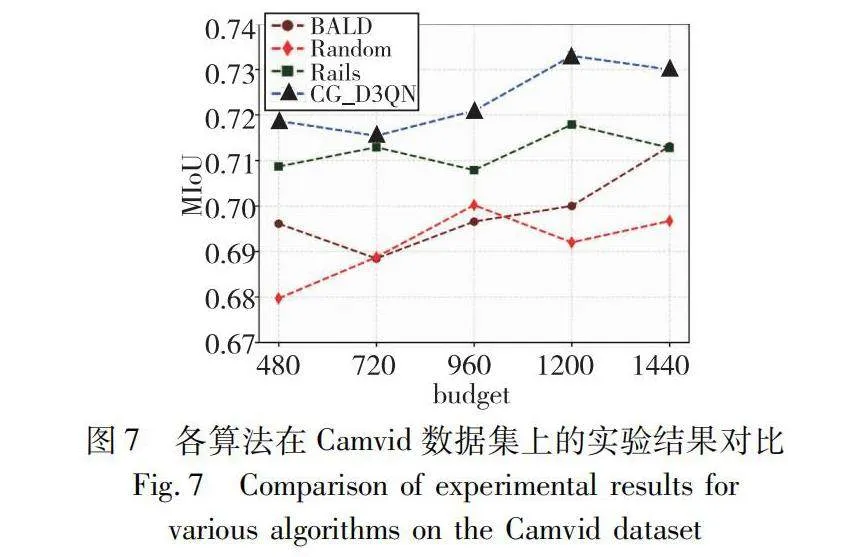
為了驗證模型的最終性能,選用CamVid和Cityscapes數據集進行實驗。使用在GTAV數據集上預訓練過的FPN網絡作為模型的主干網絡。首先,將訓練集的所有數據設置為1個epoch,并使用不同的隨機種子進行五次獨立實驗,實驗訓練100個episode,最終得到主動學習的查詢網絡。本文分別使用Rails、BALD、Random三種主動學習方法與基于CG_D3QN的主動學習語義分割模型進行對比,并在不同的像素區域預算下進行驗證。通過綜合分析驗證階段的MIoU來評估模型的訓練效果。四種主動學習方法的實驗結果如圖7、8所示,其中x軸為用于訓練的標注像素區域數量,y軸表示MIoU水平。
通過觀察圖7在Camvid小規模數據集上的實驗結果可知,傳統的隨機采樣方法Random和最大不確定性方法BALD在不同預算下表現都較差,這說明使用新獲得的標簽進行訓練并不能提供額外的信息。此外,CG_D3QN方法相對于其他模型有1%~5%的提升,說明更多的標簽預算有助于模型性能的提升。實驗結果證明了CG_D3QN的區域選擇策略可以幫助分割模型避免陷入局部最優,并提高語義分割模型的整體性能。由于Camvid數據集的數據樣本量較小,所有結果都有較大方差,于是實驗在大規模數據集Cityscapes下進行了進一步驗證。
圖8展示了Cityscapes數據集在不同預算水平時的性能表現,在3 840的像素預算條件下,CG_D3QN方法取得了63.3%的MloU水平,同時基線算法Ralis還需額外標注65%的像素才能達到同樣的性能。實驗結果進一步說明了CG_D3QN在處理大規模語義分割數據集時,能夠穩定有效地篩選需要標注的圖像像素區域。
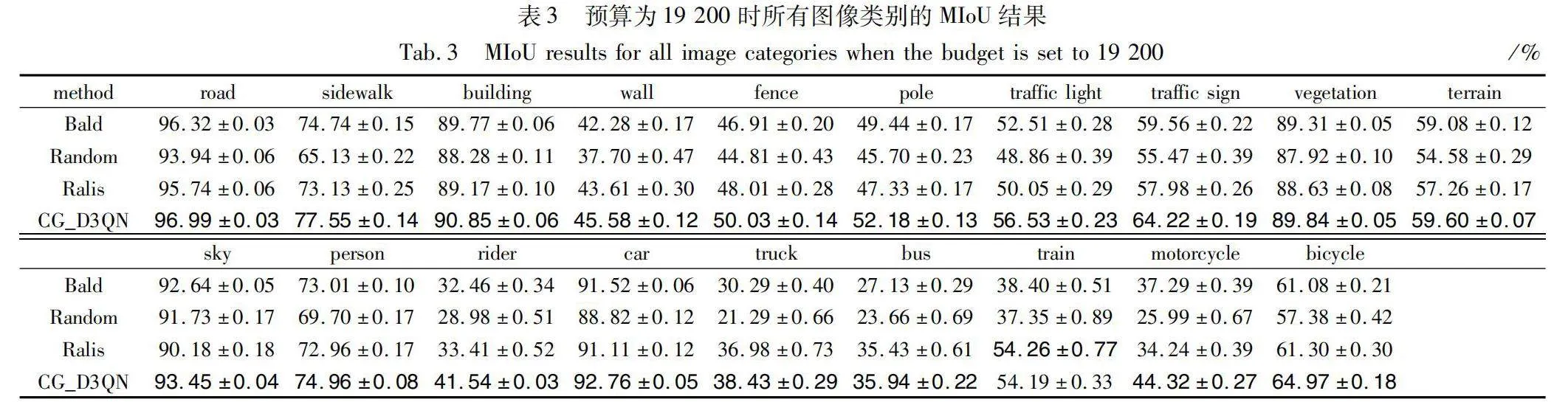
表3詳細記錄了在像素區域預算為19 200時,Cityscapes數據集的19個類別下,四種主動學習方法的MIoU以及帶有標準差的結果,其中加粗的數據表示MIoU的最大值。實驗表明,在不同類別中,CG_D3QN方法相較與其他主動學習方法能夠維持較高的MIoU水平。同時,對于樣本量較小的類別如Person、Motorcycle、Bicycle等,CG_D3QN同樣保持了較高的MIoU水平,驗證了本文方法在處理圖像數據集中的類別不平衡問題上的有效性。
為了直觀地展示CG_D3QN的優勢,本節在保持預算一致的條件下,對選定圖像的像素區域選擇結果進行了可視化分析,具體結果如圖9所示。通過與傳統的主動學習方法BALD、Random以及強化主動學習方法Rails對比,可以觀察到CG_D3QN在篩選的標注樣本區域中包含了更豐富的標簽信息。此外,CG_D3QN也更注重篩選代表性不足的區域,從而進一步提升模型的整體性能。
2.4 消融實驗
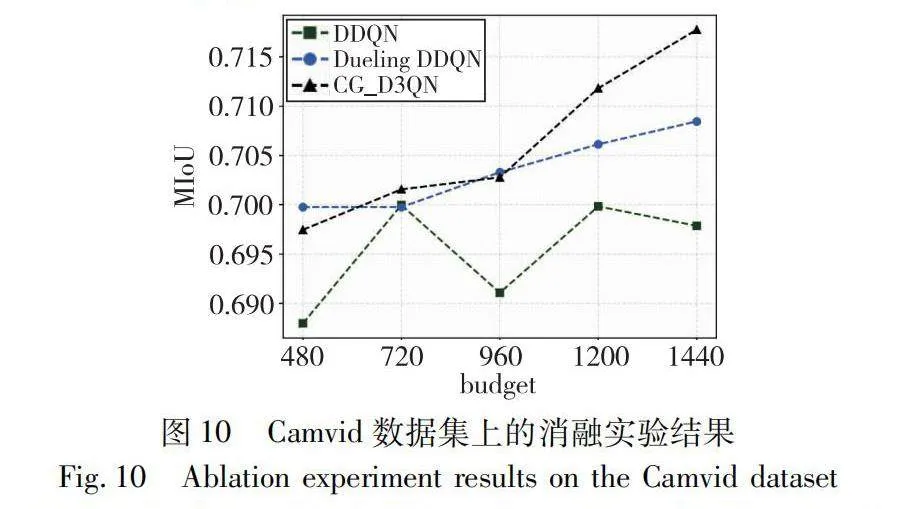
為了驗證CG_D3QN所采用的關鍵技術對模型性能的影響,設置了兩組消融模型,分別驗證了Dueling網絡模塊和聯合卷積神經網絡模塊(CG)對總體網絡性能的影響。對比算法包括原始DDQN模型、Dueling DDQN模型,以及CG_D3QN模型。這三種模型在相同的實驗參數設置下獨立訓練100個episode,實驗結果如圖10所示。
根據實驗結果可以得到以下結論:DDQN模型在不同的像素預算條件下的性能表現波動較大,并且在高預算條件下未能取得顯著改進,說明該方法并不能有效利用新的標簽信息進行決策。相比之下,引入Dueling網絡模塊的Dueling DDQN在低標注預算條件下即可實現較高的MIoU水平,并隨著預算的增加,模型性能逐步提高。這表明Dueling網絡結構能夠理解動作優勢和狀態價值,有效地解決Q網絡的價值過估計問題,從而制定出更有效的圖像區域選擇策略。在Dueling DDQN結構基礎上引入聯合卷積神經網絡模塊的CG_D3QN模型則在高預算條件時獲得了顯著的性能提升,這說明循環網絡結構能夠有效地利用強化學習的歷史狀態信息,使模型能夠學習到更有價值的信息,在大量狀態信息下進一步提高了模型性能。
2.5 分割模型對比實驗
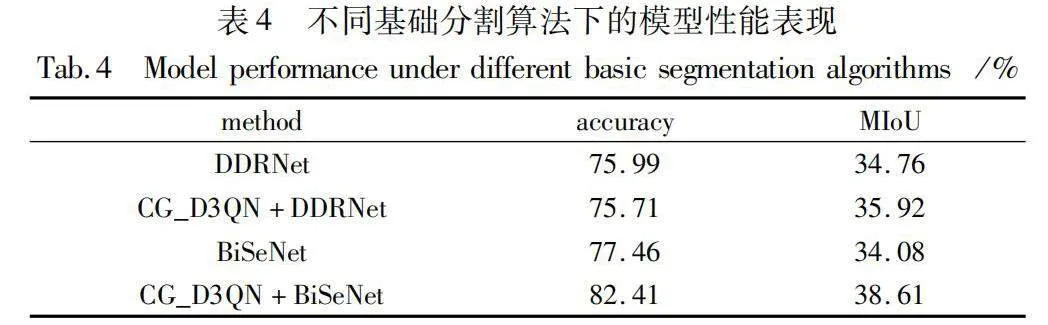
為了驗證CG_D3QN在采用不同的圖像語義分割算法時分割模型仍有性能提升,設計了如下實驗:分別采用經過ImageNet數據集預訓練的DDRNet[25]和BiSeNet[26]作為主動學習框架中的分割網絡,在Camvid數據集上與原始語義分割模型進行對比實驗。將圖像區域預算設置為480,在訓練10個epoch后驗證算法的性能。原始的語義分割網絡使用隨機策略選取圖像區域進行分割訓練,而對比方法則采用CG_D3QN模型選取區域進行訓練。在將新的語義分割算法遷移到CG_D3QN模型兩次實驗中,使用相同的超參數進行訓練。實驗評價指標包括準確率和MIoU,在驗證集下的實驗結果如表4所示。
根據表4的結果顯示,CG_D3QN模型采用不同的語義分割網絡后,在相同的預算條件下,使用CG_D3QN模型進行語義分割的MIoU水平得到了提升。說明了本文方法在采用不同的語義分割網絡后,仍然能夠提升模型的性能,驗證了本文模型的適用性。此外,本節對主動學習的區域選擇策略進行了可視化分析。圖11的結果顯示,在Camvid數據集上,通過引入主動學習模型CG_D3QN,DDRNet與BiSeNet這兩種分割網絡選擇的樣本區域的標簽信息量顯著增加,進一步驗證了本模型的優越性。
3 結束語
本文提出了一種基于區域的、數據驅動的主動學習語義分割模型CG_D3QN。該模型旨在解決語義分割任務中存在的標注任務難度大、數量多,以及圖像樣本存在的類別不平衡問題。CG_D3QN模型在雙重深度Q網絡結構的基礎上,引入了決斗網絡模塊和聯合卷積神經網絡模塊,以在主動學習流程中學習獲取函數,實現以較少的標注樣本量獲得高性能的語義分割網絡。實驗結果表明,該模型在多個數據集中的MIoU均有顯著優勢,并且在大規模數據集中少樣本類別下的效果也有所提升,驗證了模型的有效性。此外,模型在采用不同的語義分割網絡后,分割網絡的性能得到了進一步提升,從而驗證了算法的適用性。在未來的研究中,可以進一步優化強化學習算法,構建新的區域選擇的狀態表示和動作表示,以提升強化模型的特征表示能力,并進一步減少標注量。
參考文獻:
[1]Csurka G, Volpi R, Chidlovskii B. Semantic image segmentation: two decades of research [J]. Foundations and Trends in Computer Graphics and Vision, 2022, 14(1-2): 1-162.
[2]廖文森, 徐成, 劉宏哲, 等. 基于多分支網絡的道路場景實時語義分割方法 [J]. 計算機應用研究, 2023, 40(8): 2526-2530. (Liao Wensen, Xu Cheng, Liu Hongzhe, et al. Real-time semantic segmentation method for road scenes based on multi-branch networks [J]. Applications Research of Computers, 2023, 40(8): 2526-2530.)
[3]Shu Xiu, Yang Yunyun, Xie Ruicheng, et al. ALS: active learning-based image segmentation model for skin lesion [J/OL]. SSRN Electronic Journal. (2022-06-21) [2024-02-05]. https://dx. doi. org/10. 2139/ssrn. 4141765.
[4]張萌, 韓冰, 王哲, 等. 基于深度主動學習的甲狀腺癌病理圖像分類方法 [J]. 南京大學學報: 自然科學, 2021, 57(1): 21-28. (Zhang Meng, Han Bing, Wang Zhe, et al. Thyroid cancer pathological image classification method based on deep active learning [J]. Journal of Nanjing University: Natural Sciences, 2021, 57(1): 21-28.)
[5]劉霄宇, 左劼, 孫頻捷. 基于主動學習的機器學習算法研究進展 [J]. 現代計算機, 2021 (3): 32-36. (Liu Xiaoyu, Zuo Jie, Sun Pinjie. Research progress of machine learning algorithms based on active learning [J]. Modern Computer, 2021 (3): 32-36.)
[6]Siméoni O, Budnik M, Avrithis Y, et al. Rethinking deep active learning: using unlabeled data at model training [C]// Proc of the 25th International Conference on Pattern Recognition. Piscataway,NJ: IEEE Press, 2021: 1220-1227.
[7]Konyushkova K, Sznitman R, Fua P. Learning active learning from data [C] // Proc of the 31st International Conference on Neural Information Processing Systems. Red Hook: Curran Associates Inc., 2017: 4228-4238.
[8]Ren Pengzhen, Xiao Yun, Chang Xiaojun, et al. A survey of deep active learning [J]. ACM Computing Surveys, 2022,54(9): 1-40.
[9]Budd S, Robinson E C, Kainz B. A survey on active learning and human-in-the-loop deep learning for medical image analysis [J]. Medical Image Analysis, 2021,71: 102062.
[10]Hu Zeyu, Bai Xuyang, Zhang Runze, et al. LiDAL: inter-frame uncertainty based active learning for 3D LiDAR semantic segmentation [C]// Proc of European Conference on Computer Vision. Cham: Springer, 2022: 248-265.
[11]Wiering M A, Van Otterlo M. Reinforcement learning [J]. Adaptation, Learning, and Optimization, 2012, 12(3): 729.
[12]范迎迎, 張姍姍. 基于深度主動學習的高光譜遙感圖像分類方法 [J]. 東北師大學報: 自然科學版, 2022, 54(4): 64-70. (Fan Yingying, Zhang Shanshan. Hyperspectral remote sensing image classification method based on deep active learning [J]. Journal of Northeast Normal University: Natural Sciences Edition, 2022, 54(4): 64-70.)
[13]Cai Lile, Xu Xun, Liew J H, et al. Revisiting superpixels for active learning in semantic segmentation with realistic annotation costs [C]// Proc of IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway, NJ: IEEE Press, 2021: 10988-10997.
[14]Mackowiak R, Lenz P, Ghori O, et al. CEREALS-cost-effective region-based active learning for semantic segmentation [EB/OL]. (2018-10-23) [2024-02-05]. https://doi. org/10. 48550/arXiv. 1810. 09726.
[15]Gal Y, Islam R, Ghahramani Z. Deep Bayesian active learning with image data [C]//Proc of International Conference on Machine Lear-ning. New York: PMLR, 2017: 1183-1192.
[16]Hu Mingzhe, Zhang Jiahan, Matkovic L, et al. Reinforcement lear-ning in medical image analysis: concepts, applications, challenges, and future directions [J]. Journal of Applied Clinical Medical Physics, 2023, 24(2): e13898.
[17]Zhou Wenhong, Li Jie, Zhang Qingjie. Joint communication and action learning in multi-target tracking of UAV swarms with deep reinforcement learning [J]. Drones, 2022, 6(11): 339.
[18]Sener O, Savarese S. Active learning for convolutional neural networks: a core-set approach [EB/OL]. (2018-06-01) [2024-02-05]. https://arxiv.org/abs/1708.00489.
[19]Dhiman G, Kumar A V, Nirmalan R, et al. Multi-modal active learning with deep reinforcement learning for target feature extraction in multi-media image processing applications [J]. Multimedia Tools and Applications, 2023, 82(4): 5343-5367.
[20]Chan R, Rottmann M, Hyuger F, et al. Application of decision rules for handling class imbalance in semantic segmentation [EB/OL]. (2019-01-24) [2024-02-05]. https://arxiv.org/abs/1901.08394.
[21]Casanova A, Pinheiro P O, Rostamzadeh N, et al. Reinforced active learning for image segmentation [EB/OL]. (2020-02-16) [2024-02-05]. https://do i.org/10.48550/arXiv.1810.09726.
[22]Wang Ziyu, Schaul T, Hessel M, et al. Dueling network architectures for deep reinforcement learning [C]// Proc of International Confe-rence on Machine Learning. New York: PMLR, 2016: 1995-2003.
[23]Huang Guoyang, Li Xinyi, Zhang Bing, et al. PM2.5 concentration forecasting at surface monitoring sites using GRU neural network based on empirical mode decomposition [J]. Science of the Total Environment, 2021, 768: 144516.
[24]Lin T Y, Dollár P, Girshick R, et al. Feature pyramid networks for object detection [C]// Proc of IEEE Conference on Computer Vision and Pattern Recognition. Piscataway, NJ: IEEE Press, 2017: 2117-2125.
[25]Pan Huihui, Hong Yuanduo, Sun Weichao, et al. Deep dual-resolution networks for real-time and accurate semantic segmentation of traffic scenes [J]. IEEE Trans on Intelligent Transportation Systems, 2022, 24(3): 3448-3460.
[26]Yu Changqian, Wang Jingbo, Peng Chao, et al. BiSeNet: bilateral segmentation network for real-time semantic segmentation [C]// Proc of European Conference on Computer Vision. Berlin: Springer, 2018: 325-341.
猜你喜歡
文藝生活·中旬刊(2016年11期)2016-12-13 23:52:18
成才之路(2016年36期)2016-12-12 14:17:24
文藝生活·下旬刊(2016年11期)2016-12-12 09:49:36
新教育時代·教師版(2016年27期)2016-12-06 16:03:32
新課程·中旬(2016年9期)2016-12-01 11:51:59
中學課程輔導·教師教育(上、下)(2016年20期)2016-12-01 01:40:53
東方教育(2016年16期)2016-11-25 03:06:31
化學教與學(2016年10期)2016-11-16 13:29:16
人間(2016年28期)2016-11-10 22:12:11
計算機教育(2016年7期)2016-11-10 08:44:58
